











 text new page (beta)
text new page (beta) English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink1 Introduction
Named Entity Recognition (NER) is an essential task for natural language understanding to identify the names in a given sentence. A Named Entity (NE) primarily refers to the name of a person, location or organization, but sometimes a larger set of names have to be considered. The set of names used in NER is often considered as the NE tagset. In sum, NER is a multi-class classification problem.
A lot of work has been done in the area of NER 23.1 Researchers primarily use machine learning-based techniques to address the NE classification task Almost all the work in this area of research requires a substantial amount of linguistic expertise. The linguistic information is required either to produce linguistic rules for a rule-based system or to produce NE-annotated data to train a statistical model.
The performance of a machine learning-based NER system depends on the amount of data used to train the system and the features used to build the model. Some languages of the world have large amounts of annotated data to train a reasonably good NER system. However, there remain a number of languages which suffer from the scarcity of large NE-annotated data. In fact, training data for NER only exists for restricted combination of domains and genres (e.g. written news) even for the most resource-rich languages.
In this work, we use information from a resource-rich language (English) to improve the NER task of a relatively less-resourced language (Hindi). Although a large amount of NE-annotated data is not always readily available for a language, a large amount of parallel data may exist between that language and English to obtain cross-lingual information without needing to avail of linguistic expertise. If such parallel text is unavailable, a large number of third party freely available MT systems might be found between the less-resourced language and English. For example, Google Translate2 and Bing translator3 includes 8100 and 2704 possible source-target translation systems, respectively. In our work, first we adopt Google Translate to translate the Hindi NE-annotated text into English. Furthermore, we use an English language NE recognizer to identify different NE tags in the translated English text. English NER has a very high accuracy 12. We incorporate English NER information into different features of the source Hindi word using alignment information. Finally, we use these cross-lingual features along with monolingual features to build our NER model.
The rest of the paper is organized as follows. The next section presents related research in the area. Section 3 details our particular approach. Section 4 describes the cross-lingual feature extraction process with an illustrative example. Section 5 presents the experimental set-up, the data and the results obtained from the different experiments conducted. Section 6 presents our observations along with an error analysis. We conclude in Section 7 with some avenues for future work.
2 Related Work
Prior work on NER mostly use either a rule- based 14 or a machine learning (ML·) approach 4,18,27,11, with the ML-based approach being by far the most prevalent of the two. A wide range of ML techniques are used for NER of which Hidden Markov Model (HMM) (4), Maximum Entropy (MaxEnt) 5, Conditional Random Field (CRF) 18 and Support Vector Machines (SVM) 11 are quite popular. Researchers have also applied hybrid approaches for the NER task 27. The ML-based techniques primarily rely on the NE-annotated text as its main knowledge-base. However, researchers often use additional source of knowledge such as gazetteer lists or grammatical information within a ML technique 4,5,27.
More recently, the focus of NER has shifted to multilingual NER. Richman and Schone 24 proposed a technique to build large multilingual NE-annotated data from Wikipedia using the underlying multilingual characteristics. Researchers also have been using parallel data to improve NER systems. Developing annotated data (NE, part-of-speech (POS) etc.) involves a lot of time, money and other resources. In contrast, parallel data may be available for many language pairs due to the rapid growth of multilingual content on the web. Yarowsky et al. 30 used bilingual text corpora and English text analysis tools for automatic NE-tagging in a foreign language. Kim et al. 17 used a combination of Wikipedia metadata and English-foreign language parallel Wikipedia sentences to produce NE-labelled multilingual data. Parallel data has also been used to improve monolingual natural language processing (N؛P) models 7 or to improve models for both languages simultaneously 6. Parallel data has also been used in unsupervised NLP models using a projection from the resource-rich language to the resource-poor language 9,29.
Resource-poor languages may not have publicly available parallel data (between the resource-poor and a resource-rich language) to help in NLP tasks. Thus instead of using parallel data, we use MT systems to translate the resource-poor language into a resource-rich language sentence in order to use the information from the resource-rich language (26). Note that compared to (say) European language pairs, MT is still in its infancy and the quality is still poor for the language pair English-to-Hindi. Thus we are projecting information from noisy parallel data to try to improve NER performance.
Basic NLP tools are often used to improve translation quality 28,15. NER is used within an MT framework to improve the MT system by transliterating the names or by using a fixed translation for the names 1,16. Significant research work was carried out to improve MT quality using NER. However, very little work has been done in the reverse direction, i.e. to improve NER using MT.
