











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
In recent years, there has been an exponential growth in Natural Language Processing (NLP), mainly due to the emergence of Neural Language Models (NLMs). The introduction of Transformer-based models, initiated by the release of pioneering models such as BERT [10], has guided a new era in NLP methodologies.
These advances have steadily boosted achievable performance in a plethora of tasks in different domains across different languages [15, 19], ranging from general-purpose tasks such as sentiment analysis [27], information extraction [37, 18] or anaphora and coreference resolution [34, 43, 20], to very domain-specific verticalized approaches [47, 21, 29, 25, 36, 46]. Concurrently, resources, corpora, and collections of benchmark datasets suitable for different applications [5, 38] have flourished as the models have progressed in complexity, requiring a massive amount of annotated data in training. Although text classification has always occupied a priority place among the ”classic” NLP tasks, this enormous data availability has given it a crucial role [24].
In the NLP field, text classification is usually formalised as follows: automatically classifying and arranging massive amounts of textual input into predetermined categories or classes. An algorithm is trained on a labelled dataset of examples and their pre-tagged classes for text classification or categorisation.
The system uses this training data to generalise and categorise new, unseen text into one of the pre-defined groups. The primary issue in text categorisation is finding pertinent details or patterns that distinguish the various groups. Naive Bayes, Support Vector Machines, Decision Trees, Random Forests, and Neural Networks are the few well-known machine learning techniques for text categorisation [24, 35]. CNN and RNN have recently exhibited outstanding results in text categorisation tests [4].
These models can develop meaningful representations of the text data and capture complicated linkages and dependencies in the text [54]. However, text classification faces various limitations hindering its effectiveness. Some are inherent limitations to natural language processing, such as ambiguity, multi-word expressions, specialised lexicons, and language-dependent phenomena, which have always been challenging for NLMs.
Another type of problem stems from extrinsic limitations, such as unbalanced datasets, models not trained on a specific domain, onerous computational costs, or ineffective evaluation metrics. Starting from these premises, this work aims to enhance the accuracy of multi-class text classification by leveraging pre-training methodologies and exploiting the language abilities of BERT.
While this NLM has demonstrated its effectiveness in various language understanding (NLU) tasks, its adaptation for multi-class categorisation remains a debated topic with many open issues. Besides using BERT as NLM, the present approach benefits from the transfer learning algorithm and integration of cross-validation techniques; this hybrid integration helps overcome traditional models in terms of accuracy and resource efficiency. The annotated dataset chosen to experiment is the 20 Newsgroups collection [2], a de facto benchmark dataset for multi-class text classification in NLP.
The dataset has been cleaned up and prepared to be optimised for the fine-tuning phase of BERT, to which a classification layer has been added. Concerning evaluation, comparative analyses with existing models estimate the methodology’s effectiveness in content classification and sentiment analysis.
The paper is structured as follows. Section 2 provides an overview of the recent related works. Section 3 describes the research methodology, including the NLM and dataset details. Section 4 describes the experimental assessment and then presents and discusses the results. Finally, Section 5 summarises the paper and hints at future developments.
2 Related Work
Rehman et al. [4] proposed a filter-based feature selection algorithm called Normalized Difference Measure (NDM) for text classification tasks. The study compared the performance of NDM with seven other feature selection algorithms (ODDS, CHI, IG, DFS, GINI, ACC2, POISON) using Support Vector Machine (SVM) and Naive Bayes (NB) classifiers.
The research aimed to demonstrate how removing irrelevant and redundant features through NDM could enhance the performance of text classification models. The experimentation conducted by Rehman et al. showed that NDM significantly improved the classification accuracy on the 20 Newsgroups dataset.
The study highlighted the importance of feature selection in optimizing text classification models. It showcased the effectiveness of NDM in enhancing classification performance compared to other feature selection algorithms when used in conjunction with SVM and NB classifiers. Another study claims that to improve on their earlier Normalized Difference Measure (NDM) algorithm, Rehman et al. [4] developed a new version of the filter-based feature selection algorithm called Maximum Margin Ranking (MMR). The study combined MMR’s effectiveness for text classification tasks with SVM and NB classifiers to assess MMR’s effectiveness for text classification tasks.
By comparing MMR with NDM, the researcher aimed to demonstrate the improvements in classification accuracy achieved through the enhanced feature selection algorithm. The experimentation conducted by Rehman et al. showed that MMR outperformed NDM, achieving a significant performance improvement.
The study highlighted the importance of continuous refinement and development of feature selection algorithms to enhance the effectiveness of text classification models, showcasing the advancements made by MMR in improving classification accuracy when integrated with SVM and NB classifiers. Lai et al. [4] introduced a Modified CNN (Convolutional Neural Network) approach for text classification.
Their model utilized a multi-channel CNN architecture with specific modifications to enhance performance. The study focused on classifying text documents into four classes: comp, politics, rec, and religion. The Modified CNN model achieved an impressive accuracy of 96.49% on these four classes, showcasing the effectiveness of their approach in text classification tasks. Aziguli et al. [4] proposed an Autoencoder-based approach for text classification.
Their methodology utilized a denoising deep neural network (DDNN) that incorporated a restricted Boltzmann machine (RBM) and denoising autoencoder (DAE). By leveraging the DDNN model, the researchers aimed to reduce noise in the data and improve feature extraction for text classification tasks. The Autoencoder approach successfully enhanced feature extraction performance, showcasing its potential in text classification applications.
Jiang et al. [4] proposed a hybrid text classification model that combined a Deep Belief Network (DBN) with Softmax regression for text classification tasks. The DBN was utilized for feature extraction, while Softmax regression was employed to classify textual data. This hybrid approach addressed the challenge of computing high-dimensional sparse matrices in text classification.
The researchers reported that their hybrid methodology outperformed traditional classification methods on benchmark datasets, highlighting the effectiveness of combining DBN with Softmax regression for text classification. Liu et al. [4] presented an attentional framework based on deep linguistics that incorporated concept information from meta-thesauri into neural network-based classification models.
