











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
The idea of dealing with words the same way we deal with numbers comes from ancient times, with the attempts of medieval Judaic, Islamic, and Greek scholars to discover secret knowledge from Holy scriptures such as the Torah, Quran, and Gospel. The method that was used back then is called the gematria calculation [18], which assigns a numeric value to each letter of the Hebrew alphabet.
This method was used to analyze the Torah, where words with the same numerical values could be interpreted as being related in meaning. This echoes the modern concept of embeddings, in which similar words are “close” to each other in vector spaces. There is an analogous methods for the Arabic (abjadiya) which is also associated letters of the alphabet with numerical values.
In Islamic culture, this system was used for mystical interpretations of the Quran. Like modern embedding models, abjad allowed symbols to be transformed into numerical sequences while preserving semantic relationships. Moreover, Jifr was a mystical method in the Islamic world that was used to create codes and divination based on the numerical values of letters.
This numerical manipulation of texts can also be interpreted as an ancient form of mathematical analysis of language. Next is an isopsephy which in ancient Greek culture used the numerical values of Greek letters to find hidden meanings in texts.
Pythagoras, a prominent philosopher and mathematician, posited that numbers form the foundation of all things, including language. His ideas about the numerical nature of words can be seen as a precursor to modern embeddings.
Thus, words were turned into a sequence of numbers, which then were manipulated arithmetically. Interestingly, such methods allowed for preserving semantics and logical constructs linking the words, so we can consider these early research as ancient word embeddings.
This historical perspective closely aligns with the development of the distributional hypothesis in natural language processing. The core idea of this hypothesis states that “the meaning of a word can be known from the company it keeps” [13]. It has provided the pathway for many modern algorithms.
Over the decades, the concept of distributional semantics has inspired the development of various methods for representing words numerically. The initial methods included simpler approaches like Bag-of-Words and TF-IDF (Term Frequency-Inverse Document Frequency).
These approaches were based on word frequency, but they often overlooked contextual information, which result in a loss of semantic depth. Word representation experienced a revolution with the introduction of techniques like Word2Vec [24] and GloVe [27].
These approaches provided more complex distributed representations that successfully maintained semantic links in high-dimensional environments. Word2Vec uses architectures that are trained to predict a word from its context or vice versa, such as Continuous Bag of Words (CBOW) and Skip-Gram.
Words with similar semantic content could be represented as dense vectors (embeddings) in the vector space thanks to these models. Representing words as vectors in high-dimensional space has proven to be one of the most important parts of natural language processing (NLP).
They enable various machine learning models working with numbers to parallelize the processing loop, preserving some semantic and syntactic information. Nowadays, natural language processing (NLP) has gone through a significant transformation.
It initially started from the elaboration of task-specific representations and architectures. NLP advanced towards the adoption of task-agnostic models and pre-training methods.
This upgrade has led to major attainments in various challenging NLP tasks, like reading comprehension, question answering, and logical inference. A substantial growth in this field is the rise of Large Language Models (LLMs).
Famous and convenient GPT-4 is the illustration of LLMs, which build on the foundational work of models like GPT-3. These LLMs leverage larger datasets and more complex architectures, which provides enhanced performance across a wide range of tasks [7].
Moreover, there is growing interest in multimodal embeddings. These embeddings combine text with other modalities, like images and video. The features of these embeddings enable models to better understand context and perform tasks which require a comprehensive understanding of both textual and visual information.
For instance, using context-specific prompts has been shown to improve performance in various datasets, such as specifying the type of image or object being described. As a result, it expands their real-world applicability [30].
The paper is organized as follows. In section 2, we describe the issue of word vectorization as the search for the context-dependent optimum aggregate function.
In section 3, the fundamental concepts behind context-independent techniques like as LDA, Word2vec, Glove, and FastText are presented. In section 4, we describe context-dependent techniques for both short and long context embeddings.
Short-context embeddings include models such as ELMo, BERT, and ELECTRA, and long-context embeddings include variants of several transformer designs (Longformer, Linformer, Reformer, Sparse Transformer, BigBird, and Synthesizer) or methods such as GPT-3.
In section 5, we explain the data used to run several models. In the next part, we present an experiment undertaken to compare the effectiveness of all embedding approaches. In section 7, we then discuss the findings.
2 Problem Statement
There is a text corpus
In real-world problems, the values of the corpus size
Then again, techniques that learn contextual embeddings maps every token
where
3 Context-independent Embeddings
3.1 Latent Dirichlet Allocation (LDA)
Blei et al. [5] propose a technique that models topics of documents. The approach assumes that each document contains a mixture of topics characterized by the word usage statistics and uses LDA to identify sets of words for each topic and calculates probabilities of attribution to topics for each document. LDA is based on the probabilistic model shown in (1):
where
–Document vectors
–Topic vectors
LDA parameters are typically determined using methods like Gibbs sampling, variational Bayesian inference, or Expectation-Propagation.
The main problem is to correctly choose the number of topics we seek, which can be solved by running the algorithm on several topic numbers and calculating the quality metric for each version.
The quality of each topic number variant is measured by the topic words coherence [33] as their semantic closeness, which is the euclidean distance between words in a vector space.
3.2 Neural Network Language Model
In [4], authors proposed the model named Neural Network Language Model (NNLM), which produces vector representations of a word during the optimization of a neural network, which interpolates a prediction function of the next word. Like the conventional language model, at NNLM, there is a context window with the width
However, there is a difference between LM and NNLM, which consists in finding such function that approximates LM with fewer parameters rather than accurately predicting with the help of words counting. In other words, the main idea of NNLM is replacing large multi-dimensional tensors (e.g., statistical language models) by bounded and low-dimension representations that calculated with the help of distributed word interrelations across all texts of large corpus.
Another advantage of NNLM is the replacement of the computational difficulty from the processing stage to preprocessing. Of course, the cost of this additional step requires more computations, but the hardware requirements scale linearly, not exponentially, with the number of conditioning variables, how it was in statistical LM. All models presented in this section exploits this idea.
3.3 Latent Semantic Analysis (LSA)
Probabilistic latent semantic analysis (PLSA) is a statistical technique for the analysis of two-mode and co-occurrence data proposed by Hofmann and Thomas [17]. It has applications in information retrieval and filtering, topic modeling. Due to latent correlations between terms and topics, one can use PLSA for embedding generation.
The main mechanics behind the scene is a Singular Value Decomposition of co-occurrence tables, also there is a mixture decomposition derived from a latent class model.
In order to avoid overfitting, the method uses a widely applicable generalization of maximum likelihood model fitting by tempered EM. Let a set of documents
where
The number of parameters grows linearly with the number of documents in the collection, which can lead to model over-fitting;
When adding a new document d to the collection, the distribution
3.4 Word2Vec
It is important to note that relationships can be approximated in both directions, from the central word to its context (skip-gram) and from the context to its central word (CBOW, Continuous Bag of Words). In the last decade, the first of the most popular algorithms is word2vec [25]. The central idea of Word2Vec is to utilize cosine distance properties between word vectors, transforming the point cloud so that words with similar meanings are close in vector space. And vice-versa words with different meanings should be far enough, in terms of cosine distance. Formally, the model of word2vec in terms of skip-gram is following:
where
3.5 Global Vectors for Word Representation
A variation of the metric approach to word embeddings is GloVe, or Global Vectors for Word Representation. In contrast to the previously mentioned algorithm it uses the approximation of the global context with the help of co-occurrences matrix [27]. The definition of GLoVE model is following:
where
It was shown that the algorithms of this approach have a drawback, namely, instability of reproducibility of the results [35], due to the random initialization of weights, the random order of training examples. When expanding the size of the dictionary, the entire correlation structure of the word cloud changes, resulting in a machine model, the training below in the pipeline processing also require retraining.
