











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
The convergence of SMAC technologies begins a new era known as the third computing paradigm [28, 31]. This era resulted in humongous growth of multifarious web services on the internet. These web services are invoked in a variety of applications ranging from social networking sites, mobility-based applications to a sensor-based application such as the Internet of Things, Internet of Vehicles [30], Healthcare Streams [29], etc.
The advent of cloud computing services leads to the further exponential growth of web services that are deployed on cloud platforms. In [27], authors emphasize the role of Information Security Management System (ISMS) standards in handling the security challenges faced by Cloud Service Providers (CSP) during cloud engineering. Web services evaluation in real time on a large-scale is a tedious task. From the user’s point of view, Evaluation of Web services with user-dependent QoS properties are important to find out the optimal choice among them.
The performance of web services in a cloud computing setting has significantly affected by the Quality of Service which in turn depends on various quality factors. These quality factors are categorized into two types of viz. Functional and non-functional performance parameters [24]. The non-functional performance parameter is further subdivided into two groups viz. user-independent and user-dependent. The user-independent parameters, like price and popularity, are not significant in making the recommendation of the web services for users. On the other hand, the user-dependent parameters such as response time, failure probability and throughput play a very crucial role in deciding the choice of the web services which can be a recommendation to the users [2, 8, 46, 51, 52]. Recommendation of appropriate web services is a multi-criteria decision process which makes it a very challenging research problem.
There exist various types of QoS-motivated research-based approaches which are listed in the Related Work section. One of the core challenges faced by cloud service providers is that the delivery of QoS is not made as declared due to the non-functional performance of web services correlated behavior with the invocation time. This is due to the reason that service status usually changes over time. This makes time aware personalized QoS prediction a very crucial research area for high-quality web service recommendation. To the best of our knowledge, none of the existing web service recommendation methods based on neighborhood-based CF considers the service invocation time. This is an important context factor affecting QoS Performance since web service performances usually are affected due to time-varying factors (e.g. service status, network condition, etc.)
To resolve this problem, this study utilized Long Short-Term Memory (LSTM) architecture with two deep learning neural network training options such as adaptive moment estimation [18] (ADAM) and root mean square propagation [26] (RMSProp). The RMSE, MAE, and MAPE are calculated at various Epoch through tuning of hyper parameters.
From a large number of real-world web services QoS values (response time and throughput), data is collected from 142 users who are accessing 4500 web services taken at 64-time slices where each time slice is of 15 minutes.
The experiments are conducted to find the best performing models for the prediction of response time and throughput and LSTM is found to be performing in the best manner. The current work is distributed into five sections. The first section introduces the problem and the related work is discussed in the second section. The third section discusses briefly about the data set and the experimentation. The fourth Section discusses the result and conclusion are given in the last section.
