











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introducción
La educación inclusiva es un derecho fundamental que busca garantizar la igualdad de oportunidades en el acceso al conocimiento. Sin embargo, las personas sordas enfrentan barreras significativas en entornos educativos debido a la falta de estrategias de comunicación adaptadas a sus necesidades (GoMex, 2016). La Lengua de Señas Mexicana (LSM) es el medio principal de comunicación para esta comunidad, pero el desconocimiento generalizado de la LSM dificulta su integración en entornos académicos y sociales (Munguía, 2017).
Uno de los principales desafíos es la disponibilidad limitada de intérpretes de LSM en las instituciones educativas. La falta de estos profesionales restringe el acceso de los estudiantes sordos a la información, lo cual puede repercutir en su rendimiento académico y su participación en actividades de aprendizaje. Además, los materiales educativos en LSM son escasos, lo que refuerza la necesidad de herramientas tecnológicas que faciliten la comunicación entre hablantes y no hablantes de esta lengua (Pérez & Cruz, 2021).
La carencia de herramientas accesibles para traducir la LSM al español agrava esta situación. Aunque existen iniciativas que buscan mejorar la accesibilidad, muchas de ellas se centran en entornos específicos y no están ampliamente disponibles en plataformas de uso cotidiano. Esto subraya la necesidad de desarrollar soluciones tecnológicas que permitan la interpretación en tiempo real y sean de fácil acceso para docentes, estudiantes y familias (Martínez et al., 2016).
El avance de la inteligencia artificial (IA) y el aprendizaje profundo (Deep Learning) han permitido el desarrollo de sistemas capaces de reconocer y traducir lenguas de señas con alta precisión. Estas tecnologías han demostrado ser efectivas en el reconocimiento de patrones visuales y el procesamiento de lenguaje natural, lo que las convierte en herramientas viables para abordar la barrera comunicativa en la educación de personas sordas (Heaton et al., 2016).
El aprendizaje profundo permite el desarrollo de modelos avanzados de reconocimiento de imágenes que pueden interpretar con precisión gestos y señas de la LSM. Este enfoque ha sido implementado en estudios previos con resultados prometedores, mejorando notablemente la exactitud de la interpretación automática de lenguas de señas mediante el uso de redes neuronales convolucionales y redes neuronales recurrentes (Salgado et al., 2024).
La implementación de modelos de Machine Learning (ML) en dispositivos móviles representa una solución innovadora para la accesibilidad educativa. Los teléfonos inteligentes y tabletas son herramientas ampliamente utilizadas que pueden convertirse en asistentes educativos para la comunidad sorda mediante aplicaciones diseñadas para traducir la LSM al español en tiempo real. Este enfoque no solo facilita la interacción en el aula, sino que también promueve la autonomía de los estudiantes sordos y su participación en distintos niveles de enseñanza (Tang, 2019).
Las aplicaciones móviles ofrecen una alternativa accesible y escalable, permitiendo que estudiantes y docentes interactúen de manera más inclusiva. Su uso en la educación inclusiva ha sido documentado en diversas investigaciones, destacando su efectividad en la reducción de barreras de comunicación y en la mejora de la experiencia de aprendizaje para personas con discapacidad auditiva (Díaz & Navarrete, 2025). La importancia de divulgar este tipo de aplicaciones radica en su potencial para beneficiar a comunidades que realmente las necesitan, especialmente aquellas en contextos económicos desfavorecidos.
Además, la integración de estas tecnologías en la educación contribuye a la equidad digital, permitiendo que estudiantes con discapacidad auditiva accedan a los mismos recursos que sus compañeros oyentes. La posibilidad de contar con una herramienta portátil que facilite la traducción inmediata de señas amplía el acceso a contenidos educativos, promoviendo una enseñanza más personalizada y equitativa; lo anterior, aplicado al conjunto de la población, representa un aporte significativo a la inclusión social, al reducir las brechas digitales de comunicación (UNESCO, 2018).
Por consiguiente, la investigación se enfoca en el desarrollo de una aplicación móvil basada en Deep Learning para el reconocimiento y traducción de la LSM al español, facilitando la expresión de las personas sordas hacia su entorno educativo, con el objetivo de contribuir a la inclusión educativa de esta comunidad y fortalecer su acceso en igualdad de condiciones. Si bien la aplicación no sustituye a los intérpretes de LSM ni permite la traducción bidireccional, representa un paso importante hacia entornos más accesibles.