3.6 FastText
The models of Word2Vec with negative sampling and FastText looks pretty the same, but unlike Word2Vec, Fasttext considers words as a combination of N-grams. For the word “text,” it could be [“te,”, “tex,” “ext”, “xt”], depending on the parameters of the maximum and minimum n-gram. The word-vector is composed as the sum of the vectors of all the n-grams of this word. The objective function of the FastText model can be written as follows:
where
As a result, this method allows you to get better representations for words, not only based on the co-occurrence of words, but also the co-occurrence of their syllables and n-grams. Notably greatly improved are vectors for rare words, but at the same time, their parts are found in other, more frequent words.
Another significant advantage is the solution to the problem of out-of-vocabulary words due to the consideration of subword information. In other words, FastText allows us to work with words that were not available in the training set since the vectors of these words can be composed of the sum of its n-grams. On the other hand, we get increased learning time and more memory requirements [6, 22, 21].
4 Context-dependent Embeddings
Pre-trained bidirectional language models (biLMs) form the backbone of contextualized word embeddings [29]. Originally, they supposed to solve two issues:
Syntax and semantics characteristics of word.
The changing of these characteristics across variety of linguistic contexts (e.g., homonymy and polysemy). Subword information and contextual.
They have been used to improve performance for many NLP tasks. Formally bidirectional language model defined as the probability of next token with given set of previous tokens:
The embedding models based on the such LM take into account only the past information. The need to incorporate the information of future context is useful for the improvement of model performance. Hence, the design variation of BLM consists in consideration the context of current token in both directions:
where
The text summarization task also exploits the context features to determine key-words and most relevant sentences. Another industry application of contextual embeddings algorithms is semantic sentiment analysis if there are ironic or sarcastic statements, then the model can detect them only with the help of context features.
The question answering systems exploit the idea that the lexical distribution of the question correlates with the lexical distribution of the answer. In other words, these systems need to understand the contexts of answers and questions to find the correct answer. In this paper there are considered contextual embedding models based on the variety of LM, namely Bi-directional Language Model (BLM), Masked Language Model (MLM), Permutation Language Model (PML) and extension of MLM with ideas of Generative Adversarial Network(GAN). All these models extend the basic model LM in an original way to achieve specific properties about which we explain further in the paper. Based on the length of the context and the data processed by the described methods, embeddings may be split into two types: long and short-context embeddings.
The methodology to processing such information differs across various techniques. When processing a lengthy context, the algorithm’s complexity, processing time, and amount of resources utilized are frequently problematic. In order to circumvent this issue, specialized algorithms intended to operate in such circumstances have been developed.
4.1 Short-context Embeddings
4.1.1 Embeddings from Language Models (ELMo)
The popular recurrent neural network architectures, such as the Long Short Term Memory (LSTM) [16], the Generalized Recurrent Unit (GRU) [9], have opened a new stage in the development of Natural Language Processing (NLP), namely their combination in the form architecture Encoder-Decoder, please see Fig. 1.
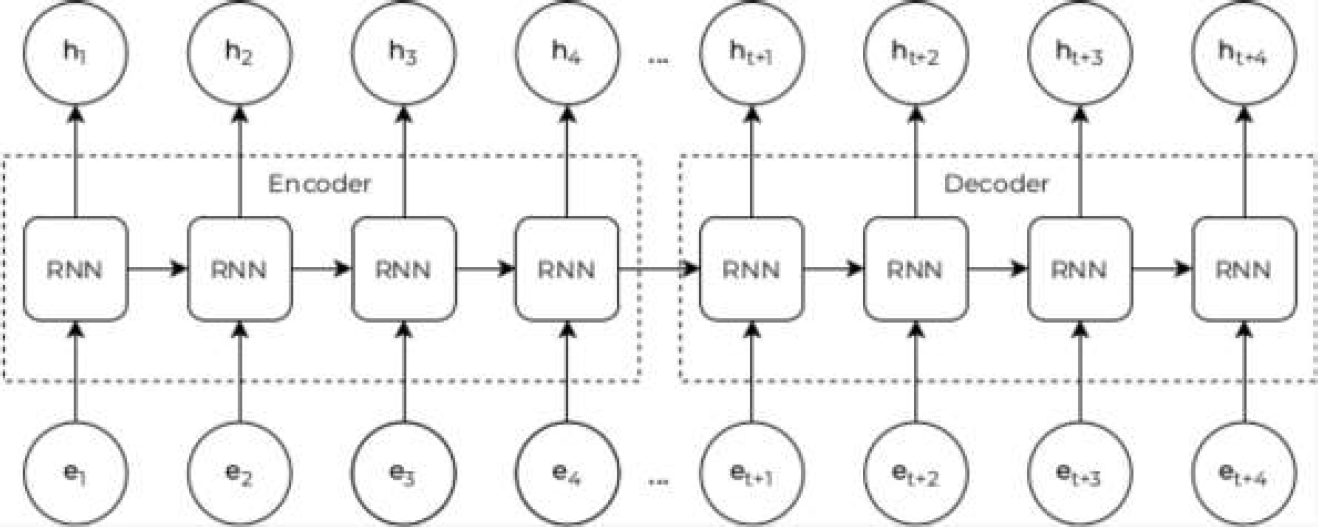
In paper [28], authors obtained context-sensitive vector representations of words, which partially solved the problems of polysemy coding and homonymy. The key advantages that have allowed the development of NLP systems to a new level are the inclusion of word order in the text and bidirectional language models:
Recursive architectures carried additional challenges such as slow learning speed, explosion, and fading gradients. Models based on the Transformer [37] neural network architecture, such as BERT [11] and XLNet [40], solved the above problems and are the last word in the field of word vectoring.
