











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introducción
Dentro de los estudios históricos, el uso de tecnologías SIG enfrenta un sinfín de desafíos y discusiones. Las polémicas, de carácter epistemológico y metodológico, han sido analizados y ampliamente abordados en algunos trabajos de carácter compilatorio (Gregory y Allen, 2007; Bodenhamer et al. 2010; Lünen y Travis, 2013). Más allá de estos debates, las dos problemáticas fundamentales para la construcción de una infraestructura geoespacial histórica son: 1) El modelado de los cambios en la “espacialidad” de las entidades históricas (territorios, vías de comunicación, o lugares, es decir, polígonos, líneas y puntos, entre otros) y; 2) La conservación de coherencia ante los distintos tipos de “incertidumbre” causada por fuentes históricas de densidad variable, incompletas, confusas y erróneas.
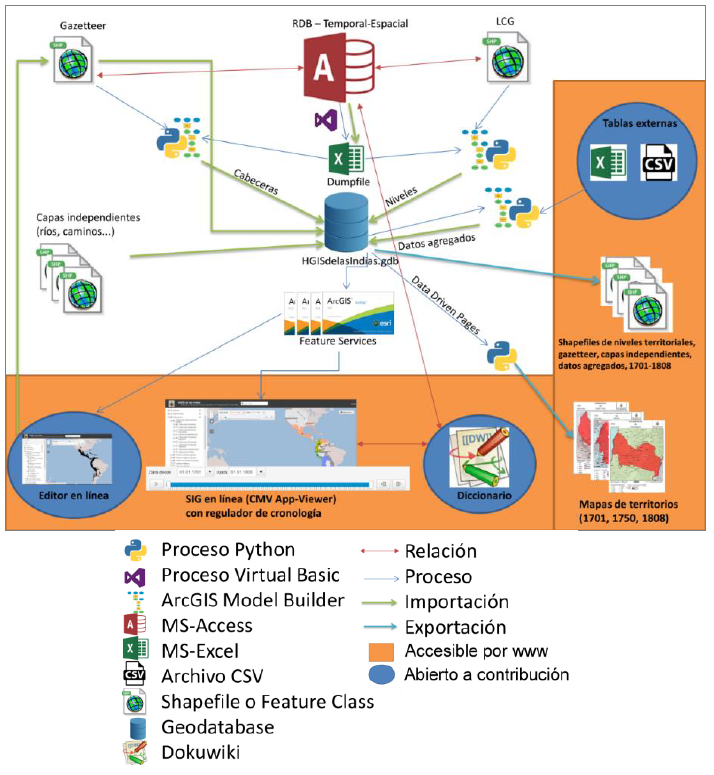
HGIS de las Indias es un sistema que ha sido calificado como un “atlas digital” para la historia de la América borbónica. Sin embargo, dentro de su propia lógica puede ser entendido como una infraestructura, un tipo de “contenedor espacio-temporal” que permitirá representar la espacialidad de los documentos producidos en la época y la producción historiográfica elaborada con base en estos. Para cumplir dicha función, el modelaje tiene que ser capaz de ofrecer una interpretación de la situación de cualquier documento o dato en un momento determinado. Para HGIS de las Indias, hemos elegido una granulación a nivel de año: cada fecha de validez en la base de datos se refiere a la situación a finales de año, por lo que situaciones inestables que existieron sólo por un par de meses no se representan. Como infraestructura, se reconstruye (con base en la granulación temporal referida) diversos tipos de territorios, como audiencias, obispados, provincias y partidos, así como 12 000 lugares de la época. También fue objeto de interés poder representar datos tabulares2 con la localización o extensión correspondientes al dato. Este reto, como veremos, era el más complejo de cumplir.
Resulta evidente que nuestra interpretación de límite, más allá de las críticas que puede despertar el uso mismo del concepto, no es inmune a errores ante la gran extensión geográfica estudiada (desde Vancouver Island hasta la isla de Chiloé, y del Misisipi al Río de la Plata). La situación también resulta compleja porque existe una oscilante calidad y disponibilidad de descripciones y mapas de la época. En efecto, muchos autores han mezclado y confundido conceptos. Por ejemplo, resulta célebre el caso de Juan de Velasco (1842 tomo III: 33-34), quien describió la “Tenencia de los Pastos” (un concepto claramente vinculado con la administración) como una división perteneciente a la provincia de Popayán. En la lista de poblaciones que conformaban la “Tenencia” agrupó pueblos que cultural, étnica y lingüísticamente pertenecían a “los pastos” pero que, al encontrarse al sur del puente Rumichaca, en realidad eran parte del corregimiento de Ibarra, dentro de la provincia de Quito. Como consecuencia de tal error, los pueblos reagrupados por Velasco han sido mal descritos en cuadros demográficos de la provincia de Popayán y otros documentos de tipo administrativo para esa provincia (Herrera, 2009; Durán y Díaz, 2012).
Otros autores tienen todavía otras concepciones de qué era “la provincia de los pastos” (Cieza, 1554; Alcedo, 1786-1789). Dentro de tal interpretación, la provincia no se correspondía totalmente con las listas de colección de tributos y censos de población, pero tampoco era independiente de dicho eje de organización. Lo anterior ha provocado ciertos equívocos entre quienes tratan de reconstruir la etnografía de los pastos, como por ejemplo Schortman y Urban (1992) o Cárdenas-Arroyo (1996). Las razones de las discrepancias entre las fuentes no son explícitas, y sólo se detectan a través de una contrastación profunda de la documentación disponible. Así, al inicio de la labor reconstructiva, teníamos una interpretación deficiente y poco clara de lo que era la provincia de “Los Pastos”, visión que poco a poco fue precisándose. Sin embargo, resulta concebible que aún no se haya llegado al final del proceso.
