











 text new page (beta)
text new page (beta) English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink1 Introduction
Short text classification plays an import role in natural language processing. It has a wide range of applications, including SMS spam filtering, sentiment analysis and question answering etc. The task can be defined as follows: given a set of input texts T and a set of classes (or labels) L, the goal is to find some appropriate methods to assign a value from the set of L to each text in T. Many approaches have been proposed to classify short text, such as Naive Bayes (NB), Support Vector Machine (SVM), SVM with NB features (NBSVM), Latent Dirichlet Allocation (LDA). In recent years, Artificial Neural Networks (ANNs) also have shown promising results, including Convolutional Neural Networks (CNNs) [7, 8], Recursive Neural Networks (RecNNs) [15], Recurrent Neural Networks (RNNs) [12] and other variants [9].
However, above methods have been developed primarily for western language (e.g. English) datasets. In English text, there is a blank space between two words. And yet Chinese words are written next to each other without a delimiter between them, we should conduct word segmentation on the Chinese short text firstly. Furthermore, errors caused by Chinese Word Segmentation (CWS) will be propagated to the subsequent tasks and reduce their performance.
From the perspective of semantic analysis, words and characters are significant to short text classification. That is to say, several words or characters may determine the class of a short text. For example, in news titles the words “体 育(sport)”, “足 球(football)”, “篮 球(basketball)” occur relatively frequently in sports, and the words “电脑(computer)”, “编程语言(program language)” and “硬 盘(hard disk)” are relatively unique for information technology. And similarly, in online product comments the characters “好(good)”, “坏(bad)” and “赞(awesome)” may show the sentiment directly. Inspired by the recent success of attention mechanism on many NLP tasks, such as neural machine translation [1] and document classification [17], we explore an end-to-end approach with attention-based neural networks to locate the key words and characters for Chinese short text classification.
The main contribution of this paper is a novel neural architecture, Hybrid Attention Networks (HANs), which is aimed to provide two insights into which characters or words contribute to the classification decision on Chinese short texts. Firstly, since Chinese short texts are composed of words or characters, we build representations based on RNN and CNN for each sentence with words and characters embeddings respectively, then concatenate them into a sentence representation. Secondly, it can be observed that there is typically a salient set of characters and words that signal each sentence class. Furthermore, the same word or character may be differentially important in different sentences.
Considering this sensitivity, our model introduces two attentive mechanisms with context, that is, character- and word-level attentions, which are designed to pay more or less attention to distinctive characters or words when constructing the character- and word-level representations of the sentence, and then concatenate these two-level attention models into an attentive representation of the sentence. Experimental results show that our model outperforms multiple baselines on one 32-class and two 5-class data sets.
The remainder of this paper is organized as follows: Section 2 briefly introduces the works related to this study. Section 3 describes the HANs model in detail. Experimental results and discussion are reported in Section 4. Section 5 concludes this paper.
2 Related Work
In general, a short text only contains several to dozens of words (e.g. the length of a mobile message is limited to 140 characters), it cannot provide enough word co-occurrences that are very important to those learning methods for normal documents. Due to data sparseness, traditional classification methods that depend on the word frequency or enough word co-occurrences, such as Naive Bayes (NB), Maximum Entropy (ME), K Nearest Neighbors (KNN) and Support Vector Machines (SVMs), usually fail to obtain satisfied performance. Hence some improved methods for short text classification appeared, such as sematic analysis, semi-supervised and ensemble models for short text classification [16].
Zelikovitz et al. [18] applied semantic analysis with Latent Semantic Indexing (LSI) to classify short text.
Chen et al. [3] put forward a solution to integrate the topics of multi-granularity, which can model the semantic of short texts more precisely.
Cabrera et al. [2] proposed a semi-supervised short text classification method, Distributional Term Representations (DTRs), which enriched document representations based on contextual information that overcame the small-length and high-sparseness short text to some extent.
Feng et al. [4] introduced an ensemble learning method, which directly measured the correlation between a short text instance and a domain instead of representing short texts as vectors of weights and outperformed the baselines based on Vector Space Model (VSM).
In recent years, many methods based on neural networks have been applied to classify text, in which distributed word representations (i.e. word embedding) [14] have been typically used as inputs to neural network models.
Socher et al. [15] introduced a Recursive Neural Network model using Matrix Vector (MV-RNN), which learned compositional vector representations for phrases and sentences with variable length.
