











 text new page (beta)
text new page (beta) Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
PermalinkIntroducción
De acuerdo con Gasca (2009), la ciencia regional y la economía espacial han revolucionado el marco cuantitativo de la geografía. Este autor considera que dichas áreas han brindado mayor peso a los procedimientos metodológicos e instrumentales, favoreciendo la obtención de evidencia empírica y, eventualmente, coadyuvan a predecir ciertos fenómenos; por ello se considera a las técnicas de agregación espacial o de regionalización como parte de la agenda actual. Delgadillo y Torres (2011: 52) explican que la herramienta región permite estudiar agrupaciones de fenómenos complejos que se encuentran en la superficie terrestre, las cuales no están predeterminadas, se elaboran intelectualmente y se crean seleccionando características relevantes al problema de estudio.
Iracheta (2002: 73) habla de la región como un espacio subnacional o subestatal cuyo objetivo es dividir el territorio de acuerdo con determinados propósitos, obedeciendo a la combinación de determinadas características geográficas y socioeconómicas. Entiende a la regionalización como una herramienta de la planeación y de la administración pública que puede adecuarse a determinados objetivos; esa característica permite que coexistan diferentes regionalizaciones, de manera que las políticas regionales se articulen con los programas sectoriales.
Las propuestas de regionalización en México son cuantiosas.2 Algunos esquemas se desarrollaron solamente con fines de investigación, mientras que otros siguieron ciertas especificaciones. Resaltan particularmente los esquemas regionales en la escala estatal y algunos municipales, mientras que las propuestas en el ámbito urbano también han obtenido creciente interés. Al respecto, Delgadillo y Torres (2011) destacan los trabajos de Luis Unikel y Gustavo Garza.
No obstante lo anterior, García y Salgado (2014) indican que a pesar de la innegable importancia de los estudios regionales, éstos usualmente no derivan en acciones concretas. Agregan que en las regionalizaciones a nivel del municipio, éste se concibe como un ente aislado, sin reparar en la posibilidad de conjuntar recursos que resulten en más beneficios. Las autoras sugieren que los gobiernos locales debieran considerar los siguientes elementos para el desarrollo regional:
La identificación de los flujos de interacción con los municipios vecinos, y en función de ello establecer convenios de colaboración.
Proponer gestiones conjuntas de los gobiernos municipales que promocionen el desarrollo regional.
Implementar cambios estructurales en materia administrativa para facilitar la cooperación interinstitucional.
De lo anterior se desprende la importancia de las técnicas de regionalización en el campo de la política pública; sin embargo, desde la perspectiva metodológica existen diferentes aristas que deben ser tomadas en cuenta. Por un lado, la literatura subraya la importancia de la adecuada formación de agregaciones espaciales, como lo indica la teoría del problema de unidad de área modificable. Además, se requiere el perfeccionamiento de algoritmos que permitan realizar dichas agregaciones, siempre bajo la consideración de la dificultad computacional que implican esos desarrollos.
Al respecto, el trabajo de Duque, Artís y Ramos (2006) es un buen ejemplo de cómo se pueden complementar la perspectiva de la política pública con los elementos metodológicos de la agregación espacial. Dichos autores parten de cuatro esquemas de regionalización: la oficial (o administrativa)3 y tres obtenidas a partir de técnicas de agregación (regiones que denominan analíticas). Las agregaciones analíticas resultan más similares a la distribución espacial del desempleo que la regionalización administrativa, lo que además resulta en una mejor medición de las disparidades regionales. De manera que considerar elementos técnicos en la conformación de los esquemas regionales es una sugerencia que se vuelve evidente.
Dado lo anterior, en este documento se presentan un problema y una propuesta de solución. Para ello se utilizará el caso de la Zona Metropolitana del Valle de México (ZMVM). En primer lugar, por ser la zona con mayor número de municipios, lo cual puede representar una dificultad en términos de la cooperación de los gobiernos locales. En segundo lugar porque su heterogeneidad se manifiesta en complejas problemáticas que padece la sociedad. De hecho, ante esa circunstancia, Iracheta (2010: 16) señala la conveniencia de establecer la participación de gobiernos locales y sociedad civil organizada en algún formato regional, es decir, representantes de conjuntos de municipios homogéneos en el contexto del Fondo Metropolitano.
Así las cosas, en este documento se realiza una revisión teórico-metodológica que fundamenta la agregación espacial que se efectuará, mostrando la aplicación práctica y la utilidad de recurrir a estas técnicas. Por ello en la primera sección se aborda el problema de unidad de área modificable, mientras que la segunda presenta diferentes métodos de agregación espacial propuestos en la literatura. En la tercera sección se explica el algoritmo MaxP, pues es la opción que se consideró adecuada para tratar los datos del ejemplo, dejando para la parte final unas breves conclusiones.
