











 text in
text in  English (pdf)
English (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
PermalinkIntroducción
Las sequías son un desastre ambiental y atraen la atención de ambientalistas, hidrólogos, meteorólogos, geólogos y científicos agrícolas. Las sequías ocurren en todas las zonas climáticas, tanto de mucha como de poca lluvia y están relacionadas con la reducción de lluvia sobre un periodo largo de tiempo, como una estación del año o un año entero (Mishra y Singh, 2010) o hasta 2 o 3 años. En años recientes hay una frecuencia mayor de valores extremos que causan sequías o inundaciones. La población ha crecido, la frontera agrícola ha aumentado o necesita crecer para producir los alimentos que demanda esa mayor población, se requiere una mayor producción de energía hidroeléctrica y el sector industrial demanda más agua, y el cambio climático también ha contribuido a la escasez de agua (Mishra y Singh, 2011).
El monitoreo y predicción de sequías es importante para evaluar riesgos, y tomar decisiones, acciones efectivas y oportunas para evitar y reducir sus efectos negativos. Una alerta anticipada de una sequía y con información sobre su intensidad, duración y extensión espacial es importante para establecer estrategias anticipadas de cómo enfrentar las sequías.
Dada la tendencia del incremento en la ocurrencia, intensidad y duración de los periodos secos en el mundo, es importante generar herramientas de pronóstico para estimar con anticipación el estado futuro de las condiciones hídricas. Las investigaciones del comportamiento de las sequías pueden ayudar en los planes de alerta a través de herramientas indirectas de pronóstico mediante los índices de sequía (Mishra and Singh, 2010; Al-Qinna et al., 2011; Beguería et al., 2014). Las sequías pueden ser de cuatro tipos: meteorológica, hidrológica, agrícola o socioeconómica (Mishra and Singh, 2010) y existen varios índices de sequía para cada una de ellas. Nuestro estudio se centra en las sequías meteorológicas, definida como una ausencia de precipitación sobre una región y la cuenca de estudio es la cuenca del río Fuerte, en el Noroeste de México. El estudio de las sequías, al menos debería tener una fase de análisis de sequías a través de los índices de sequía (Castillo et al., 2017) y una fase de pronóstico a través de varios modelos. Según Mishra and Singh (2011), los principales modelos de pronóstico son: 1) regresión lineal, 2) series de tiempo, 3) modelos probabilísticos, 4) redes neuronales artificiales, 5) modelos híbridos, y algunas técnicas novedosas como “minería de datos”. La sequía más estudiada es la meteorológica, quizá por la amplia disponibilidad de datos de precipitación en el mundo y entre los índices de sequía meteorológica más estudiados está el SPI (Standard Precipitation Index) y el SPEI (Standard Precipitation Evapotranspiration Index). Los siguientes estudios sobre pronóstico de sequías meteorológicas e hidrológicas con diversas técnicas son destacables: 1) Rhee e Im (2017), pronóstico de SPI y SPEI con “machine learning”; 2) Mossad y Alazba (2015), pronóstico de SPEI con series de tiempo AR y ARIMA; 3) Eicker et al. (2014) con el filtro de Kalman tipo “ensemble” para pronosticar balance hidrológico a grandes escalas territoriales; 4) Dehghani et al. (2014) realizando pronóstico de caudales con redes neuronales y simulación Monte Carlo; y, 5) Madadgar and Moradkhani (2013), pronostico estacional de sequías hidrológicas, índice de caudal, con enfoque probabilístico.
En México hay pocos estudios sobre el pronóstico de sequías. Ravelo et al. (2014) estudiaron detección, evaluación y pronóstico de sequías en la región Organismo de Cuenca Pacífico Norte mediante redes neuronales, y concluyeron que en 2011 y 2012 se presentaron las sequías más severas. También hay estudios de pronóstico de caudales con el filtro de Kalman discreto en cuencas mexicanas (Morales et al., 2014; González et al., 2015). Además, Kim et al. (2002) analizaron sequías en la cuenca del río Conchos, pero no abordaron el pronóstico de sequías.
El objetivo del presente estudio fue realizar el pronóstico de los índices de sequía SPI y SPEI con 1, 2, 3 y 4 meses de anticipación para 14 estaciones meteorológicas de la cuenca del río Fuerte en el Noroeste de México. La hipótesis fue que es posible lograr tal objetivo mediante la implementación del algoritmo del filtro de Kalman en su variante Discreta (DKF) junto con un modelo de series de tiempo del tipo autorregresivo de segundo orden y uno con entrada exógena, probando cuatro variables climáticas (precipitación, temperaturas máximas y mínimas, y evapotranspiración de referencia).