De hecho, en un censo de 1797 aparece por primera y única vez la población de “El Castigo” como parte de Los Pastos. Se trata de un palenque de cimarrones (esclavos fugitivos) que mantuvo una relación difícil con las autoridades de Popayán. Simplemente no disponemos de información sobre si el área de El Castigo desde siempre había sido entendida como parte de Los Pastos o si su inclusión en el censo ocurrió por un cambio territorial de “Los Pastos”. Si la segunda hipótesis es correcta, tampoco es posible establecer si anteriormente era parte de Barbacoas. No obstante, tenemos el siguiente indicio: el nombre de El Castigo se debe a la ejecución de 84 rebeldes sindaguas en 1635, una tribu relacionada con Barbacoas. En 1733, el cabildo de la ciudad de Popayán negoció con el palenque el primer acuerdo del mundo colonial. Si se hallaran más documentos, como una carta de un cura, se podría llegar a hipótesis totalmente nuevas.
Por estas razones es necesario diseñar la base de datos de una manera que facilite correcciones posteriores, sin tener que ajustar un gran número de archivos u objetos espaciales (polígonos). A esto se suma la incertidumbre sobre el desarrollo institucional. Cito una descripción de Peter Gerhard, generalmente considerado como autoridad para la geografía histórica de México, sobre la jurisdicción de Ciénega de los Olivos, en Nueva Vizcaya al norte de México:
While there is evidence on an alcalde mayor at Ciénega de los Olivos in 1659, other documents imply that the valley was attached to the jurisdiction of Sta. Bárbara as late as 1731. By the early 1760s the alcaldía mayor of S[an] José y Ciénega de los Olivos seems to have included not only the valley of that name but also Nonoava and the mountain missions (Gerhard, 1982, p. 182; cursivas nuestras).
Dicho en otras palabras, no sólo existen incertidumbres sobre los límites exactos entre jurisdicciones vecinas, sino también sobre las maneras de nombrarlas e incluso sobre su existencia. Para el interés del presente artículo, no nos dedicaremos a analizar los obstáculos a la hora de definir territorialidades indianas ni a las críticas teóricas que tiene que superar o integrar un SIG histórico como el que compone HGIS de las Indias. No todas estas incertidumbres conceptuales pueden ser representadas en una base de datos. Más bien se abordan en otras publicaciones, más monográficas y con la posibilidad de argumentación narrativa (Stangl, 2015; Stangl, 2017; Stangl, 2018). Para el diseño de nuestra base de datos no sólo tratamos de reducir el grado y número de incertidumbres, sino introducir principios rectores metodológicos para traducir información cartográfica o textual, como la de Peter Gerhard, en términos de IT (information technology). Lo que queremos elaborar aquí es el diseño de la base de datos para poder trabajar con incertidumbres sobre todo cronológicas, así como los modelos y procesos necesarios para crear composiciones espacio-temporales a partir de diferentes aspectos de la base de datos. En otras palabras: componer una sinfonía del Nuevo Mundo, como insinúa el título.
La base de datos en los tiempos de la incertidumbre
El aspecto más importante para lograr estas metas fue el de aislar fuentes de incertidumbre en diferentes partes de la base de datos. Para cada entidad de lugar o territorio, existe una simple entrada con un ID, los nombres y variantes que tenía a través del tiempo y un tipo genérico o general al que corresponde (“provincia”, “partido”, “obispado”, “audiencia”, “pueblo”, “villa”, “parcialidad”, entre otros). Cada entidad tiene un campo para indicar a cuál de las once “regiones genéricas” pertenece; los distritos pequeños y lugares además tienen un campo para indicar la “provincia genérica”; y para los lugares hay todavía más campos “genéricos” para el partido y el curato al que corresponden. Esta información sirve esencialmente para tener una segunda forma de diferenciar entre las entidades, más allá del simple ID, que es una secuencia de letras completamente abstracta (por ejemplo: JUQUPOPS para la provincia de los Pastos). Con los genéricos, tenemos por lo menos un elemento geográfico independiente de aspectos cronológicos, el cual no cambia. Así, para diferenciar entre “JUGDDUSB” (=“Santa Bárbara, Jurisdicción, GDJ [=Guadalajara], Durango)” y “PTGDCLSB” (=“Santa Bárbara, Partido, GDJ [=Guadalajara], California”); o entre “6000992” (=“Palpas, PER, Tarma, Cajatambo, Gorgor” y “6000985” (=“Palpas, PER, Tarma, Cajatambo, Churín”).
El otro elemento acrónico y abstracto es la geometría de polígonos bajo el paradigma LCG (least common geometry). Este concepto es muy robusto para formar la base SIG de un sistema complejo espacio-temporal: se diseñó para crear el SIG histórico de Bélgica en la década de los noventa (De Moor y Wiedemann, 2001), al poco tiempo ingresó en manuales y libros generales de best practice (Ott y Swiaczny, 2001; Gregory y Ell, 2007), y también se empleó con éxito en HGIS Germany (Dietze, Wachtendorf y Zipf, 2007). Aunque el paradigma LCG todavía funciona muy bien (sobre todo en cuanto a la implementación y la interacción de la infraestructura con el mundo exterior y la visualización como la colaboración), dentro de nuestro proyecto tenemos un entorno y posibilidades técnicas muy diferentes. A esto lo llamamos “Web 2.0”.
