











 text new page (beta)
text new page (beta) English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink1 Introduction
Extractive Text Summarization (ETS), is a task contemplated in Natural Language Processing (NLP), that allows to reduce the textual content of a document or a set of them, this reduction is performed through the selection of a set of most representative units (phrases or sentences), of original text obtained from a method or a computational tool, using supervised and unsupervised learning techniques [1, 2, 7, 15, 30].
Nowadays, the ETS task is one of the most worked in NLP. Since 1958, the first advances has been attributed to the works of Luhn [28], and Edmunson [10]. According to [41], these works has been considered as pioneers of Automatic Text Summarization (ATS), and particularly, ETS. Nevertheless, the most recent advances of ATS were presented through Document Understanding Conferences (DUC), workshops. Since 2001 to 2007, these workshops was organized by the National Institute of Standards and Technology (NIST), [9]. The main products of DUC workshops are the DUC datasets and are mainly used for two tasks: Single-Document Summarization (SDS), and Multi-Document Summarization (MDS), [37]. The first one consists in generate a selection of most important sentences from a single-document text, while the second task consist in generate a selection of the most important sentences of textual content of several documents [21].
In the last years, approximately 268 publications have been reported in the state-of-the-art using the DUC datasets [12]. In the most of these publications have been presented several methods for MDS task, using machine learning techniques through supervised and unsupervised methods [13, 15, 35], clustering-based methods for representing a set of clusters different relationships between sentences [14, 39, 55], algebraic reduction through Non-negative Matrix Factorization (NMF), [23, 24], and Latent Semantic Analysis (LSA), methods [18, 24, 51, 52], text representation with the use of graph-based algorithms [12, 33, 34], the use of optimization methods such as Genetic Algorithms (GA), [3, 17], Memetic Algorithms (MA), [31, 32], Greedy Search (GS), and Dynamic Programming (DP), algorithms [29].
In previous works [26, 27, 41], has been mentioned that one of the main challenges of ETS is to generate automatic extractive summaries that similar to summaries generated by humans (gold-standard summaries). However, for several domains, the gold-standard summaries are made abstracting summaries by substituting some terms and phrases of the original text. For example, in the work of Verma and Lee [49], the gold-standard summaries of DUC01 and DUC02 employ approximately 9% of words not found in the original documents [37]. Consequently, the level of maximum similarity will be less than 100%, and even more, if compared from several gold-standard summaries, the upper bounds will be lower for any ETS method. Therefore, this problem involves the search of the best combinations of sentences of a set of documents that best similarity to gold standard summaries.
For SDS task, some heuristics have been used to compare several commercial tools and state-of-the-art methods with the purpose to comparing the performance of several ETS methods [16, 21, 22]. These heuristics are known as Baseline-first, Baseline-random [21], and in recent works, the use of Topline heuristic has been introduced [43]; in the most recent work [41], these heuristics have been used for calculating the significance of SDS task. However, for MDS has not performed a significant analysis for comparing the best novel state-of-the-art methods, because this task involves a mayor number of possible combinations to represent the best multi-document summary, and therefore for calculating the significant of several state-of-the-art methods requires some variants to the method presented in [41], for finding the best combinations of sentences.
The use of several optimization-based methods in ETS has represented a viable solution to generating extractive summaries of superior performance. These types of techniques include the use of GA, MA and GS methods [17, 29, 31, 32]. Therefore, the use of optimization-based algorithms, represents a viable solution to obtain extractive summaries closest to the human-written summaries. In this paper, a GA is used to obtain the combinations of sentences that best resemble selected by humans using the ROUGE-1.5.5 system and some variants to the method presented in [41], were applied. Furthermore, some meta-document principles were applied to calculating the Topline for MDS.
