










Services on Demand
Journal
Article
 Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mailIndicators
-
 Cited by SciELO
Cited by SciELO -
 Access statistics
Access statistics
Related links
-
 Similars in
SciELO
Similars in
SciELO
Share

 Permalink
PermalinkAgrociencia
On-line version ISSN 2521-9766Print version ISSN 1405-3195
Agrociencia vol.47 n.7 Texcoco Oct./Nov. 2013
Fitociencia
Estimación de parámetros para un modelo de crecimiento de cultivos usando algoritmos evolutivos y bio-inspirados
Parameter estimation for crop growth model using evolutionary and bio-inspired algorithms
E. César Trejo-Zúñiga*, I. Lorenzo López-Cruz, Agustín Ruíz-García
Ingeniería Agrícola y Uso Integral del Agua. Universidad Autónoma Chapingo. 56230. Chapingo, Estado de México. *Autor responsable. (teze71@hotmail.com).
Recibido: junio, 2013.
Aprobado: octubre, 2013.
Resumen
La calibración de modelos dinámicos para crecimiento y desarrollo de cultivos con rangos de parámetros, genera estimaciones imprecisas de estos y predicciones erróneas del modelo cuando se usa estimación por mínimos cuadrados o máxima verosimilitud. El presente estudio muestra el uso de métodos globales de optimización para resolver este problema. Se presenta una comparación del desempeño de un algoritmo evolutivo (Evolución Diferencial, DE) y dos bio-inspirados: Búsqueda Cuco (CS) y Búsqueda Cuco Modificado (MCS). El problema prueba fue estimar los 25 parámetros del modelo para crecimiento potencial de cultivos SUCROS (a Simple and Universal CROp growth Simulator). Los datos se obtuvieron de un experimento de crecimiento de un cultivo de tomate de cáscala (Physalis ixocarpa Brot. ex Horm.) realizado en Chapingo, México. El objetivo fue determinar qué algoritmo genera valores para los parámetros del modelo que permitan lograr las predicciones más precisas. Se realizó un ANDEVA para evaluar estadísticamente la eficiencia y efectividad de los algoritmos propuestos. Los resultados mostraron un desempeño mejor del algoritmo DE estándar (DE/rand/1/ bin) en términos de eficiencia y eficacia para converger a una solución óptima. Los algoritmos bio-inspirados mostraron buen desempeño, por lo cual son confiables y se pueden aplicar en la estimación de parámetros de modelos de cultivos.
Palabras clave: estimación de parámetros, Evolución Diferencial, Búsqueda Cuco, SUCROS.
Abstract
The calibration of dynamic models for crop growth and development with parameter ranges generates imprecise estimations and erroneous predictions of the model when estimation is used by least squares or maximum likelihood. The present study shows the use of global methods of optimization for resolving this problem. A comparison is presented of the performance of an evolutionary algorithm (Differential Evolution, DE) and two that are bio-inspired: Cuckoo Search (CS) and Modified Cuckoo Search (MCS). The test problem was to estimate the 25 parameters of the model for potential crop growth SUCROS (a Simple and Universal Crop growth Simulator).The data used was obtained from an experiment of growth of a husk tomato crop (Physalis ixocarpa Brot. Ex Horm.) carried out at Chapingo, Mexico. The objective was to determine which algorithm generates values for the parameters of the model that make it possible to obtain the most precise predictions. An ANOVA was performed to statistically evaluate the efficiency and effectiveness of the proposed algorithms. Results showed a better performance of the standard DE algorithm (DE/rand/1/ bin) in terms of efficiency and effectiveness to converge to an optimum solution. The bio-inspired algorithms showed good performance; therefore, they are reliable and can be applied in the estimation of parameters of crop models.
Key words: parameter estimation, Differential Evolution, Cuckoo Search, SUCROS.