The researchers utilized MetaMap and WordNet to annotate biomedical and general text, respectively, enhancing the understanding of text content for classification tasks. By leveraging meta-thesauri and deep learning techniques, Liu et al. aimed to improve the performance of text classification models by incorporating rich concept information into the classification process.
Shih et al. [4] researched using Siamese Long Short-Term Memory (LSTM) networks for text categorization. The researchers proposed a deep learning methodology based on Siamese LSTM networks to enhance the learning of document representations for text classification tasks. By leveraging LSTM networks, Shih et al. aimed to improve the performance of text classification models by effectively capturing the sequential dependencies and context within textual data. Their study demonstrated promising results, achieving a performance of 86% on the 20 newsgroup dataset, showcasing the effectiveness of LSTM-based approaches in text classification. Shirsat et al. [4] researched sentiment identification at the sentence level using positive and negative word lists from the Bing Liu dictionary.
The study used machine learning techniques for sentiment analysis tasks on news articles, specifically Support Vector Machine (SVM) and Naive Bayes (NB) classifiers. Shirsat et al. reported a performance of 96% using the SVM classifier on the BBC news dataset, highlighting the effectiveness of SVM in sentiment identification at the sentence level. The study showcased the application of traditional machine learning algorithms like SVM and NB in sentiment analysis tasks, emphasizing their performance in text classification.
Camacho-Collados and Pilehvar [4] conducted a study on the role of text preprocessing in neural network architectures for text categorization and sentiment analysis tasks. The researchers evaluated different preprocessing practices to train word embeddings for text classification. They experimented with two versions of Convolutional Neural Networks (CNN): a standard CNN with Rectified Linear Unit (ReLU) activation function and a standard CNN with the addition of a recurrent layer (LSTM).
Their study aimed to enhance the accuracy of text classification models by optimizing text preprocessing techniques and neural network architectures. The experimentation achieved an accuracy of 97% on the BBC dataset and 90% on the 20-newsgroup dataset using six classes, demonstrating the impact of effective preprocessing on improving the performance of CNN and LSTM-based models for text classification.
Pradhan et al. [4] compared different machine learning classifiers for text classification tasks on news articles. The researchers evaluated the performance of various machine learning algorithms on topic categorization. Pradhan et al. compared the effectiveness of different classifiers in accurately categorizing news articles into relevant topics.
The study aimed to identify the most suitable machine learning classifier for text classification based on the performance metrics evaluated. Their research provided insights into the comparative analysis of machine learning classifiers for text classification tasks, contributing to understanding the strengths and limitations of different classification algorithms in handling textual data.
Elghannam et al. [4] focused on text representation and classification based on a bi-gram alphabet approach. The study proposed a methodology that utilized bi-gram frequencies for representing documents in a typical machine learning-based framework. By leveraging bi-gram features, Elghannam aimed to address the challenge of data sparsity and improve the representation of textual data for classification tasks.
The research did not rely on Natural Language Processing (NLP) tools and demonstrated significant improvements in alleviating data sparsity. Elghannam reported an F1 score of 92% on the BBC news dataset, highlighting the effectiveness of the bi-gram alphabet approach in feature representation for text classification tasks.
The study contributed to enhancing the performance of machine learning classifiers by optimizing the representation of textual data through bi-gram features. Wang et al. [4] presented a transfer learning method for text classification in cross-domain scenarios.
The study addressed the challenge of classifying text data from different domains by leveraging transfer learning techniques. Wang et al. conducted experiments on six classes of the 20 newsgroup dataset to evaluate the performance of their transfer learning approach.
By transferring knowledge from one domain to another, the researchers aimed to improve the classification accuracy in cross-domain text classification tasks.
The methodology proposed by Wang et al. demonstrated promising results, achieving a performance of
The study highlighted the effectiveness of transfer learning in enhancing text classification models’ performance across different domains, showcasing the potential of transfer learning techniques in handling cross-domain text classification tasks.
Asim et al. [4] proposed a two-stage text document classification methodology that combines traditional feature engineering with automatic feature engineering using deep learning. The methodology employs a filter-based feature selection algorithm to develop a noiseless vocabulary fed into a multi-channel Convolutional Neural Network (CNN).
Each CNN channel consists of two filters of different sizes and two dense layers. By utilising wide convolutional layers, the methodology aims to address the issue of unequal feature convolution in traditional CNN models. Experimental results showed that feeding only the most discriminative features of the vocabulary to the CNN model improved performance significantly compared to using the entire vocabulary. The study also discussed the potential for further assessment of the methodology using Recurrent Neural Networks (RNN) and other hybrid deep learning approaches.
In another research work, Asim et al. [4] proposed a robust hybrid approach for textual document classification, which combines traditional feature engineering with automatic feature engineering using deep learning techniques. The methodology involves a two-stage classification process: the first stage focuses on feature selection using a filter-based algorithm to develop a noiseless vocabulary. In contrast, the second stage utilises a multi-channel Convolutional Neural Network (CNN) model for classification.
By integrating traditional and deep learning approaches, the proposed methodology aims to improve the classification accuracy of textual documents by addressing issues such as data sparsity and feature representation. The study demonstrates the effectiveness of the hybrid approach in outperforming state-of-the-art machine learning and deep learning-based text classification methodologies on public datasets.
In Natural Language Processing (NLP), text classification is a common task that has been studied for a long time. One popular model used for this task is BERT, which is based on transformers. Researchers often use BERT to see how well it works compared to other techniques. However, they face challenges like overfitting (when the model fits too closely to the training data), imbalanced classes (when some classes have too few examples), low performance, and issues with computational resources.
