











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
The interplay between generative algorithms and Machine Learning (ML) constitutes a fascinating convergence of two fundamental fields within artificial intelligence. Despite their increasing relevance, there remains a significant knowledge gap regarding the impact and trajectory of generative algorithms in ML over time, underscoring the urgency for a systematic and detailed analysis of the influence of these algorithms in the ML landscape. The existing literature has tackled various dimensions of generative algorithms and their interaction with ML. Perdomo-Ortiz et al. [1] focus on unsupervised generative models, highlighting their role in exploratory data analysis in the era of big data. Conversely, Fanfarillo [2] compares classical and quantum ML models, emphasizing the superiority of restricted Boltzmann machines and Born machines of quantum circuits in generative tasks. Moreover, Neo et al. [3] detail the use of ML in the design of photonic crystals. The research by Sanchez-Lengeling and Aspuru-Guzik [4] centers on generative molecular design, examining molecular representations and neural network architectures.
In the study by Bilodeau et al. [5], the authors propose an innovative method employing Variational Autoencoders for the creation of synthetic populations of micro-agents, surpassing previous techniques. Additionally, Fan et al. [6] analyze the susceptibility of deep neural network classifiers to be fooled by minimal alterations, proposing defensive strategies.
Similarly, Yao et al. [7] present RNA-GAN, which integrates gene expression profiles with generative models to produce more realistic tissue mosaics. Dahl and Sørensen [8] develop predictive ML models for price signals in financial markets, enhancing trading strategies through synthetic data. In the study by Carvajal-Patiño and Ramos-Pollán [9], the application of deep learning in generating medical images is reviewed.
The authors Paz et al. [10] propose a comprehensive model for the detection of textual misinformation on social networks. Lastly, Alhomayani and Mahoor [11] evaluate the efficacy of conditional generative models in improving classifiers for imbalanced datasets.
The realm of generative algorithms in Machine Learning (ML) constitutes an expanding area of research whose depth and scope have yet to be fully elucidated. Despite rapid advancements in the adoption of these technologies, a lack of clarity persists regarding their long-term effects and effective integration across various domains. The existence of knowledge gaps indicates limitations in the comprehensive understanding of their disruptive impact.
The aim of this review is to offer a critical and detailed insight into the field, spotlighting advancements, and challenges, and proposing strategic directions for future research. The study concludes with the presentation of conclusions and suggestions for future work based on the findings obtained.
This paper is structured as follows: Chapter 2 presents the theoretical background; Chapter 3 describes the review methodology; Chapter 4 discusses the main results and findings; and Chapter 5 concludes with reflections and perspectives for upcoming research.
2 Theoretical Background
2.1 Generative Algorithms/ Generative Models
In the realm of artificial intelligence (AI), generative models have gained fundamental importance [67]. Their primary aim is to generate new data that faithfully emulates the input data. These models have experienced significant evolution since Turing's early contributions, progressing through Hidden Markov Models and Recurrent Neural Networks, to the contemporary Generative Adversarial Networks (GANs) [68]. GANs have been a milestone in the generation of synthetic data over the last decade, extending their impact beyond healthcare.
This technology exemplifies the ability of generative models to learn and sample from the implicit density functions of data. This advancement is pivotal for creating realistic data with practical value across various fields, including computational chemistry [4].
2.2 Machine Learning
The interrelation between generative models and Machine Learning is essential and highly interconnected. The study by Zhang et al. [67] highlights the crucial role of Alan Turing in the development of Machine Learning, a discipline focused on creating machines with the ability to learn and reason in a manner analogous to humans.
Turing's innovative vision has been instrumental in achieving significant advancements in automatic learning, including the development of algorithms capable of generating complex and emergent behaviors. This concept is a central pillar in the areas of neural networks and deep learning.
3 Review Method
In this systematic review, a methodology based on the guidelines by Kitchenham and Charters [29], recognized as a standard in academic research for the consolidation of scientific evidence, has been adopted. (See Figure 1).
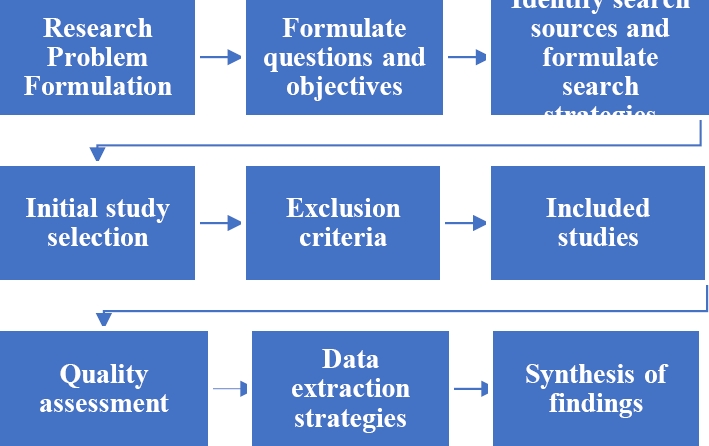
3.1 Research Problems and Objectives
For a detailed understanding of the objectives and scope of the research, Table 1 should be reviewed.