Problema de unidad de área modificable
La dependencia espacial es una de las suposiciones usuales en los estudios de la ciencia regional y urbana (Andersson y Grasjö, 2009). Este concepto tiene que ver con la denominada primera ley de la geografía, formulada por Waldo Tobler, la cual establece que las cosas más próximas en el espacio tienen mayor relación que las distantes. Anselin (1988) define a la dependencia espacial como una relación funcional entre lo que ocurre en un punto en el espacio y lo que ocurre en cualquier otro.
De acuerdo con Anselin (1988) la dependencia puede tener dos orígenes. El primero es producto de los errores de medida en las observaciones de unidades espaciales contiguas, lo que indica que algunos de los problemas de medición se deben a la elección arbitraria de las unidades espaciales de observación, a la agregación de éstas o a la presencia de efectos de derrama. El segundo deriva de la existencia de una variedad de fenómenos de interacción espacial; este supuesto se relaciona con la importancia del espacio en la estructuración de explicaciones de la conducta humana, y es la esencia de la ciencia regional y la geografía.
Si bien los conceptos de dependencia y autocorrelación espacial no son sinónimos, en ocasiones se usan indistintamente. La autocorrelación espacial es una forma débil de la dependencia y se define a través de un momento de la distribución conjunta (Anselin, 1999). La autocorrelación espacial se puede expresar formalmente como:
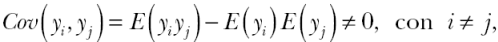
donde i, j son las localizaciones individuales, mientras yi, yj son los valores de una variable aleatoria de interés en esa localización (Anselin, 1999: 4).
De acuerdo con Openshaw (1984) no existe autocorrelación espacial a nivel individual, de manera que el grado de autocorrelación dependerá de las unidades de área consideradas. Por otro lado, sugiere que la escala espacial a utilizar también está en función de lo que se investiga, de ahí que no haya reglas para realizar el agregado de áreas y, en ese sentido, se dice que las unidades son arbitrarias y modificables. Por ejemplo, si bien los datos censales son entidades no modificables, como personas o viviendas, éstos se reportan en unidades que sí lo son, pues son unidades que se definen usualmente con base en consideraciones políticas y de administración gubernamental (Openshaw, 1984: 4). De manera que las unidades territoriales pueden ser, a su vez, agregadas de forma jerárquica en conjuntos más grandes (Gauvin et al., 2007); tal es el caso de un conjunto de municipios que conforman un estado.
El problema de unidad de área modificable (MAUP)4 se relaciona con el hecho de que las medidas para datos transversales son sensibles a los niveles de agregación y a las combinaciones de unidades contiguas que se realizan (Anselin, 1988). El caso más famoso de esta situación es el estudio de Snow (Brody et al., 2000); si Snow en lugar de puntos hubiese utilizado áreas de densidad, probablemente no hubiera sido capaz de identificar las aglomeraciones de cólera alrededor de la bomba de agua contaminada (Gauvin et al., 2007).
El MAUP se constituye por dos componentes distintos aunque relacionados. Siguiendo a Openshaw (1984) el primer problema es el de escala y se refiere a variaciones en los resultados al considerar diferentes agregaciones de unidades espaciales dentro de otras más grandes (e.g., agregaciones de estados contra agregaciones de municipios). El segundo problema es el de agregación, que concierne a las diferencias en los resultados cuando se utilizan diversas formaciones de unidades del mismo tamaño; es decir, para un número fijo de zonas se usan diversas alternativas de agregación (e.g., utilizar distintas regionalizaciones del mismo país).
Al emplear datos espacialmente agregados es usual que se presente el MAUP, por lo que los resultados dependerán de las áreas analizadas. Lo anterior es conocido en sociología como el problema de la falacia ecológica (Anselin, 1988). Freedman (2001) señala que la inferencia ecológica se refiere al acto de deducir sobre conductas individuales a partir de información a nivel agregado. Así, la falacia ecológica se refiere a pensar que las relaciones observadas en los grupos se mantienen para los individuos. Si la agrupación de unidades espaciales es homogénea en el interior, no presentará un problema de falacia ecológica; no obstante, eso no ocurre en la mayoría de las ocasiones (Openshaw, 1984).
Se han desarrollado dos aproximaciones para hacer frente al problema de la falacia ecológica. Por un lado se han formulado modelos estadísticos para reducir el sesgo de agregación, como el trabajo de Gotway y Young (2002). La otra solución ha sido controlar la forma en que se agregan áreas, tal como señala Openshaw (1977), ya que usualmente se utilizan áreas definidas administrativamente para realizar inferencias estadísticas; aunque éstas tienden a verse afectadas por el MAUP (Duque, Ramos y Suriñach, 2007: 196).