4.1.2 BERT
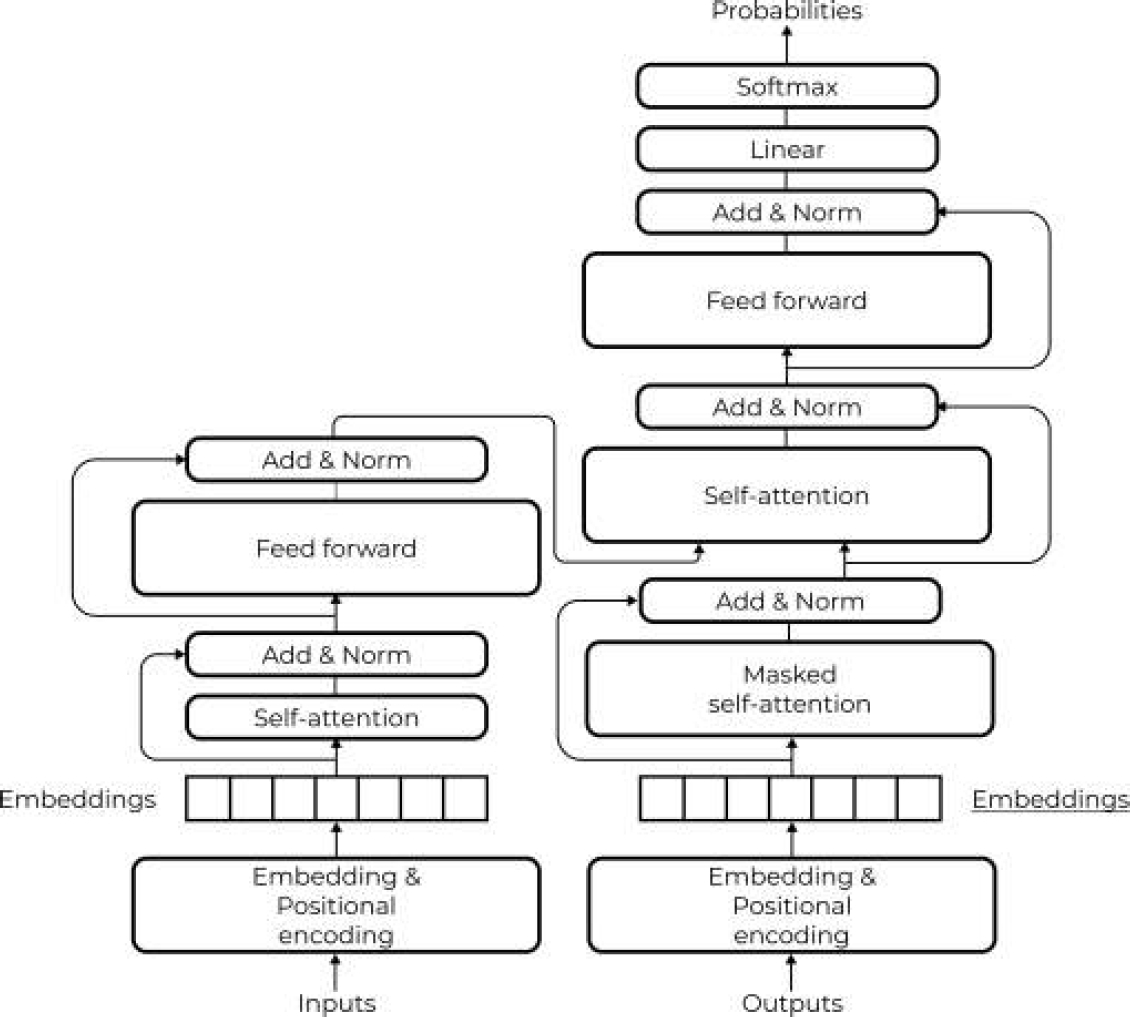
The architecture of Bidirectional Encoder Representations from Transformers (BERT) exploits the idea Encoder-Decoder approach. The Transformer model was proposed by Vaswani et al. [37]. The basic element of the Transformer model is a Dot-Product Attention unit, which is included in a Multi-Headed Attention unit.
In return, each layer in the Encoder and Decoder consists of Multi-Headed Attention units, they compute vector representations between a given token and all other tokens in the sequence S, after that position-wise feed-forward network calculate the output. BERT is an acronym for Bidirectional Encoder Representations from Transformers.
Input data is corrupter by replacing certain words with unique tokens like “[MASK]” for a training model to reconstruct the original sentence. Like the GPT, the BERT architecture is based on the Transformer model. Basically it’s a multi-layer bidirectional Transformer encoder [11]. BERT base consists of 12 layers with 12 self-attention heads each and hidden size=768. BERT large consists of 24 layers with 16 self-attention heads each and hidden size=1024.
Both models are pre-trained using two unsupervised tasks. The first training task is Masked LM. 15 percents of words in each sentence are replaced by “[MASK]” token. The second task on which this model was trained is NSP or Next Sentence Prediction. In the training process model learns to predict second sentence in the pair of sentences given as input.
Half of input pairs are subsequent sentences, and other half is random sentences from a corpus paired together. In the beginning of a sentence “[CLS]” token is inserted and “[SEP]” token at the end for model be able to distinguish between sentences.
Due to the fact that Bert learned not only to predict the next word in a sentence, but learned to predict a masked word on the basis of the previous and next words on it, he got high results and pushed GPT from the GLUE dataset leaderboard.
4.1.3 XLNet
The algorithm allows you to simulate bidirectional contexts by maximizing the expected probability for all permutations up to the factorization order and overcomes the limitations of BERT due to its autoregressive architecture. Also, XLNet brings together ideas from Transformer-XL, the most advanced autoregressive model.
Experimentally, XLNet surpasses BERT in 20 tasks, often by a wide margin, and achieves the most excellent results in 18 tasks, including answering questions, output in natural language, analysis of tonality, and ranking of documents. The original idea that distinguishes XLNet from BERT is the Permutation Language Model (PLM).
For a sequence
where
Essentially, for a text sequence
Moreover, since this objective function corresponds to the approach of autoregressive models, it naturally avoids the assumption of independence and inconsistency between the pre-workout and fine-tuning settings that were mentioned earlier [40].
The proposed objective function rearranges only the factorization order, not the sequence order. In other words, the original word order preserved with positional coding corresponding to the original sequence, and the corresponding attention mask in Transformers are used to obtain a permutation of the factorization order.