Materiales y métodos
Descripción de la cuenca
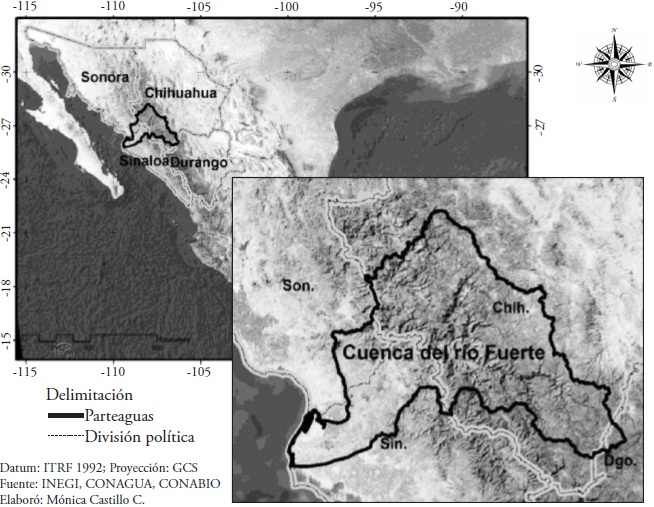
La cuenca del río Fuerte se localiza en el Noroeste de México, en los estados de Sinaloa, Sonora, Durango y Chihuahua (Figura 1), como parte de la región hidrológica No. 10 Sinaloa, entre 25.68° y 28.24° N, y 106.12° a 109.43° O, con un área de 36 456 km2. Nace en la Sierra Madre Occidental y desemboca al norte de Sinaloa en el Golfo de California; en la parte alta de la cuenca está la etnia indígena Rarámuri y es una zona de alta marginación que en la última década tuvo graves problemas debido a la sequía, y en la parte media y baja está el Valle del Fuerte que es una importante zona agrícola de producción de granos y hortalizas para el mercado nacional e internacional. Las altitudes en la cuenca van de 3168 a -9 msnm (INEGI, 2014); su precipitación media anual es de 691 mm y temperatura media de 19.4 °C, de acuerdo con las normales climatológicas de 14 estaciones dentro de la cuenca de 1961 a 2011 (SMN, 2014). La cuenca del río Fuerte es importante por su extensión superficial, el volumen de sus escurrimientos y las presas Miguel Hidalgo y Costilla, Luis Donaldo Colosio y Josefa Ortiz de Domínguez, que se usan para la generar energía eléctrica y son la principal fuente de agua para uso agrícola, urbano e industrial.
Información climatológica
La información climatológica usada para el cálculo de los índices de sequía SPI y SPEI se obtuvo de la base de datos del servicio meteorológico nacional disponible en línea (SMN, 2014), se emplearon los datos mensuales de precipitación (Pt), temperatura mínima (Tmin) y máxima (Tmax) de 14 estaciones meteorológicas durante el periodo 1961-2011, el cual fue el más completo y actualizado durante este estudio. Las estaciones seleccionadas están distribuidas por toda la cuenca; la información más incom-pleta fue la de precipitación y en promedio, se generó el 8 % de datos faltantes de lluvia (Cuadro 1). En uno de los casos más extremos, en Batopilas, Chihuahua, se generó 29 % de los datos de lluvia. Para generar los datos de lluvia se usó el método del inverso del cuadrado de la distancia, y los detalles están en un artículo en el cual se generaron los índices (Castillo et al., 2017).
Cuadro 1 Estaciones meteorológicas seleccionadas de la cuenca.
| Clave | Estación | Altitud (msnm) |
Pt. media (mm) |
T. Mín. (°C) |
T. Máx. (°C) |
Periodo | % Datos generados |
| 8038 | Creel, Chihuahua | 2348 | 648.7 | 1.7 | 20.2 | 1961 - 2011 | 10.8 |
| 8106 | Norogachic, Chihuahua | 2088 | 578.8 | 2.7 | 21.6 | 1961 - 2011 | 20.7 |
| 8161 | Batopilas, Chihuahua | 678 | 603.4 | 16.7 | 31.3 | 1961 - 2011 | 29.4 |
| 8167 | Chinipas, Chihuahua | 440 | 838.2 | 16.0 | 31.0 | 1961 - 2011 | 2.6 |
| 8172 | Guadalupe, Chihuahua | 2279 | 1083.2 | 4.0 | 22.3 | 1961 - 2011 | 2.9 |
| 8182 | Moris, Chihuahua | 754 | 627.8 | 11.0 | 29.4 | 1961 - 2011 | 3.1 |
| 8267 | El Vergel, Chihuahua | 2740 | 629.7 | 0.6 | 17.6 | 1961 - 2012 | 24.8 |
| 25009 | Bocatoma, Sinaloa | 31 | 456.6 | 17.0 | 33.0 | 1961 - 2012 | 2.6 |
| 25019 | Choix II, Sinaloa | 239 | 707.0 | 14.2 | 34.2 | 1961 - 2012 | 1.9 |
| 25025 | P. Miguel H., Sinaloa | 144 | 619.8 | 16.6 | 33.8 | 1961 - 2012 | 1.3 |
| 25042 | Higuera, Sinaloa | 10 | 307.1 | 17.3 | 31.5 | 1961 - 2012 | 7.9 |
| 25044 | Huites, Sinaloa | 269 | 812.7 | 16.4 | 34.8 | 1961 - 2012 | 2.4 |
| 25100 | Yecorato, Sinaloa | 400 | 796.1 | 13.5 | 34.9 | 1961 - 2012 | 6.1 |
| 26053 | Minas N., Sonora | 480 | 672.4 | 15.0 | 31.2 | 1961 - 2011 | 5.7 |
Metodología
La sequía meteorológica, hidrológica y agrícola están representadas por índice de sequía que es una variable para evaluar el efecto de una sequía e incluye intensidad, duración severidad y extensión espacial (Mishra and Singh, 2010). El SPI (McKee et al., 1993) es uno de los más usados para la detección y monitoreo de sequías, y se bas en la probabilidad de precipitación a cualquier escala de tiempo para cuantificar el déficit de precipitación (Velasco et al., 2004). El SPEI (Vicente et al., 2010), además de la precipitación que usa el SPI, considera la evapotranspiración de referencia (ET0) y se basa en el balance hídrico (Pt-ET0) mensual, combinando características de la sensibilidad del Palmer Drought Severity Index (PDSI) y de la simplicidad de cálculo y la naturaleza multitemporal del SPI. Es muy adecuado para detectar, monitorear y explorar las consecuencias del calentamiento global en condiciones de sequía (Vicente et al. 2010).
Los índices SPI y SPEI se desarrollaron para las 14 estaciones seleccionadas, a escalas de 3, 6, 12 y 24 meses. Las series del SPI se generaron con el programa spi_sl_6.exe desarrollado por el National Drought Mitigation Center (NDMC, 2014), y el SPEI se obtuvo con SPEI.R desarrollado por Beguería y Vicente (2014) para el programa R/RStudio. En el cálculo del SPEI se consideró el método de evapotranspiración de referencia de Hargreaves-Samani (Beguería et al., 2014). Para mayor información de la obtención de SPI y SPEI, y su interpretación como indicadores de sequía, consultar a Castillo et al. (2017), quienes detallan el proceso de SPI y SPEI en la cuenca para nuestro estudio.
