











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
Computer vision focuses on training computers to acquire, process and analyze digital images to extract meaningful information and perform a wide range of tasks [11] such as image classification, object recognition, object tracking, object location, image segmentation, image retrieval, pattern recognition to name a few.
To perform these tasks, various methods can be employed. Among them are convolutional neural networks (CNN), which have shown great success in object recognition. Their ability to capture relevant patterns and features at different spatial scales has been the key to their success and applicability in various areas [10].
In object recognition, one of the main challenges is the scarcity of labeled data. Obtaining large data sets can be costly and laborious. Also, objects can change in terms of size, shape, orientation, illumination, and background, which makes the task of recognition models difficult. In addition, models must be trained on data sets that are diverse and representative of real-world situations, which can be difficult to obtain.
Problems such as those described above can be encountered in a materials synthesis laboratory which has highly specialized equipment and materials, so the scarcity of labeled data limits the ability to train models to help within the laboratory. This paper presents the development of a set of images containing 7 particular objects which are: beaker, flask, vial, cuvette, sample holder, precisión pipette and 3-mouth flask as seen in Figure 1.
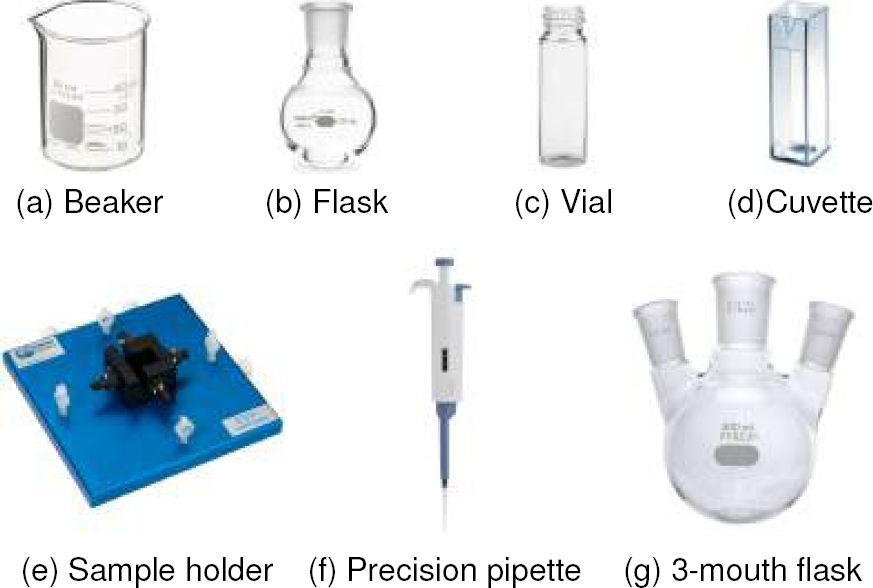
Fig. 1 Material synthesis laboratory instruments selected for the development of the customized image set
In addition, the usefulness of the image set is demonstrated by training a CNN with it, managing to identify the specialized objects.
2 Related Work
Datasets with large amounts of images that are commonly used for CNN training such as Common Objects in Context (COCO) [8] which contains 330 000 images with 80 object categories, another set used is Objects365 [9] which contains 365 object categories with more than 2 million images.
On the other hand Roboflow 100 [2] is a dataset that covers a wide range of domains and contains real world images representing everyday scenarios. ImageNet [3] is a massive dataset containing over 14 million carefully selected and annotated images, the images cover a wide range of categories. While these sets offer a wide range of categories, they do not specifically cover laboratory instruments used in materials synthesis. There are specialized databases in the literature that focus on these types of instruments.
“LabPics V1” contains 2187 images in 61 categories of chemical experiments with materials inside mostly transparent containers in various laboratory settings and under everyday conditions. Each image in the data set has an annotation of the region of each material phase and its type [5]. For its second version the “LabPics V2” dataset contains 10 528 annotated images.
The images are divided into two sets: a training set with 8 422 images and a test set with 2 106 images. The images in the “LabPics V2” dataset were obtained from a variety of sources, including images from real laboratories, images from laboratory simulations among others. [6], some examples of the images contained in the set are shown in the figure 2.

