











 text new page (beta)
text new page (beta) Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
Permalink
1. Introducción
Es de gran interés para los establecimientos, que ofrecen un producto o servicio, conocer la cantidad de posibles visitas que los clientes realizarán en un periodo de tiempo específico. Del mismo modo, estudiar si un determinado conjunto de variables guarda una relación entre si y el número de visitas, lo que resulta muy útil, pues es posible explicar qué porcentaje de variación en la variable de visitas puede ser explicada por el conjunto de variables que se estudian. Por ejemplo, en los museos, es importante conocer el número de visitas la cual es una de las métricas más importantes para evaluar el grado de demanda que se tiene y al mismo tiempo, evaluar si las estrategias de difusión están funcionando o de lo contrario, tomar decisiones más acertadas para mejorar la calidad de atención y satisfacción con los visitantes.
Los modelos lineales generalizados permiten describir la relación que existe entre una variable dependiente o de respuesta y una o más variables independientes o predictoras (Uyanik y Güler, 2013) (Graefe, Armstrong, Jones, & Cuzán, 2014). Entre estos modelos se encuentra la regresión lineal ordinaria (RLO) (Glenn, 2002) y la regresión de Poisson (RP) (Montgomery, Peck, y Vining, 2021) (Gardner, Mulvey, & Shaw, 1995). Por ejemplo, en (Azhari, Widyaningsih, y Lestari, 2018) propusieron un modelo de regresión de Poisson para pronosticar el promedio de goles por cada equipo del foot ball. Los autores utilizaron cuatro variables predictoras y obtuvieron una proporción de predicción correcta del 80 %. Por otro lado, Casey A. G. y otros usaron el mismo método, utilizando dos variables predictoras para predecir la actividad diaria de incendios forestales en Alaska (Graff et al., 2020). En el área de la salud, Maria I. V y otros utilizaron una regresión multivariante de cuasi-Poisson para modelar la evolución de los nuevos casos de covid-19 del año 2020 en Chile (Vicuña, Cristián, y Quiroga, 2021). Lo autores también utilizaron dos variables indicadoras predictoras (festividad y día de la semana) y la bondad de ajuste del modelo se evaluó con el Pseudo R2 Heinzl-Mittlböck que fue del 95.3 %.
Con respecto al modelo de regresión lineal múltiple, se han publicado varios trabajos en los que se utiliza dicho modelo. Por ejemplo, Z. Ismail y otros publicaron en (Ismail, Yahya, y Shabri, 2009) el pronóstico de los precios del oro basándose en ocho factores económicos. Las estimaciones de los parámetros para el modelo se llevaron a cabo utilizando un paquete estadístico y se usó el error cuadrático medio como medida para determinar la precisión del pronóstico. Otro ejemplo, es el pronóstico del número de pacientes asmáticos en Kota Kinabalu, Sabah (Gabda, Jubok, Budin, y Hassan, 2008). Los autores utilizaron como variables la calidad del aire y factores metereológicos siendo en total cuatro variables.
En este trabajo se presenta como caso de estudio el número de visitas a los museos en México. Los datos utilizados para el estudio corresponden a la base de datos publicada por el Instituto Nacional de Estadística y Geografía (INEGI). Se implementó el modelo lineal generalizado para pronosticar el número de visitas por año. Se aplicó la regresión lineal ordinaria y la regresión de Poisson. Las variables que fueron usadas son: página web (PW), capacidad de recepción y atención (CRA), temática principal (TP), colección permanente (CP), titularidad (T), entrada (E), cuota adulto (CA), descuentos (D), tipo de visitas (TV), días abiertos al año (DAA) y exposiciones temporales (ET). Estas fueron agrupadas mediante variables ficticias para mantener datos cuantitativos y sencillos de manejar. Para mitigar una posible colinealidad entre variables se obtuvo un nuevo conjunto de variables por medio del análisis de componentes principales sobre las cuales se aplicaron los modelos de regresión. Se tomó el número de visitas registradas en los años 2017 y 2018 para encontrar las funciones características de ambos modelos, obteniendo un
2. Métodos, técnicas e instrumentos
Modelo lineal generalizado
El modelo lineal generalizado, relaciona linealmente la variable dependiente con los factores y las variables independientes (covariables) mediante una función de enlace, definida de la siguiente manera (Montgomery et al., 2021):
Donde:
Donde:
Donde:
En particular, la regresión lineal ordinaria y la regresión de Poisson son dos modelos muy comunes para el pronóstico de eventos que dependen de una o más variables. La función de enlace para el caso ordinario es de la forma
Por otro lado, la función de enlace para el caso de la regresión de Poisson es de la forma
Optimización de los factores
El sistema de ecuaciones de la forma del modelo lineal generalizado para encontrar la función característica es:
Donde:
Este sistema de ecuaciones se puede resolver con el método Newton-Raphson que está basado en la convergencia iterativa y la solución se representa de la siguiente manera:
Donde:
Es importante mencionar que no se requiere de contar con una extensa cantidad de datos de muestra para obtener un modelo de regresión idóneo que ofrezca un buen ajuste, por ejemplo pueden ser veinte registros de muestra. Lo importante es que la muestra contenga un rango de entre el valor mínimo y el valor máximo para cada una de las variables predictoras en el conjunto de observaciones, pues esto genera una mejor variación de los datos permitiendo una mejor definición inicial. Siempre que se tengan nuevas observaciones se debe entrenar el conjunto de muestra y ajustar nuevamente los métodos de regresión y lograr así una mejor exactitud.