2 Related Work
2.1 Collaborative Filtering (CF)
It is extensively used in commercial recommender systems, such as Netflix and Amazon.com. In [34, 43, 50], CF based on user-item matrix concepts was used for recommendation systems. In [4, 3], the authors proposed a prediction method called empirical analysis for CF. They used several algorithms for predicting values based on correlation-coefficient, vector-based similarity calculation and statistical Bayesian methods. It has been shown that Bayesian networks perform better in terms of correlation-coefficient and vector-based similarity. They also used a ranking system for a product which was based on voting.
UPCC is a user based prediction algorithm using PCC. UPCC is employed to predict a QoS value y for the current time slot, it uses all other collected QoS values at the current time slot for prediction. In [39], the authors proposed a framework of imputation-boosted collaborative filtering (IBCF) using machine learning classifiers to fill-in the sparse user-item matrix, then it runs a traditional Pearson correlation coefficient based CF algorithm for this matrix to predict the rating. They did it by working with classifiers which are good in handling missing data, such as na¨ıve Bayes, by use of predictive mean matching (PMM), with no content information.
They performed a comparative analysis of IBCF with 9 commonly-used machine learning classifiers and an ensemble classifier to impute the missing rating data, in terms of MAE.
2.2 Neighborhood-Based Collaborative Filtering Approach
These methods use correlation coefficients, vector-based similarity calculations, and statistical Bayesian methods. The drawback of Neighborhood-Based CF Approach is that it is vulnerable to data sparsity. In [3, 17] , User-Based methods that utilize historical QoS experience from a group of similar users were used to make QoS predictions. In [7, 32], Item Based methods that uses historical QoS information from similar services were utilized for QoS prediction. In [50, 49], the authors introduces a hybrid approach that combines the user based and service based methods which can achieve a higher QoS prediction accuracy. All the methods often uses the Pearson Correlation Coefficient (PCC) as their similarity models.
In [1], the authors discussed all other similarity computation methods e.g. cosine measure, adjusted cosine measure, constrained PCC, etc. of neighborhood-based CF approach. In [40, 14, 5], Model based CF approaches that incorporates training data to train a predefined model and then utilize that trained model were introduced to predict QoS. The most important model discussed are clustering models, aspect models, and latent factor models.
2.3 Matrix Factorization based Collaborative Filtering Approach
In [10], the authors considered neighborhood information for a Matrix Factorization (MF) based QoS predictor. In [23], the authors proposed an extended MF-based model by considering the location information in each historical QoS record. In [51], the authors proposed an MF-based model that integrates the time interval as an additional factor in an MF process and found that the prediction accuracy was found improving. In [43], the authors investigated the non-negative latent factor model to deal with the sparse QoS matrix subject to the non-negativity constraint. They also introduced Tikhonov regularization to obtain the regularized non-negative latent factor model. In [12], They proposed a method called location-based Hierarchical Matrix Factorization (HMF), which was used to provide service recommendations and makes a cluster of users and services on their location information. They used local matrix factorization and global matrix factorization to predict the missing QoS values. In [42], a general context-sensitive approach that took advantages of both implicit and explicit factors entailed in the QoS data through exploitation of contextual information was presented for collaborative QoS prediction. In [25, 35, 6], the authors discussed location as context information and it was deduced that geographically close users or services usually have similar experiences.