Many research papers have been done to tackle these problems and improve text classification performance using models like BERT. Yusuf et al. [3] proposed evaluating pre-trained language models (PLMs) for multi-class text classification in finance. They followed BERT’s methodology, testing model performance at 1, 3, and 5 epochs using the Adam optimizer. Challenges like convergence issues or overfitting may have impacted model effectiveness, emphasising the need for careful parameter selection. Their study aims to compare PLMs’ effectiveness in financial text classification and address potential evaluation challenges.
Vedangi et al. [49] proposed using the BERT model to enhance the accuracy of long document classification tasks, particularly focusing on the 20 Newsgroups (20NG) dataset. To optimise the model’s performance, the authors implemented the Adam optimizer during the model training process, alongside gradient descent and a cross-entropy loss function. The primary purpose of employing the BERT model was to leverage its advanced capabilities in capturing complex relationships within text data, thereby improving the overall classification accuracy on the dataset of interest.
Wang et al. [50] proposed training downstream models with an Adam optimizer using a learning rate of 0.001. The models were trained for 140 epochs with early stopping based on accuracy evaluated on the development set. The study highlighted the advantages of BERT over ELMo in datasets such as 20NewsGroup, Reuters, and AAPD, although specific accuracy values were not provided in the excerpts.
The research aimed to conduct a comprehensive comparative analysis of word embeddings using CNN and BiLSTM as downstream encoders for text classification, aiming to offer evidence-based guidance for practitioners selecting word embeddings for deep learning models in text classification tasks . Taneja et al. [45] explored transfer learning and traditional machine learning for text classification, comparing BERT and DistilBERT with TF-IDF. They fine-tuned these models on the 20 Newsgroups dataset, achieving 96% accuracy across five classes.
The study’s limitations include dataset dependency and the computational demands of large models. Overall, it aimed to shed light on the effectiveness of different approaches in text classification tasks. The task of text classification has a long history in NLP, and it can be canonically divided into four different levels based on their scope and granularity of categories:
Document-level classification: This level involves categorising entire documents or individual texts into predefined groups or classes (i.e., categorising news into sports, entertainment, or politics). This classification is usually best suited for content filtering, document management, and aggregation tasks [48].
Sentence-level classification [23]: Individual sentences contained in a document are classified. This type of classification has been very successful in tasks such as sentiment analysis [12], opinion mining [30] or chat-bots.
Entity-level classification: It focuses on the categories, i.e., named entities. These entities can be general-purpose (people, organisations, and locations) or domain-tailored. This approach is typically used in tasks such as in information extraction [16, 17] or knowledge management [26].
Aspect-level classification: This level involves identifying and categorising specific aspects or attributes of a product, service, or topic within a document. It is commonly used in opinion mining, customer feedback analysis, and product recommendation systems[51].
The emergence of word embedding [32, 31] and neural language models (NLMs) [10, 1] marked a pivotal shift in the field, raising the bar in all NLP tasks. In particular, BERT was one of the first NLMs to rank tasks. Its ability to capture bidirectional contextual information makes it particularly effective in classification tasks once fine-tuned on specific classification objectives [44]. In addition, the model achieved excellent performance in topic-specific identification.
In BERT, the potential to enhance topic modelling methodologies and facilitate more profound insights into large-scale text datasets has been demonstrated. Subsequently, a BERT-derived model, RoBERTa [28], characterised by an augmented pre-training using larger datasets combining Common Crawl and BooksCorpus, dynamic masking, longer sequences, and excluding next sentence prediction, has achieved superior performance in text classification, highlighting the impact of optimised training strategies.
RoBERTa has also been adapted to perform the task in several languages [52]. [41] has proposed a different approach. This approach uses pre-trained word embedding to capture local n-gram features through CNNs and sequential dependencies through LSTMs. This combination achieves state-of-the-art performance on benchmark datasets like SST-2, MR, and TREC, demonstrating the potential to combine deep learning architectures for improved text classification accuracy.
The methodology utilises a joint training strategy with Adam optimiser and learning rate decay to optimise the hybrid CNN-LSTM network effectively. In [22], transfer learning using the ULMFiT model is exploited for text classification tasks. Significant improvements can be noted by fine-tuning pre-trained models on specific tasks compared to training from scratch. The approach adopted in this study entailed refining the ULMFiT model through fine-tuning text classification datasets such as AG News and SST-2, employing the Adam optimiser with learning rate decay.
Results confirm the effectiveness of transfer learning methodologies in enhancing NLP tasks. A hybrid approach is instead presented in [4], combining traditional feature engineering and deep learning. Using the 20 Newsgroups dataset, this approach uses a filter-based feature selection algorithm followed by a deep convolutional neural network. This two-stage methodology achieves significant accuracy improvements compared to traditional and deep learning-based approaches, paving the way for combining multiple techniques for text classification tasks.
Among more recent works using BERT or BERT-based models for text classification in [9], a text classification system for academic papers is proposed, leveraging a hybrid BERT and Bidirectional Gated Recurrent Unit (BiGRU) model. BERT extracts semantic features from paper abstracts, while BiGRU captures sequential information.
The model is evaluated on a dataset comprising 10,000 academic papers from four disciplines, demonstrating superior performance compared to several baselines.
Furthermore, [42] introduces a BERT-based hybrid recurrent neural network (RNN) model for multi-class text classification, focusing on the impact of pre-trained word embedding. BERT is employed to acquire contextualised word embedding, fed into an RNN with an attention mechanism for classification.
Experimental evaluations are conducted on three datasets: IMDb movie reviews, AG news, and Yelp reviews, highlighting the effectiveness of their proposed model. Finally, in [33], an extensive review of over 150 deep learning-based models and more than 40 widely-used datasets for text classification is presented.
3 Materials and Methods
This section describes the dataset and NLM used in the experiment in detail. In particular, the configuration and parameters used considering the BERT model are specified; further word embedding is described, and the 20 Newsgroups collection is introduced, specifying the underlying reasons for this choice.
The dataset chosen in this research is the 20 Newsgroups collection [2], a widely recognised benchmark dataset in NLP and text classification. The dataset spans different topics, including posts extracted from various newsgroups related to sports, politics, technology, and news.