Bondad de ajuste
En el análisis de regresión es importante determinar qué tan bien nuestra función de regresión ajusta a los datos y para ello se emplea el test de bondad de ajuste denominado como coeficiente de determinación múltiple
Donde:
Categorización de la base de datos
Los datos de conteo que se analizaron pertenecen al número de visitas anuales en los museos del territorio de México correspondientes a los años 2017-2020. La información se obtuvo de la base de datos del INEGI que contaba con información de 1156 museos registrados de los cuales se tomó una muestra de 110 museos para obtener un modelo de regresión que permita el pronóstico de dichas visitas anuales por museo (
Tabla 1 Categorización de las variables predictores y de respuesta.
| Variable predictora Predictor variable |
Valor según criterio Criterion value |
|---|---|
|
Página web ( Web page |
1 = Sí (Yes); 2 = No (No) |
|
Capacidad de recepción y atención Reception and service capacity |
1 = de 1 a 25 visitantes (from 1 to 25 visitors); 2 = de 26 a 50 visitantes (from 26 to 50 visitors); … 8 = de 10 001 visitantes en adelante (from 1000 onwards visitors) |
|
Temática principal
Main theme |
1 = Arqueología (Archeology); 2 = Arte (Art); 3 = Paleontología (Paleontology); 4 = Historia (History); 5 = Industria (Industry); 6 = Ciencias (Science); 7 = Tecnología (Technology); 8 = Ambiental/ Ecológico (Environmental / Ecological) |
|
Colección permanente ( Permanent collection |
1 = Sí (Yes); 2 = No (No) |
|
Titularidad
Ownership |
1 = Federal (Federal); 2 = Estatal (State); 3 = Municipal (Municipal); 4 = Universidad (University); 5 = Asociación (Association); 6 = Fundación (Foundation); 7 = Negocios (Business); 8 = Eclesiástico (Ecclesiastical); 9 = Un solo hombre (One only man) |
|
Entrada
Entrance |
1 = Gratuita (Free); 2 = Algunos días gratis (Some days free); 3 = Sin costo (free of charge) |
|
Cuota adulto en pesos mexicanos Adult fee |
1 = 0; 2 = 1 a 25; 3 = 26 a 50 |
|
Descuentos en pesos mexicanos
Discounts |
|
|
Tipo de visitas
Type of visits |
0 = Sin guía (No guide); 1 = Con persona guía (With guide person); 2 = Con audio guía (Audio guide); 3 = Otros medios (Other means). |
|
Días abiertos al año
Open days of the year |
Desde 0 hasta 365From 0 until 365 |
|
Exposiciones temporales
Temporary exhibitions |
1 = Sí (Yes); 2 = No (No) |
|
Número de vistas en un año ( Annual visits per year |
|
Una vez categorizados los datos se procedió a realizar el análisis de componentes principales, esto con la finalidad de contrarrestar una posible colinealidad entre las variables predictoras. Con este método se obtiene un nuevo conjunto de variables
Tabla 2 Coeficientes pa/ra obtener los valores de las componentes principales.