Please note that this choice is necessary, as the model only encounters text sequences with a natural order during training. Let us demonstrate an example of the prediction of the token
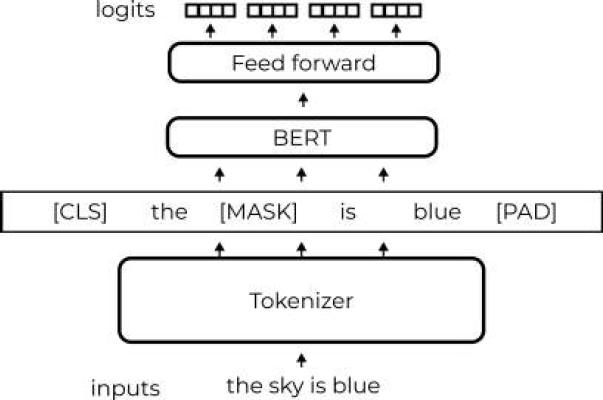
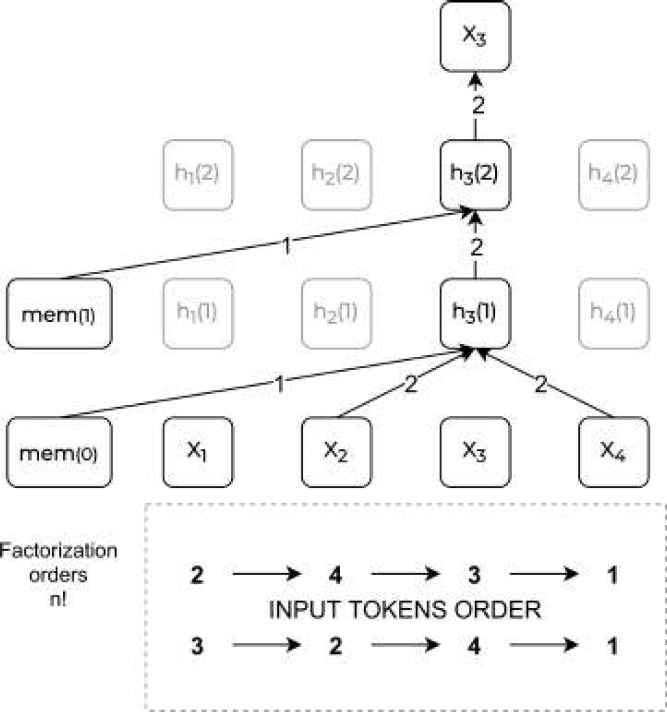
Fig. 3 Illustration of the PLM model, several permutation steps for predicting
4.1.4 ELECTRA
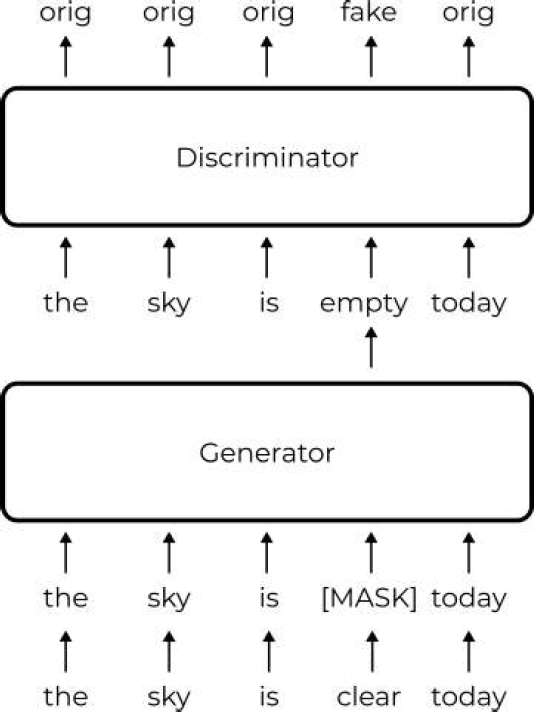
There is another original idea in contrast to the previous models that are based on masking and permutations. [10] proposed a new pre-training approach called “Replaced token detection.” Instead of masking, they replace some tokens by synthetically generated and then learns a model to distinguish real tokens from generated replacements.
The main idea of the approach is to train two neural networks the first one is a generator and second one is discriminator, each of them consisting of a Transformer network that maps input tokens
where
4.2 Long-context Embeddings
Since the introduction of Transformer architecture [37], there was a rapid development of transformer-based models. BERT being the most successful one [11]. However, the classical transformer is not without flaws, and there were many attempts to refine and improve it over the years.
Contemporary researches state the problem of Transformer optimization in terms of time and memory expenses. The fact of scientists and engineers have to train large models in long periods of time with the help of costly computational devices, e.g., sizes up to 64 layers with a width of 500 million parameters in each layer.
This resource limitation is especially evident in tasks with longer sequences. So the main research question is “does the Transformer really need such a volume of resources, or is it the inefficiency of the model?” Briefly, the main bottleneck of Transformer algorithm is contextual mapping matrix
where
4.2.1 Reformer
RevNets proposed by Gomez et al. [14], the idea of which is that the activation of each next layer can be obtained from the activation of the previous one, using only the model parameters. This allows not to save the activation of each layer, i.e. allows you to get rid of
In their model Reformer, Nikita Kitaev, Łukasz Kaiser and Anselm Levskaya [23] proposed another way to complexity reduction for transformers. Reversible layers allow you to store only one copy of the activation for the entire model instead of N times.
Handling activation in chunks allows you to reduce memory in fully connected layers. An approximate calculation of the attention mechanism based on locality-sensitive hashing reduces the complexity from O (
Locally Sensetive Hashing (LSH). Main constraint of the attention mechanism is the dot product of
A context mapping matrix may also be calculated using vector-matrix dot-product instead of matrix-matrix dot-product. This is less effective, but it reduces memory requirements by a factor of length. Deduced from
Considering that just
To swiftly locate neighbors, local-sensitive hashing is utilized, in which nearby vectors have a high possibility of having similar hashes.
where
4.2.2 Sparse Transformer
Sparse Transformer was created [8] to tackle the quadratic memory growth that can be attributed to the Transformers’ design. The model’s factorized attention mechanism takes advantage of an algorithmic innovation to extract patterns from twenty to thirty times longer sequences than was previously possible.
When modeling the density of lengthy sequences, the model produced performance comparable to or superior to that of conventional Transformers, although requiring a large reduction in the number of operations.
Sparse Transformer also demonstrated the exploitation of long-term context and the generation of globally coherent samples. On the basis of some ideas described above, OpenAI created their new model called GPT-1.
4.2.3 OpenAI GPT
In 2020, OpenAI, a group devoted to “discovering and implementing the route to safe artificial intelligence,” announced the launch of GPT-3, the most advanced natural language processing technology (Generative Pre-trained Transformer). It is characterized as a superintelligent system that learns and adapts from the immense sea of digital text to independently produce fresh, intelligent, and creative material.
It has been hailed as a stunning artificial intelligence text generator capable of imitating human writing with exceptional fluency. GPT models have revolutionized the landscape of Natural language processing (NLP) with their potent capacities to accomplish diverse NLP tasks.
The outcomes include faster reaction times and increased precisión. These language models need extremely few or even no examples to comprehend the job and execute with even more accuracy and inventiveness than models that are highly trained on a vast number of examples.
OpenAI’s GPT-3 is the third in a series of natural language processing (NLP) tools. Before its release, the model underwent years of research and development to achieve the current stage of innovation in the area of AI text production.
GPT-1. was launched in 2018 by OpenAI. Trained on an enormous BooksCorpus dataset, this generative language model was able to learn large range dependencies and acquire vast knowledge on a diverse corpus of contiguous text and long stretches [31].
In terms of its architecture GPT-1 applies the 12-layer decoder of the transformer architecture with a self-attention mechanism for training.
As a result of its pre-training, one of the significant achievements of GPT-1 was its ability to carry out zero-shot performance on various tasks. This ability proved that generative language modeling can be exploited with an effective pretraining concept to generalize the model.
With Transfer learning as its base GPT became a powerful facilitator to perform natural language processing tasks with very little fine-tuning. It generated pathways for other models which could further enhance its potential in generative pre-training with larger datasets and parameters.
GPT-2. Later in 2019, OpenAI created a Generative pre-trained Transformer 2 (GPT-2) [32] by using a bigger dataset and including extra parameters to create a more robust language model. Similar to GPT-1, GPT-2 utilizes the transformer model’s decoder.
With 1.5 billion parameters, GPT-2 is 10 times bigger than GPT-1 (117 million parameters), and it contains 10 times as many parameters and 10 times as much data.
It is trained on a varied dataset, making it effective at handling numerous language problems such as translation, summarization, etc., utilizing just raw text as input and little or no training samples. GPT-2 beat its predecessors by greatly boosting the accuracy of recognizing long-range relationships and predicting words across many downstream datasets.
GPT-3. GPT-3 is an earlier open version of the Generative Pre-training Model, paving the way for the more advanced closed GPT-4 and GPT-4o [39]. OpenAI has created a huge language prediction and generation model capable of creating extended sequences of the original text.