A more recent work is “Chemistry Laboratory Apparatus Dataset” (CLAD) which contains 21 different types of chemical laboratory instrument images, with no less than 200 images of each type, mainly glass instruments are carefully labeled with chemistry student information. Each image may contain one or more images of chemical instruments [4] as the images shown in the Figure 3.

After reviewing the image sets found in the literature, it has been found that there is no set that includes the 7 selected objects from a materials synthesis laboratory as shown in the table 2. Therefore, the creation of an own image set becomes necessary.
Table 1 Type of images contained in each set as well as the number of categories
| Laboratory equipment imaging datasets | |||
| Name | Type of images | Number of images | Number of categories |
| COCO | Animals, people, vehicles, furniture, kitchen utensils, musical instruments, sports, cities, landscapes, fields, food, wild animals and domestic objects. | 330000 | 80 |
| Objects365 | Real-world objects in various conditions of illumination, pose, size, shape, and background | 2 millones | 365 |
| Roboflow 100 | Images of airplanes, drones, cells, tissues, sea creatures, documents, radar fields, animals, plants, objects, people, places, events, transportation, art, fashion, food and text. | 232000 | 828 |
| Imagenet | Wide variety of images, including animals, plants, objects, people, places, events, transportation, art, fashion, food, text and much more. | 14 million | 22000 |
| LabPics | V1* Materials and vessels in chemistry laboratories. | 2187 | 61 |
| LabPics | V2* Materials and vessels in chemistry and medical laboratories. | 10528 | 61 |
| CLAD* | Chemistry laboratory instruments. | 2246 | 21 |
*These are sets specialized in laboratory objects
Table 2 Objects that are recognized by the sets of images found in the literature
| Image set | Selected objects of a materials synthesis laboratory | ||||||
| Flask | Vial | Sample holder | Precision pipette | Cuvette | Beaker | 3-mouth flask | |
| COCO* | 55 | 55 | 55 | 55 | 55 | 55 | 55 |
| Objects365* | 55 | 55 | 55 | 55 | 55 | 55 | 55 |
| Roboflow 100 | 55 | 55 | 55 | 55 | 55 | 55 | 55 |
| Imagenet | 55 | 55 | 55 | 55 | 55 | 51 | 55 |
| LabPics V2 | 51 | 51 | 55 | 55 | 55 | 51 | 55 |
| CLAD | 51 | 55 | 55 | 55 | 55 | 51 | 51 |
3 Development
The elaboration of a set of customized images involves a series of steps ranging from image collection and labeling, to data augmentation and final evaluation of the set.
The first task performed was to capture color images of the selected objects using a 2D camera with a capture resolution of 1080×1920 pixels obtaining a total of 673 images. However, the set of images generated was very small, since only 673 images for CNN training do not ensure optimal results.
Therefore, we resorted to using data augmentation techniques, the study conducted by [7] shows the different data augmentation techniques and that the use of these techniques can improve the accuracy between 2.83% and 95.85%.
Of the techniques shown in this study we use geometric transformations and color space transformations.
These techniques were implemented in Python with the help of the albumentations library [1], the operations that were performed are random crop, horizontal and vertical flip, random rotation, grayscale, random blur, random noise insertion, random color and finally color inversion. With this implementation, 5597 images were obtained; Figure 4 shows the transformations used. Once the images were captured, they were manually labeled using the open source software Label Studio [13],a very helpful tool for labeling images in a simple way as shown in figure 5.


4 Experiments and Discussion
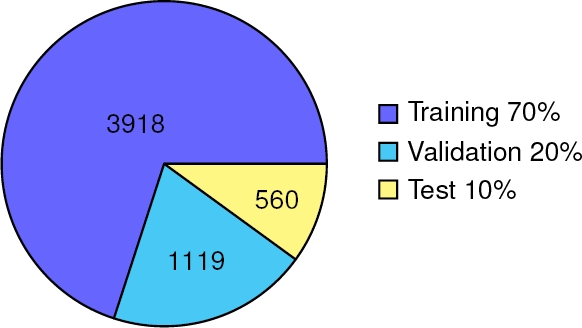
To demonstrate the usefulness of the set of images generated, the retraining process of an existing CNN was carried out in this case YOLO-NAS, which is a new YOLO model launched in 2023, YOLO-NAS developed by Deci manages to improve the speed and accuracy of the previous versions [12]. For training, the set was divided with the distribution that is normally used, 70% for training, 20% for validation and 10% for test.