Table 1 Research questions and objectives
| Research Question | Objective |
| RQ1: How are the quartiles distributed in the periodic publications that have addressed research on the Impact of Generative Algorithms in Machine Learning? | Determine the distribution of quartiles in periodic publications that have addressed research on the Impact of Generative Algorithms in Machine Learning. |
| RQ2: What terms (keywords) are predominant in the abstracts of studies related to the Impact of Generative Algorithms in Machine Learning? | Find the terms (keywords) that are predominant in the abstracts of studies related to the Impact of Generative Algorithms in Machine Learning. |
| RQ3: What sets of keywords tend to appear together in the literature examining the Impact of Generative Algorithms in Machine Learning? | Know the sets of keywords that tend to appear together in the literature examining the Impact of Generative Algorithms in Machine Learning. |
| RQ4: What categories of named entities, such as individuals, institutions, locations, dates, and figures, prevail in the abstracts of research on the Impact of Generative Algorithms in Machine Learning? | Determine the categories of named entities, such as individuals, institutions, locations, dates, and figures, that prevail in the abstracts of research on the Impact of Generative Algorithms in Machine Learning |
| RQ5: What is the distribution of clusters of the conclusions of the papers distinguished by their high objectivity and minimal emotional polarity in the context of the Impact of Generative Algorithms on Machine Learning? | Understand the cluster distribution of the conclusions of papers that are distinguished by their high objectivity and minimal emotional polarity in the context of the Impact of Generative Algorithms in Machine Learning. |
3.2 Information Sources and Search Equations
Comprehensive searches were conducted in highly relevant academic databases, including Scopus, Science Direct, Web of Science, ACM Digital Library, Springer Link, and Google Scholar. The selection of these databases was intentional due to their broad coverage in the fields of systems engineering, data science, and machine learning, key areas for the present review.
These databases provide access to high-quality, peer-reviewed studies and are recognized for their comprehensiveness in relevant academic literature.
Keywords such as generative algorithms, generative models, data science, data analysis, and machine learning were chosen for their importance in generative learning and its applications in data analysis.
Search equations were constructed to maximize the relevance of the studies and minimize the inclusion of irrelevant results. Inclusion criteria focused on high-impact studies, excluding those without empirical results or with limited access. Table 2 provides a comprehensive overview of the search strategies implemented.
Table 2 Information sources and search equations
| Source | Search Equation |
| Scopus | TITLE-ABS-KEY ( ( "generative Algorithms" OR "generative models" OR "generative modeling" OR "generative Methods" ) AND ( "data science" OR "data analysis" OR "data mining" OR "machine Learning" ) ) |
| Science Direct | Title, abstract, keywords: ("generative Algorithms" OR "generative models" OR "generative modeling" OR "generative Methods") AND ("data science" OR "data analysis" OR "data mining" OR "machine Learning") |
| Web of Science | ("generative Algorithms" OR "generative models" OR "generative modeling" OR "generative Methods") AND ("data science" OR "data analysis" OR "data mining" OR "machine Learning") (Title) OR ("generative Algorithms" OR "generative models" OR "generative modeling" OR "generative Methods") AND ("data science" OR "data analysis" OR "data mining" OR "machine Learning") (Abstract) OR ("generative Algorithms" OR "generative models" OR "generative modeling" OR "generative Methods") AND ("data science" OR "data analysis" OR "data mining" OR "machine Learning") (Author Keywords) |
| ACM Digital Library | [[All: "data science"] OR [All: "data analysis"] OR [All: "data mining"] OR [All: "machine learning"]] AND [[All: "generative algorithms"] OR [All: "generative models"] OR [All: "generative modeling"] OR [All: "generative methods"]] |
| Springer Link | '("generative algorithms" OR "generative models" OR "generative modeling" OR "generative methods") AND ("data science" OR "data analysis" OR "data mining" OR "machine learning")' |
| Google Scholar | ("generative algorithms" OR "generative models" OR "generative modeling" OR "generative methods") AND ("data science" OR "data analysis" OR "data mining" OR "machine learning") |
3.3 Study Selection
The Paper Selection and Filtering process considered the following exclusion criteria (EC):
EC1 (Publication age): The publication dates were reviewed, excluding papers older than 7 years to ensure relevance in a rapidly evolving field.
EC2 (Language of the paper): Papers not written in English were eliminated, as English is the predominant language in international scientific literature.
EC3 (Type of study): Systematic reviews and bibliometric analyses were prioritized. Studies that did not provide a significant theoretical or empirical contribution were excluded.
EC4 (Full-text access): Papers whose full text was not available were excluded, as this would limit a thorough analysis of their content.
EC5 (Peer review): Studies published in journals and conferences with rigorous peer-review processes were selected.
EC6 (Clarity in titles and keywords): Papers whose title or keywords did not clearly reflect the content were eliminated to ensure alignment with the research topic.
EC7 (Abstract clarity): Papers with ambiguous or unclear abstracts were excluded, as the abstract must provide an accurate summary of the main contributions of the study.
EC8 (Originality): Studies that did not provide new perspectives or original data were eliminated, ensuring that the selected papers were relevant. Additionally, all duplicate papers were removed.
