











 text new page (beta)
text new page (beta) Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
PermalinkCorresponding author is Guillermo De Ita Luna.
1. Introducción
Un marco de referencia ampliamente aceptado en el área del razonamiento en sistemas inteligentes es el enfoque de sistemas basados en bases de conocimiento. La idea general de estos sistemas es mantener el conocimiento en algún lenguaje de representación con una connotación bien definida. En este caso, las sentencias se almacenan en una base de conocimiento (KB - por sus siglas en inglés) provista de un mecanismo de razonamiento [9].
Un reto fundamental de estos sistemas es la automatización del razonamiento deductivo a partir de la KB. El razonamiento deductivo proposicional es generalmente resumido como sigue: dada una KB K, que contiene el conocimiento acerca de un dominio (“el mundo”), y una sentencia φ que representa la consulta que captura la situación actual, ambas expresadas en lógica proposicional, el objetivo es decidir si K implica φ (en símbolos: K ⊨ φ), lo que se conoce como el problema de implicación proposicional.
La implicación proposicional es una tarea relevante en problemas como: estimar el grado de creencia, revisión y actualización de creencias, al trabajar con explicaciones abductivas, y en muchos otros procedimientos en aplicaciones de la Inteligencia Artificial (AI, por sus siglas en inglés), por ejemplo, al trabajar en planeación, diseño de sistemas multiagentes, diagnóstico lógico, razonamiento aproximado, entre otras aplicaciones [7, 13]. En general, el problema de la implicación lógica es un reto difícil en el área de razonamiento automático, y resulta ser un problema Co-NP difícil, incluso en el caso proposicional [17].
La revisión de creencias consiste en incorporar nuevas creencias a una base de conocimiento (KB) ya establecida, cambiando lo menos posible las creencias originales y manteniendo la consistencia de la KB. La función básica de la revisión de creencias es ofrecer un método de cómo cambiar una base de conocimiento cuando nos enfrentamos con nueva información φ. La nueva información puede entrar en conflicto con la que teníamos antes, y en ese caso, si queremos mantener consistencia, se deberán eliminar algunos elementos previos de la KB.
Es deseable que los cambios en la base original de conocimiento no se efectúen de cualquier manera, sino de forma racional. En la revisión de creencias se trata por tanto, de una teoría normativa que nos indica en cada caso, cuál es la manera óptima de proceder.
En cierto sentido, la revisión de creencias propone una teoría formal, cuyos efectos podemos interpretar de diferente manera. Las creencias pueden aludir a entidades mentales de un agente, a elementos de una base de conocimiento del mundo real, o tal vez, a elementos de un problema en la teoría de la decisión. Esta característica proporciona su versatilidad a la teoría de revisión de creencias [5].
Al proceso de revisión de creencias lo donotare-mos con el operador (◦) que actúa sobre una KB K y sobre una nueva evidencia φ, para formar una nueva KB K′ = K ◦ φ. Cuando K ⊨ φ entonces K′ = K ◦ φ = K. Cuando K ⊭ φ, la idea de la revisión de creencias es formar una nueva KB K′ a partir de la previa K, que permita inferir la nueva evidencia φ y al mismo tiempo, minimice la pérdida de información de K [9], [12].
Aunque la inferencia proposicional es un problema Co-NP-completo en su versión general [22], existen también algunos casos que se pueden resolver de manera eficiente [17]. Consideraremos una KB 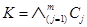 y
y 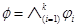 , donde cada Cj ∈ K y cada ϕi ∈ φ son cláusulas expresadas bajo un mismo conjunto de n variables Booleanas. Este artículo muestra que el uso de patrones falsificantes de las cláusulas, ayuda a determinar si una FC se infiere de otra FC, y por tanto, a construir un algoritmo para la revisión de creencias entre formas normales conjuntivas.
, donde cada Cj ∈ K y cada ϕi ∈ φ son cláusulas expresadas bajo un mismo conjunto de n variables Booleanas. Este artículo muestra que el uso de patrones falsificantes de las cláusulas, ayuda a determinar si una FC se infiere de otra FC, y por tanto, a construir un algoritmo para la revisión de creencias entre formas normales conjuntivas.
Es común el uso de FC’s en el proceso de razonamiento automático, ya que el procedimiento de resolución ha abierto un área de relevancia práctica para revisar consistencia entre FC’s. Aunque es bien conocido que la inferencia basada en el principio de resolución tiene limitaciones intrínsecas [3]. Al tener un método efectivo de revisión de creencias entre FC’s, su extensión para considerar otras formas normales no es difícil, dado que cualquier fórmula Booleana se puede expresar en forma conjuntiva.
1.1. Estado del arte
El enfoque más conocido para realizar la revisión de creencias es el paradigma AGM (debido a las iniciales de los autores Alchourrón, Gärdenfors and Makinson) [1]. La teoría AGM propone un conjunto de postulados racionales, que cualquier operador de revisión debe satisfacer
Posterior a la propuesta AGM, Alchourrón y Ma-kinson [14] desarrollaron un modelo constructivo para funciones de cambio llamado “contracción segura” (safe contraction) que después fue generalizada por Hansson [15]. Sin embargo, la mayoría de estas propuestas requieren de información adicional, tales como: relaciones de afianzamiento epistémicas, sistemas de esferas, relación de subfórmulas, entre otras [14].
Algunos de los problemas con las propuestas anteriores, es que muchas veces esta información no se tiene, o bien no existe, obligando a tratar todas las creencias por igual. Más aún, hay otras propuestas cuyos operadores de revisión de creencias son completamente dependientes de la sintaxis.
Katsuno y Mendelzon unificaron los diferentes enfoques semánticos de revisión de creencias, y reformularon los postulados AGM, a los que llamaron ahora postulados KM. Además, propusieron un teorema de representación que caracteriza las operaciones de revisión en términos de pre-órdenes totales sobre el conjunto de interpretaciones [16].
Posteriormente, Darwiche y Pearl [8] propusieron postulados para una revisión de forma iterada, donde caracterizan la revisión de creencias como un proceso que puede depender de elementos de un estado que no necesariamente son capturados por un conjunto de creencias. Su propuesta establece una representación basada en el modelo que representa los postulados y las restricciones para la revisión de creencias. Otra propuesta similar a la de Darwiche y Pearl es la presentada por Lehmann [18], donde cada observación es una sentencia general que se asume es consistente.
Hay algunas propuestas de revisión de creencias basadas en modelos, y que se identifican por el nombre de sus autores; Dalal, Satoh, Winslett, Borguida y Forbus [20]. Por ejemplo, Dalal [6] sugiere un operador de revisión basado en la distancia mínima Hamming entre las interpretaciones y la cual se extiende a distancias entre interpretaciones y bases. En la práctica, esta propuesta implica un cálculo de modelos que pueden ser muy costoso, otro de los inconvenientes del enfoque Dalal es que se limita al caso de bases de conocimientos consistentes.
