











 text in
text in  English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
PermalinkIntroducción
Las condiciones climáticas permiten que gran parte del territorio de México sea propicio para la producción de maíz. Es uno de los productos agrícolas más importantes a nivel mundial debido a su uso en la alimentación humana, producción pecuaria, en industrias como la farmacéutica, bioenergética y cosmética. El consumo promedio per cápita anual en México es de 196.4 kg de maíz blanco (SAGARPA, 2017). Es el cultivo con mayor valor económico generado por su venta, tiene 89% de participación nacional en la producción de granos (SIAP, 2019). En 2018, la producción de maíz grano se ubicó en 27.17 millones de toneladas, 86.7% correspondió a maíz blanco, 12.9% a maíz amarillo y 0.4% a otros tipos (azul, pozolero y de color) (FIRA, 2019).
En 2020 los estados con mayor participación en el total de la producción nacional de maíz en México fueron Sinaloa (23%), Jalisco (14%), Michoacán (8%) y Estado de México (7%), que en conjunto abarca 51% de la producción total. Entre 2009 y 2018, la producción en Jalisco y Michoacán creció a una tasa promedio anual de 4.7% y 6% respectivamente. El consumo nacional aparente de maíz ha crecido a una tasa promedio anual 4% en el caso del maíz blanco y 9.6% en el maíz amarillo. Se ubicó en 43.7 millones de t (56.7% maíz blanco, 24.8 millones de t y 43.35% de maíz amarillo, 18.9 millones de toneladas (SIAP, 2020).
Dada la participación mayoritaria del maíz blanco en la producción nacional y ante la falta de una señal sobre el comportamiento del precio como el Chicago Mercantile Exchange, que proporcione pronósticos del precio y sea útil a los productores, comercializadores e inversionistas financieros en la toma de decisiones anticipada al mercado este trabajo tuvo como objetivo proporcionar un predictor de maíz blanco en Jalisco y Michoacán usando la metodología de Box y Jenkins. La hipótesis planteada es que el precio de maíz blanco puede ser modelado mediante sus propios valores rezagados con modelos ARIMA y estos pueden ser usados como predictores del precio.
El contrato de maíz amarillo no. 2 free on board (FOB) puesto en el Golfo de México cotizado en la bolsa de valores de Chicago es un referente del precio internacional del maíz (FIRA, 2016) y es usado por la agencia de servicios a la comercialización y desarrollo de mercados agropecuarios (ASERCA) para realizar coberturas de precios de maíz; sin embargo, Ortiz y Montiel (2017) argumentaron que la cobertura de precios no cumple adecuadamente con su propósito de proteger a los agricultores nacionales que siembran maíz blanco. La aplicación de técnicas de modelación de series de tiempo para obtener predicciones ha sido de interés en Luis et al. (2019) quienes desarrollaron un modelo de procesos estacionales autorregresivos integrados de media móvil (SARIMA) para los precios nominales mensuales de huevo blanco pagado al productor y concluyen que el precio del huevo es explicado por los precios de dos y doce meses previos.
Delgadillo et al. (2016) compararon modelos ARIMA para pronosticar el rendimiento de granos básicos: maíz, frijol, trigo y arroz en México, con el objetivo de predecir dicha variable en el corto plazo. Contreras et al. (2016) hicieron uso de modelos de promedio móvil simple, promedio móvil ponderado, suavización exponencial y suavización exponencial ajustada para pronosticar la demanda de almacenamiento en productos perecederos, el volumen de ingreso y egreso de los productos en una cámara frigorífica, para prever los requerimientos de instalaciones, personal y materiales necesarios. Barreras et al. (2013) mostraron que mediante los modelos autorregresivos de media móvil (ARMA) es posible construir predictores de la producción porcícola en Baja California, México.
