











 text in
text in  English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink
Introducción
La evapotranspiración de referencia (ETo) es un parámetro agro-meteorológico de uso en muchas áreas de estudio como la geotecnia, climatología e hidrología, donde su mayor importancia radica en el cálculo de la evapotranspiración de cultivo (ETc) en la determinación de requerimientos hídricos en los cultivos agrícolas (Čadro, Uzunović, Žurovec, & Žurovec, 2017; Jovic, Nedeljkovic, Golubovic, & Kostic, 2018; Webb, 2010; Zhang, Gong, & Wang, 2018). La ETo se define como la “tasa de evapotranspiración de una superficie de referencia hipotética que presentan características específicas” (Allen, Pereira, Raes, & Smith, 1998). El cálculo exacto se realiza usando la ecuación estándar de la FAO 56 Penman-Monteith (ETo-FAO56PM) (Shiri, 2017); sin embargo, la ecuación requiere de cuatro variables meteorológicas, como son la radiación solar, humedad relativa, velocidad del viento y temperatura, que muchas veces no son medidas en las estaciones meteorológicas, por lo que en muchas ocasiones se opta por la utilización de ecuaciones que emplean menos variables meteorológicas, las cuales se clasifican dependiendo de la disponibilidad de variables (Fan et al., 2018a; Feng, Cui, Zhao, Hu, & Gong, 2016; Shiri, 2017). Una de las principales razones de uso de las ecuaciones convencionales es que requieren un menor número de variables meteorológicas para su implementación, siendo aquellas basadas en el parámetro temperatura del aire las menos precisas. En un estudio llevado por Almorox, Senatore, Quej y Mendicino (2018) , evaluaron el desempeño del método PMT (Penman-Monteith) y compararon los resultados con los obtenidos con la ecuación de Hargreaves-Samani (HS) utilizando los datos mensuales medidos a largo plazo del conjunto de datos climáticos globales de la FAO New LocClim. Para una base de datos completa, la expresión aproximada de PMT usando únicamente la temperatura del aire produce mejores resultados que el método de la ecuación no calibrada de HS, y el desempeño del método de PMT se desempeña aún mejor adoptando correcciones dependiendo del tipo de clima para la estimación de la radiación solar, en especial en el tipo de clima tropical.
Antonopoulos y Antonopoulos (2017) emplearon la técnica de inteligencia artificial redes neurales artificiales (ANN), y los métodos de Priestley-Taylor, Makkink (MAK), Hargreaves y transferencia de masa para estimar la evapotranspiración de referencia con datos meteorológicos diarios en un periodo de cinco años (2009-2013) en el norte de Grecia. Como resultado, se observó que al utilizar variables de entrada limitada para el ajuste de los parámetros del ANNs, los datos resultan en valores de ETo inexactos. Por otro lado, los métodos basados en radiación solar de Priestley-Taylor y Makkink correlacionaron correctamente con el método de Penman-Monteith seguido por el método de Hargreaves. El método de transferencia de masa fue correlacionado de manera satisfactoria, pero subestimaba los valores de ETo.
Recientes investigaciones en la determinación de la ETo hacen mención de las técnicas denominadas de inteligencia artificial o soft-computing, basadas en el aprendizaje automático. Estas técnicas han sido ampliamente usadas en la modelación hidrológica, y en la estimación de la ETo han mostrado superioridad sobre las ecuaciones convencionales debido a que incrementan la precisión de las estimaciones utilizando pocas variables (Mehdizadeh, 2018).
La técnica de inteligencia artificial llamada programación de expresión genética (Gene Expression Programming, GEP) propone un enfoque alternativo, que genera algoritmos y/o expresiones para resolver problemas de forma automática, y donde recientemente se ha aplicado con buenos resultados en estudios hidrológicos (Mattar, 2018). Mattar y Alazba (2019) estimaron la evapotranspiración de referencia usando la programación de expresión genética (GEP) y regresión lineal múltiple (Multiple Linear Regression, MLR), con datos recolectados de estaciones en Egipto; los resultados demuestran que la técnica de GEP, cuando se le agregaron los datos de la variable temperatura, obtuvo mejor desempeño que el modelo MLR y otras ecuaciones convencionales (HS y MAK). En otro estudio para evaluar el desempeño de algunas técnicas de inteligencia artificial, Wen et al. (2015) evaluaron el uso de la máquina de soporte vectorial (SVM) para modelar la evapotranspiración de referencia diaria (ETo) utilizando datos climáticos limitados. Para el SVM se usaron cuatro combinaciones de temperatura máxima del aire (Tmáx), temperatura mínima del aire (Tmín), velocidad del viento (U2) y radiación solar diaria (Rs ) en la región extremadamente árida de la cuenca de Ejina, China, como entradas con Tmáx y Tmín en el conjunto de datos base. Los resultados de los modelos SVM se evaluaron comparando la salida con la ETo calculada con la ecuación de Penman Monteith FAO 56 (PMF-56); la precisión del método SVM se comparó con el de la red neuronal artificial (ANN) y tres modelos convencionales, incluidos Priestley-Taylor, Hargreaves y Ritchie. Los resultados mostraron que el rendimiento del método SVM fue el mejor entre estos modelos.
Actualmente se ha propuesto un nuevo algoritmo denominado XGBoost (Extreme Gradient Boosting), resultado de una versión mejorada del aumento de gradiente (Gradient Boosting), con una mayor eficiencia de cálculo y capacidad para resolver problemas de ajustes excesivos (Fan et al., 2018a). Fan et al. (2018b) evaluaron el potencial para estimar la ETo de los modelos de algoritmos de ensamblaje basados en árboles; bosques aleatorio (RF), modelo árbol M5, aumento de gradiente (GBDT), aumento de gradiente extremo (XGBoost), máquinas de soporte vectorial (SVM) y máquinas de aprendizaje extremo (ELM); los resultados mostraron que los modelos XGBoost y GBDT alcanzaron excelente precisión y estabilidad en comparación con los modelos SVM y ELM, pero con menos costos computacionales. Bajo tales criterios, los autores recomiendan el uso de estos modelos para estimar la ETo.