Por otro lado, la propuesta de Satoh [25] es similar a la de Dalal, con la diferencia de que la distancia entre dos modelos es definida como el conjunto de literales a las que les son dados diferentes valores. En el caso de Winslett, la propuesta se basa en la comparación entre todos los sistemas consistentes de longitud máxima.
La propuesta de Borguida y Forbus es similar a la de Winslett, con la diferencia de que Borguida considera modelos incompatibles, y Forbus utiliza la distancia Hamming. La similitud entre los modelos es definida a través de un conjunto conteniendo todas las subfórmulas máximales y consistentes con la consulta realizada, lo que lleva a una búsqueda exhaustiva sobre la tautologicidad de una gran cantidad de subfórmulas, cuestionando así no sólo la funcionalidad de cada uno de los métodos, sino que nos lleva también a concluir que el problema de revisión de creencias bajo estos métodos es un problema inherentemente intratable (de complejidad exponencial en tiempo).
Más recientemente, la revisión de creencias ha ganado atención en el marco de la lógica simbólica, y numerosos operadores de revisión de creencias han sido propuestos de acuerdo a puntos de vista sintácticos o semánticos [19, 21, 25], obteniéndose diferentes resultados sobre la complejidad en tiempo de estas propuestas [6, 19]. Algunas de las investigaciones en esta dirección se han acotado principalmente a considerar el fragmento Horn dentro de la lógica clásica.
Existen diversas propuestas que involucran fórmulas proposicionales tales como las descritas en [10, 26, 2] que sugieren métodos que abordan sólo fragmentos de la lógica proposicional. Una de las propuestas recientes debida a Delgrande presenta los primeros resultados sobre cambio de creencias en el fragmento Horn [10].
En [4], los autores presentan una metodología general para definir nuevos operadores de revisión derivados de operadores estándar (como por ejemplo, los operadores de Dalal y Satoh), tal que el resultado de la revisión se mantiene en el fragmento en cuestión. Por lo tanto, en esta propuesta los autores no se limitan sólo al caso Horn, sino que ésta es aplicable a otros fragmentos de la lógica proposicional, donde los modelos de las fórmulas cumplan el ser cerrados bajo una función Booleana.
Se puede notar que estas propuestas se desarrollan para considerar algún tipo de fórmula normalizada o bien sólo consideran cláusulas de Horn. Cada una de estas propuestas propone un operador de revisión que trabaja sobre sus fórmulas normalizadas y que presentan diversos inconvenientes. Por ejemplo, algunos de los operadores son dependientes de la sintaxis o bien requieren de información adicional. Otros definen diferentes nociones de proximidad, y unos más se limitan a revisar sólo bases consistentes. Pero el principal inconveniente de estos métodos de revisión de creencias es que conllevan inherentemente a realizar procesos de complejidad exponencial en tiempo.
Por otro lado, nuestra propuesta de revisión de creencias sigue el enfoque basado en revisar los modelos de las fórmulas involucradas, porque supondremos que la KB K y la fórmula de consulta φ son FC’s. Trabajar con FC’s permite el cálculo efectivo del conjunto de asignaciones que falsifican a cada una de sus cláusulas, y por tanto, también del conjunto complemento de tales asignaciones falsificantes, que serán precisamente, los modelos de las fórmulas.
Mostramos aquí, que el proceso de revisión de creencias puede realizarse de forma práctica en función de las asignaciones falsificantes de las FC’s involucradas. Además, nuestra propuesta obtiene una nueva base de conocimiento K′ = K ◦ φ, que reduce de forma mínima el conjunto de modelos de la base de conocimiento original K.
Resumiendo, las contribuciones principales de nuestro trabajo son:
◼ Proponemos un método que trabaja sobre el conjunto de asignaciones falsificantes de las fórmulas involucradas, para revisar: K ⊨ φ.
◼ Introducimos un operador lógico entre dos cláusulas, Ind(ϕi, Cj), cuyo resultado es una FC F s, tal que F als(F s) = F als(ϕi) − F als(Cj).
◼ Demostramos que nuestra propuesta de revisión de creencias es correcto, y cumple los postulados de Katsuno y Mendelzon.
◼ El operador Ind(ϕi, Cj) se implementó para que trabaje en tiempo lineal sobre el número de variables involucradas, y es la base de nuestro proceso de revisión de creencias.
◼ A pesar de la eficiencia del operador Ind(ϕi, Cj), el número de cláusulas en F s para que (K ∧ F s) ⊨ φ, puede llevarnos a un crecimiento exponencial de orden O(|K| · n · 2(n−min{|ϕi|:ϕi∈φ})).
2. Preliminares
Sea X = {x1, . . . , xn} un conjunto de n variables Booleanas. Una literal denotada como lit es, o una variable xi o una variable negada ¬xi. Como es usual, para cada x ∈ X, x0 = ¬x y x1 = x. Sean ⊥ and > dos constantes representando los valores lógicos falso y verdadero, respectivamente.
Una cláusula es una disyunción de diferentes literales. Para k ∈ N, una k-cláusula es una cláusula que consiste exactamente de k literales, y una (≤ k)-cláusula es una cláusula con a lo más k literales. Una frase es una conjunción de literales. Una k-frase es una frase con exactamente k literales. Una variable x ∈ X aparece en una cláusula (frase) C si x o ¬x es un elemento de C.
Una forma normal conjuntiva (F C) es una conjunción de cláusulas (que también llamaremos forma conjuntiva), y una k-F C es una F C que contiene sólo k-cláusulas.
Una forma normal disyuntiva (F D) es una disyunción de frases, y una k-F D es una F D que contiene sólo k-frases. Una FC F con n variables representa una función Booleana n-aria F :{0, 1}n → {0, 1}. Por el contrario, cualquier función Booleana F tiene infinitamente muchas representaciones equivalentes, entre estas, algunas en FC y también otras en FD.
Denotamos con Y a cualquiera de los elementos lógicos básicos que estamos utilizando, como: una literal, una cláusula, una frase, una FD o una FC, y v(Y ) denota el conjunto de variables involucradas en el objeto Y . Por ejemplo, v(¬x1 ∨ x2) = {x1, x2}. Mientras lit(Y ) denota el conjunto de literales involucradas en el objeto Y . Por ejemplo, si X = v(Y ) entonces lit(Y ) = X ∪ ¬X = {x1, ¬x1, . . . , xn, ¬xn}. También usamos ¬Y como el operador de negación sobre el objeto Y . Denotaremos a {1, 2, 3, . . .,n} por [[1, n]], y a la cardinalidad de un conjunto A por |A|.
