










Servicios Personalizados
Revista

Articulo
 Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por emailIndicadores
 Citado por SciELO
Citado por SciELO Links relacionados
 Similares en
SciELO
Similares en
SciELO Compartir

 Permalink
PermalinkRevista fitotecnia mexicana
versión impresa ISSN 0187-7380
Rev. fitotec. mex vol.36 no.3 Chapingo jul./sep. 2013
Ensayo científico
IBFieldbook, an integrated breeding field book for plant breeding
IBFieldbook, un sistema integrado de libros de campo para mejoramiento de plantas
Oziel Lugo-Espinosa1, Tito M. Sánchez-Gutiérrez1, J. Gamaliel Camarena-Sagredo1, Mateo Vargas1, Gregorio Alvarado1, Diego Jarquin1, Juan Burgueño1, Jose Crossa1 and Héctor Sánchez-Villeda1, 2*
1Centro Internacional de Mejoramiento de Maíz y Trigo. Km 45 carr. México-Veracruz. 56130, El Batán, Texcoco. Edo. de México.
2G2Apps IT Engineering. Prolongación Corregidora Norte 909 - C. Villas del Parque. 76140, Querétaro, Qro. *Autor para correspondencia (hector.sanchez@g2Apps.net)
Recibido: 23 de Noviembre del 2012.
Aceptado: 2 de Julio del 2013.
Resumen
El desarrollo de un sistema integrado de libros de campo para mejoramiento (IBFieldbook, por sus siglas en inglés) para diferentes cultivos incluye la generación, manejo y análisis de grandes volúmenes de datos. El manejo de integración de la información fenotípica, ambiente y pedigrí para análisis de datos requiere de un programa computacional ("software") apropiado y exitoso, que facilite a los mejoradores, técnicos e investigadores la administración de la información recolectada en el campo de manera fácil, eficiente e interactiva. Los usuarios del programa también necesitan métodos para intercambiar información con diferentes dispositivos usados para almacenar información en el campo. La información recolectada necesita además ser analizada adentro y afuera de la aplicación, y generar reportes para el mejoramiento del germoplasma.
Palabras clave: análisis de datos, información recolectada, grandes volúmenes de datos, métodos para intercambiar información, software exitoso, libremente disponible.
Abstract
The development of an integrated breeding field book (IBFieldbook) for different crops involves the generation, handling and analysis of large amounts of data. Managing the integration of environmental, pedigree, and phenotypic information for plant breeding data analyses requires appropriate and successful software that facilitates breeders, technicians, and researchers management of the vast collected field information in an easy, efficient and interactive way. Users may also need methods to exchange information with different devices used to record information in the field. Additionally, collected information needs to be analyzed inside or outside the application, and then generate reports for germplasm improvement.
Key words: data analysis, information collected, large amounts of data, methods to exchange information, successful software, freely available.
INTRODUCTION
Nowadays maize (Zea mays L.), wheat (Triticum aestivum L.), and rice (Oryza sativa L.) are the three crops that feed 95 % of the population worldwide (FAO, 2013). To help researchers to genetically improve these crops, it is necessary to provide them with the appropriate tools to manage, use and exploit their field information. The main objective of all breeders is to improve the germplasm to reduce the hunger in the world. To achieve this goal, it is important to have software tools that allow automatic information recollection in the field, either typed, bar code scanned or acquired through Bluetooth devices. Additionally, information must be shared and made it accessible for easy management and analysis. To achieve these goals, the integrated breeding field book (IBFieldbook) was developed to facilitate breeders creation of their field books with export and import capabilities to hand held devices and Excel© spreadsheets and standard analyses with the collected information.
It is well known that breeders at different agricultural experiment stations have requirements that vary considerably depending on the objectives of their projects. It is possible to collect accurate phenotypic data with the information technology available today, which would make possible genomic selection and prediction of genetic values of germplasm. Precise phenotypic information is obtained from data collected in target environments by means of adequate experimental designs (Banziger et al., 2000; Ortiz et al., 2007).
Currently, many breeders and technicians at different experimental stations in the world use spreadsheets to manage their data, but in developing countries there is lack of information systems and analysis tools, along with a poor phenotyping infrastructure (McLaren et al., 2005; Ribaut et al., 2010). If breeders want to store and manage their data in an easy and efficient manner, they must either develop an information system, which can be cumbersome, time consuming and expensive, or they need to purchase a system. Therefore an open information system for managing breeding related data is needed.