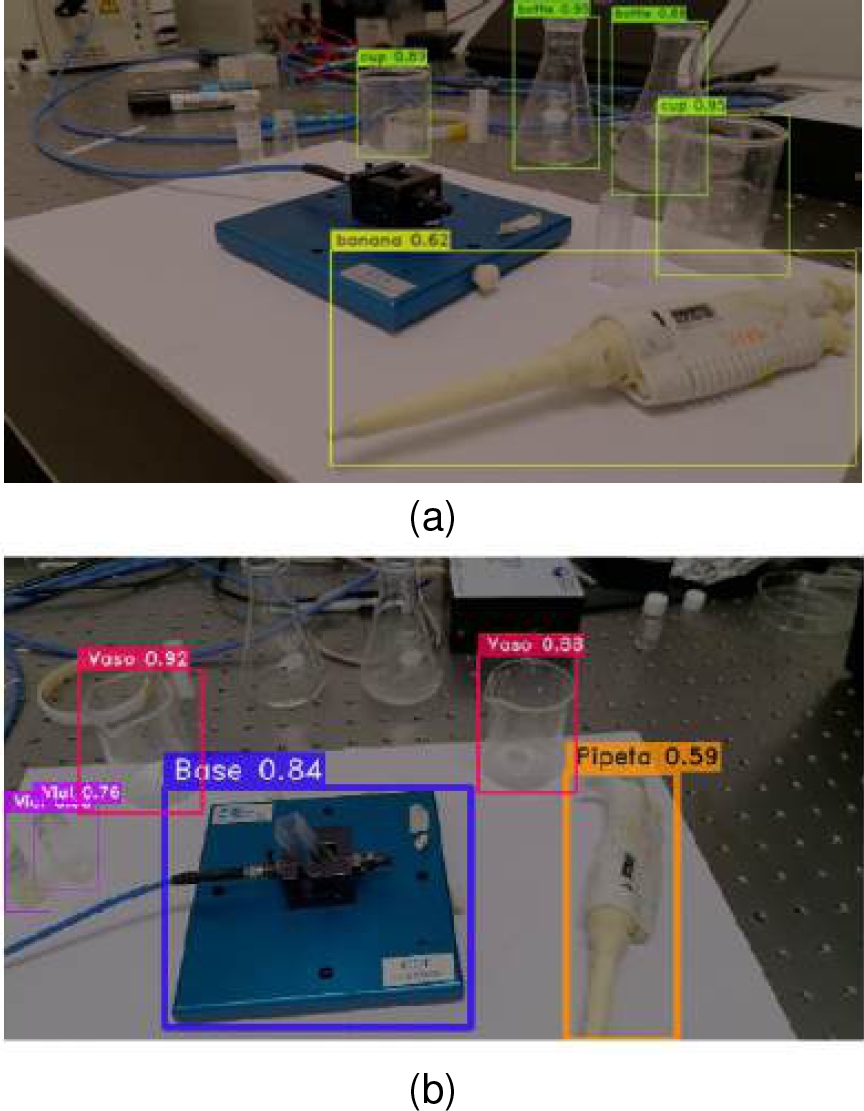
The distribution of the images is shown in graph 6. Later, the obtained detection was compared between the model without the retraining process and the retrained model using our custom dataset. There was a noticeable difference, as seen in figure 7, where some predictions did not match the actual objects despite having a high confidence level. In contrast, our model correctly identifies the selected objects and achieves a mean Average Precision mAP@0.50 of 0.93.
