











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introducción
Los CAT (Computerized Adaptive Testing) son una forma de evaluación cuya característica principal es la de adaptar las preguntas siguientes de acuerdo con las respuestas que otorga el evaluado en las preguntas previas.
El algoritmo de selección de ítems dentro del proceso de los CAT inicia con la selección de la primera pregunta de dificultad media y, dependiendo de la respuesta que otorgue la persona evaluada, adaptará la dificultad de la siguiente. Maximizar la precisión del examen es el objetivo principal de los CAT. Una de la sus ventajas fundamentales es que ocupan menos preguntas y toman menos tiempo que los exámenes tradicionales en lápiz y papel, pero conservan o mejoran el nivel de precisión (López-Cuadrado et al., 2010).
Así también, entre sus componentes principales está el criterio de selección de ítems. En la actualidad, la información máxima de Fisher (Albano et al., 2019) es uno de los métodos más empleados, pero presenta diversas desventajas, entre las cuales se encuentran a) sesgo en la elección de ítems, b) error en la estimación de habilidad y c) duplicidad de ítems presentados (Sheng et al., 2018; Lin y Chang, 2019; Yigit et al., 2019). Algunos trabajos se han enfocado en tratar de resolver los problemas presentados utilizando otras herramientas en la etapa de selección como algoritmo voraz (Bengs et al., 2018) y Kullback-Leibler Information (Tokusada y Hirose, 2016); sin embargo, a pesar de que han tenido resultados favorables, estos sólo han sido en estudios de simulación y no en aplicación con grupos reales de evaluados.
En este artículo se presenta un método de evaluación adaptativa computarizada que utiliza la minería de reglas de asociación como estrategia de selección de ítems, por medio de la cual se busca aprovechar las ventajas potenciales de las reglas de asociación para encontrar relaciones entre las preguntas contestadas correcta o incorrectamente y las preguntas contestadas correctamente y presentar las preguntas más adecuadas (con mayor probabilidad de contestar correctamente) en los exámenes de acuerdo con las respuestas del evaluado, y donde se considere las mejores reglas (guardadas en la base de datos de alumnos que contestaron el mismo examen previamente) con mayor soporte y confianza. Es importante mencionar que estas dos características son en las que está basado el algoritmo para hacer una correcta elección de la regla para la selección de la pregunta.