Le and Mikolov [10] proposed paragraph vector to learn fixed-length feature representations from variable-length pieces of texts, such as sentences, paragraphs and documents.
Kalchbrenner et al. [7] put forward Dynamic Convolutional Neural Network (DCNN) to model sentences of varying length, which used dynamic k-max pooling to explicitly capture short and long-range relations without relying on a parse tree.
Then Kim [8] proposed a simple CNN with two channels of word vectors which allow the using of dynamic-updated and static word embeddings simultaneously.
Liu et al. [12] introduced a Multi-Timescale Long Short-Term Memory (MT-LSTM) neural network to model short or long texts.
For Chinese text classification, Lai et al. [9] proposed a Recurrent Convolutional Neural Network (RCNN) and applied it to the task of text classification on Chinese long documents.
Zhang et al. [19] proposed the use of character-level Convolutional Networks (ConvNets) for text classification on Chinese news corpus.
Li et al. [11] developed two component-enhanced Chinese character embedding models and their bi-gram extensions for text classification on Chinese news titles.
More recently, there have been research efforts to incorporate attention mechanisms into CNNs or RNNs that are typically used in NLP applications. Bahdanau et al. [1] applied attention based model to machine translation, which allowed the decoder to watch different parts of the source sentence at each step of the output generation rather than to encode the full source sentence into a fixed-length vector, and explicitly find a soft alignment between the current position and the input source.
Since then, attention mechanisms are further used. Zhang et al. [20] proposed attention pooling based Convolutional Neural Network (CNN) to represent sentences, which used an intermediate sentence representation generated by the Bidirectional Long Short-Term Memory (BLSTM) as a reference for local representations produced by the convolutional layer to obtain attention weights.
Yang et al. [17] contributed to designing the Hierarchical Attention Network (HAN) for document classification, which has two levels of attention mechanisms applied at the word and sentence level. Of these our model is most closely related to the HAN model, which represents English documents with hierarchical attention mechanism. While we use the combination of character- and word-level attentions to represent Chinese short texts.
In this paper, we design a novel method to detect salient characters and words for separating the texts from different classes.
3 Model
Our model comprises four parts: embedding layer, attention layer, representation layer and classification layer. The overall architecture of the Hybrid Attention Networks (HANs) is shown in Fig. 1. We describe the model in details as follows.
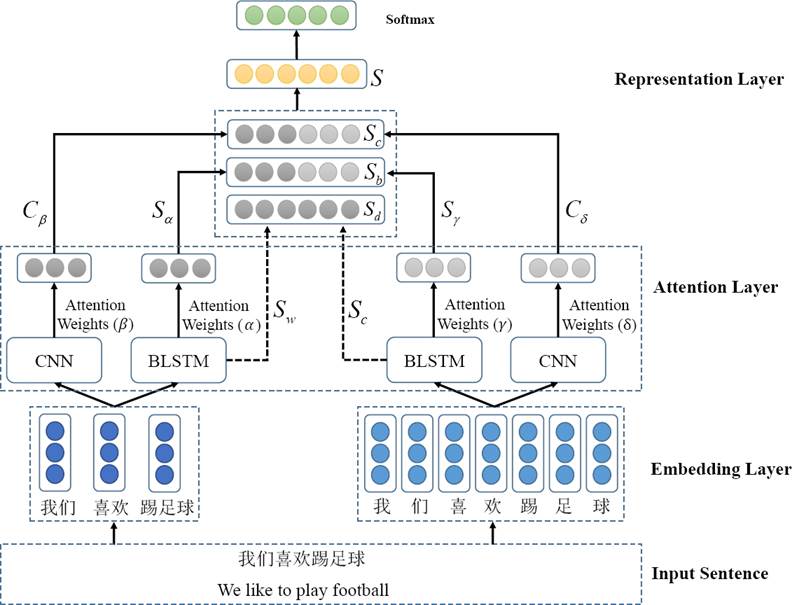
Fig. 1 The architecture of the hybrid attention networks, where α, β, γ, δ are the weights given by word- and character-level attentions, and S, C indicate the representation of the input short text respectively
3.1 Short Text Representation
In this work, we apply RNN and CNN to learn Chinese short text representation with the sequences of words and characters respectively.