GPT-3 became the groundbreaking AI language software for OpenAI. Simply put, un some tasks, such as text generation, abstractive summarization, etc, it came close to human-level performance.
It includes around 175 billion parameters and is 100 times bigger than the GPT-2 database. It is trained using a 500-billion-word data set (referred to as “Common Crawl”) obtained from the large internet and content repository.
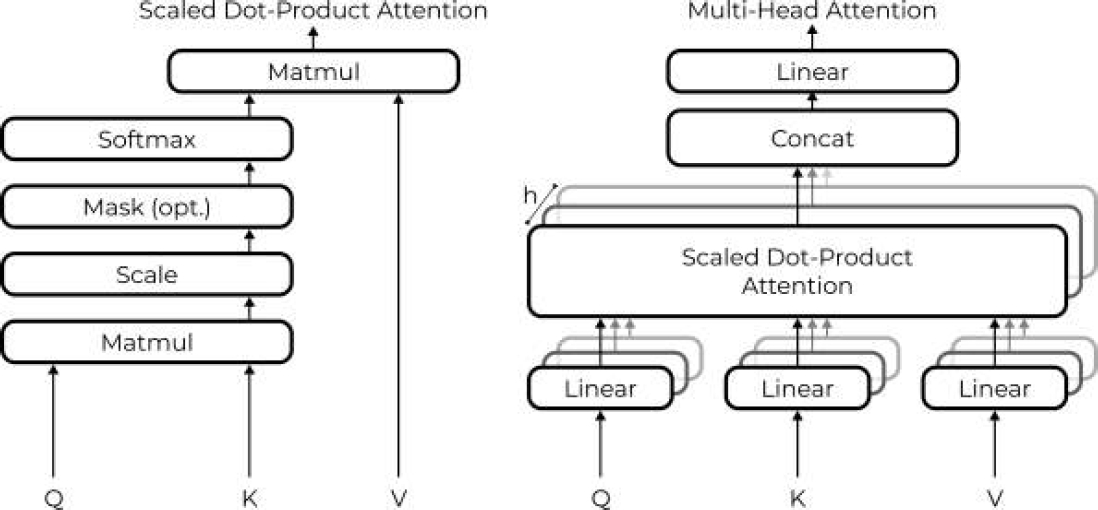
Fig. 6 On the left side there is a neural network architecture of dot-product attention. On the right side there is multi-head dot product attention
It can also do basic arithmetic problems, including producing code snippets and executing intelligent activities, which is a remarkable and unique skill. The outcomes include a quicker reaction time and higher degree of precisión, enabling NLP models to aid businesses by successfully and continuously maintaining best practices and decreasing human mistakes.
Due to its complexity and massive scale, several academics and developers have referred to it as the ultimate black box approach to artificial intelligence.
This makes it very costly and unpleasant to execute inference, and its billion-parameter size makes it resource-intensive and difficult to apply to practical applications in its present form. GPT-3 was designed to make language processing more potent and quicker than its predecessors, without requiring any further tweaking.
The majority of earlier language processing models (such as BERT) need extensive fine-tuning using thousands of examples to educate the model how to execute downstream tasks. The GPT-3 eliminates the need for fine-tuning.
The size of the three GPT models differs amongst them. The first Transformer Model had over 110 million parameters. GPT-1 accepted the size, whereas GPT-2 increased the number of parameters to 1.5 billion.
With the addition of 175 billion parameters to GPT-3, it became the biggest neural network. GPT-3 was designed to be more robust than GPT-2 in that it can address more specialized issues. It was recognized that GPT-2 performed poorly in specialized fields like as music and narrative.
GPT-3 can do more complex tasks like as question answering, essay writing, text summary, language translation, and computer code generation. Data contamination is a unique problem that GPT-3 must address.
Due to the internet origin of their training dataset, it is probable that part of the training data may overlap with the testing data.
Although this subject was addressed in GPT-2, it is especially pertinent to GPT-3 175B due to the fact that the datasets and models used for GPT-3 175B are about two orders of magnitude greater than those used for GPT-2, hence increasing the likelihood of contamination and memorization.
To study the effect of data contamination, the OpenAI team generates a “clean” version of the testing dataset for each downstream job, removing any possibly leaky instances, loosely described as “examples having a 13-gram overlap with anything in the training set”.
They next analyze GPT-3 on these “cleaned” test datasets and compare the results to those of the “uncleaned” original datasets.
4.2.4 Linformer
Experiments with traditional Bidirectional Transformers demonstrate that a context mapping matrix has a low rank [38]. The structure of the trials was predicated on the observation of ensuing unique values of
Long-tail spectrum distribution is uniform throughout each head and layer. Consequently, the matrix
In addition, we should note that the upper levels have a context mapping matrix
Consequently, using the Eckart–Young–Mirsky Theorem [12], one may approximate self-attention using a low-rank representation
where
4.2.5 Longformer
The strategy that was presented by the authors of the paper “Longformer: The Long-Document Transformer” [2] was based on the concept of shrinking the attention window in such a manner that it would fit particular regions, hence reducing the amount of memory needed and the amount of time needed to execute calculations.
How were these objectives attained? They employed three types of attention. The sliding attention window is the first of them. Instead of taking the whole
Thus, the complexity of computing becomes
However, we know that in multi-head attention approaches, various heads have varied attention scores, therefore by varying the dilation window, the authors were able to accomplish the outcome that some heads focus more on local context and others on long context.
The authors devised a second method dubbed “global attention” that utilizes unique tokens to further restrict the attention window. This strategy is based on increasing emphasis symmetrically at certain spots, based on the positioning of specific tokens in text. However, the number of these global attention windows is still quite modest compared to the total size of a
4.2.6 BigBird
The BigBird method, a descendant to the Longformer algorithm explained above, employs similar attention window principles. By combining global attention and window attention with so-called random attention, Zaheer et al. hypothesized that they may get superior outcomes in Natural Questions Long Answer (LA), TriviaQA, and WikiHop activities [41].
A computation approach that boosts the GPU/performance TPU’s is a further technological advancement. The attention matrix is divided into blocks of size 2 × 2, which accelerates retrieval owing to sparsity, while “rolling” is the transformation of a sparse matrix into a smaller nonsparse counterpart for quicker computing.
4.2.7 Synthesizer
Synthesizer model has no the query-key-values block in the self-attention module, instead of it the context matrix mapping is directly synthesized from input
where an input
where
where
This approach eliminates the dot product attention
5 Data
In our experiments, we utilized a variety of datasets to evaluate the performance of different word embedding models. Table 1 lists the datasets used for each model, along with a brief description of their contents: The use of these datasets not only allows for the assessment of the performance of various models but also helps identify their strengths and weaknesses across different contexts and tasks.
