











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introducción
La innovación, es un concepto, cuya implementación y desarrollo en el sector empresarial cobra cada vez mayor importancia, dado que, al acrecentar la innovación de la empresa, se incrementa su competitividad y su sostenibilidad en el mercado (Heijs y col., 2020; Morales-Guerrero y Álvarez-Aros, 2021; Zhang y col., 2023). Por lo que, el objetivo de toda empresa debe ser el aumentar la innovación dentro de ella; para lograr lo anterior, y como requisito necesario, las tomas de decisiones gerenciales deben estar orientadas a determinar, cuáles son las capacidades que estimulan y/o desarrollan la innovación (Fernández-Jardón, 2012; Mathison y col., 2022). Dentro del concepto de innovación, se identifican dos elementos distintivos y complementarios: el proceso de innovación, que consiste en el conjunto de la totalidad de las actividades o acciones que se ejecutan para lograr la innovación empresarial; e innovación, que representa el resultado del proceso de innovación (Mathison y col., 2022).
Las capacidades empresariales que estimulan y/o desarrollan la innovación, y, con ello, la competitividad en las empresas, son llamadas capacidades dinámicas. En el conjunto de estas capacidades, son dos las principales actividades de gestión a considerar al emprender actividades de innovación: la estrategia competitiva o de innovación de una empresa y las capacidades organizacionales y gerenciales utilizadas para implementar dicha estrategia (OECD/Eurostat, 2018). Las capacidades: capacidad de innovación (CIn); gestión del conocimiento (GC); inteligencia competitiva (IC); capital intelectual (CI); y capacidad de absorción (CA), son las principales capacidades dinámicas que utilizan en el proceso para implementar las estrategias de innovación. Estas capacidades dinámicas, son llamadas variables latentes o constructos, ya que no es posible medirlas directamente, y son medibles a través de indicadores, a los cuales se les denomina ítems, variables manifiestas o indicadores.
La GC es el proceso de identificar, crear, asimilar y aplicar el conocimiento organizativo para explotar nuevas oportunidades de innovación y mejorar el rendimiento de la organización (Cabrilo, 2020). Autores como Siregar y col. (2019) y Nabi y col. (2023), entre otros, determinaron que existe una relación causal entre la GC y la CIn.
El CI, es una capacidad dinámica, considerada como un bien intangible de la empresa, en la que se consideran tres dimensiones: capital humano; capital estructural; y capital relacional, con los que es posible crear y modificar los activos y las relaciones sociales (Ali y col., 2021).
El Instituto LISA (2023) establece que la IC tiene como objetivo general hacer más competitiva a la empresa; y tiene siete objetivos secundarios principales: “proporcionar las estrategias y tácticas de los competidores directos e indirectos para anticiparse a ellos a las oportunidades; analizar toda la información disponible (interna y externa) para coadyuvar a la mejor toma de decisiones; comprender las futuras necesidades del mercado y de los clientes; identificar las tendencias del sector a nivel de producto y servicios; monitorizar las innovaciones tecnológicas que pueden provocar un cambio en el mercado; ir de la mano del departamento de seguridad: proteger la información, el conocimiento y al personal (actual y anterior) para evitar el espionaje; monitorizar las oportunidades, riesgos y vulnerabilidades a nivel político, económico y social a nivel internacional”.
La CA de una empresa, se define como la colección de habilidades que dispone una empresa para identificar la importancia de la información, asimilarla y aplicarla con fines comerciales (Cohen y Levinthal, 1990). Amir (2017) describe a la CA como la capacidad de la empresa para identificar el conocimiento externo que se requiere, y combinarlo con el conocimiento interno con el fin de aplicarlo para satisfacer las necesidades, actuales y futuras, de los clientes. Zahra y George (2002), establecen que el desarrollar y mantener la CA es vital para la supervivencia y el éxito a largo plazo de una empresa, ya que esta capacidad puede fortalecer, complementar o reorientar la base de conocimientos de la empresa.
La CIn, es una condición que permite fortalecer la capacidad de reconfigurar los recursos que posee la organización en el campo de la innovación, como respuesta a los cambios que se presentan en el entorno en el que se desarrolla la empresa (Inków, 2020; Jalil y col., 2022). El cuantificar la CIn, le proporciona a la empresa, una base para medir su nivel de competitividad y posicionamiento dentro del mercado, y por ende, la posibilidad de sobrevivir en un mercado altamente competitivo (Escobar y col., 2017; Astudillo y col., 2018; de-las-Heras y Herrera, 2021).
Calof y Sewdass (2020), Aljuboori y col. (2021), Lam y col. (2021), Poblano (2021), Silvianita y Pradana (2022), construyeron modelos de relaciones causales, en los que la CIn aparece como variable endógena y como variables exógenas: una, dos o hasta tres de las capacidades dinámicas IC, CI, CA y GC, es decir, dichos autores, no incluyen al menos a una de estas cuatro variables exógenas en los modelos considerados. En la literatura revisada, no se encontró ningún modelo que contemple la relación causal para esas cinco capacidades dinámicas.
Los administradores de las empresas, en las que se gestiona el mejoramiento de la innovación, en la que están presentes estas cinco capacidades dinámicas, deben decidir cuántos recursos asignar a cada una de ellas con el fin de optimizar el proceso. El conocer, cuánto valor se incrementa en la innovación, por cada unidad que se eleve el valor en cada capacidad dinámica, es una información útil para los tomadores de decisiones, ya que, los recursos deben ser asignados a aquellas capacidades cuyo aumento en su valor, generen un mayor aporte al incremento en la CIn de la empresa. Dicha información, se puede obtener mediante una estimación del modelo de regresión lineal multivariante, donde se considera a la CIn como endógena y a CI, IC, GC, y CA como exógenas. Es importante incluir las cuatro variables exógenas, ya que al excluir una de ellas puede ocurrir que la decisión sobre a cuál capacidad a la que se le asigne recurso, puede resultar no óptima: dado que precisamente esta(s) capacidad(es) dinámica(s) ignorada(s) en el modelo, es(son) la(s) que mayor beneficio genere(n) en la innovación; o que esta(s), genere(n) un mayor beneficio o crecimiento en la innovación, a través del efecto indirecto sobre el resto de las variables exógenas (Chen y col., 2018).