HGIS de las Indias tiene que enfrentar dos variables que la mayoría de SIG históricos existentes no se ven en la obligación de considerar: el aspecto “colonial” y la unificación de patrones para período comparativamente temprano. La mayoría de SIG-históricos nacionales, particularmente los que ensayan una reconstrucción territorial, están centrados en los siglos XIX y XX, y por lo tanto pueden hacerse uso de datos y mapas con una fiabilidad casi incuestionable, mientras que para el siglo XVIII la documentación conservada es parcial y carece de la misma homogeneidad. Además, la conocida complejidad de las “jurisdicciones solapadas”, esto es, la administración dividida en cuatro ramos conceptualmente independientes y las idiosincrasias del régimen colonial hispanoamericano (Pietschmann, 2003), imposibilitan un modelaje en clave jerárquica entre cada uno de los doce niveles territoriales (descritos en Stangl, 2017), los cuales deben modelarse por separado.
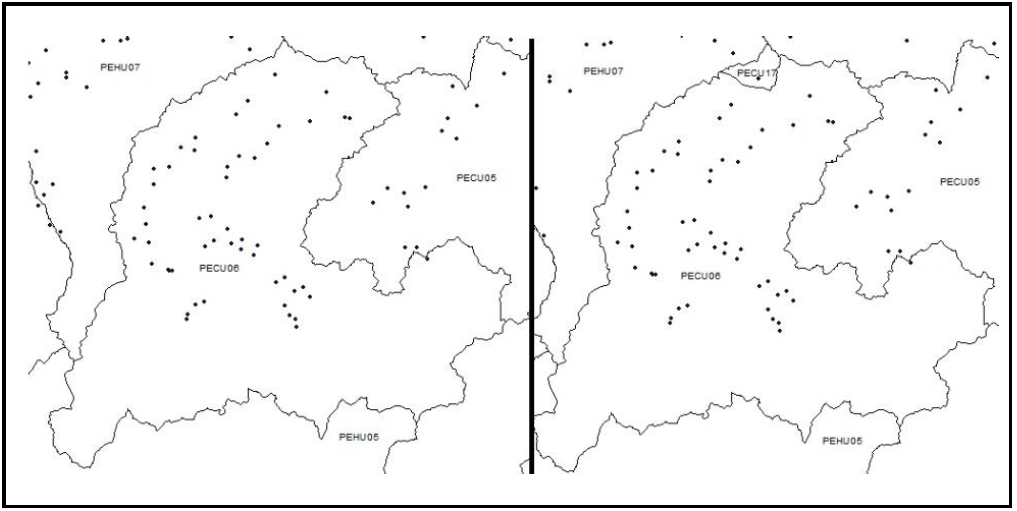
Para nuestro sistema, los polígonos LCG se definen por compartir la misma información en todos los aspectos de la base de datos durante el período estudiado. Cada vez que encontramos que un pedazo difiere en algún nivel reconstruido, aunque sea por un sólo año, hay que crear un polígono propio. Cuando se reconstruyeron los niveles territoriales a lo largo de un período de 108 años, resultaron 1 500 polígonos-LCG (contados hasta el momento). Cada vez que se crea un nuevo polígono, copiamos la información del “polígono madre” y cambiamos sólo los detalles de información en los que difiere. Es obvio que estos polígonos son abstractos y no representan ninguna entidad histórica. En el ejemplo del gráfico 1, podemos fijarnos en el pueblo de Lucuchanga, que en lo civil siempre había sido parte de Aymaraes, pero eclesiásticamente perteneció al curato de Huancarama en la vecina provincia de Andahuaylas. Por esta misma razón, Lucuchanga estuvo integrado a la diócesis de Huamanga en vez de la de Cuzco, por lo que debió formarse un nuevo polígono LCG (PECU17) para poder representar la mencionada diferencia en el modelo. No importa que se trate de una variación en un solo aspecto. (Figura 1)
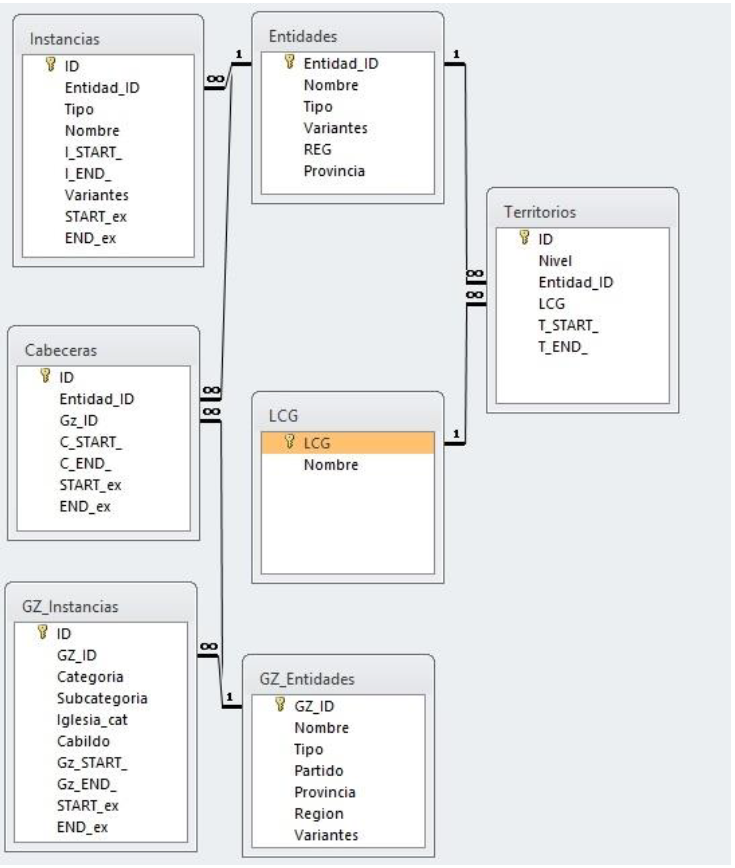
Como se había señalado, el elemento de la cronología hace parte del diseño en diferentes partes. Primero, hay tablas con sus instancias cualitativas temporales tanto para los lugares del Gazetteer3 como para las Entidades territoriales. Así, “JUNEYUCA, Campeche, Jurisdiccion, NES” existe como “jurisdicción de Campeche” entre 1701 y 1786 y como “subdelegación de Campeche” entre 1787 y 1808; y el lugar “1000226, Campeche, NES” existe como “Villa de Campeche” entre 1701 y 1776 y como “ciudad de Campeche” a partir de 1777. Con respecto a los lugares hay una variedad de aspectos que influyen en la definición de sus instancias. En efecto, una nueva instancia no sólo se introduce cuando una villa se convierte en ciudad, sino también cuando un lugar se erige en curato o si por un traslado a otro sitio (como la ciudad de Guatemala tras el terremoto de 1773), cambian las coordenadas. La cronología se modela de forma idéntica en cada tabla del sistema, con dos campos (START_ y END_) y la incertidumbre se expresa en campos separados, con un número reducido de marcadores como “not_before”, “not_after”, “exact” o “ca”.4
La Tabla de Cabeceras nos informa de que, por ejemplo, el lugar 1000226 era cabecera de su jurisdicción (JUNEYUCA) en todo el período de 1701 a 1808. Además, hay una “tabla relacional” (Territorios) que define la relación entre los polígonos y las entidades territoriales en los doce niveles. Continuando el ejemplo de Campeche, los polígonos “NEYU01” y “NEYU02” pertenecen a JUNEYUCA sólo entre 1701-1786, el polígono NEYU13 es parte de JUNEYUCA entre 1701 y 1808. En la Figura 2 muestra las diferentes tablas y sus relaciones en la base de datos, mantenida en MS-Access.