En su estudio aplicaron la metodología de Box-Jenkins para ajustar modelos ARMA (12, 12) y AR (12) a datos mensuales de producción de carne de cerdo. Sánchez et al. (2013) plantearon un modelo ARIMA para pronosticar el comportamiento de la producción de leche de bovino en el estado de Baja California y concluyeron que un modelo ARMA (1, 1) proporciona pronósticos adecuados a corto plazo. Del mismo modo, Marroquín y Chalita (2010) ajustaron un modelo ARIMA (23, 0 ,1) a una serie de precios nominales de venta al mayoreo de jitomate ‘bola’ en México y posteriormente construyeron predicciones del comportamiento del precio del jitomate en los siguientes 12 meses.
Adebiyi et al. (2014) modelaron el precio de acciones que cotizan en la Bolsa de Valores de Nueva York (NYSE) y la Bolsa de Valores de Nigeria (NSE) utilizando modelos ARIMA y concluyeron que estos modelos tienen un fuerte potencial para predecir el precio de las acciones de las empresas Nokia y Zenith Bank a corto plazo. Jamal et al. (2018) utilizaron datos históricos para predecir la demanda futura de una empresa alimentaria usando un modelo ARIMA (1, 0, 1) con el objetivo de planificar con base en pronósticos precisos para minimizar el costo total de producción compuesto por los costos de adquisición, procesamiento, almacenamiento y distribución y con el objetivo de obtener beneficios como inventarios reducidos, menores costos de la cadena de suministro, mayor rendimiento de los activos, mayor satisfacción del cliente y tiempos de entrega reducidos, concluyeron que este modelo proporciona información útil que afecta la cadena de suministro de la empresa analizada.
Materiales y métodos
Una serie de tiempo se refiere a las observaciones de una variable que ocurren en una secuencia de tiempo. Y t Simboliza el valor numérico de una observación; el subíndice t indica el periodo de tiempo en que ocurre la observación. Una secuencia de n observaciones puede representarse como
(Pankratz, 1983). Un modelo autorregresivo integrado de media móvil (ARIMA) está dado por (Box et al., 2016):
Donde: ε= son términos de error aleatorio, independientemente distribuidos con media cero y varianza 𝜎 2 . Sí es necesario diferenciar una serie de tiempo d veces para hacerla estacionaria se dice que la serie de tiempo original es ARIMA (p, d, q), donde: p= denota el número de términos autorregresivos y q= el número de términos de promedios móviles (Cryer y Sik, 2008).
Un proceso Y t es estrictamente estacionario si la distribución conjunta de
es igual a la distribución conjunta de
para cualquier punto en el tiempo t 1 , t 2 ,..., t n y para cualquier rezago k. Por lo tanto, sí n= 1 la distribución univariada de Y t es igual a la distribución de Y t-k para todo t y k; es decir, las distribuciones marginales estarán idénticamente distribuidas, además: E( Y t )= E( Y t±k ) y Var( Y t )= Var( Y t±k ), para todo t y k, esto es, la media y la varianza son constantes a través del tiempo. Un proceso estocástico es estacionario si el valor de la covarianza entre dos periodos depende sólo de la distancia o rezago entre estos dos periodos y no del tiempo en el cual se calculó la covarianza (Gujarati y Porter, 2010).
El supuesto de estacionariedad es el más importante para hacer inferencia estadística sobre la estructura de un proceso estocástico. La idea básica de estacionariedad es que las leyes de probabilidad que gobiernan el comportamiento del proceso no cambian con el tiempo (Cryer y Sik, 2008).
La metodología Box-Jenkins considera cuatro pasos para ajustar un modelo de series de tiempo; 1) identificación del orden de integración de la serie; si la serie tiene raíz unitaria debe realizarse un proceso de transformación para volverla estacionaria; 2) identificación de los valores p, d y q, la función de autocorrelación (ACF) y la función de autocorrelación parcial (PACF) son una herramienta útil para la identificación de estos valores; 3) estimación de los parámetros de los términos autorregresivos y de promedios móviles incluidos en el modelo, pueden estimarse mediante el método de mínimos cuadrados ordinarios o máxima verosimilitud. Para discriminar entre modelos se puede hacer uso de los criterios AIC, BIC, etc., tomando el modelo con el mínimo valor en cada uno de estos estadísticos; y 4) diagnóstico para corroborar que los residuales estimados a partir del modelo propuesto tengan un comportamiento de ruido blanco, en cuyo caso se acepta el modelo para realizar predicciones (Box et al., 2016).