Shah et al. 26 used machine-translated data to develop an NER system (SYNERGY) for Swahali and Arabic. They use an online MT system to translate the Swahali text into English, and English NER to find list of NEs in English. Furthermore, different alignment techniques were used to map Swahaliwordstothe English NEs. Our approach is similar to their work with the following differences: (i)SYNERGY uses only two NE classes (name and not name) while we use 15 different NE classes, and (ii) we use translated text to adopt cross-lingual features into a classification problem, while SYNERGY uses purely projection-based techniques to build an NER system.
A significant amount of work has been done previously on NER for Hindi. Hindi is the main language spoken in India, and the fourth most commonly spoken language in the world. Most of this research uses machine learning-based techniques and different monolingual features to build an NER system 11,25. Some recent work has developed an NER system using customizable rules automatically created via rule induction 21. However, no work has ever used cross-lingual features using either parallel data or an MT system to reduce the data sparsity problem of Hindi. Recently conducted NLP tool contests4 on NER report very low accuracy for Hindi NER using 15 NE classes, with the wining team achieving an accuracy of just 77 4%
3 Our Approach
The NER task can be formally defined as follows: given a sentence S = w 1 ...w n , we want to find the possible NE tag t i for each word w i in S. The NE tag for a particular word w i is assigned from a predefined NE tagset T. Thus, NER can be considered as a classification problem or a sequence-labelling problem. We use an SVM model 8 to build our NER system. SVM is a discriminative model of learning which uses both positive and negative examples to learn the distinction between two classes. Like all other discriminative approaches, an SVM model also uses feature vectors for each training instance to learn the classifier. In our approach, we use the YamCha5 toolkit to train the model and to classify new instances. We used TinySVM6 within YamCha for NER training and classification. In this paper, we do not aim to explore the best configuration of the SVM classifier; rather we explore how an MT system can be used to improve state-of-the-art NER systems.
3.1 System Architecture
In our system, we use both monolingual and cross-lingual features to build the SVM model.
Monolingual features are estimated from the NE-annotated data (cf. Section 3.2).
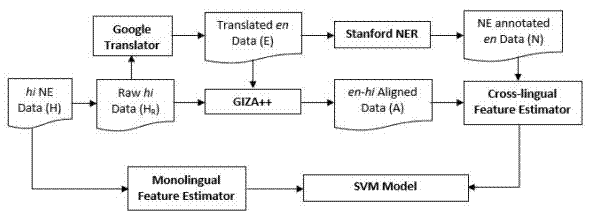
Central to our approach is the Cross-lingual Feature Estimator,
as shown in Figure 1. We use Google
Translate, the Stanford English NER toolkit7, 12 and an unsupervised word aligner GIZA++ 22 to estimate the cross-lingual
features. First, we extract the raw Hindi text (H
r
) from the Hindi NE-annotated data (H). Google Translate
is used to translate the Hindi text H
r into English (E). The unsupervised word aligner GIZA++ takes both
the corpus H
r
and E, and produces an alignment (a: i
→ j) between each pair of sentences: the Hindi sentence h
3.2 Monolingual Features
We use state-of-the-art monolingual features which are often used for Hindi NER 25 including both static and dynamic features. The static features include information from words and POS context The static features also include prefix and suffix information for all words. The term prefix/suffix is a sequence of the first/last few characters of a word, which does not necessarily imply a linguistically meaningful prefix and suffix. The dynamic features include the NE tags of the previous two words. Table 1 lists all the features used in our SVM model A combination of these features is used to conduct two baseline experiments for the NER task.

3.3 Cross-lingual Features
We use cross-lingual features along with mono lingual features to improve the NER task. The cross-lingual features are extracted from a resource-rich language for which we already have a reasonably good NER system. In our case we consider English as the resource-rich language. In our approach, we assume the availability of an MT system from the language of interest into the resource-rich language. We adopt the Google Hindi-to-English MT system.
It is important to note that the correctness of the cross-lingual features largely depends on the translation quality of the MT system. We could not conduct the automatic evaluation to estimate the translation quality for our particular data as we do not have reference translation for the NE annotated corpus, so we carried out a small human evaluation. While manually evaluating the MT systems, we assign values from two five-point scales representing fluency and adequacy20. We performed a manual evaluation of randomly selected 100 sentences of the Hindi-to-English MT output by 2 evaluators. The average fluency and adequacy for the Hindi-to-English MT output are 2.69 and 2.73, respectively (inter annotator agreement 13 of 0.51 and 0.46, respectively). This indicate the overall translation quality is still in infancy for Hindi-to-English MT however, much of the meaning is conveyed by the MT system 20.