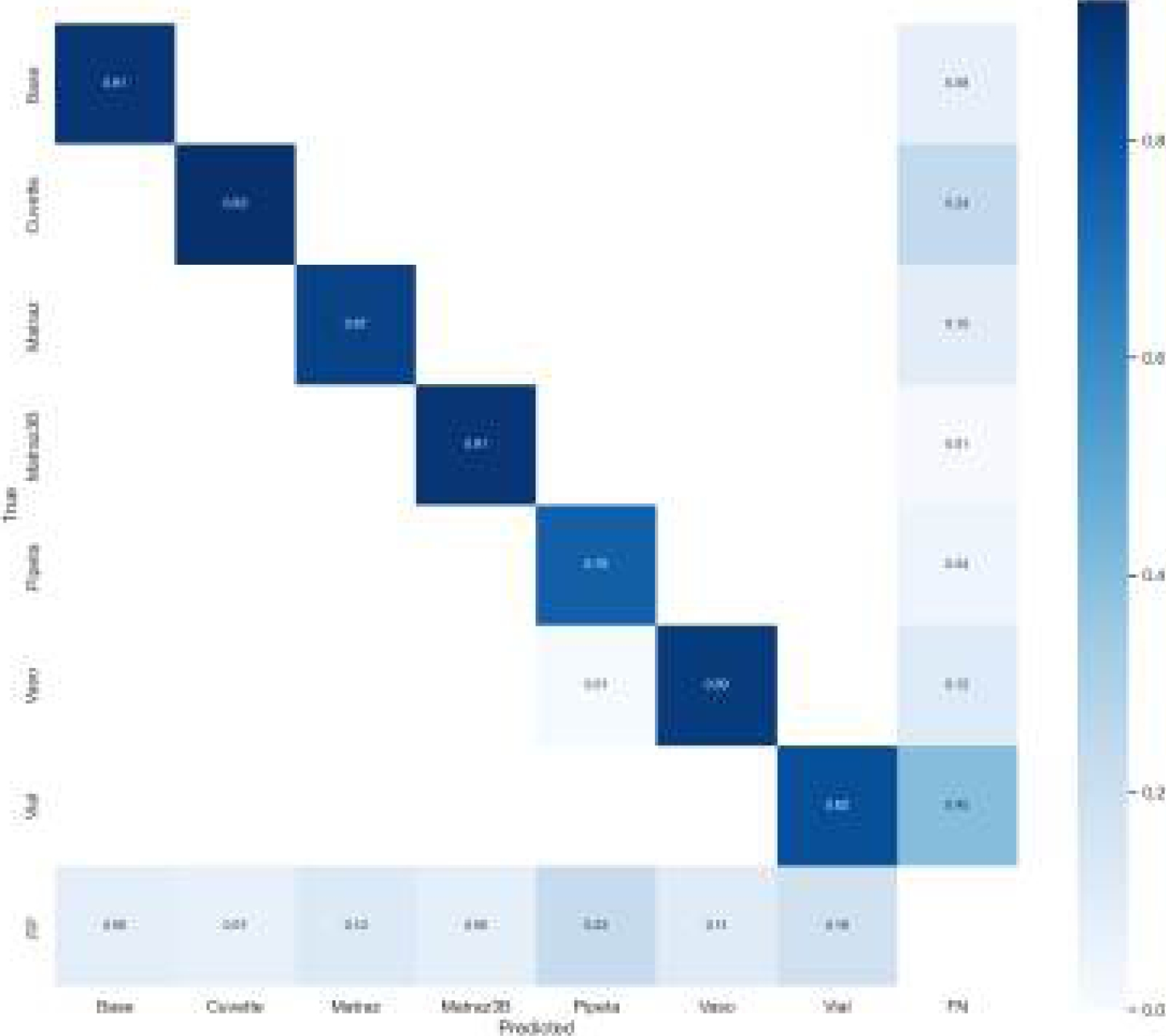
The confusion matrix shown in figure 8 reveals values greater than 0.75 on the diagonals, indicating high classification accuracy. Furthermore, the values of false positives (FP) and false negatives (FN) are very low, which confirms the reliability of our model.
5 Conclusions and Future Work
In this work, a set of images was generated that allows a CNN to identify particular objects such as chemical instruments used in materials synthesis laboratory environments.
Initially, 673 images were obtained, but with the implementation of data augmentation techniques, 5597 were obtained.
Images, thus managing to adequately retrain a CNN and obtaining a mean Average Precision mAP@0.50 of 0.93. The importance of creating custom image sets for application to specific problems should be highlighted. CNNs trained with custom image sets perform better than CNNs trained with generic image sets. This advantage is due to the greater precisión in the identification of specific instruments, avoiding confusion such as identifying a beaker and a flask as a “bottle” using generic sets of images.
A methodology has been proposed for creating customized image sets that adapt to the specific needs of the problem. As future work, it is proposed to create an identification system with the generated set and test it in real environments. It is worth mentioning that this set will be a fundamental piece if at some point it is necessary to automate processes within a materials synthesis laboratory, for example the spectroscopy process, since to achieve this these objects must first be identified.

