











 text new page (beta)
text new page (beta) English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink1 Introduction
To create classification models that better generalize the representation of objects in machine learning, Multi-view Learning (MVL) proposes to take advantage of the complementariness of information that can be obtained from different views of the same object combining this representations to characterize it.
Different representations of the same object are called views. According to [3] this is possible considering that the views must be compatible and independent to each other.
MVL has been used in different fields as document analysis [4], behavior recognition [10], image classification [6], among others.
For example, MVL has been shown to be useful to increase the performance of EEG signal classification models for seizure detection [1, 25, 28] and motor imagery [15, 12, 27], this motivated us to apply MVL techniques in other EEG classification problems such as imagined speech and stress pattern recognition which are less explored applications of MVL [13, 14, 18, 22].
This work aims to explore the use of MVL to build more robust classifiers when complementary information that describes a set of objects is available. Specifically, EEG signals can be represented and analyzed in different domains, such as time and frequency.
Two approaches of Multi-view Learning are studied in this paper: Co-training and Co-regularization. The main idea of Co-training is to create separate classifiers for each representation and then combine their results [3].
Co-regularization first combines the different views of the objects to be classified to obtain a single set of characteristics that is used to create a Multi-view classifier [19].
We compare three Co-training style algorithms: Basic Co-training (BCT) based on [24] and we propose two simple variations of it, Simple Co-training (SCT) and Majority Vote Co-training (MVCT).
Also we compare three Co-regularization style algorithms: Concatenation (CC), MULDA [20] and SVM-2K [5].
For Co-training style algorithms we experimented with the combination of four, views, namely, Absolute Power of Theta, Alpha and Beta bands (ABP); Intensity Weighted Mean Frequency (IWMF); Activity, Movility and Complexity Hjorth parameters (HjPa); and Shannon Entropy (ShEn).
Also we experimented with subsets of three and two views, ensuring the combination of time domain features with frequency domain features.
For Co-regularization style algorithms we experiment with the combination of four, three and two views in the CC approach; MULDA and SVM-2k, given the characteristics of the algorithms, were applied on combinations of two views.
All these fusion information techniques were tested and selected through a model we propose for automatic selection of view combination, using the total number of views, then three views and finally two views, based on classification performance.
The results showed that the combination of four views in MVCT algorithm and the fusion of ShEn and IWMF also in MVCT reached the highest accuracy percentages, 95.17% and 94.36% respectively.
These two selected Multi-view learning approaches exceeds the 93% achieved in [21] where the same database is used for stress pattern recognition in EEG signals.
The remainder of this paper is organized as follows: In Section 2, basic concepts on MVL and the two approaches adopted, as well as the implemented algorithms and the model for automatic selection of view combination are presented.
Section 3 provides a brief description of the pattern recognition problems in EEG signals addressed, also the characteristics extracted to obtain different views of EEG are described, and the performed experiments and the results obtained using Co-training and Co-regularization are presented and compared.
Finally, conclusions and future research directions can be found in Section 4.
2 Multi-view Learning
Multi-view Learning (MVL) is a machine learning variant that has its foundation in the work of Blum and Mitchell [3] in which they propose the use of two different views to classify web pages.
Since then, MVL has grown in multiple directions of machine learning. There have been different categorizations for MVL algorithms [19, 26], this work is based in the categories given in [29] focusing on Co-training and Co-regularization.
2.1 Co-training
Co-training was originally proposed to combine labeled and unlabeled data from different views of an object.
This technique has shown that even when there are no naturally different views to describe an object, generating these views and combining them by Co-training can improve the results of other classifiers not using different views [11].
According to [3] there are two principal considerations in Co-training: (i) Each set of features is sufficient for classification, and (ii) the two feature sets of each instance are conditionally independent given the class.
Three different Co-training style algorithms to perform supervised learning were explored to classify EEG signals: Basic Co-training, Simple Co-training, and Majority Vote Co-training, as described below. In all cases we use Random Forest (RF) as base classifier.
2.1.1 Basic Co-training (BCT)
This approach is based on the Agreement Co-training strategy presented in [24].
We train separate RF for each view, we consider the most confident model and used it to label a new example, then this new labeled example is added to the training set of individual models and iterate until there are no more unlabeled (test) objects.