The rest of the paper is organized as follows: Section 2 present some related works that have used techniques based on exhaustive searches to determine the best combinations of extractive summaries and the calculus of significance for SDS. Section 3 describe the general process of GA. Section 4 describes the structure and development of the proposed GA for calculating the Topline for MDS using a meta-document representation. Section 5 shows the GA experimental configuration to determine the highest performance sentence combinations for calculating the Topline heuristic for DUC01 and DUC02 datasets. Moreover, we present a significant analysis to determine the best novel methods in the state-of-the-art with the use of three heuristics, such as Baseline-first, Baseline-random and Topline. Finally, Section 6 we describe the conclusions and future works.
2 Background and Related Works
Over of the last two decades with the existence of the DUC workshops, many advances have been made in the development of ETS. Several problems have been worked in the ETS, some of them involve the segmentation of sentences [19, 40], and automatic evaluation of summaries [20, 25, 45, 47]. However, to know and determine the best extractive summaries, few studies have been carried out, and some of them use techniques based on exhaustive searches to determine the best combination of sentences that best represent the summaries made by humans [41]. One of the first works was presented by Lin and Hovy [26], in 2003, where they developed a comprehensive search-based method to find the best sentence combinations of a document by taking the first 100±5 and 150±5 words of the DUC01 dataset for SDS task, and evaluating sentence combinations through co-occurrence of bag-of-words of the ROUGE system [25]. Nevertheless, the main drawback that affected the performance of this procedure was exponential increase of the search space that implies the number of sentences of each document. For example, if we use a document of 100 sentences and furthermore inferred that on average each sentence has a length of 20 words, then to find the best extractive summary of 100 words should take the best 5 sentences of the 100 available (
Seven years later, Ceylan [6], presented a similar exhaustive search-based method to obtain the best combinations of sentences in ETS. Unlike the work of Lin and Hovy [26], this method employs a probability density function (pdf), to reduce the number of all possible combinations using some metrics of ROUGE system, with the purpose to be applied from different domains (literary, scientific, journalistic and legal).
As we mentioned in [41], the main problem of this method involves the modification of ROUGE-1.5.5 Perl-based script to process several combinations of sentences in a cluster of computers to distribute the processing of the documents. Furthermore, in the news domain it was necessary to divide the original document in several sub-sections to reduce the processing of documents. The reduction of several combinations involves the discrimination of different possible combinations that can be generated.
In 2017, Wang [54], presented a nine-heuristics-based method to reduce the space of search that involves the combination of sentences for SDS and MDS tasks. This method is based to reduce the number of combination of sentences that present a low relation to gold-standard summaries from SDS and MDS. Subsequently, the remaining sentences are introduced through seven weighting methods to measure the similarity of the sentences in relation to gold-standard summaries. However, the use of several heuristics to determine the best combinations of sentences in different domains and different entries allows the increase of the computational cost to find the best sentence combinations. In addition, for SDS only a single gold-standard summary was used and in the case of MDS only 533 documents of 567 of the DUC02 dataset were used, generating more biased results.
Finally, in 2018 we presented a calculus of significance for SDS task [41]. Using three different heuristics (Baseline-random, Baseline-first and Topline) that represent the lower bounds and upper bounds for ETS, it has been calculated the level of significance of several SDS methods. However, this calculus only was performed for SDS. In this paper, we propose the method based on the use of GAs to find the best combinations of sentences that can be generated from the multi-document summaries of DUC01 and DUC02 datasets and rank the MDS methods.
3 Basic Genetic Algorithm
The GAs [22, 38, 42, 54], is a technique of optimization and iterative, parallel, stochastic search inspired by the principles of natural selection proposed by Darwin in 1859 [8]. The GAs was proposed by John Holland in 1975 as a method that pretends to simulate the actions of nature in a computer to optimize a wide variety of processes [11]. Nowadays, the GA is the most widely used evolutive computing method in optimization problems [44].