| Coeficientes | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
CP0 | CP1 | CP2 | CP3 | CP4 | CP5 | CP6 | CP7 | CP8 | CP9 | CP10 |
| PW | 0.3582 | 0.0385 | 0.0274 | 0.1165 | 0.1922 | 0.2622 | 0.1758 | -0.6193 | 0.5777 | 0.0396 | 0.0222 |
| CRA | -0.3481 | -0.2988 | -0.0814 | 0.2231 | -0.2429 | -0.0803 | 0.0450 | 0.3634 | 0.6703 | 0.2852 | -0.0533 |
| TP | -0.0704 | -0.1183 | 0.7909 | 0.0907 | 0.2779 | -0.2680 | -0.3414 | 0.0104 | 0.1578 | -0.2333 | -0.0480 |
| CP | 0.0313 | 0.4459 | -0.3475 | 0.3171 | 0.5078 | -0.5350 | 0.0285 | 0.1356 | 0.1169 | -0.0193 | -0.0394 |
| T | -0.1874 | 0.1419 | 0.1173 | -0.6516 | -0.1471 | -0.4805 | 0.4347 | -0.1899 | 0.1663 | -0.0203 | -0.0291 |
| E | -0.4104 | 0.2195 | 0.2305 | 0.1092 | 0.1850 | 0.1361 | 0.0642 | -0.2400 | -0.2307 | 0.6938 | -0.2633 |
| CA | -0.4884 | 0.2456 | -0.0324 | -0.0066 | 0.0417 | 0.1531 | -0.1524 | -0.1390 | 0.0805 | -0.1057 | 0.7840 |
| D | -0.4328 | 0.2597 | -0.1735 | -0.0863 | -0.0127 | 0.3006 | -0.1865 | -0.0914 | 0.1584 | -0.4938 | -0.5523 |
| TV | -0.0634 | -0.4560 | -0.3333 | -0.4722 | 0.4830 | -0.0297 | -0.4167 | -0.0922 | 0.0491 | 0.1876 | -0.0113 |
| DAA | -0.2432 | -0.3795 | 0.0413 | 0.1139 | 0.4643 | 0.1956 | 0.6498 | 0.1288 | -0.1348 | -0.2648 | 0.0345 |
| ET | -0.2279 | -0.3850 | -0.1887 | 0.3847 | -0.2500 | -0.4054 | -0.0527 | -0.5652 | -0.2131 | -0.1418 | -0.0412 |
En la Figura 1 se muestra el porcentaje de varianza individual y acumulada explicada de las componentes principales. Se puede observar que el número de componentes que se necesitan para explicar al menos el 90 % de la variabilidad de los datos son 7. Este número no implica una reducción de variables considerable, por lo que se decidió utilizar todas las componentes para aplicar las regresiones, las cuales explican el 100 % de la variabilidad de los datos.

3. Resultados y discusión
Los dos modelos de regresión se aplicaron a los datos del 2017 y 2018, con los cuales se obtuvo las funciones características de ambos modelos. La función resultante que estima el número de visitas anuales en función de las componentes principales al aplicar el modelo de regresión lineal RLO es:
La función resultante de aplicar la RP es:
En la Figura 2 se muestra el número de visitas anuales observadas y estimadas con las dos funciones obtenidas. En la Figura 2a se muestran los resultados obtenidos con la RLO y en la Figura 2b los obtenidos con la RP. Los coeficientes de determinación fueron de
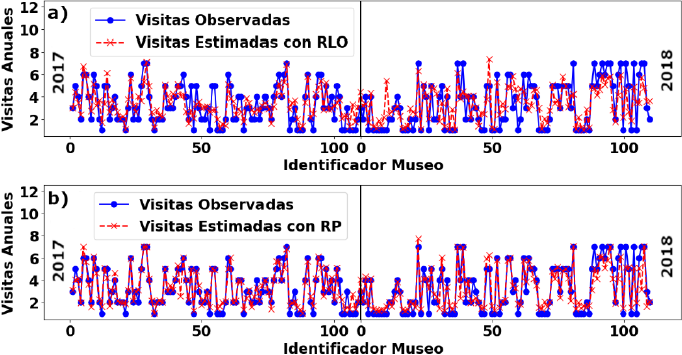
Figura 2 Número de visitas observadas durante los años 2017- 2018 y número de visitas esperadas obtenidas con: a) la regresión lineal ordinaria, y b) la regresión de Poisson.