En la figura 1 se muestra el proceso seguido por los CAT (Oppl et al., 2017), el cual comienza con la estimación inicial de conocimientos de la persona evaluada. Posteriormente, el primer ítem es seleccionado y presentado a la persona evaluada. Una vez que la respuesta se obtiene, una nueva estimación de conocimientos se lleva a cabo. La siguiente etapa consiste en verificar si el criterio de parada se cumple. Si esto no sucede, el siguiente ítem es seleccionado y el ciclo comienza de nuevo: se repite hasta que se cumple el criterio de parada. Cuando esto ocurre, se lleva a cabo una estimación final de conocimiento y termina el proceso.
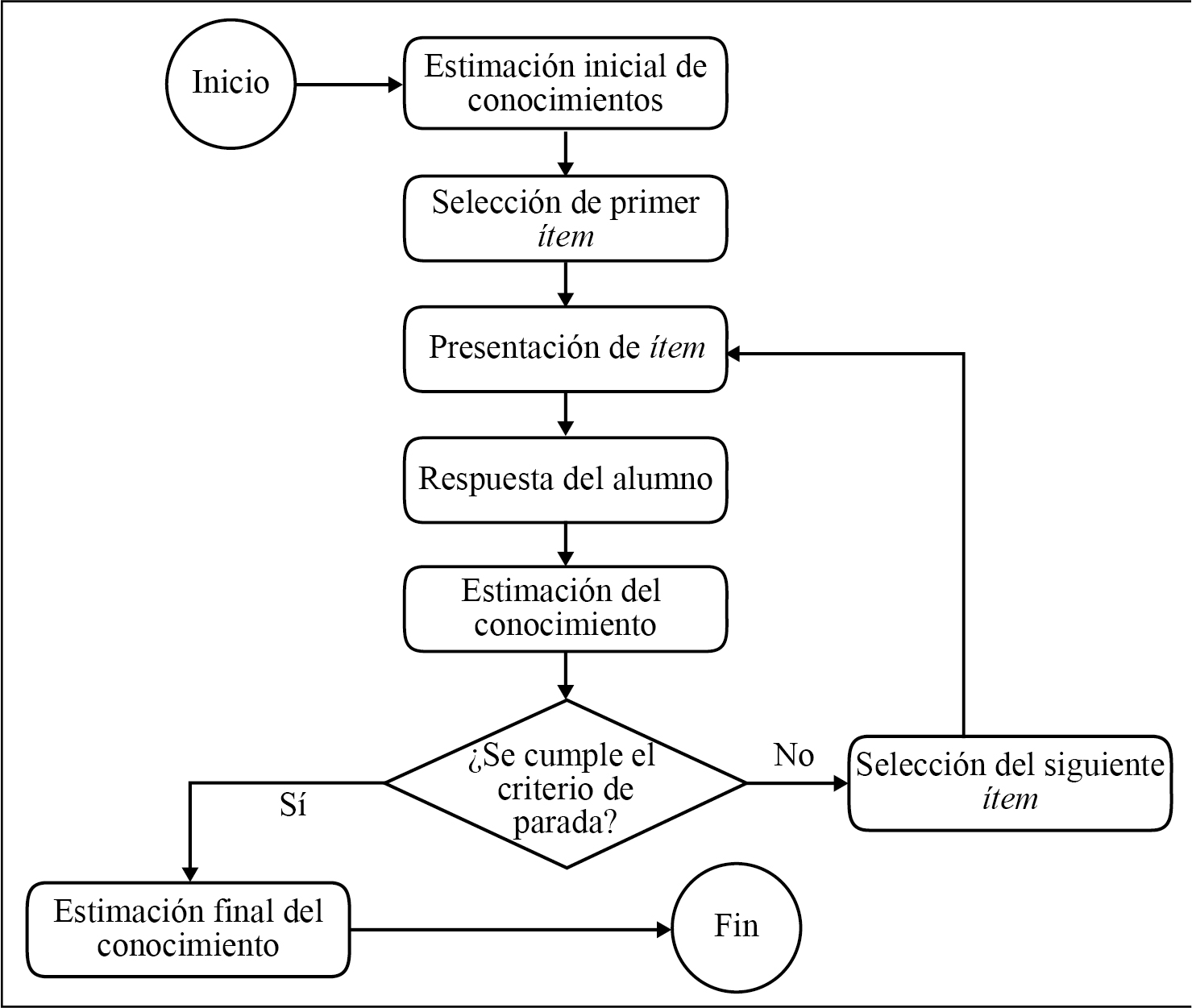
A lo largo del tiempo, diversos métodos, herramientas y estrategias han sido empleados en las distintas fases del CAT, por ejemplo el modelo logístico de tres parámetros (3PL) para la calibración de ítems, la estimación de máxima verosimilitud (MLE) para la estimación de habilidad del evaluado y las diferencias cuadráticas medias como criterio de evaluación.
1. Reglas de asociación
La minería de reglas de asociación tiene como finalidad encontrar relaciones entre los elementos u objetos de una base de datos, es decir, permite descubrir patrones comunes en los elementos. Su uso se puede encontrar en diversas áreas como de salud (Zhang et al., 2020) y aprendizaje en línea (Paladines Rodríguez et al., 2021); en cada uno de los casos ofrece resultados positivos.
Existen diversos algoritmos para la minería de reglas de asociación, entre los cuales destacan Apriori (Agrawal et al., 1993), FPGrowth (Han et al., 2016), PredictiveApriori (Scheffer, 2001) y Tertius (Flach & Lachiche, 2001). Además, para el análisis comparativo de los algoritmos de reglas de asociación, se utilizan diversos criterios:
a) Confianza: evalúa el grado de certeza de la asociación detectada.
b) Soporte: representa el porcentaje de transacciones de la base de datos que satisface la regla dada.
c) Tiempo: número de milisegundos que toma la construcción de un modelo.
d) Reglas: representa el número de reglas interesantes obtenidas.
e) Sustentación: indica la relación entre el soporte observado de un conjunto de elementos y el soporte teórico de ese conjunto dada la suposición de independencia.