3.1.1 LSTM-based Representation
The key idea behind RNN is to make use of sequential information. It can map input texts of arbitrary length into fixed size vectors by recursively outputting hidden state vectors ht that being depended on the previous computations. And yet traditional RNN suffers from the problem of exploding or vanishing gradient, where the gradient vectors can grow or decay exponentially as they propagate to earlier time steps. Consequently, it is difficult to train vanilla RNN to capture long distance dependencies in a sequence. To address this problem, Hochreiter and Schmidhuber [5] proposed the Long Short- Term Memory (LSTM) that is a special type of RNN, which introduced a memory cell (ct) and three gates (i.e. input gate it, forget gate ft and output gate ot) to control how the information flows through the network.
However, standard LSTM networks process sequences in temporal order, which cannot capture semantic dependency from future context when predicting the semantic meaning in the beginning or middle of an input text.
Bidirectional LSTM offers an effective way that can access both the preceding and succeeding contexts by involving two separate hidden layers, i.e. one is forward LSTM and the other is backward LSTM.
Therefore the model is able to capture both past and future contextual information. In the model, an input short text sequence is fed into the forward LSTM layer and the reverse of the input sequence is fed into the backward LSTM layer.
At each time step t, the hidden state of the bidirectional LSTM is the
concatenation of the forward and backward hidden states (i.e.
 and
and
 ).
).
A given Chinese short text is a sequence of words or characters, hence we use LSTM/BLSTM to learn representation for each text with word and character embeddings respectively.
In Fig. 1, the BLSTM component can be substituted by LSTM.
3.1.2 CNN-based Representation
A standard CNN is usually made up of several convolutional and pooling layers. In this work, we design a CNN model with a single convolution layer and an attention-based pooling layer. Using a filter Wc ∈ Rh×d, a convolution operation on h consecutive word or character vectors starting from ith that is a concatenation vector Xi:i+h−1, which represents a slide window with h words or characters, outputs features for the input texts in the window by the following Eq. (1), where Xi ∈ Rd is the word or character embedding, bc ∈ R is a bias, d is the dimension of embedding vector and m is the number of the filters. The operator · stands for the dot product and Relu(·) is the element-wise rectified linear unit function:
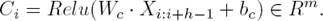 (1)
(1)
We use m different filters to perform convolution operation, and denote the resulting feature set for each window as C. Given the number of words or characters in a Chinese short text is l. For the output length of the convolution layer is equal to the input length, we set the border mode of convolution as ‘same’. Hence the C can be defined by Eq. (2). Then the features in C are fed into the attention-based pooling layer to obtain the short text representation:
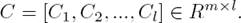 (2)
(2)
3.2 Hybrid Attention Networks
The idea of attention is inspired by the observation that not all words or characters contribute equally to the representation of the sentence meaning. When reading one sentence, people usually can roughly form an intuition about which parts of the sentence (i.e. several words or characters) are more important. And we implement this idea using attention mechanism in our model from two levels, namely word- and character-level attentions.
3.2.1 Word-level Attention
We design a word-level attention mechanism to focus on the words which have closer semantic relationship to the sentence meaning. Word-level attention architecture is applied to the feature representations of LSTM/BLSTM and CNN. These representations are concatenated together as output of the attention layer.
Attention-based LSTM/BLSTM: Suppose the LSTM layer produces the output vectors [h1, h1, ..., hl]. Then the new representation Sα of a Chinese short text is computed by an attention-weighted sum of these output vectors, which is defined as Eq. (3), where αi ∈ R, stands for the attention weight, just as the Eq. (4) and (5) demonstrate:
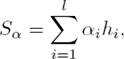 (3)
(3)
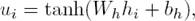 (4)
(4)
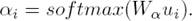 (5)
(5)
According to the formulas described above, in our model, we use attention mechanism to get the new representation  and
and  for the output of forward and backward LSTM respectively, and obtain the attentive representation Sα of the BLSTM layer by summing and .
for the output of forward and backward LSTM respectively, and obtain the attentive representation Sα of the BLSTM layer by summing and .
Fig. 2 describes the architecture of the attention-based BLSTM. By this means, our model can capture as many salient words from both directions as possible.