Considerando que la variable meteorológica temperatura del aire es la de mayor disponibilidad, el presente estudio tiene como objetivo (1) evaluar la capacidad de tres métodos de inteligencia artificial llamados XGBoost, GEP y SVM para estimar valores de ETo utilizando datos de temperatura del aire, y (2) comparar los resultados con dos ecuaciones convencionales basadas en temperatura llamadas Hargreaves-Samani y Camargo bajo un clima cálido-subhúmedo.
Materiales y métodos
Sitio de estudio
La presente investigación se realizó utilizando datos de estaciones meteorológicas automatizadas (EMAs) ubicadas en el estado de Campeche, México (Figura 1). El clima predominante es cálido subhúmedo, que se presenta en el 92 % de su territorio y el 7.75 % presenta clima cálido húmedo localizado en la parte este del estado y en la parte norte un porcentaje del 0.05 % con clima semi-seco. La temperatura más alta es mayor a 30 °C y la mínima de 18 °C. La temperatura media anual es de 26 a 27 °C. Las lluvias son de abundantes a muy abundantes durante el verano. La precipitación total anual varía entre 1 200 y 2 000 mm, y en la región norte, de clima semi-seco, es alrededor de 800 mm anuales (INEGI, 2017).
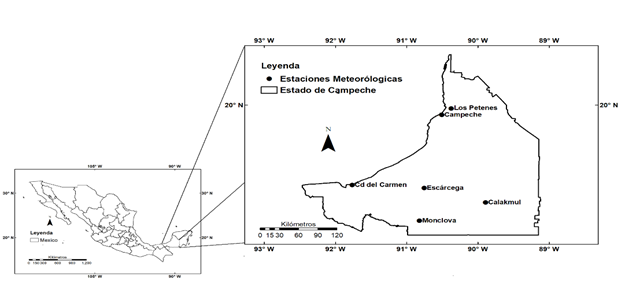
Figura 1 Ubicación de las estaciones meteorológicas en el estado de Campeche, México, usadas en este estudio.
Las bases de datos cada 10 minutos se obtuvieron de las estaciones meteorológicas automatizadas de la Comisión Nacional del Agua (Conagua) de México. La Tabla 1 muestra la información geográfica de las estaciones meteorológicas utilizadas en este estudio, así como los periodos de tiempo de registro de cada estación meteorológica.
Tabla 1 Información geográfica y condiciones anuales meteorológicas durante el periodo en estudio.
| Estación | LAT (°N) | LON (°W) | ALT (msnm) | Años de registro | Promedio anual | |||
|---|---|---|---|---|---|---|---|---|
| Tmed (°C) | RSG MJ M-2d-1 | HR (%) | U2 (ms-1) | |||||
| Calakmul | 18.365 | 89.893 | 28 | 2000-2018 | 26.20 | 15.66 | 81.00 | 1.16 |
| Campeche | 19.836 | 90.507 | 3 | 2000-2018 | 26.80 | 20.19 | 79.90 | 1.82 |
| Cd del Carmen | 18.658 | 91.765 | 4 | 2011-2018 | 27.10 | 19.40 | 75.16 | 2.36 |
| Escárcega | 18.608 | 90.754 | 60 | 2004-2018 | 27.17 | 18.74 | 79.2 | 1.51 |
| Los Petenes | 19.943 | 90.374 | 2 | 2012-2018 | 26.52 | 14.43 | 80.23 | 1.31 |
| Monclova | 18.057 | 90.821 | 100 | 2008-2018 | 26.70 | 18.77 | 72.59 | 1.63 |
LAT: latitud; LON: longitud; ALT: altitud; Tmed: temperatura media; RSG: radiación solar global; HR: humedad relativa; U2: velocidad del viento.
Manejo de datos faltantes y calidad
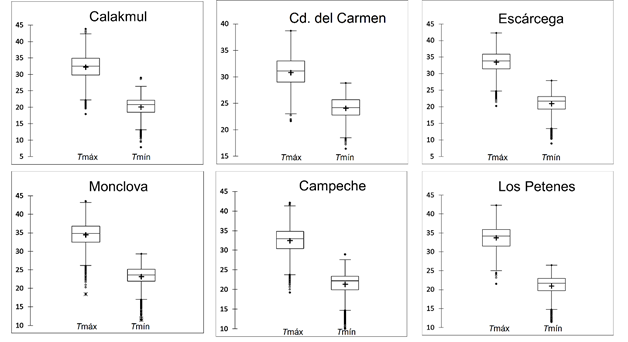
Las bases de datos fueron procesadas cada 10 minutos, detectando mediante algoritmos implementados en el software Microsoft Excel® series de tiempo faltantes, las cuales posteriormente fueron rellenadas utilizando la técnica de interpolación llamada interpolación polinómica de Hermite (PCHIP). Para una descripción más detallada, consultar Salazar, Ureña y Gallego (2010), y Torrente-Cantó (2018) . Una vez que las series de datos fueron completadas, se construyeron bases de datos diarias. Asimismo, los datos se analizaron para identificar valores atípicos, donde aquellos valores por encima de tres desviaciones estándar de la media se marcaron como atípicos. Se analizaron los datos señalados como atípicos: si un valor atípico extremo inferior se encontraba asociado con un evento de lluvia no se eliminaba; en caso contrario, se eliminaron; esto, con el objetivo de tener modelos funcionales incluso en época lluviosa. En el caso de los valores atípicos extremos superiores fueron eliminados. En ambos casos se utilizó la técnica de interpolación PCHIP para su relleno. La Figura 2 muestra el gráfico de caja y bigotes de las estaciones meteorológicas implicadas en los modelos de este estudio. El bigote representa el mínimo y el máximo de las variables. Respecto a la temperatura máxima, la media varía entre 33 y 34 °C, con valores máximos entre 42 y 43 °C (excepto la estación de Cd. del Carmen); el valor mínimo de la temperatura máxima varía entre 22 y 25 °C. La temperatura mínima tiene una media entre 20 y 24 °C, con valores máximos entre 25 y 28 °C, y mínimos entre 12 y 17 °C. La Figura 2 también muestra los valores atípicos, generalmente asociados con la temperatura mínima.