Una asignación s para una fórmula F es un mapeo Booleano s : v(F ) → {1, 0}. Una asignación s puede también ser considerada como un conjunto de literales no complementarias: l ∈ s sí y sólo si s asigna l a cierto y ¬l a falso. s es una asignación parcial para la fórmula F cuando s ha determinado un valor lógico sólo para las variables de un subconjunto propio de F , a saber s : Y → {1, 0} y Y ⊂ v(F ). Si s tiene valores lógicos determinados para todas las variables en F entonces s es una asignación total de F .
Si F1 ⊂ F es una FC que consiste de algunas cláusulas en F , y v(F1) ⊂ v(F ), una asignación sobre v(F1) es una asignación parcial sobre v(F ). Considerando n = |v(F )| y de igual forma n1 = |v(F1)|, cualquier asignación sobre v(F1) tiene 2n−n1 extensiones sobre v(F ).
Considerando una cláusula C y una asignación s como conjuntos de literales, C es satisfecha por s si s ∩ C ≠ ∅, de otra manera s contradice (o falsifica) a C. Una FC F es satisfecha por una asignación s si cada cláusula en F es satisfecha por s; F es contradicha por s si alguna cláusula en F es falsificada por s. Un modelo de F es una asignación sobre v(F ) satisfaciendo F .
Una frase f es satisfecha por una asignación s si f ⊆ s, de otra manera s falsifica a f. Una FD F es satisfecha por s si alguna frase en F es satisfecha por s. F es contradicha por s si todas las frases en F son falsificadas por s.
Dada una fórmula F , sea S(F ) el conjunto de todas las posibles asignaciones definidas sobre v(F ). Si n = |v(F )| entonces |S(F )| = 2n. s ⊨ F denota que la asignación s es un modelo de F (s satisface a F ). s ⊭ F denota que s es una asignación falsificante de F . Denotamos por SAT (F ) al conjunto de asignaciones en S(F ) que son modelos de F . F als(F ) denota el conjunto de asignaciones de S(F ) que falsifican a F .
Dadas dos fórmulas Booleanas F y G definidas sobre un mismo conjunto de variables, esto es v(F ) = v(G), decimos que F es consecuencia lógica de G, denotado como G ⊨ F , si para toda asignación s que satisface a G se cumple que s también satisface a F . Y diremos que F y G son logicamente equivalentes, denotado como G ≡ F , si ambas fórmulas tienen el mismo conjunto de modelos, esto es, una asignación s satisface a G si y sólo si s satisface a F . En términos de los conjuntos de modelos, podemos denotar que: G ⊨ F si y sólo si SAT (G) ⊆ SAT (F ), y que G ≡ F si y sólo si SAT (F ) = SAT (G).
#SAT (F ) denota el número de asignaciones de S(F ) que satisfacen a la fórmula F . Mientras que #F als(F ) representa al número de asignaciones de S(F ) que no satisfacen a F .
Para cualquier fórmula proposicional F , se cumple que: S(F ) = SAT (F ) ∪ F als(F ). El problema SAT consiste en decidir, para una fórmula de entrada F , si F es satisfactible, esto es, si F tiene un modelo o no. Una base de conocimiento KB es un conjunto K de fórmulas. Dada una KB K y una fórmula proposicional φ, decimos que K implica φ, y escribimos K ⊨ φ, si φ es satisfecha por todo modelo de K, es decir, SAT (K) ⊆ SAT (φ).
3. Inferencia entre formas conjuntivas
Un problema fundamental en el razonamiento deductivo es el problema de la implicación lógica: dada una KB K y una fórmula φ, debemos decidir si K ⊨ φ. En este trabajo analizaremos la complejidad computacional del caso del problema de implicación entre formas conjuntivas: FC ⊨ FC.
Sea una base de conocimiento K que se encuentra en forma conjuntiva, y sea una consulta expresada también en FC , donde cada Cj ∈ K y cada ϕi ∈ φ son cláusulas expresadas bajo un mismo conjunto de n variables Booleanas.
Dadas dos FC’s F1 y F2, decidir si F1 ⊨ F2 es lógicamente equivalente a probar que ¬F2 ⊨ ¬F1, que resulta en revisar la inferencia entre formas disyuntivas, ya que si F es una FC entonces ¬(F ) es una FD, debido a que negar una FC F se realiza en tiempo lineal sobre el tamaño de F , a través de una generalización de las reglas de De Morgan.
Por otro lado, revisar la inferencia entre formas disyuntivas se reduce a revisar si una FD G es una tautología, lo que es un problema clásico en la clase de complejidad Co-NP completo [22]. La reducción proviene de considerar que la existencia de un procedimiento que determina si G1 ⊨ G2, con G1 y G2 formas disyuntivas, permite a su vez, determinar la tautologicidad de cualquier forma disyuntiva G, ya que basta con hacer G1 ≡ > que es una tautología, y entonces G1 ⊨ G se cumplirá sólo si G es a su vez una tautología.
Como K y φ están en FC, las cadenas falsificantes de sus cláusulas F als(K) y F als(φ) se pueden calcular eficientemente [9]. Usar las cadenas falsificantes es la base para revisar si K ⊨ φ, lo que en términos de sus asignaciones equivale a revisar si SAT (K) ⊆ SAT (φ), o bien que: F als(φ) ⊆ F als(K). El resultado de aplicar el operador de revisión de creencias sobre la KB K y la nueva evidencia φ es denotado como K′ = K ◦ φ. Cuando K ⊨ φ entonces K′ = K ◦ φ = K.
Si K ⊭ φ entonces F als(φ) ⊄F als(K), lo que implica que existe un conjunto de asignaciones S tal que S ⊆ F als(φ) y S ⊈ F als(K). Si K ⊭ φ, entonces S = (F als(φ) - F als(K) ) ≠ ∅. En este caso, nuestro método de revisión de creencias trabaja construyendo tal conjunto S, lo que permite construir una nueva FC F s, tal que S = F als(F s) y K′ = K ∧ F s, cumple que: K′ ⊨ φ.
El método que proponemos obtiene S = (F als(φ)−F als(K)) como un conjunto de cadenas falsificantes, lo que nos lleva a construir de forma directa una FC F s, donde S = F als(F s) y tal que K′= K ∧ F s es una nueva FC con menos información que K (dado que K′ tiene más cláusulas que K), de hecho, se cumple que si S ≠ ∅ entonces F als(K) ⊂ F als(K′), y por tanto, SAT (K′) ⊂ SAT (K).
