text new page (beta)
text new page (beta) Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink
1. INTRODUCCIÓN
En la actualidad, todavía persisten definiciones que caracterizan la estadística como una rama de la matemática, aunque ya se ha establecido que la estadística es una disciplina independiente con sus propias ideas centrales (Moore, 1998), y cuya naturaleza tiene un carácter interdisciplinar que involucra convertir los datos en visiones del mundo real, siendo la matemática y la computación herramientas para tal propósito (Wild, Utts y Horton, 2018). La estadística es definida como la ciencia de aprender desde los datos, y también, de medir, controlar y comunicar la incertidumbre, según la Asociación Estadística Americana (ASA).
La falta de diferenciación disciplinar entre la estadística y la matemática, ha motivado varios estudios que dan cuenta del fenómeno didáctico relacionado con la difusa distinción entre sus enseñanzas en la escuela (Moore, 1997), lo cual motiva diseños innovadores de tareas y marcos conceptuales que permitan desarrollar y explicar el razonamiento estadístico de los estudiantes en formación (Pfannkuch, Ben-Zvi y Budgett, 2018).
Uno de los propósitos de la educación formal es contribuir al desarrollo del pensamiento estadístico de los estudiantes al resolver problemas reales y, frente a incertidumbre, tomar decisiones que se fundamenten en la comprensión, explicación y cuantificación de la variabilidad de los datos en un contexto real (Zieffler, Garfield y Fry, 2018). Generalmente, el sistema educativo promueve una alfabetización estadística en la enseñanza a través del currículo, el cual considera conocimientos estadísticos básicos requeridos para la formación desde el primer grado de escolaridad en algunos países (e.g., Ministerio de Educación de Chile, 2012). Estos conocimientos son útiles para tomar decisiones basadas en evidencias dadas por los datos en contexto y sus representaciones.
Una persona alfabetizada estadísticamente es capaz de leer, interpretar, organizar, evaluar críticamente y apreciar información estadística en áreas de conocimiento social, cultural, científico, artístico, entre otras (Ben-Zvi y Garfield, 2004; Gal, 2004). No obstante, la alfabetización estadística requiere de investigación que atienda a su progresión, en especial, a la capacidad de los estudiantes de primaria de crear representaciones que involucran la variabilidad omnipresente en los datos. Dicha capacidad no ha sido foco de la investigación en los primeros años de formación escolar, siendo subestimada, por lo que requiere un mayor reconocimiento (English, 2010, 2018).
Esta investigación cualitativa busca describir y caracterizar una lección de estadística relacionada con el análisis exploratorio de datos en el cuarto grado de enseñanza. Se realiza un análisis de la lección orientada por el ciclo investigativo y se examinan los desempeños que propició en tres estudiantes de primaria, mediante un marco conceptual referido al espacio de trabajo propio de la estadística temprana.
2. ANÁLISIS EXPLORATORIO DE DATOS
El trabajo con problemas reales, en vez de la generación de modelos abstractos, fue enfatizado por el estadístico J. W. Tukey hace más de 57 años a la comunidad científica. En sus palabras:
¿Qué hay del futuro? El futuro del análisis de datos puede implicar un gran progreso, la superación de dificultades reales y la prestación de un gran servicio a todos los campos de la ciencia y la tecnología. ¿Lo hará? Eso nos queda a nosotros [los estadísticos], a nuestra voluntad de tomar el camino difícil de los problemas reales con preferencia al camino fácil de suposiciones irreales, criterios arbitrarios y resultados abstractos sin apego real. (Tukey, 1962, p. 64).
Tukey (1977, 1980) fue pionero en liberar los vínculos tradicionales del análisis de datos de los modelos basados en probabilidad y, así el análisis exploratorio de datos comenzó a convertirse en una actividad intelectual independiente (Ben-Zvi, 2014), pues permite pensar, conjeturar y aprender desde los datos. Este análisis inicial tiene como principal característica ser exploratorio, lo que supone un tratamiento más flexible y amplio de distintas representaciones de datos para la búsqueda de regularidades, mediante la exploración sin restricciones, cuyo resultado es un análisis basado únicamente en lo que muestran los datos y solo aplicable a los individuos y circunstancias para los que fueron recolectados; por tanto, las conclusiones son informales, sin todavía hacer inferencias formales sobre alguna población.
En consecuencia, el análisis exploratorio de datos corresponde a un paradigma de la estadística, en el sentido que implica “una combinación de creencias, convicciones, técnicas, métodos y valores compartidos por un grupo científico”, según precisan Kuzniak, Tanguay y Elia (2016, p. 723).
3. EL CICLO INVESTIGATIVO PPDAC
Este ciclo conocido como PPDAC -i.e., Problema, Plan, Datos, Análisis y Conclusiones; ver Figura 1- es una de las cuatro dimensiones del pensamiento estadístico en una investigación empírica, propuesto por Wild y Pfannkuch (1999), basado en MacKay y Oldford (1994).

El ciclo investigativo (PPDAC) “describe los procedimientos a través de los cuales un estadístico trabaja y lo que el estadístico piensa para aprender más en la esfera del contexto.” (Pfannkuch y Wild, 2004, p. 41). Este ciclo se ocupa de abstraer un problema estadístico y permite explorar las posibles soluciones, provocando cambios en un sistema para mejorar algo, lo cual requiere una mejor comprensión de su dinámica, en tanto a cómo funciona, anticiparse a cómo reaccionará ante los cambios en los flujos de entrada, su configuración y el contexto (MacKay y Oldford, 2000). Por lo tanto, el ciclo investigativo contribuye al aprendizaje desde los datos (Wild et al., 2018).