En su artículo, Duque, Artís y Ramos (2006) recurrieron a técnicas de agregación espacial. Su ejercicio muestra el efecto de la falacia ecológica a partir de datos de desempleo en España; el objetivo de los autores fue evidenciar que las agregaciones espaciales normativas conducían a índices distorsionados por el MAUP. Para ello ofrecían tres esquemas regionales alternativos, los cuales se obtuvieron a partir de métodos de agregación, con el fin de maximizar la homogeneidad dentro de las regiones formadas.
De los resultados de dicho estudio es importante destacar algunos elementos. Las regionalizaciones obtenidas analíticamente son diferentes de las administrativas, tienen mayor similitud con el patrón espacial del desempleo y muestran los menores niveles de heterogeneidad interna. Las regiones administrativas nuts se concibieron pensando en que fueran configuraciones que minimizaran el impacto de los cambios estructurales sobre las regiones; sin embargo, son las que presentan la mayor variabilidad en la desigualdad intrarregional sobre el tiempo. En palabras de los autores, esto último refleja que importantes cambios intrarregionales han sido agregados de manera inconveniente.5
Métodos de agregación de unidades espaciales
Los métodos de agregación espacial han recibido una gran atención en la literatura especializada debido a su aplicabalidad a diferentes contextos. Algunas aplicaciones se han referido a la delimitación de distritos políticos (Hojati, 1996; Bozkaya, Erkut y Laporte, 2003), zonas de mercado (Zoltners y Sinha, 1983; Ríos-Mercado y Fernández, 2009), zonas de servicios (Armstrong, Lolonis y Honey, 1993; Wang, Kwan y Ma, 2014), zonas de servicios de emergencias (D'Amico et al., 2002; Indriasary et al., 2010), zonas receptoras de recursos energéticos (Bergey, Ragsdale y Hoskote, 2003; Tiede y Strobl, 2006), asignación de usos de suelo (Aerts y Heuvelink, 2002; Santé-Riveira et al., 2008), entre otros.
En función de los objetivos y métodos aplicados, estas técnicas han recibido diferentes nombres: regionalization, zone design, zoning, clustering, districting and redistricting, territory design, territory alignment, spatial allocation, partitioning, spatial tessellations, entre otros (Moreno y García, 2011). Su importancia radica en que la inferencia estadística se realiza de acuerdo con las regiones analizadas, las cuales tienden a ser definidas administrativamente y a verse afectadas por el MAUP.
Dado que la estructura espacial subyacente a los datos tiene un fuerte alcance en el análisis, es relevante considerar restricciones de contigüidad espacial. Así, los métodos de agregación se pueden clasificar en dos grandes grupos, como se muestra en el Esquema 1. La diferencia entre ellos reside en la inclusión explícita o no de dicha restricción (Duque, Ramos y Suriñach, 2007). A continuación se presenta brevemente la idea del proceso que sigue cada uno de estos métodos al citar algunos de los trabajos más importantes de las distintas clasificaciones.
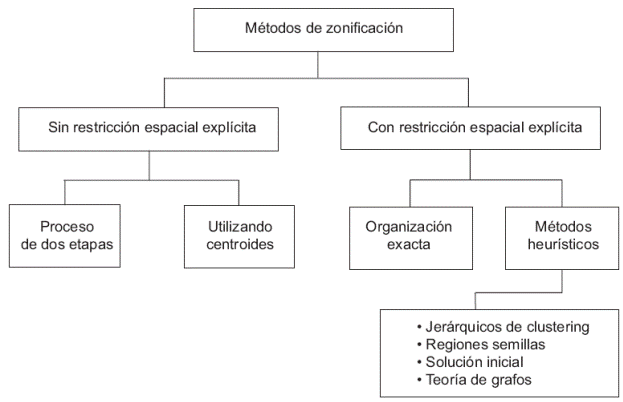
Fuente: Elaboración propia con base en Duque, Ramos y Suriñach, 2007.
Esquema 1 Clasificación de métodos de agregación espacial
Los métodos sin restricción explícita consideran la contigüidad en una etapa posterior. Dentro del subgrupo proceso de dos etapas destaca el aporte de Openshaw (1974, citado en Openshaw, 1977, y Duque, Ramos y Suriñach, 2007). En una primera etapa se agrupan áreas similares en términos de las variables, mientras que la segunda verifica la contigüidad. En cada una de las iteraciones siguientes se obtiene una nueva solución a partir de la anterior. Uno de los inconvenientes de este algoritmo es la necesidad de ir ajustando el número de regiones deseadas.