3.1. Construcción de conjuntos independientes de cláusulas
Dada una forma conjuntiva 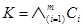 , con n = |v(K)|, para cualquier cláusula Ci ∈ K, hay exactamente 2(n−|Ci|) asignaciones de S(K) falsificando Ci. Debido a que todas las falsificaciones de Ci tiene valores fijos en las posiciones de las variables v(Ci) y tales valores falsifican cada literal de Ci. Por tanto, hay n - | Ci | variables a las que se les puede asignar cualquier valor de verdad. Esto significa que hay 2(n−|Ci|) asignaciones falsificantes para Ci.
, con n = |v(K)|, para cualquier cláusula Ci ∈ K, hay exactamente 2(n−|Ci|) asignaciones de S(K) falsificando Ci. Debido a que todas las falsificaciones de Ci tiene valores fijos en las posiciones de las variables v(Ci) y tales valores falsifican cada literal de Ci. Por tanto, hay n - | Ci | variables a las que se les puede asignar cualquier valor de verdad. Esto significa que hay 2(n−|Ci|) asignaciones falsificantes para Ci.
Sea Ai un conjunto de cadenas tales que la longitud de cada cadena es n. El valor en la j-ésima posición de la cadena Ai, 1≤j≤n representa el valor de verdad de xj que falsifica Ci. Es decir, si xj ∈ Ci entonces el j-ésimo elemento de cualquier cadena en Ai es 0. De otra manera si ¬xj ∈ Ci entonces el j-ésimo elemento es 1.
Usaremos el símbolo * para representar los elementos que pueden tomar cualquier valor de verdad en las cadenas Ai. Por ejemplo, si K = {C1, .., Cm} es una 2-FC, n = |v(K)|, C1 = {x1, x2} y C2 = {x2, ¬x3} entonces se representa A1 como 00**· · · * y A2 como *01*· · · *. Este abuso de notación nos permitirá dar una representación concisa y clara en el resto del documento, considerando a las cadenas Ai como patrones que representan las falsificaciones de la cláusula Ci. A tales cadenas las llamaremos cadenas falsificantes de una cláusula.
Definición 1 [11] Dadas dos cláusulas Ci y Cj, si ellas tienen al menos una literal complementaria, se les llamará cláusulas independientes. En otro caso, se dice que ambas son cláusulas dependientes.
Definición 2 Sea K = {C1, C2, . . . , Cm} una FC. K es llamada independiente si para cualquier par de cláusulas Ci, Cj ∈ K, i ≠ j, se cumple la propiedad de independencia.
Definición 3 Dadas dos cadenas falsificantes A y B, ambas de la misma longitud, si hay una i tal que A[i] = x y B[i] = 1 − x, x ∈ {0, 1}, se dice que tienen la propiedad de independencia. En otro caso, decimos que ambas cadenas son dependientes.
Sea C una cláusula cualquiera, para cualquier variable x se cumple que:
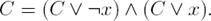 (1)
(1)
Además, esta reducción conserva el número de asignaciones falsificantes, ya que para cualquier par de cláusulas independientes Ci, Cj se cumple que F als(Ci)∩F als(Cj) = ∅ y entonces #F als(C) = 2(n−|c|) = 2(n−(|c|+1))+2(n−(|c|+1)) = #F als((C ∨ ¬x) ∧ (C ∨ x)), porque (C ∨ ¬x) y (C ∨ x) son cláusulas independientes.
La conjunción de un par de cláusulas dependientes C1 y C2 puede expresarse mediante una conjunción de cláusulas independientes. Supongamos que hay literales en C1 que no están en C2, sea L = {x1, x2, . . . , xp} tales literales. Esto es, L = lit(C1) − lit(C2). Existe una reducción para transformar C2 (o C1) como cláusula independiente con C1 (o C2) llamada reducción de independencia, y que trabaja de la siguiente manera.
Por (1) se puede escribir:
C1 ∧ C2 = C1 ∧ (C2 ∨ ¬x1) ∧ (C2 ∨ x1). Ahora C1 y (C2 ∨ ¬x1) son independientes. Aplicando (1) a (C2 ∨ x1) : C1 ∧ C2 = C1 ∧ (C2 ∨ ¬x1) ∧ (C2 ∨ x1 ∨ ¬x2) ∧ (C2 ∨ x1 ∨ x2). Las primeras tres cláusulas son independientes. Repitiendo la reducción de independencia hasta xp, se tiene que C1 ∧ C2 puede expresarse como:
C1 ∧ (C2 ∨ ¬x1) ∧ (C2 ∨ x1 ∨ ¬x2) ∧ . . . ∧ (C2 ∨ x1 ∨ x2 ∨ . . . ∨ ¬xp) ∧ (C2 ∨ x1 ∨ x2 ∨ . . . ∨ xp).
La última cláusula contiene todas las literales de C1, así que puede eliminarse porque es subsumida por la cláusula C1, obteniéndose que:
 (2)
(2)
Las cláusulas del lado derecho de la ecuación (2) son independientes por construcción.
El operador central para revisar inferencia entre FC’s es un operador de independiencia que trabaja sobre dos cláusulas ϕ y C, y que construye un conjunto de cláusulas independientes equivalentes a ϕ ∧ C. Sea L = {x1, x2, . . . , xp} = lit(C) − lit(ϕ) se define el operador de independencia entre ϕ y C como sigue:

La complejidad en tiempo para ejecutar Ind(ϕ, C), que denotaremos como TInd(|ϕ|, |C|), depende directamente del tiempo para ejecutar operaciones básicas entre conjuntos de literales. Por ejemplo, la operación lit(C) − lit(ϕ) podría realizarse como: para cada x ∈ lit(C) revisar si x ∈ lit(ϕ) o si ¬x ∈ lit(ϕ), lo que requiere de a lo más |C| * |ϕ)| ≤ n2 operaciones de comparación. Si los conjuntos lit(C) y lit(ϕ) se representan mediante arreglos de n posiciones (fijando una posición para cada una de las n posibles variables), entonces lit(C) − lit(ϕ) se realizará en a lo más O(n) operaciones lógicas entre las posiciones de ambos arreglos.
Por otro lado, cuando L = lit(C) − lit(ϕ) ≠ ∅, se realiza un ciclo de |L| ≤ (n − 1) iteracciones, y en cada iteracción i se agrega una disyunción y una negación para formar (ϕ ∨ x1 ∨ . . . ∨ ¬xi), y a través de una conjunción se adiciona esta cláusula a la FC que se esta construyendo. Esto nos lleva a un proceso, en el peor caso, de orden O(n) para construir Ind(ϕ, C).
Veamos como este operador de independencia Ind(ϕi, Cj) entre cláusulas ϕi ∈ φ y Cj ∈ K es la base para realizar la revisión de creencias entre K y φ.