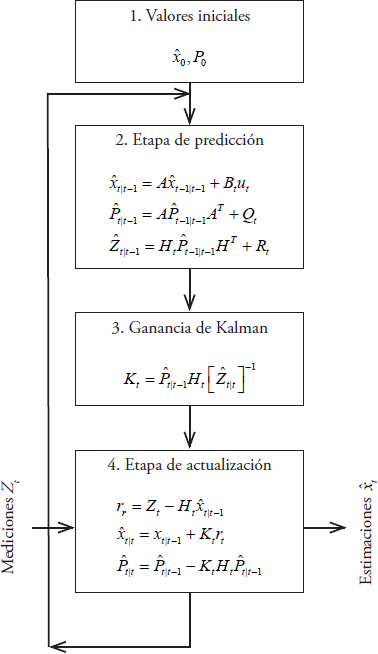
En nuestro estudio el pronóstico de sequías meteorológicas se realizó mezclando modelos de series de tiempo autorregresivos con el filtro de Kalman discreto (Kalman, 1960), que es un conjunto de ecuaciones matemáticas para estimar el estado de un proceso minimizando la media del error cuadrático. El filtro de Kalman opera por medio de un mecanismo de predicción y corrección, el algoritmo pronostica el nuevo estado a partir de una estimación previa, añadiendo un término de corrección proporcional al error de predicción, minimizándolo estadísticamente (Welch y Bishop, 2006).
Los modelos autorregresivos se usan en la hidrología y meteorología porque tienen dependencia del tiempo y son fáciles de usar (World Meteorological Organization, 2011). En nuestro estudio se propuso la creación de dos modelos autorregresivos, uno de segundo orden (AR2) y otro de segundo orden con entrada exógena (ARX) para pronosticar los estados mensuales futuros de los índices de sequía SPI y SPEI con base en los registros anteriores de la serie; la elección de modelos autorregresivos se demostrará en el Cuadro 2 de Resultados y Discusión. Los modelos AR2 y ARX (ecuaciones 1 y 2, respectivamente) relacionan la entrada del sistema con su salida mediante una ecuación lineal en diferencias con coeficientes constantes:
Cuadro 2 Resultados en el pronóstico del SPI para valores de na y nb.
| Modelo | Índice | na | Nb | MSE | RMSE | E | R | PBE |
| DKF - AR (2) | SPI 12 meses | 2 | -- | 0.15 | 0.38 | 0.848 | 0.92 | -7.4 % |
| DKF - ARX (Pt) |
2 | 1 | 0.15 | 0.38 | 0.849 | 0.92 | -7.4 % | |
| 2 | 2 | 0.10 | 0.32 | 0.888 | 0.94 | 26 % | ||
| 2 | 3 | 0.10 | 0.32 | 0.887 | 0.94 | 35 % | ||
| 1 | 2 | 0.11 | 0.32 | 0.884 | 0.94 | 35 % | ||
| 3 | 1 | 0.10 | 0.32 | 0.889 | 0.94 | 23 % | ||
| 3 | 2 | 0.10 | 0.32 | 0.889 | 0.94 | 30 % | ||
| 3 | 3 | 0.10 | 0.32 | 0.888 | 0.94 | 40 % | ||
| 4 | 1 | 0.10 | 0.32 | 0.889 | 0.94 | 20 % | ||
| 4 | 2 | 0.10 | 0.32 | 0.889 | 0.94 | 26 % | ||
| 4 | 3 | 0.10 | 0.32 | 0.887 | 0.94 | 30 % | ||
| 4 | 4 | 0.10 | 0.32 | 0.887 | 0.94 | 31 % |
donde yt es el valor observado del índice en el tiempo t, el cual representa un mes; rt es el valor de la variable exógena (Pt, Tmin, Tmax, ET0) en el tiempo t; et+1 es el término de error en la estimación del índice; αi y βi son parámetros; los índices na y nb especifican el número de observaciones previas del índice y de las variables exógenas, respectivamente. A partir de la estructura general de ambos modelos autorregresivos, la formulación en espacio de estados permite utilizarlos dentro del algoritmo del filtro de Kalman Discreto así:
donde xk+1 es el valor del índice (no observado) de tamaño (n x 1); A es la matriz de parámetros αi de tamaño (n x n); xk es el índice en el tiempo k de tamaño (n x 1); B es la matriz de parámetros exógenos βj de tamaño (n x m); vk es el vector que contiene la variable exógena registrada para el tiempo k; zk es el índice en el tiempo k de tamaño (m x 1); H es la matriz de transformación que mapea el vector de estados al dominio de la medición con dimensiones (m x n); Wk y vk son vectores que representan el ruido gaussiano en el proceso y el ruido en la medición para cada observación con tamaños (m x 1), y lo esperado es que tales ruidos gaussianos se distribuyan de manera normal con media 0 y varianzas Q y R, respectivamente:
De acuerdo con Simon (2001), se asume que no existe correlación entre Q y R, es decir, son variables aleatorias independientes y pueden variar en el tiempo, pero se suponen constantes por simplicidad, y se pueden definir como:
donde Q es la matriz de covarianza de la perturbación del sistema;
R es la matriz de covarianza de la perturbación de la
medición;
La matriz R es de (1 x 1) y contiene el error esperado de las mediciones, definido como una proporción (α) de la medición anterior, entonces R=α*(xk -1), en este caso específico α=0.001, valores mayores generan datos extremos que se ubican fuera del rango en que normalmente se presentan los valores de los índices de sequía, reduciendo el poder de predicción del modelo. Con respecto al tamaño de las matrices, el valor de n es igual a na, y el valor de m igual a nb; donde na y nb indican el número de observaciones previas del índice y de las variables exógenas, respectivamente. El algoritmo del filtro de Kalman Discreto se describe en la Figura 2.