2. Proceso CAT con reglas de asociación
La figura 2 ilustra el método de evaluación adaptativa computarizada propuesto que integra a la minería de reglas de asociación como estrategia de selección de ítems en el proceso de los CAT. A continuación se muestra su empleo:
a) Basándose en que cada pregunta o ítem tiene un nivel de complejidad (1 a 100), el sistema elige la pregunta inicial de acuerdo con el criterio de arranque seleccionado, el cual es la elección de una pregunta de nivel medio.
b) Para la elección de la siguiente pregunta:
• Si la respuesta de la pregunta inmediata anterior fue correcta (pX = 1), el sistema elige una de mayor complejidad (pY) tomando en cuenta las reglas de asociación almacenadas en la base de datos (de alumnos que presentaron la misma prueba previamente), con mayor soporte y confianza. Las reglas de asociación se generan de la siguiente forma:
• Si la respuesta de la pregunta inmediata anterior fue errónea (pX = 0), el sistema elige una de menor nivel de complejidad (pZ) tomando en cuenta las reglas de asociación almacenadas en la base de datos (de alumnos que presentaron la misma prueba previamente), con mayor soporte y confianza.
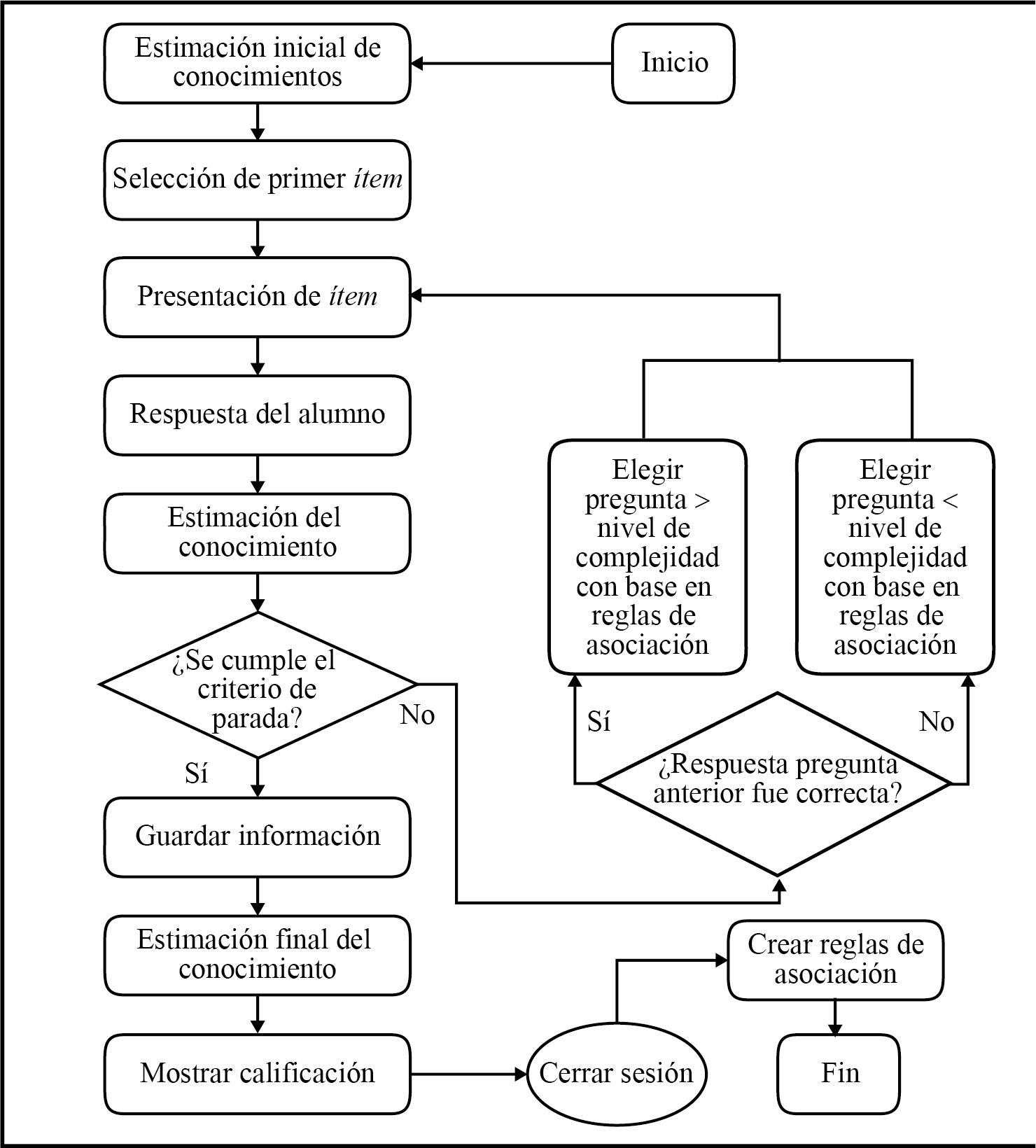
c) El proceso del paso 2 se repite con cada una de las preguntas siguientes.