La metodología Box-Jenkins aplica a series estacionarias, antes de ajustar un modelo ARIMA es necesario verificar las condiciones de estacionariedad en cada una de las series: media y varianza finitas y constantes respecto al tiempo y covarianza finita que dependa del tiempo en la definición de proceso autorregresivo (Quintana y Mendoza, 2010).
Criterios para evaluar el desempeño de los modelos
Se aplicaron dos pruebas para verificar la presencia de raíces unitarias: Dickey Fuller Aumentada (DFA) y Phillips-Perron (PP). Las series resultaron no estacionarias y fueron transformadas con la finalidad de inducir estacionariedad. Se obtuvo el logaritmo natural para estabilizar la varianza y se diferenciaron las series para estabilizar la media alrededor de cero. La estimación de los parámetros de los modelos ARIMA se realizó mediante MCO y se verificó que los residuales presenten un comportamiento similar a ruido blanco, en cuyo caso se realizaron predicciones usando los modelos seleccionados.
Bajo el supuesto de que el modelo ha sido correctamente especificado y los parámetros verdaderos para cada serie son conocidos, es posible pronosticar el valor de Y t+k que ocurrirá en k unidades de tiempo en el futuro mediante:
La observación futura y t+k estará contenida dentro de los límites de predicción con (1 - α) % de confiabilidad:
El supuesto habitual para construir intervalos de predicción es que los errores de pronóstico tienen una distribución normal con media cero Makridakis et al. (1997). Bajo este supuesto, un intervalo de predicción aproximado para la siguiente observación es:
Donde:
Después de identificar los parámetros del modelo y estimarlos es posible determinar predicciones puntuales mediante el siguiente procedimiento en un modelo MA (q): dados los valores observados y 1 , y 2 ,.., y t-1 es posible utilizar estos valores para obtener una predicción puntual y t de valor y t mediante el siguiente cálculo:
Para determinar la predicción puntual del valor futuro y t se calcula la perturbación aleatoria:
Donde:
La predicción puntual ϵ t de la perturbación o choque futuros ϵ t es cero y la predicción puntual ϵ t-1 de la perturbación aleatoria pasada ϵ t-1 es el residuo (t-1)-ésimo. En caso de no poder estimarse y t-1 se considera igual a cero (Bowerman et al., 2007). Siguiendo un procedimiento similar es posible construir pronósticos para un modelo AR (p). El error estimado usado para medir la precisión de un modelo calculado usando los mismos datos para ajustar el modelo puede tender a cero, incluso se pueden obtener errores porcentuales medios absolutos y errores cuadrático-medios de cero si en la fase de ajuste se utiliza un polinomio de orden alto, que conduce a tener modelos sobre ajustados.
Estos problemas pueden superarse midiendo la verdadera precisión del pronóstico fuera de la muestra. Los datos totales se dividen en un conjunto para ajustar el modelo y estimar los parámetros. Posteriormente, se realizan pronósticos para el conjunto de prueba, dado que el conjunto de prueba no se usó en el ajuste del modelo, estos pronósticos son pronósticos genuinos hechos sin usar los valores de las observaciones para estos tiempos. Las medidas de precisión se calculan solo para los errores en el conjunto de prueba (Makridakis et al., 1997).
La capacidad predictiva de los modelos puede ser medida utilizando estadísticas como: el error promedio de pronóstico (ME), el error promedio absoluto de pronóstico (MAE), el error cuadrático medio del pronóstico (MSE), la raíz del error cuadrático medio, del inglés root mean squared error (RMSE), el porcentaje medio de error (MPE), el error porcentual absoluto medio, del inglés mean absolute percentage error (MAPE) y la U de Theil.
