











 texto en
texto en  Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introducción
La asimilación de datos para la estimación de estados es esencial en las aplicaciones de pronóstico en hidrología (Liu et al., 2012), pues mediante la actualización cíclica que llevan a cabo es posible disminuir los errores que se acumulan en los modelos (Clark et al., 2008; Maxwell, Jackson, & McGregor, 2018). El filtro de Kalman de conjuntos (EnKF) (Evensen, 1994) es uno de los algoritmos ampliamente utilizado como método recursivo en hidrología (Liu & Gupta, 2007; Maxwell et al., 2018; Sun, Seidou, Nistor, & Liu, 2016) es una extensión del filtro de Kalman discreto (Kalman, 1960) para tratar sistemas dinámicos no lineales (Evensen, 1994; Evensen, 2003), y se ha utilizado, entre otros, para el pronóstico de caudales (Maxwell et al., 2018), evapotranspiración (Zou, Zhan, Xia, Wang, & Gippel, 2017) y humedad del suelo (Brandhorst, Erdal, & Neuweiler, 2017; Meng, Xie, & Liang, 2017), además se ha integrado con modelos hidrológicos distribuidos como TopNet, Hydrotel y MGB-IPH (Abaza, Anctil, Fortin, & Turcotte, 2015; Clark et al., 2008; Quiroz, Collischonn, & Paiva, 2019).
En los sistemas de cuenca hidrográfica se puede identificar la relación entre los caudales medidos en diferentes posiciones y un punto de interés, a lo que se denomina función de respuesta (Valdés, Mejía, & Rodríguez-Iturbe, 1980). Con base en esta relación se pueden hacer pronósticos a corto plazo que se actualizan constantemente y de forma indefinida mientras el fenómeno bajo estudio persista.
En este trabajo se evalúa la capacidad de pronosticar del filtro de Kalman discreto (DKF) (Kalman, 1960), el filtro de Kalman de conjuntos (EnKF) (Evensen, 1994) y la integración del filtro de Kalman discreto (DKF) con el filtro de Kalman de conjuntos (EnKF) para el pronóstico de uno hasta seis pasos hacia delante de los caudales del río Huaynamota en la estación Chapalagana. El DKF es implementado para estimar el vector de estado (Hidrograma Unitario Instantáneo, HUI) y el EnKF hace estimaciones escalares de caudal. La integración se hace mediante la ecuación de estados del EnKF.
Materiales y métodos
El área de estudio corresponde a la delimitación aguas arriba a partir de la estación Chapalagana sobre el río Huaynamota (río Chapalagana o río Atengo), se ubica al noroeste de la república mexicana y se comparte entre los estados de Durango, Nayarit, Zacatecas y Jalisco (INEGI, 2010) (Figura 1); geográficamente se ubica entre los -104° 33’ 34.16” y los -103° 27’ 29.84” de longitud, y entre los 23° 28’ 50.05” y los 21° 23’ 57.62” de latitud; tiene un área de 12 075.7 km2; la altitud máxima es de 3 147 msnm (metros sobre el nivel del mar) y la mínima en la estación Chapalagana es de 219 msnm; el tiempo de concentración es de 39.88 horas; la precipitación media anual es de 707 mm y la temperatura media anual de 17.9 °C (SMN, 2019).
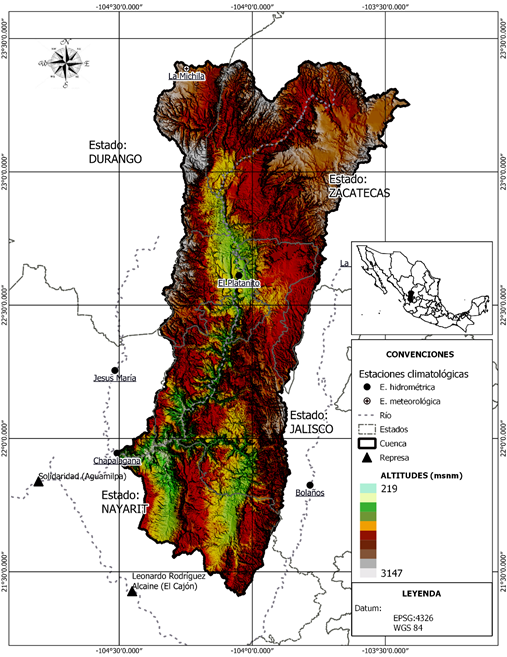
La principal estructura hidráulica con fines de generación de electricidad que se encuentra aguas abajo del área de estudio y sobre el río Lerma-Santiago Pacífico es la represa Solidaridad, comúnmente conocida como Aguamilpa, ubicada en los -104° 48’ 10.55” de longitud y los 21° 50’ 22.74” de latitud, con una capacidad de 5 540 millones de m3, para generar 960 MW de electricidad (Conagua, 2008). La presa Aguamilpa se encuentra a unos 90 km del océano Pacífico, donde el río Santiago desemboca frente a las costas del estado de Nayarit.