2.4 Service Recommendation System
In [22], the authors explored the use of two main machine learning approaches. Bayesian unsupervised method was utilized to cluster the data into classes and supervised decision tree-based classifier such as C4.5 to model the missing variables. In [8], the authors proposed a novel cloud service, selection through the missing value prediction and multi-attribute trustworthiness evaluation for user support. In [45], Non-negative Tensor Factorization (NTF) algorithm that works on three parameters like a user’s-services-time model was used to predict the missing values of QoS performance and recommend Web services to the users. In [2], neural-network adapter models were used for Web Services response time prediction in cloud environments.
In [48, 53] , the authors combined item and user-based CF algorithms to recommend web services and also integrated Neighbourhood approach through MF. In [44], the authors presented an approach that integrates MF through decision tree learning to bootstrap service recommendation systems. In [6], the authors utilized a region-based CF algorithm web service recommendation. In [21], a comparative study of important seven machine learning algorithms was discussed in the prediction of QoS-values for Web service recommendations. Bagging and SMO-regression were performing well in the case of response time and throughput QoS datasets respectively. In [19], the authors applied an artificial neural network (ANN) approach for missing values imputation.
Bayesian regularization (BR) was giving promising results for both datasets other than two important algorithms such as Levenberg Marquardt and scaled conjugate gradient. In [20], the authors have applied two major types of Meta learners, namely bagging and additive regression with a different combination of base learners for solving the problem of missing value imputation in QoS dataset consisting of response time and throughput values. Random forest algorithm was found performing relatively better than other base learners, for both bagging and additive regression.
2.5 Time Aware Web Service Recommendation System
In [15], the authors proposed a novel time aware approach for QoS Prediction that integrates time information into both the similarity measures. In [16], an improved time aware collaborative filtering approach that uses an applied hybrid personalized random walk to infer indirect user similarities and service similarities was proposed for high-quality QoS Prediction.
In [41], the authors proposed a novel spatial-temporal QoS prediction approach for time-aware Web Service recommendation by using ARIMA as the baseline method.
In [38], the authors used extraction of feature points of QoS sequences and dynamic time warping distance to compute the similarity instead of Euclidean distances for a personalized QoS prediction of dynamic web services. A web service QoS prediction framework WSPred was proposed to provide the time aware personalized QoS values prediction service for different service users in [47].
In [36, 37], authors experimented with econometrics model and wavelet enabled LSTM to explore the working in time aware recommendation systems.