This dataset offers a rich repository of textual content suitable for multi-class text classification tasks. A preprocessing step was necessary to prepare the dataset before it could be used in the experiments.
First, documents were cleaned up by removing duplicates to mitigate potential biases and redundancy, enhancing the accuracy and reliability of model training and evaluation. Subsequently, only each document’s ”From” and ”Subject” headers contain pertinent information for predicting the corresponding category or topic. After that, classical preprocessing operations, widely known in the literature, were performed.
The WordPiece tokenization technique has been chosen, facilitating the decomposition of words into sub-word units. Furthermore, the tokenized data is shuffled and split into training and validation subsets, ensuring a balanced representation across both sets. This preprocessing phase helps optimise the dataset for fine-tuning BERT models tailored for multi-class text classification tasks.
Concerning evaluation, classical metrics like accuracy, precision, recall, and F1 score are taken into account to estimate performance using two independent subsets: the pre-processed 20news-18828.tar.gz dataset with 18,828 unique documents and the raw 20news-19997 dataset with the original samples.
Removing duplicates from 20news-18828 ensures reliable training and evaluation by eliminating biases and redundancy, while 20news-19997 retains the raw data (see Table 2).
Table 1 20news-18828.tar.gz(Dataset 1) and 20news-19997.tar.gz(Dataset 2) dataset types, changes and their samples
| Dataset name | Changes | Samples |
| 20news-18828.tar.gz | Duplicates removed, only ”From” and ”Subject” headers | 18828 |
| 20news-19997.tar.gz | Original 20 Newsgroups data set | 19997 |
Table 2 Comparison of pre-trained BERT model with state-of-the-art machine and deep learning methodologies on 20 newsgroup dataset regarding Advantages and disadvantages. More details are in related work
| Model | Size of dataset | No of Models | Architecture | Pre-trained | Accuracy | Disadvantage | Performance | TC task | Classification |
| 20 | 3 | Simple | No | 71.10% | Not as accurate as other models | Poor | No | binary | |
| MMR, SVM, NB | 20 | 3 | Simple | No | 84.00% | Not as accurate as other models with fine-tuning | Fair | No | binary |
| Modified CNN | 4 Classes only | 2 | Complex | No | 96.49% | Requires large dataset to achieve high accuracy | Good | No | binary |
| Auto Encoder | 20 | 2 | Complex | No | 773.78% | Not as accurate as other models | Poor | No | binary |
| DBN+Softmax | 20 | 2 | Complex | No | 85.57% | Not as accurate as other models with fine-tuning | Fair | No | binary |
| DL and meta-thesaurus | 20 | 2 | Complex | No | 69.82% | Not as accurate as other models | Poor | No | binary |
| LSTM | 20 | 2 | Complex | No | 86.00% | Requires large dataset to achieve high accuracy | Good | Yes | binary |
| SVM+NB | 9 classes only | 2 | Complex | No | 82.20% | Not as accurate as other models with fine-tuning | Fair | No | binary |
| CNN+LSTM | Topic categorization | 2 | Complex | No | 90.00% | Requires large dataset to achieve high accuracy | Good | Yes | binary |
| ML Classifier comparison | 20 | 4 | Complex | No | 86.00% | Not as accurate as other models with fine-tuning | Fair | No | binary |
| Feature representation, ML classifiers | 20 | 2 | Complex | No | 68.00% | Not as accurate as other models | Poor | No | binary |
| Cross-domain Transfer learning | 6 classes only | 3 | Complex | Yes | 95.62% | Requires large dataset to train the initial model | Good | Yes | binary |
| Multi-Channel CNN | 20 | 2 | Complex | Yes | 82.76% | Requires large dataset to get better accuracy | Fair | No | binary |
| Feature Engineering, Multi-Channel CNN | 20 | 2 | Complex | Yes | 91.72% | Requires large dataset to get better accuracy | Good | No | binary |
| Pre-Trained BERT | 20 | 1 | Deep bidirectional transformer | Yes | 92.13% | Already trained and better accuracy | Excellent | Yes | binary |
3.1 Model
The paper presents a novel methodology focusing on fine-tuning a BERT model for text classification, considered a standard baseline model in contemporary natural language processing tasks. Recent studies, including experiments with multi-text classification using the 20 Newsgroups dataset, have encountered significant challenges such as model forgetting unseen data, leading to overfitting, class imbalance, low performance, and high computational demands, ultimately resulting in lower accuracies.
To address these challenges comprehensively, the primary objective of this research is to optimize the fine-tuned BERT model using advanced cross-validation techniques. This optimization strategy includes leveraging the Radam optimizer to enhance the model’s learning capabilities and improve its performance.
The methodology involves training the fine-tuned BERT model with seven epochs on five-folds, encompassing all available data, including previously unseen data samples. The results of this approach have demonstrated significant improvements, achieving an impressive 92% accuracy on pre-processed data and maintaining a solid 90% accuracy on original data, even with noisy elements.
Notably, these improvements were achieved relatively quickly and with limited computational resources. Comparative analysis with baseline models highlights the superior performance of the proposed pre-trained BERT model, showcasing its ability to outperform traditional methods in text classification tasks.
Furthermore, the research aims to explore additional optimization strategies in future directions. These strategies may include fine-tuning model parameters or investigating ensemble techniques to enhance further the robustness and generalizability of the fine-tuned BERT model, thereby addressing key limitations observed in current approaches. As depicted in Figure 1, the proposed methodology involves several key steps. First, a large-scale labelled dataset for fine-tuning regarding multi-class text classification tasks is collected. Next, an appropriate BERT model, already pre-trained on natural language data to perform NLU, is selected and acquired. The BERT is a pre-trained deep learning model for NLP developed in 2018 by Devlin et all at Google [39].