Se evaluó la capacidad predictiva del algoritmo del filtro de Kalman discreto (DKF) (Kalman, 1960); el filtro de Kalman de conjuntos (EnKF) (Evensen, 1994); la integración del DKF y EnKF (DKF-EnKF), y el modelo autorregresivo con variable exógena de primer orden (AR(1,1)), para realizar el pronóstico a 1, 2, 3, 4, 5 y 6 horas (pasos
La implementación del DKF, EnKF, DKF-EnKF y ARX(1,1) se hizo mediante rutinas en R (R Core Team, 2020), que generan los pronósticos a seis pasos con DKF y ARX, y con 36 combinaciones entre pasos por tamaños de conjunto en EnKF y DKF-EnKF. El DKF se implementó para estimar el vector de estado que equivale a la función de respuesta de la cuenca o hidrograma unitario instantáneo (HUI) (Valdés et al., 1980) y el EnKF realiza estimaciones escalares del caudal (Evensen, 2009), es decir, con el DKF se estiman los valores correspondientes a las columnas del HUI que se pasan a multiplicar por los valores de caudal; por su parte, el EnKF estima directamente valores de caudal. En los tres casos con filtros se consideraron las últimas observaciones de cada variable, es decir, un retraso autorregresivo (Valdés et al., 1980). El modelo ARX se implementó de forma recursiva con base en una fracción de serie con 100 registros.
La cantidad adecuada de miembros en los conjuntos de EnKF y DKF-EnKF se determinó mediante análisis de sensibilidad, con base en la raíz del cuadrado medio del error (RMSE) (Quiroz et al., 2019). La generación del ruido blanco (simulación de Monte Carlo) se hizo con el paquete mvtnorm (normal multivariante y distribución t) (Genz & Bretz, 2009). En los tres algoritmos evaluados, la varianza Q se supone constante (Simon, 2001) de valor cero (Morales-Velázquez, Aparicio, & Valdes, 2014) y R con valor cercano a cero (0.01) para dar flexibilidad a la convergencia del algoritmo (Welch & Bishop, 2006).
El ajuste de las series pronosticadas se evaluó mediante el coeficiente de Nash-Sutcliffe (Nash & Sutcliffe, 1970) y la raíz del cuadrado medio del error (RMSE) (Morales-Velázquez et al., 2014). Los supuestos de normalidad de errores del filtro de Kalman se verificaron mediante gráficos comparados con la curva normal estandarizada (González-Leiva, Ibáñez-Castillo, Valdés, Vázquez-Peña, & Ruiz-García, 2015). Los valores atípicos y su ubicación se determinó con base en los residuales estandarizados (Cryer & Chan, 2008).
Filtro de Kalman discreto
Es un algoritmo que permite la identificación de sistemas dinámicos lineales como un estimador óptimo de estados mediante un proceso recursivo (Kalman, 1960) (Figura 2). El DKF sirve de base para los algoritmos que tratan sistemas no lineales (Welch & Bishop, 2006).