Sea
una secuencia de n pronósticos. El error de pronóstico se define como la diferencia entre la observación real y el valor pronosticado:
Por lo tanto, los errores del pronóstico serán:
Y el error cuadrático medio (ECM) es:
La raíz del error cuadrático medio (RECM) asociado con dicha secuencia es:
Es la desviación típica muestral de los errores del pronóstico
Una medida que sólo toma valores positivos; cuando esta medida tiende a cero indica que los pronósticos tienden al valor real observado.
El error porcentual absoluto medio, del inglés mean absolute percentage error (MAPE) se define como:
La U de Theil permite una comparación relativa de los métodos de pronóstico formales con métodos ‘ingenuos’ o simplistas, que utilizan la observación más reciente disponible como pronóstico y también pondera los errores involucrados para que los errores grandes tengan mucho más peso que los errores pequeños (Makridakis et al., 1997). Se define como:
Sí el coeficiente de Theil es igual 0, significa que el pronóstico es perfecto (exacto). Sí el coeficiente de Theil es igual a 1, indica que la precisión del método de pronóstico bajo estudio es igual a la del método simplista, que asigna el valor del pronóstico igual al valor de y t por lo que no se justifica implementar el método bajo estudio. Si el coeficiente de Theil es mayor que 1, significa que el modelo no es útil para fines predictivos. Sí 0 < U de Theil < 1 el método usado para pronosticar es superior al método simplista. Cabe destacar, que la U de Theil es una medida de precisión relativa que toma valores no negativos. Los análisis estadísticos fueron realizados usando el software R versión 3.6.1 y el software Statistical Analysis System (SAS, 2019).
Las series de tiempo analizadas corresponden a los precios promedio mensuales en los estados Michoacán y Jalisco. Los datos fueron obtenidos del portal del sistema nacional de información de mercados (SIIM). Los datos están expresados en pesos por kilogramo ($ kg-1). El periodo de análisis es desde enero del año 2000 a diciembre del año 2018 con 228 observaciones en cada serie. Dado que los valores futuros de las series son desconocidos, retener una parte de las observaciones, estimar modelos alternativos sobre un conjunto de datos reducido y usar estas estimaciones para pronosticar las observaciones del período en retención permite comparar las propiedades de los errores de pronóstico de los modelos estimados (Enders, 2015).
Se realizó una partición del conjunto de datos de cada serie, en dos subconjuntos. El primer subconjunto correspondió al conjunto de ‘entrenamiento’ y tuvo 222 observaciones del periodo de enero de 2000 a junio de 2018, éste fue usado para ajustar los modelos ARIMA. El conjunto de ‘validación’, tuvo las 6 las últimas observaciones de cada serie, desde julio de 2018 a diciembre de 2018 y fue utilizado para evaluar la capacidad predictiva de los modelos, usando la raíz del error cuadrático medio (RECM), el error porcentual absoluto medio (MAPE) y la U de Theil.
Resultados y discusión
Las series del precio de maíz en Michoacán y Jalisco presentaron una tendencia creciente de 2000 a 2020, con periodos de volatilidad después de 2010, este comportamiento fue similar en los precios al productor de maíz a nivel nacional que en 2020 se incrementó por sexto año consecutivo llegando a 4 190.00 $ t-1, lo que representó un aumento de 7% en relación con el año previo. Algunos factores que influyen en la volatilidad de los precios incluyen fenómenos climáticos que provocan afectaciones en los cultivos, disminución de la oferta, incrementos en la demanda, políticas económicas internas y externas, la participación de commodities agrícolas en los mercados de valores, perspectivas económicas a nivel nacional e internacional, entre otros. El comportamiento errático y tendencia creciente sugiere que estas series temporales no cumplen con las condiciones de estacionariedad, media y varianza constante a través del tiempo (Figura 1).