d) Después de finalizar el número de preguntas establecidas por el profesor, el sistema termina el examen, guarda toda la información generada en su base de datos y proporciona la calificación al alumno.
e) El alumno cierra sesión o regresa a la página inicial para presentar otro examen.
Finalmente, el sistema origina reglas de asociación a través de la aplicación inmediata del algoritmo Apriori (Agrawal et al., 1993) a la información guardada con la finalidad de encontrar relaciones entre las preguntas contestadas y que sirvan como base para la próxima vez que un alumno presente el mismo examen.
3. Selección de ítems con reglas de asociación
La figura 3 muestra el proceso completo de la fase de selección de ítems aplicando reglas de asociación. A continuación se describe:
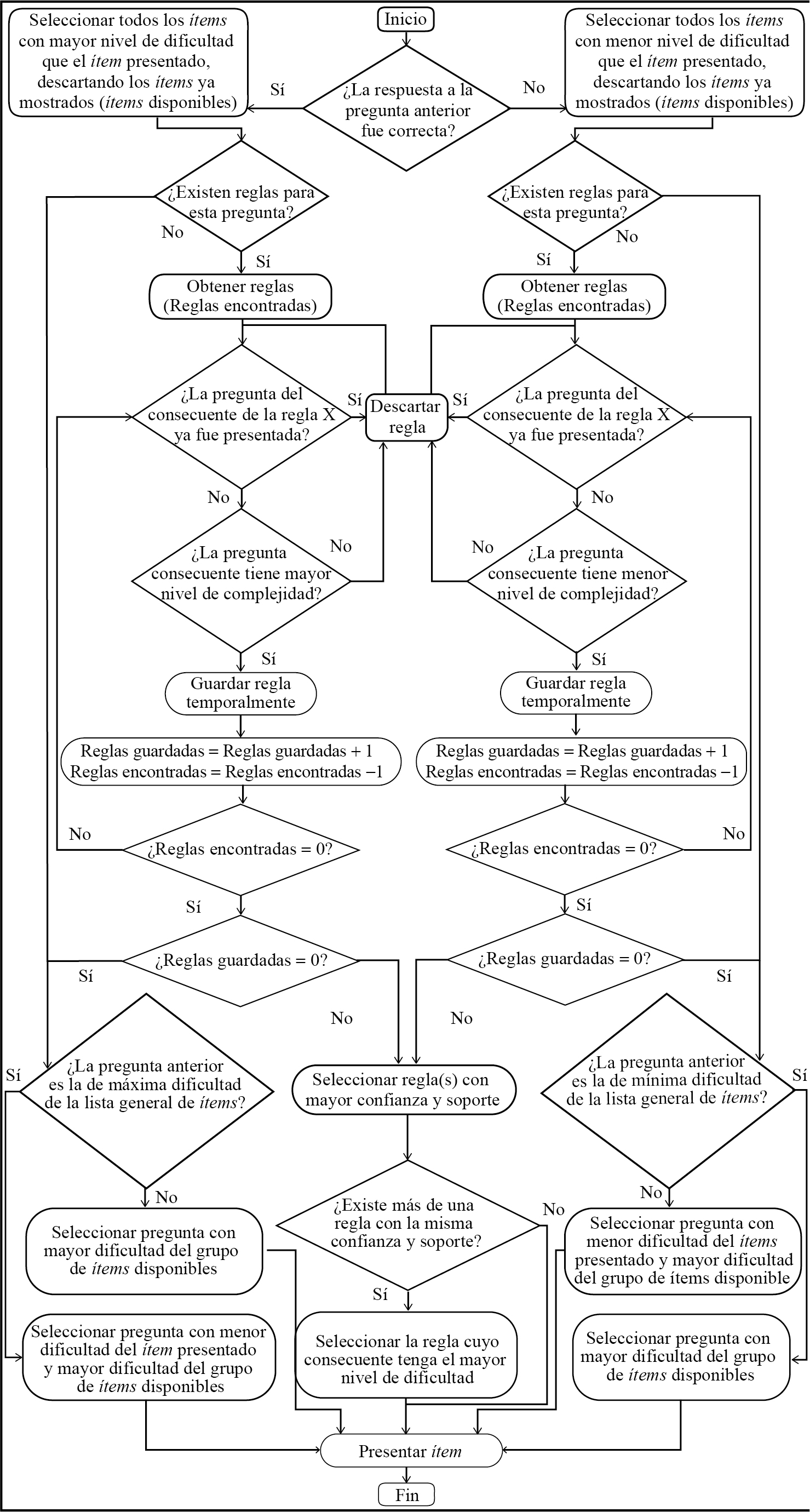
El proceso de la fase de selección de ítems comienza cuando el algoritmo verifica si la respuesta a la pregunta anterior fue correcta o incorrecta. En caso de ser correcta:
a) Se seleccionan todos los ítems con mayor nivel de dificultad que el ítem presentado y se descartan los ya mostrados. A este conjunto de ítems se les denomina “ítems disponibles”.
b) Se verifica si existen reglas de asociación almacenadas en la base de datos para el ítem presentado. En caso de existir, se obtienen. A este conjunto se le denomina “reglas encontradas”. Si no existen reglas, se procede al paso 5.
c) El siguiente paso consiste en revisar cada una de las reglas encontradas: primero se revisa si la pregunta consecuente de la regla ya fue presentada al alumno; en caso de ser afirmativo, se descarta la regla. Si no lo ha sido, entonces ahora se verifica si la pregunta consecuente tiene mayor nivel de complejidad que la pregunta previa; en caso de ser negativo, se descarta la regla. Si la regla ha pasado los dos filtros previos, se guarda de manera temporal en un grupo llamado “reglas guardadas”.