Table 1 Comparison of embedding methods
| Embedding Method | Model Type | Context Sensitivity | Architecture | Training Method | Use Cases | Strengths | Limitations |
| Word2Vec | Static | None | Feed-forward Neural Network | Predictive (Skip-gram, CBOW) | Text classification, document retrieval | Efficient, good for semantic relationships | No context sensitivity, struggles with polysemy |
| GloVe | Static | None | Matrix Factorization | Global statistical info | Text classification, keyword search | Captures global word co-occurrences | Static representations, same issues as Word2Vec |
| FastText | Static | None | Feed-forward Neural Network | Predictive | Text classification, morphological analysis | Handles subword information well | Still lacks contextual understanding |
| ELMo | Contextual | Yes | LSTM (Bidirectional) | Contextual embeddings | Sentiment analysis, question answering | Captures context, handles polysemy | Computationally intensive |
| BERT | Contextual | Yes | Transformer (Bidirectional) | Masked language modeling | Question answering, dialogue systems | Excellent at understanding context | High computational cost, input length limits |
| GPT-3 | Contextual | Yes | Transformer (Unidirectional) | Generative pre-training | Text generation, creative writing | Strong text generation capabilities | High resource demand, interpretability issues |
| ChatGPT | Contextual | Yes | Transformer (Fine-tuned) | Fine-tuning on dialogues | Conversational agents, chatbots | Maintains context in conversations | Bias issues, high latency |
6 Evaluation
In our evaluation, we aimed to compare the efficiency of various word embedding methods by employing several performance metrics tailored to different tasks. We include these types of dataset:
Massive Multitask Language Understanding (MMLU), which comprises a diverse array of tasks spanning multiple domains, including mathematics, science, and social studies. MMLU serves as a critical benchmark for assessing the reasoning capabilities of language models across varying levels of difficulty.
The Stanford Question Answering Dataset (SQuAD) was also utilized; this reading comprehension dataset requires models to answer questions based on a set of Wikipedia articles, making it instrumental in evaluating their abilities to understand and extract relevant information from text.
Additionally, we employed GLUE (General Language Understanding Evaluation) and SuperGLUE, which consist of a collection of tasks designed to evaluate model performance on various language understanding challenges, including sentiment analysis and textual entailment.
Other domain-specific datasets, such as the TREC AP corpus and the Brown corpus, were also included to evaluate performance in specific contexts.
In order to ensure comparability, the input data and the training conditions were standardized in the experimental setups for each model. This also included preparation of the text resources from the chosen datasets, such as cleaning and tokenization. In the case of multilingual datasets, certain rules regarding tokenization were followed in order to suit other languages.
Each word embedding model was fitted to data trained on the respective corpus using standard settings. In the case of BERT, GPT-2, and T5 models, we applied their pre-trained versions and adjusted them on the specific datasets to achieve better outcomes.
Hyperparameters, including but not limited to learning rate, batch size, and the number of training epochs, were thoroughly tuned for each model so as to improve performance. Various metrics were employed to assess model performance.
Accuracy is the ratio of the total number of correct predictions made out of the total population of predictions by the model, and this has been reported in most text classification tasks of the system performance.
The F1 score, which is the mean of recall and precisión, is very applicable to problems with skewed classes because it helps to strike a chord between the positives retrieved and instances that are required.
By employing these metrics, we can effectively compare the efficiency of different word embedding methods. This approach enables us to evaluate not only how accurately the models predict or classify data but also how well they generalize across various tasks and datasets.
Furthermore, modern benchmarks like MMLU, XNLI, and SQuAD enable a robust evaluation framework by incorporating diverse tasks and languages, ensuring that the models are assessed under realistic conditions.
Analyzing performance across these datasets and metrics provides insights into the strengths and weaknesses of each embedding method, ultimately contributing to ongoing advancements in natural language processing.
7 Discussion
In this section, we reflect on the findings regarding matrix factorization and neural network methods for generating embeddings, particularly in the context of natural language processing and recommendation systems.
7.1 Matrix Factorization Methods vs. Neural Network Methods
Matrix factorization is a method that breaks a given Matrix into parts in such a way that a lower-dimensional representation of it is produced. A well-known instance of this is seen in collaborative filtering, where the user-item matrix is broken into user and item latent feature matrices A and B correspondingly.
Thus, within this class, there are numerous known factorization techniques, which include Singular Value Decomposition (SVD) as it shrinks a high dimensional data but retains important information; Non-negative Matrix Factorization (NMF) as it is suitable for applications where it makes sense to constraint vendors’ factors to positive values; and Probabilistic Matrix Factorization (PMF) which means addition of a probabilistic approach to the process of the factorization for the purpose of improving its robustness.
Matrix factorization offers numerous benefits to users. They are easy to apply and understand which allows for their use in many situations. Also, they can be performed on very large and sparse interaction patterns very well. Further, they seem to have the best performance when dealing with the cold start problem especially when the new item/user has very few or no data at all.
This is achieved by tapping into the hidden factors from the simple product metrics present in the implemented system. That being said, it is not without weaknesses that matrix factorization has come. Most of them will be based around data which leads to a problem of linearity which does not explain more creative and complex data. Without a deeper description of temporal or contextual information, there is the possibility that these procedures are not going to be entirely effective in any problem where these aspects are critical. It is likely to perform poorly in problems where it is necessary to appreciate an even higher level of meaning than carried different perspectives. On the other hand, there are differences, especially in the use of thin portions of these matrices because convolution neural networks and neural network structures such as fast hidden units enable horizontal problems to be addressed more effectively. They are also made up of several layers used for feature extraction and classification analysis ready via softwares in CNN.
Some of the widely applied varieties within neural network methodologies are feedforward neural networks having adjacencies with neurons exchanging information in one neural direction; recurrent neural networks, which process quasi-periodic spectral components and design utilizing recurrent neural connections spanning over a length of time; classifiers which act as a series of connected operations in CNN; and finally, transformer models. Which has been an incredible transformation in advancing natural language processing – BERT and GPT – by means of capturing long-range dependencies. Neural network techniques serve the purpose very well. They are good at grasping intricate, non-linear patterns within the data making it easier to improve the performance on different fronts.
Besides, some state-of-the-art models such as BERT and GPT are equipped with strong contextual embeddings that contribute to a better understanding of meaning and relations between data points. These models also do well in that they are highly changeable, allowing them to be altered according to the requirements and application making them suitable for any type of given problem.
On the other hand, it is not all roses. There are cons to the application for neural networks due to several reasons. These models are computationally expensive and calls for huge resources in terms of memory size and processing capability. This may put a disadvantage to some businesses, particularly.
Also, most applications of the machine learning Neural Networks typically require rich training data which could be difficult to obtain in some applications. Finally, a key component, which is training process for such models is usually longer as compared to matrix factorization methods hence being unable to meet deadlines on certain tasks.
Projection of User-Item invocations onto k-dimensional spaces is also a general process that is more suitable for simpler tasks and situations where understandability, and ubiquitous and geographically expansive use is the norm, as opposed to capturing the different hidden layers of a network.
The essence of Neural Network Methods is on the other hand more robust and target based as it is well adapted for complex, high-dimensional data and intense contextual relationships but incurs higher resource outlay and structural intricacies.
It is mostly focused on the needs of a specific task, including but not limited to the volume of information such as data, performance and computational infrastructure level, and the aspect of the problems or solution under consideration.
7.2 Differences between Embedding Methods
In the course of the development of natural language processing (NLP), historically famous models like Word2Vec and GloVe have attracted interest with their understanding specialized in the word embeddings. However, as the evolution of the field entails, new models are developed such as BERT, GPT-3, and ChatGPT, which constitute solutions for significantly advanced problems.
Models of content-dependent and independent models were discussed in the previous sections. But no comparative studies were given. Types of context-independent models (Word2Vec and GloVe) are useful in conducting basic functions including text classification, document retrieval, and tasks where context is not important. They are less time-consuming and can be trained with smaller datasets.