INTRODUCCIÓN
La estructura de los modelos dinámicos para crecimiento de cultivos consiste en un conjunto de ecuaciones diferenciales ordinarias de primer orden, en general no-lineales. Estas ecuaciones poseen coeficientes que representan parámetros fisiológicos, los que se deben determinar con precisión para lograr un mejor ajuste entre las predicciones del modelo y los datos observados. Es necesario estimar algunos o todos los parámetros del modelo con datos de campo para mejorar el ajuste de las predicciones (Wallach et al., 2001). La determinación de los valores de los parámetros puede plantearse como un problema de optimización, lo que permite usar diversos algoritmos. Generalmente se usan métodos de búsqueda local que utilizan el gradiente de la función objetivo. Sin embargo, debido a la no-linealidad alta de los modelos de crecimiento y desarrollo de cultivos y la dependencia posible entre los parámetros (epístasis), el problema de optimización puede resultar no convexo, multimodal o sobre-parametrizado. Además, cuando se estiman más de 10 parámetros con algoritmos de mínimos cuadrados o de máxima verosimilitud, se pueden generar varianzas muy altas en los parámetros estimados e imprecisiones en las predicciones del modelo (Makowski et al., 2006).
Para resolver problemas de optimización multi-modal, los métodos globales de optimización como los algoritmos evolutivos (Evolución Diferencial) y bio-inspirados (Búsqueda Cuco) pueden ofrecer buenas aproximaciones al óptimo global (Yang y Deb, 2009, 2010; Walton et al., 2011; Civicioglu y Besdok, 2013). Wallach et al. (2001) propusieron un procedimiento automático para estimar los parámetros de modelos de cultivo calibrados con datos de campo, pero no usaron métodos globales de optimización. Pabico et al. (1999) estimaron coeficientes de cultivares en modelos de cultivo mediante algoritmos genéticos, los cuales son un método evolutivo global pero ineficiente. Dai et al. (2009) realizaron un proceso de estimación de parámetros para modelos de crecimiento de cultivos en invernadero usando algoritmos genéticos. Guzmán-Cruz et al. (2009) efectuaron un proceso de calibración de un modelo del clima de un invernadero con algoritmos evolutivos, pero no usaron evolución diferencial. De acuerdo con la literatura, no se han aplicado algoritmos de optimización bio-inspirados para la estimación de parámetros de crecimiento de cultivos en campo abierto.
El objetivo de la presente investigación fue evaluar el desempeño, a través de la eficiencia y efectividad, de los algoritmos de Evolución Diferencial (DE) reconocido como uno de los algoritmos evolutivos más eficientes, Búsqueda Cuco (CS) y Búsqueda Cuco Modificado (MCS) para estimar 25 parámetros del modelo de crecimiento SUCROS (Goudriaan y Van Laar, 1994) aplicado a un cultivo de tomate de cáscara (Physalis ixocarpa Brot. ex Horm.) con datos de un experimento realizado en Chapingo, México, en el verano de 2007 (López-López et al., 2009). La eficiencia o costo computacional de un algoritmo es el número de veces que la función objetivo es evaluada para encontrar un óptimo. La efectividad o capacidad de un algoritmo para alcanzar un óptimo en un problema de optimización multimodal, se calcula contando el número de veces que el algoritmo converge a un óptimo con diferentes valores iniciales para el proceso iterativo (Baritompa y Hendrix, 2005; Khompatraporn et al., 2005).