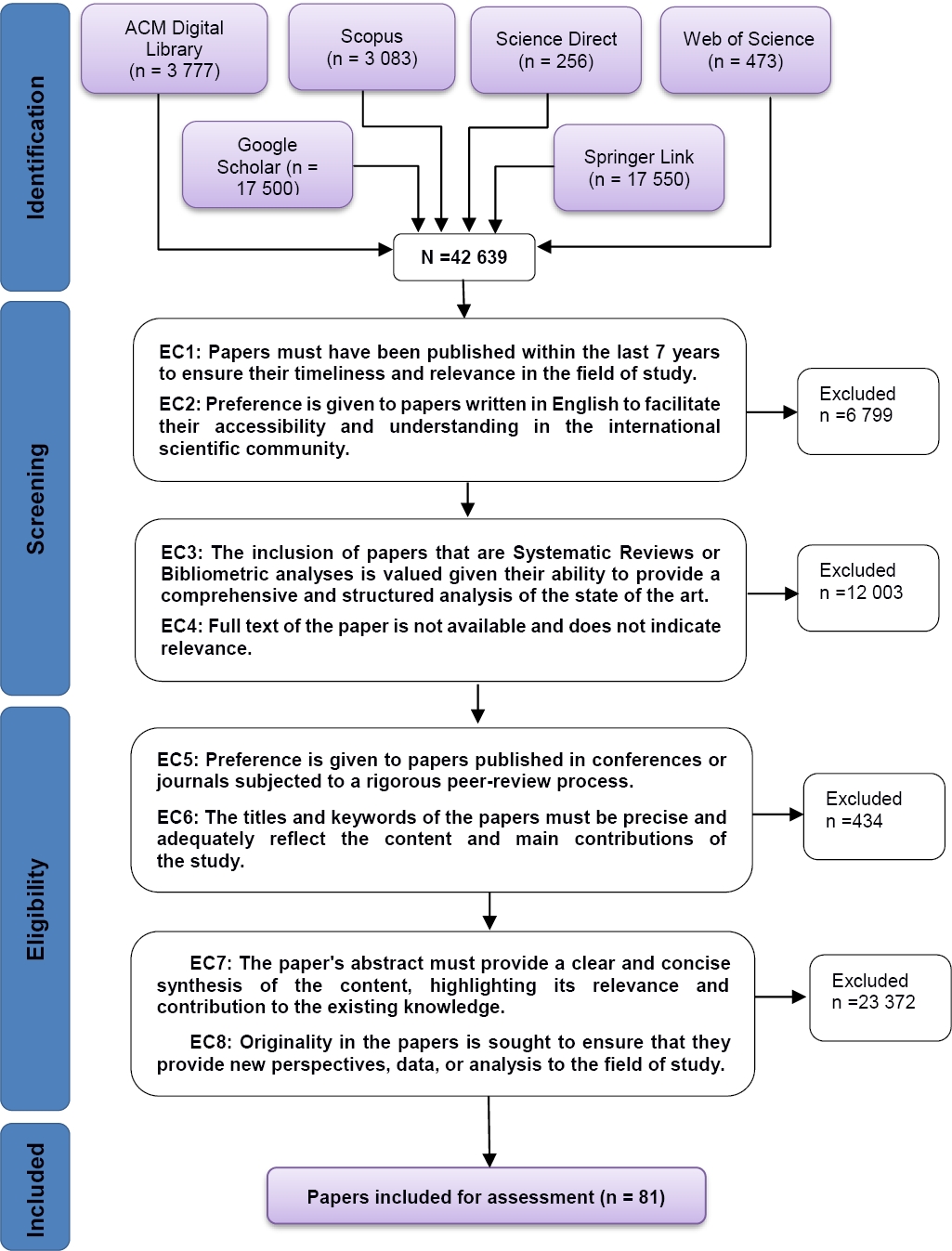
The selection process is detailed in Figure 2. The InOrdinatio formula (1), derived from the document by Pagani et al. [42], was developed to assess the relevance of scientific papers:
where: H_Index is the paper's H-Index, Quartile is the paper's quartile, and ∑Ci is the total number of citations of the paper.
The index ranks the selected publications based on their relevance, combining four key factors: impact factor, year of publication, quartile, and citation count. By applying this formula, researchers can identify the most relevant studies within their bibliographic portfolio, ensuring a selection based on objective and meaningful criteria.
Studies that, despite their significant InOrdinatio score, were not available, were acquired by the researchers.
3.4 Quality Assessment
In the final stage of the research, specific criteria were applied to measure the quality (QA) of the studies, which was essential for determining the final selection of papers included in the analysis. Five quality criteria are detailed below:
− QA1. Does the paper present a logical and coherent structure that facilitates the understanding of the content?
− QA2. Are the data sets used in the research precisely specified?
− QA3. Are the results obtained in the research explicitly delineated and communicated?
− QA4. Do the study's conclusions align with the initial objectives?
− QA5. Does the study contribute valuable and applicable information for the advancement of the field of study?
In the quality assessment process of this study, 81 selected investigations were examined, following specific exclusion criteria. An assessment of each study determined that 62 studies met all the established quality criteria.
4 Results and Discussion
In this section of the study, the obtained results are presented and analyzed, placing them in the context of the previous literature and the objectives established in the research.
4.1 Overview of the Studies
The systematic literature review is a rigorous methodology that allows for the collection and evaluation of relevant studies on a specific topic. Once the relevant studies were collected, data extraction was performed to obtain detailed information about each study, such as the title, authors, publication year, and other relevant data. Figure 3 shows the number of studies published each year, providing a visual representation of the temporal distribution of research in this field.