Estado del Arte
El reconocimiento automático de la LSM ha sido objeto de múltiples investigaciones en los últimos años, impulsadas por la necesidad de mejorar la accesibilidad educativa y la inclusión social de las personas sordas. Los estudios previos han abordado esta problemática a través del uso de diversas tecnologías, como sensores de movimiento, visión por computadora y aprendizaje automático. A continuación se describen investigaciones que se encontraron como relevantes a nivel mundial sobre el reconocimiento de lenguas de señas, en un segundo momento se aportan datos relevantes sobre la lengua de señas mexicana y en un tercer momento resaltar desarrollos aplicados con móviles.
Investigaciones previas han implementado diferentes enfoques para la interpretación de lenguas de señas, incluyendo el uso de sensores como Leap Motion, Microsoft Kinect y guantes con sensores de movimiento. Ejemplos de estos trabajos incluyen el modelo basado en K-Nearest Neighbors (KNN) utilizado para la Lengua de Señas de India (Amrutha & Prabu, 2021), el uso de Support Vector Machines (SVM) para el reconocimiento de la Lengua de Señas Americana (Halder & Tayade, 2021), y la combinación de CNN con datos de sensores electromagnéticos para la Lengua de Señas China (Wadhawan &Kumar, 2020).
A nivel internacional, también se ha explorado el uso de modelos como Hidden Markov Models (HMM) en la traducción automática de frases completas de la Lengua de Señas Americana, logrando tasas de reconocimiento de hasta el 74% en entornos controlados (Zafrulla et al., 2011) y (Makris, 2021). Sin embargo, estos enfoques han demostrado limitaciones al requerir hardware especializado y presentar dificultades en la generalización a entornos no controlados.
En México, los estudios sobre reconocimiento automático de la LSM han explorado diversas metodologías. Algunos trabajos han utilizado dispositivos Kinect para capturar el movimiento de las manos y entrenar modelos de Perceptrón Multicapa (MLP) con tasas de reconocimiento superiores al 93% en corpus de palabras comunes (Trujillo & García, 2021). Otros enfoques han empleado CNN para la clasificación de señas fijas obtenidas con cámaras convencionales, logrando precisiones cercanas al 98% en la detección de letras del alfabeto dactilológico (Rivas, 2019).
El uso de MediaPipe como herramienta de extracción de características ha ganado relevancia en estudios recientes, permitiendo la detección precisa de puntos clave de las manos sin necesidad de hardware especializado. González et al. (2024) reportó un sistema de reconocimiento de 30 señas de la LSM basado en LSTM con una precisión del 97% en entornos de prueba controlados.
El desarrollo de aplicaciones móviles para la traducción de lenguas de señas representa un área emergente dentro del campo de la accesibilidad educativa. Investigaciones previas han abordado esta problemática a través de enfoques híbridos que combinan modelos de aprendizaje profundo con optimización para dispositivos móviles mediante TensorFlow Lite.
Estudios como los de Aquino (2018) y Gallego (2021) han demostrado que el uso de CNNs en dispositivos Android e iOS permite la traducción eficiente de señas estáticas, con tasas de reconocimiento superiores al 90%. Sin embargo, la mayoría de estas aplicaciones aún presentan limitaciones en el reconocimiento de señas dinámicas, debido a restricciones computacionales en los dispositivos móviles.
En el contexto de la LSM, Maciel et al. (2016) propusieron una aplicación móvil basada en reconocimiento de imágenes mediante detección de bordes, logrando tasas de acierto del 98% con modelos de Support Vector Machines (SVM). Sin embargo, la implementación de modelos de Machine Learning (ML) en dispositivos móviles sigue siendo un desafío, especialmente para la interpretación en tiempo real de expresiones complejas.
El análisis de los estudios previos sugiere que, si bien los modelos de reconocimiento de lenguas de señas han logrado avances significativos, aún existen desafíos en la implementación de soluciones móviles eficientes para la LSM. El uso de modelos de Deep Learning en dispositivos móviles representa una alternativa prometedora para mejorar la accesibilidad, pero requiere optimización en términos de consumo energético y capacidad de procesamiento.