Ecuación de la FAO 56 PM (ETo-FAO56PM)
La ecuación FAO56PM es el modelo estándar usado para estimar con precisión la ETo, propuesto por la Organización de las Naciones Unidas para la Agricultura y la Alimentación (FAO, por sus siglas en inglés). Incorpora aspectos termodinámicos y aerodinámicos, y considera muchos parámetros meteorológicos relacionados con el proceso de evapotranspiración, como la radiación neta, la temperatura del aire, el déficit de presión de vapor, la velocidad del viento. Ha demostrado ser un método relativamente preciso bajo diferentes condiciones o regiones (Allen et al., 1998). Estos aspectos se han incorporado en la siguiente ecuación:
donde Rn = radiación neta en la superficie (MJ m-2 día-1); G = flujo del calor de suelo (MJ m-2 día-1); Tmed = temperatura media del aire a 2 m de altura (°C); u2 = velocidad del viento a 2 m de altura (m s-1); es = presión de vapor de saturación (kPa); ea = presión real de vapor (kPa); ∆ = pendiente de la curva de presión de vapor (kPa °C-1); γ = constante psicrométrica (kPa °C-1).
En este estudio, el método ETo-FAO56PM se usó para evaluar los métodos convencionales y de inteligencia artificial.
Ecuación de Hargreaves y Samani
El modelo de HS se considera como un modelo alternativo para estimar la ETo cuando solo los registros de temperatura están disponibles en el lugar de estudio; es uno de los métodos que ha sido utilizado consecutivamente por su simple implementación y la precisión en sus resultados (Gong et al., 2016; Shiri, 2017). La Ecuación (2) del modelo de Hargreaves y Samani está estructurada de la siguiente manera:
donde ETo = evapotranspiración de referencia (mm día-1); KHG = es un coeficiente empírico, que inicialmente fue establecido en 0.0023, pero se ha recalibrado acorde con el lugar empleado; Tmed = temperatura media; Tmáx = temperatura máxima; Tmín = temperatura mínima; Ra = radiación solar extraterrestre. Ra se calculó en función del día del año, latitud del sitio y ángulo solar de acuerdo con la ecuación propuesta por Allen et al. (1998).
Ecuación de Camargo
El modelo de Camargo es una modificación a la ecuación de Thornthwaite (TH). Es un modelo basado en la variable climática de temperatura. Camargo sustituyó el valor de la temperatura media de la ecuación de Thornthwaite por la temperatura media efectiva (Tef) (Camargo, Marin, Sentelhas, & Picini, 1999). La Ecuación (3) del modelo de Camargo está estructurada de la siguiente manera:
donde ETo = evapotranspiración de referencia (mm día-1); KCA1 y KCA2 = coeficientes empíricos, donde sus valores originales son 16 y 0.36, respectivamente, y deben ser calibrados acorde con el lugar de empleo; I = índice de calor anual; a = exponente empírico en función de I; N = tiempo máximo de insolación en horas; (KCA2 * (3Tmáx - Tmín) = temperatura efectiva, reemplazando a la temperatura media en la ecuación de Thornthwaite. El valor de I se define como la suma de 12 valores de índices de calor mensual, como se muestra en la siguiente ecuación:
donde Tmedj = temperatura media mensual (°C).
y:
El valor de a varía de 0 a 4.25; mientras que el índice de calor anual I varía de 0 a 160.
Ajuste de parámetros en los métodos convencionales
Los métodos convencionales basados en temperatura deben ajustarse a las condiciones locales antes de ser utilizados (Almorox et al., 2018) para obtener buenas estimaciones de ETo. Por tal motivo, los coeficientes originales de las ecuaciones se calibraron utilizando técnicas de regresión no lineal mediante al algoritmo Levenberg-Marquardt.
Máquinas de soporte vectorial (SVM)
La técnica máquinas de soporte vectorial (SVM) fue desarrollada por Vapnik (2000) y es uno de los enfoques basado en el aprendizaje automático. Es una técnica de aprendizaje supervisado, robusta, para resolver problemas de clasificación y regresión aplicados a grandes conjuntos de datos complejos con ruido; selecciona un hiperplano único de separación de cada clase y la idea básica es mapear los datos x en un espacio de características de alta dimensión a través de un mapeo no lineal y hacer una regresión lineal en este espacio. Durante el entrenamiento solo se consideran los ejemplos que se encuentran en el margen de separación, llamados vectores de soporte. Se aplican con éxito en problemas de regresión, generalmente denominados SVR (regresión de vectores de soporte), utilizando SVM para un conjunto de datos {(Xi , Yi )} N/i = 1, donde Xi es el vector de entrada; Yi , el valor de salida, y N es el número total de conjuntos de datos mediante el mapeo de X en un espacio característico a través de una función no lineal φ(x) para después encontrar una función de regresión (Fan et al., 2018a; Mehdizadeh, Behmanesh, & Khalili, 2017; Quej, Almorox, Arnaldo, & Saito, 2017; Topi & Vanita, 2017; Wen et al., 2015):
donde φ (x) es la función de mapeo no lineal; ω es un vector de peso, y b es un valor de sesgo; son los parámetros de la función de regresión, los cuales pueden ser calculados minimizando la siguiente función de riesgo regularizado:
donde el término
Es decir, si la diferencia entre los valores predichos y los medidos es menor que ε, entonces la pérdida es igual a 0. Si los valores predichos están dentro del tubo, el error de pérdida es igual a 0. Para el resto de los puntos predichos encontrados fuera del tubo, la pérdida es igual a la diferencia entre el valor predicho y el radio ε del tubo. Para la detección de valores atípicos, las variables de holgura ξ y ξ ⃰ miden de arriba y abajo en el tubo de ε.