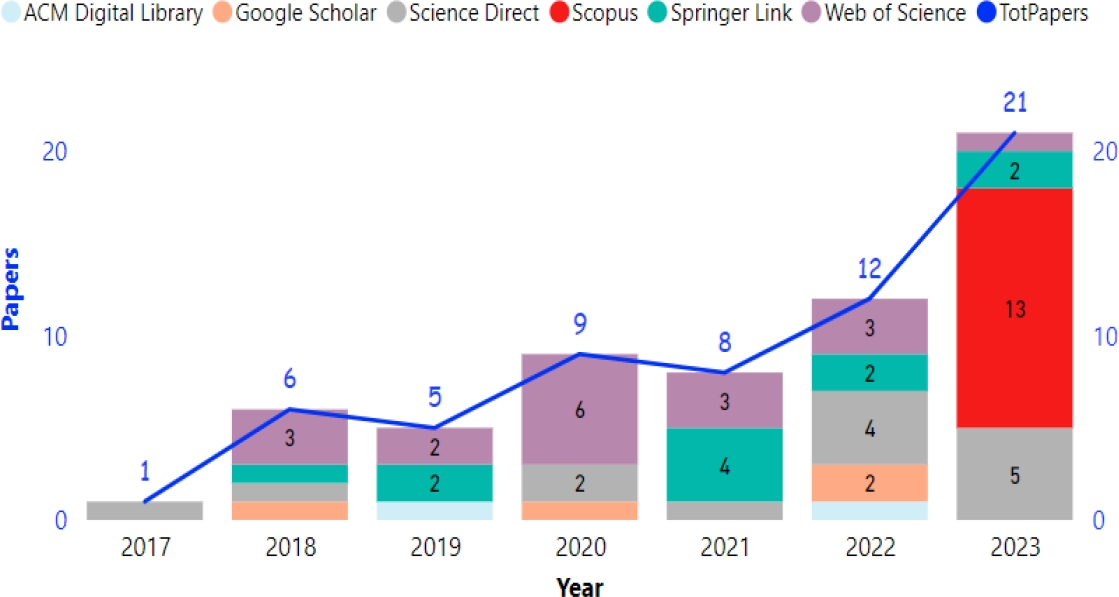
This figure displays an increase in the number of publications on generative algorithms in Machine Learning from 2017 to 2023, highlighting the growing interest in this field. Scopus and Web of Science, which are consolidated as the main sources of these publications, reflect the preference of researchers or a greater inclusion of works of this nature in their indexes. The steady growth of publications between 2017 and 2023 can be attributed to several key factors.
Technological advancements, such as generative algorithms and machine learning, have gained popularity during this period, driving more research. Access to infrastructures like cloud computing and big data has enabled more complex studies, while increased funding for research in data science and machine learning has incentivized academic production. Additionally, changes in academic policies, such as the pressure to publish in indexed journals and the focus on open science, have contributed to this increase, allowing for broader international collaboration and access to resources that accelerate result generation.
When compared with the study by Cárdenas-Quispe et al. [10], which highlights IEEE Xplore as a primary source, a marked technical inclination in its collection is appreciated.
Conversely, Aparcana-Tasayco and Gamboa-Cruzado [5] show a pattern of sustained growth until 2020 and a subsequent decrease, differentiating from the more uniformly ascending trend observed in this review.
In their study, Rojas Valdivia et al. [49] show similar behavior until 2021, followed by a drop in 2022, which could reflect changes in the dynamics of publication or a shift in research focus towards emerging subdomains.
4.2 Responses to Research Questions
This phase of the Systematic Literature Review (SLR) is decisive, focused on exploring and detailing the responses to the four research questions (RQs) that have guided this study.
RQ1: How are the quartiles distributed in the periodic publications that have addressed the research on the Impact of Generative Algorithms in Machine Learning?
Quartiles (Q1, Q2, Q3, and Q4) are a classification that reflects the relative position of journals within their field, based on impact metrics. Journals in Q1 are those with the highest impact and prestige, while those in Q3 or Q4 have lower impact. SQ may represent publications outside the quartile system, such as conference papers or journals without a defined quartile ranking. Figure 4 displays the annual distribution of publications by quartile in the selected sources.
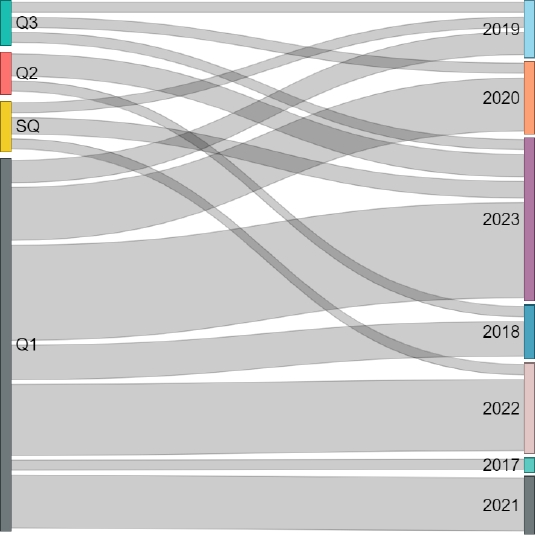
The temporal distribution of publications evidence trends in the research of generative algorithms and Machine Learning from 2017 to 2023. The persistence of papers in the third quartile (Q3) suggests established research in mid-range journals, while the increase in unclassified quartiles (SQ) and second quartile (Q2) in 2023 reflects an interest towards emerging areas and the growing perception of their relevance. Notably, the first quartile (Q1) dominates the distribution, particularly in 2023, underlining the advancement and increasing importance of this field.