La línea de investigación de Pfannkuch y Wild (2000, 2004) ha permitido fundamentar el ciclo investigativo como un método para elaborar un diseño de enseñanza estadística a nivel escolar, tal como reportan Makar y Fielding-Wells (2011). Ejemplo de ello, es el Reporte GAISE, pues ha sido un marco de referencia desde la perspectiva curricular desde Pre-K al grado 12 (Franklin et al., 2007).
A través del ciclo investigativo como propuesta de formación estadística en la escuela, se fomenta la alfabetización y razonamiento de los estudiantes en su rol de consumidores y productores de datos, vinculado al desarrollo de habilidades relacionadas, al ser capaz de representar y argumentar estadísticamente en base a evidencias y, de manera crítica, examinar afirmaciones basadas en datos. Respecto a estas habilidades, Ben-Zvi (2018, p. 7) indica “que todos los ciudadanos las deberían tener y, por lo tanto, que todos los estudiantes deben aprender como parte de su educación formal.”
4. MARCO CONCEPTUAL
A partir de estudios previos, se presenta un marco conceptual que extiende el modelo Espacio de Trabajo Matemático al trabajo estadístico (Cf., Estrella, Olfos, Morales y Vidal-Szabó, 2018; Estrella y Vidal-Szabó, 2017).
4.1 ESPACIO DE TRABAJO MATEMÁTICO (ETM)
El ETM es un modelo teórico y metodológico que brinda un enfoque analítico para estudiar el trabajo que realizan personas (o sujetos potenciales) frente a alguna actividad matemática. La noción de espacio está referida al ambiente intencionado y sistematizado que puede facilitar el trabajo que ejecuta un individuo al enfrentar algún problema matemático (Kuzniak y Richard, 2014; Flores-González y Montoya-Delgadillo, 2016).
Este modelo permite examinar y comprender la construcción del significado personal o institucional referido a un objeto matemático de manera pragmática, en la resolución de actividades por el estudiante o de manera hipotética en la propuesta de tareas por el docente o el currículo, considerándose la perspectiva epistemológica y cognitiva propias de la matemática, cuyas conexiones se asignaron en el diagrama ETM de la Figura 2a, con la denominación de génesis semiótica, instrumental y discursiva. Además, cada dos génesis coordinadas se constituyen planos verticales como se exhibe en el diagrama ETM de la Figura 2b, cuyas representaciones se establecen como [Sem-Ins], [Ins-Dis] y [Dis-Sem].
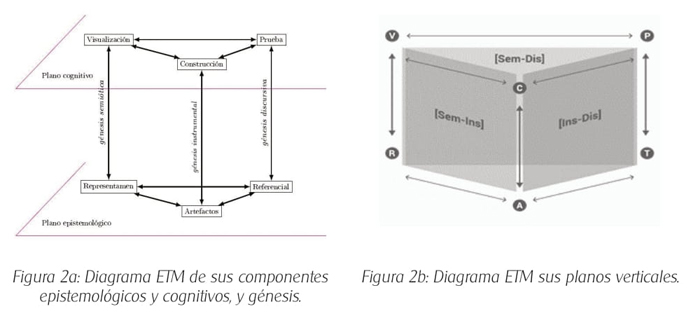
La tarea cumple un rol primordial en este modelo porque es, en parte, la responsable de la completitud de un ETM, en relación con la activación parcial o total de sus génesis (Kuzniak, Nechache y Drouhard, 2016; Parzysz, 2014). En ese sentido, los diagramas del ETM de la Figura 2 presentados por Kuzniak y Richard (2014) son operativos, según el análisis que se requiera realizar en una investigación.
4.2 AJUSTES AL MODELO ETM DE ACUERDO CON EL TRABAJO ESTADÍSTICO
Considerando que el ETM es una herramienta teórica que tiene la flexibilidad para interactuar con otros enfoques teóricos (Kuzniak, Tanguay et al., 2016), se presenta un ajuste para extender el modelo ETM a la disciplina estadística (Figura 3). En este ajuste, se releva el rol del contexto como idea clave en la estadística y su enseñanza, pues “sin contexto, el modelado estadístico no puede ocurrir.” (Pfannkuch, Ben-Zvi y Budgett, 2018, p. 1115).

El contexto implica al menos dos perspectivas. Desde lo epistemológico, el contexto de los datos se refiere a la situación del mundo real de la que surgen los datos para responder a un problema (Cobb y Moore, 1997). Desde lo cognitivo, el contexto del aprendizaje y la experiencia se remiten a los conocimientos contextuales del sujeto frente a los datos (Pfannkuch, 2011).
El ETM estadístico (ETM-E) es un espacio de trabajo en la disciplina estadística, siendo fundamental el contexto que dota de significado a la interpretación de la variabilidad omnipresente en los datos, como también indica Makar (2018). El ETM-E situado en el paradigma del análisis exploratorio de datos, demanda una nueva caracterización de la génesis semiótica, instrumental y discursiva. A saber:
Génesis semiótica en ETM-E. Da cuenta de la dialéctica entre lo semántico y lo sintáctico de los datos en contexto, en tanto significado y representación, permitiendo el análisis de los signos involucrados en las acciones de leer o escribir en estadística y que se relacionan a los procesos de decodificación y codificación de signos.
Génesis instrumental en ETM-E. Da acceso a explicar la acción de un sujeto al operar con artefactos, materiales o simbólicos, ya sean herramientas (valor epistemológico) o instrumentos (valor cognitivo) involucrados en un proceso de construcción en estadística, esto es, representar datos, determinar resúmenes numéricos de los datos en contexto, entre otros.