MATERIALES Y MÉTODOS
Algoritmo de evolución diferencial
Los algoritmos de evolución diferencial son una clase de algoritmos evolutivos planteados como métodos de optimización global (Storn y Price, 1997; López-Cruz et al., 2003; Price et al., 2005). El método consiste en generar en forma aleatoria una población inicial de vectores de números reales P(0)=(uij); i=1,..., NP; j=1,..., D dentro del dominio de cada una de las variables a ser optimizadas. D es la dimensión del vector y NP es el tamaño de la población. Normalmente el dominio de las variables del problema está restringido entre valores mínimos bj.L y máximos bj.u . Por tanto, cada individuo de la población inicial se genera mediante la ecuación (1):

donde randj (0,1) genera un número aleatorio uniformemente distribuido dentro del rango [0,1]. Después de evaluar cada vector, calculando la función objetivo f(ui), se inicia un ciclo interno y otro externo en los cuales se aplican los operadores de evolución diferencial. El ciclo externo se detiene cuando se satisface un criterio de convergencia como el número especificado de iteraciones. El ciclo interno permite que cada individuo de la población sea considerado una vez como padre de las nuevas soluciones y sea usado en los operadores evolutivos de mutación, cruzamiento y selección diferencial. En la presente investigación se usó el algoritmo de evolución diferencial llamado estándar DE/rand/1/ bin, lo cual indica que el vector mutado fue elegido en forma aleatoria, y solamente dos vectores tomados también en forma aleatoria de la población se combinaron para calcular un vector diferencia. El cruzamiento fue implementado mediante el esquema binomial (Price, 1999; Price et al., 2005).
Operador de mutación
La mutación consiste en la construcción de NP vectores aleatorios  , los cuales son creados con la ecuación (2):
, los cuales son creados con la ecuación (2):

donde r1, r2, r3 ∈ [1, ...NP] son distintos entre sí, verificando que se satisfaga las condiciones r1≠ i, r1≠ r2, r2≠i, r3≠i, r3≠r2, r3≠r1. F es un parámetro que controla la tasa de mutación y se encuentra en el rango [0,2].
Operador de cruzamiento
El cruzamiento consiste en combinar el vector  mutado previamente con otro vector llamado vector blanco
mutado previamente con otro vector llamado vector blanco  el cual se puede considerar como un individuo padre de la generación anterior. Así se genera un nuevo vector descendiente
el cual se puede considerar como un individuo padre de la generación anterior. Así se genera un nuevo vector descendiente 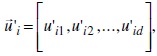 llamado vector ensayo. El cruzamiento binomial se implementa mediante la ecuación (3):
llamado vector ensayo. El cruzamiento binomial se implementa mediante la ecuación (3):

donde randb(j) ∈ [0,1] es la j-ésima evaluación de un generador de números aleatorios uniforme; rnbr(i) ∈ [1,...,d] es un índice generado en forma aleatoria. CR ∈ [0,1] es un parámetro de probabilidad de cruzamiento que controla la diversidad de la población.
Operador de selección
Ésta se realiza simplemente comparando el valor de la función de costo  del vector blanco
del vector blanco  contra el correspondiente valor de la función objetivo
contra el correspondiente valor de la función objetivo  del vector de prueba
del vector de prueba  , luego entonces, el vector que tenga el menor valor de la función de costo pasa a ser miembro de la población en la siguiente generación (Price, 1999; Price et al., 2005; Chakraborty, 2008).
, luego entonces, el vector que tenga el menor valor de la función de costo pasa a ser miembro de la población en la siguiente generación (Price, 1999; Price et al., 2005; Chakraborty, 2008).
Algoritmo cuco clásico (CS) y modificado (MCS)
Este algoritmo está inspirado en el comportamiento parasitario de las crías de algunas especies de aves cuco en combinación con el comportamiento de vuelo Lévy de algunos pájaros y moscas de la fruta (Yang y Deb, 2010). Esto se puede resumir en tres reglas idealizadas: 1) cada cuco pone un huevo a la vez y lo deposita en un nido elegido al azar; 2) los mejores nidos con huevos de alta calidad serán transferidos a las próximas generaciones; 3) el número de nidos hospederos es fijo y el huevo puesto por un cuco es descubierto por el ave hospedera con una probabilidad pa ∈ [0,1]. En este caso el hospedero puede desechar el huevo o abandonar el nido y construir uno nuevo. Para simplificar, esta última suposición puede ser aproximada por la fracción pa de los n nidos que son reemplazados (nuevas soluciones aleatorias). En su forma más simple cada huevo en el nido representa una solución y cada huevo puesto por un cuco es una nueva solución al problema en cuestión (Civicioglu y Besdok, 2013; Gandomi et al., 2013).