The variability in quartiles observed in recent years could indicate increased competition in high-impact journals or a greater openness to explore publications in other impact levels. This behavior may also reflect the need to diversify publications to reach broader audiences or meet different evaluation metrics.
Publications in Q1 remain important, but the relevance of adjusting publication strategies to maximize reach and visibility across various academic forums becomes evident.
RQ2: What terms (keywords) are predominant in the abstracts of studies related to the Impact of Generative Algorithms on Machine Learning?
The analysis of prominent keywords, presented in Figure 5, reveals the areas of greatest focus and their relevance in current research.
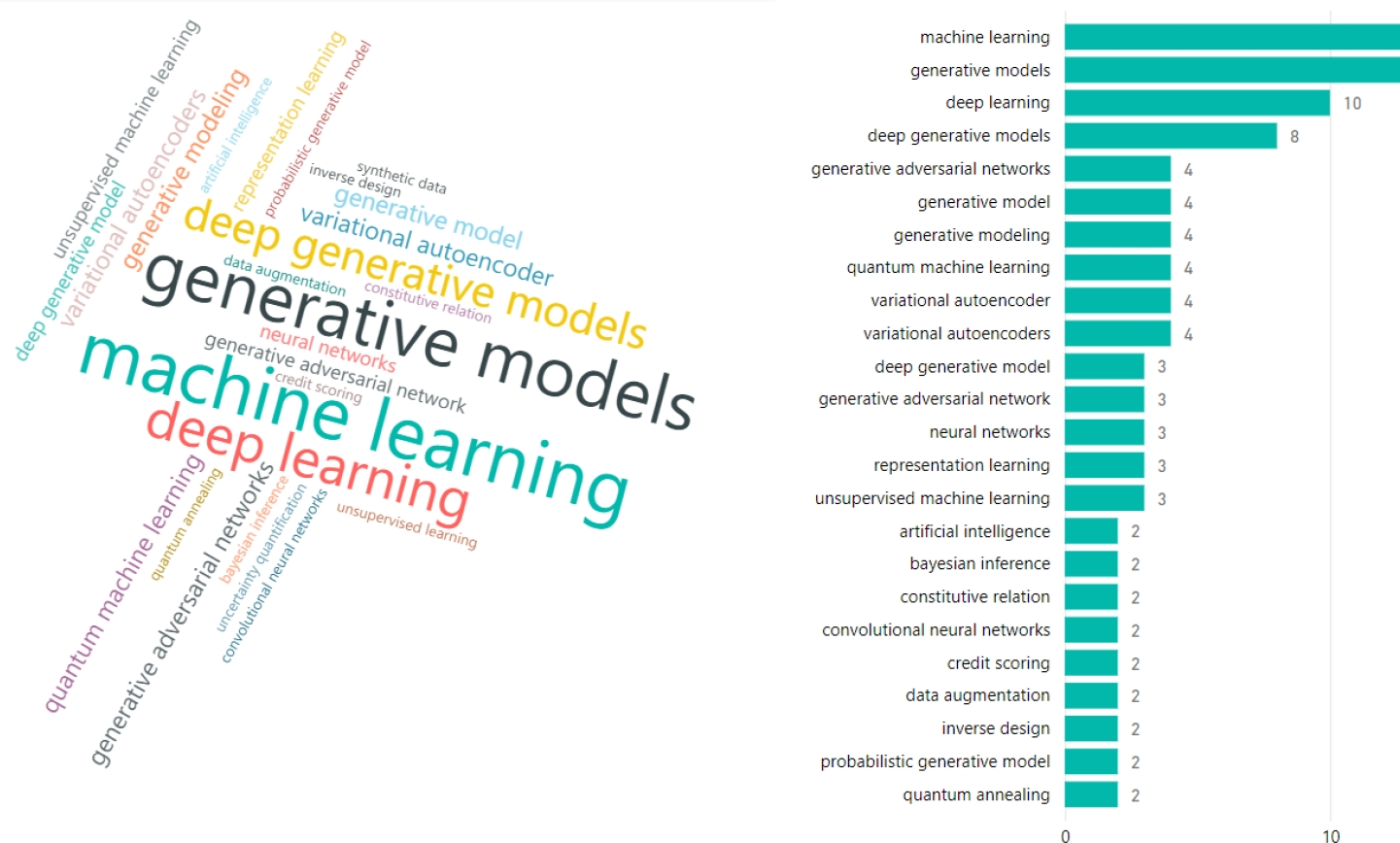
The analysis of the word cloud and bar chart shows that "machine learning" is the most predominant term, with 14 mentions, followed by "generative models" with 13 and "deep learning" with 10. This reflects the main focus of current research around these key concepts. The rise of terms like "deep generative models" (8 mentions) and "generative adversarial networks" (4 mentions) suggests that advanced data generation techniques are gaining relevance. Terms such as "quantum machine learning" and "probabilistic generative model," with only 2 mentions each, indicate that these topics are still in an emerging phase, though they are promising for future research. The comparison over time shows that terms like "deep learning" and "machine learning" have maintained their prominence, while more specialized terms like "variational autoencoders" and "unsupervised machine learning" are beginning to gain traction in recent discussions.
Figure 5, shown in Rojas Valdivia et al. [49], reveals a distinctive focus in the literature, with the prevalence of terms like "android", "detection", and "malware". This orientation highlights the practical application of Machine Learning algorithms in mobile device security, demonstrating a commitment to solving real technological challenges.