Debido a que ambas variables adquieren valores positivos, se tiene que minimizar el riesgo con la siguiente ecuación:
Sujeto a
donde la
El modelo SVM estima la regresión en función de una serie de funciones Kernel, que convierten los datos de entrada originales de dimensiones inferiores a un espacio de características de mayor dimensión de una manera implícita. Entre los Kernel más utilizados se halla el SVM polinomial (SVM-Poly) y la función de base radial SVM (SVM-RBF), cuyos parámetros del Kernel deberán ajustarse previamente mediante un algoritmo. Por ejemplo, los parámetros óptimos del Kernel y del modelo SVM generalmente se obtienen utilizando el método de búsqueda de cuadrícula (Mehdizadeh et al., 2017):
Implementación del modelo SVM en la estimación de la ETo
En el presente estudio, el modelo SVM para estimar la ETo se construyó usando el software R (RDevelopment, 2009). Como variables de entrada se usaron los datos meteorológicos de Tmáx, Tmín y Ra , y como variable objetivo se utilizaron los valores de ETo-FAO56PM (Ecuación (1)). Para el entrenamiento y validación del modelo SVM, se utilizó el software R en conjunto con el paquete LIBSVM 3.1 (Chang, Lin, & Tieleman, 2013). Para la redimensión de los datos se utilizó la función Kernel de Base Radial (RBF) (Ecuación (10)). Con la finalidad de evitar el sobre ajuste y aumentar el desempeño del modelo SVM para estimar la ETo, los parámetros ε, C y ɣ de la SVM, y de la función Kernel de base radial se optimaron mediante el algoritmo genético (GA), utilizando validación cruzada (VC = 5 fólders) (Quej et al., 2017; Shrestha & Shukla, 2015), y variando los parámetros ε = 0.002 a ε = 2, C = 0.0001 a C = 10, y ɣ = 0.0001 a ɣ = 2. El GA se implementó utilizando el software R en conjunto con la librería e1079 y Caret. Se utilizó el 60 % de los datos durante la etapa de entrenamiento y el 40 % en la etapa de validación.
Los parámetros optimizados por GA utilizados en el entrenamiento de la SVM se muestran en la Tabla 2.
Programación de expresión genética (GEP)
La programación de la expresión génica (GEP) fue presentada por Ferreira (2001) . Es una rama de los algoritmos evolutivos que tiene la capacidad de modelar los procesos dinámicos y no lineales. Es un algoritmo que pertenece a la familia de los algoritmos genéticos (GA) y programación genética (GP) tradicionales. Puede emular la evolución biológica basada en la programación por computadora para resolver un problema definido por el usuario.
Los GEP se consideran un híbrido entre los GA y GP. Utilizan programación genética para la solución del problema en forma de árbol, donde existen dos tipos de nodos:
Terminales u hojas del árbol. No tienen descendientes, se asocian con las variables o constantes.
Funciones. Tienen descendientes, se asocian con operadores del algoritmo que se desea desarrollar.
En GEP, los individuos se codifican primero como cadenas lineales de longitud fija como en GA. Luego, se expresan como entidades no lineales de diferentes tamaños y formas, como el GP (Ferreira, 2001). Además, un conjunto de terminales (coeficientes y predictores), funciones y operadores matemáticos se utilizan en el GEP para estimar la variable dependiente (Mehdizadeh et al., 2017), creando funciones de manera aleatoria y seleccionando aquellas que presenten un mejor ajuste a los resultados experimentales, permitiendo la generación de algoritmos y expresiones matemáticas de manera automática para la solución de problemas (Mattar, 2018; Shiri, 2017).
Implementación del modelo GEP en la estimación de la ETo
En este estudio, la implementación de la técnica GEP se llevó a cabo utilizando el software GenexprooTols v. 5.0. Las variables de entrada son los valores de los datos meteorológicos de Tmáx, Tmín, Ra y valores de ETo-FAO56PM como variable objetivo. Los operadores aritméticos y funciones matemáticas implementadas dentro del programa fueron
Tabla 3 Parámetros del modelo GEP.
| Parámetro | Valor |
|---|---|
| Número de cromosomas | 30 |
| Tamaño de cabeza | 8 |
| Número de genes | 3 |
| Función de enlace | Adición |
| Tipo de error en la función fitness | RMSE |
| Tasa de mutación | 0.044 |
| Tasa de inversión | 0.1 |
| Tasa de recombinación primer punto | 0.3 |
| Tasa de recombinación segundo punto | 0.3 |
| Tasa de recombinación de genes | 0.1 |
| Tasa de transposición de genes | 0.1 |
| Tasa de transposición de la secuencia de inserción | 0.1 |
| Raíz inserción secuencia transposición | 0.1 |
| Herramienta de penalización | Pp* |
*Presión de parsimonia (Parsimony pressure).
XGBoost
Es uno de los algoritmos más importantes y potentes del “Machine Learning” (aprendizaje automático) creado por Chen y Guestrin (2016), utilizado para el análisis de problemas de regresión y clasificación estadística, el cual produce un modelo de predicción complejo a partir del ensamblaje de árboles de decisión (modelos simples) en un contexto de aprendizaje supervisado.
El modelo se basa en la teoría del aumento de gradiente, por lo que las predicciones de varios aprendices "débiles" (modelos cuyas predicciones son ligeramente mejores que las suposiciones aleatorias) se combinan para desarrollar un aprendiz "fuerte". Estos aprendices "débiles" se combinan siguiendo una estrategia de aprendizaje gradual, evitando un sobreajuste y optimizando los recursos de cómputo. Esto se obtiene simplificando todas las funciones que permitan combinar términos predictivos y de regularización, pero que, a su vez, mantenga una velocidad computacional óptima durante todo el procesamiento. Al comienzo del proceso de calibración, un aprendiz "débil" se ajusta a todo el espacio de datos, y luego un segundo aprendiz se ajusta a los residuos de la primera. Este proceso de ajuste de un modelo a los residuos del anterior continúa hasta que se alcanza algún criterio de detención (minimización de la raíz cuadrada media del error). El resultado es un tipo de media ponderada de las predicciones individuales de cada alumno débil. Tradicionalmente, los árboles de regresión se seleccionan como aprendices "débiles" (Fan et al., 2018a). Bajo este contexto el modelo XGBoost se basa en la siguiente función objetivo: pérdida + regularizador:
donde
donde G y H se obtienen de la expansión de las series de Taylor de la función de pérdida; λ es el parámetro de regularización, y T es el número de hojas en un árbol. Esta expresión analítica de la función objetivo permite un rápido escaneo de izquierda a derecha de las posibles divisiones del árbol, pero siempre teniendo en cuenta la complejidad.
XGBoost tiene una amplia gama de parámetros de ajuste. Además, la flexibilidad del algoritmo se mejora al dar la oportunidad al usuario de incluir algunos parámetros autodefinidos, como la función de pérdida, o la métrica utilizada para la validación y prueba (Urraca, Antonanzas, Antonanzas-Torres, & Martinez-De-Pison, 2017).