La mayor desventaja de LCG es que los objetos son muy abstractos, ya que los polígonos no representan objetos históricos y los identificadores también son genéricos. Un simple cambio de límite puede desencadenar una pequeña avalancha de nuevas entradas en la base de datos, como veremos en el siguiente apartado. Berman (2013) ha calificado el trabajo necesario en estas operaciones como “esmerado” y “laborioso”. Berman también ha señalado que “el cuidado necesario para mantener consistente las relaciones de los partículos LCG con los objetos geográficos-históricos es enorme”. Además, llama la atención la complejidad del proceso para situar cientos o miles de objetos a lo largo de distintas décadas. La mayor ventaja y fortaleza del diseño es que es posible aislar los diferentes tipos de incertidumbre. Dándole a cada uno su propio lugar (Figura 3):
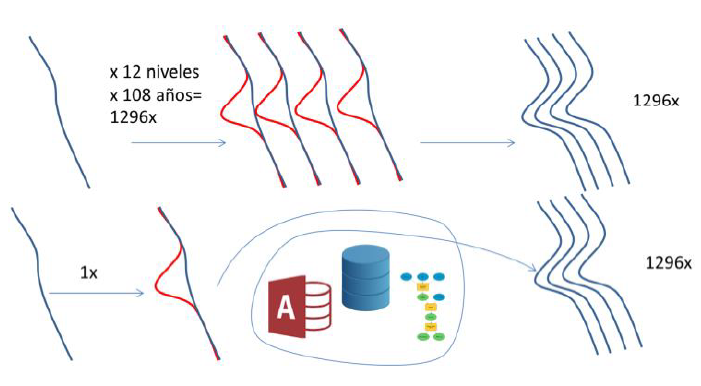
Las dudas sobre límites se ciñen a los polígonos LCG,5
Las dudas sobre la pertenencia de un área a una entidad en determinado período son ubicadas en la “tabla relacional” de Territorios.
Las dudas sobre el desarrollo institucional pasan a formar parte de la tabla de Instancias.
En la Figura 3, esboza la ventaja de esta estructura con el ejemplo de un simple ajuste de límite. Imaginemos que encontramos que una hacienda hasta ahora no considerada, situada al oeste del límite original, en realidad perteneció a las mismas entidades administrativas de los lugares situados al este. Sin el concepto de LCG y una base de datos relacional intermedia (para gestionar el sistema), deberíamos hacer la misma corrección 1 296 veces. Bajo el paradigma LCG, se hace el ajuste una vez y el resto lo deben manejar procesos y rutinas.
“Una tabla para gobernarlas a todas”
La información, así organizada, genera mayores beneficios cuando se combina. Para crear un SIG en línea, es imprescindible presentar las diferentes facetas conjuntamente. Un problema esencial es la coherencia de las diversas cronologías de cada parte de la base de datos. Inventamos una situación simple para ilustrar dicha dificultad (Tabla 1).
Tabla 1 Tablas “Territorios”; “Instancias”, “Cabeceras”, “Gz_Instancias”
| TERRITORIOS | LCG | Entidad_ID | T_START_ | T_END_ |
| XY1 | Una | 1701 | 1745 | |
| XY1 | Otra | 1746 | 1808 | |
| INSTANCIAS | Entidad_ID | Título | I_START_ | I_END_ |
| Una | Corregimiento | 1701 | 1808 | |
| Otra | Corregimiento | 1701 | 1750 | |
| Otra | Gobernación | 1751 | 1808 | |
| CABECERAS | Cabecera_ID | Entidad_ID | C_START_ | C_END_ |
| C200 | Una | 1701 | 1808 | |
| C300 | Otra | 1701 | 1730 | |
| C100 | Otra | 1731 | 1808 | |
| GZ_INSTANCIAS | Cabecera_ID | Tipo | Gz_START_ | Gz_END_ |
| C300 | Villa | 1701 | 1720 | |
| C300 | Ciudad | 1721 | 1808 | |
| C200 | Ciudad | 1701 | 1808 | |
| C100 | Villa | 1701 | 1720 | |
| C100 | Ciudad | 1721 | 1808 |
En las tablas, algunas columnas contienen identificadores únicos para referirse a: entidades territoriales (Entidad_ID); los polígonos a los que corresponden (LCG); y las capitales de las entidades (Cabecera_ID). Los campos “*_START_” y “*_END_” indican las fechas de validez de cada entrada. En el ejemplo de la Tabla 1, se tienen diferentes combinaciones de información que tienen sentido para 1701-1745, 1746-1750 y 1751-1808. Un inconveniente grave para este esfuerzo es que ni siquiera ArcGIS procesa bases de datos relacionales con aspectos cronológicos divergentes en la parte geométrica y una tabla relacionada (porque la relación no puede modelarse usando una consulta compleja sino sólo en la identificación a partir de un campo llave).