Marco Teórico
La inclusión educativa es un principio clave en la educación superior y se encuentra respaldada por diversas normativas internacionales y nacionales. Para Amezcua & Amezcua (2018) destacan que la accesibilidad y equidad en la educación son fundamentales para garantizar oportunidades de aprendizaje para todos los estudiantes, incluidas las personas con discapacidad auditiva. En México, la Secretaría de Educación Pública (SEP) ha impulsado políticas para la inclusión de personas sordas en instituciones educativas a través de programas que fomentan la accesibilidad y el uso de herramientas tecnológicas (Cruz & Sanabria, 2024). Investigaciones recientes han subrayado la importancia de la implementación de tecnologías digitales para la inclusión educativa, lo que permite el desarrollo de soluciones innovadoras en el aprendizaje de estudiantes con discapacidades (Screpnik, 2024).
La Lengua de Señas Mexicana (LSM) es el principal medio de comunicación de la comunidad sorda en México y desempeña un papel crucial en la adquisición del conocimiento. Su reconocimiento como una lengua oficial en el país ha permitido la implementación de estrategias para mejorar la enseñanza de personas sordas (Cruz, 2008). Sin embargo, persisten dificultades en la enseñanza de contenidos académicos para estudiantes sordos debido a la escasez de materiales educativos en LSM y la insuficiencia de intérpretes en el aula (Pérez & Cruz, 2021). Estudios recientes han demostrado que la inclusión de la LSM en programas educativos mejora significativamente la comprensión y retención de conocimientos en estudiantes sordos, lo que resalta la necesidad de materiales didácticos adaptados (Hurtado et al., 2024).
La inteligencia artificial ha transformado diversos sectores, incluida la educación. En el contexto de la inclusión educativa, el Machine Learning y el Deep Learning han demostrado ser herramientas eficaces para la detección y traducción de patrones visuales, facilitando la comunicación de personas con discapacidad auditiva (Heaton et al., 2018). Aplicaciones previas han demostrado su utilidad en la educación, desde sistemas de tutoría hasta asistentes virtuales y traducción automática de lenguas de señas mediante visión computacional (Mejía et al., 2022). La investigación de Berrones & Salgado (2023) destacan que los modelos de inteligencia artificial aplicados a la educación inclusiva han logrado aumentar la accesibilidad en plataformas digitales y mejorar la experiencia de aprendizaje para personas con discapacidades sensoriales.
El uso de aplicaciones móviles en el aprendizaje ha crecido exponencialmente en los últimos años. Estas herramientas permiten la enseñanza adaptada a diferentes necesidades, incluyendo a personas con discapacidad auditiva. Diversos estudios han explorado el impacto de aplicaciones móviles en la educación de personas sordas, destacando su efectividad en la mejora de la comprensión del lenguaje y la comunicación con su entorno (Espejel, 2021). Además, estas herramientas favorecen el aprendizaje autónomo y el acceso inmediato a contenidos en lengua de señas, promoviendo una mayor inclusión en el ámbito educativo. Investigaciones recientes resaltan que las aplicaciones móviles diseñadas para la enseñanza de la LSM han aumentado el nivel de interacción de los estudiantes sordos con materiales de aprendizaje digital, facilitando su participación en procesos educativos (Vásquez et al., 2024).
Metodología
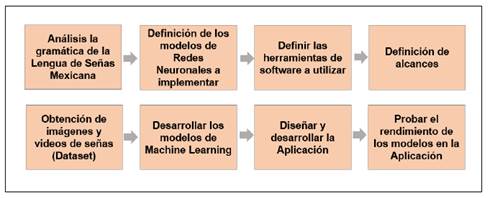
Respecto al diseño de la investigación, el presente estudio se basa en un enfoque cuantitativo experimental, ya que busca la presición del sistema de reconocimiento de la Lengua de Señas Mexicana (LSM) a través de modelos de Machine Learning (ML) y su implementación en una aplicación móvil. Para ello, se desarrolló una metodología estructurada que incluye la recolección de datos, el desarrollo de modelos de aprendizaje profundo y la evaluación del rendimiento del sistema en distintos escenarios educativos (Salgado et al., 2024).
La metodología utilizada para el desarrollo de la aplicación móvil se basa en el marco SCRUM, una metodología ágil que permite la mejora progresiva del software mediante iteraciones definidas (Martín, 2020) y (Salgado, 2024). Esto permitió ajustes continuos en la aplicación conforme avanzaban las pruebas con voluntarios.