En ocasiones se solicita que las regiones cumplan el criterio de compacidad, de manera que éstas se forman a partir de centroides.6 Dentro de estos métodos es usual referirse al trabajo de Horn (1995), en el que se busca encontrar la partición más compacta, donde la suma de las aristas interregionales ponderadas sea mínima. Se aplican pequeños cambios a una partición inicial, y una partición será la solución final si se formó el número establecido de territorios, si son lo más compactos posibles y si los valores umbrales de las variables se cumplen en cada región. Los movimientos que se realizan en cada etapa son aquellos que puedan hacerse entre las periferias de las regiones; el algoritmo termina cuando ya no se obtienen mejoras.
En los métodos con restricción explícita se requiere información sobre las relaciones espaciales entre las áreas vecinas. Uno de los subgrupos es el de optimización exacta, el cual resulta poco conveniente desde la perspectiva computacional. Y es que se pueden lograr propuestas téoricamente adecuadas, pero que no son eficientes, pues la restricción de contigüidad se incrementa exponencialmente con el número de áreas y regiones a considerar. Un trabajo clásico es el de Zolterns y Sinha (1983), donde las redes carreteras definen si las áreas están interconectadas. Este procedimiento inicia con un conjunto de áreas consideradas regiones centrales, de forma que se calculan las rutas más cortas entre cada centro y las otras áreas ponderando, por ejemplo, con los tiempos de trayecto.
Dada la dificultad de resolver esta problemática de manera exacta se ha incrementado el uso y desarrollo de heurísticas.7 El grupo jerárquicos de clustering adaptados solamente permite regiones que se conecten espacialmente y cada área es una región en la fase inicial. Una referencia tradicional es la de Lankford (1969), donde se realizan comparaciones contra otros métodos. El autor concluye que el método de centroides requiere de numerosas repeticiones para alcanzar un patrón definido, mientras que el algoritmo de Ward brinda resultados similares al de centroides, resaltando la sensibilidad del resultado ante el algoritmo elegido. La propuesta del autor es la que mejor identifica los patrones, además de examinar solamente a los vecinos inmediatos cuando se agregan más puntos al patrón.
Iniciar los algoritmos partiendo de un conjunto de regiones semillas es una estrategia común. Por ejemplo, Openshaw (1977) inicia con un arreglo de zonas disjuntas, posteriormente enlista las áreas contiguas a cada una de éstas. Los elementos de la lista se van insertando aleatoriamente en diferentes zonas y así se forman nuevos arreglos. Éstos intentan mejorar la función objetivo, de manera que se realizan iteraciones hasta que la mejora en la función es menor a cierta tolerancia especificada previamente. Ésta es una importante aportación sobre técnicas que permiten ir incrementando el número de áreas pertenecientes a una región.
El documento de Openshaw y Rao (1995) es un referente de los métodos que modifican una solución factible inicial. Los autores sugieren dos planteamientos alternativos de este algoritmo, basados en dos diferentes heurísiticas. En la primera estrategia recurren al recocido simulado: se toma una zona, de ella se elige aleatoriamene alguna de sus áreas vecinas; si mejora la solución, el movimiento es aceptado; si no lo hace, se permite con una mínima probabilidad. En la otra opción utilizan la búsqueda tabú: se elige un área vecina de una zona; el área se acepta si el criterio mejora, de no hacerlo se verifica si algún vecino de esa área consigue una mejora; cuando no hay posibles mejoras en ese movimiento se guarda como uno prohibido. La principal propuesta de este trabajo es la exploración con diferentes técnicas heurísiticas para lograr la mayor homogeneidad dentro de las regiones, respetando la contigüidad.
Otras metodologías recurren a la teoría de grafos. La idea es que cada área representa un nodo, los cuales se unen a través de aristas ponderadas. Hansen et al. (2003) subdividen el grafo maximizando las disimilitudes entre nodos y con ello van eliminando aristas y formando clusters. Dadas n áreas, el algoritmo devuelve diferentes soluciones, considerando clusters de 2, 3, ..., n - 1 áreas; lo cual puede resultar en una tarea computacional difícil. El autor explica que la inclusión de las restricciones de contigüidad evita que entidades en los extremos de la cadena que puedan ser muy diferentes entre sí se asignen en la misma categoría.
Duque Cardona (2004: 18) explica que métodos como el de Openshaw (1977) y Horn (1995) se han utilizado con el fin de minimizar el efecto MAUP en el proceso de regionalización. El algoritmo de agregación propuesto por Openshaw llamado AZP es un método que si bien no garantiza encontrar el óptimo global, localiza un buen óptimo local. Es claro que los problemas de agregación espacial cuanto más grandes son, mayor dificultad implican, por lo que se sugiere el desarrollo y mejora continua de heurísticas.