d) El paso 3 se repite para cada una de las reglas encontradas. Cuando ya no hay más, entonces se comprueba si el conjunto de reglas guardadas es igual a 0. Si es afirmativo, se procede al paso 5 y si es negativo, se seleccionan reglas con mayor confianza y soporte y se procede a verificar si existe más de una regla con la misma confianza y soporte. Si es negativo, se procede al paso 6 y si es positivo, se selecciona la regla cuyo consecuente tenga el mayor nivel de dificultad y se continúa con el paso 6.
e) Se verifica si la pregunta recién presentada es la de máxima dificultad en la lista general de ítems. En caso de ser afirmativo, se elige una pregunta con menor dificultad y con mayor dificultad del grupo de ítems disponibles y se procede al paso 6; de ser negativo, se selecciona la pregunta con mayor dificultad del grupo de ítems disponibles y se sigue con el paso 6.
f) Se presenta la pregunta y termina la etapa de selección de ítems.
Si la respuesta a la pregunta anterior es incorrecta, prácticamente se sigue el mismo proceso con las siguientes diferencias:
a) En el paso 1 se seleccionan ítems con menor nivel de dificultad que el ítem presentado.
b) En el paso 3 se verifica si la pregunta consecuente de la regla tiene menor nivel de complejidad.
c) En el paso 5 se revisa si la pregunta reciente presentada es la de mínima dificultad en la lista general de ítems. En caso de ser afirmativo, se selecciona la pregunta con mayor nivel de dificultad del grupo de ítems disponibles; en caso de ser negativo, sería una pregunta con menor dificultad del ítem presentado y mayor dificultad del grupo de ítems disponibles. En ambos casos igual se procede al paso 6.