Para solucionar esto, podríamos pensar en la siguiente estrategia: crear una interfaz poderosa con la posibilidad de que los usuarios aportaran queries. Basado en las búsquedas de los usuarios, el sistema podría producir los output necesarios para reprogramar la interfaz. Aunque es cierto que esta estrategia es muy flexible, para nuestro caso debemos descartarla por varias razones. Primero, puede afectar el rendimiento del sistema en línea. De hecho, una base de datos de muchas tablas consumiría demasiados recursos y retrasaría la aparición de los resultados. Segundo, en una interfaz tan compleja las búsquedas sensibles sólo podrían producirse si el usuario sabe cómo funciona la base de datos que está detrás del sistema. Tercero, no existe actualmente ninguna aplicación que pudiera servir como punto de partida para un SIG en línea de esta índole. Para ello, sería necesario todo un equipo capaz de desarrollar un software pertinente. Finalmente, lo más problemático es que todo dependería de la interfaz, pues ningún producto “tiene sentido por sí mismo”. En otras palabras, y para usar un ejemplo, no existiría un objeto que pueda determinar la “extensión del corregimiento de Toluca en 1800”. Este solo podría reconstruirse formulándole a la interfaz la siguiente pregunta: “¿cuál era la extensión del corregimiento de Toluca en 1800?
Para conseguir objetos concretos, es necesario procesar y juntar todos los componentes de la base de datos. Dentro del presente artículo y dentro del producto que construimos, resulta novedoso el workflow que media entre las diferentes partes de la base de datos relacional y que, progresivamente, lleva al output final. Como se verá, la creación de una cronología lógica y consistente sobre un número de tablas relacionadas (donde cada una tiene su propia cronología), es un desafío considerable que merece ser documentado para poder reproducirse con mayor facilidad.
Primero, se crea una tabla maestra (Dumptable) que combina las diferentes tablas individuales por un inner join, y por lo tanto son combinados todos los diferentes campos cronológicos. En el ejemplo hipotético de la Tabla 2, tendríamos:
| LCG | Entidad_ID | T_START_ | T_END_ | Título | I_START | I_END | C_ID | C_START | C_END | Tipo | Gz_START | GZ_END |
| XY1 | Una | 1701 | 1745 | C | 1701 | 1808 | C200 | 1701 | 1808 | Ciudad | 1701 | 1808 |
| XY1 | Otra | 1746 | 1808 | C | 1701 | 1750 | C300 | 1701 | 1730 | Villa | 1701 | 1720 |
| XY1 | Otra | 1746 | 1808 | C | 1701 | 1750 | C300 | 1701 | 1730 | Ciudad | 1721 | 1808 |
| XY1 | Otra | 1746 | 1808 | G | 1751 | 1808 | C300 | 1701 | 1730 | Villa | 1701 | 1720 |
| XY1 | Otra | 1746 | 1808 | G | 1751 | 1808 | C300 | 1701 | 1730 | Ciudad | 1721 | 1808 |
| XY1 | Otra | 1746 | 1808 | C | 1701 | 1750 | C100 | 1731 | 1808 | Villa | 1701 | 1720 |
| XY1 | Otra | 1746 | 1808 | C | 1701 | 1750 | C100 | 1731 | 1808 | Ciudad | 1721 | 1808 |
| XY1 | Otra | 1746 | 1808 | G | 1751 | 1808 | C100 | 1731 | 1808 | Villa | 1701 | 1720 |
| XY1 | Otra | 1746 | 1808 | G | 1751 | 1808 | C100 | 1731 | 1808 | Ciudad | 1721 | 1808 |
Obviamente, no todas estas entradas tienen sentido, por lo que tenemos que limpiar la tabla eliminando todas las entradas ilógicas. No interesan aquellas entradas en las que los demás pares de cronología no tienen intersección con el período T_START_ a T_END.
En MS-Access SQL, eliminamos estas líneas así:
DELETE Dumptable.*, T_END_, I_END_, T_END_, C_END_
FROM Dumptable
WHERE (((T_END_)<(I_START_))) OR (((I_END_)<(T_START_))) OR (((T_END_)<(C_START_))) OR (((C_END_)<(T_START_)));
El resultado de esta operación es la Tabla 3:
Tabla 3 Dumptable ajustado
| LCG | Entidad_ID | T_START_ | T_END_ | Título | I_START | I_END | C_ID | C_START | C_END | Tipo | Gz_START | GZ_END |
| XY1 | Una | 1701 | 1745 | C | 1701 | 1808 | C200 | 1701 | 1808 | Ciudad | 1701 | 1808 |
| XY1 | Otra | 1746 | 1808 | C | 1701 | 1750 | C100 | 1731 | 1730 | Ciuda | 1721 | 1808 |
| XY1 | Otra | 1746 | 1808 | G | 1751 | 1808 | C100 | 1731 | 1808 | Ciudad | 1721 | 1808 |
Se nota, como es lógico, que desaparecen todas las entradas con la cabecera “C300” de la entidad “Otra” que había en la Tabla 1 porque dejan de ser cabecera antes de que el polígono formara parte de la provincia; desaparecen las entradas con “C100” en calidad de villa, porque ya era ciudad en 1746, cuando empieza a ser cabecera.