El objetivo del presente trabajo fue desarrollar un modelo de regresión lineal multivariado que permitiese establecer la magnitud del efecto que tienen las capacidades dinámicas IC, CI, GC, CA (variables exógenas) en la capacidad dinámica CIn (variable endógena) de las empresas, identificando los factores críticos y su efecto en la innovación.
Materiales y métodos
Metodología
Se utiliza con un enfoque cuantitativo, con alcance correlacional. El diseño de la investigación es de tipo observacional; y es transeccional o transversal de tipo correlacional-causal.
Validación de contenido del instrumento de medición
El Instrumento de Medición (IM), incluye cinco variables latentes o constructos de naturaleza reflexiva: CIn, GC, IC, CI, y CA, y cada una de ellas consta, respectivamente, de cinco, seis, cinco, siete y cuatro ítems. Los ítems pertenecientes a las primeras cuatro variables latentes, son traducidos y adaptados de Poblano (2021), mientras los ítems correspondientes al constructo CA, son traducidos y adaptados de los trabajos presentados por: Nazarpoori, 2017, Popescu y col., 2019, Miroshnychenko y col., 2021 y Müller y col., 2021. La validación de contenido del IM, se somete a la valoración de un grupo de cinco expertos en el área, quienes evalúan cuatro rubros: suficiencia, relevancia, claridad y coherencia (Escobar-Pérez y Cuervo-Martínez, 2008). Después de que los expertos emiten su juicio, se cuantifica el grado de acuerdo entre ellos en sus valoraciones para cada uno de estos cuatro rubros, para ello se prueban cuatro hipótesis nulas H0: existe concordancia entre los jueces en la valoración de la: suficiencia; relevancia; claridad; y coherencia, lo cual se lleva a cabo con la prueba de Friedman, con un nivel de significancia P = 0.05. Los ítems correspondientes y sus respectivas codificaciones considerados en el IM, se muestran en la Tabla 1.
Tabla 1 Variables latentes, ítems y su codificación, considerados en el IM.
| Variable latente | Ítems | Codificación |
|---|---|---|
| Capacidad de innovación (CIn)* |
Promueve la generación de ideas, obteniendo al menos una nueva idea de manera periódica. | CIn1 |
| Promueve la generación de nuevos conceptos y obtiene al menos un nuevo concepto a ser llevado a cabo de manera periódica. | CIn2 | |
| Promueve la generación de productos y obtiene al menos un producto nuevo o mejorado para su realización de manera periódica. | CIn3 | |
| Promueve la generación de procesos y obtiene al menos un proceso nuevo o mejorado de manera periódica. | CIn4 | |
| Promueve la generación de propiedad intelectual (patentes, marcas, etc.) y obtiene al menos un registro de manera periódica. | CIn5 | |
| Gestión del conocimiento (GC)* |
Promueve la creación del conocimiento que pueden generar los individuos, organizaciones o grupos. | GC1 |
| Analiza y selecciona la información que se llega a generar por parte de los individuos, organizaciones o grupos. | GC2 | |
| Cuenta con manuales, procedimientos y/o fuentes donde sea fácil encontrar datos estructurados adecuadamente. | GC3 | |
| Tiene mecanismos para traducir el conocimiento de manera que pueda ser transmitido de distintas formas: por ejemplo, informes, bases de datos, entre otros. | GC4 | |
| Desarrolla actividades encaminadas a favorecer una dispersión inteligente de la información, esto es, la transferencia interna y externa. | GC5 | |
| Lo importante está en representar el conocimiento de forma que quede accesible y entendible para todos los miembros de la organización. | GC6 | |
| Capacidad de absorción (CA)** |
Cuenta con prácticas de adquisición de conocimientos sobre los nuevos productos/servicios dentro de la industria. | CA1 |
| Implementa prácticas para la integración de diferentes fuentes y tipos de conocimiento. | CA2 | |
| En la empresa, las ideas y los conceptos se comunican de forma interdepartamental. | CA3 | |
| La dirección hace hincapié en el apoyo interdepartamental para resolver los problemas. | CA4 | |
| Inteligencia competitiva (IC)* |
Realiza reuniones de planeación estratégica para definir información importante del entorno de la empresa. | IC1 |
| Realiza reuniones de planeación estratégica para definir cómo obtener información del entorno. | IC2 | |
| Recolecta la información relevante del entorno de forma sistemática. | IC3 | |
| Analiza la información del entorno para generar reportes con información estratégica. | IC4 | |
| Proporciona formación y desarrollo al personal encargado de definir, buscar, analizar y generar información estratégica. | IC5 | |
| Capital intelectual (CI)* |
Considera el nivel académico/profesional del personal para su contratación y promoción. | CI1 |
| Proporciona capacitación y desarrollo a su personal de acuerdo con las competencias requeridas en la función a desempeñar. | CI2 | |
| Promueve la cultura de compartir conocimiento entre su personal. | CI3 | |
| Conoce el capital humano con el que cuenta la empresa (sistema de información del personal). | CI4 | |
| Promueve la participación del personal en las actividades de mejora e innovación. | CI5 | |
| Proporciona capacitación para la gestión de la innovación. | CI6 | |
| Mantiene relaciones con sus clientes y proveedores para la mejora de procesos y productos. | CI7 |
Fuente: *modificada a partir de Poblano (2021); **adaptada a partir de: Nazarpoori (2017), Popescu y col. (2019), Miroshnychenko y col. (2021), Müller y col. (2021).