During cross-lingual feature extraction, we try to find whether the translation of a Hindiword belongs to a particular NE in the resource-rich language. Note that a Hindi word may correspond to several words in English as in example (1). Thus we consider cross-lingual features as a vector of integers(=count) to accumulate cues from English. If the translation of the Hindiword belongs to a particular NE then that information is projected into the feature vector. It is likely that NEs remain in the same class across languages. The main issue is that the aligner (GIZA++) may not find the correct alignment. Thus, cross-lingual projections are used as features where otherwise English NEs could have been used as NE tags for the Hindi words; indeed, in Section 5 we use such a model to demonstrate indicative performance.
Another issue is that the number of tags may differ between two languages. Our cross-lingual features use the number of NE tags available in the resource-rich language regardless of the number of tags available in the Hindi NE-annotated data, i.e. the number of features is equal to the number of tags available in English. We use two variants of the Stanford NE recognizer which uses 4 and 7 NE classes and accordingly generates 4 and 7 cross-lingual features in our system, respectively. The detail of our cross-lingual feature extraction process is given in Algorithm 1 when using 4 cross-lingual features.

Lines 1-2 of the algorithm translate raw Hindi sentences from the NE-tagged data into English (E) using Google Translator and aligns HR with E. In line 4, we estimate the NE-tags for an English sentence e. In steps 5-7, we find the English words that map to a source Hindiword and initialize the feature vector to all 0s. In steps 8-10, we update the feature vector based on the NE tags associated with the mapped English words using the OR operation (in line 9). This is to ensure that if any of the mapped English words (in case of multiple words aligned to a single Hindi word) indicate an NE tag, we consider that the Hindiword is likely to belong to the same NE category.
4 An Illustrative Example
We describe below the cross-lingual feature extraction process with a running example from our corpus. Consider the HindiNE-tagged sentence from the annotated corpus in (1a). All the words are represented in word/POS-tag/NE-tag format. Expansion of POS tags can be found in 3.
The Hindiraw sentence from (1a) is translated into English in (1b) and aligned in (1c). Note that (1b) is a machine-translated sentence.

The Hindi sentence in (1c) is listed word by word with reference to the aligned English word(s) in e. For example, the word  ({ 1 })’ is aligned to the first English word Anushka, the word
({ 1 })’ is aligned to the first English word Anushka, the word ({ })’
({ })’
is not mapped to any English word and ‘ ({4 5 7 })’ is mapped to three English words {much{4}, like{5} and Brazil{7}}.
({4 5 7 })’ is mapped to three English words {much{4}, like{5} and Brazil{7}}.
The NE-tagged output using the Stanford tagger is shown in (2) for the translated English sentence in (1b). Example (2) represents the sentence with word/NE-tag format where ‘O' indicates not a name.
(2)N: Anushka/PERSON is/O very/O much/O like/O particularly/O Brazil/LOCATION ./O
For each word in hi, we initialize the cross-lingual feature vector to 〈0,0,0,0〉 based on step
6 of Algorithm 1. The four fields of the
feature vector indicate (Is Person?, Is Location?, Is Organization?, Other NE?) (4
NE tags of the Stanford tagger). For example, initially  ≡ 〈0,0,0,0〉 and
≡ 〈0,0,0,0〉 and  ≡〈0,0,0,0〉. Based on (2), the
word
≡〈0,0,0,0〉. Based on (2), the
word  is projected
to ‘Anushka/PERSON’ using the mapping from (1c). Thus the word
is projected
to ‘Anushka/PERSON’ using the mapping from (1c). Thus the word  is a potential candidate for
PERSON name and we update the feature vector to 〈1,0,0,0〉. Similarly, the word
is a potential candidate for
PERSON name and we update the feature vector to 〈1,0,0,0〉. Similarly, the word
 is mapped to
three words (much, like and Brazil). We find only one of these words (Brazil)
belongs to LOCATION type and the remaining two words (much and like) are not NEs.
Thus the cross-lingual feature vector for the word
is mapped to
three words (much, like and Brazil). We find only one of these words (Brazil)
belongs to LOCATION type and the remaining two words (much and like) are not NEs.
Thus the cross-lingual feature vector for the word  is 〈0,1,0,0〉. Note that more
than one field in the feature vector can be ‘1’ if the mapped English words point to
different NE types. We combine the above cross-lingual features with monolingual
features to produce the training instances for the SVM-based classifier.
is 〈0,1,0,0〉. Note that more
than one field in the feature vector can be ‘1’ if the mapped English words point to
different NE types. We combine the above cross-lingual features with monolingual
features to produce the training instances for the SVM-based classifier.