La función característica obtenida con el modelo de RLO (ecuación 9) se utilizó para estimar el número de visitas anuales esperadas para los años 2019 y 2020 (ver Figura 3). Comparando los resultados estimados con los datos observados, los coeficientes de determinación que se obtuvieron fueron:
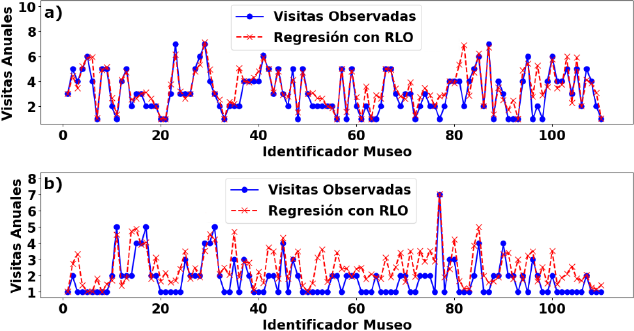
Figure 3 Number of observed and expected visits obtained with the RLO for the years: a) 2019, and b) 2020.
También la función característica obtenida con el modelo de RP (ecuación 10) se utilizó para obtener el número de visitas anuales esperadas para los años 2019 y 2020 (ver Figura 4). El coeficiente de determinación que se obtuvo fue de
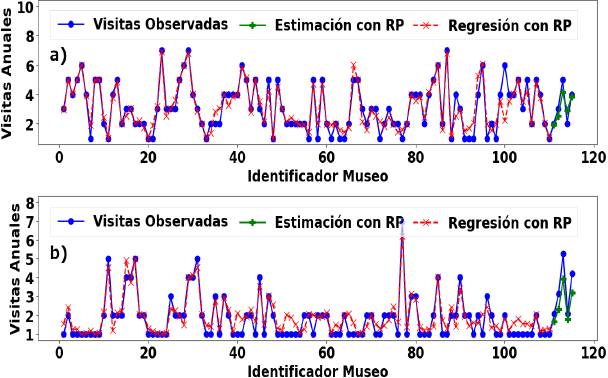
Figura 4 Número de visitas observadas y esperadas obtenidas con la RP para los años: a) 2019, y b) 2020.
Además, el modelo de RP, el cual fue el que mejor ajuste dio al número de visitas anuales observadas, se utilizó para estimar las vistas de cinco museos de prueba (museo 111 al 115) que no se tomaron de muestra para la obtención de dicho modelo. En la Figura 4 se puede observar para cada uno de los años las visitas observadas y las visitas estimadas.
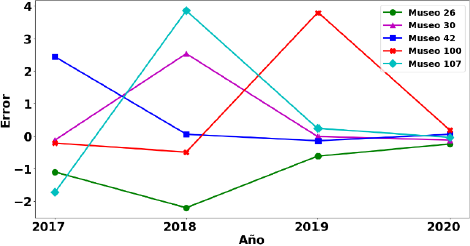
Para el análisis de errores, se utilizaron los datos obtenidos con el modelo de regresión de Poisson por ser el mejor método de ajuste. Para obtener el error, se restó el número de visitas anuales esperadas al número de visitas anuales observadas para los museos de muestra. Para cada año se tomaron los 5 museos que presentaron los mayores errores, obteniendo un total de 20 valores. De estos 20, se tomaron los cinco museos con los mayores errores. En la Figura 5 se muestran los errores de estos cinco museos para los años de 2017-2020. Finalmente, con respecto a los errores que se presentan en las estimaciones del número de visitas anuales de los cinco museos de prueba, se tiene que para los años 2019 y 2020, el máximo error fue de ~1, que en términos de visitas anuales es de 0 a 1000.
4. Conclusiones
Es notorio que con el modelo de RP se obtuvo el mejor ajuste con un coeficiente de determinación de ~
Tomando en cuenta que los resultados obtenidos con el modelo de RP son los que mejor ajuste dieron, fueron los que se utilizaron para el análisis de errores de estimación. El máximo error de estimación que se registró fue de alrededor de 4, en términos de visitas anuales, significa que fueron de entre 10 001 y 20 000; lo que equivale en promedio a un 10 % de un máximo de 150 000 visitas observadas por año. El análisis de componentes principales y los modelos de pronóstico se implementaron en el lenguaje de programación Python manteniendo un bajo costo computacional y de programación con un grado de respuesta inmediato.
Finalmente, en este trabajo se demostró que la implementación de un método de pronóstico basado en el modelo lineal generalizado es una estrategia viable para estimar el número de visitas anuales en algún establecimiento, específicamente en un museo, en el que se requiere un control del espacio, mejorar la experiencia de los visitantes o bien tomar decisiones más acertadas al percatarse de que el nivel de visitantes estimados será bajo.