To establish which is the most confident model we use the misclassification probability of each tree in the ensemble (RF). We select the tree with the minimum misclassification probability to label test samples of each view.
2.1.2 Simple Co-training (SCT)
We propose a slight variation of the basic Co-training algorithm. Again, we modeled a different RF for each view. We observed the resulting models and the more confident model was used to classify the whole test dataset.
As in the previous approach, we select the most confident model according to misclassification probability, but in this case, there are not incremental construction of the models.
Each model is trained just once with the corresponding training set, then for each test object the most confident model is used to label it.
2.1.3 Majority Vote Co-training (MVCT)
We propose this approach that has an initial stage as the previous variation presented.
Different RFs are modeled, one for each view, then each model classifies the complete test set through a ten-fold cross validation schema, meanwhile the label assigned to each sample is stored.
Finally stored labels are used to emit a vote, and contrary to the previous approach, test samples are classified according to the most voted class.
2.2 Co-regularization
Co-regularization style algorithms are based on integrating different views into a unified representation.
One simple approach is Concatenating the features of each view and then run a standard classification algorithm.
There are other strategies summarized in [29] like constructing a transformation, linear or non-linear, from the original views to a new representation, or including label information to the transformation to add intraclass and interclass constrains, also combining the data and label information using classifiers with the aim that the results obtained from different views be as consistent as possible.
In this work three methods were applied: Concatenation of characteristics from different views, MULDA [20] that extracts uncorrelated features in each view and computes transformations of each view to project data into a common subspace, and SVM-2K [5] that combines into a single optimization kernel Canonical Correlation Analysis and Support Vector Machine.
2.2.1 Concatenation (CC)
Given Xi and Xj two views of EEG signals, we concatenated them into a single set Xij=[Xi,Xj]. This set is divided into training, validation, and testing subsets to model a RF for classification of EEG signals.
2.2.2 MULDA
The purpose of this method, introduced in [20], is to take advantage of Canonical Correlation Analysis (CCA) and Uncorrelated Linear Discriminant Analysis (ULDA), so that useful features can be exploited for Multi-view applications.
Through optimizing the corresponding objective, discrimination in each view and correlation between two views can be maximized simultaneously.
We apply MULDA given Xi and Xj, two views of EEG signals, the characteristics are combined in correlation matrices, then features containing minimum redundancy are extracted.
The resulting sets of features are divided into training, validation and testing subsets to model a RF for classification of EEG signals.
2.2.3 SVM-2K
In [5], the authors trained a Support Vector Machine (SVM) from each individual view and then regularized the consistencies across different views.
This study takes advantage of kernel Canonical Correlation Analysis (kCCA) to represent the common relevant information from two different correlated views using this as a preprocessing stage to improve performance of a SVM combining them into a single optimization SVM-2K.
We apply the method developed in [5], given Xi and Xj, two views of EEG signals.
2.3 Automatic Selection of View Combination
In this work we have proposed to combine features in the time domain with features in the frequency domain by means of Multi-view learning techniques for the classification of EEG signals, two sets of features were extracted for each domain.
In frequency domain, ABP and IWMF were extracted. In time domain we extracted HjPa and ShEn.
We design a model capable of selecting different subsets of views, ensuring the combination of time and frequency domain features, while evaluating the different MVL techniques explained above.
The model identifies the MVL method and the set of views that achieve the highest accuracy in pattern recognition in EEG signals.
This model is divided in five stages: multidomain feature set generation (S1), selection of a MVL approach (S2), evaluation of the combination of selected views and MVL approach (S3), performance comparison (S4) and finally, identification of views and MVL approach with highest accuracy (S5).
A general description of the proposed model is showed in Fig. 1. In S1 stage a subset of Multi-view features is selected, the views are not combined or fused, they are included as input information for the subsequent stage.