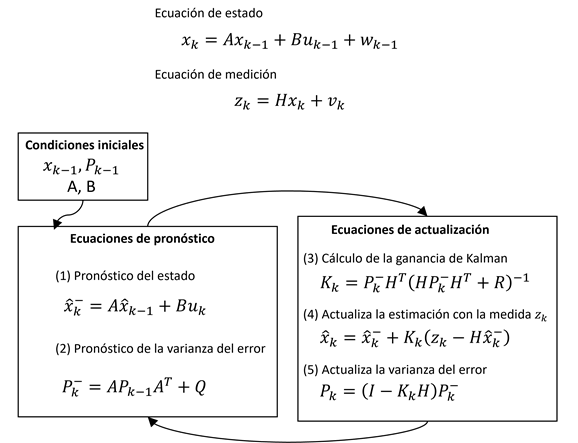
La ecuación de estado tiene como entrada dos series horarias (
La nueva medición para el tiempo
Con las ecuaciones de estado y medición, el algoritmo inicia un ciclo que se repite de forma indefinida. En el tiempo
Filtro de Kalman de conjuntos
El filtro de Kalman de conjuntos (EnKF) es un estimador subóptimo, que se basa en simulaciones de Monte Carlo para la estimación del error estadístico (Evensen, 1994; Gillijns et al., 2006; Rafieeinasab, Seo, Lee, & Kim, 2014). Se supone distribución normal de los errores y las estimaciones se hacen con base en conjuntos que agrupan
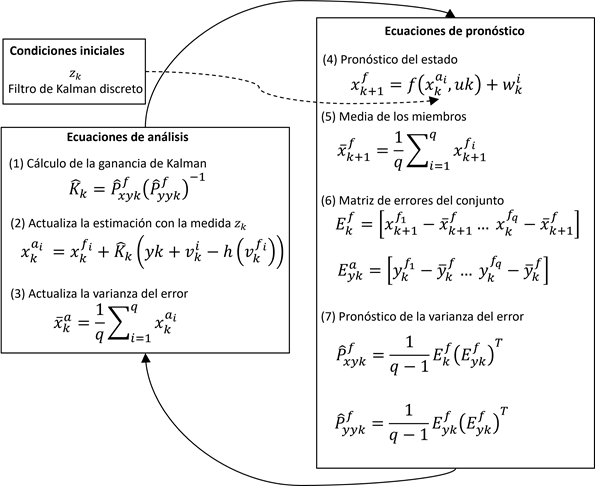
Los errores
El ruido en las mediciones se genera agregando a la medición en el tiempo
El vector
Filtro de Kalman discreto y filtro de Kalman de conjuntos
La integración del DKF y EnKF se hizo mediante la ecuación de estado del algoritmo del EnKF. El DKF genera un pronóstico para el tiempo
Modelo autorregresivo de primer orden (ARX(1,1)) y DKF
El modelo autorregresivo de primer orden, también conocido como modelo de Markov, es una de las primeras aproximaciones para el estudio de series de tiempo y se basa en la autocorrelación que se presenta dentro de la misma serie de datos (Box, Jenkins, Reinsel, & Ljung, 2016; Bras & Rodríguez-Iturbe, 1985). Algebraicamente se describe de la siguiente forma:
Donde
Resultados y discusión
En total se evaluaron 36 combinaciones resultado de seis pasos (
En la Figura 4 se muestra el análisis de sensibilidad que permite identificar el tamaño adecuado de los conjuntos para los algoritmos de EnKF (línea punteada) y DKF-EnKF (línea continua), mediante la relación entre el valor de RMSE a medida que aumenta la cantidad de miembros por conjunto. El conjunto con cinco miembros presenta el RMSE más alto en cada uno de los pasos
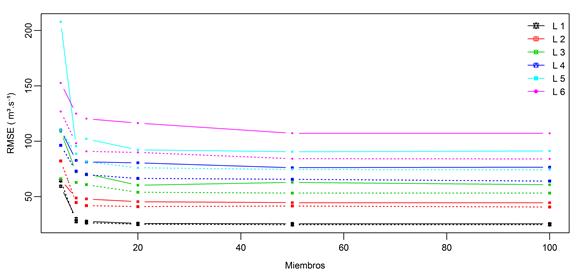
La importancia de la definición de la cantidad adecuada de miembros radica en obtener el mejor ajuste posible sin agregar carga computacional que no mejore el comportamiento del algoritmo. Cuando se tienen conjuntos grandes, la carga computacional es alta; por el contrario, si se usan conjuntos pequeños se puede perder ajuste entre la serie observada y la pronosticada (Gillijns et al., 2006; Quiroz et al., 2019).