On the other hand, context-dependent models such as BERT and ELMo are more efficient for advanced operations e.g., understanding the relationship between concepts, answering questions, translating. They are most useful in text manipulation due to the high level of precisión, however, they require more resources and a larger sample data set for training.
As described earlier, not all embeddings are created equal as they have intricate differences in terms of their design, training procedures, use, and effects. Various embeddings are employed because different tasks underscore different strategies in text manipulation and understanding of the context. We will also focus on the differences between different types of embeddings, their benefits and drawbacks, and their applicability in various tasks.
7.2.1 Traditional Models: Word2Vec and GloVE
The model developed by [24], known as Word2Vec, works by constructing vectors such that the relationships between words are predicted. Word embeddings can be created using the Skip-gram and Continuous Bag of Words model implementations. The ultimate result of this guideline is that it considers the distance or being among the words in terms of meaning but does not consider their abstract meaning in context, making use of the same word sense in multiple situations (polysemy) problematic. On the contrary, static efficiency is known as the inefficiency of traditional methods in handling such cases due to the surrounding words or, simply put, the context. This is the same case for GloVe. This fails on the notions of global statistics which comes from the complete corpus leading to static representation and insensitivity of context. These embeddings can come in handy for use in such situations, those being:
7.2.2 Limitations of Traditional Models
The adaptivity of embeddings from the Word2Vec and GloVe models is limited by the fact that these vectors are constant regardless of the given semantic unit. This is unsuitable for fine linguistic uses. The two technologies are economizing of computational resources allowing for hardly more burdensome operations at an immense proportion whilst the effectiveness of these technologies falls back very quickly when large data sets and advanced NLP applications are used. This is one of the reasons why they are not good is real-world applications. The following are the most significant they did not include the following limitations:
– No Context Sensitivity: Due to the nature of such embeddings, they provide a fixed vector to every word such that a word’s meaning cannot be distinguished in different contexts. For example, the word ‘bank‘ is the same whether it is used about a financial institution or a riverbank;
– Dealing with Ambiguity: If there are two meanings to one word, for instance the verb “lead” and the metal “lead” the situation I the same and this is one of the causes to error in fierce contextualized work patterns such as machine translation and answering questions;
– Sparse Data Headache: The most difficult part in working with these models is helping them cope with training statistics that never catches up with some target vocabulary items. This follows that some rare words or expressions will be hard to learn even when using these models;
– Limited Reach: They are typically meant to capture co-occurrences of words within a small contiguous region— hence they cannot report word relations which span beyond the window;
– Fixed Representations: Embedded representations do not admit of variability that would take into account changing conditions within the context such as a word’s difficulty;
– Data Requirement: These methods call for huge amounts of well-prepared data so that the provided embeddings will be correct, and it is impossible to represent anything informative with a limited amount of data.
7.2.3 Newer Models: BERT, GPT-3, and ChatGPT
Nevertheless, BERT (Bidirectional Encoder Representations from Transformers) makes use of a transformer architecture to generate embeddings for a given term considering both left-to-right and right-to-left context.
Consequently, BERT is good at various NLP benchmarks because it can cope with the ambiguity and the context in which it is available. Different from it, GPT-3 (Generative Pre-trained Transformer 3) employs a one-way transformer model trained on an enormous source text.
The collaborative writing abilities such as few-shot text generation and coherence text enable to aid in the creation of text or stories.
The modifying of GPT-3 to be a chatbot is referred to as ChatGPT, and this improvement assists in context preservation and engagement dissonance. We present a criterion based on when it is preferable to use content-specific approach for these reasons:
– When There is need of a deep understanding of the context controlling a certain word: These types of embeddinings are best suited for tasks that are dependent on the context of words. This includes tasks like question-answering, sentiment analysis, and natural language understanding;
– Polysemy and Ambiguity are Both addressed by content Dependent models: One of the examples: The word “bank” in one case is a financial institution and in another case it is a side of a river, in such cases, contextual embeddings differentiate these two meanings according to the context in which the word is used;
– Cardinals in Dialogue Agents and Conversational AI: For such systems as chatbots or virtual agents, continuing and comprehending the context across utterances are pivotal, with the model used GPT-3 and its customization into ChatGPT being best at producing contextually appropriate responses;
– Tasks with Entailment: in cases where there exist words or phrases that are semantically related, but are way too distant in a sentence or even in a document, embedding models work better than non-embedding models;
– Text Summoning and Synthesis: Content-aware models generate relevant and context-coherent text by understanding the organization of the input text in the cases of machine translation, text summarization or even fiction writing;
– Chores that Offer a Challenge to Transferrable Mechanisms Such As Machine Translation or Restatement: In contrast, when changing languages or redirecting meaning to certain sentences, contextually-dependent models demonstrate a better understanding of the sentence or paragraph construction and its purpose, hence expressing translations or modifications more accurately;
– Wide-Ranging and Varied Tasks: Moreover, such models are capable of carrying out Intelligent NLP designs for multiple and wide-ranging tasks like language translation when dealing with big varying data because they are capable of self-adjusting their knowledge instantly.
7.2.4 Limitations of Newer Models
Even several outstanding developments such as the BERT, GPT-3, and ChatGPT models seem to have their own obstacles. These new designs can undertake at greater length various problems and perform well in several tasks than the traditional designs; there comes a cost, however, because of their capacity and they have some setbacks. let us look at some of the draw backs and issues that these modern models have as they may be needed.
Here is a short version for dependent representations of the content such as BERT, GPT-3, and ChatGPT:
– Appropriate for tasks that require more than basic understanding; it is more necessary with tasks like sentiment analysis or answering questions;
– Mainly linguistic Use in a broader sense gets intensive sedated erasing within given context;
– Best for pertinent usage cases, i.e. chatbots where one needs to preserve the context through multiple conversational turns;
– Used for requests with words that are geographically far from one another;
– Outputs are generated ensuring coherence and text relevancy;
– Outstanding in translation and rephrasing by perceiving the meaning of a sentence;
– Able to address the issue of different contexts correctly and efficiently in different data worlds.
7.2.5 Comparative Analysis
The advancements in context handling are significant; while traditional models provide static representations, BERT and GPT-3 adapt embeddings based on context, leading to improved performance. In terms of scalability, newer models leverage large datasets and sophisticated architectures, allowing them to scale effectively in complex applications.
Furthermore, BERT and GPT-3 demonstrate superior efficiency in real-world applications, showcasing their ability to understand and generate human-like text, thus addressing the challenges faced by traditional models. Table 2 provides a comparative overview of various word embedding methods, summarizing key aspects of each model.