Algoritmo MaxP
Son tres las bondades del algoritmo MaxP que lo vuelven atractivo respecto de otras propuestas. La primera de ellas es que permite que el número de regiones se establezca de manera endógena, pues posibilita que las áreas similares se agrupen de forma natural y no porque se haya forzado a cumplir un número predefinido. Por otro lado, es importante señalar que pretende la minimización de la heterogeneidad interna de las regiones, buscando reducir el efecto de agregación que pueda producir el problema de unidad de área modificable. Y finalmente, no busca la compacidad de las regiones, más bien, permite que la agregación se realice siguiendo el patrón espacial de las variables. A continuación se presentan algunos estudios que recurrieron a este algoritmo y obtuvieron resultados satisfactorios tras su aplicación.
Utilizar regionalizaciones acordes al tema de interés de los investigadores es fundamental. A manera de ejemplo, en el caso de México existen diversas propuestas de regionalización: Esquivel (1999), Hanson (2003), Chiquiar (2005), por mencionar algunos. Sin embargo, el trabajo de Rey y Sastré-Gutiérrez (2010) compara agregaciones propuestas por investigadores y por instituciones con la ofrecida por el algoritmo MaxP. Uno de los principales resultados es que su propuesta es la que reporta el menor nivel de desigualdad interregional en términos del PIB estatal per cápita, la cual es estadísticamente significativa en todos los años de estudio, a diferencia de los otros esquemas regionales.
El algoritmo MaxP permitió analizar el cambio espacial en las zonas metropolitanas de Estados Unidos en Rey et al. (2011). La unidad de análisis fueron los census-tracts, pues fue la escala elegida para representar el concepto de neighborhoods. La idea detrás de la conceptualización del cambio espacial es que los neighborhoods son unidades con una composición socioeconómica y una impresión geográfica que se modifica con el transcurso del tiempo. A partir de un conjunto de 22 variables censales se realizó la agregación de censustracts dentro de cada zona metropolitana para dos puntos en el tiempo, 1990 y 2000.
Los autores propusieron un índice de cambio espacial considerando cuántas áreas cambiaron de región dentro de una misma zona metropolitana de un periodo a otro. Uno de los resultados interesantes es que dos tercios de los census-tracts sufrieron alguna reconfiguración en sus componentes socioeconómicos. Y, por otro lado, aquellas áreas que al inicio del periodo tenían una alta densidad poblacional y que estaban localizadas más centralmente presentaron los mayores cambios espaciales hacia el año 2000, a diferencia de las áreas menos densas y más periféricas.
Otra interesante aplicación del MaxP se encuentra en Duque, Royuela y Noreña, (2012). Su objetivo es lograr la delineación de áreas deprimidas dentro de la ciudad de Medellín, Colombia. La escala que utilizan es la correspondiente a los barrios; sin embargo, en algunos casos éstos se constituyen por un número pequeño de hogares en comparación con otros. Entonces, se propone el diseño de "regiones analíticas", las cuales eviten los problemas que surgen de utilizar las regiones que se definen de manera administrativa.
Los autores explican que sus regiones analíticas deben cumplir con dos criterios. Primero, ser homogéneas en términos de características socioeconómicas que perfilen su situación de pobreza. Segundo, que cada región contenga al menos 100 hogares, a fin de asegurar la validez estadística. Por lo anterior, el MaxP es una opción viable para construir estas regiones una vez manipulados los datos. Posteriormente se calculan los índices locales I de Moran y G* (para analizar la existencia de dependencia y concentración espaciales, respectivamente) al índice de privación de cada región.8 Las regiones analíticas, a diferencia de las administrativas, sí permitieron la identificación significativa de agrupaciones de barrios que presentan características asociadas a la pobreza.
Por lo ilustrado anteriormente, en el presente documento se recurrirá al algoritmo MaxP propuesto por Duque, Anselin y Rey (2012), ya que dicho método no requiere establecer previamente un número de regiones, pues por lo general no hay reglas para esa condición. Básicamente, el método agrega una determinada cantidad de áreas en un número máximo de regiones, de forma que cada agrupación satisface un valor predefinido (umbral) de un atributo espacial, e.g., población por región o número mínimo de áreas por región. Este algoritmo contiene una restricción de contigüidad explícita y minimiza la heterogeneidad intrarregional.
Siguiendo a los autores del algoritmo, el objetivo del MaxP es buscar la partición óptima Pp* . Siendo Π el conjunto de las posibles particiones Pp de un territorio, y siendo H la función que mide la heterogeneidad total de la partición, el problema se formula de la siguiente manera:
Determinar
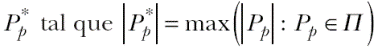
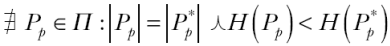
Dado que resolver de forma exacta el algoritmo es computacionalmente costoso, se recurre a una heurística para aproximar las soluciones. En dicha heurística la función objetivo a minimizar consta de dos términos. El primero controla el número de regiones, mientras que el segundo controla la heterogeneidad total (pues considera las disimilitudes entre áreas que pertenecen a la misma región). El algoritmo se divide en dos fases: la de construcción y la de búsqueda local. En la fase de construcción se generan regiones a partir de áreas semillas, a las cuales se van agregando áreas vecinas hasta alcanzar el valor umbral. La búsqueda local modifica la solución de la fase anterior al tiempo que mejora la función objetivo.