This paper describes and discusses the integrated breeding field book (IBFieldbook) as one component of the molecular breeding platform (Delannay et al., 2011) that was developed to aid breeders during the plant breeding process: (a) To generate nurseries for line advancement with and without randomization; (b) To generate trials for germplasm evaluation in different locations using different randomizations; (c) To allow data management with record keeping, reporting, and retrieving; (d) To ensure data quality and accessibility to the scientific community, and (e) To generate standard analysis for one and multiple locations.
MATERIALS, METHODS AND IMPLEMENTATION OF THE IBFieldbook
The integrated breeding fieldbook system described here is an example of an application of informatics to practical agronomic and plant breeding challenges. An overview of the IBFieldbook components and their functions is shown in Table 1.
Several open source software were used to develop the IBFieldbook system. The Java© programming language used provides users with a modular and intuitive user interface (UI). The UI focuses on creating an easy to use system that facilitates information handling and analysis of information to help in breeding activities and improve the germplasm for different crops. The UI is a high-performing, cross-platform Java© client application, which can be executed in Microsoft Windows©, Mac OS X© or any type of IX Operating System. The IBFIeldbook system uses MySQL© for the backend, with a dual database (central and local) containing the same structure to keep track of public and private information. The client-server architecture system permits many concurrent users to access the central database and also makes their private local information available. Java© database connectivity (JDBC) provides interoperability with the databases and shells connectivity with R package. R software uses scripts developed to generate the standard analysis (See section of managing phenotypic data, below).
The programming language used to code the integrated breeding field book was Java 1. 6. 0© using NetBeans 7.1.2© as a developer platform. To collect the data, either Microsoft Access© or MySQL versions 5.0© were used as the backend; however, other relational databases can be used with little tuning. The application interfaces with R Statistical Package© for field trial design and data analysis. IBFieldbook provides data management for the information collected in the field and generates either single or multi-location trials for data analysis. It also manages catalogs using UI components for easy information management located in the presentation layer.
This system provides a middleware, which is composed of the service layer and data access layer using the Spring© framework to send and receive objects from the service layer to the presentation layer, and it also uses Hibernate© to communicate between the data access layer and service layer through entities. Spring provides a lightweight container which allows injecting required objects into others objects; this results in a design where the Java Class are not hard coded. A design based on independent classes/components increases re-usability and software testability. The data access layer gets and receives information through records from the local and central databases using Microsoft Access® or MySQL© with Java© database connectivity (JDBC) as shown in Figure 1.
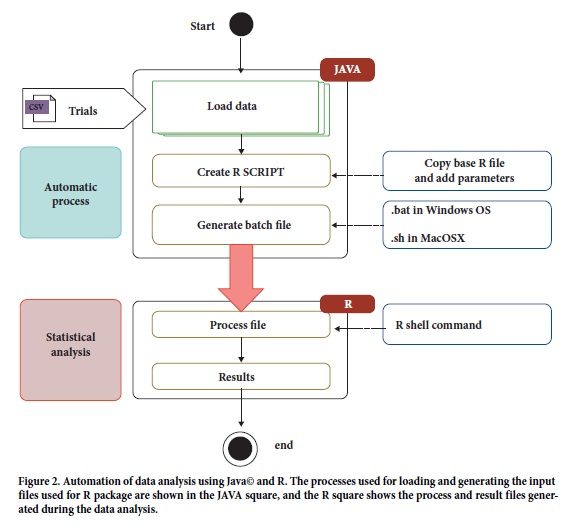
Automation using Java© and R software for data analysis
There are several steps used to generate single and multi-location analyses that start after the information is collected in the field and stored into the database. First the information has to be exported to a coma separated values (csv) format file used by R software. The csv-file is automatically uploaded, the standard R scripts and the needed parameters are copied, and a batch file generated for Windows© or Mac OS X© operating systems. This file is passed on to R and processed using a shell command in the R environment without user interaction. Finally the result files are returned after the analyses are done (Figure 2).
Managing phenotypic data by the IBFieldbook
The IBFieldbook stores a set of interrelated tables in a relational database (ICISDB) that supports pedigree, phenotypic, and inventory information for the germplasm. This provides easy editing, querying, importing and exporting functions from trials and nurseries, shown in the entity relationship diagram [Available at: http://www.revistafitotecniamexicana.org/documentos/36-3/ICISdbschema.pdf]. All of this makes the system a user-friendly field book generation tool, using Java© interface components to facilitate data access (Figure 3).