Los resultados que se presentan son con base en 20 miembros por cada conjunto. En la Tabla 1 se tienen los indicadores estadísticos de ajuste de la serie observada contra las series pronosticadas.
Tabla 1. Resumen de estadísticos para la aplicación de DKF, EnKF, DKF-EnKF y ARX-DKF.
| Índice | L1 | L2 | L3 | L4 | L5 | L6 | DEp | |
|---|---|---|---|---|---|---|---|---|
| DKF | RMSE | 24.76 | 39.55 | 50.46 | 59.21 | 67.20 | 74.49 | 18.36 |
| Nash-Sutcliffe | 0.9869 | 0.9666 | 0.9457 | 0.9252 | 0.9037 | 0.8816 | 0.0393 | |
| Media | 161.55 | 161.71 | 161.39 | 161.57 | 160.74 | 160.67 | 0.45 | |
| DEs | 217.58 | 216.33 | 213.69 | 212.47 | 209.96 | 208.30 | 3.58 | |
| EnKF | RMSE | 25.08 | 41.00 | 53.99 | 66.40 | 76.04 | 89.93 | 23.67 |
| Nash-Sutcliffe | 0.9866 | 0.9641 | 0.9378 | 0.9060 | 0.8767 | 0.8275 | 0.0587 | |
| Media | 160.65 | 160.55 | 160.88 | 160.15 | 160.93 | 161.27 | 0.38 | |
| DEs | 216.48 | 215.81 | 217.25 | 216.67 | 218.17 | 219.18 | 1.23 | |
| DKF-EnKF | RMSE | 25.83 | 45.45 | 60.29 | 80.57 | 92.24 | 116.41 | 32.89 |
| Nash-Sutcliffe | 0.9858 | 0.9559 | 0.9225 | 0.8616 | 0.8185 | 0.7110 | 0.1013 | |
| Media | 160.28 | 159.51 | 159.78 | 160.34 | 161.64 | 162.09 | 1.03 | |
| DEs | 216.21 | 217.95 | 219.67 | 226.07 | 229.10 | 239.75 | 8.84 | |
| ARX-DKF | RMSE | 26.07 | 44.11 | 59.70 | 72.60 | 83.23 | 91.65 | 24.71 |
| Nash-Sutcliffe | 0.9855 | 0.9586 | 0.9243 | 0.8882 | 0.8532 | 0.8222 | 0.0625 | |
| Media | 163.32 | 165.27 | 166.79 | 168.01 | 169.71 | 170.52 | 2.72 | |
| DEs | 219.90 | 222.08 | 224.70 | 226.56 | 228.20 | 228.34 | 3.42 |
La implementación del modelo ARX(1,1) y el modelo ARX-DKF con actualización recursiva obtienen similares resultados debido a que los parámetros de ARX se multiplican por los valores de caudal en el tiempo
Para el paso
De acuerdo con el resumen estadístico de la Tabla 1, la media y la desviación estándar en los seis pasos tienden a sobreestimarse con diferentes magnitudes respecto a la serie observada. La mayor estabilidad de la media la tiene el algoritmo de EnKF con desviación estándar (DEp) de 0.38, con leve diferencia con DKF, que tiene desviación de 0.45 entre los seis pasos, mientras que ARX-DKF y DKF-EnKF tienen mayor desviación estándar de 1.03 y 2.72, respectivamente. Por otra parte, la dispersión representada por la desviación estándar entre las series pronosticadas (DEp) confirma que EnKF guarda mayor similitud con la serie observada en los seis pasos. El aparente mejor ajuste de los pronósticos de EnKF se debe al efecto de desplazamiento respecto a la observada sin mayor cambio en los picos máximos o mínimos de tal manera que no hay efecto notable en la media y desviación estándar.
Las diferencias entre los pronósticos generados se hacen notables de forma gráfica, y para una comparación detallada en la Figura 5 y Figura 6 se presentan dos avenidas a diferentes pasos.