Definición, análisis y validación de la muestra
Definición y análisis
El tamaño de la muestra fue de 196 empresas ubicadas en la ciudad de Hermosillo, Sonora, México, a las cuales se les aplicó el IM, y para cada ítem se utilizó una escala de medición Likert del 1 a 5, donde el 1, representa estar totalmente en desacuerdo y el 5, representa estar totalmente de acuerdo. La recolección de la muestra se llevó a cabo por el método de conveniencia, mediante una encuesta de manera presencial, a la persona con más alta jerarquía, de cada una de estas empresas, que estuviera en condiciones, en cuanto al conocimiento necesario dentro de la empresa para responder el IM. La información que se recopiló, no es información crítica o confidencial de las empresas, y es por ello, que no fue necesario establecer acuerdos de confidencialidad con los entrevistados, a quienes, se les hizo énfasis que, en este IM no había respuesta correctas ni incorrectas, por lo que se les invitaba a contestarlo lo más apegado a la realidad. Se asumió que la muestra era homogénea, es decir, no posee heterogeneidad observada, ni no observada, esta suposición se plantea debido a que en la literatura no se considera variable alguna, que pueda generar estratos o conglomerados en la población.
Caballero (2006) y Hair y col. (2011), establecieron que el tamaño mínimo de la muestra debe ser igual al valor más alto que resulte de: a) multiplicar por 10 la cantidad de variables latentes en el modelo, que en este trabajo fueron 5; o b) del número total de ítems de la variable latente con mayor cantidad, que fueron 7. En este estudio su multiplicación correspondería a 50 y 70, respectivamente, por lo que este último, sería el tamaño mínimo de la muestra a considerar. Por otro lado, acorde al criterio del método recomendado por Kock y Hadaya (2018), de la raíz cuadrada inversa del tamaño de la muestra (n = 196), se obtiene que 0.202 es el valor mínimo para que los parámetros estimados del modelo de regresión lineal, sean significativos a un nivel del 5 %, y con una potencia de prueba de hipótesis de al menos del 80 %.
Validación
Para la validación de la muestra se trabajó con tres fases: primera, eliminación de datos atípicos, este tipo de datos son eliminados de la muestra, si el valor numérico de su distancia de Mahalanobis, calculada con la función Mahalanobis del software RStudio, versión 4.3.2. (2023-1031 ucrt), es mayor que el valor del percentil 97.5 de la distribución chi cuadrada con 27 grados de libertad; segunda, aplicación del criterio de Kaiser-Meyer-Olkin (KMO), valor que se calcula con la función KMO del paquete psych del software RStudio, versión 4.3.2. (2023-1031 ucrt), el cual, establece que los datos de la muestra son apropiados para usarlos en análisis factorial, si el valor del KMO ≥ 0.70; tercera, prueba de esfericidad de Bartlett, aquí se pone a prueba, la hipótesis nula en la que se afirma que la matriz de varianza covarianza de los datos de la muestra, es igual a la matriz identidad, lo cual implica una nula correlación entre las variables de la base de datos de la muestra. El nivel de significancia que se usa para esta prueba de hipótesis es del 5 %, dicha prueba de hipótesis se ejecuta con la función cortestbartlett del paquete psych del software RStudio, versión 4.3.2 (2023-10-31 ucrt).
Construcción del modelo de regresión lineal multivariante o modelo estructural
La construcción del modelo estructural, se llevó a cabo en cinco etapas: primera, se evaluó la calidad del IM o del modelo “outer”, para lo cual, se debe cumplir que el IM es confiable y válido; segunda, se construyó el modelo de regresión lineal o modelo “inner”, por ello, se estimaron y validaron los valores del modelo; tercera, se determinó la bondad de ajuste del modelo, en donde se midió su capacidad explicativa y predictiva; cuarta, se evaluó la colinealidad de las variables latentes; quinta, se determinó la presencia de heterogeneidad no observada (Hair y col., 2011; 2012; Ghasemy y col., 2020).
Determinación de la confiabilidad y validez del IM
Confiabilidad
Se establece que el IM es confiable, si los valores numéricos de las cargas factoriales de cada ítem del IM, y de los indicadores alfa de Cronbach y rho de Dillon-Goldstein, para cada variable latente del IM es ≥ 0.070 (Aldás y Uriel, 2017).
Validez
Se dice que el IM tiene validez si posee: validez convergente, esto ocurre cuando el valor numérico del Promedio de la Varianza Extraída (AVE, por sus siglas en inglés: Average Variance Extracted), para cada variable latente del IM es ≥ 0.50; validez discriminante, si se cumple el criterio de Fornell y Lacker, el cual ocurre si, el valor de la correlación para cualquier pareja de variables latentes, es menor que el valor de la raíz cuadrada del AVE de cada una de las parejas de estas variables (Aldás y Uriel, 2017).
Construcción y validación del modelo estructural
Estimación de parámetros
Las ecuaciones lineales (1), (2), (3), y (4), representan el modelo de regresión lineal multivariante propuesto.
Los valores numéricos de los parámetros ki (i = 1, 2, 3, y 4) corresponden a la magnitud con la que varía, acorde al signo de ki, el valor de la CIn. Por ejemplo, si el valor numérico de k1 es igual a 0.875, esto es un indicador de que por cada unidad en que se incremente el valor de la IC, el valor numérico de la CIn se incrementa en 0.875 unidades; dicha información es importante para los administradores de las empresas que decidan implementar un proceso para el mejoramiento de la CIn en la empresa, ya que este modelo le permite visualizar cuál de esas cuatro capacidades dinámicas tiene un mayor efecto en el incremento en el valor de la variable CIn. Situación similar representan los valores de los parámetros ki (i = 5, 6, 7), k8, y k9, respectivamente, para las variables endógenas CA, el CI, y la GC, de las ecuaciones (2), (3), y (4).