The prevalence of terms such as "machine learning" and "generative models" suggests that these approaches are at the core of current research and may be key areas for future innovations. The diversification into more specific terms, such as "variational autoencoders" and "quantum machine learning," indicates an expansion towards more specialized and advanced approaches. This could imply that future research will focus on developing new applications and methodologies within generative learning and its integration with emerging technologies like quantum computing.
RQ3: What sets of keywords tend to appear together in studies examining the Impact of Generative Algorithms on Machine Learning?
Figure 6 presents a bibliometric network focused on keywords, which shows the prevalent thematic connections in research on generative algorithms in Machine Learning.
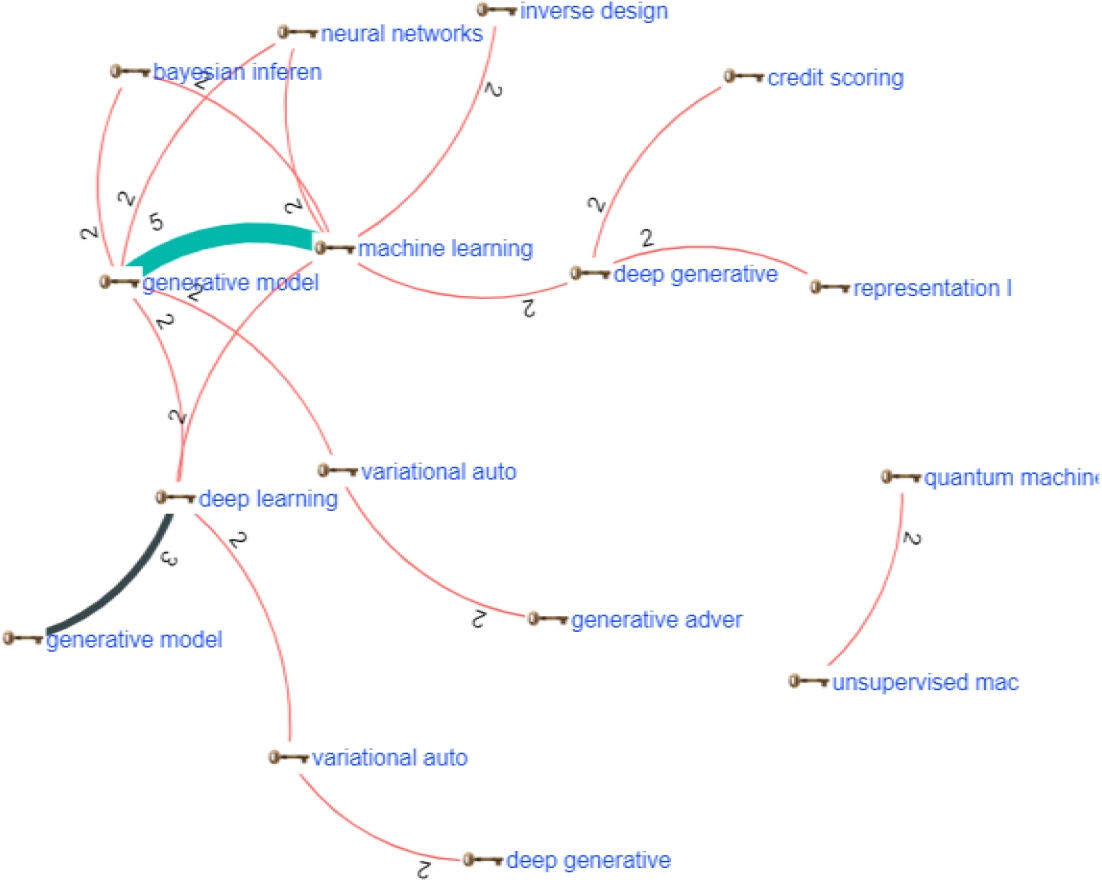
The bibliometric network of keywords was generated using computational tools based on NLP and generative AI, allowing for the visualization of the relationship and co-occurrence of key terms in publications.
The clustering algorithm used, such as the Louvain algorithm for community detection, identifies groupings of related terms. In this case, keywords like “machine learning,” “generative models,” and “deep learning” form the most connected nodes, suggesting that these areas are highly interrelated in the reviewed research. The selection of keywords was based on key terms from the fields of machine learning and generative models, reflecting the central focus of research around these technologies. The strong connection between “machine learning” and “generative models” indicates that these techniques are frequently studied together.
Figure 11, from the study by Aparcana-Tasayco and Gamboa-Cruzado [5], places "machine learning" in a strategic position, linking it to specific challenges like network technology security. Alternatively, Figure 8 from Rojas Valdivia et al. [49], associates "machine learning" with advances in "artificial intelligence" and "deep learning", pointing towards applications in "internet of things" and "robotics".
The strong interrelationship between the key terms suggests that the field is converging towards greater integration of machine learning and generative techniques, which could accelerate advancements in areas such as artificial intelligence and complex data processing.
The presence of emerging approaches like "quantum machine learning" indicates a growing interest in exploring disruptive technologies that could transform the capabilities of generative models. However, the weaker connections suggest that these areas are still developing and will require further research to consolidate within the main field.
RQ4: Which countries show co-occurrence in research on best practices and their impact on decision-making?