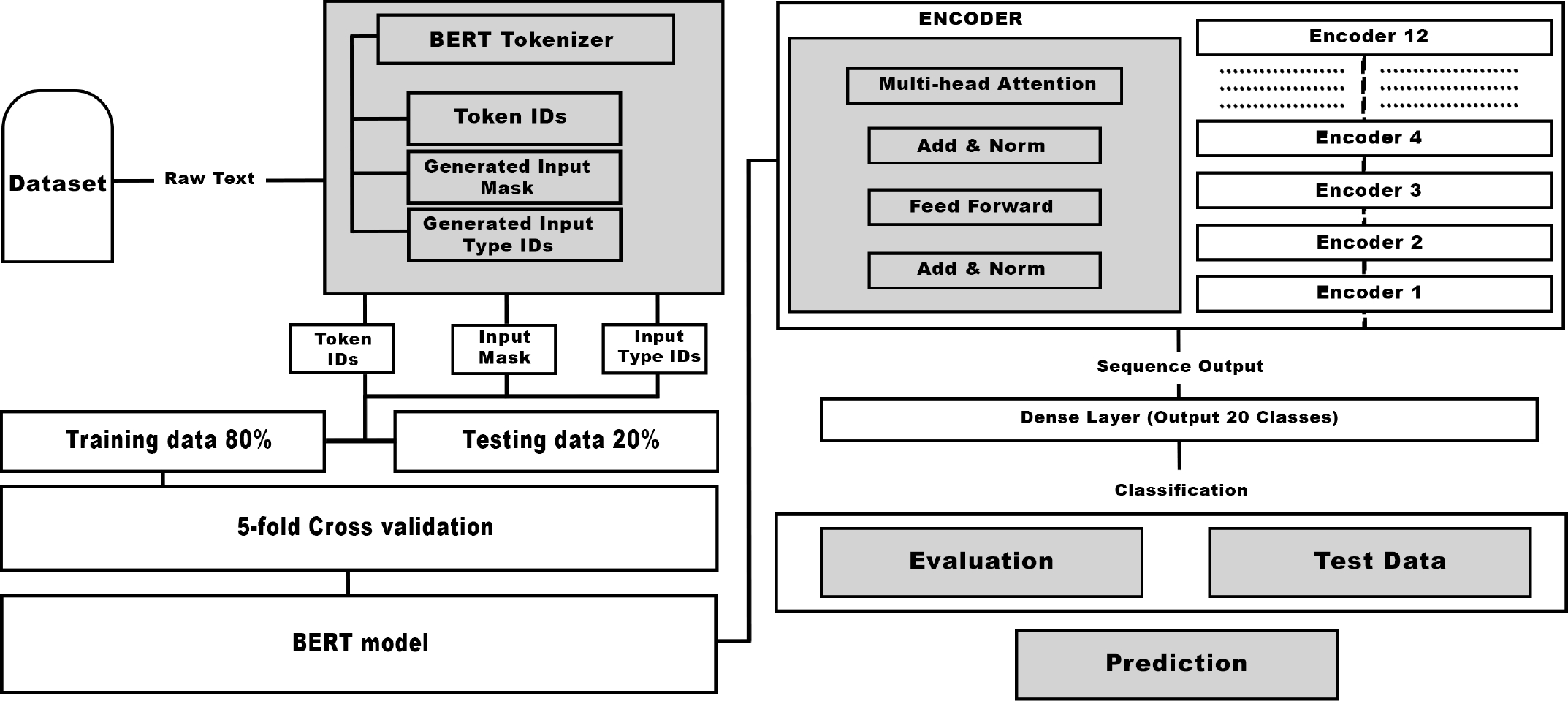
Fig. 1 Proposed pre-trained BERT models with strategic five-fold cross-validation methodology structure
It uses the transformer architecture. The key attribute of BERT is its ability to pre-train huge amounts of text data using a distributed computing system and memorise the underlying patterns and relationships in the language syntax and semantics. This pre-training is done through masked language modelling (MLM) and next sentence prediction (NSP).
A pre-trained BERT can be easily fine-tuned on specific NLP tasks. For fine-tuning, we add a task-specific layer on top of the pre-trained BERT and then train the network on a smaller dataset related to the specific task. The effectiveness of BERT in NLP has been demonstrated through various benchmark datasets [14], wherein it has achieved advanced performance. The availability of pre-trained BERT models has also facilitated researchers and developers to apply them to various NLP tasks and achieve high levels of accuracy with less data and computing resources.
3.2 Technical Details
In our approach, we employ wordpiece tokenization for word embedding, breaking down words into sub-word units. This enhances the model’s capacity to handle less common terms and ensures more accurate data representation. Wordpiece tokenization effectively dissects words into smaller units, aiding the model in understanding complex structures and dealing with rare or unknown words. Leveraging pre-trained wordpiece embedding from the BERT model, we obtain dense vector representations for each sub-word. These embeddings capture essential semantic and syntactic information, playing a vital role in the success of our multi-class text classification methodology.
In our proposed algorithm, the hidden layers of BERT include the attention layers, renowned for capturing contextual relationships between words. These attention layers are the initial hidden layers, effectively encoding input text and capturing crucial semantic information.
Additionally, we augment these layers with one or more dense layers comprising fully connected neurons. These dense layers enable the model to learn non-linear input representations, which is pivotal in extracting meaningful features for accurate predictions in multi-class text classification tasks.
As essential parts of BERT’s pre-training phase, Next Sentence Prediction (NSP) and Masked Language Modeling (MLM) use the model’s hidden layers to improve comprehension of textual context and semantic linkages. NSP involves training the model to predict whether two sentences are consecutive, enhancing its understanding of sentence-level relationships and coherence. On the other hand, MLM tasks the model with predicting masked words in a sentence based on the surrounding context, improving its grasp of contextualized word representations. Both NSP and MLM leverage the hidden layers of BERT to refine word embeddings and contextual embeddings, ultimately enhancing the model’s performance across various natural language processing tasks.
Activation functions introduce non-linearity, which is crucial for learning intricate connections and capturing non-linear dependencies in textual data. Our approach applies the softmax activation function in the final layer.