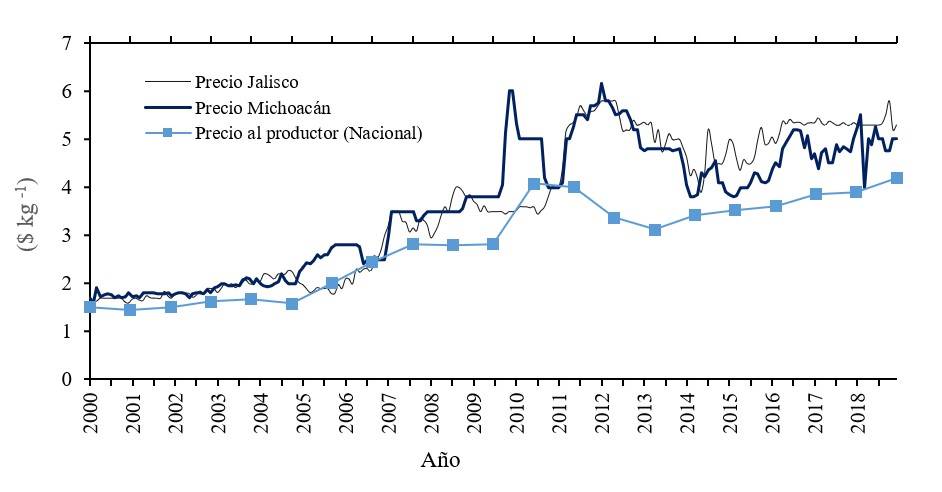
Figura 1. Comportamiento gráfico del precio de maíz blanco en Michoacán y Jalisco en $ kg-1. Elaboración con datos de SNIIM (2018); SIAP (2020).
Las series de precios transformadas en logaritmos tampoco muestran medias y varianzas constantes (Figura 2). En la práctica pueden aplicarse trasformaciones para obtener series estacionarias como son: diferenciación simple o estacional para eliminar la tendencia o inducir estacionariedad en media. Asimismo, se puede realizar una transformación de box-Cox o logaritmo natural para inducir estacionariedad en varianza. Se obtuvo la primera diferencia del logaritmo de las series para inducir estacionariedad en media y varianza (Figura 3).
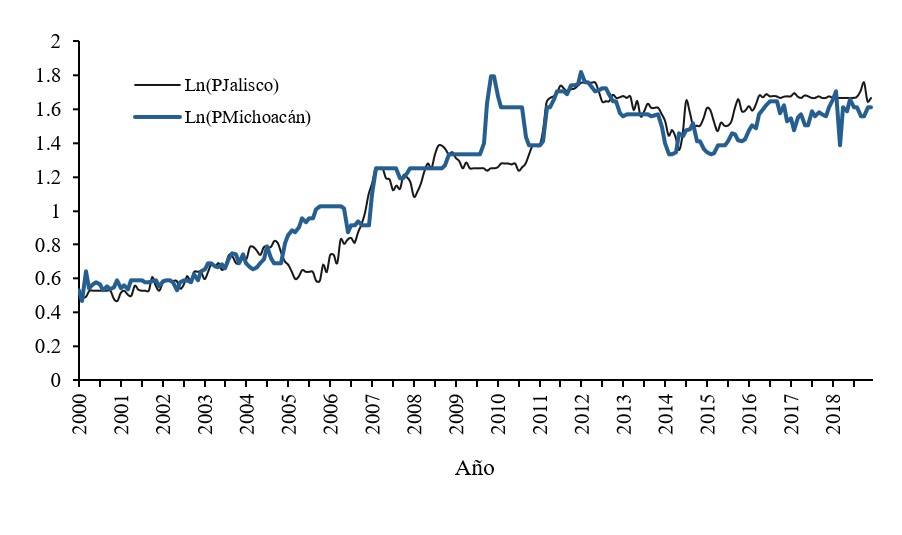
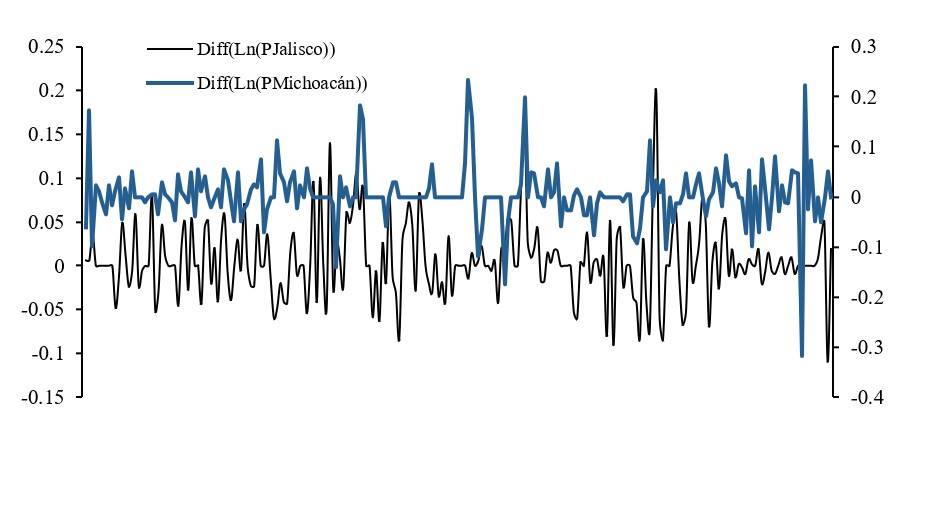
Una forma de comprobar la presencia de raíz unitaria en una serie es mediante un análisis gráfico, si éste presenta tendencia puede ser un indicio de que la media y varianza no son constantes, una alternativa para verificar si la serie es no estacionaria es analizar su correlograma, en un proceso puramente de ruido blanco las autocorrelaciones en distintos rezagos se ubican alrededor del cero, por lo tanto, si las autocorrelaciones disminuyen lentamente puede indicar que la serie es no es estacionaria y finalmente se puede aplicar alguna de las siguientes pruebas: prueba Dickey Fuller Aumentada (DFA) y Phillips Perrón (PP) (Greene, 2012).