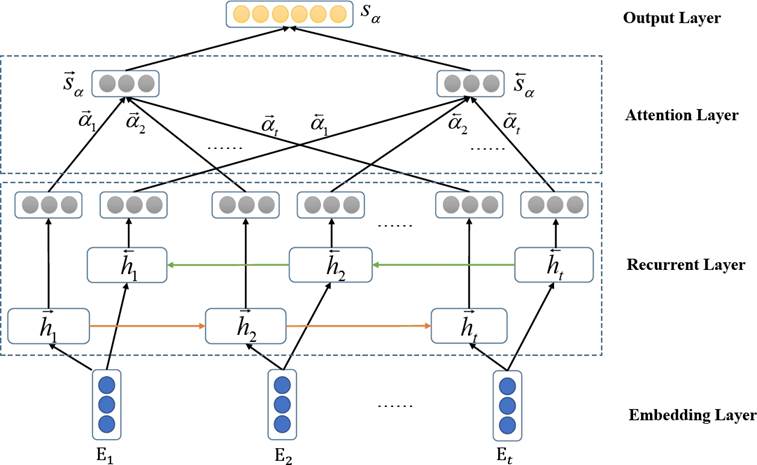
Attention-based CNN: Given the vectors [C1, C2, ..., Cl] are the output of the convolution layer. Just as the attention-based LSTM/BLSTM, we first feed the convolution feature Ci into a tanh layer to get vi as a hidden representation of Ci, and get the attention weight βi that determines the informative convolution features through a softmax function. After that, we compute the pooling vector Cβ by a weighted sum of the convolution output based on the attention weights. The attentive representation Cβ of those output vectors is computed as follows:
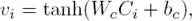 (6)
(6)
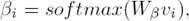 (7)
(7)
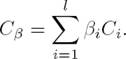 (8)
(8)
We use the filters with variable convolution window sizes to form parallel CNNs, which can learn multiple local representations and complement each other to improve the model accuracy. Then we feed the attentive representations produced by all the distinct CNNs through a max function to obtain the final pooling feature vector. That is, Cβ = argmax(Cβk), where k is the length of convolution window.
3.2.2 Character-level Attention
Word-level attention mechanism is introduced to extract salient words in a Chinese short text. Meanwhile, we use character-level attention to capture informative characters. For an input text, our model first encodes it with character embedding vectors, and then transmits the output to the LSTM/BLSTM and CNN layers simultaneously. Next, our model computes the attentive representations for the outputs of LSTM/BLSTM and CNN layers respectively, the process is the same as word-level attention. Finally, our model produces the new representation Sγ (i.e. the output of the attention-based LSTM/BLSTM) and Cδ (i.e. the output of the attention-based CNN).
3.2.3 The Hybrid of Attention
For BLSTM-based representation, we concatenate the outputs of BLSTM with word- and character-level attentions and get the attentive representation Sb. For CNN-based representation, we also concatenate the outputs of CNN with word- and character-level attentions and get the attentive representation Sc. The output vectors are defined by the following equations:
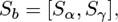 (9)
(9)
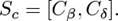 (10)
(10)
Besides the hidden states, the LSTM/BLSTM layer also produces the last time step output. Hence we concatenate the two last outputs of LSTM/BLSTM with word and character embedding that are defined as Sw and Sc, and get the new output Sd defined by the Eq. (11):
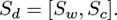 (11)
(11)
At last, our model outputs the final sentence vector S as follows:
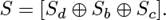 (12)
(12)
3.3 Classification
The output of representation layer is a comprehensive feature vector of the original sentence. It then be fed into the classification layer for supervised topic recognition. The classification layer is consist of a linear transformation layer and a softmax layer. That is, the linear layer converts sentence vector S to a real-valued vector whose dimension is the number of class, and the softmax layer is added to map each real value to a conditional probability, which is computed by Eq. (13):
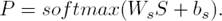 (13)
(13)
For training data, each short text has its golden label Pg. We
use the following cost function defined by Eq. (14) to minimize the categorical
cross-entropy between gold classification probability
Pg (S) and predicated
classification probability P(S), where
Nt is the number of training data,
Nc is the class number,  has a 1-of-K schema whose
dimension corresponding to the true class is 1 while all others are 0. During
training phrase, all the parameters including weights and bias terms in the
attention layer are determined and updated by the model. Word and character
embeddings are also fine-tuned as well. Optimization is performed using
Stochastic Gradient Descent (SGD):
has a 1-of-K schema whose
dimension corresponding to the true class is 1 while all others are 0. During
training phrase, all the parameters including weights and bias terms in the
attention layer are determined and updated by the model. Word and character
embeddings are also fine-tuned as well. Optimization is performed using
Stochastic Gradient Descent (SGD):
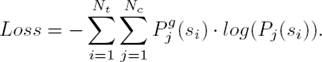 (14)
(14)
4 Experiments
We evaluate the effectiveness of our model for multi-class Chinese short text classification on two representative types of data sets, one is nearly formal short text (i.e. Chinese news titles) and the other is informal (i.e. Chinese Douban movie reviews and Weibo rumors). The detail of experimental setup, results and analysis is as follows.