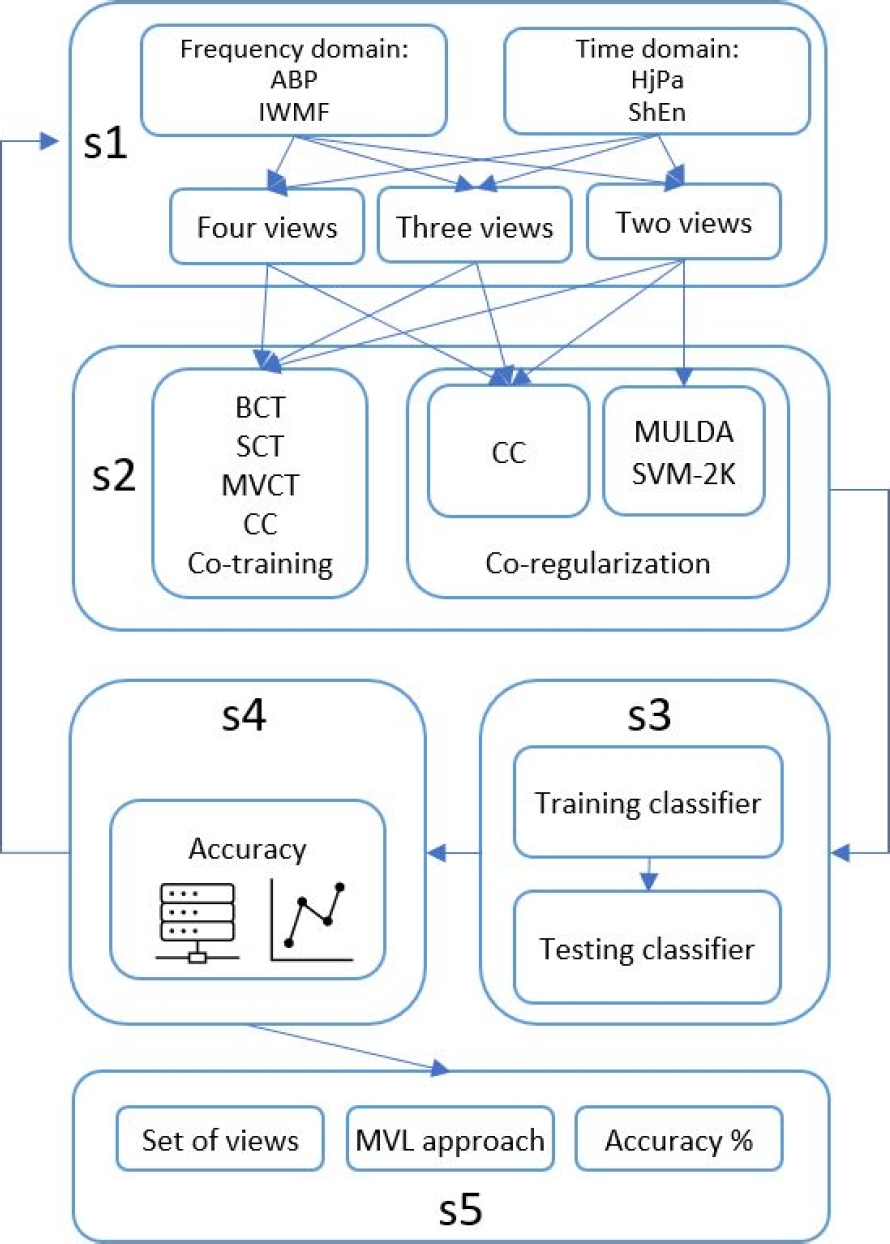
The subsets that this stage generate consist of four views: {ABP, IWMF, HjPa, ShEn}; three views{ABP, IWMF, ShEn}, {ABP, IWMF, HjPa}, {ABP, HjPa, ShEn}, {IWMF, HjPa, ShEn}; and two views: {ABP, HjPa}, {ABP, ShEn}, {IWMF, HjPa}, {IWMF, ShEn}.
Each subset includes the objects (EEG signals), described by the corresponding features and labels to identify the objects. Stage S2 is in charge of selecting a MVL technique compatible with the number of views selected.
Co-training approaches as well as CC Co-regularization technique are able to work with any subset o views generated in previous stage S1. MULDA and SVM-2k given the characteristics of the algorithms, are selected just for subsets of two views.
Stage S3 receives the information from S2 about which MVL technique in going to be applied as well as the combination of views to be used. S3 applies 10-fold cross validation, this stage divides the subset of views in ten random sections, nine of them are taken as train samples and the one that has not been selected is used as the set of test samples, then the MVL algorithm is executed, this process is repeated ten times.
Given that there is no formal rule, we choose to work with 10-fold, taking into account the size of the dataset and avoiding high variance and bias in the classification results. The result of this stage is the classification assigned to the test samples and it is received by S4.