La solución brindada por el código MaxP puede ser evaluada obteniendo un pseudo p-valor. Entre regiones se compara la suma de cuadrados de la solución contra soluciones simuladas, en las cuales las áreas fueron aleatoriamente asignadas a las regiones, manteniendo la cardinalidad de la solución original.9 Se puede establecer el número de simulaciones a realizar y este proceso se calcula una vez concluida la regionalización. Si el pseudo p-valor fuese menor a 0.05 indicaría que la agregación obtenida es significativamente diferente a una partición aleatoria.
Una aplicación a la ZMVM
En el presente documento se eligieron algunas variables que pudieran representar problemáticas de interés para los tomadores de decisiones.
De manera tal que los resultados obtenidos pueden ser una guía para una organización regional de esta zona metropolitana.
Para la utilización del algoritmo MaxP se recurrió a los siguientes criterios. Se consideró una matriz de pesos espaciales tipo rook, la cual define a dos unidades espaciales como vecinas si comparten una frontera de longitud mayor a cero.10 El arreglo de observaciones de m atributos de n áreas se conformó con diferentes variables, asociadas a algunas de las problemáticas que enfrenta la ZMVM. Los valores umbrales para la formación de regiones pueden ser de dos tipos: un mínimo de unidades espaciales por región, o un valor mínimo sobre una determinada variable. En el presente documento se recurre únicamente a la agregación por número de unidades geográficas, estableciendo el umbral en 5 y 7 municipios.
Es adecuado hacer observaciones sobre algunas cuestiones técnicas del algoritmo. El número de soluciones iniciales a generar es el número de veces que se itera el algoritmo a fin de encontrar la mejor solución, el cual se estableció en 999. No se establecieron elementos "semillas" (áreas con las que se inician las agregaciones); cuando no hay sugerencias el algoritmo selecciona áreas aleatoriamente. Para la aplicación de los ejercicios se recurrió al lenguaje Python v.2.7.6 y a la librería PySAL v.1.6.0.
La elección de variables tiene solamente un carácter exploratorio y como un primer acercamiento a los problemas que enfrenta la ZMVM. A continuación se describirán las variables utilizadas, indicando la fuente y año correspondientes. La escala espacial fue el municipio, por ser un ámbito de acción política que se recomienda en la gestión, ejecución y vigilancia de los proyectos (Iracheta, 2010: 15, en el contexto particular del Fondo Metropolitano). Los conjuntos de variables utilizados fueron:
Agropecuario: porcentaje de población ocupada que se encuentra en la división ocupacional "trabajadores agropecuarios" (Cuestionario ampliado del Censo de Población y Vivienda 2010).
Delitos: ilícitos del fuero común denunciados (SESNSP, 2012).11
Desempleo: tasa de desocupación (elaborada a partir del Cuestionario básico del Censo de Población y Vivienda 2010).
Dotación de agua: porcentaje de viviendas particulares habitadas con agua entubada, considerando dotación de agua diaria (Cuestionario ampliado del Censo de Población y Vivienda 2010).
Ingreso: porcentaje de población ocupada que tiene un ingreso por trabajo de hasta un salario mínimo mensual (Cuestionario ampliado del Censo de Población y Vivienda 2010).
Educación: población de 3 a 14 años que no asiste a la escuela; población de 8 a 14 años que no sabe leer ni escribir; población de 15 años y más analfabeta; población de 15 años y más sin escolaridad; población de 15 años y más con educación básica incompleta (SCINCE, 2010).12
Vivienda: viviendas con las siguientes características: piso de tierra; con 2.5 o más ocupantes por dormitorio; con un solo cuarto; sin luz eléctrica; sin agua entubada; sin excusado o sanitario; sin drenaje; sin luz eléctrica, agua entubada ni drenaje (SCINCE, 2010).
Residuos: promedio diario de residuos sólidos urbanos recolectados (indicadores de medio ambiente, INEGI, 2010).13
El objetivo de seleccionar estas variables fue mostrar que diferentes problemáticas se pueden presentar en distintos lugares. Por ello, los proyectos deben considerar cuál es el fenómeno que desean abordar y dónde se encuentra geográficamente localizado. Si bien parece obvio que distintos fenómenos ocurren en diferentes lugares, para muchos no es algo tan claro, y muestra de ello es que suelen establecer regionalizaciones sin tener en consideración el fenómeno que se desea analizar, como señalan Iracheta e Iracheta (2014: 99-100) para el Fondo Regional del Gobierno Federal Mexicano.