This function normalises output probabilities across multiple classes, creating a reliable probability distribution. It ensures predicted class probabilities sum up to 1, facilitating trustworthy and interpretable predictions in multi-class classification. Utilising the softmax activation function empowers the model to assign probabilities to each class, making confident predictions based on these probabilities:
The RAdam optimiser has been chosen for the optimisation algorithm. RAdam combines Adam optimiser benefits with rectified linear units, enhancing convergence speed and performance. Adam’s predefined learning rate allows faster convergence and improved sparse gradient handling. RAdam’s integration of rectified linear units introduces non-linearity, enabling the model to learn complex patterns and enhance generalisation. Our choice of the RAdam optimiser aims to optimise training and enhance fine-tuning for multi-class text classification.
Evaluation has been assessed considering diverse evaluation metrics, including a generated confusion matrix. This matrix provides a comprehensive overview of predictions aligned with true labels. The model’s performance is scrutinised by examining true positives, true negatives, false positives, and false negatives for each class. Computed metrics like F1 score, recall, accuracy, and precision offer insights into overall prediction accuracy, false positive reduction, and minimisation of false negatives. These metrics aid in understanding the model’s performance, identifying strengths and weaknesses, and guiding further optimisation.
4 Results
This section presents the results from experiments that indicate the performance of a fully trained (pre-trained + fine-tuned) BERT model for multi-class text classification by implementing the cross-validation technique. This section provides a detailed analysis of the results and discusses their implications.
The details of the experimental results are directly presented, highlighting key findings and the insights gained. The impact of different components of the proposed methodology, such as Wordpiece word embedding, BERT’s attention layers, the dense layer, the soft-max activation function, and the RAdam optimiser, is analysed.
The effect of hyperparameters, parameter tuning, and architecture on the model’s performance is investigated. Starting with the pre-processed dataset (Dataset 1) and original dataset (Dataset 2), evaluating metrics, including accuracy, precision, recall, and F1 score, provide insights into the model’s capability to classify text into multiple classes correctly. These metrics are calculated using the test dataset for the 20news-18828.tar.gz and 20news-19997.tar.gz dataset. The performance of a fully trained BERT model is then examined.