Table 2 Datasets and models used in experiments
| Model | Dataset |
| Latent Dirichlet Allocation | 16,000 documents from a subset of the TREC AP corpus |
| Neural Network Language Model | Brown corpus, Associated Press (AP) News from 1995 and 1996 |
| Latent Semantic Analysis | MED, CRAN, CACM, CISI |
| Word2Vec | Google News corpus |
| GloVe | 2010 Wikipedia dump, 2014 Wikipedia dump |
| FastText 2016 | Wikipedia data in nine languages: Arabic, Czech, German, English, Spanish, French, Italian, Romanian, and Russian |
| ELMo | One billion word benchmark for measuring progress in statistical language modeling (Chelba 2014) |
| BERT | BooksCorpus and English Wikipedia |
| XLNet | BooksCorpus and English Wikipedia, Giga5 (16GB text), ClueWeb 2012-B, Common Crawl |
| ELECTRA | ClueWeb, CommonCrawl, and Gigaword |
| Reformer | enwik8 and imagenet64 |
| Sparse Transformer | CIFAR-10, Enwik8, ImageNet 64x64 |
| GPT-1 | BooksCorpus dataset |
| GPT-2 | Common Crawl, WebText |
| GPT-3 | Common Crawl (filtered) 410 billion, WebText2 19 billion, Books1 12 billion, Books2 55 billion, Wikipedia |
| Linformer | BookCorpus, English Wikipedia |
| Longformer | text8 and enwik8 |
| BigBird | Books, CC-News, Stories, and Wikipedia |
| Synthesizer | SuperGLUE |
| RoBERTa | SQuAD, GLUE |
| XLM-R | XNLI |
| DeBERTa | MMLU, SQuAD |
| T5 (Text-to-Text Transfer Transformer) | MMLU, GLUE, SuperGLUE, SQuAD |
7.3 Special Types
The landscape of Natural Language Processing (NLP) is continuously evolving, and with it comes an explosion of specialized embedding techniques designed to better suit individual needs or use cases. This section takes an in-depth look at some of the special types of embeddings that help NLP models to learn better and perform well.
7.3.1 Multimodal Embeddings
This offers multimodal embeddings (that is, information from textual and visual or auditory modalities) for models to be able to more extensively capture context..) These embeddings are exceptionally effective in captioning a picture, understanding the content of a video and cross-modal retrieval.
For example, models such as CLIP (Contrastive Language-Image Pretraining) use textual and visual information together to increase the accuracy in tasks where fine-grained knowledge of both modalities is needed.
7.3.2 Domain-specific Embeddings
So domain-specific embeddings literally mean they are embeddings which are specifically trained on a certain field of text such as the biomedical, legal or financial texts.
The additional embeddings are useful for capturing customized lingo and context that broader, or generalized perhaps the word in am looking for, embeddings might miss. BioBERT, on the other hand, is BioMedically-oriented BERT and training it on biomedical literature helps the model to better understand and process domain-relevant information.
7.3.3 Contextualized Embeddings
The main goal of contextualized embeddings was to account for context (that adds a higher level) — that means words change representations based on surrounding text. ELMo, BERT, RoBERTa which are contextualized embeddings help to solve challenges like the presence of homonymous or polysemous tokens. Such flexibility vastly enhances the effectiveness of NLP duties as it permits spacious semantic representations.
7.3.4 Graph-based Embeddings
Graph-based embeddings come from graph structures, showing connections between entities in a network. These embeddings are important in knowledge graphs, social networks, and recommendation system applications. Models such as Node2Vec and GraphSAGE generate embeddings by the graph topology, which results in learning much deeper relational data.
7.3.5 Temporal Embeddings
Time-aware entities are temporal embeddings to capture the changes in meaning or usage from a historical context. That is useful for trend analysis, event prediction, and time-relevant recommendations. Models that use temporal information, like Temporal Graph Networks, tend to be able to model well the language dynamics and how it walks over time.
7.3.6 Adversarially Trained Embeddings
Adversarially trained embeddings are adversarially robust and incrementally learned by an adversarial training approach. This is particularly important in applications like sentiment analysis and spam detection, where models must perform well even when attacked. The adversarial training techniques along with these embeddings, along improve the quality and reliability of the model as a whole.
7.3.7 Zero-shot and Few-shot Learning Embeddings
Zero-shot learning (and few-shot learning) embeddings are meant for cases in which models are required to generalize from only a handful of examples. These embeddings are very beneficial in classification and translation tasks with less or no labeled data. This is how GPT-3 models work, they are capable of performing a wide range of tasks with few examples, this way opening more possibilities for using NLP systems.
8 Bias in Word Embedding
This topic of bias in word embeddings is particularly relevant as we continue to move towards artificial intelligence and natural language understanding/processing. Societally-biased training data can create models that perpetuate, or worse, amplify societal biases.
For example, a word embedding that encodes gender stereotypes may lead to models associating specific genders with certain professions or characteristics which in turn can lead to discrimination and bias in hiring practices, exposure within media, etc.
While likewise, racial prejudices can be present in how communities are represented by data-driven applications. These biases have severe ethical ramifications, especially in applications that require fairness and equity.
The same type of scrutiny should be used with the datasets on which AI systems are trained as organizations increasingly deploy them. This has spawned a burgeoning set of communities demanding the ethical development of AI, calling on researchers and practitioners to think first about fairness, accountability and transparency in their work. To extend this discussion, we have found more recent research a useful reference as in [3] who write about the dangers of using large language models and the ethical obligations that their developers have.
Additionally, [30] have explored the implications of multimodal models that utilize language and vision together, emphasizing the need for careful consideration of bias in both domains. By addressing these ethical concerns and incorporating a comprehensive analysis of bias in word embeddings, we can contribute to a broader understanding of the implications of AI technologies in society. This approach not only enhances the readership of our work but also aligns with the growing emphasis on fairness in AI research and development.
9 Future Challenges
Presented work is dedicated to the fundamental task of mapping human language concepts into a vector space, with the preservation of topological properties in terms of semantics and lexics. This paper discusses the features of various approaches that developed in neurocomputing science. The paper’s key analysis and findings are described as follows.
This paper outlines unsettled tasks posed by the modern state of industry and technology, and proposes several related approaches as well. In details, despite all the mentioned successes in the field of natural language processing [11, 34, 40, 10], several authors [20, 1, 19] showed that most modern systems are “fragile” and “fictitious”.
Some researchers suggest that the voiced problems should be solved by integrating “common sense” at various levels of word processing, including the level of word vectorization. Attention-based models also have such drawbacks.
The peak accuracy of 77 for BERT in the problem of understanding arguments reaches only three points below the average level of an unprepared person.
However, this result is entirely explained by false statistical patterns in the data set. The reason these models achieve random accuracy lies in the methodology for constructing the data set [26].
To study how BERT “makes a decision,” examples were considered that are most easily classified through many runs of the algorithm.
The authors of [15] performed a similar analysis with the SemEval dataset, and as evidence of their results, it was found that BERT uses the presence of a hint word to confirm a sentence, for example, denial words such as “no” or “not.”
Through point experiments, a method isolating such an effect was developed; indeed, the accuracy of the BERT model can be entirely dependent on random statistical laws [26]. The question of “fragility” and “deceit” of XLNet remains open; studies in the areas of machine translation, machine reading of a text, construction of argumentative models, tonality analysis, and others seem interesting.
In our opinion, there are three main areas of development of natural language processing algorithms, namely:
-
The use of the inductive bias approach for better control over the result, the use of linguistic structures in neural network architectures is one of the main trends of 2017.
The integration of common sense in the natural language processing model; indeed, most of the urgent tasks of text processing involve such qualities as abstraction, logic, comprehensive knowledge of the world.
Modeling data and distributions that do not belong to the training set, since most systems are oriented to a specific knowledge domain and do not have, in a broad sense, the quality of generalization.