5 Experimental Set-up
First we conduct two different experiments to estimate the baseline accuracy of our approach for the Hindi NER task. We use two different sets of monolingual features to train the baseline systems and compare the results with our cross-lingual feature-based approach. The following are the feature vectors for the two baseline systems:
Baseline1: {w i , w i-1 , w i-2 , wi+1, wi+2, pi,
|pref| ≤ 4, |suff| ≤ 4, t i-1 , t i-2 }
Baseline2: {wi, wi-1, wi-2, wi+1, wi+2, pi, pi-1,
pi-2, |pref| ≤ 4, |suff| ≤ 4, t i-1 , t i-2 }
We conduct the second set of experiments adding the cross-lingual features (cf. Section 3.3) with the monolingual features used in the two base line experiments. We call them Baseline i+ CL. We conduct two different experiments within the Baseline i+ CL experiments.
-. We use 4 different cross-lingual features (〈 Is Person?, Is Location?, Is Organization?, Other NE? 〉) (cf. Algorithm1) based on the 4 different NE classes of the Stanford English NER. We call this system Baseline i+ CL-4. Note that, the Hindi NE-data has 15 different NE classes.
-. Moreover, instead of considering only 4 classes, we consider the 7 NE-tags from the Stanford NE recognizer to annotate the English text. This generates a feature vector of size 7. The four additional features included here are 〈 Is Money?, Is Date?, Is Time?, Is Percent? 〉 and there is no Other NE type. We anticipate that the use of a larger number of classes for the English NER will help to improve the Hindi NER task using 15 NE types. We call this system Baseline i+ CL-7.
Furthermore, we assume that an equal number of NE-tags for both Hindiand English may have a higher impact while projecting information from the resource-rich to the resource-poor language. Thus, we merge the 15 NE classes from Hindi into the 4 classes (Person, Location, Organization and Others) of the Stanford NER tool. This gives us equivalent tagsets for both the Hindi task and the Stanford tagger. We conduct a third set of experiments using the 4 cross-lingual features and using 4 NE classes for Hindi. We call this experiment Baseline i+ CL-4 eq. Note that the Baseline systems also change (in accuracies) in this setting.
Finally, we conduct another experiment to understand the performance of the direct projection of NEs between two languages based on GIZA++ alignment. This indeed justify the need of using cross-lingual features in a classifier instead of directly identifying NEs based on the alignment. This direct mapping require equal number of NE types between two languages. The number of NE classes in Hindi NER task is different from the Stanford English NE recognizer. Thus we conduct this experiment only in the CL-4eq setup, where English and Hindi NEs refer to an equivalent tagset of 4 NE types. We shall call this Projection Baseline. In this process, we assign the most likely NE type to a Hindi word based on the alignment information and the English NEs corresponding the alignment. If multiple NE types are equally likely for a Hindiword based on alignment function and English-side NE types, we randomly select one from them.
5.1 Data
For all experiments we used the Hindi NER data from ICON2013 NLP tools contest.8 The training data consists of 3,583 sentences (approximately 70k words). We used 449 sentences from IC0N2013 test data to evaluate our system. The test data contains a total of 630 NEs. All the data is represented in ShaktiStandard Format (SSF) 2. For our experiments, we transformed the data from SSF to BIO format where B-X indicates the first word of an NE type X, I-X indicates the intermediate word of an NE type X and O indicates a word outside a NE. Note that the best reported system performance achieved for Hindi in the IC0N2013 contest with this data set is 77.44% 10 using both linguistic and word-based features along with a gazetteer list and post-processing rules.
6 Results and Observations
We measure tagging accuracy in terms of Precision, Recall and F1 score. F 1 -score is the armonic mean of precision and recall: F 1 = 2.precision.recall/(precision + recall). Table 2 shows the results obtained with different systems for the first two sets of experiments. We evaluate our NER systems using the C0NLL-20009 shared task evaluation strategy. Table 3 shows the accuracy obtained from ourthird set of experiments using an equal number of NE classes for Hindi and English.


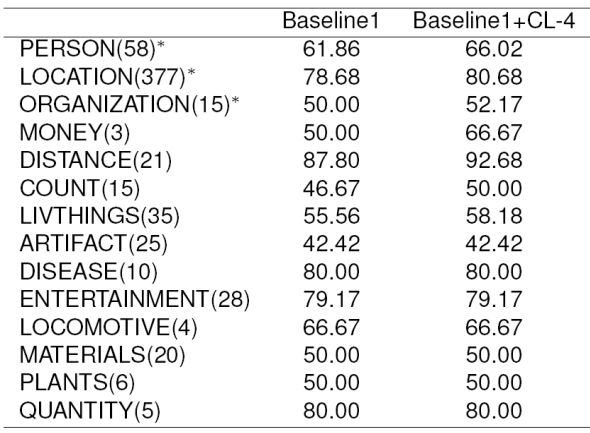
The effect of cross-lingual features on different NE classes is given in Table 4. We compare the Baseline1 system with the Baseline1+CL-4 system.