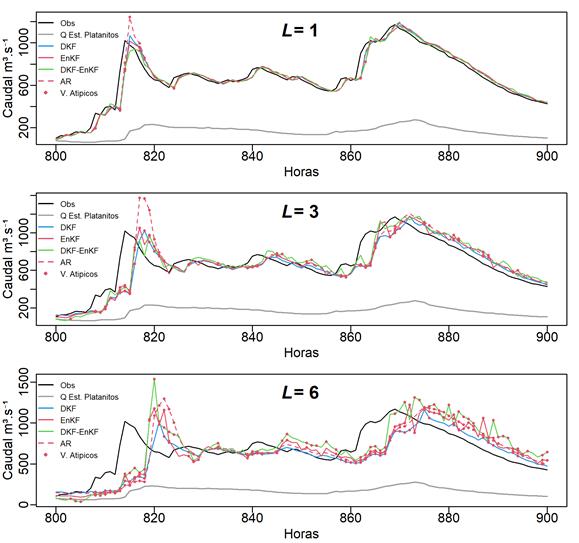
Figura 5 Caudal observado y pronosticado con DKF, ENKF y DKF-EnKF (avenida del 4/9/2017 16:00 h al 8/9/2017 20:00 h).
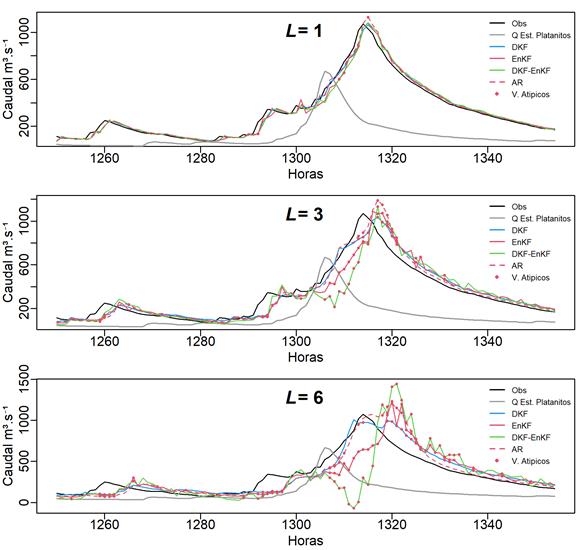
Figura 6 Caudal observado y pronosticado con DKF, En KF y DKF-EnKF (avenida del 23/09/17 10:00 h al 28/09/17 00:00 h).
Los pronósticos para el tiempo
Por otra parte, los algoritmos de EnKF y DKF-EnKF no obtienen mejoras debido a que EnKF hace estimaciones de escalares y no se incluye el retraso entre series. A diferencia de DKF, el pronóstico generado por DKF-EnKF se invierte de tal forma que genera un pico mínimo (hora 1311, 25/09/2017 23:00), que se debe a la actualización con el pico máximo de caudal que presenta la estación Platanitos (hora 1306, 25/09/2017 18:00) y que el algoritmo de EnKF trata de corregir. Una posible adecuación es la implementación de EnKF para la estimación de estados en lugar de escalares que también puede agregar capacidad para tratamiento de no linealidad además de la integración del filtro de Kalman con modelos de simulación distribuidos, como lo proponen Rafieeinasab et al. (2014). En realidad, para modelar en Kalman, simplifica los parámetros que incluye el modelo distribuido Sacramento Soil Moisturing Accounting (SAC) y al final compara sus filtros de Kalman de conjuntos con los resultados de ese modelo. El trabajo de Rafieeinasab et al. (2014) es muy interesante desde dos puntos de vista: 1) el trabajo compara dos filtros de Kalman de conjuntos, el sencillo (ENKF) y el de máxima verosimilitud (MELF); 2) considera todo un sistema que relaciona pronóstico de caudales con humedad del suelo y dicha humedad está vista desde un balance que considera una lluvia media en la cuenca, una evaporación potencial media en la cuenca. Desde el punto de vista conceptual, nuestro modelo es más sencillo, porque sólo realiza la asimilación de datos de los caudales medidos. Sin embargo, una crítica constructiva a sus resultados es la siguiente: su cuenca es pequeña (435 km2) comparada con nuestra cuenca (12 076 km2). El orden del tamaño de sus caudales es pequeño (entre 100 y 200 m3/s), pero su error (RSME) es muy alto, pudiendo llegar a ser de 45 m3/s. En nuestro trabajo, los caudales son del orden de 200 a 1 100 m3/s y sin embargo el máximo RSME es 116 m3/s en el peor caso.
