











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
Understanding skin lesions is fundamental to diagnosing and treating numerous dermatological conditions, which fall into two broad categories: primary and secondary. Primary lesions emerge on previously healthy skin and are the first indication of pathology. They can arise from various internal causes, such as hormonal imbalances and allergies, or external causes, such as exposure to infectious agents. In contrast, secondary lesions result from the evolution or transformation of primary lesions. They may develop as a natural consequence of the progression of a lesion or due to external factors such as trauma, secondary infections, or even the patient's self-interventions. Physical examination alone is often insufficient to diagnose the lesion accurately, so it is necessary to perform complementary tests, including dermatological imaging.
However, the quality of these images is strongly influenced by acquisition conditions, which can impact dermatologic diagnosis and the pre-accuracy of computer-aided diagnostic systems. In addition, the public images currently available are limited to a specific population, which creates a bias in representing the wide variety of skin types and skin tones of a people group. The style transfer algorithm has emerged as a powerful tool to address texture problems, allowing the standardization of images. This study implements the VGG19 algorithm based on style transfer published by Leon A. Gatys [5] using CNNs. The CNN approach synthesizes textures from the original images while preserving their semantic content. The resulting images are evaluated using the Kullback-Leibler (KL) divergence and the Structural Similarity Index (SSIM) metrics. These evaluations demonstrate that the results obtained with these algorithms are promising. Fig. 1 provides a graphical summary to help understand the implemented style transfer technique.
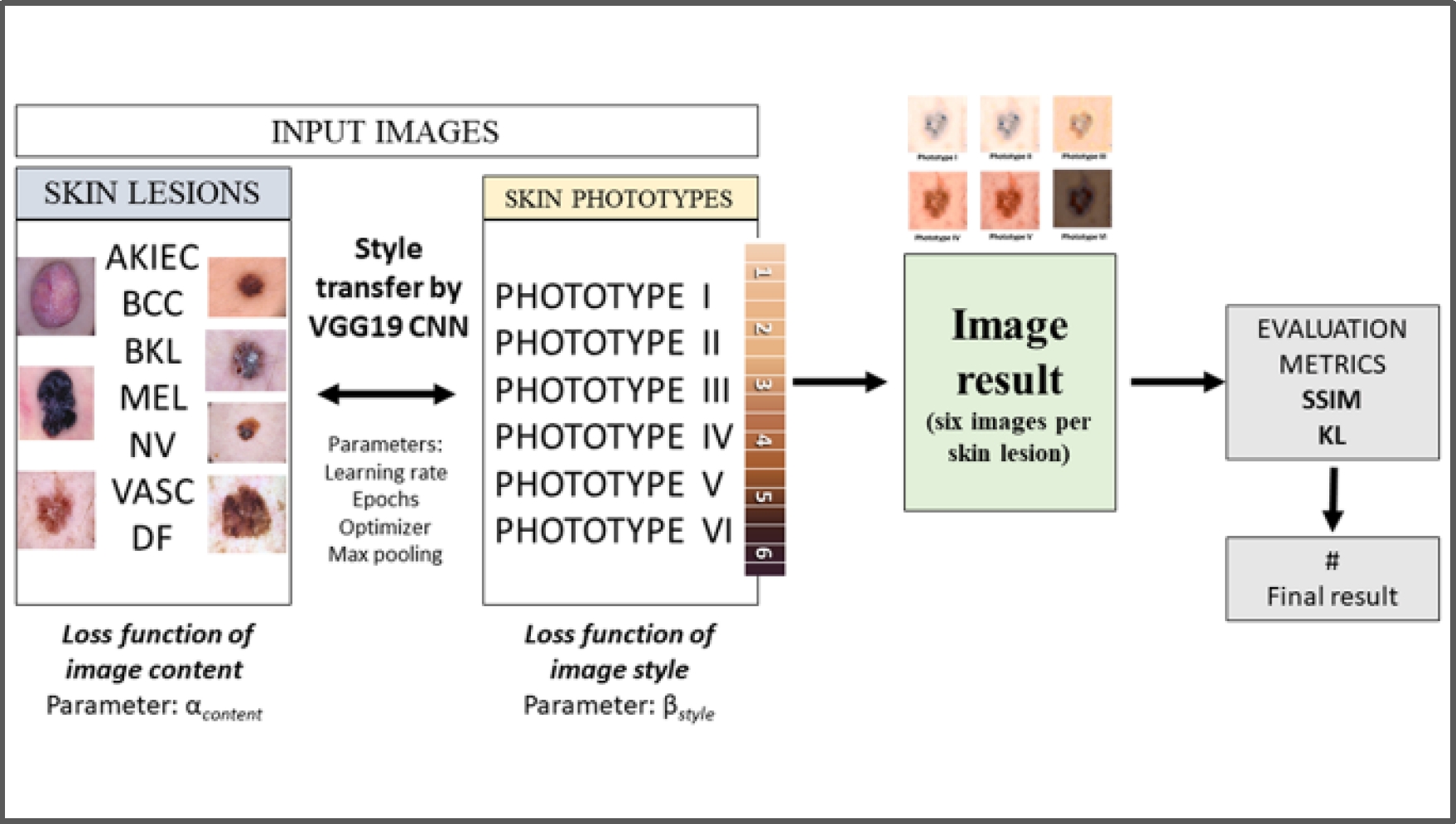
The contribution of this research is based on two main points:
Generating images of dermatological lesions according to six different skin phototypes.