IBFieldbook accepts comma separated values format used in hand held devices, as well as a pre-established Microsoft Excel® format. Once the information is imported into the system, it can be edited in an intuitive user-friendly interface and also can be saved to the database to be exported to a specific R format for statistical analysis.
The steps to generate a trial or nursery for collecting information are as follows:
• Generate the germplasm list.
• Generate a template or use one that come as example with the traits to measure
• Generate a study; a set of trial and nurseries
• Generate a trial or a nursery using the wizard or quick creation interfaces
• Collect the phenotypic information in the system or export to hand held or Excel© for collection
The best possible way to collect phenotypic information and avoid errors is by means of automating the data collection as much as possible.
Statistical models for single and multienvironment plant breeding trials
For the description of the mean response of genotypes over environments and for studying and interpreting genotype ' environment interaction (GE) in multi environment plant breeding trials (MET), the baseline conventional two-way model used to explain the empirical mean response, ȳ , of the ith genotype (I = 1, 2, I) in the jth environment (j = 1, 2,..., J) with n replications in each of the I x J cells is expressed as (Eqn. 1)
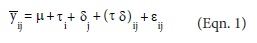
Where µ is the grand mean over all genotypes and environments, τi is the additive effect of the ith genotype, δ. is the additive effect of the jth environment, (τδ) is the non-additivity interaction GE of the ith genotype in the jth environment, and 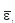 ij is the average error assumed to be NID (0, σ2 /n)(where σ2 is the within-environment error variance, assumed to be constant). The model for a single environment is represented by ȳ = µ + τi + i.. The single and multi-environment model can be used to analyze as many traits as it is required.
ij is the average error assumed to be NID (0, σ2 /n)(where σ2 is the within-environment error variance, assumed to be constant). The model for a single environment is represented by ȳ = µ + τi + i.. The single and multi-environment model can be used to analyze as many traits as it is required.
The simplest linear model for assessing GE was proposed by Yates and Cochran (1938), where the GE is expressed as the linear regression coefficient of the ith genotype value on the environmental mean. This approach was later used by Finlay and Wilkinson (1963) and modified by Eberhart and Russell (1966). Williams (1952) was the first author to link the fixed effects two-way model (Eqn. 1) with principal components analysis by considering the model ȳij = µ + τi + λαiγj + ij, where λ is the largest singular value of ZZ' and Z'Z (for Z = ȳij - ȳi) and αi and γj are the corresponding eigenvectors. An extension to Williiams work was done by considering the bilinear GEI term as (τδ)ij =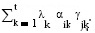
Thus, the general formulation of this linear-bilinear model is
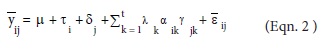
Where the constant λk is the singular value of the kith multiplicative component that is ordered λ1 ≥λ2 ≥ ...≥λt; the terms αik are elements of the kith left singular vector of the ik ith true interaction and represents the genotypic sensitivity to hypothetical environmental factors represented by the kith right singular vector with elements yjk. The αik and yjk satisfy the ortho-normalization constraints Σi αik αik, = Σj Yjk Yjk = 0 for k ≠ k' and Σi α2ik = Σj y2jk = 1. This model was called "additive main effects and multiplicative interaction (AMMI)" model by Zobel et al. (1988) and Gauch (1988).
A biplot is a simultaneous representation of the rows and columns of a two-way array of data in terms of directions and projections Gabriel (1978). The biplot is designed to operate with one matrix (two-mode), and the singular vector of the genotypes and environmental scores for the first two components are drawn from the origin to the end of the vector. Vectors of genotypes (or environments) that are related are parallel (or near parallel), whereas vectors with angles greater than 90 % represent negligible or negative relationship of genotypes (or environments). Furthermore, vectors of genotypes and environments pointing on the same direction denote positive GE between those genotypes and those environments, whereas vectors of genotypes and environments pointing in opposite directions denote negative GE.
DISCUSSION
There are several packages that can be used to generate field books for breeding germplasm, as well as to generate trials for evaluation, with exporting and importing functions, using several statistical packages to evaluate information recorded in the field or in the lab with different types of devices. However, these packages are very expensive, require a lot of training, and are not user friendly. Therefore we programmed a package that can handle several crops, is comprehensive and user friendly, at no cost for the final user (Table 2).