Génesis discursiva en ETM-E. Se enmarca en actividades estadísticas que demandan justificación basadas en propiedades y definiciones de la estadística, considerando la evidencia en los datos para tomar decisiones en contexto. Esta génesis integra el razonamiento estadístico que contempla la vinculación entre los procesos de prueba con pocos o muchos datos (big-data) y los referentes teóricos usados en la estadística (e.g., conceptos de medidas de tendencia central, de dispersión, de posición, de forma, entre otros), coherentes al conocimiento contextual que portan los datos.
En esta investigación se consideraron dos tipos de ETM-E, basados en los ETM reportados por Kuzniak, Tanguay et al. (2016). Por un lado, el ETM-E idóneo refiere a la forma en que el conocimiento debe ser enseñado, en relación con su lugar y función específica dentro del currículo, dependiendo de la institución involucrada, por lo que la activación potencial o efectiva de una o más génesis promoverán el aprendizaje en virtud de la enseñanza. Por otro lado, el ETM-E personal remite tanto a conocimientos estadísticos como a capacidades cognitivas vinculadas entre sí que posee un sujeto al enfrentar alguna tarea estadística. Las distintas activaciones de la génesis semiótica, instrumental y/o discursiva del ETM-E, evidencian una caracterización del trabajo estadístico de un sujeto como resolutor de problemas estadísticos.
Mediante el marco conceptual ETM-E, se describe y caracteriza una lección orientada por el ciclo investigativo y se examinan los desempeños de estudiantes de primaria.
5. METODOLOGÍA
Esta investigación cualitativa se enfoca en el estudio de casos de tipo instrumental (Stake, 1998), bajo una visión global de la lección y una visión local de las implicancias de la lección en tres estudiantes de primaria.
5.1 CONTEXTO Y SUJETOS
En una escuela chilena con un puntaje sobre el promedio nacional de 250 puntos en una prueba de matemática -i.e., Prueba SIMCE, Sistema de Medición de la Calidad de la Educación, del grado 4 en el año 2014-, 17 estudiantes del grado cuatro, fueron partícipes de una lección de organización de datos con final abierto sin instrucción previa y diseñada por un equipo docente (tres profesoras de la escuela que trabajaron conjuntamente con cuatro investigadores del área de la educación estadística temprana). Se consideraron los consentimientos escritos de la directora del establecimiento, docentes y apoderados.
De los 17 estudiantes, se seleccionaron tres, a quienes se les asignó los nombres de Miguel (10 años), José (10 años) y Javier (9 años 5 meses). El criterio de selección consideró la originalidad y riqueza de las representaciones de datos que produjeron durante la implementación de la lección, como también la capacidad de comunicar ideas sobre ellas durante las entrevistas aplicadas.
5.2 RECOLECCIÓN DE DATOS
Fueron recolectados a través de: (a) la resolución escrita del problema de la lección en una hoja de trabajo; (b) fotografías de cada una de las representaciones de datos producidas (ver Anexos 2, 3 y 4); (c) el registro audiovisual de la lección implementada y (d) la transcripción de las entrevistas in-situ durante la lección y posteriores a la implementación de la lección.
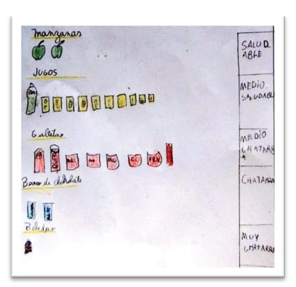
| Problema de la lección. Los estudiantes enfrentaron una situación de análisis exploratorio con datos reales. El problema proponía la siguiente tarea ¿de qué manera podemos organizar nuestras colaciones para saber si son saludables? La foto-grafía fue entregada en una hoja de trabajo a cada estudiante, la cual también contempló espacios en blanco para que los estudiantes pudieran construir una representación de los datos y así pudieran responder al problema (Figura 4). |
|

Cabe señalar que esta lección está basada en una experiencia anterior que describen Estrella, Zakaryan, Olfos y Espinoza (2020), aunque en esta ocasión se consideraron las colaciones que realmente llevaron los estudiantes a la escuela un día, las que fueron fotografiadas sobre la mesa de la profesora (ver Anexo 1).
5.3 MODALIDAD DEL ANÁLISIS
Tras la recolección de datos, el análisis de esta investigación contempló dos etapas: (I) Un análisis global de la lección que describió y caracterizó la lección siguiendo las etapas del ciclo investigativo (PPDAC) en el paradigma del análisis exploratorio de datos y de acuerdo con el ETM-E idóneo; (II) Un análisis local del desempeño de tres estudiantes partícipes de la lección, según las génesis del ETM-E personal, y la activación de los planos verticales (i.e., los planos [Sem-Ins], [Ins, Dis] y/o [Dis-Sem]).
Como análisis previo referido a la respuesta experta, se esperaba: (a) la definición explícita o implícita de la variable estadística con sus respectivas categorías (i.e., tipo y/o calidad nutricional de la colación); (b) la determinación de las frecuencias absolutas correspondientes (e.g., haciendo uso de alguna estrategia de conteo); (c) el diseño de alguna representación de datos -e.g., lista, tabla, gráfico de barras con o sin escala u otra-; (d) en la conclusión al problema, una indicación por escrito o de manera verbal sobre la mayoría de las colaciones de baja calidad nutricional, usando la frecuencia mayor de la categoría de la variable respectiva, desde su propia representación de datos.