Para estimar y validar los valores numéricos de los parámetros ki (i = 1, 2,…, 9), se utilizó el método de Modelos de Ecuaciones Estructurales, con Mínimos Cuadrados Parciales (PLS-SEM, por sus siglas en inglés: Partial Least Squares Structural Equation Modeling), el cual tiene las siguientes características: no requiere que las variables latentes o manifiestas del modelo, asuman alguna distribución de probabilidad; proporciona una adecuada capacidad predictiva, lo que lo convierte en una herramienta administrativa apropiada; funciona eficientemente con muestras de tamaño pequeño, en comparación con otros métodos (Hair, 2019).
La estimación de parámetros se llevó a cabo utilizando la función plspm del paquete PLSPM del software estadístico de acceso libre RStudio, versión 4.3.2. (2023-1031 ucrt). La validación estadística de estos parámetros, se realizó con la ejecución de la función bootstrapping, con 200 remuestreos, del mismo paquete estadístico, y se estableció que cada parámetro estimado es estadísticamente significativo si, el intervalo del 95 % de confianza estimado para el valor de cada parámetro, no contiene al cero (Sánchez, 2013).
Evaluación de la bondad de ajuste del modelo estimado
Para evaluar la bondad de ajuste del modelo, se midieron dos características: la capacidad explicativa del modelo, que mide la precisión de los parámetros estimados o el porcentaje de la variación observada en la variable endógena que es explicada por sus correspondientes variables exógenas, capacidad que fue cuantificada con el coeficiente de determinación (R2), misma que es clasificada como: baja, si R2 < 0.30; moderada, si 0.30 ≤ R2 ≤ 0.60; alta, si R2 > 0.60, no existe consenso en estos rangos de clasificación, por lo que también se consideró este rango de clasificación alternativo: baja, si R2 < 0.20; moderada, si 0.20 ≤ R2 ≤ 0.50; alta, si R2 > 0.50. La capacidad predictiva del modelo, fue evaluada a través del indicador Pseudo Bondad de Ajuste (GoF, por su siglas en inglés: Goodness of Fit) (Sánchez, 2013). La capacidad de predicción bajo este indicador, se clasifica como pequeña, si GoF < 0.10; mediana, si 0.10 ≤ GoF ≤ 0.25; alta, si GoF > 0.25 (Wetzels y col., 2009).
Análisis de la heterogeneidad no observada en la muestra
El análisis de heterogeneidad, del modelo global, es un análisis que se lleva a cabo posterior al análisis estructural del modelo, y tiene como objetivo validar el supuesto de que los datos de la muestra son homogéneos, esto es determinar si no existen categorías o conglomerados en la muestra que pudieran afectar los resultados que se obtienen bajo la hipótesis de que la muestra es homogénea. En este trabajo, el análisis de heterogeneidad se ejecuta con el método Respuesta Basado en Unidades de Segmentación en SEM-PLS (REBUS, por sus siglas en inglés: REsponse Based procedure for detecting Unit Segments in PLS-PM), el cual es un algoritmo que detecta clases latentes dentro del SEM-PLS, este método, no requiere asumir distribuciones de probabilidad para las variables involucradas en el modelo, y una de sus utilidades, al descubrir estas clases, es mejorar la capacidad de predicción. La muestra se declara heterogénea, si el valor del indicador GoF del modelo global, es menor, al menos en un 25 %, que el valor del Índice de Calidad Grupal (GQI, por sus siglas en inglés: Group Quality Index) (Vincenzo y col., 2010). El valor de numérico de GQI se obtiene con la función rebus.pls, de la función plspm del software de acceso libre RStudio, versión 4.3.2. (2023-1031 ucrt).
Resultados
Análisis y adecuación de la muestra
Análisis
En la Tabla 2, se presenta el número de empresas entrevistadas, de acuerdo al sector económico al que pertenecen y por su tamaño o número de empleados que laboran en ella, en donde, el 73 % corresponde al sector manufactura y el 27 % restante al sector servicio; por otro lado, el 57.1 % de ellas son clasificadas como grandes empresas, mientras que el resto, el 42.9 % son clasificadas como Pequeñas y Medianas Empresas (PyMES).
Adecuación
La adecuación de la muestra, se evaluó en tres etapas: primera, de los 196 datos de la muestra, se identificaron y eliminaron 18 datos atípicos, por lo que el análisis final se llevó a cabo con una muestra de 178 datos, donde el valor de cada variable latente es ≥ 0.212, resultó significativa al nivel del 5 %, y con una potencia de prueba de hipótesis del 80 %; segunda, el valor del KMO para estos 178 datos es igual 0.82, lo cual implica que los datos son útiles para análisis de correlación; tercera, en la prueba de hipótesis de la esfericidad de Bartlett, el valor de la variable aleatoria chi cuadrada con 406 grados de libertad genera un “p-value” con valor a 0.000 04, por lo que, con un nivel de significancia del 5 %, se rechaza la hipótesis nula que establece que, la matriz varianza covarianza de los datos de dicha muestra es igual a la matriz identidad. De los resultados anteriores, se llegó a comprobar que la muestra es adecuada para analizarse a través de los modelos de ecuaciones estructurales.
Análisis descriptivo de los ítems y las variables latentes del IM
Los valores más bajos de la media aritmética corresponden a los ítems de la variable latente CIn. Los valores mínimos y máximos para cada uno de todos los ítems del IM, son iguales a 1 y 5. Los valores de los cuartiles 1 y 3 para los ítems de la variable latente CIn, son, respectivamente, igual a 1 y 5, y los valores correspondientes para las cuatro variables latentes restantes, son de 3 a 5, lo que implica que la varianza en la variable CIn, es mayor que la variable correspondiente al resto de las variables latentes IC, CI, GC y CA. Para cada uno de dichos ítems, no fue posible afirmar que sigan una distribución normal, dada la diferencia entre los valores de la media aritmética, la moda, y la mediana (Tabla 3).