Evaluating the produced images to assess their similarity and divergence from the original images.
The rest of this investigation is structured as follows. Section 2 introduces the necessary background to understand this research. Section 3 reviews related work. Section 4 details the proposed methodology. Section 5 presents the experimental study and discusses the results. Finally, Section 6 provides the conclusion and suggests paths for future research.
2 General Background
2.1 Deep Learning
This work employs deep neural networks composed of processing units called artificial neurons or nodes [11]. A Convolutional Neural Network (CNN or ConvNet) is a network architecture that learns directly from data. They help identify image patterns to recognize objects, classes, and categories. In addition, they can be very effective for classifying audio, signal, and time series data. CNNs generally consist of input, output, and several hidden layers. They can have tens or hundreds of layers. Filters are applied to the training image at different resolutions, and the resulting output is used as input for the next layer. The three most common layers are convolution, activation or ReLU (Rectified Linear Unit), and clustering layers. Convolution applies a set of convolutional filters to the input data; each filter activates different features of the images. ReLU keeps positive values and sets negative values to zero, allowing faster and more efficient training. It is also known as activation since only activated features proceed to the next layer. Finally, clustering simplifies the output by nonlinear reduction of the sampling rate, which reduces the number of parameters the network must learn. These operations are repeated on tens or hundreds of layers; each layer learns to identify different features [2]. The convolution operation is a process in which a group of pixels is taken from the input image, and a scalar product is performed with a kernel; mathematically, a convolution of two functions, f, and g, is defined as:
where f y g are two functions; f is the input function, and g is the kernel. i is the index at which the convolution is being evaluated. m is the length of the convolution kernel. The symbol * denotes the discrete convolution operation. The summation ∑ is performed over the index J from 1 to m. The expression
2.2 Image Evaluation Metrics
An image evaluation metric is a technique used to measure the quality and similarity between two images. They are essential for evaluating the accuracy and efficiency of image processing algorithms, such as segmentation and classification. Some image evaluation metrics include structural similarity index (SSIM), Kullback-Leibler divergence (KL), peak signal-to-noise ratio (PSNR), and mean squared error (MSE). Each metric has advantages and disadvantages, and choosing the appropriate metric for the task at hand is essential. For example, the (SSIM) metric is used to evaluate the quality of compressed images. At the same time, the (KL) helps compare probability distributions; the (PSNR) and (MSE) metrics are commonly used to evaluate the accuracy of segmentation and classification algorithms.
Structural Similarity Index (SSIM). Structural Similarity Index (SSIM) is a metric used in image processing to evaluate the quality and similarity between two images, Wang Z. et al. [16]. It was proposed by [16] in 2002 as an improvement of the Universal Image Quality Index (UIQI) metric, which had only first and second-order statistics of the original and distorted images. It is considered an unstable metric and does not correlate well with subjective evaluation, which led Wang & Bovik to propose the Structural Similarity Index (SSIM) as an improvement.
The SSIM is calculated by dividing the original and distorted images into blocks of size 8 x 8, converting them into vectors, and calculating the images mean, standard deviation, and covariance. The comparison of luminance, contrast, and structure based on statistical values is calculated using the metric (UIQI). The formula (2) gives the measure of the structural similarity index between the images a and b:
where μa y μb are the means of the images a and b, σa and σb are their standard deviations, and σab is the covariance between the images a and b. The constants C1 and C2 are used to avoid division by zero and stabilize the calculation. SSIM is considered a stable metric.
Kullback-Leibler Divergence (KL). The Kullback-Leibler (KL) divergence [17] is a metric used to calculate the difference between two probability distributions. It measures the amount of information lost when one distribution is used to approximate another and is applied in several areas, such as machine learning and information theory. The formula for the Kullback-Leibler divergence is as follows:
In this equation, P and Q are the probability distributions to be compared. The Kullback-Leibler divergence is used in various applications, such as detecting biases in data, comparing machine learning models, and assessing the quality of estimates. In addition, it can be used to define other metrics, such as the Jensen-Shannon distance.
3 Related Work
In texture transfer, the goal is to synthesize a texture from a source image while constraining texture synthesis to preserve the semantic content of a target image. For example, Efros and Freeman [4] introduce a correspondence map with target image features, such as image intensity, to constrain the texture synthesis procedure. Hertzman et al. [5] use image analogies to transfer texture from a stylized image to a target image. Ashikhmin [6] focuses on transferring high-frequency texture information while preserving the scale of the target image. Lee et al. [7] improve this algorithm by additionally informing texture transfer with edge orientation information. Convolutional Neural Networks trained with sufficient labeled data on specific tasks, such as object recognition, have been shown to learn to extract high-level image content in generic feature representations that are generalized across datasets (J. Donahue et al. [8]) and even to other visual information processing tasks (M. Kümmerer et al. [9]), and texture recognition (M. Cimpoi et al. [10]). In this paper, we explore using generic feature representations learned by convolutional neural networks (CNNs) to process both content and style of images. We implement the neural network-based algorithm with the VGG19 architecture, according to the work of L. A. Gatys et al. [11], to perform style transfer.