In stage S4 the accuracy of the MVL technique applied to the subset of views is computed. This metric is stored as well as the corresponding subset of views and the MVL approach applied. After this stage the model iterates until all the combinations of views subsets and MVL techniques are tested.
This stage draws a graph to observe the results of each combination of views with the selected multi-view approach. Finally, stage S5 compare all the results stored in stage S4, it is responsible of displaying the findings indicating the MVL approach and the subset of views with higher accuracy.
3 Experiments and Results
The exploration of MVL was motivated as a promissory alternative to achieve better results in classifying imagined speech and in stress pattern recognition. While other machine learning approaches have been applied to the analysis of imagined speech and EEG stress signals [13, 14, 18, 22], MVL is a less explored approach. The experiments performed with imagined speech EEG signals as well as with stress EEG signals are described below.
3.1 Imagined Speech
The first experiment to explore and compare MVL approaches focused on the combination of two views of imagined speech EEG signals. Imagined speech, also known as unspoken speech, is the internal pronunciation or imagined pronunciation of words without making sounds or gestures. The present work uses Electroencephalography (EEG) signals to recognize the imagined pronunciation of words from a reduced vocabulary made up of five words in Spanish language: arriba (up), abajo (down), izquierda (left), derecha (right), and seleccionar (select).
The database used is described in [23] and consists of EEG signals from 27 healthy subjects (S1-S27), two of them are left-handed and the rest are right-handed. For acquiring EEG signals an EMOTIV kit was used.
This is a wireless kit and consists of fourteen channels which frequency sample rate is 128 Hz. According to the international 10-20 system, channels are named: AF3, F7, F3, FC5, T7, P7, O1, O2, P8, T8, FC6, F4, F8 and AF4. Each subject imagined the aforementioned 5 words.
Samples collected included 33 repetitions (epochs) of each word. For each of the 27 subjects there are 165 samples corresponding to 33 samples of each of the 5 imagined words, making a total of 4,455 samples analyzed.
Two representative feature extraction methods were used to generate two different views of the original EEG signals: Average band power and Hjorth parameters.
Each imagined speech sample consist of 14 columns, corresponding to 14 channels of the EEG, for each view 14 features were extracted from each of the signals.
Present work identifies average band power view as view V1-AVP and Activity Hjorth parameter as V2-ACT. MATLAB and EEGLAB toolbox [2] were used to extract characteristics.
For conducting preliminary experiments we used Weka [7] to classify the signals, each view separately, tree classifiers were tested: SVM, Naive Bayes (NB), and RF with 30, 50, 100, 500, 1000 and 5000 trees.
To evaluate the performance of classifiers we observed the percentage of accuracy which is computed as the number of epochs correctly classified divided by the number of epochs presented to the classifier.
The accuracy percentages were obtained by ten-fold cross validation. We discovered that the classifier with higher percentage of accuracy, was RF with 50 trees with Activity as the Hjorth Parameter selected to perform the imagined speech classification.
To explore the different approaches of Co-training and Co-regularization of Multi-view Learning, the discussed methods in Section 2 were implemented in MATLAB. Classification was performed per subject and the results summarized here are the average accuracy computed from the classification accuracy of the 27 subjects.
Regarding Co-training, MVCT is the approach that yields the best results. Within the Co-regularization strategies the approach with the greatest accuracy is SVM-2K.
This algorithm manages to project the characteristics of each view to spaces in which the highest correlation between them is ensured. Fig 2. shows average accuracy results using RF to classify different views independently and the results obtained with different MVL approaches.