A traditional GA is characterized by representing the solution of a problem in individuals, which are represented by variable bit strings and together form a population [4]. A GA begins with a population of
Each individual
From the value obtained as a fitness function, a selection of individuals is performed, where each pair of parents
where the function
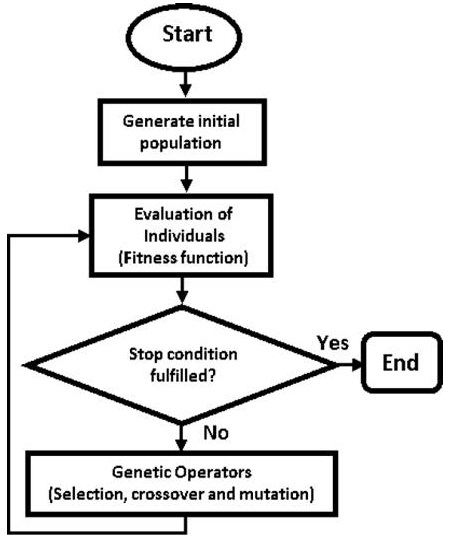
The selection, crossing, and mutation of individuals are iterated until they meet a certain termination criterion, these criteria are based on the number of iterations, the convergence of individuals of a gene, and on a fitness function [22]. In summary, the general process that conducts a GA is presented in Fig. 1 [4, 46].
4 Proposed Method
In general, the proposed method is based on the steps and procedures of the basic GA described in Section 3. The proposed GA evaluates several combinations of sentences in an optimized search space, which are candidates in representing the best extractive summary of one or multiple documents. In this section, the proposed GA is presented.
4.1 Solution Representation
In [41], the solution is presented using a coding of individuals considering the order of sentences that can appear in extractive summary. Therefore, each individual
For each coding to be considered as an extractive summary, the first sentences are considered from a set of words. For example, if we have a document with
Nevertheless, for MDS, the search space involves a mayor number of combinations of sentences due to the increase of sentences from a set of documents.
To represent the sentences of multi-documents we used the same genetic codification through the union of
For each coding to be considered as an extractive summary, the first sentences are selected until they comply a certain number of words as constraint. For example, if we have a set of documents
4.2 Fitness Function
The fitness function is an important stage for the performance of the GA and is the value by which the quality of the summaries is maximized with the passing of (
where
4.3 Population Initialization
The most common strategy for initializing the population (when
where
where
where
In this way, all the set of documents
4.4 Selection
The selection is the GA stage that allows to take a set of individuals
According to [31], if we have
To select the remaining individuals from each generation, we propose to generate new offspring from the tournament selection operator by taking several subsets of
where
4.5 Crossover
For the crossover of individuals, we use the cycle crossover operator (CX). The operator CX has the capacity to generate new offspring from the genetic coding of each pair of parents, considering their hereditary characteristics [11]. For the CX operator to be started, is necessary considering a crossover probability
where
4.6 Mutation
Remembering Eq. (2) of Section 3, the mutation stage takes a set of individuals
where
4.7 Replacement of Individuals
For the replacement of individuals, we propose to integrate the set of individuals generated by elitist selection
5 Experiments and Results
In this section, we present the experiments performed to generate the best extractive summaries by the proposed GA, using DUC01 and DUC02 datasets. Moreover, the performance of some MDS methods and heuristics was presented through a calculus of significance for determine the best MDS methods in the state-of-the-art.
5.1 Datasets
Remembering some ideas from Section 1, the DUC datasets are the most common used for SDS and MDS task researches. In the state-of-the-art, approximately 89 publications in DUC01 and DUC02 has been reported. Due to this, we used DUC01 and DUC02 datasets to calculate the upper bounds for MDS. DUC01 and DUC02 are products of workshops organized by the National Institute of Standards and technology (NIST), for the development of ETS. The documents of these datasets are based on news articles from some agencies such as The Financial Times, The Wall Street Journal, Associated Press and others [36, 37].