Vuelos Lévy
Al generar nuevas soluciones xt+1 para un cuco i-ésimo se genera un vuelo Lévy dado por la ecuación (4):

donde α>0 es el tamaño de paso y debe estar relacionado con las escalas del problema en cuestión. En la mayoría de los casos se puede utilizar α=1. La ecuación (4) es esencialmente la ecuación estocástica de recorrido aleatorio. En general, un recorrido aleatorio es una cadena de Markov cuya próxima posición depende de la ubicación actual (primer término en la ecuación) y la probabilidad de transición (segundo término). El símbolo ⊕ significa producto con respecto a las entradas. Este recorrido aleatorio a través del vuelo Lévy es más eficiente en la exploración del espacio de búsqueda.
El vuelo Lévy representa un recorrido aleatorio y es la longitud de paso obtenida mediante una distribución de Lévy (ecuación 5):

que tiene media y varianza infinitas. En este caso, los pasos consecutivos de un cuco forman un proceso de caminata aleatoria que obedece a una distribución de ley de potencias con longitud de paso de doble cola (Yang y Deb, 2009; Yildiz, 2013).
En el caso del algoritmo de búsqueda cuco modificado (MCS) (Walton et al., 2011) el tamaño de paso del vuelo Lévy (α) disminuye cuando aumenta el número de generaciones, esto con la finalidad de estimular más la búsqueda localizada de los individuos o huevos, cuando estén cercanos a la solución. Se selecciona un valor inicial del tamaño de paso del vuelo de Lévy A=1 y en cada generación se calcula un nuevo tamaño de paso con α= A / √G, donde G es el número de generación. Esta búsqueda exploratoria se realiza solamente en la fracción de nidos a ser abandonados. Otra modificación es la adición de intercambio de información entre los huevos con la finalidad de acelerar la convergencia hacia el mínimo, en contraste con CS donde no hay intercambio de información entre individuos y la búsqueda se realiza en forma independiente. En el MCS, una fracción de huevos con mejor aptitud (valor menor de la función objetivo) es ubicada en un grupo superior. Para cada uno de estos huevos se crea un segundo grupo y se elige un nuevo huevo al azar generándose una línea que une a estos huevos seleccionados. La distancia a lo largo de esta línea se calcula con la inversa de la proporción aurea φ = (1 + √5) /2 , de tal manera que el nuevo huevo está más cerca del huevo de mayor aptitud. En el caso de que ambos huevos tengan la misma aptitud, el nuevo huevo se genera en el punto medio. Hay una posibilidad de que, en este paso, sea generado dos veces el mismo huevo. De ser así, un vuelo de Lévy de búsqueda local es realizado entre los nidos elegidos al azar con tamaño de paso α=A/G2.
Modelo para crecimiento potencial de cultivos SUCROS
El modelo de crecimiento potencial de cultivos SUCROS fue descrito por Goudriaan y van Laar, (1994) y van Laar et al. (1997). Este modelo dinámico predice el comportamiento de la biomasa, el índice de área foliar y el estado de desarrollo a partir de procesos fundamentales, como la fotosíntesis y la respiración del cultivo. El modelo es para crecimiento potencial porque supone que las variables ambientales que afectan los procesos fundamentales son sólo la cantidad de radiación solar, la temperatura y las características genéticas del cultivo; las otras variables (agua, nutrientes) se consideran óptimas (van Ittersum et al., 2003). Las variables de entrada del modelo SUCROS para este estudio fueron radiación global (J m-2 d-1), temperatura mínima diaria (°C) y temperatura máxima diaria (°C). Las variables de salida fueron biomasa seca total (g m-2), biomasa seca de tallos (g m-2), biomasa seca de frutos (g m-2), biomasa seca de hojas (g m-2) e índice de área foliar (m2 m-2) (Cuadro 1). El problema de estimación es que dadas las mediciones de algunas de las variables que el modelo predice, se determinan los valores de los parámetros que permitan lograr el mejor ajuste entre las predicciones y mediciones.