4.1 Datasets
We conduct experiments on three datasets as follows:
Chinese news titles are obtained from [21]. This is a topic classification with 32 classes. There are 47,850 training samples and 15,950 testing samples.
Chinese Douban movie reviews are obtained from Douban1. We tag 84,634 samples with gold standard classification labels. 56,945 samples are used for training and 27,689 samples are used for testing. There are five levels of ratings from 1 to 5 (higher is better).
Weibo rumors are obtained from [13]. There are 9,079 Weibo rumors. After deleting these records with ’x’ label, we remain 5 classes, and 6,031 samples for training and 2,159 samples for testing.
The above three datasets all have no validation samples. We randomly choose 10 percent of the training samples for validation. The statistics of the data sets are summarized in Table 1.

4.2 Baselines
Most neural methods used to text classification are variants of convolutional or recurrent networks. We select five neural network baselines including CNN, RNN, RCNN, FastText [6] and C-LSTMs/BLSTMs[21].
CNN: We report the CNN baselines from [21], which implemented the model[8] and conducted experiments with word and character embeddings respectively (i.e. CNN-char and CNN-word).
RNN: We also report the RNN baselines from [21], which implemented a single layer recurrent neural network with LSTM and bidirectional LSTM, and conducted experiments with word and character embeddings respectively (i.e. LSTM-char, LSTM-word, BLSTM-char and BLSTM-word).
RCNN: Lai et al. [9] developed a two-layer neural model, the first layer applied a bi-directional recurrent structure to learn text representation with word embedding, and the second layer used a max-pooling mechanism to choose the salient features in the texts. We implement the RCNN baseline with LSTM-RNNs instead of vanilla RNNs, and experiment with word and character embeddings respectively (i.e. RCNN-char and RCNN-word).
FastText: Joulin et al. [6] proposed a fast text classification method based on word embedding, which averaged all of the word representations in each text into a vector representation that was in turn fed to a hierarchical softmax layer to classify the texts. We implement the baseline to classify Chinese short texts, and also experiment with word and character embeddings respectively (i.e. FastText-char and FastText-word).
C-LSTMs/BLSTMs: Zhou et al. [21] introduced a compositional recurrent neural networks with LSTM or BLSTM, which used word and character embeddings to learn a Chinese short text representation respectively, and then concatenated the two vectors to construct a sentence representation for classification. The results were reported in [21].
4.3 Experimental Setup
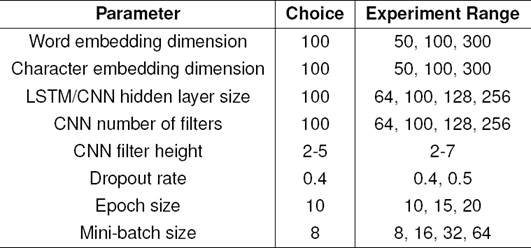
Note that we directly use the word and character embeddings from [21]. We apply Jieba2 to conduct Chinese word segmentation on the input text, and initialize the lookup tables of input texts with the 100-dimensional word and character embeddings respectively. The hyperparameters of our model are tuned on the validation set and early stopping is used with 10 epoches. Dropout rate of 0.4 is applied to obtain better performance. We use stochastic gradient descent to train all models with learning rate of 0.01 and momentum of 0.9. Table 2 shows the hyper parameter settings.
4.4 Results
Table 3 shows a detailed comparison of our model with the baselines. From Rows 1 to 6, the results show that the performances of CNN-word and RNN-word are better than CNN-char and RNN-char respectively. These results indicate that word embedding is more effective than character embedding and RNN with LSTM or BLSTM is also more effective than the CNN model. The results of Rows 11 and 12 prove that the combination of word and character embeddings can improve performance further. The non-attentive networks C-LSTMs/BLSTMs already perform better than other baselines. If we add the attentive mechanism, then the performance on all data sets improves further better than all baseline methods.