Los pronósticos pueden alcanzar mejor ajuste con la incorporación dinámica del tiempo de retraso entre series, tratamiento de variables con distintos tipos de observación y proporciones (Meng et al., 2017), e incorporación de las variables que afectan el tiempo de retraso, como la ubicación y dirección de los eventos de precipitación, y la condición de humedad antecedente del suelo de la cuenca. La precipitación, presión atmosférica, temperatura y humedad relativa son variables que pueden ayudar a tener mejores ajustes en el pronóstico. Asimismo, dado que los caudales que se miden en la parte alta de la cuenca son proporcionalmente menores debido a la menor área de captación disponible, es conveniente incluir en el modelo parámetros que ayuden a equiparar las magnitudes de los caudales. Además, es determinante tener registros de estaciones meteorológicas distribuidas en el área de la cuenca para definir y actualizar la función de respuesta de la cuenca (HUI) (González-Leiva et al., 2015).
La dispersión entre la serie observada y las series pronosticadas (Figura 7) muestran similitud entre los algoritmos. A medida que se aumenta
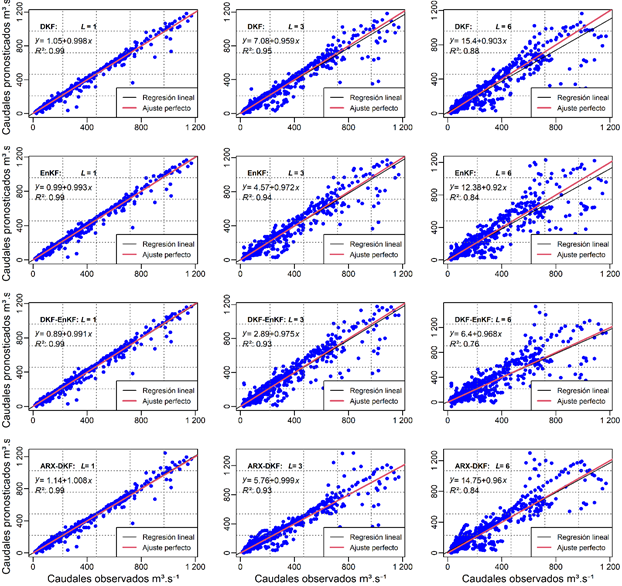
Cuando
Tabla 2 Coeficientes de determinación del caudal observado contra los pronosticados.
| L1 | L2 | L3 | L4 | L5 | L6 | |
|---|---|---|---|---|---|---|
| DKF | 0.99 | 0.97 | 0.95 | 0.93 | 0.90 | 0.88 |
| EnKF | 0.99 | 0.96 | 0.94 | 0.91 | 0.88 | 0.84 |
| DKF-EnKF | 0.99 | 0.96 | 0.93 | 0.87 | 0.84 | 0.76 |
| ARX-DKF | 0.99 | 0.96 | 0.93 | 0.90 | 0.87 | 0.84 |
A fin de verificar la normalidad de los residuales generados a partir de los pronósticos del DKF, EnKF y DKF-EnKF, en la Figura 8 se muestran los histogramas y el ajuste de la curva normal para cada algoritmo en los diferentes pasos. Es importante considerar que es ideal que los residuales tengan distribución normal, pero en pocos casos se obtiene así, por tanto se admite una aproximación (Chatfield, 2001).