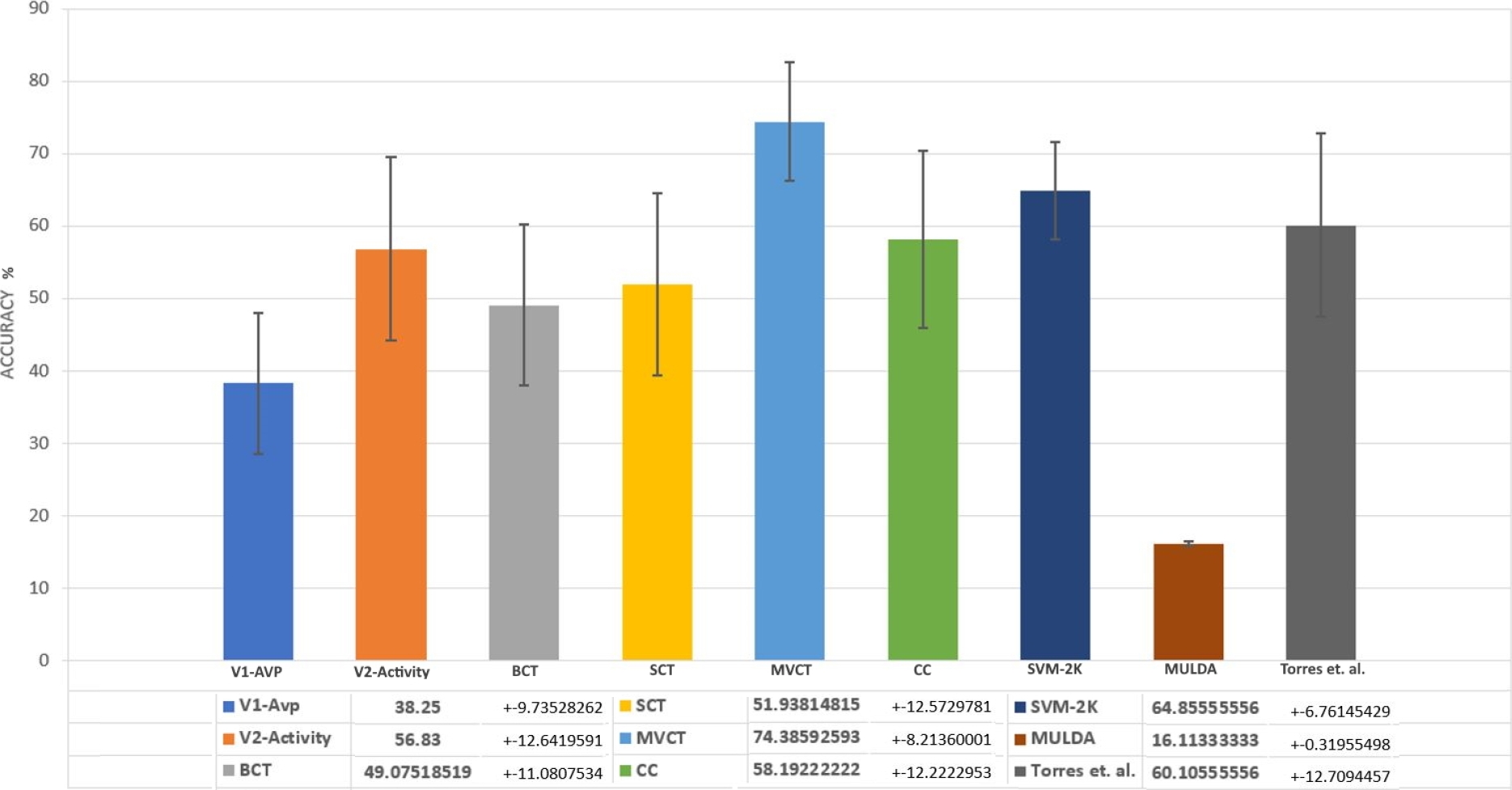
Also, we can see the comparison of MVL approaches explored with results reported in [23], where the same problem of classifying EEG imagined speech signals, using the same data base, is addressed but using a single view.
Over all the experiments with MVL, Majority Vote Co-training is the approach that reaches the highest average accuracy (74.38%), followed by SVM-2K (64.86%).
Results of the paired-t test indicated that there is a significant difference between [23] ( M = 60.1, SD = 12.7 ) and MVCT ( M = 74.4, SD = 8.2 ), t( 27 ) = 5.8, p <.001.
3.2 Stress Pattern Recognition
EEG signals contain relevant information that can be used to represent physiological and pathological states of the human being and in recent years the analysis of academic stress through the study of EEG signals has gained importance.
By being able to determine if an individual experiences stress, it is intuited that it is also possible to distinguish between different levels of stress, and maybe to determine different specific stimuli to help reduce this harmful physiological state.
Studies such as [21] have managed to find a relationship between listening to music and academic stress generated by a cognitive activity, by observing significant changes in the brain waves of students, reaching up to 93% correct classification when distinguishing three stress scenarios.