On the other hand, Wang Z. et al. [16] introduced an alternative, complementary framework for quality assessment based on the degradation of structural information. They developed a structural similarity index as a specific example of this concept. They demonstrated that human visual perception is highly adapted to extracting structural information from a scene through intuitive examples and comparing subjective ratings and state-of-the-art objective methods on a compressed image database. Likewise, Kullback and Leibler [17] developed a non-symmetric measure of the similarity or difference between two probability distribution functions. The divergence is not a distance metric; it is not symmetric and is a particular case of a broader class of divergences. It was introduced as a directed divergence in two distributions and can be derived from the Bregman divergence. This paper explores using generic feature representations learned by convolutional neural networks (CNNs) to process images' content and style. An algorithm based on the VGG19 neural network is implemented to perform style transfer, and two evaluation metrics, SSIM and KL, are applied to test the similarity and divergence of the produced images. Finally, malignant and benign skin lesions were classified using the EfficienNet B0 and B1 models. This approach combines a CNN-based parametric texture model with a method to invert the image representation, which allows for effective style fusion. This model not only stands out as an effective pre-processing strategy for deep learning-based applications but also has the potential to significantly improve the visual diagnosis performed by dermatologists in skin lesion analysis.
4 Methodology
4.1 Dataset
The HAM10000 database [13] is a fundamental reference in dermatology and computer vision, widely used to research and develop skin disease detection algorithms. This database contains high-resolution dermatoscopic images, including benign and malignant skin lesions. For this particular study, 700 images were carefully selected. They are evenly distributed (100 for each type of lesion), covering the seven most common classes of lesions: Actinic keratoses (AKIEC), basal cell carcinoma (BCC), benign keratosis-like (BKL), dermatofibroma (DF), melanoma (MEL), melanocytic nevu (NV) and vascular lesions (VASC). These images were primarily collected by the ViDIR Group of the Department of Dermatology at the Medical University of Vienna and by the Australian Skin Cancer Bureau, specifically the University of Queensland Medical School.
4.2 Skin Phototypes According to the Fitzpatrick Scale
The Fitzpatrick scale is a skin classification system developed by dermatologist Thomas Fitzpatrick in 1975 [14]. This scale is based on the skin's response to sun exposure and the amount of melanin Fig. 1. It classifies skin into six phototypes, from phototype I (light skin that always burns and never tans) to phototype VI (very dark skin that never burns and always tans, producing a dark brown tone). This work used six shades representing the six skin phototypes to create the styled images. Figure 2 presents the images with the shades of the six phototypes.

4.3 Image Style Transfer using CNN
Style transfer, an artificial intelligence technique based on convolutional neural networks (CNNs), is a process where a new image (output image) is created from two input images (a content image and a style image) using the style transfer algorithm [11]. This algorithm extracts structural features from the content image, such as edges or general shape, while it extracts information, such as texture or color, from the style image. This information is combined to generate the new output image, blending both input images. In dermatology, style transfer is used to enhance image quality and standardization. Both techniques, in turn, can profoundly impact diagnostic accuracy, ensuring more precise diagnoses and the efficiency of diagnostic support systems, enabling faster and more effective patient care. Previously, these algorithms required significant computational power. However, they have become more accessible and do not require excessive computational cost. The most critical hyperparameters and parameters of the transfer of estimate are shown in Table 1.
Table 1 Hyperparameters and parameters
| Hyperparameters | Parameters |
| Number of layers of filters: 19 Kernel size: 3 x 3 |
Epochs: 50 Learning rate: 1e-2 Value of alpha α: 1 |
| Activation function: ReLU Image size: 512 * 512 Max pooling: 2 x 2 |
Value of beta β: 1e-4 Optimizer: SGD |
Style and content features are generated using a VGG19 network. This network consists of multiple convolutional and clustering layers that learn hierarchical representations of the visual features in the images. Activations are extracted from the intermediate convolutional layers of the network to create style features. These activations represent texture and style patterns present in the reference style image.
On the other hand, activations are extracted from a specific convolutional layer that captures high-level semantic information in the network to generate content features. This layer is generally located near the network output, where the activations represent abstract images. Once the style and content features have been extracted from the images, they are used to compute the Gram matrices of the style and content layer activations. These matrices capture the statistical correlations that combine a reference style image with a reference content image.
The loss functions used are the style and content loss functions. Lstyle loss is calculated by comparing the Gram matrices of the style layer activations between the generated and the reference style images. The style loss function is defined as the difference between the Gram matrices of the style layer activations of the generated image and the reference style image.
The goal is to minimize this difference so that the generated image is styled similarly to the reference style image. The content loss Lcontent is calculated by comparing the activations of a content layer between the generated image and the reference content image. The content loss function is defined as the difference between the activations of the content layer of the generated image and the reference content image. The objective is to minimize this difference so that the generated image retains the semantic content of the reference image.