Función a optimizar y características de los algoritmos involucrados
La función a minimizar fue:

donde yi,k representa la variable medida, biomasa total, biomasa de tallos, biomasa de frutos, biomasa foliar (hojas verdes y secas) así como el índice de área foliar. La variable  representa los valores estimados por el modelo SUCROS, wk es un peso asociado con cada variable para hacerlas equiparables. Los coeficientes fueron 1, 1, 1, 1 y 100. N es el número de muestreos durante el periodo de cultivo y M es el número de variables consideradas en la función objetivo. El vector de parámetros estimados consideró los 25 parámetros del modelo (Cuadro 1). Los algoritmos se ejecutaron durante 1000 iteraciones y se efectuaron 20 optimizaciones con inicializaciones aleatorias de las poblaciones dentro de un intervalo del 20 % del valor nominal de los parámetros como límites superior e inferior. Los parámetros del algoritmo de evolución diferencial fueron: NP=50, F=0.5 y CR=0.5. Para el caso del algoritmo de búsqueda cuco clásico los parámetros fueron NP=25 y pa=0.25 como lo recomiendan Yang y Deb (2009, 2010) y para el algoritmo búsqueda cuco modificado los parámetros fueron NP=80 (valor obtenido experimentalmente), pa=0.75 y SA=0.01 como lo recomiendan Walton et al. (2011).
representa los valores estimados por el modelo SUCROS, wk es un peso asociado con cada variable para hacerlas equiparables. Los coeficientes fueron 1, 1, 1, 1 y 100. N es el número de muestreos durante el periodo de cultivo y M es el número de variables consideradas en la función objetivo. El vector de parámetros estimados consideró los 25 parámetros del modelo (Cuadro 1). Los algoritmos se ejecutaron durante 1000 iteraciones y se efectuaron 20 optimizaciones con inicializaciones aleatorias de las poblaciones dentro de un intervalo del 20 % del valor nominal de los parámetros como límites superior e inferior. Los parámetros del algoritmo de evolución diferencial fueron: NP=50, F=0.5 y CR=0.5. Para el caso del algoritmo de búsqueda cuco clásico los parámetros fueron NP=25 y pa=0.25 como lo recomiendan Yang y Deb (2009, 2010) y para el algoritmo búsqueda cuco modificado los parámetros fueron NP=80 (valor obtenido experimentalmente), pa=0.75 y SA=0.01 como lo recomiendan Walton et al. (2011).
RESULTADOS Y DISCUSIÓN
El Cuadro 2 muestra el rendimiento global promedio de las 20 optimizaciones realizadas para los tres algoritmos estudiados. De acuerdo con los valores de la función objetivo f(p), el algoritmo de evolución diferencial (DE) fue el método más efectivo ya que alcanzó el valor más cercano a cero y también mostró la desviación estándar menor. El algoritmo cuco clásico (CS) superó en efectividad y eficacia al algoritmo cuco modificado (MCS) y mostró desviación estándar menor y valor de la función objetivo cercano al mínimo alcanzado por el algoritmo DE. Este resultado es similar al obtenido por Civicioglu y Besdok (2013).

La desviación estándar de menor valor para cada variable estimada, con excepción de LAICR, CFLV, CFRT y CFSO, fue obtenida por el algoritmo DE (Cuadro 3). Esto significa que el algoritmo DE tuvo el mejor desempeño en el proceso de estimación.
De acuerdo con el ANDEVA de un solo factor el desempeño de los tres algoritmos es significativamente diferente (α=0.05) (Cuadro 3). Considerando el proceso de comparación múltiple de Tukey-Kramer el algoritmo CS tuvo un rendimiento similar al DE pero diferente al del algoritmo MCS. Los resultados del análisis muestran diferencias estadísticas significativas en la mayoría de los parámetros estimados, con excepción de EFF, KDF, ASRQLV, LAICR, CFLV, CFRT y CFSO. Esto sugiere que este subconjunto de parámetros puede ser estimado con precisión. Sin embargo, la estimación debe complementarse con un análisis de sensibilidad e identificabilidad del modelo. Es decir, son más confiables y precisas las estimaciones obtenidas mediante el algoritmo DE.