Implementación del modelo XGBoost en la estimación de la ETo
Para la implementación del modelo XGBoost, como primer paso se optimizaron los hiperparámetros nrounds, max_depth, eta, gamma, colsample bytree, min_child_weight y subsample (Tabla 4) utilizando la librería Caret del Software R (Fan et al., 2018a); segundo, se ajustó el modelo XGBoost utilizando la librería “Xgboost” del Software R, utilizando validación cruzada (VC = 5 fólders) para evitar el sobreajuste. El 70 % de los datos se usó para la etapa de entrenamiento y el 30 % para la validación. Las variables de entrada al modelo son los valores de los datos meteorológicos de Tmáx, Tmín y Ra , los valores de ETo-FAO56PM como variable objetivo.
Tabla 4 Hiperparámetros XGBoost optimizados.
| Parámetros ajustados | Calakmul | Campeche | Cd. del Carmen | Escárcega | Monclova | Los Petenes |
|---|---|---|---|---|---|---|
| Nrounds | 50 | 50 | 50 | 50 | 150 | 50 |
| Max_depth | 2 | 3 | 3 | 3 | 2 | 3 |
| Eta | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 | 0.3 |
| Gamma | 0 | 0 | 0 | 0 | 0 | 0 |
| Colsample bytree | 0.8 | 0.8 | 0.8 | 0.8 | 0.8 | 0.8 |
| Min_child_weight | 1 | 1 | 1 | 1 | 1 | 1 |
| subsample | 1 | 1 | 1 | 1 | 0.75 | 1 |
Análisis estadístico
En el presente estudio se utilizaron cuatro indicadores estadísticos para evaluar el desempeño de los modelos convencionales y de inteligencia artificial, estos indicadores son coeficiente de determinación (R2; Ecuación (13)); raíz cuadrada media del error (RMSE; Ecuación (14)); error absoluto medio (MAE; Ecuación (15)); error medio de sesgo (MBE; Ecuación (16)):
donde n es el número de comparaciones; Pi y Oi , valores estimados y observados de ETo-FAO56PM, respectivamente; Pprom , el promedio de los valores estimados de ETo; Oprom , el promedio de los valores observados de ETo; las unidades de ETo se encuentran en mm d-1.
R2 se usa por lo común para estimar el desempeño de modelos hidrológicos. Representa la fracción de los valores estimados que son los más cercanos a la línea de datos de medición. Valores del coeficiente de determinación cercanos a 1 indican modelos más eficientes y la línea de regresión se ajusta mejor a los datos. EL RMSE es una medida utilizada con frecuencia para comparar errores de predicción en diferentes modelos; cuanto menor sea su valor, mejor será la capacidad predictiva de un modelo en términos de su desviación absoluta. El MAE es la suma de los valores absolutos de los errores divididos por el número de observaciones; se usa con frecuencia para medir qué tan cerca están los valores estimados de los valores observados. El MBE proporciona información sobre la tendencia del modelo a sobreestimar o subestimar la variable; cuantifica el error sistemático del modelo.
La evaluación de la incertidumbre de los indicadores estadísticos R2, RMSE, MAE y MBE se realizó mediante la construcción de intervalos de confianza bootstrap (ICB) al 95 % de nivel de confianza. Para tal propósito se utilizó el método no paramétrico bootstrap percentil como técnica de remuestreo, utilizando B = 10 000 réplicas con remplazamiento, con el propósito de inducir mayor precisión en las estimaciones (Efron, 1992).
Los ICB ofrecen una manera de estimar con alta probabilidad un rango de valores en el que se encuentra el valor del parámetro (indicador estadístico).
También se computó el error estándar de la distribución (ee) y el valor de cada indicador estadístico bootstrap, calculando la desviación estándar y la media de las B réplicas.
Resultados
En el presente estudio se evaluaron dos ecuaciones convencionales y tres técnicas de inteligencia artificial para estimar la ETo utilizando la variable de temperatura del aire.
En la Tabla 5 se observan los índices estadísticos obtenidos mediante bootstrap (media de las B réplicas bootstrap). Entre las ecuaciones convencionales evaluadas, el modelo de Camargo mostró mejores resultados globales (R2 = 0.734; MAE = 0.564; RMSE = 0.721; MBE = -0.008) respecto a la ecuación de HS (R2 = 0.727; MAE = 0.588; RMSE = 0.750; MBE = -0.032), siendo la estación de Monclova donde presentó mejor desempeño (R2 = 0.815; MAE = 0.488; RMSE = 0.608; MBE = -0.011). De manera global, la ecuación de Camargo tuvo una tendencia a subestimar ligeramente valores de ETo según el indicador MBE = -0.008. Respecto a la ecuación de Camargo, el coeficiente KCA1 varió de 34.922 a 44.476, y el coeficiente KCA2 varió de 0.195 y 0.290. En la ecuación de HS, el coeficiente KHS calibrado varió de 0.0015 a 0.0027.
Tabla 5 Índices estadísticos bootstrap (R2, MAE, RMSE y MBE) de los modelos convencionales y de inteligencia artificial usados para la estimación de la ETo de cada estación meteorológica.