These losses are combined in a loss function:
where: Ltotal is the total loss, Lcontent is the content loss, Lstyle is the style loss, α is a weight parameter (tends to 1), and β is a weighing parameter (tends to 0).
This loss function is minimized using optimization algorithms such as stochastic gradient descent (SGD). By minimizing this loss function, the optimization algorithm adjusts the pixels of the generated image so that both the style and the content resemble the reference images. The formulas used in the context of the style transfer algorithm to optimize a generated image so that it matches both content and style to a reference image are as follows:
These formulas calculate the losses. The style loss equation (5) focuses on capturing the style characteristics of the reference image. Meanwhile, the content loss equation (6) focuses on maintaining the essential content of the original image. The total loss equation (7) combines both to guide the optimization process toward a final image that achieves the desired balance between content and style.
In Figure 3, an example of the result of applying the style transfer algorithm to a skin lesion image (dermatofibroma) with a phototype I is presented.
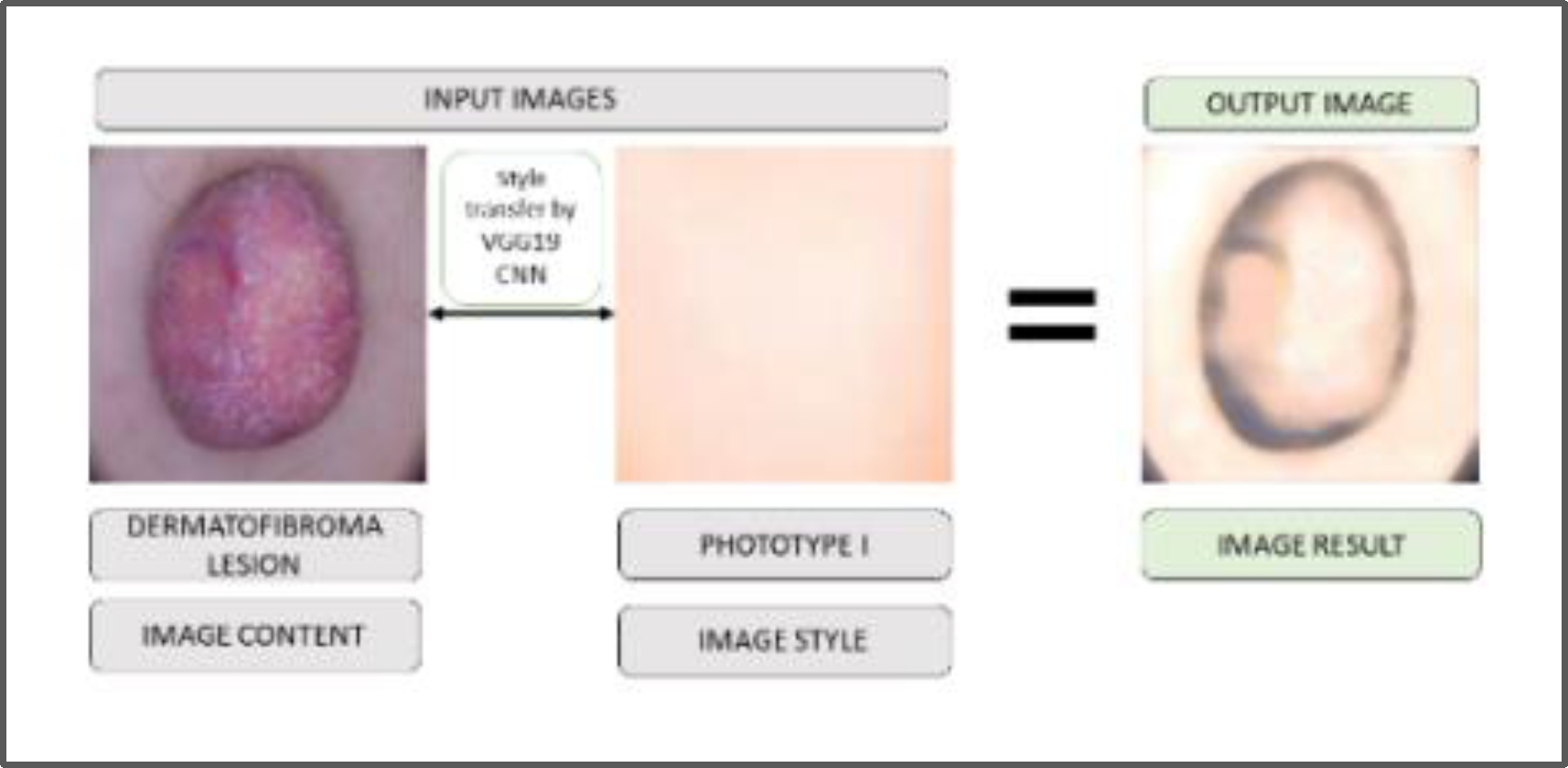
Algorithm 1 shows the pseudocode describing the style transfer process using the method proposed by [5], implemented in this work.

5 Experimental Study
5.1 Key Elements of the Method
Key elements of the method are described as follows:
Dataset Selection: The HAM10000 dataset, widely used in dermatology and computer vision, collected 70 clinical images of seven common skin lesions.