Table 3 Results in percent of weighted-average on Chinese news title, Douban movie review and Weibo Rumor. Best result per column is bold. HANs- stands for different attention layers in our model. HANs-CNN denotes the model with only the attention-based CNN. HANs-LSTM denotes the model with only the attention-based LSTM. HANs-BLSTM denotes the model with only the attention-based BLSTM. HANs-LSTM+CNN denotes the model with the combination of the attention-based LSTM and CNN. HANs-BLSTM+CNN denotes the model with the combination of the attention-based BLSTM and CNN
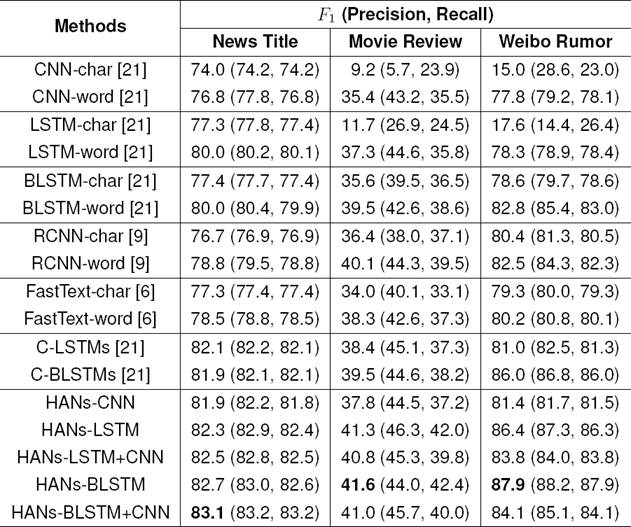
In Fig. 1, our model concatenates the outputs of the word- and character-level LSTM/BLSTM layers, which are equivalent to the C-LSTMs/BLSTMs model. From Rows 11 and 12, it is observed that C-LSTMs/BLSTMs model achieves differentiated results on three datasets respectively. For each data set, we choose the LSTM or BLSTM model that gets the best performance, which is the basis of our model. That is to say, for non-attentive representation, our model concatenates the word-and character-level outputs of the LSTM on the datasets of News Title, and concatenates the outputs of BLSTM on Douban Movie Review and Weibo Rumor.
On the basis, we further investigate the effect of our model on three datasets by augmenting different attentive approaches. In Table 3, from Row 13 to 14, it shows that the results of HANs-LSTM are better than HANs-CNN. While combined with the attention-based CNN and LSTM layer, HANs-LSTM+CNN obtains further better performance on two datasets. Row 16 implies that HANs-BLSTM can continue to improve performance. And we observe that HANs-BLSTM+CNN achieves best results on News Title, while lowers the performances on Movie Review and Weibo Rumor.
4.5 Analysis
These experimental results agree well with the findings of the effectiveness of attentive mechanism. For Chinese short text, we explore the attentive neural networks from two levels, that is, word- and character-level. Experimental results prove that our model is effective for the representation of Chinese short text and obtains better classification performance.
The experimental results from Rows 14 to 17 reveal that HANs-BLSTM is better than HANs-LSTM and HANs-BLSTM+CNN is also better than HANs-LSTM+CNN. These comparisons indicates that the BLSTM-based attention is more effective than the LSTM-based attention. The reason is that the BLSTM-based attention can capture more semantic information from both directions than the LSTM-based attention. In Fig. 2, our model firstly computes the attentive representation for the forward and backward LSTM layer respectively, then sum the two outputs to generate the representation of the input short text. Therefore the addition of the attentive representation from both directions picks out informative characters and words.
For Movie Review and Weibo Rumor, Rows 16 and 17 imply that adding CNN-based attention does not help and may even lower the performances. It may be the reason that several discrete words or characters determine the semantic of each Chinese short text in above two datasets, and the distances among these salient words or characters are long while CNN can only capture the semantic in the range of convolution window.
In all of the baselines, C-LSTMs/BLSTMs model almost achieves the best result relatively. However, comparison with the best results of all baselines, our model HANs-BLSTM (+CNN) further improves the F1-score by 1.0%, 1.5% and 1.9% on three datasets respectively.
5 Conclusion
In this paper, we propose a Hybrid Attention Networks (HANs) for Chinese short text classification, which aggregates important characters and words into sentence vectors respectively and merges them into one representative vector. Experimental results demonstrate that our model outperforms all of the baselines on two typical types of Chinese short text (i.e. regular and user-generated short text). Also it shows that our model is effective to select informative semantic units from a Chinese short text. In the future, we intend to explore our model in the representation of longer document.