DUC01 dataset consist of 309 English documents grouped into 30 collections, each collection contains an average of 10 documents based on news articles addressing natural disaster issues, biographical information, and others [36].
This dataset is divided for two tasks, the first task consists in generate summaries of single-documents with a length of 100 words and these summaries were compared with two gold-standard summaries.
For MDS, consist in generate summaries of multiple newswire/newspaper documents (articles), on a single subject with 50, 100, 200, and 400 words. Moreover, for evaluation step, two abstracts were generated for each collection, generating 60 abstract summaries with the same lengths.
DUC02 dataset consist of 567 news articles in English grouped into 59 collections, each collection contains between 5 and 12 documents dealing with topics of technology, food, politics, finance, among others. Like DUC01, this dataset is mainly used for two tasks, the first is to generate summaries of a document, and each document has one or two gold-standard summaries with a minimum length of 100 words.
For MDS, consist in generate summaries of multiple documents, one and two abstracts were generated as gold-standard summaries for each collection, generating 118 abstracts/extracts with lengths of 10, 50, 100 and 400 words [37]. Table 1 shows the general data for each dataset.
Table 1 Datasets main characteristics
| DUC01 | DUC02 | |
|---|---|---|
| Number of collections | 30 | 59 |
| Number of documents | 309 | 567 |
| Number of gold-standard summaries per collection/document | 2 | 1-2 |
| Multi-document gold-standard extractive/abstractive summaries | 50, 100, 200, 400 abstracts | 10, 50, 100, 200 abstracts 200, 400 extracts |
5.2 Parameters
To determine the upper bounds (Topline), of DUC01 and DUC02, different tests were carried out with some adjustments of parameters with the objective of obtaining the best extractive summaries. Table 2, shows the best tuning parameters applied to GA proposed to calculate the best extractive summaries of multiple documents.
Table 2 GA parameters to calculate Topline of DUC01 and DUC02 for MDS
| Generations | Selection | Crossover | Mutation | |||||
|---|---|---|---|---|---|---|---|---|
| 60 | Elitism | Tournament | CX | Insertion | ||||
|
|
10% |
|
2 |
|
85% |
|
12% | |
The fitness value of each solution is obtained from the n-gram specification to be evaluated by the ROUGE system. In this paper, the unit of evaluation based on the co-occurrence of bag-of-words and bigrams (ROUGE-1 and ROUGE-2), was used, to compare the performance of the most state-of-the-art methods in relation to set of gold-standard summaries [25].
5.3 Comparison to State-of-the-Art Methods and Heuristics
As we have mentioned in Section 1, the importance of knowing the best multi-document extractive summaries consist in determining the Topline from the extractive summaries of several set of documents and calculating the significance of several state-of-the-art methods. In this section, we present a performance comparison of the state-of-the-art methods and their advances with respect to performance obtained from Baseline-first, Baseline-random and Topline heuristics. The methods and heuristics involved in this comparison are the following:
- Baseline-first: It is an heuristic that allows to use the first sentences of an original text according to a length of words to present as a summary to the user [16]. The performance of this heuristic generates good results in the ETS. However, this heuristic must be overcome by state-of-the-art methods [21]. To perform this heuristic in MDS, the summary is generated from the first sentences of each document until the determined number of words is met.
- Baseline-random: It is an heuristic in the state-of-the-art that selects random sentences to present them as an extractive summary to the user [21]. In addition, this heuristic allows us to determine how significant is the performance of ETS methods are in the state-of-the-art [22]. To perform this heuristic in MDS, we generate ten summaries for each set of documents with randomly selected sentences until the number of words is met.
- Topline: It is an heuristic that allows to obtain the maximum value that any state-of-the-art method can achieve due to the lack of concordance between evaluators [43], since it selects sentences considering one or several gold-standard summaries. As mentioned in Section 2, efforts have been made in the state-of-the-art to know the scope of the ETS.