Neural Network Model used (VGG19): The VGG19 convolutional neural network model was employed for dermatological image generation of skin lesions. This architecture is known for its efficiency in extracting visual features from images.
Style Transfer: The technique based on the algorithm proposed by Leon A. Gatys was implemented using convolutional neural networks. This technique allows combining the content of one image with the style of another, thus generating new images that preserve structural and characteristics.
Image Pre-processing: Before applying for the style transfer, images were pre-processed to adjust to the appropriate size and format for the VGG19 model.
Hyperparameter Optimization: The style transfer algorithm's hyperparameters, such as image size, optimizer, learning rate, and number of epochs, were adjusted to obtain optimal results.
Evaluation of Generated Images: Image evaluation metrics, such as Structural Similarity Index (SSIM) and Kullback-Leibler (KL) Divergence, were used to measure the quality and similarity between the generated images and the reference images.
Classification of Skin Lesions: Malignant and benign skin lesions were classified using the EfficientNet B0 and B1 models.
Results and Analysis: The results obtained by applying the style transfer algorithm to different types of skin lesions and skin phototypes were presented. In addition, the results were analyzed in terms of the evaluation metrics used.
These elements constitute the primary methodology of the study and hopefully provide a better understanding of how the style transfer technique was applied.
5.2 Retrained Architectures
Seventy representative images of seven benign and malignant skin lesions were selected equally from the HAM10000 dataset. These images were distributed into seven sets, each comprising ten images corresponding to the seven most common skin lesions.
The style transfer algorithm (CNN) was implemented during this stage using the VGG19 architecture. Finally, two evaluation metrics, SSIM and KL, were applied.
5.3 Implementation of Style Transfer Algorithm
Fig. 3 shows the result obtained by applying the VGG19 style transfer algorithm in skin phototype I and the results of the evaluations generated by the two metrics applied to seven different skin lesions.
5.4 Results of Style Transfer Algorithm and Evaluation Metrics
Figs. 4a to 4g show the results obtained by applying the VGG19 style transfer algorithm to seven images corresponding to seven skin lesions in six different skin phototypes and the results of the evaluations generated by the two metrics applied to seven different types of skin lesions.
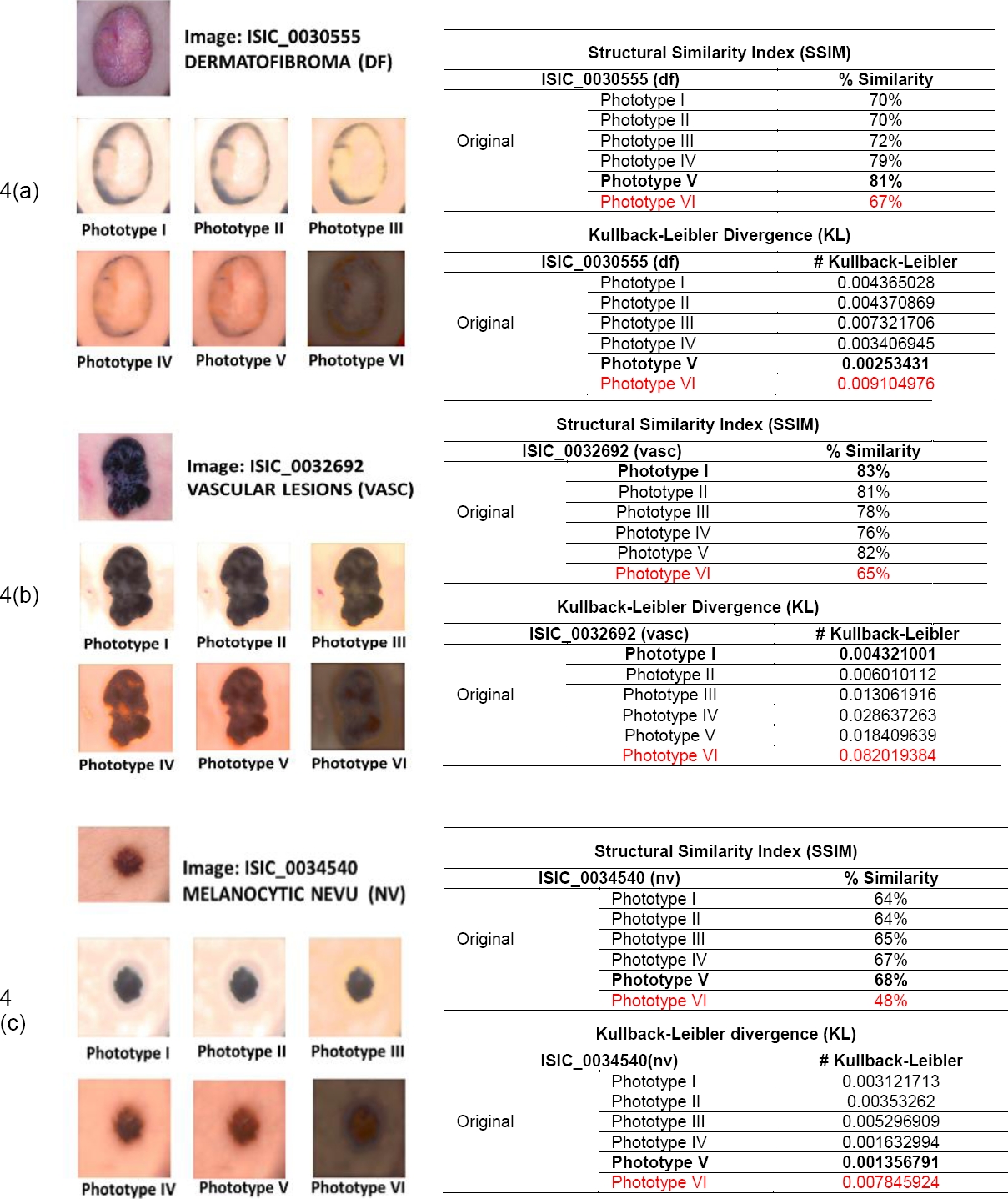
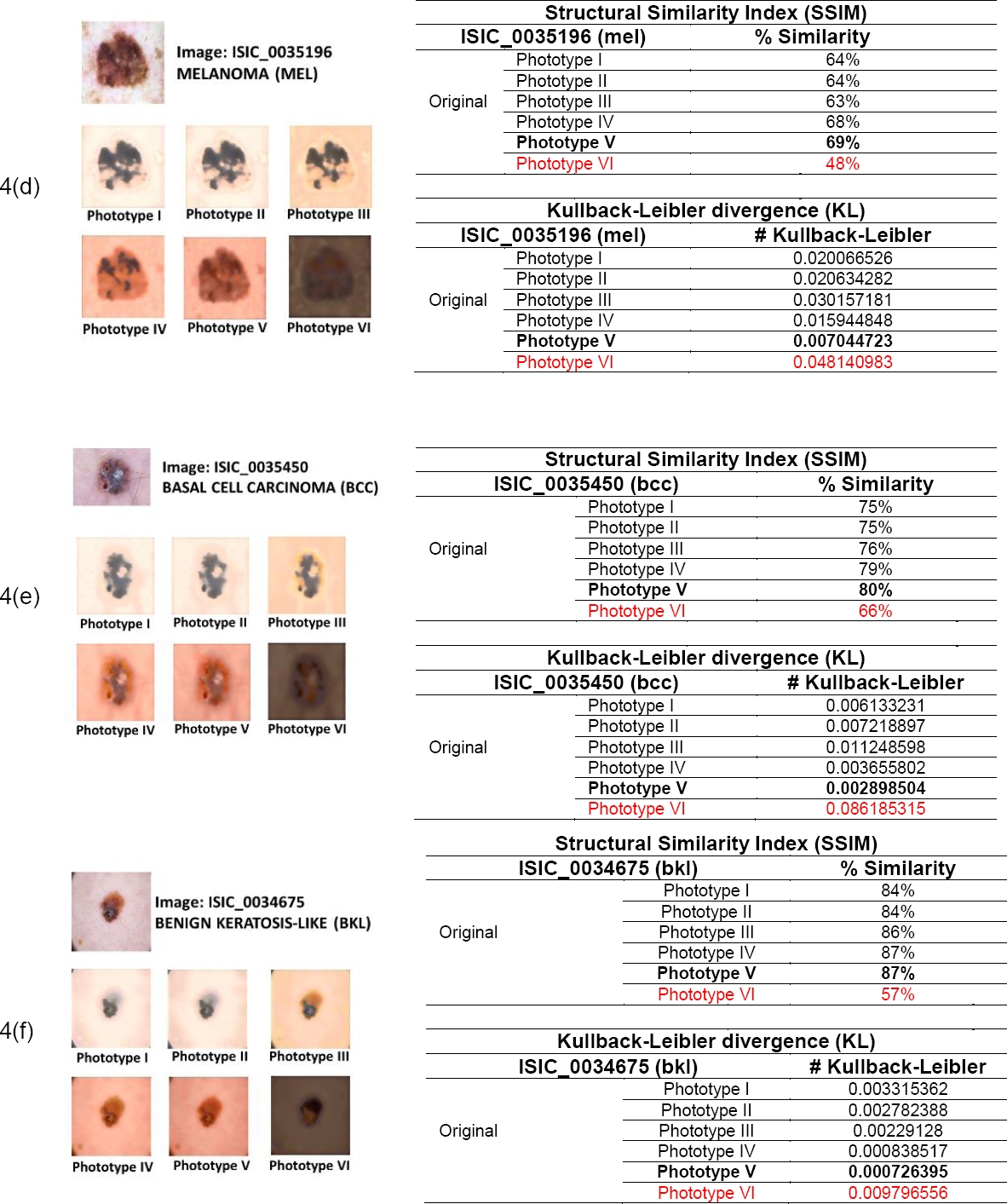
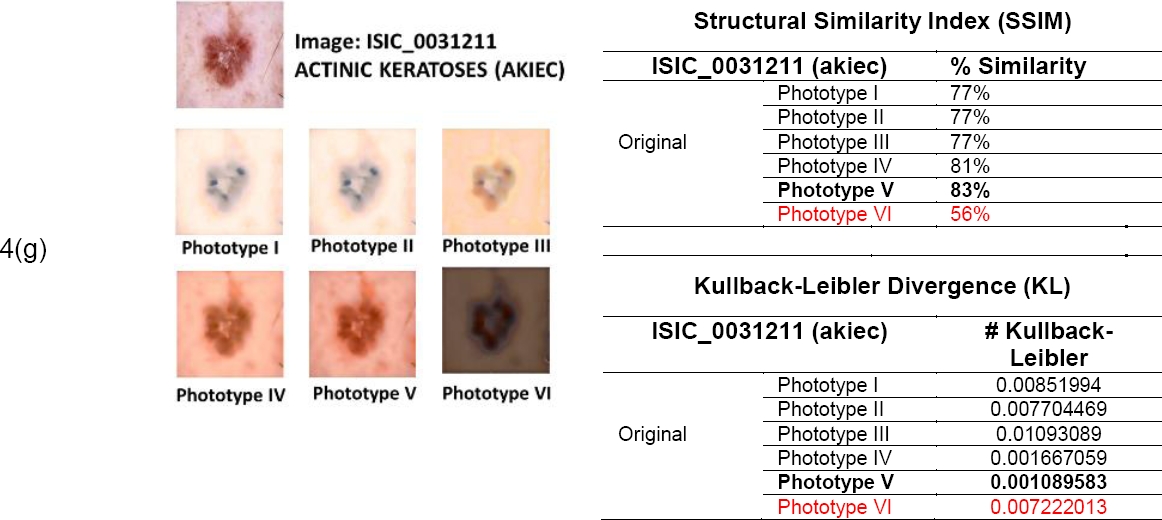
5.5 Classification of Phototype VI Skin Lesions using the EfficientNet Model