4. Revisión de Creencias entre formas conjuntivas
Nuestro método de Revisión de Creencias se basa en las siguientes dos propiedades:
1. Si ∀ s ∈ F als(φ) se cumple que s ∈ F als(K), entonces K ⊨ φ.
2. Si ∃ s ∈ F als(φ), y s ∉ F als(K), entonces K ⊭ φ.
El primer caso considera que todas las asignaciones de F als(φ) están en el conjunto F als(K), lo que demostraría que K ⊨ φ. Y en este caso K′ = K, ya que no se necesita cambiar la KB K.
En el segundo caso, se detectarán los conjuntos de asignaciones S tal que ∃ϕ ∈ φ, S ⊆ F als(ϕ) y S ⊈ F als(K). Para construir estos conjuntos S se inicia con la cadena A1 que representa a F als(ϕ1) y se aplica el operador Ind con cada una de las cadenas Bj que representan F als(Cj), j = 1, . . . , m.
La operación Ind(ϕi, Cj) forma una cadena que representa el conjunto de asignaciones falsificantes: F als(ϕi) − F als(Cj). Esto es, Ind(ϕi, Cj) determina las asignaciones que están en F als(ϕi) pero que no están contenidas en F als(Cj). Si se aplica la operación Ind sobre todo Cj ∈ K, obtendremos como resultado el conjunto S ⊆ F als(ϕi) ∧ S ⊄ F als(K).
El conjunto S permite construir una FC F si, F si = (D1 ∧ D2 ∧ . . . Dt), donde S = F als(F si). Al agregar las nuevas cláusulas de F si a K, obtenemos una nueva KB K′i = K ∧ F si, que cumple que: K′i ⊨ ϕi, y además, K′i sigue siendo una FC. Presentamos algorítmicamente este proceso.

Ind(ϕi, K) consiste de dos ciclos, uno externo sobre Cj ∈ K, de orden O(|K|). Este ciclo (el F or) recorre las columnas de una tabla donde se irán colocando los resultados de Ind(ϕi, Cj).
El cuerpo del ciclo interno consiste esencialmente de realizar el operador Ind(ϕi, Cj) que es de orden O(n), y de realizar ajustes a la FC F si que inicia con la cláusula ϕi y que involucra no más de O(n) operaciones.
El número de filas de la tabla se va ajustando de forma dinámica, dependiendo del resultado de Ind(ϕi, Cj). En el peor caso, este ciclo sobre el número de filas puede llevarnos a un crecimiento exponencial sobre el número de cláusulas que contiene una F si, como se mostrará en la sección de análisis de complejidad de nuestro método.
Cuando el proceso Ind(ϕi, K) itera sobre toda ϕi ∈ φ, se forman las cláusulas F si tal que F als(∪(F si)) = F als(φ) − F als(K). Al adicionar a K el conjunto de cláusulas ∪(F si), se forma una nueva KB K′ tal que K′ ⊨ φ, puesto que F als(φ) ⊆ F als(K′), y por tanto, SAT (K′) ⊆ SAT (φ).
Ejemplo 1. En todos los ejemplos a presentar, supondremos un ordenamiento alfanumérico sobre el conjunto de variables que se utilizan. Sea K = (¬p∨q∨s)∧(¬q∨¬r∨s)∧(¬q∨r∨¬s)∧(¬p∨¬q∨r) y φ = (¬p ∨ ¬r) ∧ (¬q ∨ r) ∧ (p ∨ q ∨ ¬r ∨ ¬s) ∧ (¬t). Probar que K ⊨ φ, es equivalente a revisar que: F als(φ) = {1*1**, *10**, 0011*, ****1} ⊆ F als(K) = {10*0*, *110*, *101*, 110**}. En cada celda de las columnas 2 en adelante de la Tabla 1, se va mostrando el resultado de Ind(ϕi, Cj).

Dadas 2 cláusulas Ci, Cj que difieren en el signo de sólo una variable, la reducción por literal complementaria genera una sóla cláusula de Ci ∧ Cj, de hecho, la reducción se basa en la aplicación de la ecuación (1).
Por ejemplo, sea Ci = (x ∨ q), y Cj = (¬x ∨ q), entonces Ci ∧ Cj = (q). En términos de las cadenas falsificantes de las cláusulas, denotaremos tal reducción como: V arcom(Ai, Aj). En el caso de nuestro ejemplo, se tiene que: V arcom(1111*, 1011*) = 1 * 11*.
Es relevante aplicar la operación de reducción por literales complementarias sobre las cadenas en S, para así minimizar el número total de cláusulas.
Aplicando la reducción V arcom y eliminando cláusulas subsumidas al resultado del ejemplo 1, se tiene que: S = {1*11*, 0100*, 0011*, 00**1, *1111, 10*11}. Escribiendo S como una FC, F s = (¬p ∨ ¬r ∨ ¬s) ∧(p ∨ ¬q ∨ r ∨ s) ∧ (p ∨ q ∨ ¬r ∨ ¬s) ∧ (p ∨ q ∨ ¬t) ∧ (¬q ∨ ¬r ∨ ¬s ∨ ¬t) ∧ (¬p ∨ q ∨ ¬s ∨ ¬t). Y así, la nueva KB K′ = K ∧ F s es una FC que cumple: K′ ⊨ φ.
4.1. Propiedades del método de Revisión de Creencias
El conjunto de cláusulas construido mediante Ind(ϕi, K) se agrega a la KB original K, y así, cada ϕi ∈ φ se infiere de K ∧ Ind(ϕi, K). Esto se demuestra en el siguiente teorema sobre la corrección de nuestro método.
Teorema 1 Dadas dos cláusulas ϕi y Cj se cumple que (Cj ∧ Ind(ϕi, Cj) ) ⊨ ϕi.
Demostración.
Si ϕi y Cj son cláusulas independientes, entonces ϕi = Ind(ϕi, Cj) y por tanto (Cj ∧ Ind(ϕi, Cj)) = (Cj ∧ ϕi). Así (Cj ∧ ϕi) ⊨ ϕi, por la propiedad proposicional: (p ∧ q) ⊃ q y por la reflexividad de la inferencia lógica: ϕi ⊨ ϕi.
Si ϕi y Cj no son independientes, pero Ind(ϕi, Cj) = ∅, esto implica que F als(ϕi) ⊆ F als(Cj) y por tal Cj ⊨ ϕi. Como Cj = (Cj ∧ Ind(ϕi, Cj)), entonces (Cj ∧ Ind(ϕi, Cj)) ⊨ ϕi.