En este punto, haría falta definir el período en que la información combinada es válida. Es decir, calcular una nueva cronología en la que hay una sola entrada correcta para cada momento. Para esto, introducimos dos nuevos campos Dump_START_ y Dump_END_ que en un principio tienen el mismo valor como T_START_ y T_END, pero que se cambian con esta búsqueda SQL:
UPDATE Dumptable SET (Dump_START_) = (I_START_), (Dump_END_) = (I_END_)
WHERE ((((T_START_))<(I_START_))) OR (((T_END_)>(I_END_)));
Lo mismo se hace con C_START_, Gz_START_, C_END_ y Gz_END_ (aunque en este ejemplo, estas queries no cambian nada).(Tabla 4)
SIG: el moderno Prometeo
A la tabla ajustada (que es la esencia del sistema), habría que darle cuerpo e insuflarle un límite espacial. Para esto, importamos el Dumptable en ArcGIS y hacemos un query table con el feature class LCG sobre Dumptable.LCG= LCG.LCG. El resultado de esta operación (Figura 4) todavía tendría el inconveniente de que cada polígono LCG (recordamos: en abstracto) seguiría existiendo como objeto. Para combinar aquellos LCG que comparten la misma información, faltaría un dissolve (eliminación de límites internos).
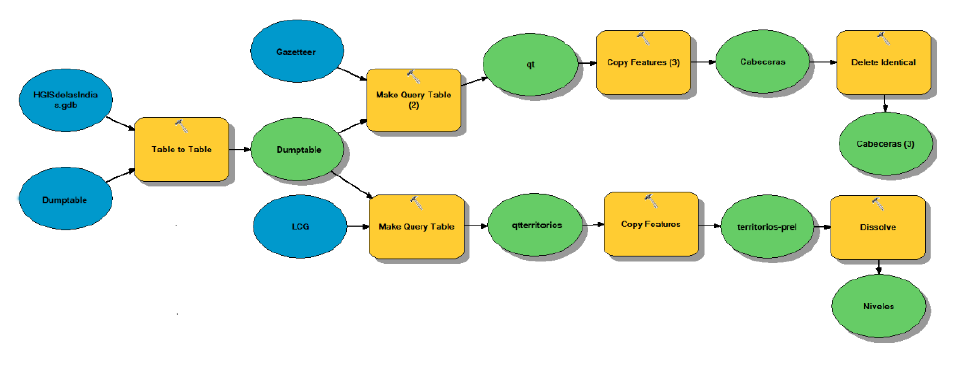
Figura 4 Modelo “Dissolve” en ArcGIS model builder para convertir territorios y cabeceras en una geodatabase.
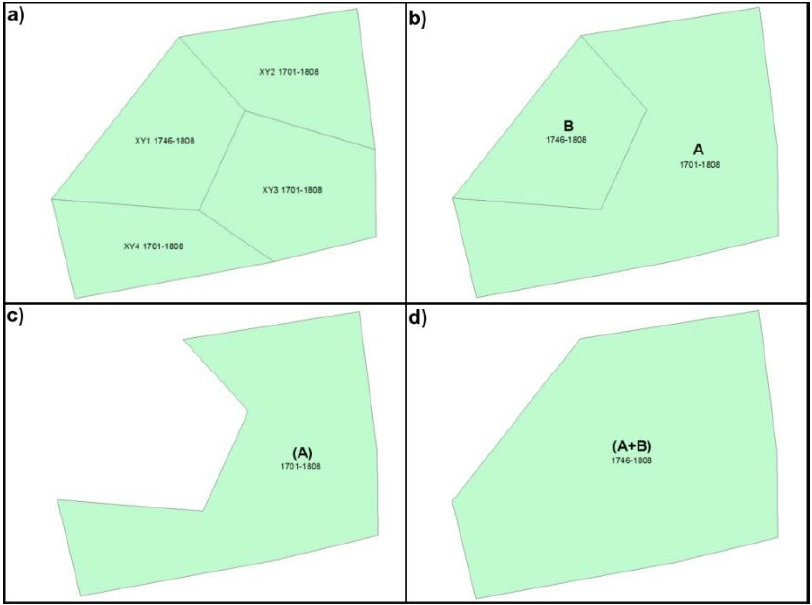
Sin embargo, este simple dissolve sólo es una solución parcial (feature class: Territorios-prel). La siguiente serie de gráficos ayuda a comprender la problemática. El gráfico 5a muestra el resultado del query table de cuatro polígonos diferentes, y el gráfico 5b el resultado de Territorios, hecho sobre Dump_START_, Dump_END_, Entidad_ID y Nivel idénticos. El polígono A pertenece a la entidad “Otra” desde 1701 a 1808; el polígono B desde 1746 a 1808. Pero lo que realmente queremos como resultado es un polígono que represente a la provincia entera en cada momento. En para 1746 a 1808, con la extensión “A+B” (Figura 5, Gráficos 5c y 5d). Así, para 1746 a 1808 todavía tenemos un límite interno que hay que eliminar.