La triangulación de datos se realizó entre el análisis de las producciones de los estudiantes, el análisis de las transcripciones de la lección videograbada y el análisis de las entrevistas videograbadas de los estudiantes sobre sus producciones.
6. RESULTADOS Y DISCUSIÓN
Se presenta una visión global que describe y caracteriza la lección en términos de las etapas del ciclo investigativo en términos de las génesis del ETM-E idóneo. Posteriormente, se presenta una visión local respecto a las implicancias del ETM-E idóneo en los ETM-E personales de los tres estudiantes partícipes de la lección.
6.1 VISIÓN GLOBAL DE LA LECCIÓN
6.1.1 La lección en términos del ciclo investigativo (PPDAC)
El problema y el plan. Tanto las etapas del problema como el plan fueron realizadas por el equipo docente, se consideró un Problema (P) cercano que tomaba como contexto la calidad nutricional de las colaciones que llevaban sus estudiantes a la escuela, y se formuló el problema de la lección en términos de una pregunta que requirió de datos reales para ser contestada, ¿de qué manera podemos organizar nuestras colaciones para saber si son saludables? Respecto al Plan (P), el equipo docente tuvo que elaborar una planificación para recolectar y registrar los datos necesarios para dar respuesta al problema. La profesora a cargo de la implementación de la lección en un día escolar, reunió las colaciones de sus estudiantes para fotografiarlas en su conjunto.
La necesidad de los datos. En la etapa de Datos (D), al inicio de la implementación de la lección, los estudiantes identificaron sus propias colaciones, a través de la proyección ampliada de dicha fotografía en aula. A continuación, un extracto de cómo la profesora despertó la necesidad de los datos en sus estudiantes.
| Profesora: | ¿Qué aparece ahí? |
| Estudiante-1: | Hay comida |
| Profesora: | ¿Cualquier tipo de comida? |
| Estudiante-2: | Hay comida saludable y comida chatarra [de bajo valor nutricional] |
| Profesora: | Me parece conocida esta imagen [muestra la proyección de la fotografía en la pizarra] |
| Estudiante-3: | ¡Son nuestras colaciones! |
Asimismo, la profesora les solicitó saber la cantidad total de colaciones en su hoja de trabajo, y usando distintas estrategias de conteo, la mayoría llegó a la cantidad correcta de 24 colaciones en total. Luego, la profesora introdujo el problema de la lección, planteando la pregunta, y permitiendo a los estudiantes trabajar individualmente en su hoja de trabajo.
| Profesora: | Todos estos son nuestros datos [muestra la fotografía de las colaciones proyectada sobre la pizarra]. Ustedes tienen que representarlos acá [muestra la hoja de trabajo] buscando una estrategia para representarlos. Ustedes van a buscar sus propias formas de representación de estas colaciones [que les permita responder a la pregunta que está por escrito en la pizarra]. |
Las representaciones de los datos. En el Análisis (A), los estudiantes trabajaron autónomamente, organizaron y representaron los datos a partir de la variable tipo de colación y/o calidad nutricional de la colación, y activaron sus conocimientos contextuales previos. Hubo una amplia variedad de representaciones producidas, cuatro de ellas correspondieron a Listas, tres a Diagramas, dos a Tablas, ocho fueron consideradas como Otras Representaciones; además, ninguno construyó Gráficos. Estas representaciones permitieron que los estudiantes iniciaran un análisis exploratorio de los datos para resolver el problema en el marco de la estadística temprana.
La conclusión al problema. Al término de la lección, algunos estudiantes explicaron sus representaciones de datos y contestaron ¿de qué manera podemos organizar nuestras colaciones para saber si son saludables? En la Conclusión (C), los estudiantes indicaron que la mayoría de las colaciones son “chatarras”, puesto que tenía un bajo valor nutricional. A continuación, se exhibe un extracto del término de la lección.
| Profesora: | ¿Qué podemos decir, para cerrar, con esta imagen [indica la proyección de las colaciones], sobre nuestras colaciones? ¿Qué podrían decir ustedes de sus colaciones? |
| Estudiante-4: | Es que algunas son saludables y algunas son chatarras |
| Estudiante-5: | La mayoría son chatarras |
| Profesora: | La mayoría son chatarras, ¿ya? |
| Estudiante-6: | En realidad, todas son chatarras |
| Profesora: | ¿Qué más podrían decir? En realidad, me parece que sí. Ah, al final el “juguito” [señala un jugo envasado en caja], ¿es saludable o no? |
| Estudiantes: | ¡No! |
| Estudiante-7: | Tiene mucho sodio. |
| Estudiante-8: | Tiene mucha azúcar. |
| Profesora: | Mucho sodio, mucha azúcar, las galletitas también. Entonces, ¿qué podríamos hacer después? Empezar a traer, ¿qué tipo de ...? |
| Estudiante-9: | El Agustín trae colación saludable [manzana]. |
| Profesora: | Felicitaciones Agustín. ¿Se comprometen a traer colaciones saludables? |
También, surgió un cuestionamiento sobre la clasificación de una colación.
