











 nueva página del texto (beta)
nueva página del texto (beta) Inglés (pdf)
Inglés (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink1 Introduction
Majority of recent approaches to sentiment analysis tries to detect the overall polarity of a sentence (or a document) regardless of the target entities (e.g. restaurants, laptops) and their aspects (e.g. food, price, battery, screen). In contrast, the current approach, aspect-based sentiment analysis (ABSA) identifies the aspects of a given target entity and estimates the sentiment polarity for each mentioned aspect.
In the context of the ABSA task, the bottleneck is the size of the annotated data, which should be considerably larger in order to simulate real world applications. Web content such as blogs, forums, reviews etc. present a large amount of easily accessible domain-relevant unlabeled data which we could use to add specific domain knowledge essential for improving the state of the art of sentiment analysis. Thus we try to demonstrate the usefulness of these data.
Most of the research in automatic sentiment analysis has been devoted to English. There have been several attempts in Czech as well27,8,2 , but all were focused on the global (sentence or document level) sentiment.
The first attempt at aspect-based sentiment analysis in Czech was presented in25 . This work provides an annotated corpus of 1244 sentences from the restaurant reviews domain and a baseline model achieving 68.65% F-measure in aspect term extraction, 74.02% F-measure on aspect category extraction, 66.27% accuracy in aspect term polarity classification, and 66.61% accuracy in aspect category polarity classification. The work in26 creates a dataset in the domain of IT product reviews. This dataset contains 200 annotated sentences and 2000 short segments, both annotated with sentiment and marked aspect terms (targets) without any categorization and sentiment toward the marked targets.
The current state of the art of aspect-based sentiment analysis methods for English was presented at the latest SemEval ABSA tasks namely the SemEval 2014 - 201623,22,21. The detailed description of each system is beyond thescope of this paper.
Our main goal is twofold: to show how unsupervised methods can improve an ABSA system in different languages and the creation of sufficiently large corpora for the ABSA task in Czech.
2 The ABSA Task
Aspect-based sentiment analysis firstly identifies the aspects of the target entity and then assigns a polarity to each aspect. There are several ways to define aspects and polarities. We use the definition based on the SemEval 2014’s ABSA task, which distinguishes two types of aspect-based sentiment: aspect terms and aspect categories. The whole task is divided into four subtasks. The later SemEval’s ABSA tasks (2015 and 2016) further distinguish between more detailed aspect categories and associate aspect terms (targets) with aspect categories.
2.1 Subtask 1: Aspect Term Extraction
Given a set of sentences with pre-identified entities (e.g. restaurants), the task is to identify the aspect terms present in the sentence and return a list containing all the distinct aspect terms.

2.2 Subtask 2: Aspect Term Polarity
For a given set of aspect terms within a sentence, the task is to determine the polarity of each aspect term: positive, negative, neutral or bipolar (i.e. both positive and negative).

2.3 Subtask 3: Aspect Category Extraction
Given a predefined set of aspect categories (e.g. price, food), the task is to identify the aspect categories discussed in a given sentence. Aspect categories are typically coarser than the aspect terms of Subtask 1, and they do not necessarily occur as terms in the given sentence. In the analysed domain of ‘restaurants’, the categories include food, service, price, and ambience.