En la estimación de la biomasa seca total y bio-masa seca de los tallos hubo una pequeña sub-estimación y para la biomasa seca de frutos de hojas e índice de área foliar hubo sobre-estimación del modelo (Figura 1). En general, con los parámetros estimados por el algoritmo DE se obtiene mejor predicción del modelo para las variables de salida estudiadas, ya que permitió obtener el ajuste mejor, fue más eficaz y preciso.
Si se toma como referencia el sesgo generado por los métodos de optimización se corrobora la sub y sobre-estimación del modelo para las diferentes variables de salida (Cuadro 4). MCS generó una sub-estimación pequeña de la biomasa total [a)] pero los algoritmos restantes la sobre-estimaron. Para la biomasa seca de tallos [b)] los tres algoritmos mostraron sub-estimación pequeña. Al contrario, la biomasa seca de los frutos [c)] fue sobre-estimada ligeramente y la biomasa seca de hojas [d)] e índice de área foliar [e)] fueron sobre-estimadas. De acuerdo con los estadísticos MSE, RMSE y MAE, el algoritmo de evolución diferencial fue ligeramente mejor que el algoritmo CS y este último fue mejor que el algoritmo MCS. En general, los tres algoritmos presentaron eficiencia aceptable en el proceso de calibración del modelo; las excepciones fueron la biomasa seca de frutos y hojas, estimaciones que tuvieron rendimiento bajo. El coeficiente de correlación (r) indica una relación lineal entre datos medidos y estimados; una r cercana a 1 es una estimación buena (Wallach, 2006). Aquí hubo un desempeño similar de los algoritmos en la mayoría de los casos.
CONCLUSIONES
El algoritmo evolutivo y dos algoritmos bio-inspirados permitieron estimar todos los parámetros del modelo SUCROS para crecimiento potencial de cultivos. Aunque los resultados fueron bastante similares, el algoritmo de evolución diferencial mostró el desempeño mejor, ya que obtuvo el valor menor de la función objetivo. Los tres algoritmos presentaron desempeño similar. Según los resultados, los algoritmos bio-inspirados son confiables y pueden ser aplicados en el proceso de estimación de parámetros de modelos de cultivos. Sin embargo, es necesario investigar con mayor detalle si los resultados obtenidos son corroborables en el caso de una estimación de parámetros en modelos más complejos con varias decenas o cientos de parámetros.
LITERATURA CITADA
Baritompa, B., and E. M. T. Hendrix. 2005. On the investigation of stochastic global optimization algorithms. J. Global Optim. 31: 567-578. [ Links ]
Chakraborty, U. K. 2008. Advances in Differential Evolution, Studies in Computational Intelligence 143, Springer-Verlag Berlin Heidelberg, 338 p. [ Links ]
Civicioglu, P., and E. Besdok. 2013. A conceptual comparison of the Cuckoo-search, particle swarm optimization, differential evolution and artificial bee colony algorithms. Artif. Intell. Rev. 39: 315-346. [ Links ]
Dai, C., M. Yao, Z. Xie, C. Chen, and J. Liu. 2009. Parameter estimation for growth model of greenhouse crop using genetic algorithms. Appl. Soft Comput. 9: 13-19. [ Links ]
Goudriaan, J., and H. H. Van Laar. 1994. Modelling Potential Crop Growth Processes. Textbook with Exercises, Kluwer Academic Publisher. Dordrecht, The Netherlands, 238 p. [ Links ]
Guzmán-Cruz, R., R. Castañeda-Miranda, J. J. García-Escalante, I. L. López-Cruz, A. Lara-Herrera, and J. I. De la Rosa. 2009. Calibration of a greenhouse climate model using evolutionary algorithms. Biosyst. Eng. 104:135-142. [ Links ]