A continuación, un extracto de la discusión entre dos estudiantes.
| Estudiante-10: | Las dos manzanas, yo las puse en lo saludable, y la barrita de cereal también lo puse en lo saludable porque tiene cereal y tiene, así como frutas. |
| Profesora: | ¡Ah!, la compañera puso dentro de lo saludable manzana y la barrita de cereal. Si bien, es cierto, contiene trocitos de frutas y contiene avena, hay que fijarse que también trae harto saborizante, harto colorante, mucha azúcar, entonces tan saludable no es. |
| Estudiante-4: | Profesora!, descubrí que mi cereal tiene cero azúcares y cero grasas. |
| Profesora: | ¡Ah! Vamos a verlo después. |
El conocimiento previo del contexto de la experiencia de aprendizaje estimuló en los estudiantes el razonamiento estadístico en la resolución de la tarea, tal conocimiento media la construcción del razonamiento involucrado, según Pfannkuch (2011). En este sentido, el rol del contexto es fundamental para provocar la actitud estadística de escepticismo al analizar el comportamiento de los datos, al cuestionar las limitaciones o explicaciones que pueden conformar la conclusión al problema. En la lección, las colaciones que llevaron los estudiantes a la escuela y el cuestionamiento sobre el valor nutricional de sus propias colaciones, permitieron que los estudiantes construyan representaciones y argumentaran sobre ellas, despertando la necesidad de los datos y la construcción de representaciones con sentido.
Dada la oportunidad de resolver un problema estadístico mediante el ciclo investigativo, los estudiantes fueron capaces de representar datos categóricos y argumentar sobre ellos, tal como indican otros estudios (e.g., Estrella et al., 2018; English, 2012, 2018).
6.1.2 La lección en términos de las génesis del ETM-E idóneo y su relación con el ciclo investigativo
A continuación, se presenta la lección analizada por el ETM-E idóneo en términos de las génesis en el paradigma del análisis exploratorio de datos y su relación al ciclo investigativo.
Génesis semiótica. La lección fomentaba que el estudiante observara la hoja de trabajo con las colaciones para responder a la pregunta, se esperaba que decodificara cada colación como dato de al menos una variable (tipo y/o calidad nutricional de la colación) y codificara al dibujar íconos o escribir en palabras cada colación, como registro de cada dato. Dichas acciones son presentadas mayormente en el tránsito de Datos a Análisis en el PPDAC, provocando una activación potencial de la génesis semiótica.
Génesis instrumental. La lección contempló que el estudiante fuera adaptando las herramientas que tenía para dibujar o escribir cada colación, con o sin colorear, en los espacios disponibles en la hoja de trabajo para construir representaciones de datos de tipo lista, tabla, diagrama u otra representación distinta, que le permitiera hacer sus conteos. Dichas acciones son presentadas mayormente en el tránsito de Análisis a Conclusiones en el PPDAC, provocando una activación potencial de la génesis instrumental.
Génesis discursiva. La lección promovía que el estudiante, dada la tarea, utilizara una estrategia de clasificación y conteo para determinar las categorías de la variable con su respectiva frecuencia, asociadas al tipo de colación y/o calidad nutricional de las colaciones. Ello provee en el estudiante una manera de comparar las frecuencias de las categorías de la variable entre sí para concluir al problema y obtener así la moda como medida de tendencia central (implícita o explícita en las representaciones de datos que construyeron). Dicha comparación entre frecuencias se hizo por uso del criterio aritmético de orden entre los números naturales en lista o tabla; o bien, por inspección visual, reconociendo la mayor longitud entre íconos alineados o barras en un pictograma, diagrama o gráfico, construido de manera vertical u horizontal. Dichas acciones son presentadas mayormente en el tránsito de Conclusiones a Problema en el PPDAC, provocando una activación potencial de la génesis discursiva.
Hay estudios que indican que los docentes, al momento de diseñar una lección de estadística, también vivencian el ciclo investigativo, lo cual contribuye a su alfabetización y razonamiento estadístico (e.g., Estrella et al., 2020; Estrella y Vidal-Szabó, 2017). En este caso, las etapas Problema (P) y Plan (P) son diseñadas por el equipo docente, mientras que las etapas de Datos (D), Análisis (A) y Conclusiones (C) lo vivencian los estudiantes durante el desarrollo de la lección junto a los andamiajes que realiza, anticipadamente, la profesora producto del análisis previo del equipo docente.
6.2 VISIÓN LOCAL DE LAS IMPLICANCIAS DE LA LECCIÓN EN TRES ESTUDIANTES
6.2.1 Aproximación al ETM-E personal de Miguel (10 años)
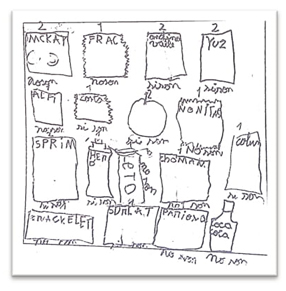
| Miguel produjo una lista icónica como representación de los datos, la cual contiene íconos, textos y dígitos (ver Anexo 2). La lista posee íconos que indican la categorización de las colaciones, según la variable “tipo de colación”; y los textos bajo cada ícono dan cuenta de la categorización, según la variable “calidad nutricional de la colación” (Figura 5). En un episodio ocurrido durante la lección, mientras Miguel terminaba de construir su lista, uno de los investigadores le pregunta respecto a su representación. |
|

| Miguel: | Estoy haciendo lo que es… lo que “noson” o lo que “sison”, estoy ordenando en 2, ahí hay 2 [indica el primer ícono de su lista], aquí hay 1 [indica el segundo ícono de su lista] y aquí dicen lo que son “sison” o “noson”. |
| Investigador: | ¿qué cosa? |
| Miguel: | Aquí, abajo dice lo que “noson” o lo que “sison”, aquí y aquí [lo indica en su representación] |
| Investigador: | Ya, por ejemplo, te refieres como no son saludables y sí son saludables, ¿algo así? |
| Miguel: | Sí. |
En una entrevista, posterior a la lección, Miguel explica su representación.