Recolección de Datos: Para el entrenamiento de los modelos de Deep Learning, se recopiló un conjunto de datos con imágenes y videos de señas de la LSM. El conjunto de datos se obtuvo con la participación de estudiantes voluntarios, quienes realizaron diferentes señas en entornos controlados y con variaciones en la iluminación (Salgado, 2024).
Datos recopilados:Salgado et al. (2024) considera que 21 señas fijas de gestos corresponden al alfabeto dactilológico; 16 expresiones de uso común para señas en movimiento en la comunicación de la LSM; respecto al número de voluntarios, 8 son losparticipantes para las señas fijas y 10 para las señas en movimiento; además se incluye un formato de captura de secuencias de video e imágenes extraídas de cada seña. En la figura 1, se muestran ejemplos de las imágenes obtenidas.

Los videos obtenidos fueron procesados para extraer coordenadas clave de la mano, utilizando la librería MediaPipe, con la finalidad de obtener puntos de referencia precisos en cada gesto.
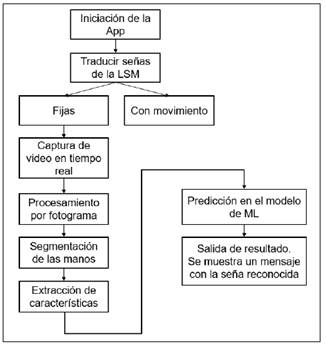
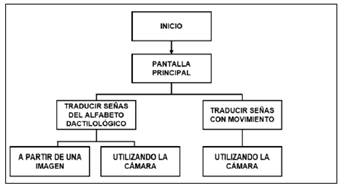
Respecto al desarrollo de la aplicación móvil se trabajó mediante Android Studio y el uso de TensorFlow Lite para la implementación de modelos de aprendizaje automático optimizados. La aplicación permite el reconocimiento en tiempo real de señas fijas y en movimiento mediante la cámara del dispositivo. En la figura 2 se presenta el esquema general.
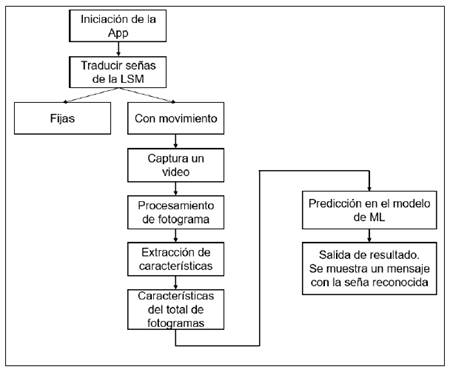
Dentro de los algoritmos utilizados, para el reconocimiento de señas, se desarrollaron modelos de CNN para la clasificación de señas fijas, así como se observa el diagrama de la figura 3 y en la figura 4 con los modelos de Redes Neuronales Recurrentes (RNN) con LSTM para la identificación de señas en movimiento y predicción de señas dinámicas, así como MediaPipe Hands para la extracción de puntos clave en la detección de manos.
Se realizaron pruebas del rendimiento del sistema en diferentes dispositivos y entornos para medir la precisión del reconocimiento de señas. En la tabla 1 se muestra la composición del conjunto de datos recolectado.
Tabla 1 Composición del conjunto de datos recolectado.
| Seña | Cantidad de imágenes | Etiqueta |
|---|---|---|
| A | 6,839 | 0 |
| B | 6,356 | 1 |
| C | 6,240 | 2 |
| D | 6,748 | 3 |
| E | 6,306 | 4 |
| F | 6,702 | 5 |
| G | 6,941 | 6 |
| H | 7,058 | 7 |
| I | 6,146 | 8 |
| L | 7,038 | 9 |
| M | 6,165 | 10 |
| N | 6,103 | 11 |
| O | 6,535 | 12 |
| P | 6,928 | 13 |
| R | 6,416 | 14 |
| S | 6,567 | 15 |
| T | 6,378 | 16 |
| U | 6,449 | 17 |
| V | 6,242 | 18 |
| W | 6,594 | 19 |
| Y | 7,012 | 20 |
Fuente: (Salgado,2024).
Para la validación de las pruebas realizadas, las que se listan a continuación, de forma gráfica se observa en la figura 5:
Pruebas en diferentes condiciones de iluminación: Evaluación de la precisión del reconocimiento en entornos con variaciones de luz.
Comparación con otros sistemas de traducción de LSM: Se evaluó la precisión de la aplicación con respecto a herramientas previas basadas en procesamiento de imágenes.