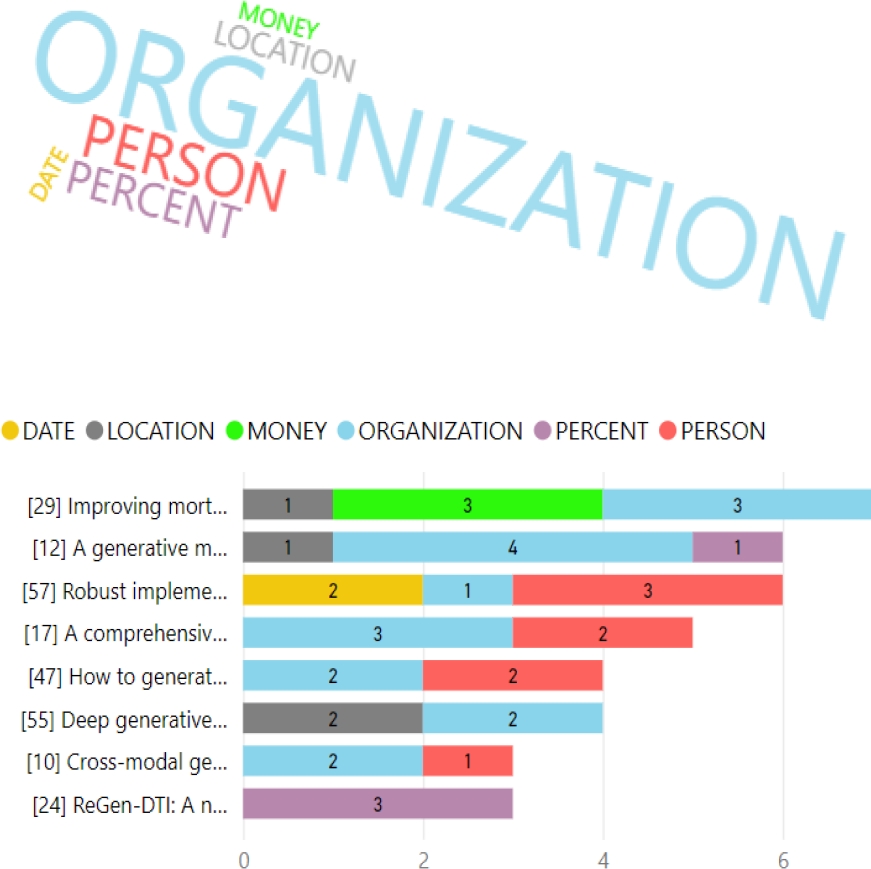
Figure 7 displays the frequencies of various named entities (NER) in the abstracts of papers, providing a detailed view of the main focuses of interest in this research field.
The figure analyzes how 'ORGANIZATION' dominates the abstracts, highlighting the fundamental role of institutions in the evolution of research on generative algorithms and Machine Learning. Additionally, the inclusion of 'PERSON' and 'PERCENT' illustrates the synergy between organizational support and individual contribution, along with the importance of statistical analysis.
Figure 11 in Rojas Valdivia et al. [49], shows a preference for 'PERCENT' in papers indexed in Scopus and ACM Digital Library, indicating an inclination towards studies with solid quantitative foundations. Contrasting with the current review, which highlights organizational support, the authors Rojas Valdivia et al. [49] emphasize the priority given to accuracy and measurability.
The frequent mention of the 'ORGANIZATION' category in the abstracts of the studies underlines the importance of institutional collaboration and support in the progress of research on generative algorithms and Machine Learning. Simultaneously, the prominent presence of 'PERSON' and 'PERCENT' indicates the relevance of individual contributions and the centrality of quantification and statistical analysis in research. These elements evidence that both individual expertise and analytical precision are fundamental in the study of generative algorithms and their impact on Machine Learning.
RQ5: What is the distribution of clusters of the conclusions of the papers distinguished by their high objectivity and minimal emotional polarity in the context of the Impact of Generative Algorithms on Machine Learning?