3 Data Set and Experiments
The data set used in the current work is taken from the Web services linked dataset
which was shaped by [2, 8, 46,
51, 52]. They set up a lab called PlanetLabfn to collect these online invocations of Web services by
active users in a cloud environment. The details about the dataset are given in
Table 1. They have generated two
matrices, which contains response time and throughput values of different Web
services for different users and are named as rtmatrix and
tpmatrix. Here an element
4 Results and Discussion
To access the performance of the proposed model, the following error measures are employed as Evaluation Criteria:
In the above formula,
The tuning of hyperparameters is described in Table 2. The result of the experiment is given in the Table 3 and Table 4. It is quite clear from the results that LSTM produces best result for the prediction of response time as well as throughput as compared to the previous approaches as mentioned in Table 5.
Table 2 Hyperparameters of the LSTM
| Hyperparameters | Training Options |
| Hidden Units =200 | Adaptive |
| Dropout layer =0.2 | Moment |
| Gradient Threshold =1 | Estimation |
| Initial Learn Rate =0.005 | (ADAM) |
| Learn Rate Drop Factor = 0.2 | |
| Learn Rate Drop Period =125 | |
| Hidden Units =200 | Root Mean |
| Dropout layer =0.2 | Square |
| Initial Learn Rate =3e-4 | Propagation |
| Squared Gradient Decay =0.99 | (RMSProp) |
| Mini Batch Size =64 |
Table 3 Prediction error of the model at 200 epoch for response time
| Epoch | Model | MAE | RMSE | MAPE |
| 200 | ADAM LSTM (Observed Vs Forecast) |
0.07928 | 0.09711 | 1.65260 |
| 200 | ADAM
LSTM (Observed Vs Predicted) |
0.02382 | 0.03026 | 0.59773 |
| 200 | RMS Optimizer LSTM (Observed Vs Forecast) |
0.76301 | 0.76995 | 33.4842 |
| 200 | RMS Optimizer LSTM (Observed Vs Predicted) |
0.66465 | 0.66988 | 27.9934 |
Table 4 Prediction error of the model at 200 epoch for throughput
| Epoch | Model | MAE | RMSE | MAPE |
| 200 | ADAM LSTM (Observed Vs Forecast) |
0.4792 | 0.7778 | 1.61 |
| 200 | ADAM
LSTM (Observed Vs Predicted) |
0.58402 | 1.0795 | 2.2732 |
| 200 | RMS Optimizer LSTM (Observed Vs Forecast) |
1.388 | 2.7226 | 6.3549 |
| 200 | RMS Optimizer LSTM (Observed Vs Predicted) |
1.4076 | 2.7087 | 7.1559 |
Table 5 Comparison with the previous works
| MAE | RMSE | Reference | |
| WSPred (RT) | 2.1266 | 3.8943 | [47] |
| WSPred (RT) | 6.8558 | 36.572 | [47] |
| AVG at 75 % | 1.159 | 3.206 | [49] |
| UPCC at 75 % | 1.464 | 3.026 | [4, 3] |
| UPCC* at 75 % | 1.242 | 2.763 | [41] |
| IPCC at 75 % | 1.374 | 2.923 | [32] |
| IPCC* at 75 % | 1.202 | 2.717 | [32] |
| WSRec at 75% | 1.372 | 2.923 | [49] |
| WSRec* at 75% | 1.202 | 2.721 | [41] |
| ARIMA | 1.028 | 2.986 | [41] |
| LS, K=1 | 1.006 | 2.774 | [41] |
| 1.102 | 3.062 | [41] | |
| LASSO, K=1 | 0.997 | 2.735 | [41] |
| 0.89 | 2.538 | [41] | |
| RT-0.0635 at 35 % | RT-0.0692 at 35 % | [38] | |
| TP-4.4101 at 40 % | TP-5.1943 at 40 % |
The experiment is conducted with training options ADAM and RMSProp. The experiment is carried out by standardizing the data to avoid the data from diverging and then LSTM network architecture is created to train the LSTM network for forecasting the future time steps.
In case of ADAM as a training option, this is represented in Figure 1 and Figure 5 where the variation of Loss and RMSE can be observed. The Network state with Predicted value and observed values is represented in Figure 2, Figure 3 for response time and Figure 6, Figure 7 for throughput. Figure 4 represents the observed and forecasted throughput.
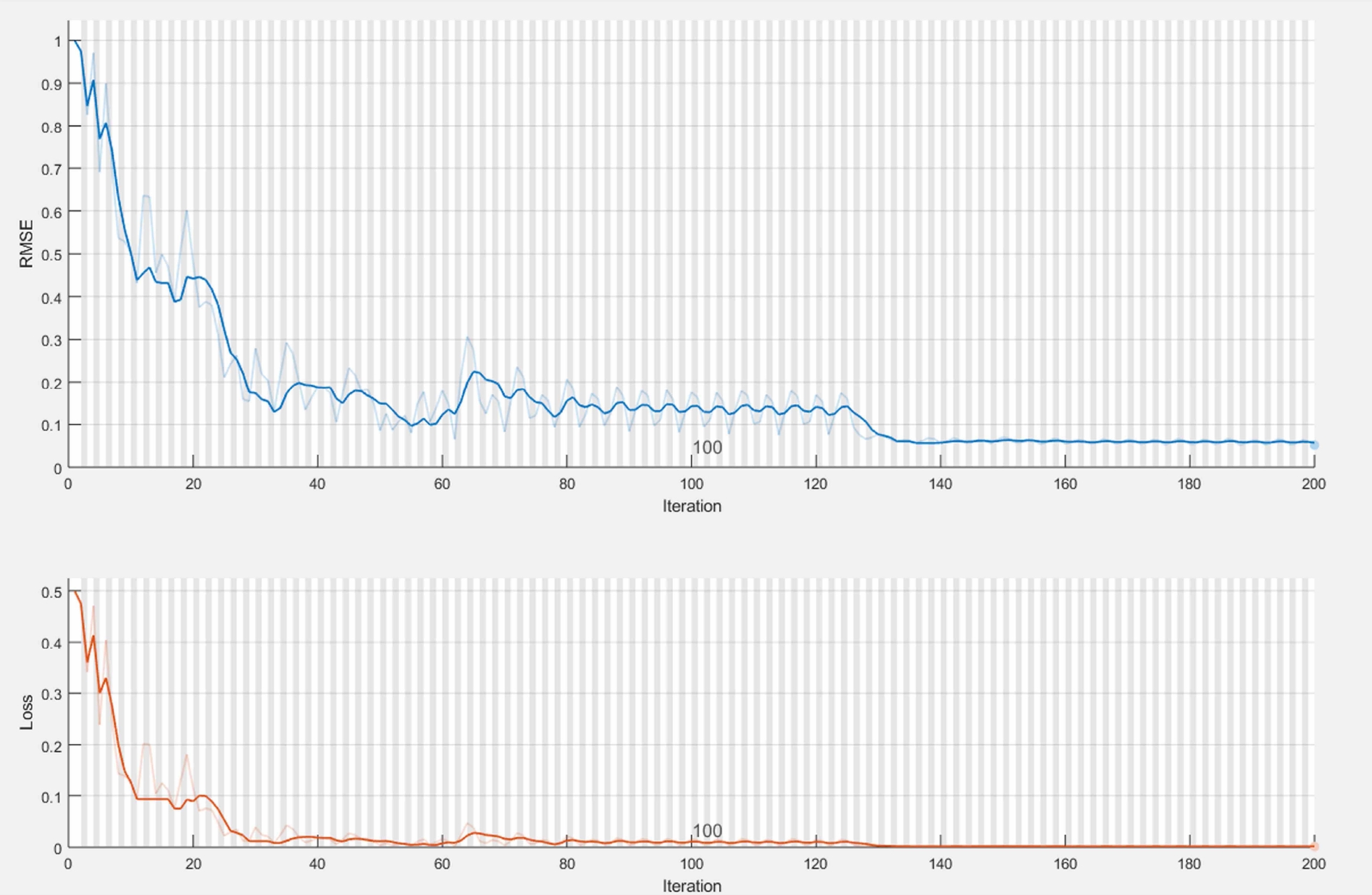
Fig. 1 Variation of Loss and RMSE Observed during Training at Epoch 200 for Response Time for training option ADAM