- Ur, Sr, ILP: In the work of [5], several machine regression models has been presented, the method Ur uses a bag-of-words regression with GS-based selection. The method Sr uses a sentence regression method with GS-based selection. Finally, the method Integer Linear Programming (ILP), is implement for MDS. These methods wezre considered as baseline methods.
- R2N2_ILP and R2N2_GA: In [5], a method for ranking the sentences for MDS is proposed. Through a ranking framework upon recursive neural networks (R2N2), based on a hierarchical regression process the most important sentences of each document are selected.
- ClusterCMRW and ClusterHITS: The methods of [55], uses an Cluster-based Conditional Markov Random Walk Model (ClusterCMRW) and the Cluster-based HITS Model (ClusterHITS), to fully leverage the cluster-level information. Through these methods, relationships between sentences in a set of documents are associated.
- LexRank: It is a common stochastic graph-based method to generate extractive summaries through a centrality scoring of sentences. A similarity graph is constructed that provides a better view of important sentences from source text using a centroid approach [12].
- Centroid: In [39], a multi-document summarizer (MEAD) is presented. This method uses a centroid-based algorithm to score each sentence of each document through a linear combination of weights computed using the following features: Centroid based weight, sentence position and first sentence similarity.
- GS, Knapsack and ILP algorithms: In the work of [29] three inference global algorithms are proposed for MDS. Through the GS, Knapsack and ILP algorithms it was performed a study global of performance in MDS. The first is a greedy approximate method, the second a dynamic programming approach based on solutions to the Knapsack problem, and the third is an exact algorithm that uses an Integer Linear Programming formulation problem.
- NMF: The method of [52], uses an NMF to measure the relevance of document-terms and sentence-term matrices to ranks the sentences by their weighted scores.
- FGB: In [52], the clustering-summarization problem is translates into minimizing the Kullback-Leibler divergence between the given documents and model reconstructed terms for MDS.
- BSTM: The BSTM (Bayesian Sentence-based Topic Models), explicitly models the probability distributions of selecting sentences given topics and provides a principled way for the summarization task. BSTM is similar to the FGB summarization since they are all based on sentence-based topic model [53]. The difference is that the document-topic allocation matrix is marginalized out in BSTM.
- FS-NMF: The work of [50], considers a selection of theoretical and empirical features on a document-sentence matrix, and selects the sentences associated with the highest weights to form summaries.
- WFS-NMF-1, WFS-NMF-2: In [50], the NMF model is extended and provides a framework to select sentences with the highest weights to perform extractive summaries.
ClusterCMRW and ClusterHITS methods do not participate in the following comparisons, because in their evaluation stage was performed with a lower version of ROUGE system (ROUGE-1.4.2) and their results can differ of ROUGE-1.5.5 version.
For comparing and reweigh the performance of the methods previously described with the heuristics of the state-of-the-art, we used the evaluation based on the statistical co-occurrence of bag-of-words and bigrams (ROUGE-1 and ROUGE-2), of the ROUGE system [25], using the function of Eq. (13) to establish the performance of each state-of-the-art method respect to the best extractive summaries obtained by the proposed GA:
Table 3, 4 and 5, shows the average results of ROUGE-1 and ROUGE-2 when calculating the Topline for MDS of 30 document sets in DUC01 dataset and 59 document sets in DUC02 dataset using the limit of 50, 100 and 200 words as constraint of GA parameters presented in Table 2. The performance of the state-of-the-art methods are shown in this comparison.