Para crear los modelos AR y ARX se programaron rutinas en Matlab® (Math Works 2015), para obtener los valores de las matrices de parámetros en función del orden del proceso autorregresivo de acuerdo a las ecuaciones 1 y 2. El ARX también quedó como modelo autorregresivo de segundo orden pero con variable exógena.
Debido a que el comportamiento de la sequía en la cuenca varía en función de la ocurrencia de la temporada de lluvias y de fenómenos como El Niño o la Niña, entre otros fenómenos climáticos globales, los parámetros estimados para los modelos AR y ARX se recalcularon cada cierto periodo (P) para obtener pronósticos más representativos de las condiciones previas de humedad en cada estación, el pronóstico se inició en el periodo (t0 + P) hasta el tiempo (t0 + 2P), en este punto se recalcularon los parámetros de los modelos en función de periodo [P : 2P], así sucesivamente hasta terminar con el último grupo de datos. De esta forma la implementación del DKF - AR2 y del DKF - ARX se hizo dinámica e incorporó los cambios climáticos que se produjeron en la cuenca durante el periodo de estudio cada temporada o cierta época.
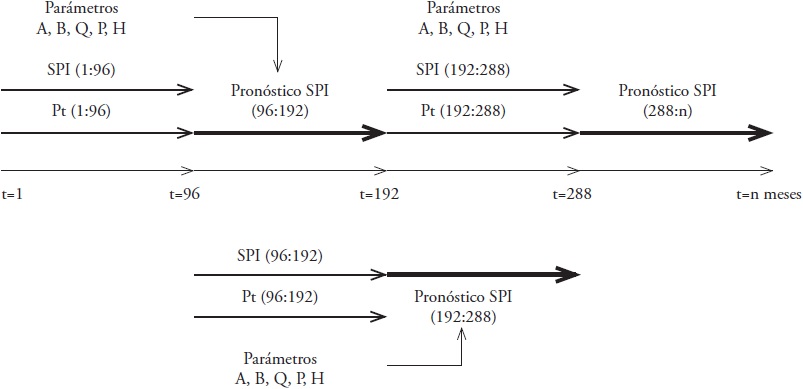
El pronóstico de los índices SPI y SPEI se realizó a cuatro escalas temporales para cada estación, y se implementaron los modelos AR2 y ARX (Pt, Tmin, Tmax y ET0 como variables exógenas) con el filtro de Kalman Discreto. Para conocer la efectividad de los modelos en el pronóstico para L pasos hacia adelante, es decir, con 1, 2, 3 y 4 meses de adelanto, se creó una rutina en Matlab® para realizar el pronóstico considerando la información en el tiempo k y avanzar L pasos en el pronóstico sin actualizar la información (Figura 3), este proceso se realizó considerando el periodo P de calibración de los modelos AR2 y ARX.

Para evaluar los resultados del pronóstico se calcularon las principales estadísticas de acuerdo con Gupta et al. (2009), el RMSE (la raíz del error cuadrático medio) y E (la eficiencia de Nash-Sutcliffe) fueron los criterios a considerar por ser los más usados para la calibración y evaluación de modelos hidrológicos (Moriasi et al., 2007). Además, se incluyó un intervalo de confianza al 95 % que sigue el recorrido de cada estado de la serie con el objetivo de establecer el grado de incertidumbre asociado al pronóstico en cada paso del tiempo (L) con respecto a los valores observados.
El intervalo de predicción (I.P.) se obtuvo de acuerdo con los criterios establecidos por Chatfield (2004), el I.P. se calculó con base en la siguiente forma general: Un 100(1-α)% I.P. para xt+L está dado por:
donde
Resultados y discusión
En su proceso el filtro de Kalman genera dos tipos de resultados: los estados pronosticados y actualizados, los resultados comprenderán sólo la parte de pronóstico ya que con base en esta se evaluará el desempeño de los modelos para predecir los estados futuros de los índices de sequía.
Los resultados se presentan en el pronóstico de los índices de sequía SPI y SPEI en la cuenca del río Fuerte, implementando los modelos DKF - AR2 y DKF - ARX con información de 14 estaciones meteorológicas en el periodo de 1961 a 2011.
A los índices na y nb, se les asignaron los valores de na = 2 y nb = 2, por generar los mejores resultados en términos de RMSE y E con la menor cantidad de observaciones posible (Cuadro 2). La Figura 4 muestra que el periodo de calibración para ambos modelos fue 96 meses. El periodo de calibración se estableció para estimar y re-estimar los parámetros del modelo durante el estudio, ya que las características de la sequía pueden variar en el tiempo y tener un comportamiento cíclico o estacional. Se probaron diferentes periodos entre 60 y 108 meses (menos de 10 años), rango dentro del cual se puede apreciar algún comportamiento recurrente de los índices de sequía y, además, hay suficiente información para estimar los parámetros del modelo sin reducir considerablemente la serie disponible para realizar el pronóstico. En el Cuadro 3 se muestran los resultados para cada periodo de calibración en términos de RMSE y E, donde se consideró que el periodo más adecuado es de 96 meses.