| Estación/ modelo | R2 | MAE (mm d-1) | RMSE (mm d-1) | MBE (mm d-1) | KHS | KCA1 | KCA2 |
|---|---|---|---|---|---|---|---|
| Calakmul | |||||||
| HS | 0.700 | 0.569 | 0.729 | -0.055 | 0.0015 | ||
| Camargo | 0.712 | 0.534 | 0.688 | 0.028 | 36.071 | 0.200 | |
| SVM | 0.740 | 0.486 | 0.646 | 0.046 | |||
| GEP | 0.696 | 0.544 | 0.719 | -0.003 | |||
| XGBoost | 0.771 | 0.467 | 0.607 | -0.0004 | |||
| Campeche | |||||||
| HS | 0.703 | 0.550 | 0.709 | -0.010 | 0.0020 | ||
| Camargo | 0.635 | 0.623 | 0.797 | 0.037 | 40.256 | 0.218 | |
| SVM | 0.731 | 0.519 | 0.680 | -0.003 | |||
| GEP | 0.695 | 0.561 | 0.726 | 0.036 | |||
| XGBoost | 0.695 | 0.543 | 0.721 | -0.012 | |||
| Cd. del Carmen | |||||||
| HS | 0.694 | 0.633 | 0.820 | -0.002 | 0.0027 | ||
| Camargo | 0.702 | 0.627 | 0.811 | 0.005 | 44.476 | 0.240 | |
| SVM | 0.742 | 0.585 | 0.778 | -0.056 | |||
| GEP | 0.721 | 0.638 | 0.809 | -0.034 | |||
| XGBoost | 0.703 | 0.611 | 0.802 | 0.032 | |||
| Escárcega | |||||||
| HS | 0.711 | 0.654 | 0.825 | -0.050 | 0.0018 | ||
| Camargo | 0.783 | 0.554 | 0.705 | -0.036 | 38.581 | 0.211 | |
| SVM | 0.838 | 0.471 | 0.608 | 0.034 | |||
| GEP | 0.773 | 0.561 | 0.713 | 0.030 | |||
| XGBoost | 0.815 | 0.500 | 0.642 | -0.043 | |||
| Monclova | |||||||
| HS | 0.796 | 0.523 | 0.651 | 0.014 | 0.0020 | ||
| Camargo | 0.815 | 0.488 | 0.608 | -0.011 | 39.391 | 0.214 | |
| SVM | 0.852 | 0.426 | 0.531 | -0.046 | |||
| GEP | 0.816 | 0.500 | 0.618 | 0.009 | |||
| XGBoost | 0.842 | 0.442 | 0.569 | 0.025 | |||
| Los Petenes | |||||||
| HS | 0.755 | 0.599 | 0.767 | -0.089 | 0.0014 | ||
| Camargo | 0.754 | 0.555 | 0.716 | -0.071 | 34.922 | 0.195 | |
| SVM | 0.801 | 0.392 | 0.574 | -0.042 | |||
| GEP | 0.812 | 0.406 | 0.574 | -0.022 | |||
| XGBoost | 0.804 | 0.414 | 0.584 | 0.041 | |||
| Todas las estaciones | |||||||
| HS | 0.727 | 0.588 | 0.750 | -0.032 | |||
| Camargo | 0.734 | 0.564 | 0.721 | -0.008 | |||
| SVM | 0.784 | 0.480 | 0.636 | -0.011 | |||
| GEP | 0.752 | 0.535 | 0.693 | 0.003 | |||
| XGBoost | 0.772 | 0.496 | 0.654 | 0.007 | |||
* En los modelos de inteligencia artificial, los índices estadísticos bootstrap corresponden a los obtenidos en el proceso de validación.
** KHS, KCA1, KCA2 son los coeficientes empíricos ajustados de las ecuaciones de Hargreaves-Samani y Camargo, respectivamente.
Respecto a los modelos de inteligencia artificial para estimar la ETo, la Tabla 5 muestra que el modelo SVM obtuvo el mejor desempeño con relación a los otros modelos evaluados, obteniendo valores de R2 = 0.784, MAE = 0.480, RMSE = 0.636 y MBE = -0.011, siendo la estación de Monclova donde se presentó mejor desempeño (R2 = 0.852; MAE = 0.426; RMSE = 0.531; MBE = -0.046). Le sigue el modelo XGBoost con resultados de R2 = 0.772, MAE = 0.496, RMSE = 0.654, y MBE = 0.007, donde el mejor desempeño fue en la estación de Monclova (R2 = 0.842; MAE = 0.442; RMSE = 0.569; MBE = 0.025). El modelo GEP fue el de menor rendimiento comparado con los otros modelos de inteligencia artificial, obteniendo resultados de R2 = 0.752, MAE = 0.535, RMSE = 0.693 y MBE = 0.003; sin embargo, su rendimiento fue superior a lo obtenido por las ecuaciones convencionales.
El modelo SVM de manera general presentó una tendencia a subestimar valores de ETo de acuerdo con un valor global de MBE = -0.011, mientras que los modelos GEP y XGBoost presentaron una leve tendencia a sobreestimar valores de ETo.
El modelo SVM tiene buen rendimiento cuando se realiza el ajuste de los parámetros de Costo, Gamma y Épsilon utilizando el algoritmo genético. Asimismo, al usar validación cruzada se evita el sobreajuste del modelo.
Una de las principales ventajas del método SVM sobre los demás métodos radica en que el problema no lineal siempre convergerá en un mínimo global.
Por otra parte, una característica útil de la técnica GEP es que proporciona una expresión algebraica para estimar la ETo, que puede programarse en una hoja de cálculo, software R, Matlab o Python. En la Tabla 6 se presentan las expresiones algebraicas obtenidas por el modelo GEP para las seis estaciones meteorológicas.
Tabla 6 Expresiones algebraicas obtenidas por el modelo GEP para cada estación meteorológica.
| Estación | Expresión matemática |
|---|---|
| Calakmul |
|
| Campeche |
|
| Cd. del Carmen |
|
| Escárcega |
|
| Monclova |
|
| Los Petenes |
|
Como un ejemplo práctico del modelo GEP, se proporciona la fórmula en formato de Microsoft Excel®, cuyas entradas corresponden a las variables de Tmín, Tmáx, Ra :
B2 / ((M2*Tmáx) ^ (1/3)) + (ATAN(Tmáx)*M3) / (ATAN(Ra -M4)) + Ra / (ATAN((Tmáx-Tmín) - LOG(Ra )) + Tmín)
donde M2 = 0.0815; M3 = 9.223; M4 = 5.126 son constantes en el modelo.
Así se verifica que al ingresar los valores de Tmáx = 31.7, Tmín = 18.40 y Ra = 38.87, obtendremos el valor de la ETo = 3.407 mm d-1.
La Tabla 7 muestra los intervalos de confianza bootstrap (ICB) al 95 % de nivel de confianza y el error estándar de la distribución (EE) de los índices estadísticos R2, MAE, RMSE y MBE de los modelos convencionales y de inteligencia artificial. De manera general, los intervalos de confianza muestran una amplitud reducida, relacionada con error estándar, lo cual indica que si utilizamos muestras aleatorias y se determinan sus indicadores estadísticos de evaluación, éstos variarán en un rango siempre aceptable.