Table 3 Results of ROUGE-1 and ROUGE-2 methods and heuristics on DUC01 and DUC02 for summaries of 100 words (evaluated from abstractive gold-standard summaries)
| DUC01 | DUC02 | |||
|---|---|---|---|---|
| Method | ROUGE-1 | ROUGE-2 | ROUGE-1 | ROUGE-2 |
| Topline | 47.256 | 18.994 | 49.570 | 18.998 |
| R2N2_ILP | 36.910 | 7.870 | 37.960 | 8.880 |
| R2N2_GA | 35.880 | 7.640 | 36.840 | 8.520 |
| Ur | 34.280 | 6.660 | 34.160 | 7.660 |
| Sr | 34.060 | 6.650 | 34.230 | 7.810 |
| Ur+Sr | 33.980 | 6.540 | 35.130 | 8.020 |
| LexRank | 33.220 | 5.760 | 35.090 | 7.510 |
| Baseline-first | 31.716 | 6.962 | 33.385 | 7.042 |
| Baseline-random | 26.994 | 3.277 | 28.637 | 3.798 |
Table 4 Results of ROUGE-1 and ROUGE-2 methods and heuristics on DUC02 for summaries of 200 words (evaluated from extractive gold-standard summaries)
| DUC02 | ||
|---|---|---|
| Method | ROUGE-1 | ROUGE-2 |
| Topline | 75.163 | 66.512 |
| Baseline-first | 50.726 | 26.979 |
| Centroid | 45.379 | 19.181 |
| LexRank | 47.963 | 22.949 |
| NMF | 44.587 | 16.280 |
| FGB | 48.507 | 24.103 |
| BSTM | 48.812 | 24.571 |
| FS-NMF | 49.300 | 24.900 |
| WFS-NMF-1 | 49.900 | 25.800 |
| WFS-NMF-2 | 49.100 | 25.200 |
| Baseline-random | 38.742 | 9.528 |
Table 5 Results of ROUGE-1 and ROUGE-2 methods and heuristics on DUC02 for summaries of 50, 100 and 200 words (evaluated from abstractive gold-standard summaries)
| DUC02 | ||||||
|---|---|---|---|---|---|---|
| 50 words abstracts | 100 words abstracts | 200 words abstracts | ||||
| Method | ROUGE-1 | ROUGE-2 | ROUGE-1 | ROUGE-2 | ROUGE-1 | ROUGE-2 |
| Topline | 42.967 | 16.084 | 49.570 | 18.998 | 56.120 | 23.682 |
| ILP | 28.100 | 5.800 | 34.600 | 7.200 | 41.500 | 10.300 |
| Knapsack | 27.900 | 5.900 | 34.800 | 7.300 | 41.200 | 10.000 |
| Baseline-first | 26.939 | 5.241 | 33.385 | 7.042 | 41.118 | 10.362 |
| GS | 26.800 | 5.100 | 33.500 | 6.900 | 40.100 | 9.500 |
| Baseline-random | 21.599 | 2.298 | 28.637 | 3.798 | 36.074 | 6.308 |
According to the results presented in Tables 3, 4 and 5, Topline performance is substantially distant from other state-of-the-art methods, as mentioned by [43]. For DUC01 with 100 words, Topline obtained a performance equivalent to 47.256 with ROUGE-1 and 18.994 with ROUGE-2, while the best state-of-the-art method is R2N2_ILP obtaining 7.870 with ROUGE-2. For DUC02 with 100 words, Topline obtained a performance equivalent to 49.570 with ROUGE-1 and 18.998 with ROUGE-2, in the same way, R2N2_ILP is the best state-of-the-art method obtaining 37.960 with ROUGE-1 8.880 with ROUGE- 2 (see Table 3).
For DUC02 with 200 words, Topline obtained a performance equivalent to 75.163 with ROUGE-1 and 66.512 with ROUGE-2, while the best state-of-the-art method is WFS-NMF-1 obtaining 49.900 with ROUGE-1 and 25.800 with ROUGE-2. Moreover, the heuristic Baseline-first outperforms all state-of-the-art methods (see Table 4).