3. 1. Ejemplo
Suponiendo que se toma el mismo nivel de estimación inicial de habilidad para todos los alumnos de un grupo (pregunta con dificultad media) y se tienen 10 preguntas identificadas como Pregunta1 a Pregunta10, ordenadas de acuerdo con su nivel de dificultad de menor a mayor respectivamente, la última pregunta presentada fue la Pregunta7 y la respuesta del alumno fue correcta, entonces:
a) El algoritmo selecciona todas las preguntas con mayor nivel de dificultad que la pregunta presentada; descarta las preguntas ya presentadas: Pregunta8, Pregunta9 y Pregunta10 (paso 1).
b) Se verifica si existen reglas para la Pregunta7. Al respecto, se tienen dos:
• Pregunta7(1) => Pregunta8(1) Confianza = 1, Soporte 0.90
• Pregunta7(1) => Pregunta10(1) Confianza = 1, Soporte 0.90
Lo anterior significa que si se contesta bien la Pregunta7, entonces implica mayor probabilidad de responder correctamente la Pregunta8 y la Pregunta10. Este conjunto se reglas reciben el nombre de “reglas encontradas” (paso 2).
c) El algoritmo comprueba si la pregunta consecuente (Pregunta8) de la primera regla encontrada ya fue presentada. Si no ha sido presentada, entonces se tiene que verificar si la pregunta tiene mayor nivel de dificultad. En este caso sí presenta mayor nivel de dificultad; por lo tanto, procede a almacenarla de manera temporal en “reglas guardadas”. Se repite el proceso con la pregunta consecuente (Pregunta10) de la segunda regla, siendo el mismo resultado, y también la almacena (paso 3).
d) El siguiente paso en el algoritmo consiste en verificar si existe más de una regla en “reglas guardadas” que tenga el mismo nivel de confianza y soporte; para este ejemplo ambas reglas cuentan con los mismos niveles. Por lo tanto, el algoritmo selecciona la regla cuya pregunta consecuente posea el mayor nivel de dificultad; para este caso, la segunda regla dispone de la Pregunta10 que, de acuerdo con las bases del ejemplo, es la que tiene mayor nivel de dificultad (paso 4).
e) Por último, la Pregunta10 es presentada al alumno (paso 6).
Prospectiva
La contribución principal de este artículo es proponer un método de evaluación adaptativa computarizada que integra a la minería de reglas de asociación como estrategia de selección de ítems. La principal ventaja de este método es que la selección se basa en los datos recolectados de otros estudiantes que han realizado el mismo examen con el objetivo de presentar al evaluado las preguntas con mayor probabilidad de responder correctamente. En el futuro, se desarrollará una aplicación web que implemente el método propuesto y se aplicará en un curso de bases de datos en nivel maestría para evaluar su desempeño.
Conclusiones
Evaluar es una parte fundamental dentro del proceso enseñanza-aprendizaje, ya que no solamente le da una nota o calificación al alumno, sino que, además, le brinda información al profesor acerca de las ventajas y desventajas que tiene cada evaluado, lo cual puede ser utilizado para mejorar la calidad del proceso. A lo largo del tiempo, las pruebas o exámenes han sido la forma más de común de medir el nivel de conocimientos de las personas.
Mientras que en el sistema tradicional suele aplicarse el mismo examen para todas las personas que forman parte de un grupo físico, en el sistema e-Learning las pruebas son de manera digital y, de la misma forma que en el sistema tradicional de enseñanza, también puede aplicarse el mismo examen para todos los alumnos que forman parte de un grupo virtual. Sin embargo, con el surgimiento de los CAT, las pruebas pueden adaptarse al nivel de conocimiento de los evaluados.
El proceso de los CAT contempla varias etapas: una de las principales es la selección de ítems, donde la información máxima de Fisher es uno de los criterios más empleados, aunque plantea ciertas desventajas, tales como repetición de ítems presentados, sesgo en la elección, entre otras. Para tratar de resolver estos errores, este artículo muestra la aplicación de la minería de reglas de asociación como una estrategia de selección de ítems, donde, basándose en el conocimiento generado en información de exámenes previamente contestados por alumnos, el algoritmo de selección puede elegir los ítems que mejor se adapten al alumno de acuerdo con su nivel de conocimiento.
El proceso de selección de ítems presentado se empleará en la implementación de un sistema de evaluación CAT, cuya característica principal es la de utilizar reglas de asociación en la etapa de selección; por el momento, el sistema de evaluación se encuentra en la etapa de desarrollo. Al finalizar, se llevarán a cabo pruebas de simulación que permitirán verificar su eficacia.