| Investigador: | ¿Te acuerdas lo que era? ¿Sí? ¿Qué era? [indica las colaciones presentes en la fotografía] |
| Miguel: | Era la colación que usamos para saber la que son buenas, la que son saludables o la que son malas. |
| Investigador: | Cuéntanos, ¿qué hiciste acá? |
| Miguel: | Puse lo que estaban ahí [indica las colaciones presentes en la fotografía] y lo puse que “noson” y lo que “sison”. |
| Investigador: | Y ¿qué significa eso que “sison”, “noson”? |
| Miguel: | Lo que “noson” son las que son malas para la salud y las que “sison” son las que son saludables. |
Para Miguel el dígito sobre cada ícono indica la cantidad de datos que dicha categoría contiene y el texto bajo los íconos refiere a una segunda clasificación, en la que cada tipo de colación fue categorizada como no son saludables (representado como “noson”) y, sí son saludables (representado como “sison”). Sin embargo, su clasificación no es exhaustiva porque representó 22 de las 24 colaciones.
La génesis semiótica de Miguel se activó al decodificar el representamen de las colaciones de su hoja de trabajo, en que visualiza las colaciones como datos, según la variable “tipo de colación”. Luego, codifica en íconos que dibuja como categorías de la variable “tipo de colación” y después vuelve a decodificar, visualizando una segunda variable “calidad nutricional de la colación”, en que para cada categoría inicial vuelve a codificar con los rótulos “noson” y “sison”.
La génesis instrumental de Miguel fue activada al construir la lista -producto de la instrumentación que hace de los íconos dibujados para las 22 colaciones consideradas-, aunque dificulta responder la pregunta. En la lista, cada ícono con cardinal representa una categoría de la variable “tipo de colación” con su respectiva frecuencia, y luego rotula dichos íconos como “sison” o “noson”, que remiten a la categoría de la variable “calidad nutricional de la colación”.
La génesis discursiva de Miguel se activó al poner en uso su conocimiento contextual y estadístico, en que primero clasifica las colaciones como datos de la variable tipo de colación en varias categorías con su frecuencia, y después vuelve a clasificar como datos de la variable calidad nutricional de la colación en dos categorías, lo cual permitió argumentar si las colaciones son o no mayormente saludables o sanas, con la salvedad de que consideró 22 de las 24 colaciones.
En el ETM-E personal de Miguel, el plano [Dis-Sem] es el privilegiado (ver plano vertical tachado en Figura 6) porque, el problema sobre lo saludable de las colaciones, fue abordado considerando dos variables durante el análisis exploratorio de los datos. Sin embargo, la lista que construye no consideró a todas las colaciones y dificulta comunicar a otros la información del comportamiento de la mayoría de los datos, lo que muestra una génesis instrumental en proceso de consolidarse.

6.2.2 Aproximación al ETM estadístico personal de José (10 años)
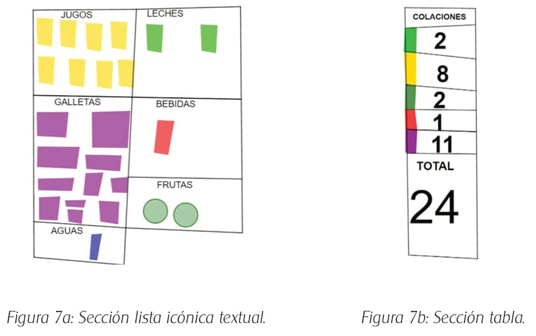
José produjo dos representaciones relacionadas (ver Anexo 3). Primeramente, construyó una lista del tipo icónica textual, esto es, íconos repetidos en celdas de una grilla para representar cada dato sin cardinal, utilizando palabras (registro textual) para rotular la categoría de la variable (Figura 7a). Luego, a partir de la primera representación construye la segunda, la que corresponde a una tabla con categorías de la variable representadas por rectángulos de color con sus respectivas frecuencias absolutas marginales y frecuencia total (Figura 7b). Su clasificación es exhaustiva porque representó las 24 colaciones. Sin embargo, la cantidad de categorías de la variable de la lista que corresponde a seis, no coincide numéricamente con las cinco categorías de la variable de la tabla que consideró en su construcción.
En un episodio ocurrido durante la lección, mientras José terminaba de construir su tabla, uno de los investigadores le entrevistó, de acuerdo con su representación.
| Investigador: | Ya José, ¿qué hiciste? |
| José: | Primero lo dibujé y después los pinté para clasificarlo por color. |
| Investigador: | ¿Y qué significa por ejemplo amarillo y 8? [indica sección de la tabla] |
| José: | Son los jugos porque [yo] los pinto de amarillo y aquí tengo el amarillo y significa jugo. |
Al final de la lección, José presenta su representación de datos frente al grupo de su curso y señala:
| Profesora: | José di lo que hiciste. |
| José: | Yo primero los dibujé, hice 24 colaciones en total. Puse 11 galletas, 1 bebida, 2 frutas, 2 leches y 8 jugos. Después los pinté por cada color, los jugos amarillos, leche verde, galleta morada, bebida roja y fruta verde más claro. Después lo fui viendo por colores [en la tabla], por ejemplo, la leche, habían 2. |
Cuando José pinta, no lo hace de manera azarosa, sino que establece una estrategia de clasificación en el que presenta para cada color una única categoría de la variable. Por ejemplo, indica que pinta de amarillo los íconos dibujados que remiten a jugos.
La génesis semiótica de José se activó al decodificar el representamen, visualizando a los datos asociados a la variable “tipo de colación”, en que luego codifica en íconos por categoría de la variable siguiendo una lógica de distribución espacial en la grilla para clasificar. Después, decodifica los íconos de una misma categoría (Figura 7a), haciendo uso de un color para cada categoría, exceptuando el color celeste que representa aguas, codificando en rectángulos de color y dígitos que representan la frecuencia de cada categoría en la tabla (Figura 7b).