Gandomi, H. A., X. S. Yang, and A. H. Alavi. 2013. Cuckoo search algorithm: a metaheuristic approach to solve structural optimization problems. Eng. Computers 29: 17-35. [ Links ]
Khompatraporn, Ch., J. D. Pinter, and Z. B. Zabinsky. 2005. Comparative assessment of algorithms and software for global optimization. J. Global Optim. 31:613-633. [ Links ]
López-Cruz, I. L., L. G. Van Willigenburg, and G. Van Straten. 2003. Efficient Differential Evolution algorithms for multi-modal optimal control problems. Appl. Soft Computing 3: 97-122. [ Links ]
López-López, R., R. Arteaga-Ramírez, M. A. Vázquez-Peña, I. L. López-Cruz, I. Sánchez-Coen, y A. Ruíz-García. 2009. Índice de estrés hídrico del cultivo de tomate de cáscara. Rev. Chapingo Ser. Hort. 25: 259-267. [ Links ]
Makowski, D., J. Hillier, D. Wallach, B. Andrieu, and M. H. Jeuffroy. 2006. Parameter estimation for crop models. In: Wallach, D., D. Makowski, and J.W. Jones (eds). Working with Dynamic Crop Models. Evaluation, Analysis, Parameterization, and Applications. Elsevier. Amsterdam, The Netherlands. pp: 55-100. [ Links ]
Pabico, J. P., G. Googenhoom, and R. W. Mcclendon. 1999. Determination of cultivar coefficients of crop models using a genetic algorithm: a conceptual framework. Trans. ASAE 42: 223-232. [ Links ]
Price, K. V. 1999. An introduction to differential evolution. In: Corne, D., M Dorigo, and F. Glover (eds). New Ideas in Optimization. McGraw-Hill. England, pp:79-108. [ Links ]
Price, K. V., R. M. Storn, and J. A. Lampinen. 2005. Differential Evolution. A Practical Approach to Global Optimization. Springer, Berlin Germany. 558 p. [ Links ]
Storn, R., and K. Price. 1997. Differential evolution-a simple and efficient heuristic for global optimization over continuous spaces. J. Global Optim. 11: 341-359. [ Links ]
van Ittersum, M, K., S. M. Houden, and S. Asseng. 2003. Sensitivity of productivity and deep drainage of wheat cropping systems in a Mediterranean environment to changes in CO2, temperature and precipitation. Agr. Ecosyst. Environ. 97: 255-273. [ Links ]
van Laar, H, H., J. Goudriaan, and H. van Keulen. 1997. SU-CROS97: Simulation of Crop Growth for Potential and Water-limited Production Situations, AB-DLO Wageningen, The Netherlands. 78 p. [ Links ]
Wallach, D. 2006. Evaluating crop models. In: Wallach, D., D. Makowski, and J. W. Jones (eds). Working with Dynamic Crop Models. Evaluation, Analysis, Parameterization, and Applications. Elsevier. Amsterdam, The Netherlands. pp: 11-54. [ Links ]
Wallach, D., B. Goffinet, J. E. Berguez, D. Leenhart, and J. N. Aubertot. 2001. Parameter estimation for crop models: a new approach and application to a corn model. Agron. J. 93:757-766. [ Links ]
Walton, S., O. Hassan, K. Morgan, and M. R. Brown. 2011. Modified cuckoo search: A new gradient free optimisation algorithm. Chaos Solitons Fract. 44: 710-718. [ Links ]
Yang, X. S., and S. Deb. 2009. Cuckoo Search via Lévy flights. Proceedings of World Congress on Nature & Biologically Inspired Computing (NaBIC, 2009, India), IEEE Publications, USA. pp: 210-214. [ Links ]
Yang, X. S., and S. Deb. 2010. Engineering optimisation by Cuckoo search. Int. J. Math. Mod. Numer. Optim. 1: 330-343. [ Links ]
Yildiz, A. R. 2013. Cuckoo search algorithm for the selection of optimal machining parameters in milling operations. Int. J. Adv. Manuf. Tech. 64: 55-61. [ Links ]