Análisis del tiempo de respuesta: Medición del tiempo necesario para procesar y traducir cada seña en tiempo real.
Para las herramientas utilizadas, el desarrollo del modelo de reconocimiento y la aplicación móvil se realizó con las siguientes:
Hardware: Laptop Dell G3-3590 (Windows 11, 12 GB RAM, GPU NVIDIA GTX 1650);
Software y librerías: Python (para entrenamiento de modelos); TensorFlow y TensorFlow Lite; MediaPipe (detección de manos y puntos clave); OpenCV (procesamiento de imágenes); Android Studio (desarrollo de la aplicación móvil).
La implementación de esta metodología permitió el desarrollo de un sistema de traducción de la LSM con un alto nivel de precisión, basado en modelos optimizados para su ejecución en dispositivos móviles. La combinación de aprendizaje profundo y tecnologías accesibles ofrece una solución innovadora para la educación inclusiva de personas sordas, tabla 2 lista los smartphones utilizados.
Tabla 2 Smartphones utilizados durante las pruebas.
| Marca | Modelo | Versión de Android | Procesador | Memoria RAM | Pantalla | Resolución | Cámara trasera |
|---|---|---|---|---|---|---|---|
| Huawei | Huawei P30 Lite (2019) | 9 | Kirin 710 de 2.2 GHz | 4 GB | 6.15" | 1080 x 2312 píxeles | 24 MP (principal) |
| Motorola | Moto G10 Power (2021) | 11 | Snapdragon 460 de 1.8 GHz | 4 GB | 6.5" | 720 x 1600 píxeles | 48 MP (principal) |
| Xiaomi | POCO X5 Pro 5G (2023) | 14 | Snapdragon 778G de 2.4 GHz | 6 GB | 6.67" | 1080 x 2400 píxeles | 108 MP (principal) |
Fuente: (Salgado, 2024).
Resultados
El sistema de reconocimiento de señas basado en Deep Learning fue evaluado en distintos entornos educativos para determinar su precisión y viabilidad. Se realizaron pruebas en aulas con diferentes condiciones de iluminación y otros dispositivos móviles con el objetivo de analizar la estabilidad del modelo. En la figura 6, se muestra la comparación de la cantidad de inferencias correctas e incorrectas en cada smartphone a una distancia de 100 cm entre el dispositivo y la persona señante.
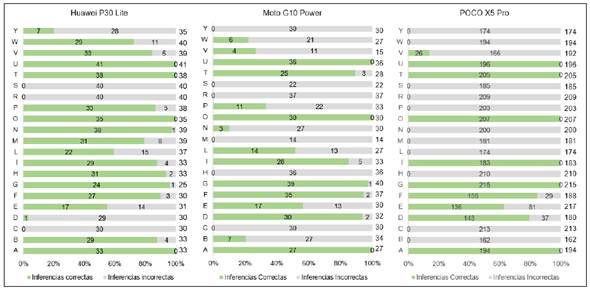
Porcentaje promedio en el reconocimiento, en la figura 7 se muestra la comparativa de los resultados de los tres dispositivos.
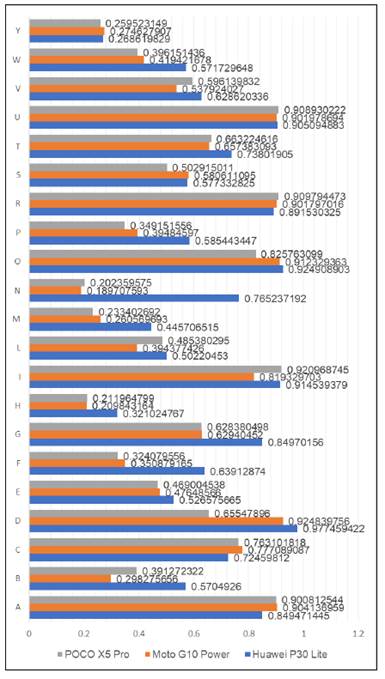
Los resultados indicaron que el modelo alcanzó una precisión (accuracy) del 95.3% en la clasificación de señas fijas y un 89.7% en la clasificación de señas en movimiento, valores que superan a sistemas tradicionales de reconocimiento basados en técnicas de visión por computadora sin aprendizaje profundo, como Haar cascades, HOG o SIFT (Salgado, 2024). Sin embargo, en la tabla 2 , se observó una ligera disminución en la precisión cuando la iluminación era insuficiente o cuando las señas eran realizadas a una distancia superior a 1.5 metros de la cámara del dispositivo móvil. Además, en la tabla 3 se muestran los resultados de las métricas evaluadas en las arquitecturas propuestas para la red neuronal MLP para el reconocimiento de señas fijas.