Tabla 3 Valores descriptivos de los ítems del IM.
| Variable latente | Codificación | Min | Max | Mediana | Moda | Media | Q1 | Q3 |
|---|---|---|---|---|---|---|---|---|
| Capacidad de innovación (CIn) |
CIn1 | 1 | 5 | 1 | 1 | 2.90 | 1 | 5 |
| CIn2 | 1 | 5 | 3 | 1 | 2.97 | 1 | 5 | |
| CIn3 | 1 | 5 | 1 | 1 | 2.92 | 1 | 5 | |
| CIn4 | 1 | 5 | 1 | 1 | 2.91 | 1 | 5 | |
| CIn5 | 1 | 5 | 1.5 | 1 | 2.91 | 1 | 5 | |
| CIn6 | 1 | 5 | 1 | 1 | 2.89 | 1 | 5 | |
| CIn7 | 1 | 5 | 1.5 | 1 | 2.92 | 1 | 5 | |
| Gestión del conocimiento (GC) |
GC1 | 1 | 5 | 4 | 4 | 4.01 | 3 | 5 |
| GC2 | 1 | 5 | 4 | 5 | 3.82 | 3 | 5 | |
| GC3 | 1 | 5 | 4 | 5 | 3.96 | 3 | 5 | |
| GC4 | 1 | 5 | 4 | 5 | 3.81 | 3 | 5 | |
| GC5 | 1 | 5 | 4 | 5 | 3.75 | 3 | 5 | |
| GC6 | 1 | 5 | 4 | 5 | 3.55 | 3 | 5 | |
| Capacidad de absorción (CA) |
CA1 | 1 | 5 | 4 | 4 | 4.18 | 4 | 5 |
| CA2 | 1 | 5 | 4 | 5 | 3.96 | 3 | 5 | |
| CA3 | 1 | 5 | 4 | 4 | 3.92 | 3 | 5 | |
| CA4 | 1 | 5 | 4 | 4 | 3.92 | 3 | 5 | |
| Inteligencia competitiva (IC) |
IC1 | 1 | 5 | 4 | 5 | 3.74 | 3 | 5 |
| IC2 | 1 | 5 | 4 | 4 | 3.90 | 3 | 5 | |
| IC3 | 1 | 5 | 4 | 5 | 3.83 | 3 | 5 | |
| IC4 | 1 | 5 | 4 | 5 | 4.07 | 3.25 | 5 | |
| IC5 | 1 | 5 | 4 | 5 | 4.07 | 3.25 | 5 | |
| Capital intelectual (CI) |
CI1 | 1 | 5 | 4 | 5 | 3.83 | 3 | 5 |
| CI2 | 1 | 5 | 4 | 4 | 3.91 | 3 | 5 | |
| CI3 | 1 | 5 | 4 | 5 | 3.86 | 3 | 5 | |
| CI4 | 1 | 5 | 4 | 5 | 4.09 | 3 | 5 | |
| CI5 | 1 | 5 | 4 | 4 | 3.90 | 3 | 5 | |
| CI6 | 1 | 5 | 4 | 5 | 3.87 | 3 | 5 | |
| CI7 | 1 | 5 | 4 | 5 | 3.99 | 3 | 5 |
Las variables latentes del IM presentaron valores estandarizados pertenecientes al intervalo de números reales [- 3.3], y sus rangos intercuatílicos ≥ 1, esto último, aunado al hecho de que, los valores de la media aritmética, la moda, y la mediana no coinciden, no permiten establecer que dichas variables latentes sigan una distribución normal (Tabla 4). Dado que el método de análisis PLS-SEM que fue utilizado, es un método no paramétrico, no se verificó la normalidad de estas variables.
Tabla 4 Valores descriptivos de las variables latentes del IM.
| Variable latente | Min | Max | Mediana | Moda | Media | Q1 | Q3 |
|---|---|---|---|---|---|---|---|
| CIn | - 0.987 | 1.066 | - 0.690 | - 0.978 | 0 | - 0.978 | 1.066 |
| GC | - 2.78 | 1.069 | 0.261 | 0.994 | 0 | - 0.604 | 0.895 |
| CA | - 2.392 | 0.994 | 0.001 | 1.145 | 0 | - 0.698 | 0.994 |
| IC | - 2.920 | 1.057 | 0.256 | 1.057 | 0 | - 0.653 | 0.846 |
| CI | - 2.785 | 1.069 | 0.215 | 1.068 | 0 | - 0.604 | 0.895 |
Fuente: elaboración propia
Determinación de la confiabilidad y validez del instrumento de medición
Confiabilidad
El IM es confiable, dado que se cumple con los criterios establecidos (≥ 70) en los valores del alfa de Cronbach, del rho de Dillon-Goldstein y de la carga factorial para cada ítem (Tabla 5).