Cuadro 3 Prueba de diferentes periodos de calibración para la estación 25025 P. Miguel Hidalgo, Sinaloa.
| Modelo | Periodo de calibración (meses) | |||||||||
| DKF - ARX-Pt | 60 | 72 | 84 | 96 | 108 | |||||
| RMSE | 0.37 | 0.37 | 0.37 | 0.36 | 0.37 | |||||
| E | 0.855 | 0.860 | 0.857 | 0.868 | 0.869 | |||||
Los estadísticos seleccionados para describir los resultados de este estudio son el RMSE el cual se expresa en las unidades de los índices y se consideró debido a que el error que se comete en el pronóstico define la efectividad del modelo para predecir y, con ello, si es una herramienta adecuada o si se opta por otros métodos de pronóstico. El segundo parámetro es E, coeficiente de eficiencia de Nash, que según Moriasi et al. (2007), dependiendo de los valores de E, sería la calidad de la predicción del modelo (E<0.5 el modelo es insatisfactorio y al acercarse a 1 es un buen modelo). Estos valores surgen de una relación entre los datos observados del índice y los que arroja el pronóstico con el algoritmo del filtro de Kalman Discreto, en esta relación el valor de E nos indica el grado en que los modelos DKF - AR2 y DKF - ARX son mejores predictores que la media de los datos observados (dado que E > 0.5), es por ello que se considera como uno de los parámetros de evaluación del pronóstico de los índices de sequía.
Los Cuadros 4 y 5 muestran los valores medios de los estadísticos RMSE y E obtenidos en el pronóstico de los índices SPI y SPEI para las 14 estaciones analizadas, estos resultados se presentan por escala temporal de los índices y por modelo utilizado, modelos DKF - AR2 y DKF - ARX- (Pt, ET0, Tmin, Tmax).
Cuadro 4 Media de los resultados en el pronóstico del SPI en la cuenca.
| Duración de la sequía en meses | ||||||||
| Modelo | 3 | 6 | 12 | 24 | ||||
| RMSE | E | RMSE | E | RMSE | E | RMSE | E | |
| AR-2 | 0.67 | 0.50 | 0.53 | 0.70 | 0.34 | 0.88 | 0.24 | 0.94 |
| ARX-Pt | 0.68 | 0.51 | 0.46 | 0.78 | 0.32 | 0.89 | 0.21 | 0.95 |
| ARX-ET0 | 0.70 | 0.48 | 0.46 | 0.78 | 0.32 | 0.89 | 0.21 | 0.95 |
| ARX-TMIN | 0.70 | 0.49 | 0.46 | 0.78 | 0.32 | 0.89 | 0.21 | 0.95 |
| ARX-TMAX | 0.70 | 0.48 | 0.47 | 0.78 | 0.32 | 0.89 | 0.21 | 0.95 |
Cuadro 5 Media de los resultados en el pronóstico del SPEI en la cuenca.
| Duración de la sequía en meses | ||||||||
| Modelo | 3 | 6 | 12 | 24 | ||||
| RMSE | E | RMSE | E | RMSE | E | RMSE | E | |
| AR-2 | 0.65 | 0.58 | 0.48 | 0.76 | 0.30 | 0.90 | 0.21 | 0.96 |
| ARX-Pt | 0.63 | 0.61 | 0.43 | 0.81 | 0.27 | 0.92 | 0.19 | 0.96 |
| ARX-ET0 | 0.64 | 0.59 | 0.44 | 0.81 | 0.27 | 0.92 | 0.19 | 0.96 |
| ARX-TMIN | 0.64 | 0.60 | 0.44 | 0.81 | 0.27 | 0.92 | 0.19 | 0.96 |
| ARX-TMAX | 0.65 | 0.58 | 0.44 | 0.81 | 0.27 | 0.92 | 0.19 | 0.96 |
Las escalas temporales de 3 y 6 meses en ambos índices obtuvieron RMSE medios de entre 0.40 y 0.70, el SPI y SPEI cambian de categoría cada 0.50 unidades por lo que errores de esa magnitud significan un amplio margen de error en la predicción de los índices que puede llevarnos a subestimar la intensidad de las condiciones de sequía o de humedad. En cambio, las escalas temporales de 12 y 24 meses obtuvieron valores promedio de RMSE entre 0.19 y 0.34, lo que genera una mejor aproximación de las condiciones reales en la cuenca.
El coeficiente E, en el pronóstico del SPI de 3 meses presenta valores medios menores e iguales a 0.5, clasificando los modelos como insatisfactorios para estas condiciones; mientras que el SPEI para la misma escala temporal presenta valores medios de E clasificados como satisfactorios. El pronóstico del SPI y SPEI a escalas temporales de 6, 12 y 24 meses obtuvo valores promedio de E mayores a 0.70 clasificando los cinco modelos probados como buenos y muy buenos, por lo tanto, a pesar de la magnitud de los errores que se cometen a escala de 6 meses, los modelos son mejores predictores que la media de los datos observados.
En términos generales de RMSE y E, el pronóstico del SPEI es mejor que el pronóstico del SPI para los modelos probados y en todas las escalas temporales, esto puede deberse a que el SPEI involucra dos variables en su cálculo: la precipitación, que es una variable de carácter más aleatorio (espacial y temporalmente) que la temperatura, por lo que la variable temperatura da mayor estabilidad a las series del SPEI mejorando el pronóstico; en cambio el SPI utiliza para su cálculo únicamente a la precipitación, lo que genera alta variabilidad a la serie de datos y aumenta el error cometido en el pronóstico del índice como se observa en los Cuadros 4 y 5.
De los Cuadros 4 y 5 se concluye que el pronóstico del SPEI para las escalas de 12 y 24 meses genera mejores resultados que las escalas de 3 y 6 meses, en términos del RMSE y de E para los modelos autorregresivos probados.
El Cuadro 6 muestra el modelo que generó mejores resultados en el pronóstico con el filtro de Kalman Discreto del SPEI de 12 y 24 meses, se observa que en 6 de las 7 estaciones ubicadas en el estado de Chihuahua, en la parte alta de la cuenca, el mejor modelo es el autorregresivo de segundo orden, AR2, el cual emplea solo la serie de datos mensuales del SPEI; las 8 estaciones restantes, la mayoría ubicadas en el norte de Sinaloa, presentaron mejores resultados con el modelo autorregresivo con entrada exógena de precipitación ARX-Pt. De entre las variables exógenas analizadas (precipitación, evapotranspiración de referencia y temperaturas máxima y mínima), la precipitación presentó menor RMSE y mayor valor de E en todas las estaciones.