Cuando ϕi y Cj no son independientes, e Ind(ϕi, Cj) ≠ ∅, se cumple que (Cj ∧ Ind(ϕi, Cj)) ≡ (Cj ∧ ϕi) por (2), cumpliéndose que: (Cj ∧ ϕi) ⊨ ϕi, por la propiedad proposicional: (p ∧ q) ⊃ q, y por la reflexividad: ϕi ⊨ ϕi.
Así, para cualquiera de los tres posibles resultados de Ind(ϕi, Cj), se cumple: (Cj ∧Ind(ϕi, Cj)) ⊨ ϕi.
El conjunto de cláusulas construido mediante Ind(ϕi, Cj) contiene exactamente las cláusulas necesarias que permitirán inferir cada ϕi ∈ φ a partir de Cj ∧ Ind(ϕi, Cj). Al iterar Ind(ϕi, Cj) sobre todo Cj ∈ K, se obtiene un conjunto de cláusulas con las que se asegura cumplir (K ∧ Ind(ϕi, K)) ⊨ ϕi. El teorema anterior demuestra así la corrección de nuestro método.
Mostremos ahora que el conjunto de cláusulas en Ind(ϕi, Cj) representa el conjunto mínimo de cláusulas que permiten cubrir el espacio: F als(ϕi) − F als(Cj), que es el espacio mínimo necesario de asignaciones para que F als(ϕi) ⊆ F als(Cj)∪F als(Ind(ϕi, Cj)), y por tanto, para que se cumpla (Cj ∧ Ind(ϕi, Cj)) ⊨ ϕi.
Teorema 2 F als(Ind(ϕi, Cj)) = F als(ϕi) − F als(Cj).
Demostración.
Si Ind(ϕi, Cj) = ∅, se cumple que Ind(ϕi, Cj) es el número mínimo de cláusulas que permiten inferir (Cj ∧ Ind(ϕi, Cj)) ⊨ ϕi, ya que de hecho, Cj ⊨ ϕi.
Supongamos ahora que Ind(ϕi, Cj) ≠ ∅. Veamos que ∀s ∈ F als(Ind(ϕi, Cj)) se cumple que s ∈ F als(ϕi), y s ∉ F als(Cj). Sea s ∈ F als(Ind(ϕi, Cj)), entonces s falsifica a ϕi, ya que cada cláusula en Ind(ϕi, Cj) tiene la forma (ϕi ∨ R), con R una disyunción de literales. Si s falsifica a (ϕi ∨ R) entonces s falsifica tanto a (ϕi) como a (R), por tanto s ∈ F als(ϕi). Además, s ∉ F als(Cj), ya que Cj es independiente con cada una de las cláusulas de Ind(ϕi, Cj) (por construcción del operador de independencia), y por tal, s ∉F als(Cj).
El teorema anterior demuestra que el operador de independencia Ind(ϕi, Cj) construye un conjunto de cláusulas que cubren de forma exacta el espacio de asignaciones que hacen falta para que F als(ϕi) ⊆ F als(Cj) ∪ F als(Ind(ϕi, Cj)). Aún más, el conjunto F als(Ind(ϕi, Cj)) es el conjunto mínimo de asignaciones para cubrir el espacio F als(ϕi) − F als(Cj), ya que F als(Cj) y F als(Ind(ϕi, Cj)) son ajenos (por construcción del operador de independencia), y por tanto F als(Cj) ∩ F als(Ind(ϕi, Cj)) = ∅.
Corolario 1 F als(Ind(ϕi, K)) ⊆ F als(ϕi).
Demostración.
Por el teorema (2), se tiene que F als(Ind(ϕi, Cj)) = F als(ϕ) − F als(Cj), al iterar sobre cada Cj de K se cumple que F als(Ind(ϕi, K)) = F als(ϕi) − F als(K). Y por propiedades entre conjuntos, se cumple que F als(Ind(ϕi, K)) ⊆ F als(ϕ).
Al iterar Ind(ϕi, Cj) sobre todo Cj ∈ K, se obtiene un conjunto mínimo de cláusulas: F si que asegura que: (K ∧ F si) ⊨ ϕi.
Al extender K con las cláusulas obtenidas en Ind(ϕi, K) se va formando K′. Así K′ extiende al conjunto de cláusulas de K, y por tanto, extiende también el espacio inicial de falsificaciones de K, agregando las asignaciones que falsifican a Ind(ϕi, K). De hecho, estos dos conjuntos de falsificaciones son excluyentes por construcción de Ind(ϕi, K), y por tanto, F als(K)∩F als(Ind(ϕi, K)) = ∅. En otras palabras, el conjunto de modelos de K′ es ahora un subconjunto de los modelos de K, SAT (K′) ⊆ SAT (K).
Sin embargo, al iterar el operador Ind(ϕi, K), sobre cada ϕi ∈ φ, i = 1, . . . , k, se tiene que los k conjuntos de cláusulas F si formados por Ind(φ, K) podrían no tener un número mínimo de cláusulas. La reducción V arcom permite reducir el número de cláusulas en Ind(φ, K).
Así, después de obtener el conjunto de cláusulas Ind(φ, K), se reduce su cardinalidad, eliminando cláusulas subsumidas y aplicando la reducción V arcom entre cláusulas de dos diferentes conjuntos Ind(ϕi1, K) e Ind(ϕi2, K).
Este último proceso de reducción de cláusulas a través de literales complementarias y de eliminación de cláusulas subsumidas, se ejecuta en tiempo polinomial (de hecho en tiempo cuadrático) sobre la longitud inicial de |Ind(φ, K)|, ya que consistiría en ir tomando una cláusula C ∈ Ind(φ, K), y revisar si es subcláusula (como subconjunto de literales) o si hay una literal complementaria con alguna otra cláusula en Ind(φ, K) − C. Además, el resultado de la reducción mantiene la forma de una FC.
Un proceso similar a V arcom se aplicó en el cálculo de los implicantes primos de una fórmula, presentada por Quine y McCluskey [24]. En esta propuesta, los autores buscan los implicantes primos esenciales que sean necesarios y suficientes para generar la función Booleana de entrada.
Sin embargo, cuando la heurística de éste método recibe una fórmula con un gran número de variables, conduce a resultados no mínimos, por lo que se tiene que recurrir al método de Petrick con el fín de poder caracterizar la expresión mínima de la función Booleana [23].
Ejemplo 2.
Sea K = (¬p∨q∨r∨s) ∧ (¬p∨¬q) ∧ (¬p∨¬r) y φ = (¬p∨¬s∨¬t) ∧ (q∨¬r∨¬s∨¬t) ∧ (¬p∨q∨r∨¬s∨t) ∧ (¬p), probar que K ⊨ φ, es equivalente a revisar si F als(φ) = {1**11, *0111, 10010, 1****} ⊆ F als(K) = {1000*, 11***, 1*1**}. En cada celda de la Tabla 2, se va calculando Ind(ϕi, Cj).