Images corresponding to phototype VI were generated to classify skin lesions. They were equally distributed between malignant and benign lesions of the most common classes, such as Actinic Keratosis (AK), Benign Keratosis (BKL), Basal Cell Carcinoma (BCC), Seborrheic Keratosis (SK), Carcinoma (C), Dermatofibroma (DF) and Melanoma (MEL).
One hundred forty images were generated from the HAM10000 dataset using the style transfer technique implemented in this work, thus obtaining a new brown skin database, PhotoVI BS.
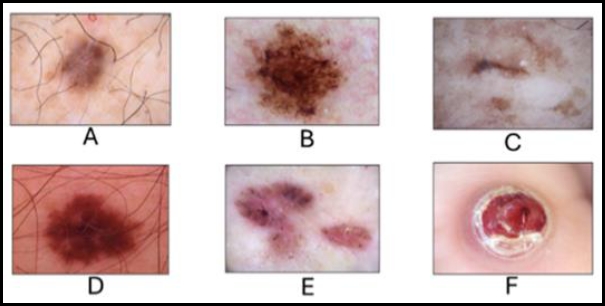
The following figure, Fig. 5, shows images of the most common skin lesions in the HAM10000 dataset.
5.6 Result of Classification of Skin Lesions by CNN
The following table (Table 2) shows the values obtained and the plot of the accuracy measure. A new database was generated by applying the style transfer (ST) technique, specifically phototype VI (PhotoVI BS). Some examples of this new dataset are shown in Figure 6. We used 140 images from the HAM10000 and PhotoVI BS datasets, equally distributed between malignant and benign categories, with 70 images in each category (the number of images is reduced to facilitate training without excessive use of computational resources). The images were divided into training and validation sets, with a 90% and 10% ratio, respectively. At this stage of the work, the two models used (EfficientNet B0 and B1) were retrained and adjusted.