Fig. 2 Observed Vs Forecasted Cases at Epoch 200 for Response Time and associated RMSE, MAE, and MAPE for training option ADAM

Fig. 3 Observed Vs Predicted Cases at Epoch 200 for Response Time and associated RMSE, MAE, and MAPE for training option ADAM


Fig. 5 Variation of Loss and RMSE Observed during Training at Epoch 200 for Throughput for training option ADAM

Fig. 6 Observed Vs Forecasted Cases at Epoch 200 for Throughput and associated RMSE, MAE, and MAPE for training option ADAM

Fig. 7 Observed Vs Predicted Cases at Epoch 200 for Throughput and associated RMSE, MAE, and MAPE for training option ADAM
In case of RMSProp as a training option, LSTM architecture is represented in Figure 8 and Figure 11 where the variation of Loss and RMSE can be observed. The Network state with Predicted value and observed values is represented in Figure 9, Figure 10 for response time and Figure 12, Figure 13 for throughput.

Fig. 8 Variation of Loss and RMSE Observed during Training at Epoch 200 for Response Time for training option RMSProp

Fig. 9 Observed Vs Forecasted Cases at Epoch 200 for Response Time and associated RMSE, MAE, and MAPE for training option RMSProp

Fig. 10 Observed Vs Predicted Cases at Epoch 200 for Response Time and associated RMSE, MAE, and MAPE for training option RMSProp

Fig. 11 Variation of Loss and RMSE Observed during Training at Epoch 200 for Throughput for training option RMSProp

Fig. 12 Observed Vs Forecasted Cases at Epoch 200 for Throughput and associated RMSE, MAE, and MAPE for training option RMSProp

Fig. 13 Observed Vs Predicted Cases at Epoch 200 for Throughput and associated RMSE, MAE, and MAPE for training option RMSProp
The network state is updated with observed values and found that the predictions are more accurate when updating the network state with the observed values instead of the predicted values.
In case of time series and sequence data, long term dependencies play a crucial role which makes an LSTM [13, 9, 11, 33] a wonderful choice in which layer learns through long-term dependencies in data. There is an additive interaction among the layers which improves the gradient flow very long sequences during training. The state of the layer comprises the hidden state also known as output state and the cell state. The cell state stores the information learned from the past time steps.
Figure 14 elucidates the flow of data at time
step
ENTRA TABLA BORRAR
| Components | Purpose |
| Input gate |
Cell State Update is controlled through this gate. |
| Forget
gate |
Cell State Reset or Forget is controlled here. |
| Cell
candidate |
Information to the cell state is added here. |
| Output gate |
The level of cell state that is added to the hidden state is controlled here. |

The weights that can be learned in an LSTM layer are the input weights W, the
recurrent weights R and the bias b. The concatenated input weights are represented
as matrices
where
The state of the hidden at a given time step
here
The component at a given time
ENTRA TABLA BORRAR
| Component | Formula |
| Input gate | |
| Forget gate | |
| Cell candidate | |
| Output gate |
Here,
5 Conclusions
In the current work, time information is incorporated into web service recommendation for the prediction of QoS parameters namely, response time and throughput accurately. This forms a series which is a kind of nonlinear and non-stationary. Thus, efficient processing of the data is required. Effective preparation and processing strategies should take this nonlinear and non-stationary behavior into account. The effectiveness of the proposed approach is being validated by thorough experiments.
After standardizing the data to avoid the data from diverging, LSTM network architecture is created to train the LSTM network for forecasting the future time steps. The network state is updated with observed values and found that the predictions are more accurate when updating the network state with the observed values instead of the predicted values.
The LSTM gave the best RMSE in case of Response time as 0.030269 with ADAM as the training option and 0.66988 with RMSProp as the training option. In case of throughput, the LSTM gave the best RMSE value as 0.77787 with ADAM as the training option and 2.7087 with RMSProp as the training option.
In future work, context also needs to be explored in time aware web services recommendation through QoS prediction.