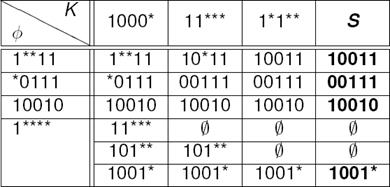
Como se puede observar en la Tabla 2, al aplicar el operador Ind(φ, K) se genera un número de cadenas mayor a las que aparecen en la Tabla 3, debido a que en la Tabla 3, antes de aplicar el operador de independencia, se ordenan las cláusulas Ci ∈ K, de acuerdo al tamaño |lit(Cj) − lit(ϕi)| de menor a mayor, dado que el número de literales de Cj diferentes con ϕi determinará el número de cláusulas independientes a generarse, además de descartar con anticipación cadenas que serán subsumidas.

Por tanto, antes de aplicar el operador Ind(ϕi, K) es conveniente ordenar las cláusulas en K de acuerdo al valor de cada ϕi que se esté considerando, tal y como se muestra en la Tabla 3. Con lo que se obtiene una estrategia de reducción sobre el número de cláusulas independientes a generar. Al aplicar el proceso de reducción de cláusulas vía literales complementarias, se tiene como resultado para el caso del ejemplo 2, que S = {1001*, 00111}, cuya FC es F s = (¬p ∨ q ∨ r ∨ ¬s) ∧ (p ∨ q ∨ ¬r ∨ ¬s ∨ ¬t). Así, K′ = K ∧ F s = (¬p ∨ q ∨ r ∨ s) ∧ (¬p ∨ ¬q) ∧ (¬p ∨ ¬r) ∧ (¬p ∨ q ∨ r ∨ ¬s) ∧ (p ∨ q ∨ ¬r ∨ ¬s ∨ ¬t).
5. Postulados KM
Katsuno y Mendelzon (KM) unificaron los diferentes enfoques semánticos que un operador de revisión de creencias debería cumplir [16]. Presentamos aquí el análisis de estos postulados sobre nuestra propuesta de operador de revisión de creencias K′ = K ◦ φ = K ∧ Ind(φ, K).
Consideremos ahora los postulados KM.
◼ (R1) K ◦ φ ⊨ φ.
◼ (R2) Si K ∧ φ es satisfactible entonces K◦φ ≡ K ∧ φ.
◼ (R3) Si φ es satisfactible, entonces también lo es K ◦ φ.
◼ (R4) Si K1 ≡ K2 y φ1 ≡ φ2, entonces K1 ◦ φ1 ≡ K2 ◦ φ2.
◼ (R5) (K ◦ φ) ∧ γ ⊨ K ◦ (φ ∧ γ).
◼ (R6) Si (K ◦ φ) ∧ γ es satisfactible entonces también K ◦ (φ ∧ γ) ⊨ (K ◦ φ) ∧ γ.
El teorema 1, muestra que nuestro operador de revisión de creencias cumple el postulado R1. Si K ∧φ es satisfactible y K ⊨ φ, entonces cada ϕi ∈ φ se infiere de K y por tanto, Ind(ϕi, K) = ϕi, i = 1, . . . , k. Así, K ◦ φ = K ∧ Ind(φ, K) = K ∧ φ, cumpliéndose el postulado R2.
Analicemos el cumplimiento del postulado R3. Este se cumple si K ◦ φ es satisfactible (por R2). Pero si F als(K) ∪ F als(Ind(φ, K)) cubriera a todo el espacio de asignaciones: 2n, entonces sólo en este caso se redefine K ◦ φ. Por ejemplo, si K = (p∨q)∧(p∨¬q) y φ = (¬p), como φ es independiente con cada cláusula de K, se tendría que K◦φ = (¬p) ∧ (p∨q) ∧ (p∨¬q), que claramente es una fórmula insatisfactible.
Bajo estas circunstancias de comprobación de que (K ∧ Ind(φ, K)) es insatisfactible, se redefine K ◦ φ para que cumpla R3. Se redefine K ◦ φ = ((K ∧ Ind(φ, K))-Cj), seleccionando la cláusula Cj ∈ K con la menor información (note que |SAT (Cj)| es mínimo sobre la cardinalidad del conjunto de modelos de cada Cj ∈ K, si |Cj| es máximo en K), y de esta forma se mantendría la satisfactibilidad del resultado de la revisión de creencias.
Los postulados R4 y R5 se cumplen debido a que nuestro operador de revisión es cerrado sobre las formas conjuntivas. Por ejemplo, si consideramos dos diferentes KB; K1 ≡ K2, y dos subfórmulas φ1 ≡ φ2, se cumple que F als(K1) = F als(K2) y F als(φ1) = F als(φ2). Al trabajar nuestro método sobre los conjuntos F als(Ind(φ, K)) y al ser tanto K, φ y Ind(φ, K) FC’s, se cumple de forma directa el postulado R4.
Veamos que se cumple R5 (K ◦ φ) ∧ γ ⊨ K ◦ (φ ∧ γ). Consideremos: K ◦ (φ ∧ γ) = K ∧ Ind(φ ∧ γ, K) por definición del operador (◦), K ◦ (φ ∧ γ) = K ∧ Ind(φ, K) ∧ Ind(γ, K) por definición del operador Ind y puesto que tanto φ como γ son FC’s. Entonces, K ◦ (φ ∧ γ) = K ∧ S ∧ Ind(γ, K) con S = Ind(φ, K). Por otro lado, F als(K ◦ (φ ∧ γ)) = F als(K ∧ S ∧ Ind(γ, K)) = F als(K ∧ S) ∪ F als(Ind(γ, K)) = F als(K◦φ)∪F als(Ind(γ, K)) ⊆ F als(K ◦ φ) ∪ F als(γ), por el Corolario 1. Así, F als(K ◦ (φ ∧ γ)) ⊆ F als(K ◦ φ) ∪ F als(γ) = F als((K ◦ φ) ∧ γ) cumpliéndose R5.
(R6) Si (K ◦ φ) ∧ γ es satisfactible, entonces K ◦ (φ ∧ γ) ⊨ (K ◦ φ) ∧ γ. Sea F als((K ◦ φ) ∧ γ) = F als(K ∧ Ind(φ, K) ∧ γ), pero (γ) sólo sería igual a Ind(γ, K) sí y solo si γ fuera independiente con cada cláusula de K, y entonces sólo en ese caso se tiene que F als(K ∧ Ind(φ, K) ∧ γ) = F als(K ∧ Ind(φ, K) ∧ Ind(γ, K)) = F als(K ◦ (φ ∧ γ) y así se cumpliría el postulado R6.