For DUC02, Topline obtained a performance equivalent to 42.967 with ROUGE-1 and 16.084 with ROUGE-2 for summaries in 50 words. For summaries in 100 words, Topline obtained a performance equivalent to 49.570 with ROUGE-1 and 18.998 with ROUGE-2. For summaries in 200 words, Topline obtained a performance equivalent to 56.120 with ROUGE-1 and 23.682 with ROUGE-2. The best state-of-the-art methods are the methods ILP obtaining 28.100 with ROUGE-1 in 50 words, 41.500 with ROUGE-1 and 10.300 with ROUGE-2 in 200 words. The method based of in the Knapsack problem obtained 5.900 with ROUGE-2 in 50 words, 34.800 with ROUGE-1 and 7.300 with ROUGE-2 for summaries in 100 words. Furthermore, the Baseline-first heuristic outperform to the GS-based method in several scores (see Table 5).
A comparison of the level of advance of the most recent state-of-the-art methods is shown in Tables 6, 7 and 8. To determine this performance, we use the Eq. (14) based on the premise that the performance of Topline heuristic is 100% and Baseline-random is 0%.
where
The best state-of-the-art method from the Table 6 presents an advance equivalent to 48.94% for ROUGE-1 and 29.22% for ROUGE-2 in DUC01, and DUC02 presents an advance equivalent to 44.54% for ROUGE-1 and 33.43% for ROUGE-2 for summaries of 100 words. Therefore, it follows that for the development of the MDS task there is 51.06% for ROUGE-1 and 70.78% for ROUGE-2 in DUC01, and 55.46% for ROUGE-1 and 66.57% for ROUGE-2 in DUC02 to be explored in summaries of 100 words. In the other hand, it is observed that the performance of Baseline-first heuristic is overcome by all state-of-the-art methods (see Table 6).
Table 6 Ranking of state-of-the-art methods and heuristics on DUC01 and DUC02 for summaries of 100 words
| DUC01 | DUC02 | |||
|---|---|---|---|---|
| Method | ROUGE-1 | ROUGE-2 | ROUGE-1 | ROUGE-2 |
| Topline | 100% | 100% | 100% | 100% |
| R2N2_ILP | 48.94% | 29.22% | 44.54% | 33.43% |
| R2N2_GA | 43.86% | 27.76% | 39.19% | 31.07% |
| Ur | 35.96% | 21.52% | 26.38% | 25.41% |
| Sr | 34.87% | 21.46% | 26.72% | 26.39% |
| Ur+Sr | 34.48% | 20.76% | 31.02% | 27.78% |
| LexRank | 30.73% | 15.80% | 30.83% | 24.42% |
| Baseline-first | 23.30% | 23.45% | 22.68% | 21.34% |
| Baseline-random | 0% | 0% | 0% | 0% |
The best state-of-the-art methods present an advance equivalent to 30.64% for ROUGE-1 and 28.56% for ROUGE-2 (see Table 7). Therefore, it follows that for the development of the MDS task in summaries of 200 words, there is a 69.36% for ROUGE-1 and 71.44% for ROUGE-2 to be explored. In the other hand, the performance of Baseline-first heuristic is outperforming to best state-of-the-art method with 32.90% for ROUGE-1 and 30.62% for ROUGE-2.