La solución al problema descrito es una búsqueda SQL con parámetro iterativo para cada año, agregando un campo de cronología nuevo (que llamamos year), luego repitiendo el dissolve en cada nivel por separado sobre valores idénticos en year y Entidad_ID (Figura 6).6
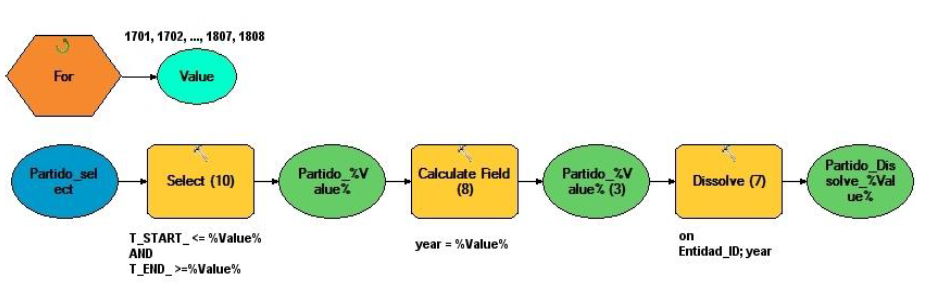
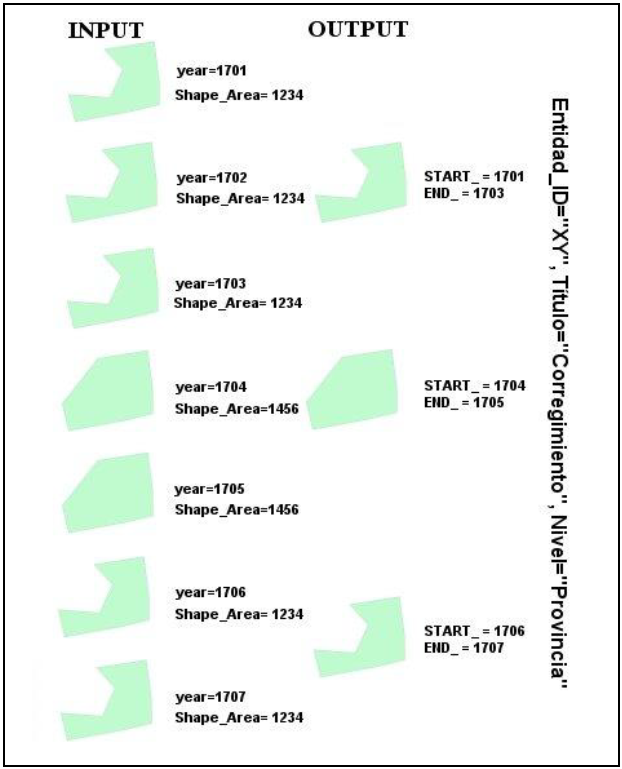
El paso final sería realizar un dissolve sobre Entidad_ID, Título, Nivel y Shape_Area en años consecutivos. No es posible hacer el dissolve sólo sobre una entidad y un área porque entonces se perdería un cambio de título (de corregimiento a alcaldía mayor...). Así mismo, es posible que después de un cambio político vigente por algunos años, el área de una entidad vuelva a su estado anterior. Sin considerar la limitación “en años consecutivos”, entonces, se produciría un resultado erróneo. Lógicamente, la nueva feature class tendría que disponer nuevamente de campos START_ y END_, tomando los valores de los años extremos de los polígonos disueltos (=que no cambian). No es posible modelar este proceso directamente con model builder porque requiere de varios iteradores y para ello debe programarse directamente en Python.7
El resultado es parecido, pero no igual al deseado. Ahora tenemos 45 polígonos idénticos para la entidad “Otra” (de extensión “A”) para 1701, 1702,... hasta 1745; y 63 otros polígonos idénticos (de extensión “A+B”) para 1746, 1747,... hasta 1808. Al final, los 108 feature classes de cada nivel se reúnen en un master feature class (Todosniveles). Así se haría en todos los niveles de reconstrucción, para todas las entidades territoriales, lo cual daría como resultados unos 200 000 polígonos aproximadamente. Lo anterior resultaría excesivo, ya que se multiplican polígonos iguales con excepción del campo year, pero con la ventaja de poder hacer extractos fáciles para cada año.8 (Figura 7)
El mayor problema del modelo arriba descrito (con y sin el último proceso), sería el recálculo necesario siempre que se realicen ajustes en alguna parte de la base de datos, ya sea en los límites, en la asignación de atributos cualitativos o cronológicos en una parte del RDBM o del gazetteer. Para este recálculo existen rutinas escritas en Python que automatizan este proceso cada tres meses y que producen una nueva versión de HGIS de las Indias.
Con este núcleo tenemos la base para posibilitar la “espacialización” de los datos tabulares externos, agregados por parte de los usuarios, aunque no sean integrados en la aplicación web del SIG. Hay muy pocas convenciones a las que tiene que sujetarse una tabla para poder agregarse a HGIS de las Indias, lo cual facilita su creación:
Tiene que ser una tabla Excel o un .csv;
si se refiere a lugares del gazetteer, tiene que contener los campos START_, END_ para la validez y como identificador el GZ_ID correspondiente para el dato;
si se refiere a lugares del gazetteer, tiene que contener los campos START_, END_ para la validez y como identificador el GZ_ID correspondiente para el dato.
Para hacerlo más claro, en este modelo el parámetro year es necesario porque tenemos que definir el polígono que usamos (“el polígono de la entidad “XY”, en el nivel de “Provincia” tal como existió en “1750”), mientras que START_ y END_ regulan la validez del dato (“Entre 1750 y 1760 la provincia XY producía 1 000 marcos de plata”).