6. Análisis de complejidad en tiempo
La función que mide el tiempo de nuestro operador de revisión de creencias K ◦ φ, que denotaremos como: T0(|φ|, |K|), depende principalmente del tiempo de ejecución del operador de independencia: Ind(φ, K). Y como Ind(φ, K) se obtiene del cálculo iterativo de Ind(ϕi, K), ∀ϕi ∈ φ, entonces el tiempo de construcción para Ind(φ, K) depende del tiempo máximo que requiere algún Ind(ϕi, K), ϕi ∈ φ.
Como se presentó en la sección del diseño del algoritmo 1, la complejidad en tiempo del proceso Ind(ϕi, K) es de orden O(|K| · n · f(|ϕi|, |K|)), donde f(|ϕi|, |K|) es una función entera, que dada una cláusula ϕi y una FC K, determina el número de cláusulas que regresará el proceso Ind(ϕi, K). Analicemos ahora, el número máximo posible de cláusulas que se pueden generar a través del proceso Ind(ϕi, K).
En algunos casos, Ind(ϕi, K) puede generar conjuntos nulos (cuando ∃ Cj ∈ K, tal que Cj ⊨ ϕi), pero en los peores casos, la complejidad en tiempo del cálculo de Ind(ϕi, K), dependerá de la longitud de los conjuntos: Sij = {x1, x2, . . . , xp} = lit(Cj) - lit(ϕi), j = 1, . . . , m.
Como se hizo notar en el ejemplo 2, fija una ϕi ∈ φ, es conveniente ordenar las cláusulas Cj ∈ K de acuerdo a la cardinalidad de los Sij, j = 1, . . . , m de menor a mayor, y eliminando de este ordenamiento las cláusulas que sean independientes con ϕi. Una vez ordenadas las cláusulas en K en función a la longitud de Sij, se va aplicando el operador Ind(ϕi, Cj), j = 1, . . . , m, determinándose así, la sucesión:
Si0 = v(ϕi)
Si1 = v(C1) - v(ϕi)
Si2 = v(C2) - (v(C1) ∪ v(ϕi))
. . .
Sim = v(Cm) - (v(Cm−1) ∪ . . . ∪ v(C1) ∪ v(ϕi)).
El número de cláusulas que se generan por Ind(ϕi, C1) sería |Si1|, y para Ind(ϕi, C2) se podría tener en el peor caso, hasta |Si2| nuevas cláusulas por cada una de las cláusulas generadas en Ind(ϕi, C1), y así sucesivamente. Para Ind(ϕi, Cm), habría a lo más |Sim| posibles cláusulas que se pueden generar por cada una de las anteriores cláusulas en Ind(ϕi, Cm−1).
Esto nos genera un proceso multiplicativo sobre el número de cláusulas en Ind(ϕi, K), dado por: 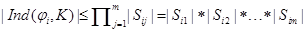 y bajo la restricción
y bajo la restricción 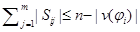 , ya que cada conjunto Sik cubre el espacio de asignaciones formado por las variables que no ha sido cubierto por las variables de las Cj, j = 1,. . ., k−1 y las variables de ϕi, y en todo este proceso no puede cubrirse más de n − v(ϕi) variables.
, ya que cada conjunto Sik cubre el espacio de asignaciones formado por las variables que no ha sido cubierto por las variables de las Cj, j = 1,. . ., k−1 y las variables de ϕi, y en todo este proceso no puede cubrirse más de n − v(ϕi) variables.
De hecho, si algún Sij = ∅, entonces el conjunto de cláusulas en Ind(ϕi, K) es también vacío, indicando que el K actual no cambiará al considerar tal ϕi y entonces Qmj=1| Sij ⊨ 0.
Cuando no hay cláusulas independientes con ϕi, ni ningún Sij = ∅ para j = 1, . . . , m, entonces la complejidad en tiempo para calcular Ind(ϕi, K) es acotado por su número de cláusulas, en otras palabras, se tiene que |Ind(ϕi, K)| ≤ |Si1| * |Si2| * . . . * |Sim| * P oly(n). Donde P oly(n) resume un tiempo polinomial sobre el número de variables que se genera de aplicar el operador Ind(ϕi, Cj) y por aplicar el ordenamiento inicial sobre las cláusulas de K.
Es claro que el valor |Ind(ϕi, K)| no puede ser mayor al número de asignaciones que están en F als(ϕi) − F als(K), ya que de hecho, se está cubriendo este espacio de asignaciones vía cláusulas independientes. Esto significa que |Si1| * |Si2| * . . . * |Sim| ≤ 2(n−|ϕi|).
Podemos inferir entonces que la complejidad en tiempo T0(|φ|, |K|) para nuestro operador de revisión de creencias, en el peor de los casos, esta acotado superiormente por Max{|Si1| * |Si2| * . . . * |Sim| : ∀ϕi ∈ φ}, suprimiendo factores polinomiales sobre n (el número de variables) y sobre el tamaño de la KB K. A su vez, este valor máximo está acotado superiormente por 2(n−min{|ϕi|:ϕi∈φ}). Cumpliéndose entonces que: T0(|φ|, |K|) ≤ Max{|Si1| * |Si2| * . . . * |Sim| : ∀ϕi∈φ} ∈ O(2(n−min{|ϕi|:ϕi∈φ})). Y por tanto, la complejidad en tiempo de nuestra prouesta es de O(|K| · n · 2(n−min{|ϕi|:ϕi∈φ})).
7. Conclusiones
Un problema fundamental del razonamiento automático en el cálculo proposicional y de los sistemas inteligentes en general, es el problema de revisión de creencias.
En este trabajo se presenta un método novedoso para construir K′ = K ◦ φ, a partir de considerar que K y φ son FC’s. Como K y φ son FC’s, el proceso de revisión entre K y φ se va reduciendo a realizar la revisión entre cada ϕi de φ y cada Cj de K, simplificando el problema total de revisión en resolver los |K| * |φ| subproblemas de revisión entre dos cláusulas.
Se construyó un operador lógico llamado Ind(ϕi, Cj), que encuentra las cláusulas que cubren el espacio de asignaciones faltantes para que se cumpla que: F als(ϕi) ⊆ F als(Cj) ∪ F als(Ind(ϕi, Cj)), al iterar este proceso sobre todo ϕi ∈ φ, y cuidando reducir clásulas complementarias, encontramos un proceso efectivo para la revisión de creencias entre formas conjuntivas.
Se demuestra la corrección de nuestra propuesta de revisión de creencias, la verificación de cumplimiento de los postulados KM, así como el análisis de la complejidad en tiempo de los procesos involucrados en nuestro método.