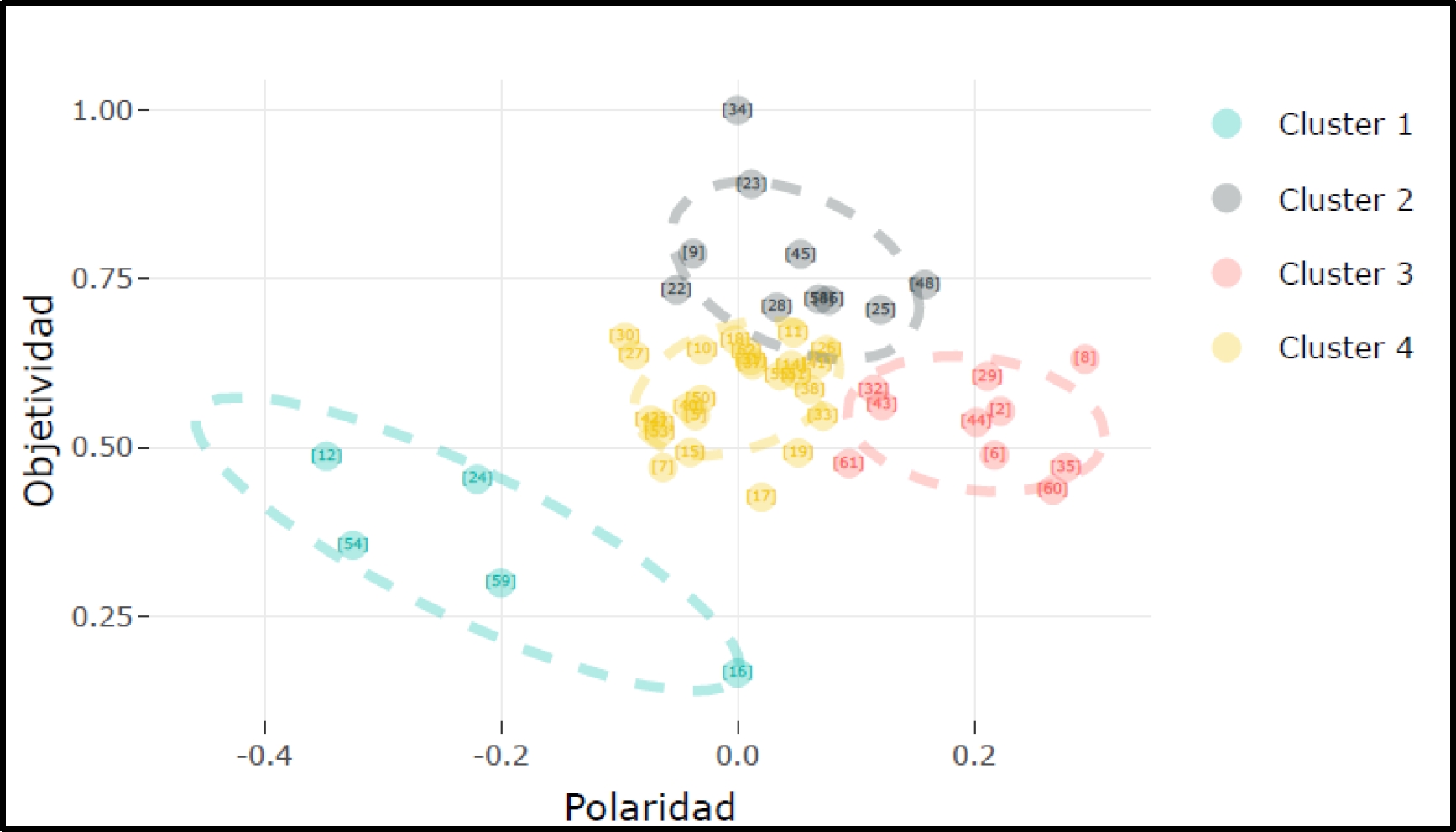
The cluster distribution illustrated in Figure 8 shows significant differences in the objectivity and polarity of the conclusions in the literature on generative algorithms in Machine Learning. This representation indicates variations in neutrality and the emotional tone of the academic discourse, evidencing diversity in the approaches and perspectives adopted in the field.
The analysis of the clusters reveals variations in the approach and tone of the papers on generative algorithms and Machine Learning.
Cluster 1 stands out for its emotional neutrality, pointing to a rigorous technical analysis.
Cluster 2, with its trend towards positive conclusions, reflects an analytical approach that emphasizes favorable outcomes. In contrast,
Cluster 3 shows cautious optimism, combining objectivity with a slight positive tendency.
Cluster 4, on the other hand, displays diversity in objectivity and polarity, indicating a possible fusion of analysis and persuasion.
This spectrum of approaches not only enriches the understanding of the field but also underscores the plurality of perspectives in the study of these topics.
This study is distinguished by its novelty, given the scarcity of direct comparatives in the realm of generative algorithms and Machine Learning. It highlights the variability in methods and approaches used in research, contributing to a broader and deeper understanding of the area. The high objectivity observed in some clusters underscores their methodological robustness and the validity of their conclusions. The trend towards positive conclusions in certain groups reflects an inherent optimism about the potential of these algorithms, suggesting promising paths for future inquiries and underlining the importance of this work in advancing knowledge.
The variability between clusters reflects different styles in the interpretation of results, ranging from more neutral and objective to more subjective and optimistic. This may suggest the existence of more conservative approaches in certain research, while others may lean towards bolder claims. For future studies, understanding this distribution of conclusions can help identify trends in the presentation of results and how these may influence the perceived impact of the study. Additionally, it may be useful to consider how the degree of polarity and objectivity affects acceptance or critical appraisal by the scientific community.
5 Conclusions and Future Research
In this Systematic Literature Review, the impact of generative algorithms on Machine Learning (ML) is analyzed. A total of 62 papers were reviewed for the research, highlighting the growing relevance and dynamics of this field of study. The research emphasizes the importance of international collaboration, with the United States and Canada as leaders, alongside the active participation of Italy, China, and the United Kingdom.
The interconnection of key terms like "machine learning", "deep learning", and "generative model" in the bibliometric keyword network (RQ3) underscores the convergence of various methodologies and techniques, evidencing the interdisciplinary nature of the field. Moreover, the prominence of 'ORGANIZATION' in the paper abstracts (RQ4) emphasizes the crucial role of institutions in the research and development of the generative algorithms and ML field.
This trend highlights the importance of institutional support and the relevance of individual contributions and quantitative data, suggesting a balance between institutional cooperation and individual initiative in knowledge generation. In future research, we will incorporate quantitative metrics such as impact factor, citation count, and statistical rigor of the reviewed studies. This will complement the qualitative criteria, providing a more balanced evaluation and reducing potential interpretative biases.