Cuadro 6 Mejores modelos de pronóstico del SPEI con el DKF para cada estación.
| Clave | Estación | Mejor modelo de pronóstico |
Duración de la sequía | |||
| 12 | 24 | |||||
| RMSE | E | RMSE | E | |||
| 8038 | Creel | AR-2 | 0.27 | 0.92 | 0.19 | 0.97 |
| 8106 | Norogachic | AR-2 | 0.27 | 0.92 | 0.19 | 0.97 |
| 8161 | Batopilas | AR-2 | 0.28 | 0.91 | 0.16 | 0.97 |
| 8167 | Chinipas | ARX-Pt | 0.27 | 0.92 | 0.19 | 0.96 |
| 8172 | Guadalupe | AR-2 | 0.26 | 0.94 | 0.16 | 0.98 |
| 8182 | Moris | AR-2 | 0.17 | 0.97 | 0.10 | 0.99 |
| 8267 | El Vergel | AR-2 | 0.27 | 0.91 | 0.17 | 0.96 |
| 25009 | Bocatoma | ARX-Pt | 0.27 | 0.92 | 0.19 | 0.96 |
| 25019 | Choix | ARX-Pt | 0.27 | 0.92 | 0.19 | 0.96 |
| 25025 | P. Miguel H. | ARX-Pt | 0.27 | 0.92 | 0.19 | 0.96 |
| 25042 | Higuera | ARX-Pt | 0.27 | 0.92 | 0.19 | 0.96 |
| 25044 | Huites | ARX-Pt | 0.27 | 0.92 | 0.19 | 0.96 |
| 25100 | Yecorato | ARX-Pt | 0.27 | 0.92 | 0.19 | 0.96 |
| 26053 | Minas Nuevas | ARX-Pt | 0.27 | 0.92 | 0.19 | 0.96 |
En el pronóstico del SPEI a duraciones de 12 y 24 meses, se observó que un solo modelo no puede generar los mejores resultados para todas las estaciones de la cuenca, sino que ambos modelos pueden ser buenas herramientas de pronóstico en función de características específicas de las series de datos de las estaciones.
En la Figura 5 se muestra el modelo que resultó mejor predictor en cada estación y su probable asociación con las unidades climáticas que predominan en cada zona, es notable como las estaciones en las cuales la inclusión de una variable exógena no mejoró el pronóstico se localizan en climas semifríos y templados; en cambio, las estaciones en las cuales el modelo ARX-Pt fue el mejor modelo de pronóstico se ubican en climas secos y cálidos, y en estas estaciones la inclusión de la precipitación como variable exógena mejora el pronóstico de SPEI, y da mayor información al algoritmo.

Esta diferencia en el mejor modelo de pronóstico para las estaciones de clima templado y cálido está dada por las características de las series del SPEI de cada estación. En la Figura 6 se muestran dos series del SPEI de 12 meses, la primera de la estación 8172 Guadalupe ubicada en un clima templado, y la segunda de la estación 25100 Yecorato, que se encuentra en un clima cálido. En la figura se señalan algunas partes de las series donde se observa claramente que el número de oscilaciones del SPEI en Guadalupe es mucho menor que en Yecorato. Recordar que a partir de índices de sequía de -1.0 inicia la clasificación de sequía moderada (Castillo et al., 2017), y que entre más negativo es el índice, mayor es la sequía.
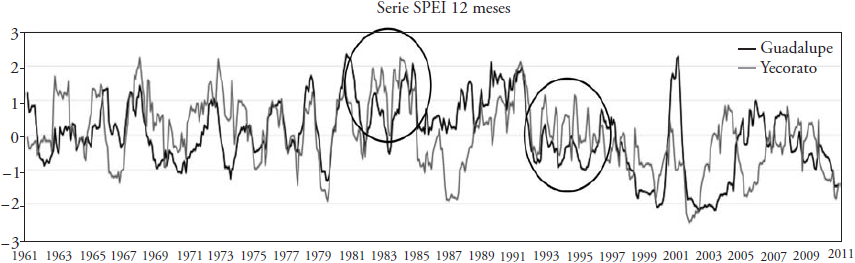
Figura 6 Comparación entre las series del SPEI de 12 meses de una estación de clima templado (Guadalupe, Chihuahua) y una estación de clima cálido (Yecorato, Sinaloa).
De manera similar, la Figura 7 muestra dos series del SPEI de 12 meses observado (línea) y el valor pronosticado (asterisco). La serie superior corresponde a la estación 8106 Norogachic, de clima templado, su valor pronosticado se obtuvo con el modelo AR2 y se aprecia como la predicción se ajusta a la serie observada especialmente en los valores extremos. La serie inferior corresponde a la estación 25025 Presa Miguel Hidalgo, ubicada en clima cálido, el mejor pronóstico se obtuvo con el modelo ARX-Pt, y a diferencia de la estación de clima templado la predicción no tiene un ajuste adecuado a los valores extremos.
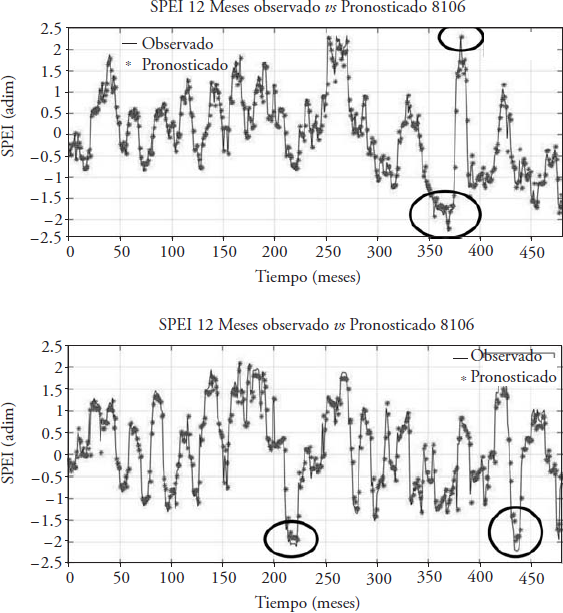
Figura 7 Serie del SPEI de 12 meses observado y pronosticado de una estación ubicada en clima frío (8106, Norogachic) y otra en un clima cálido (25025, P. Miguel Hidalgo).