Las series analizadas mostraron una disminución lenta de las autocorrelaciones; sin embargo, se realizaron las pruebas de raíz unitaria en las que probó la siguiente hipótesis: H0: las series presentan raíz Unitaria vs H1: la series no presentan raíz Unitaria. Las pruebas de Dickey-Fuller Aumentada (DFA) y Phillips Perron indicaron que ambas series son integradas de orden uno I (1) en niveles, pero son estacionarias mediante transformaciones de logaritmo natural y primera diferencia (Cuadro 1).
Cuadro 1. Prueba de raíz unitaria: Dickey Fuller Aumentada y Phillips Perron.
| Variable | H0: raíz unitaria, H1: no raíz unitaria | Orden de integración | |
| DFA (Pr < Tau) | PP (Pr < Tau) | ||
| Michoacán | 0.7946 | 0.3146 | I (1) |
| Ln(PMichoacán) | 0.7988 | 0.5695 | I(1) |
| ∆Ln(PMichoacán) | <0.0001 | <0.0001 | I(0) |
| Jalisco | 0.4597 | 0.4268 | I (1) |
| Ln(PJalisco) | 0.6396 | 0.6436 | I (1) |
| ∆Ln(PJalisco) | 0.0002 | <0.0001 | I(0) |
*= indica rechazo de la hipótesis nula a un nivel de significancia de 5%; ∆= denota al operador de primeras diferencias; Ln= denota logaritmo natural.
Las funciones de autocorrelación y autocorrelación parcial son útiles en la identificación de modelos; sin embargo, en modelos ARIMA, la especificación del modelo está sujeta a un examen de verificación, diagnóstico y modificación (si es necesario). Algunas herramientas para seleccionar un modelo son: el criterio AIC introducido por Akaike (1974) y el criterio de información bayesiano (BIC) de Schwarz (1978); (Box et al., 2016).