Se realizaron dos ejercicios de agregación; el número de regiones en cada ejercicio es reportado en el Cuadro 1. En el primero se estableció como umbral el mínimo de siete municipios por región, en el segundo se estableció un mínimo de cinco. Todas las soluciones resultaron con un p-valor de 0.001, indicando que todas las agregaciones son significativamente diferentes de una formación aleatoria. En el primer ejercicio, el número de agregaciones varió de siete a nueve; mientras que en el segundo se encontraron entre 10 y 14.

Se puede inferir que el incremento en el número de agregaciones cuando se reduce el número de municipios por región se debe a dos cuestiones. En primer lugar, a la heterogeneidad existente entre las unidades y, por otro lado, a que el algoritmo busca el mayor número de agregaciones posibles. En este punto, sin embargo, hay que evitar la confusión. Si las unidades presentaran mayor homogeneidad, el número de agregaciones debiera ser menor a pesar de que el umbral se redujera. No obstante, no son lo suficientemente similares y por ello el algoritmo genera más agregaciones a fin de cumplir con la función objetivo: determinar el mayor número de agregaciones con el menor valor de heterogeneidad total en su interior.
En el Mapa 1 se muestran las regionalizaciones obtenidas con el umbral de siete municipios.14 Estos mapas permiten ver que cada grupo de variables agrupa de distinta forma a las unidades geográficas. Si bien algunas parecen mantenerse, sólo son unos cuantos municipios, pues en cada agregación varía la forma en que se agrupan con los vecinos.
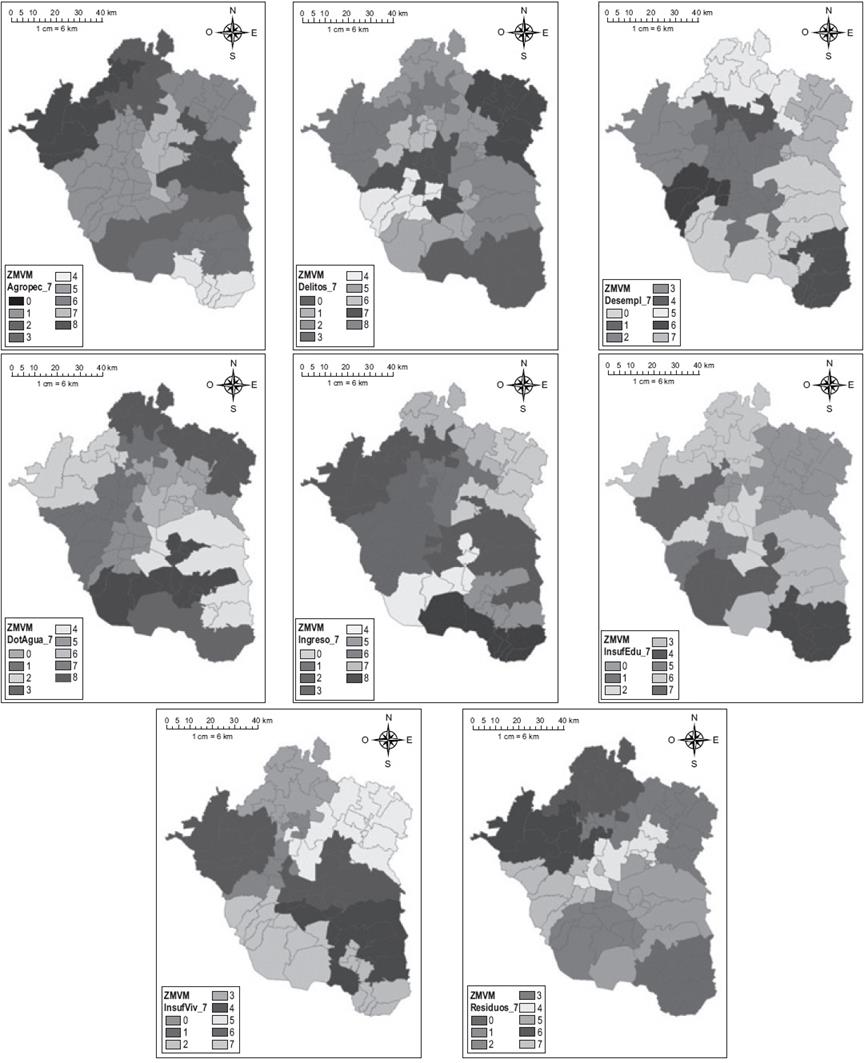
Fuente: Elaboración propia.
Mapa 1 Agregaciones obtenidas a partir de los diferentes conjuntos de variables, con umbral de siete municipios por región
Destaca que bajo el umbral de siete municipios, para todas las variables se obtienen menos del máximo posible de regiones (que serían 10). Incluso en el caso donde se consideran todas las variables juntas resultan siete agregaciones, como se muestra en el Mapa 2, lo que significa que en algunos casos se pudieron agrupar más allá de las siete áreas establecidas como umbral para una región, indicando cierto grado de homogeneidad entre las unidades.