Pronóstico con DKF - ARX-Pt
En las estaciones 8167, 25009, 25019, 25025, 25042, 25044, 25100 y 26053 (6 de ellas están en Sinaloa), se obtuvieron mejores resultados en el pronóstico del SPEI con el modelo DKF - ARX-Pt. Los resultados mostraron que el empleo de la precipitación como variable exógena mejora el pronóstico en comparación con el realizado con el modelo DKF-AR2 para estas estaciones. Con el modelo ARX se probaron como variables exógenas la precipitación, la evapotranspiración de referencia, la temperatura máxima y la mínima; sin embargo, en la mayoría de los casos la precipitación aportó mayor información al algoritmo y generó mejores resultados en términos de E y R que las variables restantes (Cuadro 6).
La asociación de los resultados con las unidades climáticas de la cuenca ubica estas estaciones en climas cálidos y secos. Como ya se mostró, las estaciones de clima cálido presentan series con mayor oscilación entre valores negativos y positivos del SPEI que las series de estaciones en climas templados y semifríos. Al tener series menos suavizadas el pronóstico se hace menos preciso, por lo que la inclusión de una variable exógena (precipitación) aporta la información necesaria al modelo para mejorar su desempeño.
Las Figuras 8 y 9 presentan los diagramas de dispersión del SPEI de 12 y 24 meses, respectivamente, para las estaciones donde el modelo ARX-Pt resultó mejor. Estos muestran los valores de MSE, RMSE, E, R y PBE.
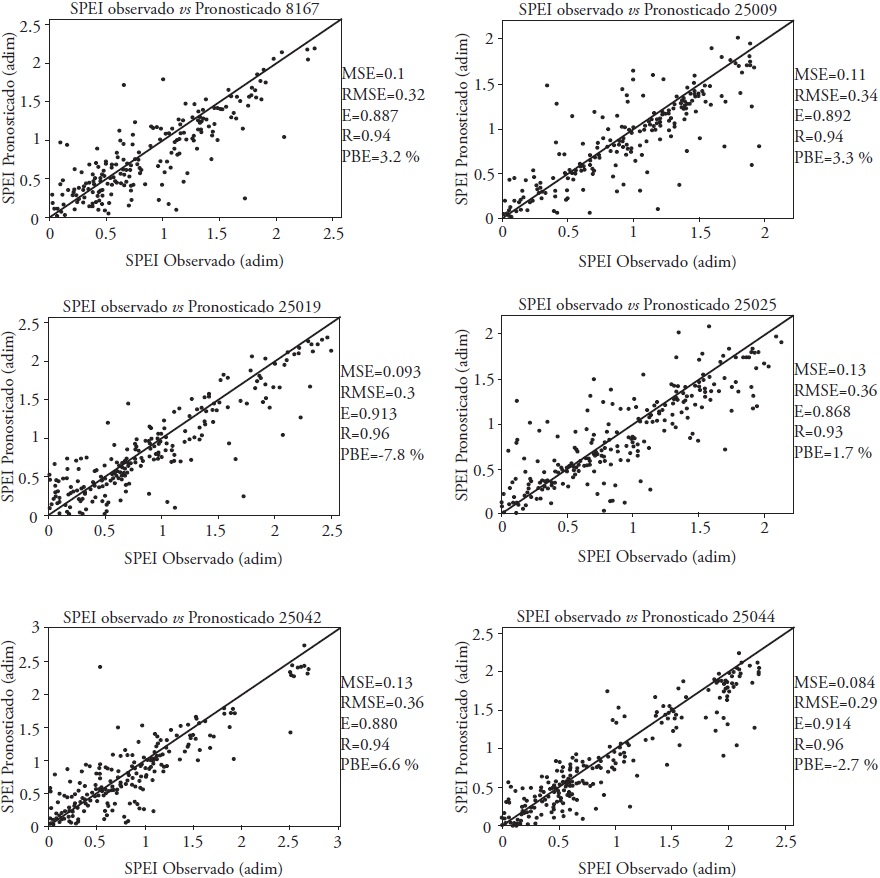
Figura 8 Diagramas de dispersión de valores observados y pronosticados del SPEI de 12 meses para algunas estaciones donde el ARX-Pt fue el mejor modelo.

Pronóstico con DKF - AR2
Las estaciones 8038, 8106, 8161, 8172, 8182 y 8267, toda ubicadas en el estado de Chihuahua sobre la Sierra Madre Oriental, obtuvieron mejores resultados en el pronóstico del SPEI con el modelo DKF - AR2 (Cuadro 6). Los resultados mostraron que en estas estaciones la inclusión de una variable exógena como la precipitación, la evapotranspiración de referencia, la temperatura máxima y la mínima no aporta la suficiente información al algoritmo para mejorar los resultados obtenidos con el modelo AR2, en el mejor caso los iguala. La asociación de los resultados con el tipo de clima de la estación ubica estas estaciones en climas semifríos y templados semihúmedos.
El valor del estadístico PBE (Percentage Bias Error, Porcentaje de Error de Sesgo) presenta valor negativo en la mayoría de las estaciones, lo que indica que el modelo DKF-AR2 subestima el valor del índice SPEI (Cuadro 6).