Tabla 5 Valores de confiabilidad, validez, capacidad explicativa y predictiva.
| Ítem | Carga factorial |
Alfa | rho | AVE | R2 | GoF | |
|---|---|---|---|---|---|---|---|
| IC | IC1 | 0.908 | 0.930 | 0.947 | 0.781 | n. a. | 0.659 |
| IC2 | 0.885 | ||||||
| IC3 | 0.913 | ||||||
| IC4 | 0.856 | ||||||
| IC5 | 0.856 | ||||||
| CI | CI1 | 0.863 | 0.940 | 0.951 | 0.737 | 0.308 | |
| CI2 | 0.898 | ||||||
| CI3 | 0.854 | ||||||
| CI4 | 0.812 | ||||||
| CI5 | 0.894 | ||||||
| CI6 | 0.881 | ||||||
| CI7 | 0.800 | ||||||
| GC | GC1 | 0.832 | 0.952 | 0.962 | 0.809 | 0.330 | |
| GC2 | 0.897 | ||||||
| GC3 | 0.903 | ||||||
| GC4 | 0.888 | ||||||
| GC5 | 0.926 | ||||||
| GC6 | 0.945 | ||||||
| CA | CA1 | 0.711 | 0.892 | 0.927 | 0.763 | 0.780 | |
| CA2 | 0.857 | ||||||
| CA3 | 0.951 | ||||||
| CA4 | 0.951 | ||||||
| CIn | CIn1 | 0.995 | 0.999 | 0.999 | 0.992 | 0.692 | |
| CIn2 | 0.994 | ||||||
| CIn3 | 0.997 | ||||||
| CIn4 | 0.996 | ||||||
| CIn5 | 0.996 | ||||||
| CIn6 | 0.998 | ||||||
| CIn7 | 0.997 |
Nota: n. a. = no aplica.
Validez
El IM es válido, dado que tiene validez convergente, ya que los valores del AVE para cada variable latente es ≥ 0.50 (Tabla 5), y también tiene validez discriminante, dado que, el valor numérico de la correlación entre cualquier pareja de variables latentes, es < que el valor de la raíz cuadrada del que corresponde a cualquiera de estas dos variables latentes (Tabla 6). Dado que el IM es confiable y válido, se procede al análisis del modelo estructural.
Estimación y validación del modelo estructural
En la Tabla 7, se presentan los valores de los parámetros ki (i = 1, 2, …, 9) correspondientes a las ecuaciones lineales (1), (2), (3), y (4), que son estimados a través de los efectos directos que las variables exógenas tienen sobre la variable endógena, y validados, con un nivel de significancia del 5 %. Y se muestran en las siguientes ecuaciones:
Tabla 7 Valores estimados de los parámetros de las Tabla 7, se presentan los valores de los parámetros ki (i = 1, 2, …, 9) correspondientes a las ecuaciones lineales (1), (2), (3), y (4).
| Parámetro | K1 | K2 | K3 | K4 | K5 | K6 | K7 | K8 | K9 |
|---|---|---|---|---|---|---|---|---|---|
| Efecto directo | 0.342* | 0.242* | 0.328* | 0.103ns | 0.293* | 0.230* | 0.555* | 0.557* | 0.575* |
| Efecto indirecto | 0.399* | 0.024ns | 0.058ns | 0.031ns | 0.447* | 0 | 0 | 0 | 0 |
| Efecto total | 0.741* | 0.266* | 0.386* | 0.134ns | 0.740* | 0.230* | 0.577* | 0.555* | 0.575* |
Nota: *significativo al 5 %; ns = no significativo al 5 %.
También, en la Tabla 7, se presentan los valores de los parámetros ki (i = 1, 2, …, 9) correspondientes a las Tabla 7, se presentan los valores de los parámetros ki (i = 1, 2, …, 9) correspondientes a las ecuaciones lineales (1), (2), (3), y (4), que son estimados a través de los efectos totales que las variables exógenas tienen sobre la variable endógena, y validados, con un nivel de significancia del 5 %. Y se muestran en las siguientes ecuaciones:
Del valor 0.741, que representa la magnitud del efecto total, que la capacidad dinámica IC tiene sobre la CIn, las cantidades 0.342 y 0.399 (Tabla 7), corresponden, respectivamente al efecto directo, y al efecto indirecto que la IC tiene sobre la CIn. El efecto directo, con referencia al modelo de regresión lineal multivariado representado por las ecuaciones (1), (2), (3), y (4), se refiere al impacto o efecto que tiene la IC, sobre la CIn, sin interactuar sobre ninguna de las restantes variables exógenas del modelo; mientras, que el efecto indirecto, es referido, en este caso, como el efecto directo que la IC, tiene sobre el CI y la GC, el cual genera que el efecto de CI y la GC sobre la CIn se vea incrementado o amplificado como efecto de la relación lineal representados por las ecuaciones (3) y (4).
Evaluación de la bondad de ajuste del modelo estimado
Capacidad explicativa del modelo multivariado estimado
Los valores numéricos 0.692, 0.780 0.308 y 0.330 (Tabla 5), que corresponden, respectivamente a los coeficientes de determinación (R2), para las variables endógenas de CIn, CA, CI y GC, consideradas, respectivamente, en las ecuaciones (1), (2), (3), y (4), son valores estadísticamente significativos con un nivel del 5 %. Dichos resultados numéricos, y bajo los criterios establecidos por Sánchez (2013) para los valores de este indicador, permitieron establecer que la capacidad explicativa para las ecuaciones (1) y (2) es alta. Esto implica, para el caso de la ecuación (1), que de las variaciones que se observan en la CIn, el 69.2 % de ella se explica, o se genera por efecto de las variaciones en las variables exógenas IC, CI y GC, por lo que el incremento en los niveles o valores de estas tres variables exógenas o capacidades dinámicas, genera un incremento en la capacidad dinámica CIn. Para el caso de la ecuación (2), el 78 % de la variación en la variable endógena CA, se explica, o es atribuible, a variaciones en las variables exógenas IC, CI, y GC de este modelo. En los valores para las ecuaciones (3) y (4), los porcentajes respectivos, de la variación de las variables endógenas CI y GC, que se justifica por la variación de la variable exógena IC, es del 30.8 % y del 33.0 %, por lo que la capacidad explicativa de estas dos últimas ecuaciones se clasifica en moderada.