La génesis instrumental de José se activó de manera doble, ya que la tabla (Figura 7b) sintetiza la lista que construyó (Figura 7a), la cual fue conseguida por los artefactos que instrumentaliza a través de los íconos que dibuja y colorea en espacios determinados en la grilla que elabora.
La génesis discursiva de José que fue activada no respondió al problema de la lección, pues no es posible argumentar, a partir de su representación de datos, si las colaciones son o no mayormente saludables porque consideró la variable estadística tipo de colación, y además restó una categoría de la variable al transitar de la primera a la segunda representación.
En el ETM-E personal de José, el plano [Sem-Ins] es el privilegiado (ver plano vertical tachado en Figura 8) porque al razonar estadísticamente, progresó en la comprensión del comportamiento de los datos utilizando solamente la variable tipo de colación. Aunque, José activó una génesis discursiva que no se ajustó a lo esperado para concluir al problema de la lección por no considerar la variable calidad nutricional de la colación, posee una génesis instrumental adecuada para la variable estadística que consideró.
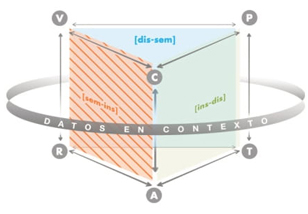
6.2.3 Aproximación al ETM estadístico personal de Javier (9 años 5 meses)
Javier produjo dos representaciones, una lista icónica textual y una escala con cinco niveles, en que ambas representaciones están vinculadas entre sí (ver Anexo 4). Primeramente, construyó una lista icónica textual, esto es, repetición del dato como ícono sin cardinal de forma horizontal y un texto que nombra la categoría de la variable “tipo de colaciones” (Figura 9a). Luego, construyó una escala con cinco niveles sobre la “calidad de la colación” (Figura 9b). Efectuó una clasificación exhaustiva puesto que representó todas las colaciones.

En un episodio ocurrido durante la lección, mientras Javier terminaba de construir su lista, uno de los investigadores le entrevistó de acuerdo con su representación.
| Investigador: | Javier ¿me puedes explicar cómo lo hiciste? |
| Javier: | Sí. Primero tengo manzanas que es lo más saludable. Después los jugos que igual tienen grasa, pero un poquito. Después las galletas y después los chocman [queques pequeños cubiertos de chocolate] que también son (…) que tienen un poco de chocolate y las bebidas que son lo más chatarra por así decirlo, y eso. |
Al final de la lección, Javier presenta su representación de datos frente al pleno del curso y señala:
| Javier: | La manzana son saludables, los jugos son medio saludable, las galletas son medio chatarra, los chocman son chatarra y la bebida es muy chatarra. |
| Profesora: | ¿Y cuántos te dieron en total? |
| Javier: | 24 [colaciones]. |
Javier al explicar su representación -lista con escala- evidencia que el orden de su lista estaba implícitamente graduado en niveles desde “lo más saludable” a “lo más chatarra” en sus palabras. La representación final de Javier muestra la variabilidad de los datos en la lista con la escala de cinco niveles.
La génesis semiótica de Javier se activó al decodificar el representamen, mediante una visualización de los datos asociados a la variable “tipo de colación”, después codifica los datos en íconos referidos al tipo de colación (Figura 9a), en que activó una visualización de los datos asociados a la variable “calidad nutricional de la colación” con cinco niveles graduados (Figura 9b).
La génesis instrumental de Javier se activó al construir su representación mediante íconos que dibuja -artefactos que representan datos- explicitando las categorías de la variable “tipo de colación”, y cuyo orden responde a la variable “calidad nutricional de la colación” (Figura 9a). Después, a través de la lista de datos, construye una escala de cinco niveles de forma textual para representar las categorías de la variable “calidad nutricional de la colación”, explicitando en su representación de datos final la coordinación que hizo de ambas variables (Figura 9b).
La génesis discursiva de Javier se activó al analizar exploratoriamente los datos, coordinando dos variables estadísticas en la organización y clasificación de los datos, coherente al contexto del problema. En ese sentido, la escala graduada evidencia un razonamiento sobre la variabilidad de los datos que es movilizado por el conocimiento contextual disponible.
El ETM-E personal de Javier es completo (ver todos los planos verticales tachados en Figura 10), en el sentido que activó las tres génesis. La argumentación basada en la variabilidad de los datos en contexto, evidencia un razonamiento estadístico robusto a su nivel educativo, sustentado por su representación y el uso de dos variables estadísticas que interactúan entre sí, lo cual permitió concluir sobre la calidad nutricional de las colaciones correctamente.

En síntesis, los tres estudiantes exhiben un ETM-E personal en el paradigma análisis exploratorio de datos, tal como lo proponía el ETM-E idóneo. En particular, tanto Miguel como Javier realizan representaciones de datos en las que consideraron dos variables estadísticas coordinadas (i.e., tipo y calidad nutricional de las colaciones), mientras que José consideró una única variable en su representación de datos que no se relacionaba con el contexto del problema.
La capacidad de invención de los tres estudiantes y la funcionalidad de las representaciones de Miguel y Javier dan cuenta de su competencia meta-representacional en desarrollo, la cual describe la completa gama de capacidades que los sujetos tienen para construir y usar representaciones (Cf., Estrella et al., 2018). Las representaciones de datos que construyeron los mismos estudiantes -no necesariamente las que propone el currículo escolar- permitió desarrollar la toma de conciencia del contexto de los datos, además de tener las oportunidades de comprender, interpretar y explicar los datos basados en evidencia empírica (Rumsey, 2002).