The confusion matrix in the following figure lists the proportions of true positives, true negatives, false positives, and false negatives for each class. This analysis helps spot correct or incorrect behaviours during the classification process and the model’s advantages and disadvantages for various classes. The data in the figure below shows that the numbers that move along the diagonal are those that were correctly derived from the whole data. The chart also shows no class imbalance issue, indicating that the model has been trained well and is in stable mode.
Figure 3 visually represents the model’s weaknesses and strengths. The x-axis of the graph shows the epoch number, and the y-axis gives the accuracy. A bar plot is generated using the Matplotlib library with the help of validation data. This plot displays the number of folds, allowing visualisation of any overfitting exhibited by the model, which can impact its performance and provide insights for further analysis.
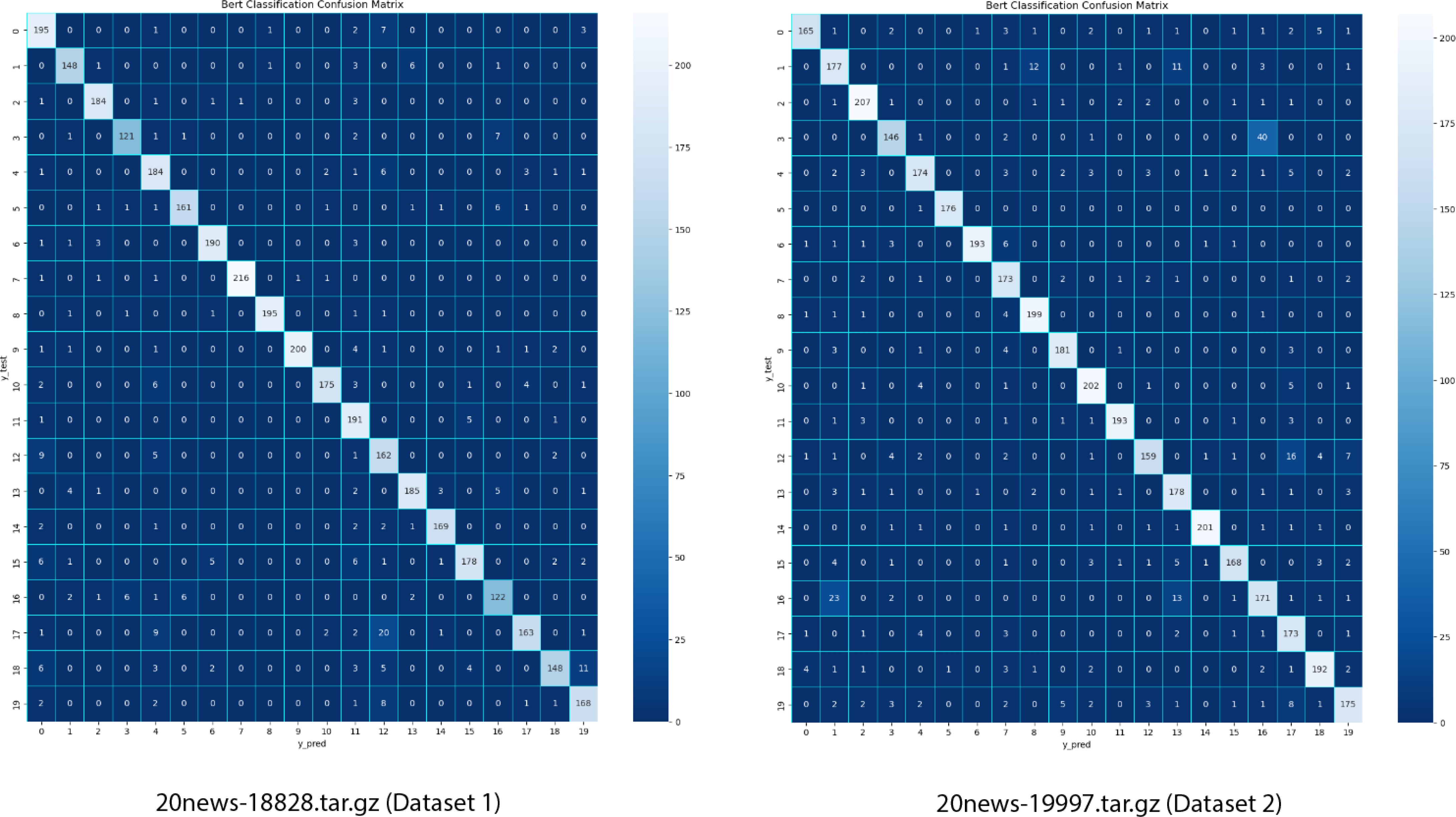
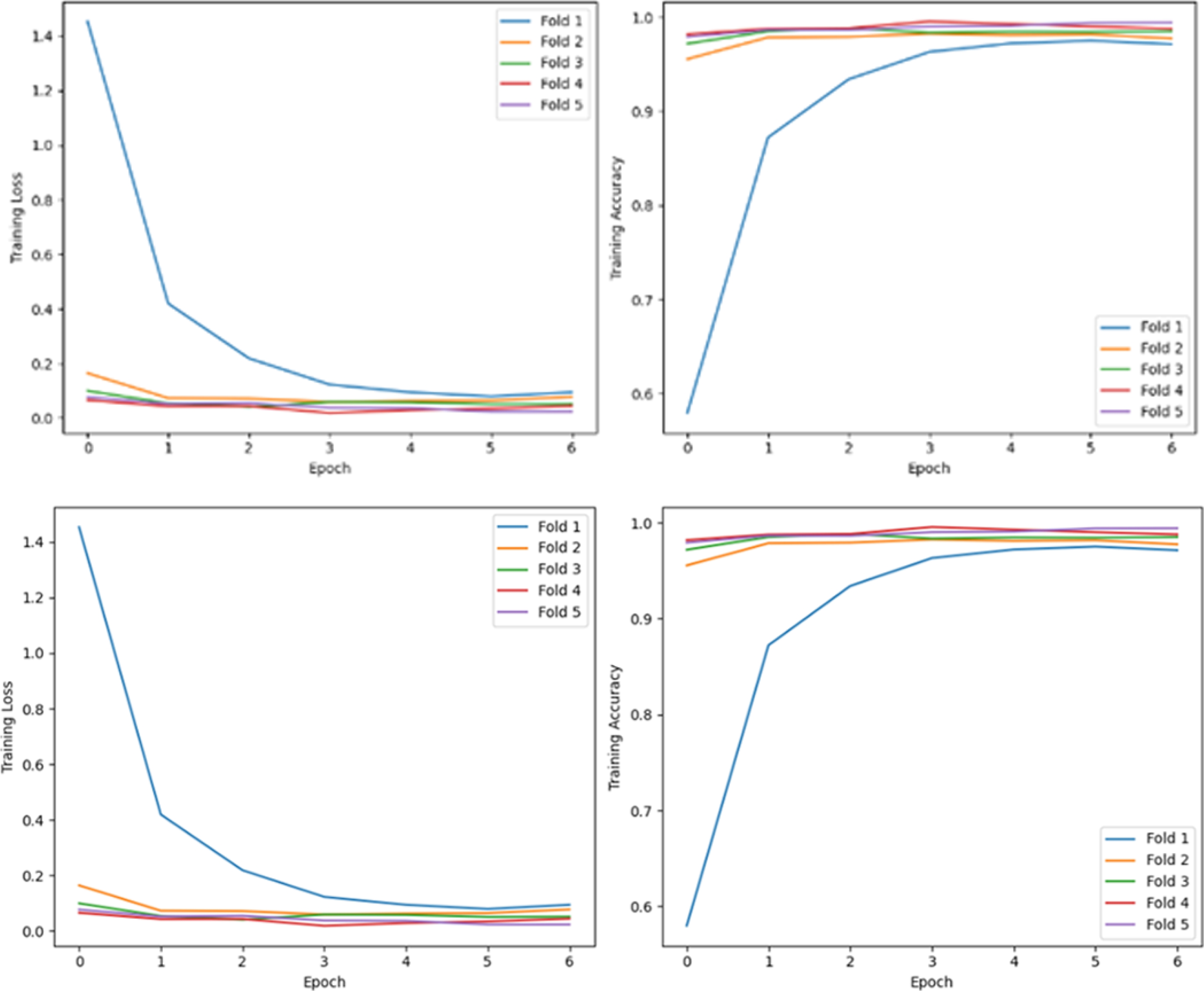
Fig. 3 Visualisation of model performance: the first row represents outcomes derived from (Dataset 1), while the second row illustrates results from (Dataset 2). Within each row, the first and second graphs correspondingly portray the training loss and training accuracy over the training epochs across the five chosen cross-validation folds
The plot showed that the BERT pretrained model had trained well on the 20newsgroup dataset. The training accuracy curves are fairly close, and there is no indication that the model is starting to plateau or decreasing the accuracy. This suggests that the model can generalise well to new unseen data as intended and that it is not simply memorising the training data.
The image shows the training accuracy of a model trained with cross-validation. Cross-validation is a widely used technique for machine learning model assessment, which involves dividing the dataset into subsets or ”folds”.
The model is trained on all but one fold, serving as the training set, and evaluated on the excluded validation set. This process iterates through all folds, ensuring comprehensive training and testing on the entire dataset. Its key advantages include mitigating overfitting by exposing the model to diverse data partitions reducing the impact of data-specific nuances. This approach optimally utilises available data, enhancing the model’s reliability, robustness, and generalizability. The proposed methodology employs 5-fold cross-validation. Figure 4 also shows the metrics for each class in the dataset and the overall metrics for the model. The overall metrics are calculated by averaging the metrics for each class. It also shows the number of instances in different classes.