The IBFieldbook was designed to meet the challenges of collecting, managing, and analyzing phenotypic information for different crops, in different experimental stations around the world. This tool has been used in nine crops (beans, cassava, chickpeas, cowpea, groundnuts, maize, rice, sorghum, and wheat) handling more than 150 000 pedigrees; more than 11 000 different field trials in different locations worldwide for the Consultative Group on International Agricultural Research (CGIAR) centers. Related information can be downloaded at: https://www.inte-ratedbreeding.net/ib-tools/project-planning-and-queries/crop-databases-ib-workbench.
The IBFieldbook is a complete system for breeding management, and the software is freely available to the public. The system includes the trait management for all the variables that are measured in the field, export and import functions to work with the information into hand held devices or Microsoft Excel© software. The system also allows direct modification or addition of information using a programmed graphical user interface, and to run statistical analysis with the information collected interacting directly with R package. It has printing facilities and stores the information into a relational database management system.
CONCLUSION
The IBFieldBook is a freely available open source software tool that helps breeders, technicians, and molecular breeders to generate their field books, collect phenotypic information in the field, analyze their collected data for single-environment and multi-environment statistical analyses, store the data in a comprehensive database, and report their results, thus helping users improve their germplasm. It was successfully tested in Africa, Asia, and Latin America. Free downloadable copies of the application and examples of databases for the nine crops can be obtained by filling out the form at: http://www.g2apps.net/index.php?consulta=PRODUCTOS&principal=IB-FIELDBOOK.
ACKNOWLEDMENTS
To the members of the Generation Challenge Program including Jean Marcel-Ribaut, Graham McLaren, Arllet Portugal, and Clarissa Pimentel, for their full support to develop the IBFieldbook system. The International Maize and Wheat Improvement Center (CIMMYT) does not guarantee nor warrant the standard of the product. The use of the name implies no approval of the product to the exclusion of others that may also be suitable. This system was supported by the Generation Challenge Program (Grant ID OPP53402).
BIBLIOGRAPHY
AGROBASE (2012) Generation II® Plant and Crop Breeding Software. http://www.agronomix.com. [ Links ]
Banziger M, G O Edmeades, D Beck, M Bellon (2000) Breeding for drought and nitrogen stress tolerance in maize: from theory to practice. CIMMYT. [ Links ]
Central Software Solutions, Inc. (2012) PRISM® http://www.teamcssi.com. [ Links ]
Delannay X, G McLaren, J M Ribaut (2011) Fostering molecular breeding in developing countries. Mol. Breed. 29:857-873. [ Links ]
Eberhart S A, W A Russell (1966) Stability parameters for comparing varieties. Crop Sci. 6:36-40. [ Links ]
FAO Statistical Yearbook (2013) World food and agriculture. Food And Agriculture Organization Of The United Nations, Rome, Part 3, Feeding the world. http://www.fao.org/docrep/018/i3107e/i3107e00.htm. [ Links ]
Finlay K W, A A Wilkinson (1963) The analysis of adaptation in a plant breeding program. Austr. J. Agric. Res. 14:742-754. [ Links ]
Gabriel K R (1978) Least Squares Approximation of Matrices by Additive and Multiplicative Models. J. Royal Stat. Soc., Series B 40:186196. [ Links ]
Gauch H G (1988) Model selection and validation for yield trials with interaction. Biometrics 44:705-715. [ Links ]
McLaren C G, R M Bruskiewich, A M Portugal, B Cosico (2005) The international rice information system. A platform for meta-analysis of rice crop data. Plant Physiol. 139:637-642. [ Links ]
Ortiz R, R Trethowan, G O Ferrara, M Iwanaga, J H Dodds, J H Crouch, J Crossa, H J Braun (2007) High yield potential, shuttle breeding, genetic diversity, and a new international wheat improvement strategy. Euphytica 157:365-384. [ Links ]
Ribaut J M, de M C Vicente, X Delannay (2010) Molecular breeding in developing countries: challenges and perspectives. Curr. Opin. Plant Biol. 13:1-6. [ Links ]
Williams E J (1952) The interpretation of interactions in factorial experiments. Biometrika 39:65-81. [ Links ]
Yates F, W G Cochran (1938) The analysis of groups of experiments. J. Agric. Sci. 28:556-580. [ Links ]
Zobel R W, M J Wright, H G Gauch Jr (1988) Statistical analysis of a yield trial. Agron. J. 80:388-393. [ Links ]