La etapa de identificación de los modelos se realizó siguiendo los pasos sugeridos en la metodología de Box y Jenkins, (Pankratz, 1983). Los valores (p, d y q) se definieron considerando varios modelos mediante la inspección de las funciones de autocorrelación (ACF) y funciones de autocorrelación parcial (PACF) y se estimaron los parámetros autorregresivos AR y de media móvil MA, mediante mínimos cuadrados ordinarios (Cuadro 2).
Cuadro 2. Estimación de los parámetros de modelos ARIMA.
| Serie | Modelo ajustado | Intercepto | Coeficiente estimado | log likelihood | AIC | ||
| AR (1) | MA (1) | MA (2) | |||||
| ∆Ln(PMichoacán) | AR (1) | 0.0051 | -0.0563 | 326.49 | -646.9 | ||
| Ee | -0.0035 | -0.0675 | |||||
| MA (1) | 0.0051 | -0.0493 | 326.44 | -646.89 | |||
| Ee | -0.0035 | -0.0636 | |||||
| ∆Ln(PJalisco) | MA (2) | 0.0054 | 0.0822 | -0.088 | 389.23 | -770.47 | |
| Ee | -0.0028 | -0.067 | -0.0679 | ||||
| MA (1) | 0.0054 | 0.0816 | 388.4 | -770.8 | |||
| Ee | -0.003 | -0.0737 | |||||
Ee= denota error estándar.
Además de observar las correlaciones residuales en los rezagos individuales, es útil tener una prueba que tenga en cuenta sus magnitudes como grupo (Cryer y Sik, 2008). La verificación de autocorrelación en los residuales puede realizarse mediante la estadística de Box y Pierce (1970) o Ljung-Box (1978). Con la prueba Ljung-Box se verificó la no autocorrelación en los residuales (Makridakis et al. 1997) (Cuadro 3), de acuerdo con el p valor ≥ 0.05 asociado a la prueba no se rechazó la hipótesis nula y se concluyó que no existe autocorrelación en los errores. En la etapa de diagnóstico de los modelos, se verificó que los errores tengan un comportamiento de ruido blanco y se comporten como una distribución normal.
Cuadro 3. Prueba Ljung-Box a los residuales de los modelos ARIMA.
| Serie | Modelo ajustado | Ljung-Box test H0: no existe autocorrelación |
| ∆Ln(PMichoacán) | AR (1) | Q*= 20.74, df= 22, p-value= 0.5369 |
| MA (1) | Q*= 20.96, df= 22, p-value= 0.5232 | |
| ∆Ln(PJalisco) | MA (2) | Q*= 18.45, df= 21, p-value= 0.6199 |
| MA (1) | Q*= 21.139, df= 22, p-value= 0.5122 |
Se usaron los modelos construidos para realizar predicciones puntuales fuera de la muestra en cada serie. Se obtuvieron valores predichos de los datos de julio a diciembre de 2018 y se compararon con los datos observados que se habían reservado en el conjunto de ‘validación’ (Cuadro 4).
Cuadro 4. Precios observados y predichos obtenidos a partir de los modelos ARIMA en $ kg-1.
| Modelo | Jalisco | Michoacán | |||||
| MA (2) | MA (1) | Observados | AR (1) | MA (1) | Observados | ||
| Predichos | Predichos | Predichos | Predichos | ||||
| Julio 18 | 5.32874 | 5.326339 | 5.3 | 5.256702 | 5.259425 | 5 | |
| Agosto 18 | 5.359954 | 5.354975 | 5.34 | 5.284727 | 5.286318 | 5 | |
| Septiembre 18 | 5.388794 | 5.383764 | 5.52 | 5.311693 | 5.313348 | 4.75 | |
| Octubre 18 | 5.41779 | 5.412709 | 5.8 | 5.338864 | 5.340516 | 4.75 | |
| Noviembre 18 | 5.446941 | 5.441809 | 5.2 | 5.366171 | 5.367823 | 5 | |
| Diciembre 18 | 5.47625 | 5.471065 | 5.3 | 5.393618 | 5.39527 | 5 | |
Elaboración con datos de SNIIM (2018).