Tabla 7 ICB (límite inferior [LI] = 2.5 % y límite superior [LS] = 97.5 %) al 95 % de nivel de confianza, y el error estándar de la distribución (ee) de los índices estadísticos R2, MAE, RMSE y MBE de los modelos convencionales y de inteligencia artificial.
| Estación / modelo | R2 | MAE (mm d-1) | RMSE (mm d-1) | MBE (mm d-1) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| LI | LS | ee | LI | LS | ee | LI | LS | ee | LI | LS | ee | |
| Calakmul | ||||||||||||
| HS | 0.683 | 0.717 | 0.008 | 0.554 | 0.584 | 0.007 | 0.709 | 0.748 | 0.009 | -0.079 | -0.031 | 0.012 |
| Camargo | 0.696 | 0.727 | 0.007 | 0.519 | 0.548 | 0.007 | 0.669 | 0.706 | 0.009 | 0.006 | 0.049 | 0.011 |
| SVM | 0.715 | 0.765 | 0.013 | 0.462 | 0.511 | 0.012 | 0.615 | 0.677 | 0.016 | 0.009 | 0.083 | 0.019 |
| GEP | 0.667 | 0.724 | 0.014 | 0.516 | 0.572 | 0.014 | 0.682 | 0.757 | 0.019 | -0.046 | 0.039 | 0.022 |
| XGBoost | 0.757 | 0.786 | 0.007 | 0.453 | 0.482 | 0.007 | 0.589 | 0.626 | 0.009 | -0.023 | 0.023 | 0.012 |
| Campeche | ||||||||||||
| HS | 0.688 | 0.717 | 0.007 | 0.537 | 0.562 | 0.006 | 0.692 | 0.726 | 0.008 | -0.029 | 0.009 | 0.009 |
| Camargo | 0.617 | 0.652 | 0.008 | 0.609 | 0.636 | 0.007 | 0.778 | 0.815 | 0.009 | 0.014 | 0.059 | 0.011 |
| SVM | 0.707 | 0.754 | 0.011 | 0.497 | 0.54 | 0.011 | 0.652 | 0.708 | 0.014 | -0.036 | 0.029 | 0.017 |
| GEP | 0.669 | 0.72 | 0.013 | 0.537 | 0.584 | 0.012 | 0.694 | 0.758 | 0.016 | -0.001 | 0.073 | 0.018 |
| XGBoost | 0.662 | 0.727 | 0.016 | 0.517 | 0.569 | 0.013 | 0.682 | 0.759 | 0.019 | -0.052 | 0.028 | 0.021 |
| Cd. del Carmen | ||||||||||||
| HS | 0.662 | 0.726 | 0.016 | 0.603 | 0.662 | 0.015 | 0.400 | 1.241 | 0.214 | -0.049 | 0.045 | 0.024 |
| Camargo | 0.671 | 0.732 | 0.016 | 0.597 | 0.656 | 0.015 | 0.770 | 0.852 | 0.021 | -0.041 | 0.052 | 0.023 |
| SVM | 0.692 | 0.792 | 0.025 | 0.534 | 0.637 | 0.026 | 0.700 | 0.856 | 0.039 | -0.134 | 0.021 | 0.039 |
| GEP | 0.675 | 0.766 | 0.023 | 0.585 | 0.691 | 0.027 | 0.742 | 0.875 | 0.034 | -0.118 | 0.050 | 0.043 |
| XGBoost | 0.639 | 0.767 | 0.032 | 0.551 | 0.672 | 0.031 | 0.718 | 0.886 | 0.043 | -0.061 | 0.125 | 0.047 |
| Escárcega | ||||||||||||
| HS | 0.695 | 0.727 | 0.008 | 0.635 | 0.673 | 0.009 | 0.802 | 0.847 | 0.012 | -0.082 | -0.018 | 0.016 |
| Camargo | 0.769 | 0.796 | 0.007 | 0.537 | 0.570 | 0.008 | 0.685 | 0.724 | 0.010 | -0.063 | -0.009 | 0.014 |
| SVM | 0.817 | 0.859 | 0.011 | 0.445 | 0.496 | 0.013 | 0.574 | 0.642 | 0.017 | -0.006 | 0.074 | 0.021 |
| GEP | 0.745 | 0.800 | 0.014 | 0.530 | 0.592 | 0.015 | 0.677 | 0.749 | 0.018 | -0.018 | 0.079 | 0.025 |
| XGBoost | 0.791 | 0.838 | 0.012 | 0.470 | 0.531 | 0.015 | 0.606 | 0.678 | 0.018 | -0.093 | 0.006 | 0.025 |
| Monclova | ||||||||||||
| HS | 0.781 | 0.811 | 0.007 | 0.507 | 0.539 | 0.008 | 0.632 | 0.670 | 0.009 | -0.058 | -0.004 | 0.014 |
| Camargo | 0.802 | 0.829 | 0.006 | 0.473 | 0.503 | 0.007 | 0.590 | 0.626 | 0.009 | -0.036 | 0.014 | 0.013 |
| SVM | 0.832 | 0.871 | 0.009 | 0.403 | 0.449 | 0.012 | 0.503 | 0.558 | 0.014 | -0.084 | -0.007 | 0.019 |
| GEP | 0.792 | 0.839 | 0.012 | 0.471 | 0.528 | 0.014 | 0.585 | 0.651 | 0.016 | -0.037 | 0.056 | 0.024 |
| XGBoost | 0.818 | 0.866 | 0.012 | 0.412 | 0.472 | 0.015 | 0.532 | 0.605 | 0.018 | -0.022 | 0.072 | 0.024 |
| Los Petenes | ||||||||||||
| HS | 0.710 | 0.800 | 0.023 | 0.564 | 0.633 | 0.017 | 0.715 | 0.818 | 0.026 | -0.144 | -0.035 | 0.027 |
| Camargo | 0.710 | 0.798 | 0.022 | 0.523 | 0.588 | 0.016 | 0.665 | 0.767 | 0.026 | -0.122 | -0.019 | 0.026 |
| SVM | 0.724 | 0.878 | 0.039 | 0.338 | 0.446 | 0.027 | 0.463 | 0.686 | 0.057 | -0.114 | 0.030 | 0.037 |
| GEP | 0.738 | 0.886 | 0.037 | 0.352 | 0.460 | 0.027 | 0.463 | 0.684 | 0.056 | -0.097 | 0.054 | 0.038 |
| XGBoost | 0.742 | 0.866 | 0.032 | 0.353 | 0.473 | 0.030 | 0.494 | 0.674 | 0.046 | -0.042 | 0.123 | 0.042 |
Discusión
Se evaluaron dos modelos convencionales y tres técnicas de inteligencia artificial para estimar valores de ETo, siendo las variables de entrada para todos los modelos los datos de Tmáx, Tmín y Ra , excepto para el modelo de Camargo, que utiliza las horas máximas de insolación para un determinado sitio; de esta manera, los modelos tienen un ámbito de uso espacial y temporal delimitado por la amplitud térmica.