En ambos modelos de pronóstico del SPEI, DKF-AR y DKF-ARX, las series de 12 meses presentan mayor error y menor valor del coeficiente de Nash que las de 24 meses, esto se debe a que a una escala mayor la serie temporal asimila más lentamente los cambios dados en el balance Pt-ET0 a lo largo del tiempo, y, por lo tanto, presenta mayor suavidad en su recorrido mejorando el pronóstico. Sin embargo, ambos pronósticos de sequías de duraciones de 12 y 24 meses son útiles. Pero dadas las características de los índices de sequía (SPI y SPEI) a una determinada escala (duración de sequía), en términos de operatividad, la escala temporal de 12 meses se considera la más adecuada para el pronóstico de las sequías. Esto último, es especialmente apropiado en la parte media y baja de la cuenca, por su vocación agrícola y energética, donde al operar las presas se revisan políticas anuales de operación. Aunque el análisis de periodos de sequía de 24 meses es muy útil también.
Además del pronóstico del índice de sequía para el tiempo t+1|t, se pronosticaron los índices con 2, 3 y 4 meses de adelanto, es decir, dado un valor observado del índice en el tiempo t se pronosticaron los valores del índice para el tiempo t+1, t+2, t+3 y t+4, sin actualizar la información, esto con el propósito de conocer el poder de predicción de los modelos para diferentes pasos de adelanto en el tiempo.
Sin embargo, a manera de muestra, aquí se presentan solo los resultados del pronóstico para el SPEI de 12 meses. La Figura 10 muestra el pronóstico en la estación de la Presa Miguel Hidalgo en Sinaloa, con el SPEI de 12 meses con el modelo DKF - ARX-Pt con 1, 2, 3 y 4 meses de anticipación.
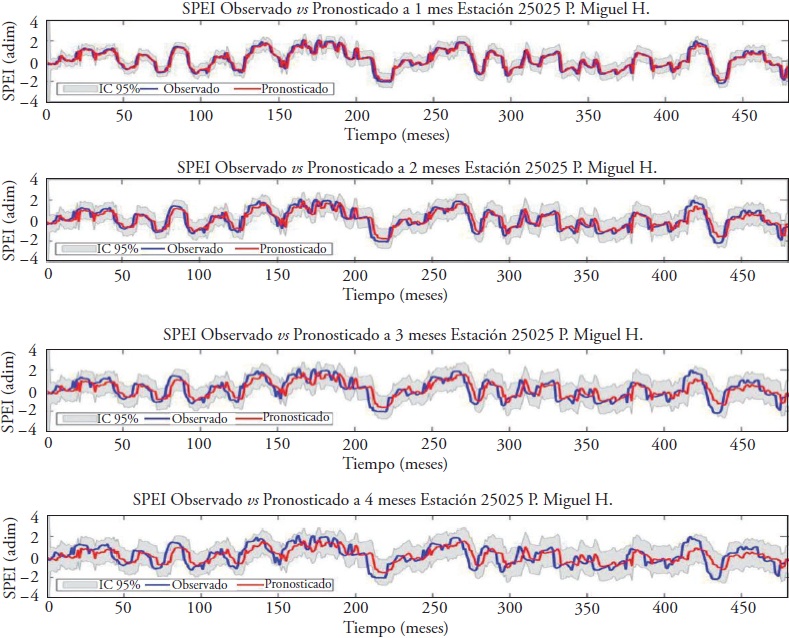
Figura 10 SPEI de 12 meses pronosticado con el modelo DKF - ARX-Pt con 1, 2, 3 y 4 meses de anticipación e intervalo de confianza al 95 %, estación Presa Miguel H., Sinaloa.
El pronóstico se concentra en la estimación puntual de un valor del SPEI de 12 meses para algún mes futuro, pero de acuerdo con Chatfield (2004): “el pronóstico puntual es adecuado para muchos propósitos, pero un intervalo de predicción es frecuentemente de gran ayuda para dar un mejor indicador de la incertidumbre futura”. Por lo tanto, se calculó el intervalo de confianza del pronóstico al 95 % para los pasos de adelanto (L) como se indica en la ecuación (9).
En la Figura 10, además de los valores observados y pronosticados, hay una franja que sigue el recorrido del pronóstico (entre más negativo el índice, mayor es la sequía), y este es el intervalo de confianza del pronóstico al 95 %. Conforme se avanza en el pronóstico el intervalo se hace más ancho, esto es, por ejemplo, que en el tiempo t hay menor incertidumbre de donde puede localizarse el valor observado del SPEI en el tiempo t+1 que del valor en el tiempo t+4 en el cual la incertidumbre es mucho mayor. También es importante agregar que al final se observó como los errores totales de la predicción (del proceso + de medición) se ajustaron a una distribución t-Student de media 0, la cual se acerca a una distribución Normal.
Es importante enfatizar que el filtro de Kalman es importante para el pronóstico de variables hidrometeorológicas porque se pueden predecir caudales medios diarios (Gonzalez et al, 2015), caudales subhorarios (Morales et al., 2014), y predecir indicadores de sequías con algunos meses de anticipación. La predicción de sequías permite preparar planes de contingencia para reducir su impacto negativo.
Conclusiones
El pronóstico de los índices de sequía SPI y SPEI mediante el filtro de Kalman discreto y dos modelos autorregresivos, AR2 y ARX, fue implementado satisfactoriamente para 14 estaciones meteorológicas en la cuenca del río Fuerte en el periodo 1961-2011. El modelo AR2 presentó mejores ajustes para la parte alta de la cuenca y el ARX, para la parte media y baja de la cuenca. Como variables externas en el modelo ARX se probaron las siguientes variables: precipitación, evapotranspiración de referencia, temperatura máxima y temperatura mínima. La variable externa en el modelo ARX que mejoró la predicción fue la precipitación. En otros estudios se recomienda incluir como variable externa la humedad antecedente en la cuenca.
Resulta importante no solo monitorear sequías con índices mejorados como el SPEI, sino también pronosticarlas con anticipación para realizar planes de contingencia para las demandas de agua potable, agrícolas y ganaderas. El filtro de Kalman discreto resultó una buena herramienta para el pronóstico de sequías. Ese es el aporte principal de esta investigación.