We worked with a corpus of electroencephalographic signals from 12 participants under different sound stimuli recorded with a commercial EEG headband (Epoc+ from EMOTIV). The signals were acquired with a sampling frequency of 128 Hz.
The channels that record the biosignal in the device used are based on the international 10-20 system; AF3, F7, F3, FC5, T7, P7, O1, O2, P8, T8, FC6, F4, F8 and AF4.
The sampling of this database was carried out in a controlled environment and each subject participated in three sessions: one in total silence, another with relaxing music and another with pleasant music chosen by the subject participating in the session.
In each session, participants are asked to keep their eyes closed for 40 seconds, then open them and do basic multiplication exercises for 5 minutes.
To induce a state of emotional stress, each exercise must be solved within a time limit of less than 5 seconds and if the answer is wrong, the participants get negative feedback. At the end of the mathematical test, the participants close their eyes for another 30 seconds to finish taking the sample.
The objective of the analysis of the EEG signals obtained with these experiments is to determine if it is possible to discriminate these three stress scenarios: Stress while listening to music rated by the participant as pleasant, stress while listening to music identified as relaxing, and stress while in silence.
For details of this database refer to [21]. We took the signal from second 240 to second 300 as this is the segment when the participants are more concentrated on the mathematical task. We worked with 216 samples, 72 samples from each stress scenario.
Features ABP, IWMF, HjPa and ShEn, were extracted from each second of the signal, and then for each 10 seconds of the signal, statistical measures were obtained: average, maximum, standard deviation, variance, skewness, and kurtosis.
As ABP and HjPa include three different measures, Theta, Alpha and Beta bands; Activity, Movility and Complexity; respectively, each sample is represented by 252 characteristics in these two views. Samples have 84 features in IWMF and ShEn views.
Once feature vectors were computed the model discussed in Section 2 was applied. RF with 50 trees was selected as base classifier because the exploratory experiments showed that it was the classifier that achieved highest accuracy.
Table 1 shows an example of part of the values stored in stage S4 of the model. In this table we can see how MVCT with {IWMF, ShEn} set of views is the combination which results achieve the highest accuracy in classification (94.36%).
Table 1 Accuracy % reached with subsets of two views and MVL approches
| MVL | Subset of views | Accuracy % |
| BCT | ABP, HjPa | 92.81 |
| BCT | ABP, ShEn | 85.74 |
| BCT | IWMF, HjPa | 89.23 |
| BCT | IWMF, ShEn | 90.92 |
| SCT | ABP, HjPa | 92.31 |
| SCT | ABP, ShEn | 89.74 |
| SCT | IWMF, HjPa | 85.13 |
| SCT | IWMF, ShEn | 92.31 |
| MVCT | ABP, HjPa | 92.27 |
| MVCT | ABP, ShEn | 92.31 |
| MVCT | IWMF, HjPa | 92.82 |
| MVCT | IWMF, ShEn | 94.36 |
| CC | ABP, HjPa | 74.88 |
| CC | ABP, ShEn | 75.62 |
| CC | IWMF, HjPa | 70.37 |
| CC | IWMF, ShEn | 73.75 |
| MULDA | ABP, HjPa | 60.67 |
| MULDA | ABP, ShEn | 28.57 |
| MULDA | IWMF, HjPa | 44.44 |
| MULDA | IWMF, ShEn | 45.21 |
| SVM-2k | ABP, HjPa | 50.00 |
| SVM-2k | ABP, ShEn | 54.67 |
| SVM-2k | IWMF, HjPa | 50.00 |
| SVM-2k | IWMF, ShEn | 56.28 |
The results with three views for each of the possible subsets are very close to those obtained with two views, in some cases obtaining results with a lower accuracy than with two views.
Fig. 3 shows the graph obtained at the end of stage S4 of the built models where the results obtained with different numbers of views can be quickly compared.

In Table 2 another section of the results stored in stage S4 of the model is showed, in this case, one can see an example of the results achieved by the combination of the four views {ABP, IWMF, HjPa, ShEn} and the MVL approaches.