En un caso de clima árido y súper húmedo donde existe una amplitud térmica mayor, Camargo et al. (1999) presentaron una modificación al método de Thornthwaite usando el término “temperatura efectiva” Tef = 0.36 (3 Tmáx - Tmín), obteniendo excelentes resultados para regiones súper húmedas de Brasil. En el presente estudio, la ecuación empírica de Camargo obtuvo mejores estimaciones de ETo en comparación con la ecuación de HS, esta última comúnmente utilizada en la península de Yucatán, México, para estimar la ETo cuando solo existen datos de temperatura, lo anterior debido a que en las estaciones estudiadas existe mayor amplitud térmica. Asimismo, la calibración del coeficiente KHS de la ecuación de HS coincide con el obtenido por Bautista, Bautista y Delgado-Carranza (2009) para algunos sitios de la península de Yucatán, donde el valor más alto del coeficiente KHS = 0.0027 se observó en la estación de Cd. del Carmen, rodeada por aguas del golfo de México, y los valores más bajos se observaron en regiones rodeadas por abundante vegetación, como en los casos de las reservas de la biosfera de los Petenes (KHS = 0.0014) y Calakmul (KHS = 0.0015). Similar resultado obtuvieron Quej, Almorox, Arnaldo y Moratiel (2019) al evaluar la ETo diaria utilizando la ecuación de HS y Camargo, obteniendo valores de RMSE de 0.70 y 0.80 mm d-1, respectivamente. También en un estudio regional realizado por Kelso-Bucio et al. (2013) se calibró el coeficiente empírico de la ecuación de Hargreaves, y se consiguieron valores de RMSE en el rango de 0.68 a 0.87 mm d-1 para la región norte y centro del estado de Campeche, México, valores similares a este estudio, donde el valor de RMSE en la ecuación de HS tuvo una variación de 0.651 a 0.820 mm d-1.
Entre las técnicas de inteligencia artificial evaluadas para estimar la ETo, el modelo SVM utilizando el kernel de base radial presentó mejores resultados. GEP obtuvo el rendimiento más bajo de las tres técnicas en ambas etapas; esto coincide con los resultados obtenidos por Mehdizadeh et al. (2017) en regiones áridas y semiáridas de Irán, donde implementaron la técnica GEP, dos modelos SVM de base radial y polinomial; y MARS (Spline de regresión adaptativa multivariada) comparándolo con 16 ecuaciones convencionales basadas en transferencia de masa, radiación y parámetros meteorológicos. Los resultados revelaron que tanto MARS como SVM de base radial obtuvieron mejores estimaciones que el resto de las técnicas de inteligencia artificial y que las ecuaciones convencionales. Por otra parte, los resultados de las técnicas SMV y XGBoost coinciden con un estudio realizado en China por Fan et al. (2018b), donde evaluaron algunos métodos de inteligencia artificial, SVM y XGBoost entre ellos. Los resultados obtenidos en el clima subhúmedo utilizando solo datos de temperatura del aire y con la técnica XGBoost obtuvo un valor de RMSE = 0.723 mm d-1 y con la técnica SVM un valor de RMSE = 0.717 mm d-1.
Finalmente, la técnica XGBoost obtuvo un desempeño muy cercano a SVM. Sin embargo, se recomienda el uso de SVM de base radial al ser una técnica más robusta por sus fuertes bases matemáticas, con menos gasto computacional al no usar todos los datos para el cálculo sino solo algunos llamados vectores de soporte, además es una técnica con menos tendencia al sobreajuste una vez que sus parámetros han sido ajustados vía algoritmo GA.
Conclusiones
De las ecuaciones convencionales evaluadas basadas en temperatura, la ecuación propuesta por Camargo obtuvo mejor desempeño en la estimación de la ETo, por lo que se recomienda su uso para climas cálidos-subhúmedos, como el de la región del estudio. En ambos casos, el estudio provee de coeficientes calibrados tanto para estaciones que se localizan en sitios cercanos al mar y en sitios tierra adentro.
Respecto a los modelos de inteligencia artificial, el modelo SVM de base radial se recomienda para realizar estimaciones de ETo.
El ajuste previo de los parámetros de los modelos de inteligencia artificial mediante algoritmos es fundamental para evitar un sobreajuste que afectaría a futuras estimaciones utilizando otras series de datos.
Por otra parte, es importante destacar que los modelos GEP también son una buena opción al momento de realizar estimaciones de la ETo, ya que el modelo algebraico proporcionado por la técnica se podría programar en una hoja de cálculo u otro software, y de este modo realizar predicciones; como se comprobó en el presente estudio, el modelo GEP superó ligeramente a los modelos convencionales.
Los modelos de inteligencia artificial son una excelente opción para estimar valores de ETo al superar a las ecuaciones convencionales; sin embargo, para su implementación se requiere de un conocimiento especializado en el uso de software y ejecución de códigos de programación.
Los modelos evaluados en este estudio se pueden utilizar en regiones de clima cálidos subhúmedos y en los rangos de temperatura señalados en la Figura 2.
En futuros trabajos se podría evaluar el efecto de la humedad relativa, velocidad del viento en la estimación de la ETo para diferentes meses del año y bajo condiciones extremas de lluvia.
Para la implementación de los modelos de inteligencia artificial descritos en este estudio, se recomienda el uso del software libre R. En caso de requerir los códigos para su implementación, se pueden solicitar vía correo electrónico al autor para correspondencia de este artículo.