Los datos y sus representaciones son ideas fundamentales del currículo de la estadística (Burrill, y Biehler, 2011), las que permiten a los estudiantes desarrollar habilidades como el visualizar la distribución empírica de los datos, como también, el modelar y comunicar el comportamiento de estos. Dichas habilidades pueden desarrollarse desde los primeros años escolares, lo cual reafirma los principales desafíos que sintetiza Ben-Zvi (2016) para el razonamiento estadístico de los estudiantes en el paradigma del análisis exploratorio de datos; en especial, la comprensión de centrarse en uno o unos pocos dentro del total y a la vez comprender globalmente el comportamiento de los datos, lo que refiere a la capacidad de buscar, reconocer, describir y explicar patrones en un conjunto de datos mediante la observación de las distribuciones y/o mediante parámetros o técnicas estadísticas (Cf., Ben-Zvi y Arcavi, 2001).
7. CONCLUSIONES
Esta investigación buscó describir y caracterizar una lección orientada por el ciclo investigativo (PPDAC) y se examinaron los desempeños que propició en tres estudiantes de primaria (9-10 años). Para ello, se realizó un análisis cualitativo de los aprendizajes estadísticos con la mirada de los espacios de trabajo matemático orientado por una tarea basada en el ciclo investigativo. Esta investigación propuso una extensión del modelo ETM, ajustándolo a la disciplina estadística (ETM-E) -relevando el rol de los datos en contexto como idea fundamental en el aprendizaje y enseñanza de la estadística-, con el fin de analizar desde una perspectiva global la lección y examinar localmente las producciones de tres estudiantes.
Desde el análisis global de la lección, se concluye que potencialmente la lección en el marco de la estadística temprana, permitió que los estudiantes pudieran aproximarse a los procedimientos que utiliza un estadístico para pensar y aprender más en la esfera del contexto, tal como lo indican Pfannkuch y Wild (2004). La lección orientada por el ciclo investigativo, fomentó un ambiente de aprendizaje estadístico como diseño de enseñanza en el paradigma del análisis exploratorio de datos y en el contexto de las colaciones con datos reales y cercanos a la realidad de los estudiantes partícipes de la lección. En consecuencia, el ciclo investigativo propició en los sujetos un trabajo estadístico temprano como un espacio organizado e intencionado, lo cual permite comprender el comportamiento de los datos en contexto, promoviendo la alfabetización y razonamiento estadístico durante el proceso cíclico. Los estudiantes tuvieron que activar sus conocimientos previos -en cuanto a sus experiencias personales y sus predisposiciones frente al contexto- para organizar los datos que fueron presentados sin orden en la hoja de trabajo y poder así construir sus propias representaciones que permitieran conectar ideas y concluir exploratoriamente.
Desde el análisis local del desempeño de los tres estudiantes, se concluye que, a través de sus representaciones, pudieron descubrir, razonar y comunicar ideas estadísticas de distintas formas como una oportunidad de aprendizaje propiciado por la lección y sus experiencias previas. Por consiguiente, esta investigación concuerda con los estudios que recomiendan que el currículo y los textos escolares promuevan la organización y representación de datos -bajo las propias formas que entiendan y decidan los estudiantes (e.g., Estrella y Estrella, 2020)- de modo que facilite el razonamiento estadístico a partir de sus representaciones, y experimenten aspectos fundamentales del análisis de datos (e.g., English, 2010, 2012, 2018; Estrella, Olfos, Morales y Vidal-Szabó, 2017; Makar, 2018), enfrentándose a problemas auténticos y cercanos a la realidad que les rodea (Franklin et al., 2007; National Council of Teachers of Mathematics, 2015).
El término plano dirigido en el ETM que se conforma por la coordinación de dos génesis en que una de ellas da inicio al trabajo y se observa privilegiada por sobre la otra en la activación del plano vertical (Menares, 2019), es posible reconocerlo en el trabajo estadístico de los estudiantes porque los tres casos evidenciaron que la génesis semiótica estuvo privilegiada y se coordinó con la génesis instrumental y/o con la génesis discursiva.
Incluir la participación de niños y niñas en los componentes básicos de la elaboración de modelos de datos, a saber, la visualización de las categorías de la variable, la estructuración y representación de los datos, la identificación de la variabilidad en los datos; son aspectos esenciales para la diversificar oportunidades de aprendizaje estadístico, en concordancia con English (2010, 2012, 2018), Estrella y Vidal-Szabó (2017). Por tanto, promover desde el currículo y diseños de enseñanza la construcción de representaciones usuales e inusuales con datos reales, facilitaría el desarrollo de la alfabetización y razonamiento estadístico desde los primeros años formativos.
Dentro de las limitaciones de esta investigación, se encuentra la falta de seguimiento de la discusión estadística de los estudiantes, referida al conocimiento contextual de la calidad nutricional de sus propias colaciones; lo que impidió desde la enseñanza, afianzar una actitud escéptica -la que forma parte de una de las dimensiones del pensamiento estadístico (Cf., Pfannkuch y Wild, 2000, 2004; Wild y Pfannkuch, 1999)- frente a las distintas conclusiones e inferencias informales.
Esta investigación amplía el ETM a la disciplina estadística y, sugiere nuevos estudios que precisen otros paradigmas presentes en la estadística con fines educativos, o bien, examinen la influencia de los ETM-E personales de los profesores en el ETM-E idóneo, entre otros tópicos de interés en la Didáctica de la Estadística.