Table 2 Results of the classification
| Databases | Model CNN | Epochs | ||||||
| 30 | 100 | 500 | 1000 | 1500 | 2000 | 5000 | ||
| HAM 10000 | EfficientNet B0 | 55.00% | 40.00% | 69.00% | 65.00% | 65.00% | 70.00% | 68.75% |
| PhotoVI (BS) | EfficientNet B0 | 64.28% | 67.85% | 71.42% | 71.42% | 57.14% | 60.71% | 67.85% |
| HAM 10000 | EfficientNet B1 | 43.75% | 75.00% | 68.75% | 56.25% | 68.75% | 50.00% | 68.75% |
| PhotoVI (BS) | EfficientNet B1 | 57.14% | 64.28% | 60.71% | 71.42% | 64.28% | 75.00% | 67.85% |
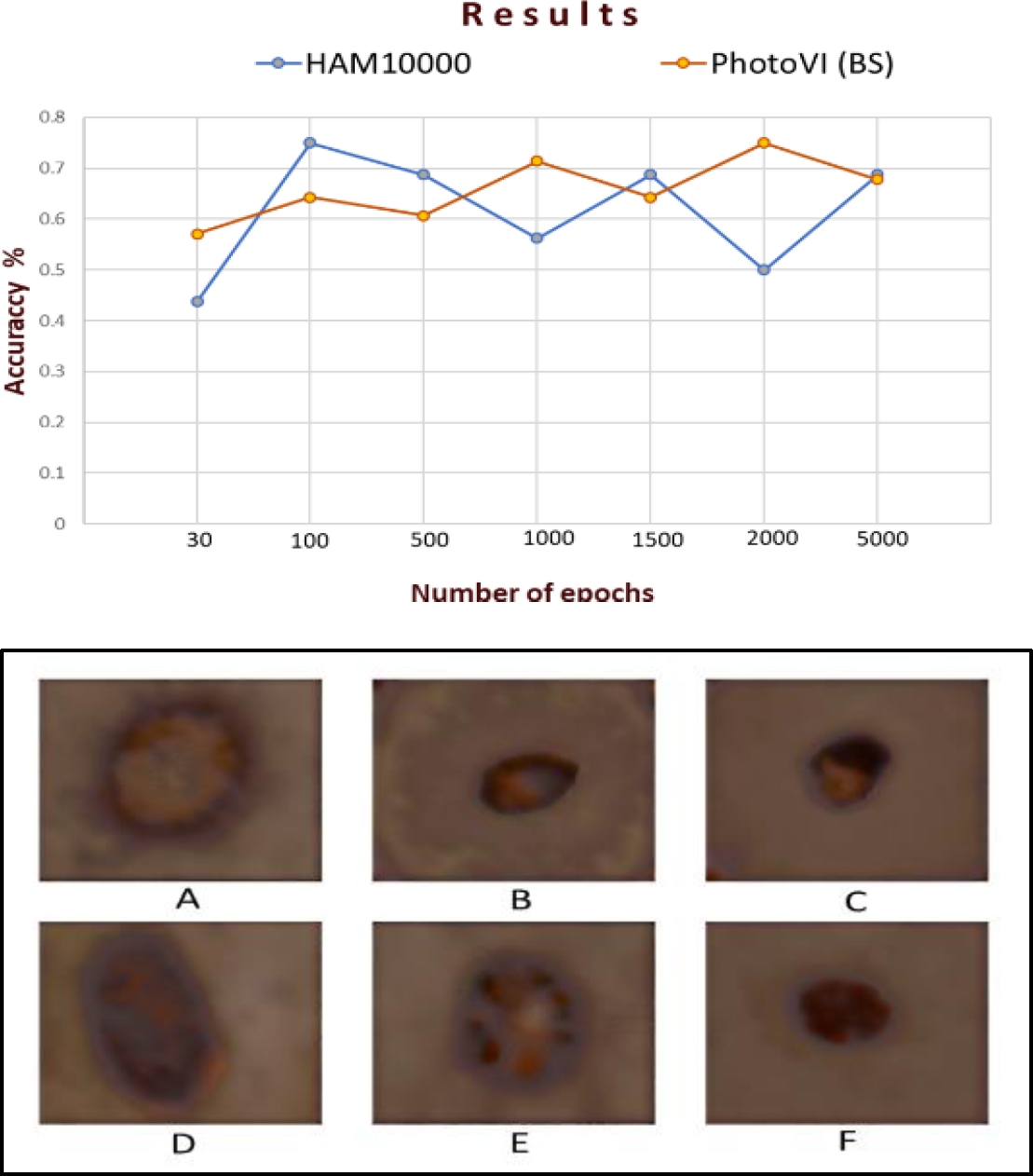
It can be observed that the best value obtained in the HAM10000 database (white skin) using the EfficientNet B0 model was 70% with 2000 epochs, while for the PhotoVI BS database, it was 71.42% with 500 and 1000 epochs, respectively. Furthermore, for the EfficientNet B1 model, the HAM10000 database obtained 75% with 100 epochs, equaling PhotoVI BS with the same value but with 2000 epochs. These results show that it is possible to classify skin lesions in dark skin (phototype VI) using our PhotoVI BS database.
5.7 Final Remarks
This work has shown that skin phototypes are essential as they significantly influence the accuracy of dermatological lesion analysis. The reasons can be diverse, such as the amount of training data, the contrast of the lesions, the illumination at the imaging time, and the model's generalization. For phototype V, which represents a more common skin tone in Mexico, the model has been trained more effectively due to the availability of a significant amount of training data. However, the model has difficulty distinguishing between the different classes for phototype VI, which has fewer common features in the dataset and shares similarities with other classes, such as color, texture, and borders. This resulting confusion contributes to lower accuracy in skin lesion classification for phototype VI compared to phototype V.
6 Conclusion
This study demonstrates the feasibility of using convolutional neural networks (CNN), specifically the VGG19 architecture, to perform style transfer.
Also, the study demonstrates the outstanding performance of the proposed approach. An essential part of this work was the application of similarity and divergence evaluation metrics, which allowed us to assess the technique's effectiveness accurately. These metrics revealed positive results, demonstrating that Style Transfer enhances and standardizes images, synthesizes textures, and preserves the original content, thus generating consistent, high-quality images. In addition, Style Transfer was found to facilitate image analysis, which is important because, in dermatological diagnostics, image quality and clarity are essential for accurate assessment. Style transfer is a promising technique to improve image generation quality, and applying evaluation metrics to these images will undoubtedly be crucial to validate their performance. These metrics need to be further explored and refined to ensure reliable evaluations.