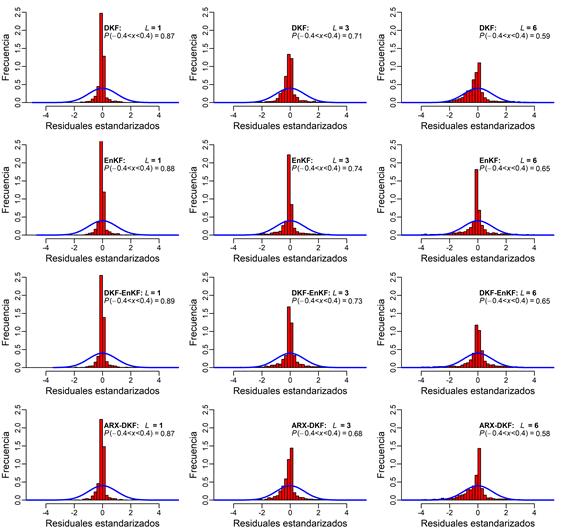
Se puede notar distribución simétrica con mayor concentración de pronósticos en la parte central. En el rango entre -0.4 y 0.4 de los residuales estandarizados,
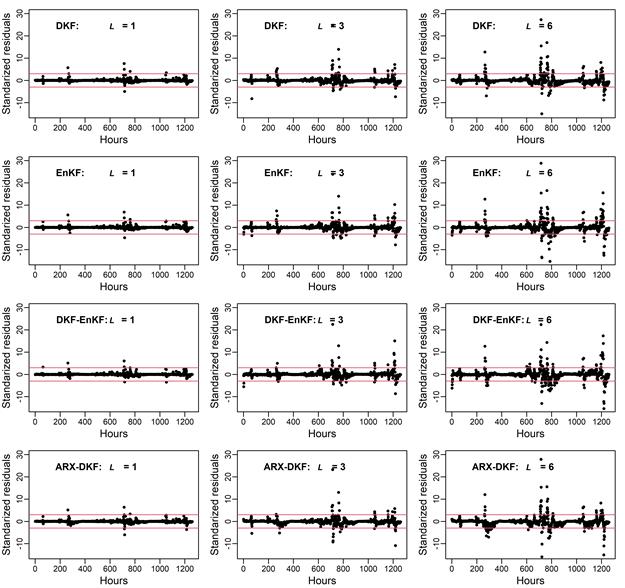
La presencia de datos atípicos está estrechamente relacionada con el nivel de ajuste. Como se muestra en la Tabla 3, DKF presenta la menor cantidad de valores atípicos asociados con la capacidad que tienen para gestionar los retrasos entre las series (Tabla 1). Por el contrario, DKF-EnKF, con excepción del paso
Tabla 3 Cantidad de valores atípicos por algoritmo y paso.
| L1 | L2 | L3 | L4 | L5 | L6 | |
|---|---|---|---|---|---|---|
| DKF | 13 | 41 | 63 | 84 | 96 | 112 |
| 1.03 % | 3.25 % | 5.00 % | 6.67 % | 7.62 % | 8.89 % | |
| EnKF | 15 | 41 | 70 | 99 | 112 | 143 |
| 1.19 % | 3.25 % | 5.56 % | 7.86 % | 8.89 % | 11.35 % | |
| DKF-EnKF | 14 | 46 | 66 | 105 | 132 | 167 |
| 1.11 % | 3.65 % | 5.24 % | 8.33 % | 10.48 % | 13.25 % | |
| ARX-DKF | 15 | 42 | 62 | 87 | 107 | 137 |
| 1.19 % | 3.33 % | 4.92 % | 6.90 % | 8.49 % | 10.87 % |
Conclusiones
El DKF obtiene el mejor ajuste debido a la estimación de estados que permite el aprovechamiento del retraso entre series como base para la actualización. El EnKF estima valores escalares y genera suavizado con efecto de desplazamiento, que mantiene estables la media y la desviación estándar, pero con ajuste inferior al DKF. De esta manera, la utilización del DKF donde se incorpore de forma recursiva el tiempo de retraso para actualización puede mejorar ajuste en los picos, además, la simplicidad para programar y operar el DKF los hace viables para pronóstico de caudales a corto plazo. El pronóstico de caudales horarios, con todos los filtros de Kalman analizados, es muy bueno con coeficientes de Nash-Sutcliffe muy altos y errores bajos medidos como RSME.
Para mejorar el ajuste de los pronósticos es importante adelantar trabajos de investigación donde se incluya la actualización recursiva del tiempo de retraso entre las series de diferentes estaciones teniendo en cuenta que se presentan variaciones a lo largo del tiempo. Además, se pueden evaluar los pronósticos con tamaños de paso de varias horas, por ejemplo, agrupar seis horas mediante valores como la media o máximo, a fin de que cada paso equivalga a seis horas y un pronóstico a seis pasos equivalga a 36 horas, de esta forma se da más flexibilidad al modelo y se puede ampliar el periodo de pronóstico.