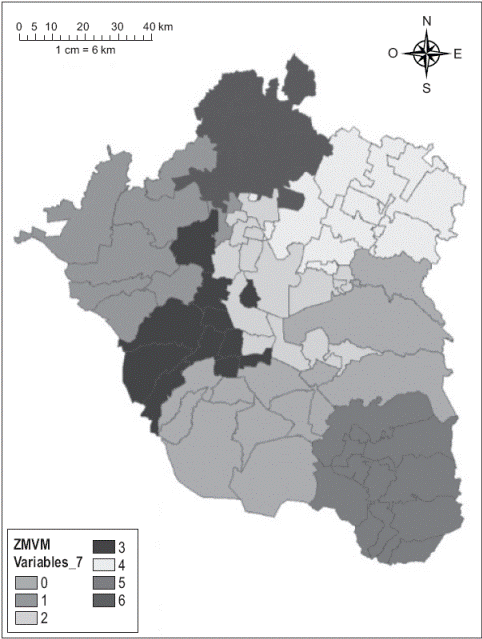
Fuente: Elaboración propia.
Mapa 2 Agregaciones obtenidas seleccionando todas las variables, con umbral de siete municipios por región
En los Mapas 1 y 2 hay un elemento a destacar.15 A pesar de existir diferentes patrones de acuerdo con cada una de las variables, se presenta cierta similitud entre sí y respecto de la agregación del Mapa 2. Esto supone que hay una diferenciación entre los municipios que resalta a pesar de considerar diferentes variables, lo que hace pensar en el MAUP. Es decir, en el ámbito nacional la ZMVM surge como una región con características propias que puede diferenciarse, pero en su interior siguen presentándose contrastes. Dichos contrastes seguramente persisten a una escala menor, como localidades o ageb; sin embargo existe una cuestión de suma importancia: si bien a menor escala se obtienen resultados más precisos, en términos de política pública debe usarse la escala que mejor permita la colaboración de los distintos ámbitos de gobierno.
Los resultados presentados en esta breve aplicación representan un apoyo empírico a la utilidad de recurrir a una técnica de agregación que permita identificar regiones de acuerdo con determinadas características. Dichas agregaciones espaciales pueden ser utilizadas posteriormente para mejorar la focalización de programas de política pública, lo que permitiría garantizar la mayor eficiencia de los programas, así como de sus presupuestos. Brindar poder a esquemas regionales de gobierno (en este caso, a nivel de un conjunto de municipios) es una posibilidad de aprovechar las ventajas propias de las regiones y así promover su desarrollo económico y social.
Reflexiones finales
Los métodos de agregación espacial permiten obtener esquemas regionales adecuados a distintos intereses y objetivos, y aunque una de sus limitantes es el aspecto computacional, ello ha conducido a la constante mejora de los algoritmos. Su mayor ventaja radica en la amplia gama de opciones existentes: técnicas que buscan la compacidad, técnicas que parten de buscar un número predefinido de regiones, o técnicas que regionalizan de acuerdo con algún atributo particular.
A pesar de las virtudes de estos métodos su aplicación no ha sido generalizada más allá de la investigación. Por ejemplo, respecto de la diferenciación existente entre los municipios de la ZMVM, son numerosos los trabajos que aportan evidencia del fenómeno; tal es el caso de los documentos de Aguilar y Ward (2003), Ariza y Solís (2009), Neme, Pulido y Neme (2011), Pérez y Santos (2011), Aguilar y Mateos (2011); sin embargo, los programas de política pública usualmente definen sus regiones sin aclarar los soportes teóricos o metodológicos con los que fueron diseñadas.
El objetivo de este documento fue mostrar los fundamentos sobre los cuales se desarrollan los métodos de agregación espacial y evidenciar la pertinencia de utilizar tales herramientas en el diseño de la política pública, particularmente cuando ésta se refiere a dimensiones espaciales menores, como los municipios.
Aquí se realizó un ejercicio de agregación con los municipios que conforman la ZMVM y puede concluirse que se presentan diferencias en el espacio de acuerdo con las distintas variables seleccionadas en el proceso. Cabe señalar que en el ejercicio donde se combinaron todas las variables se encontró un número menor al máximo esperado de regiones. Esto es importante porque implica la existencia de patrones claros de asociación entre las unidades espaciales que se mantienen a pesar de considerar diferentes variables. Una posible extensión de lo presentado es la utilización de un conjunto definido de variables asociadas a un problema específico, de manera que los resultados pudieran ser extendidos a un programa de política pública que se beneficie a partir de la regionalización obtenida.