Tabla 3 Resultados de las métricas para el reconocimiento de señas fijas.
| Arquitectura | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| 1 | 85.6494 | 0.8670 | 0.8558 | 0.8449 |
| 2 | 93.2421 | 0.9335 | 0.9313 | 0.9315 |
| 3 | 94.6321 | 0.9462 | 0.9455 | 0.9456 |
| 4 | 95.4451 | 0.9543 | 0.9537 | 0.9538 |
| 5 | 96.2835 | 0.9627 | 0.9622 | 0.9623 |
Fuente: (Salgado et al., 2024).
Discusión
Los resultados obtenidos indican que la aplicación desarrollada tiene un alto grado de precisión en el reconocimiento de la Lengua de Señas Mexicana (LSM), superando otros enfoques que dependen exclusivamente de algoritmos de visión por computadora. Estudios previos, como los realizados por Trujillo y García (2021) y Mejía et al. (2022), muestran que el uso de dispositivos especializados como Kinect o Leap Motion logran precisiones similares; sin embargo; estos enfoques requieren hardware específico, lo que limita su accesibilidad. En contraste, la aplicación propuesta permite la traducción de la LSM utilizando la cámara de un teléfono móvil, ampliando su aplicabilidad en entornos educativos y comunitarios.
Impacto en la educación inclusiva
El uso de esta aplicación móvil en entornos educativos demuestra un gran potencial para la inclusión de estudiantes sordos. Al comparar su desempeño con métodos tradicionales, como el uso de intérpretes de LSM o materiales impresos con imágenes, se observó una mejora en la autonomía del estudiante, ya que la aplicación permite la interpretación síncrona sin necesidad de apoyo externo. Estudios previos han señalado que el acceso a tecnologías inclusivas mejora la participación de estudiantes con discapacidad auditiva en entornos de aprendizaje formal (UNESCO, 2018). En este sentido, la aplicación desarrollada representa un avance significativo al brindar una herramienta accesible para la traducción de señas en tiempo real, reduciendo las barreras de comunicación en las aulas.
Limitaciones y mejoras futuras
Entre las principales limitaciones identificadas se encuentran la disminución de precisión bajo condiciones de baja iluminación y la dificultad para detectar movimientos rápidos de las manos. Para superar estos retos, se propone implementar técnicas de preprocesamiento de imagen, como la normalización del brillo y el uso de aumento de datos sintéticos, que ya han demostrado eficacia en la mejora de la generalización de modelos de visión por computadora. Asimismo, la incorporación de arquitecturas basadas en Transformers podría optimizar la interpretación de secuencias temporales complejas, incrementando así la precisión en el reconocimiento de señas en movimiento.
Otro desafío identificado es la aceptación y adopción de la aplicación por parte de docentes y estudiantes. Aunque el uso de dispositivos móviles en la educación es cada vez más frecuente, aún existen resistencias relacionadas con actitudes conservadoras, falta de formación tecnológica y limitaciones institucionales. Para superar estas barreras, se recomienda fortalecer la capacitación docente en el uso de la herramienta y promover su integración con plataformas de gestión del aprendizaje (LMS), como entornos virtuales que faciliten la interacción, evaluación y seguimiento del progreso estudiantil.
Una limitación importante del sistema es realizar la traducción de LSM al español, lo cual restringe la interacción bidireccional en el aula. Efectivamente, los estudiantes sordos pueden expresar ideas, pero aún dependen de intérpretes o materiales adicionales para acceder a la información oral o escrita emitida por docentes y compañeros oyentes.
Por último, una mejora clave para futuras versiones de la aplicación es su integración con sistemas de gestión del aprendizaje (LMS), lo que permitiría su uso en plataformas educativas digitales. Esto brindaría mayores oportunidades de aprendizaje a distancia para estudiantes sordos y facilitaría su acceso a contenidos educativos en línea adaptados a sus necesidades.