Table 4 Comparison of F1-score for different NE types. The first column represents different NE tags and their frequency in the test data. ‘*’ indicates the NE types that are common between the Hindi task and English NER.
6.1 Summary of the Results
We found that the inclusion of cross-lingual features projected from a resource-rich language improves the NER accuracy (cf. Table 2). We found that Baseline1+CL-4 gives an improvement of 2.08 points F1-score over the Baseline1 model (2.9% relative). Furthermore, when a larger monolingual feature set is used in Baseline2 model, we found an improvement of 0.85 points (1.1% relative) in F1-score in Baseline2+CL-4 system.
The use of 7 NE types gives an improvement of 1.17 points (1.6% relative) and 0.52 points (0.7% relative) F1-score for Baseline1+CL-7 and Baseline2+CL-7 system, respectively, compared to their relative baseline scores. These improvements are lower compared to the improvement from Baseline1+CL-4 and Baseline2+CL-4 systems.
In Table 4, we find that there are significant improvements in F1-score for PERSON, LOCATION and ORGANIZATION types. These three NE types are common in both the Hindi NE tagset and Stanford 4 NE tags. Note that 71% of the NEs in the test document belong to these three NE types. Thus an improvement in these three NE types gives a significant improvement in the overall accuracy. Only 4 tag types (MONEY, DISTANCE, COUNT and LIVTHINGS) show some improvement out of a total of 11 tags that are not common between the two tagsets. However, these tags occur less frequently in the corpus compared to PERSON and LOCATION. Thus these tags have a lesser contribution to the overall accuracy. Most interestingly, we found that the accuracy does not drop for any of the tag type.
We expected the use of an equal number of tags in both the resource-rich and resource-poor language to improve NER accuracy. This is refiected in Table 3. We found 2.07 points (2.8% relative) and 0.50 points (0.6% relative) improvement in F1-score with Baseline1+CL-4eq and Baseline2+CL-4eq systems, respectively, com pared to the relative baseline system. This improvement is comparable to the improvement we obtained in our second set of experiments (cf. Table 4). Note that the direct projection of NEs has very low score (F1=33.04%) which essentially indicates direct cross-lingual projection is not effective for NE recognition in Hindi using English-to-Hindi MT system. Altogether, in all our experiments we found that use of cross-lingual features projected from the resource-rich language to the resource-poor language improves the NER accuracy regardless of the feature set used.
6.2 Assessment of Error Types
Errors are propagated mostly due to errors in the GIZA++ alignment and incorrect NE recognition in the English text. Due to alignment errors, some potential Hindi NE words do not map to the actual corresponding word in the English sentence. This produces misleading features for the wrongly aligned Hindiword. In example (3b), the word  does not map to any word in (3a) despite the correct aligning word (Bombay) being present in e.
does not map to any word in (3a) despite the correct aligning word (Bombay) being present in e.
(3) a. e: Royal Bombay continued into the 20th century .

Sometimes the potential Hindi NE word is aligned to the correct word in the translated English sentence e but the English NER produces an incorrect NE tag for the English word. In example (4b) the word  . is mapped to the correct English word Diu in (5a) but the Stanford NER marks it as Diu/O (not a name).
. is mapped to the correct English word Diu in (5a) but the Stanford NER marks it as Diu/O (not a name).
(4) a. e: It/O is/O also/O the/O story/O of/O Diu/O./O

Finally, we use an MT system to translate the Hindi sentence into English. The translation system sometimes fails to produce an accurate enough translation to allow the correct translated word to be found for a given potential Hindi NE word.
7 Conclusion
Our experiments show that MT systems can be used to project information from resource-rich languages to resource-poor ones. These projections can be used as cross-lingual features in the classification problem. We have shown that NER for a resource-poor language Hindi can be improved using a Hindi-to-English MT system and English NER. Our best performance improvement results in 2.1 (2.9% relative) F1 score improvement over the baseline.
So far our system has been tested for just one classification problem, namely NER. In order to test the effectiveness of our approach, we plan to use our approach for other NLP classification problems (viz. POS labelling, NP chunking). We have tested our approach using one learning algorithm and we plan to test our approach over a wide range of classification algorithms using state-of-the-art features. We also plan to use different word aligners (e.g. (19)) to compare the effect of alignment in our work.