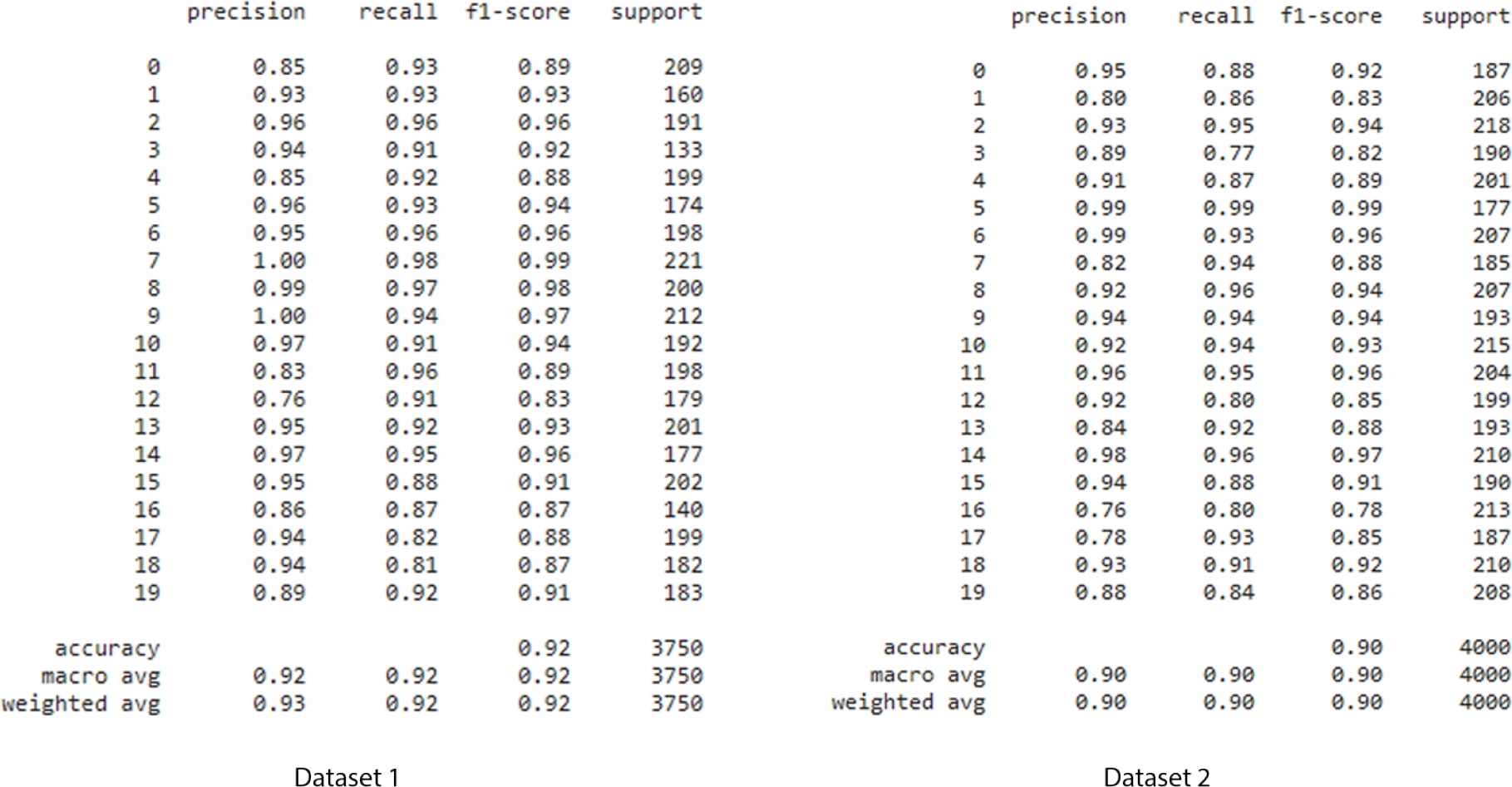
This information can be used to calculate the class imbalance, which is the difference in the number of instances in different classes. Overall, the image shows the performance of the BERT model on a multi-class classification task. The metrics in the table can be used to evaluate performance and to identify any potential problems.
Table 2 shows different text classification models compared to each other. Each model is described by several features in the related work section, including the size of the dataset it was trained on, the type of models used, the architecture of the models, whether the models were pre-trained, the accuracy of the models, the disadvantages of the models, the performance of the models, and whether the models are good for text classification tasks and lastly Classification tab.
The classification tab includes Binary classification, which means models can only predict two classes, while multi-class classification models can predict more than two classes. In this chart, the performance of different text classification models is investigated. The accuracy, disadvantages, performance, and suitability for text classification tasks are also compared using the Pre-trained BERT model with different other models [4]. This comparison helps us assess the effectiveness and superiority of the proposed methodology in achieving higher accuracy and better performance in multi-class text classification tasks.
5 Discussions and Conclusions
This paper has presented a BERT-based approach exploiting cross-validation to enhance text classification, achieving state-of-the-art results on a widely used benchmark dataset. The presented approach reaches an accuracy score of
Future improvements identified include incorporating domain-specific knowledge, exploring ensemble methods, addressing imbalanced data, and enhancing model interpretability to increase robustness and achieve even better performance metrics. Concerning other future developments, given the enormous proliferation of increasingly refined NLMs and LLMs in this field of study [7], it would be interesting to extend the experiments using additional models.
Some of them [8] proved remarkably versatile, outperforming BERT with lower computational cost in several tasks [53, 13]. Additionally, new perspectives have emerged with the advent of Quantum NLP [11, 19], a sub-field of NLP employing techniques derived from quantum theory to enhance performance. Although still limited by the youth of the research field and currently available hardware, quantum-based approaches have shown tremendous potential, especially in classification tasks [40, 15, 6], so future developments will be oriented in this direction.