Con estos resultados, se considera que el modelo multivariante estimado, tiene una capacidad explicativa de moderada a alta (de acuerdo al valor de R2: Tabla 5). Lo que a su vez lleva a establecer que los valores de los parámetros del modelo, no presentan grandes diferencias con los valores del parámetro poblacional (si se aplica a la totalidad de empresas en la región).
Capacidad predictiva del modelo multivariante estimado
El valor numérico del índice Pseudo bondad de ajuste (GoF), para este modelo de regresión lineal multivariante estimado en la presente investigación es igual 0.659 (Tabla 5), por lo que la capacidad de predicción de este modelo, es clasificada como alta, de acuerdo al criterio establecido por Wetzels y col. (2009). Dicha clasificación, implica que, si se conocen los niveles o valores de las variables exógenas IC, CI y GC, en los que están operando o que corresponden a la empresa, entonces el valor de la CIn, que se estima con el modelo lineal representado por la ecuación (1), es aproximadamente igual al valor que corresponde, al nivel de la CIn en el que opera la empresa.
La capacidad explicativa y predictiva del modelo de regresión multivariante estimado, lleva a establecer que este modelo es adecuado para representar las relaciones causales entre las capacidades dinámicas de las empresas: CIn; IC; CI; GC. De lo anterior, se afirma que la IC, es la que mayor impacto o efecto, tiene sobre la CIn, esto como consecuencia de su efecto directo, más los efectos indirectos que genera en las capacidades CI y GC.
Análisis de la heterogeneidad no observada en la muestra
La aplicación de la función rebus.pls a la muestra determina únicamente dos posibles estratos que pudieran generar diferentes modelos de regresión lineal. De la evaluación del par de modelos de regresión que se estiman en cada uno de los estratos, el valor del Índice de Calidad Grupal es igual a 0.679, el cual, no cumple con la condición de ser mayor en al menos el 25 % del valor GoF del modelo global, cuya magnitud es igual a 0.659. De lo anterior, se establece que la muestra es homogénea. Lo que permite garantizar que, no existen factores de ruido o estratos que afecten el análisis estadístico al utilizar los datos de esta muestra. Lo que lleva a establecer que, ninguna variable o característica concerniente a las personas o a las empresas encuestadas, que, no fueron consideradas en el IM, por ejemplo: el tamaño de la empresa; el género de las personas que contestan la encuesta; el giro de la empresa; la antigüedad de la empresa o cualquier otra variable de esta naturaleza, no tienen efecto sobre la CIn.
Discusión
El efecto existente entre las diferentes variables de estudio, de acuerdo con el modelo desarrollado puede apreciarse en la Figura 1. Se observa que la IC afectó de manera directa y significativa a las capacidades dinámicas CI y GC, consideradas como variables endógenas, y calculadas con las ecuaciones (3) y (4), respectivamente. La IC, CI y la GC tuvieron un efecto moderado y significativo sobre la variable endógena CIn, de acuerdo con la ecuación (1), en tanto que la IC lo tuvo alto y significativo de acuerdo con la misma ecuación. Lo anterior contrasta con los resultados presentados por Poblano (2021) y Yuwono (2021), quienes estudiaron las relaciones causales entre la variable endógena CIn con tres variables exógenas, seleccionadas de las cuatro capacidades dinámicas IC, CI, GC, y CA, incluidas en el modelo. Ambos autores determinaron que el efecto del CI sobre la variable CIn no es significativo. Tratar de explicar esta discrepancia en dichos resultados, no es una tarea trivial, ya que las posibles causales de esa diferencia pueden ser múltiples: el error aleatorio; el número y tipo de variables latentes consideradas en el modelo; diferentes instrumentos de medición; métodos de análisis estadísticos utilizados; estructuración o diseño del modelo de regresión lineal multivariante; cultura de la región geográfica de donde se obtienen los datos para el análisis; tamaño y giro de las empresas encuestadas, entre otros.
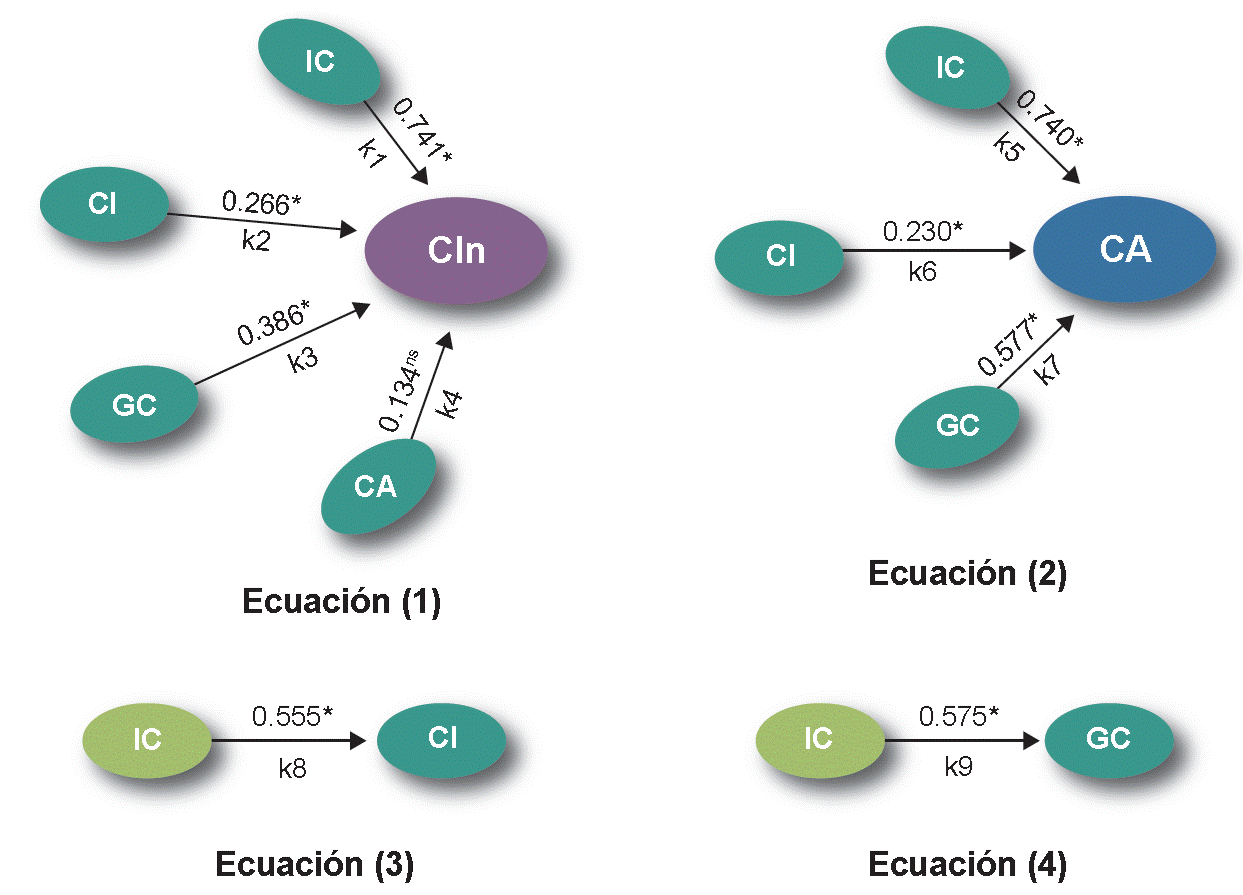
Nota: *significativo al 5 %; ns = no significativo al 5 %.