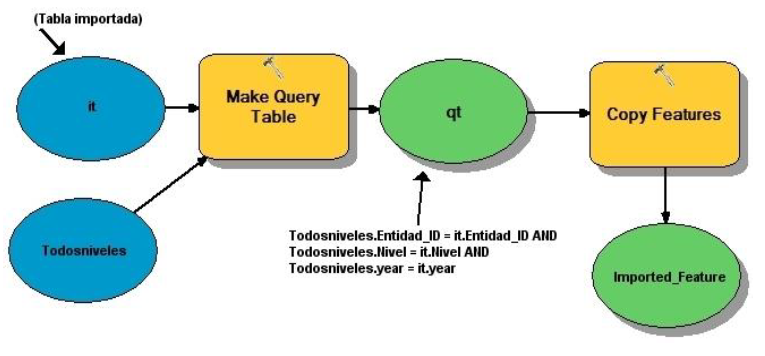
De modo análogo al ajuste de las diferentes cronologías (y que se ha descrito arriba), creamos un modelo que agrega la información de la tabla a la feature class Todosniveles. El siguiente gráfico muestra el modelo y la búsqueda SQL asociada (Figura 8).
Conclusiones
El diseño de la base de datos como infraestructura espacio-temporal no se ciñe al ámbito histórico concreto estudiado, sino que puede adaptarse fácilmente a otras áreas y temáticas complejas con un alto grado de cambio a través del tiempo o incertidumbres en los datos. Se espera que la detallada iteración de los problemas planteados y los diferentes workflows puedan servir de guía para otros proyectos que implican retos similares o problemas metodológicos. Estos pueden estar en la naturaleza de las fuentes, en la función de infraestructura o en la necesidad de tener que acoplar marcos cronológicos independientes, pero referentes a entidades espacio-temporales. Como se ha visto arriba, la base SQL para agregar datos temporales no es excesivamente complicada. A partir de los procesos delineados aquí un ingeniero de desarrollo de software debería ser fácilmente capaz de programar un plug-in en ArcGIS o QGIS, para que cronologías independientes en el futuro se puedan manejar de forma más natural. Con esta capacidad, podrían relacionarse las tablas a la geodatabase preexistente, sin tener que realizar otros shapefiles o feature classes.
En el campo de la historiografía colonial, las principales pruebas para el modelo analizado en este artículo son: primero, su puesta en práctica en una aplicación interactiva concreta; segundo, el interés que podría generar en la comunidad de historiadores de la Hispanoamérica colonial y la capacidad efectiva de HGIS de las Indias de integrar nuevos datos; y, tercero, su compatibilidad con otras herramientas e infraestructuras digitales.
La realización del modelo se ha hecho en forma de SIG en línea usando una aplicación open-source llamada CMV-App Viewer.9 Esta última ha sido adaptada a las necesidades del proyecto, incluyendo un regulador de cronología, alta modularidad para combinar diferentes capas, y una visualización comparativamente rápida.
La capacidad de integrar datos externos de colegas se ha realizado a través del elemento tal vez más innovador de HGIS de las Indias: una rutina diaria del modelo para agregar tablas externas que permite al usuario registrado subir su tabla bien formada a la página-web y convertirla en un shapefile descargable.10 Sin embargo, puede resultar difícil el motivar a la comunidad de colegas para usar los identificadores únicos de las entidades de HGIS de las Indias, incluso desde el momento de compilar sus datos. Esperamos que sea cuestión de tiempo, pero seguramente hace falta promoción para dejar claras las ventajas de enlazar diferentes datasets a través de una infraestructura común, y que valdría la pena realizar este esfuerzo “extra”. Aun así, sabemos que se han usado geometrías de HGIS de las Indias para la cartografía de varios artículos y libros -ya en los primeros dos años de su existencia. (Figura 9)
Además, existen diferentes cooperaciones y proyectos que han planeado sumarse a la iniciativa y ser el germen para una ampliación del sistema a los siglos XVII y XVI. Nos encontramos cooperando intensamente con el equipo del proyecto “Digging into Early Colonial Mexico” de la Universidad de Lancaster, guiado por Patricia Murrieta Flores. Su grupo de trabajo extrae información estructurada de las relaciones geográficas novohispanas del siglo XVI -entre otros objetivos- y reconstruye la geografía escondida en esos textos.11 Adicionalmente, en 2018 se ha llevado a cabo un avance de proyecto llamado “LatAm Gazetteer”, junto con Ben Brumfield (Austin), Gimena del Río (Buenos Aires) y otros, para explorar la creación de un gazetteer histórico general de América Latina basado en el ya mencionado diccionario de Alcedo (1786-1789) para la plataforma Pelagios.12
A partir de “LatAm Gazetteer” se ha logrado la inclusión de nuestro gazetteer en dos infraestructuras digitales más generales. Una de ellas es la herramienta Recogito de Pelagios para la edición colaborativa de textos, donde ya se pueden identificar topónimos a través de la información proveída por HGIS de las Indias.13 De forma similar, hemos sido incluidos en el “World Historical Gazetteer” diseñado por Karl Grossner para el World History Center de la Universidad de Pittsburgh.14 Se trata de una nueva plataforma con la meta de integrar diferentes gazetteers históricos y nuestra base de datos sirve de ejemplo implementación de datos espacio-temporales de terceros. Dentro del “World Historical Gazetteer” no sólo se incluyen los lugares, sino también los territorios. Y todo permitiendo la definición de validez temporal en los objetos.
Es en este reto donde tal vez mejor puede juzgarse la idoneidad de la estructura fundamental delineada en este artículo. Para ello se siguen matices prácticos y universales que facilitan: 1) la interoperabilidad con; 2) la integración en; 3) el ajuste a; y 4). la transformación en otros ámbitos. Para concluir, presentamos aquí una partitura gráfica de la “sinfonía del Nuevo Mundo”, la cual sintetiza el continuum espacio-temporal que es HGIS de las Indias.