Table 7 Ranking of state-of-the-art methods and heuristics on DUC02 for summaries in 200 words
| DUC02 | ||
|---|---|---|
| Method | ROUGE-1 | ROUGE-2 |
| Topline | 100% | 100% |
| Baseline-first | 32.90% | 30.62% |
| Centroid | 18.22% | 16.94% |
| LexRank | 25.32% | 23.55% |
| NMF | 16.05% | 11.85% |
| FGB | 26.81% | 25.58% |
| BSTM | 27.65% | 26.40% |
| FS-NMF | 28.99% | 26.98% |
| WFS-NMF-1 | 30.64% | 28.56% |
| WFS-NMF-2 | 28.44% | 27.50% |
| Baseline-random | 0% | 0% |
For summaries of 50, 100 and 200 words, the best state-of-the-art methods were ILP-based method with a percentage equivalent to 30.42% for ROUGE-1 (50 words), 27.07% for ROUGE-1 and 22.98% for ROUGE-2 (200 words), while the Knapsack problem-based method obtained a percentage equivalent to 26.13% for ROUGE-1 (50 words), 29.44% for ROUGE-1 and 23.04% for ROUGE-2 (100 words), (see Table 8). In general, the best state-of-the-art methods presents an average percent of advance equivalent to 28.97% for ROUGE-1 and 24.05% for ROUGE-2. Therefore, it follows that for the development of the MDS task in summaries of 50, 100 and 200 words in DUC02, there is an average 71.03% for ROUGE-1 and 75.95% for ROUGE-2 to be explored. In the other hand, the performance of GS-based method is closer than Baseline-first in several ROUGE metrics.
Table 8 Ranking of state-of-the-art methods and heuristics on DUC02 for summaries in 50, 100 and 200 words
| DUC02 | ||||||
|---|---|---|---|---|---|---|
| 50 words abstracts | 100 words abstracts | 200 words abstracts | ||||
| Method | ROUGE-1 | ROUGE-2 | ROUGE-1 | ROUGE-2 | ROUGE-1 | ROUGE-2 |
| Topline | 100% | 100% | 100% | 100% | 100% | 100% |
| ILP | 30.42% | 25.40% | 28.49% | 22.38% | 27.07% | 22.98% |
| Knapsack | 29.49% | 26.13% | 29.44% | 23.04% | 25.57% | 21.25% |
| Baseline-first | 24.99% | 21.35% | 22.68% | 21.34% | 25.16% | 23.33% |
| GS | 24.34% | 20.33% | 23.23% | 20.41% | 20.08% | 18.37% |
| Baseline-random | 0% | 0% | 0% | 0% | 0% | 0% |
6 Conclusions and Future Works
In previous works, the upper bounds for SDS and MDS has been calculated on exhaustive search-based methods to obtain the best extractive summaries. However, determine the best extractive summaries through this method was inadequate and expensive due to increase of documents and sentences. In this paper, we propose the use of GAs for calculating the upper bounds (Topline heuristic), to reweigh the performance of MDS methods.
Some GA operators were used to obtain the best extractive summaries. In the fitness function stage, it was proposed to use ROUGE-N method of ROUGE-1.5.5 system to evaluate the quality of GA combinations. Through ROUGE-N, we obtained several patterns features from gold-standard summaries.
In the state-of-the-art, the maximum possible performance value of MDS in DUC01 and DUC02 were unknown. However, it was possible to approximate the performance of the best extractive summaries with the use of GAs, to know the scope of MDS methods. In the other hand, we propose identifying several patterns of sentence features obtained from the best sentence combinations through supervised and unsupervised machine learning models to improve the performance of MDS methods.
In general, the best state-of-the-art methods (reported in Table 6, 7 and 8), are R2N2_ILP, R2N2_GA, WFS-NMF-1, ILP and Knapsack in different metrics. However, it was not possible perform a ranking of all state-of-the-art methods because several methods were not implemented in different subsets of documents of DUC01 and DUC02 datasets. In the other hand, the performance of Baseline-first is overcome in several subsets of documents (see Table 6 and 8), except for summaries in 200 words (from DUC02).
With the new reweight of MDS methods (reported in Table 6, 7 and 8), it was possible to determine the advance percentages of the best state-of-the-art methods. In several subsets of documents (see Table 6, 7 and 8), it is observed that the percentage of significance is much closer to several methods of the state-of-the-art, so it will be very important to analyze the quality of the summaries generated by means of a Turing test, to demonstrate if the level of achieved performance of extractive summaries is confounded with summaries created by humans. Finally, we propose the use of GA-based method for calculating the upper bounds in several languages for determining the ranking of significance for several multilingual ETS methods.