Figura 1 Modelo estructural que representa al modelo de regresión lineal multivariante expresados en las ecuaciones (1), (2), (3), y (4); los valores numéricos representan los valores estimados del efecto directo, k1, k2, …, k9, con el que cada variable exógena tiene sobre su respectiva variable endógena.
Además de las regiones geográficas donde se estima el modelo y el número de capacidades dinámicas consideradas, también es de destacar, que estos dos autores utilizan el método de Modelos de Ecuaciones Estructurales Basado en la Covarianza (CB-SEM, por sus siglas en inglés: Covariance based Structural Equation Modeling), el cual genera resultados diferentes a los resultados que se generan con el método PLS-SEM. Hair (2019), Dash y Paul (2021), Hair-Jr. y col. (2021) señalan que el método PLS-SEM, presenta, en relación al método CB-SEM, que: no requiere asumir distribución de probabilidad para las variables del modelo; funciona adecuadamente con muestras pequeñas; funcionan óptimamente para estimar modelos complejos y genera una mayor capacidad de predicción (Figura 1).
Calof y Sew-dass (2020), Aljuboori y col. (2021), Lam y col. (2021), Poblano (2021), Silvianita y Pradana (2022), contemplaron un análisis de la relación causal, hasta en un máximo de cuatro de las cinco variables latentes. El no contemplar a alguna de esas capacidades dinámicas en el proceso del mejoramiento de la CIn, puede llevar a resultados no óptimos o deficientes, en el sentido de que, por ejemplo, puede ocurrir que la(s) variable(s) latente(s) omitida(s) como variable(s) exógena(s) en el análisis sea(n) las que mayor efecto tienen sobre la variable endógena CIn, lo cual no permite lograr el máximo mejoramiento de la competitividad de la empresa involucrada en este proceso.
La no significancia estadística de la capacidad dinámica en la CA en los modelos de regresión lineal, implica que esta capacidad, no tiene efecto alguno sobre la CIn de las empresas, lo cual coincide con los resultados que obtiene Silvianita y Pradana (2022). Las afirmaciones anteriores, contradicen a los resultados presentados por Bhadauria y Singh (2023), Laachach y Ettahri (2023) y Maleski y col. (2023), en los que establecen que la correlación entre CA y CIn, es significativa, y que, existe una alta dependencia o un alto efecto que la CA tiene sobre la CIn, de tal forma que declaran que el desarrollo de la CA es esencial para el desarrollo de la CIn. Esta discrepancia se explica por el hecho de que la significancia del efecto de la CA sobre la CIn, estuviese en función o dependiere del número de capacidades dinámicas consideradas como variables exógenas en el modelo.
Conclusiones
El modelo de regresión lineal multivariante, permitió establecer la relación causal entre las variables exógenas o predictoras IC, CI, GC, y CA con la variable endógena CIn. Es un modelo estadístico útil en la gestión e implementación del proceso de mejoramiento de la CIn de las empresas ubicadas en la ciudad de Hermosillo, Sonora, México, dado que sus capacidades explicativa y predictiva fueron adecuadas, lo que genera confianza en la precisión y exactitud en las estimaciones del valor de la CIn, en función de los valores de las variables predictoras IC, CI, y GC. Dicha información resulta importante para asignar, de manera eficiente, los recursos para mejorar los valores de estas capacidades dinámicas. En el presente modelo, se observó que no es necesario destinar recursos para mejorar la CA, ya que esta capacidad dinámica, no tuvo efecto alguno sobre la CIn. Por otro lado, la IC, es la capacidad dinámica con mayor efecto, tanto directo como total, sobre la CIn y por cada unidad que se incremente en el valor del nivel de la IC, el valor del nivel de la CIn, aumenta en más del doble que, cuando se incrementa una unidad en el CI o la GC. La decisión final, sobre cuál de las tres variables exógenas del modelo de regresión lineal multivariado es prioridad para asignarle recursos con el objetivo de incrementar su nivel, está en función de lo que resulta del análisis financiero que determine el costo de incrementar el nivel de cada una de tres variables exógenas, contra el beneficio que se refleja en el incremento de la variable endógena del modelo.