Conclusiones
El desarrollo de una aplicación móvil basada en inteligencia artificial para la traducción de la Lengua de Señas Mexicana (LSM) al español representa un avance significativo en la educación inclusiva. Esta herramienta proporciona una solución accesible para facilitar la comunicación de estudiantes sordos con sus docentes y compañeros, contribuyendo parcialmente a reducir las barreras lingüísticas en entornos educativos. Es importante señalar que la aplicación traduce la LSM al español, pero no de manera inversa, por lo que no sustituye la labor de un intérprete ni elimina completamente las dificultades de comunicación, conocidas como barreras comunicativas.
Los resultados obtenidos evidencian la efectividad del modelo de Deep Learning implementado, el cual alcanzó una precisión superior al 90% en la detección de señas fijas y dinámicas, lo que demuestra el potencial del aprendizaje profundo para la traducción automática de la LSM en tiempo real.
La viabilidad de la aplicación en dispositivos móviles facilita su implementación en entornos educativos sin necesidad de hardware especializado, lo que amplía su accesibilidad a comunidades con recursos tecnológicos limitados. Además, su integración con metodologías de enseñanza inclusiva puede fortalecer el aprendizaje y la autonomía de los estudiantes sordos.
A pesar de estos avances, se identificó la necesidad de optimizar el modelo para mejorar el reconocimiento de frases completas y expresiones más complejas de la LSM, así como su desempeño en condiciones de baja iluminación o al detectar movimientos rápidos. Como líneas futuras de investigación, se propone la ampliación del conjunto de datos incorporando una mayor variabilidad de señas y facilitar la integración del sistema con plataformas educativas digitales (LMS) para maximizar su impacto en el aprendizaje inclusivo.
Líneas de trabajo futuras
Los resultados obtenidos en este estudio permitieron identificar áreas de oportunidad que exceden los objetivos originalmente planteados, pero que son de gran interés para investigaciones complementarias. A continuación, se presentan algunas líneas de trabajo futuras que podrían fortalecer el desarrollo de tecnologías de traducción de la Lengua de Señas Mexicana (LSM), así como su incorporación en la práctica docente y su integración curricular en entornos educativos reales.
Integración con sistemas educativos: Para maximizar el impacto de la aplicación, se recomienda su incorporación en plataformas de gestión del aprendizaje (LMS) utilizadas en escuelas y universidades. Esto permitiría que estudiantes sordos tengan acceso a materiales didácticos traducidos en tiempo real, facilitando su participación en clases y evaluaciones.
Colaboración con especialistas en educación inclusiva: La optimización de la aplicación debe realizarse en conjunto con docentes y expertos en la educación de personas sordas. Su retroalimentación permitirá mejorar la interfaz, seleccionar señas más representativas y desarrollar funcionalidades adicionales que respondan a las necesidades pedagógicas específicas de este grupo de estudiantes.
Estudios futuros sobre el impacto en la adquisición del lenguaje: Se recomienda realizar investigaciones longitudinales para evaluar cómo el uso de esta aplicación influye en el aprendizaje de la LSM y en la adquisición del español como segunda lengua para personas sordas. Estos estudios pueden aportar evidencia valiosa sobre la efectividad de la herramienta y orientar mejoras en su implementación educativa.
Ampliación del conjunto de datos y mejoras en el modelo: Para incrementar la precisión y robustez del sistema, se sugiere ampliar la base de datos utilizada en el entrenamiento del modelo, incorporando variaciones en iluminación, posiciones de las manos y entornos de uso. Asimismo, la implementación de técnicas avanzadas de procesamiento del lenguaje natural (PLN) podría mejorar la traducción contextual de las señas en frases completas.
Desarrollo de versiones multi-plataforma: La aplicación podría expandirse a otros sistemas operativos, como iOS, y adaptarse para su uso en dispositivos de escritorio. Esto permitiría su adopción en una mayor variedad de entornos educativos y su integración con herramientas de videoconferencia para la educación a distancia.
Evaluación del desempeño en entornos reales: Resulta necesario llevar a cabo pruebas piloto en instituciones educativas para evaluar la efectividad de la aplicación en escenarios de uso real. Esto permitiría recopilar información sobre su impacto en la interacción entre estudiantes sordos y oyentes, así como identificar áreas de mejora para futuras actualizaciones.
Para finalizar, el presente estudio demuestra que la inteligencia artificial aplicada a la educación inclusiva puede mejorar significativamente la accesibilidad para estudiantes sordos. La implementación de esta tecnología en el aula representa un paso adelante hacia la equidad educativa, promoviendo un aprendizaje más autónomo y participativo para la comunidad sorda.