Table 2 Accuracy percentages achieved using four views
| MVL | Subset of views | Accuracy % |
| BCT | ABP,IWMF,HjPa,ShEn | 89.52 |
| SCT | ABP,IWMF,HjPa,ShEn | 90.94 |
| MVCT | ABP,IWMF,HjPa,ShEn | 95.07 |
| CC | ABP,IWMF,HjPa,ShEn | 80.07 |
Majority Vote Co-training is the Multi-vie learning technique that obtains the higher accuracy. The final stage of our model, S5, showed as output that the best combination of views is ABP, IWMF, HjPa, ShEn and the Multi-view learning approach that achieves the best results is MVCT with 95.07% accuracy in recognizing three different stress patterns.
The classification was made by subject and the results reported here correspond to the average accuracy of the classification obtained for each subject.
Comparing our results with the results achieved by Reyes in [21] it can be observed that the application of MVL is usseful to achieve higher accuracy in discriminating among tree different stress scenarios: Silence, listening to pleasant music and listening to Relaxing music (Table 3).
Table 3 Accuracy % comparison of MVL approach and single view approach in [21]
| Approach | Accuracy % |
| MVCT -{WMF, ShEn} | 94.36 |
| MVCT -{ABP,IWMF,HjPa,ShEn} | 95.07 |
| Single view -[21] | 93 |
To assess the statistical significance of relative performance of different approaches we applied a paired t-test at a significance level of 0.05 to each pair of models.
Results of the paired-t test indicated that there is no significant difference between two views (M = 94.3, SD = 1.1) and four (M = 95, SD = 0.9), t(12) = 1.6, p = .137.
Results of the paired-t test indicated that there is a significant difference between [21] (M = 93, SD = 6) and MVCT with four views (M = 95, SD = 0.9), t(12) = 3.2, p = .008.
Comparing our classification results of three stress scenarios with other works, we observed that classification accuracy is below 90% when data processing aims to detect at least 3 levels of stress [?].
For example, in [16], 3 levels of stress are classified reaching 84.3% of accuracy, in [17], 4 levels of stress are classified reaching 83.43% of accuracy.
Other works like [9, 8] combine multiple characteristics from time domain and frequency domain achieving results of 93.2% and 93.87% accuracy respectively when classifying two stress scenarios.
4 Conclusions and Future Work
Six different Multi-view learning approaches were applied to two different problems in EEG signals, imagined speech and stress pattern recognition, areas of EEG signal classification where, according to our best knowledge, this machine learning approach has been less explored.
In this work, we have proposed to combine features in the time domain with features in the frequency domain using Multi-view learning techniques.
Regarding imagined speech, experiments were performed using two views, the results shown here help to conclude that it is possible to improve classification accuracy of imagined speech by combining the information of the same object extracted from different domains.
Over all the experiments with MVL, Majority Vote Co-training is the approach that reaches the highest average accuracy (74.38%), followed by SVM-2K (64.86%).
Results obtained are competitive when compared with the results reported in [23] where the same database is used to classify imagined speech. Regarding EEG stress signals, two feature sets were extracted from each aforementioned domain.
In order to identify the views and the MVL approach that present the higher performance we have designed a model that, given a set of views, generate subsets of these ensuring the combination of features in frequency domain with features in time domain, to then test the subset of views generated applying six different MVL approaches.
The model is composed of five different stages, the final stage indicates which combination of views and which model of MVL presents the best percentage of accuracy in recognizing patterns of interest in the EEG signal along with the percentage of accuracy achieved.
To recognize 3 different stress states, our automatic selection model indicated that the use of four views and Majority Vote Co-Training is the combination that achieves the highest classification accuracy, 95.07%.
This result improves the accuracy achieved by [21] in which the same database is used to differentiate between three different stress states. For both imagined speech and stress, the Multi-view technique applied that yielded the best results was Majority Vote Co-Training.
According to the data produced by our model, the most appropriate views to represent EEG signals from different stress scenarios are Intensity Weighted Mean Frequency and Shannon Entropy, from frequency domain and time domain respectively.
Given the design of our proposed model, it can be easily adapted to automatically select the most useful views and the most appropriate Multi-view learning techniques to recognize other types of patterns, not only stress patterns in EEG signals. Also, further preprocessing of signals, trying different kernel functions, and different classifiers could lead to more powerful models pattern recognition in EEG signals.
Our main interest is to identify the views and information fusion techniques with the best performance to later transfer this knowledge to more complex models and problems such as the construction of deep learning models for the classification of correlated biosignals.