Se utilizaron tres criterios para medir la capacidad predictiva de los modelos: la U de Theil, la raíz del error cuadrático medio (RECM) y el error porcentual absoluto medio (MAPE) (Cuadro 5). Estos han sido empleados para evaluar modelos de predicción en Barreras et al. (2013); Sánchez et al. (2013); Contreras et al. (2016). La U de Theil es una medida entre cero y uno. Se espera que el coeficiente de Theil sea igual a cero, lo que significa que el pronóstico es exacto, si el coeficiente de Theil es igual a uno no está justificado el uso del modelo para realizar predicciones. En los modelos propuestos se obtuvieron valores de U de Theil cercanos a cero, lo que indica que los modelos son útiles para predecir los precios de maíz en seis meses inmediatos siguientes.
Cuadro 5. Criterios de discriminación de modelos.
| Serie | Modelo | U de THEIL | RECM | MAPE |
| ∆Ln(PMichoacán) | AR (1) | 0.04176587* | 1.000933* | 8.37* |
| ∆Ln(PMichoacán) | MA (1) | 0.04192237 | 1.005392 | 8.41 |
| ∆Ln(PJalisco) | MA (2) | 0.01911703* | 0.0169519* | 2.99 |
| ∆Ln(PJalisco) | MA (1) | 0.01914904 | 0.02830746 | 2.96* |
*= modelo con mejor desempeño según los criterios.
En la serie de precios de Michoacán el modelo AR (1) tuvo el menor error porcentual absoluto medio (MAPE) comparado con el modelo MA(1) igual a 8.37, lo que significa que el pronóstico está errado en 8.37%, además, este mismo modelo obtuvo la menor U de Theil igual a 0.04 y la menor raíz del error cuadrático medio (RECM) igual a 1. En la serie de precios de Jalisco el modelo MA (2) tuvo un mejor desempeño en dos de los criterios usados, comparado con el modelo MA(1), la U de Theil y raíz del error cuadrático medio con 0.01 y 0.02 respectivamente. El menor error porcentual absoluto medio para esta serie fue de 2.96, lo que indica que el pronóstico fue erróneo en 2.96%.
Actualmente el precio de maíz amarillo No. 2 de la bolsa de Chicago es tomado como referencia del precio del maíz en México; sin embargo, Ortiz y Montiel (2017) mostraron mediante un análisis de volatilidad estocástica multivariante que el precio de mercado de futuros de maíz no se encuentra fuertemente relacionado con los precios registrados en algunos estados del país. En un análisis comparativo de los precios de maíz en la Bolsa de Chicago y los precios al productor de maíz en México se encontró que estos últimos son más altos; no obstante, se trata de variedades diferentes (amarillo y blanco respectivamente). Al mismo tiempo, los precios de maíz amarillo son afectados por la política agrícola aplicada en Estados Unidos de América, quien se caracteriza por mantener altos subsidios a sus productores y precios de exportación bajos de maíz (SIAP, 2012).
Dados los inconvenientes de tomar el precio del maíz amarillo como estimador del precio de maíz blanco y ante la falta de información sobre el comportamiento futuro de los mercados, los modelos propuestos proporcionan un predictor de los precios de maíz en Jalisco y Michoacán y muestran que éstos pueden ser estimados a partir de sus propios valores pasados, sin embargo, se ha mostrado que los modelos ARIMA tienen un desempeño restringido. Chu (1978) plantea que esta metodología es un mecanismo simple que puede usarse para el pronóstico a corto plazo, pero tiene una capacidad limitada para predecir movimientos inusuales en los precios, aunque, el poder predictivo posiblemente se puede mejorar incorporando otras variables.
Conclusiones
Los resultados muestran que la metodología de Box y Jenkins es útil para pronosticar los precios de maíz blanco en Michoacán y Jalisco, en el corto plazo. Los precios de maíz en Michoacán y Jalisco pueden ser predichos mediante sus propios valores pasados usando modelos AR (1) y MA (2) y estos predictores constituyen una herramienta útil en la toma de decisiones de los productores y comercializadores de productos relacionados con el maíz.