3 Distributional Semantics in ABSA
The backbone principle of methods for discovering hidden meaning in a plain text is the formulation of the Distributional Hypothesis in6: “a word is characterized by the company it keeps.”
The direct implication of this hypothesis is that the meaning of a word is related to the context where it usually occurs and thus it is possible to compare the meanings of two words by statistical comparisons of their contexts. In this paper we use six distributional semantics models (see the following list).
Hyperspace Analogue to Language (HAL)16 is a very simple method for building semantic space based on co-occurrence matrix.
Correlated Occurrence Analogue to Lexical Semantics (COALS)24 is an extension of the HAL model which employs the Pearson’s correlation and Singular Value Decomposition (SVD).
Continuous Bag-of-Words (CBOW)18 is model based on Neural Network Language Model (NNLM) that tries to predict the current word using a small context window around the word.
Skip-gram19 is similar to CBOW but works in opposite direction.
It finds word patterns that are useful for predicting the surrounding words within a certain range in a sentence.
Global Vectors (GloVe)20 use the ratios of the word-word co-occurrence probabilities to encode the meanings of the words.
Latent Dirichlet Allocation (LDA)1 discovers hidden topics in the text.
Distributional semantics models typically represent the meaning of a word as a vector, that reflects the contextual information of the word throughout the training corpus. Each word is associated with a vector of real numbers. Represented geometrically, the word meaning is a point in a high-dimensional space. The words that are closely related in meaning tend to be closer in the space.
The ability to compare two words enables us to use a clustering method. Similar words are clustered into bigger groups of words (clusters). The clusters derived from semantics models are used as new sources of information for all four subtasks of ABSA (see Section 5).
4 The Data
The methods described in Section 3 require large unlabeled data in order to be trained. In this paper we used two types of corpora, labeled and unlabeled for both Czech and English. The properties of these corpora are shown in Table 1.
Table 1 Properties of the SemEval ABSA tasks and corpora used in the experiments in terms of the number of sentences, aspect terms (targets), aspect categories (categories), tokens and unique words
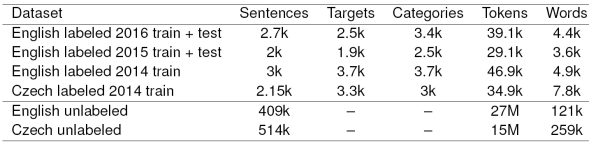
Labeled corpora for both languages are required to train the classifiers (see Section 5). For English, we use the corpora introduced in SemEval 2014 Competition Task 4 23. The main criterion in choosing the dataset was the dataset size (see Table 1).
For Czech, we extended the dataset from25 , nearly doubling its size. The annotation procedure was identical to that of the original dataset. The corpus was annotated by five native speakers. The majority voting scheme was applied to the gold label selection. Agreement between any two annotators was evaluated in the same way as we evaluate our system against the annotated data (taken as the gold standard). This means we take the output of the first annotator as the gold standard and the output of the second annotator as the output of the system. The same evaluation procedure as in23 is used, i.e. the F-measure for the aspect term and aspect category extraction, and the accuracy for the aspect term and aspect category polarity. The resulting mean values of annotator agreement for the Czech labeled corpus are 82.91% (aspect term extraction), 88.02% (aspect category extraction), 85.71% (aspect term polarity) and 88.44% (aspect category polarity). We believe this testifies to the high quality of our corpus. The corpus is available for research purposes at http://nlp.kiv.zcu.cz/research/sentiment.
The labeled corpora for both languages use the same annotation scheme and are in the same domain. This allows us to compare the effectiveness of the used features on the ABSA task for these two very different languages.
The lack of publicly available data in the restaurant domain in Czech forced us to create a cross-domain unlabeled corpus for Czech. The Czech unlabeled corpus is thus composed of three related domains: recipes (8.8M tokens, 57.1%), restaurant reviews (2M tokens, 12.8%), and hotel reviews(4.7M tokens, 30.1%). We selected these three domains because of their close relations, which should be sufficient for the purposes of the ASBA task.
The English unlabeled corpus was downloaded from http://opentable.com.
5 The ABSA System
We use and extend the systems created by3 . We implemented four separate systems - one for each subtask of ABSA. The required machine learning algorithms are implemented in the Brainy machine learning library12 . We further extended this system and competed in the SemEval 2016 ABSA task and we were ranked as one of the top performing systems9.
The systems share a simple preprocessing phase, in which we use a tokenizer based on regular expressions. The tokens are transformed to lower case. Punctuation marks and stop words are ignored for the polarity task. In the case of Czech, we also remove diacritics from all the words, because of their inconsistent use.
The feature sets created for individual tasks are based on features commonly used in similar natural language processing tasks, e.g. named entity recognition14, document level sentiment analysis7, and document classification5. The following baseline features were used:
Affixes (A) - Affix (length 2-4 characters) of a word at a given position.
Tf-idf (T) - Term frequency - inverse document frequency of a word.
Learned dictionary (LD) - Dictionary of aspect terms from training data.
Words (W) - The occurrence of word at a given position (e.g. previous word).
Bag of words (BoW) - The occurrence of a word in the context window.
Bigrams (B) - The occurrence of bigram at a given position.
Bag of bigrams (BoB) - The occurrence of a bigram in the context window.
The baseline feature set is then extended with semantic features. The features are based on the word clusters created using the semantic models described in Section 3. The following semantic features were used:
Clusters (C) - The occurrence of a cluster at a given position.
Bag of clusters (BoC) - The occurrence of a cluster in the context window.
Cluster bigrams (CB) - The occurrence of cluster bigram at a given position.
Bag of cluster bigrams (BoCB) - The occurrence of cluster bigram in the context window.
Each C (alternatively, CB, BoC, or BoCB) feature can be based on any of the models from Section [sec:latent]. In the description of the systems for individual tasks, we use simply C to denote that we work with this type of feature. When we later describe the experiments, we use explicitly the name of the model (e.g. HAL).
5.1 Subtask 1: Aspect Term Extraction
The aspect term extraction is based on experiences in Named Entity Recognition (NER)13,14. The NER task tries to find special expressions in a text and classify them into groups. The aspect term extraction task is very similar, because it also tries to identify special expressions. In contrast with NER, these expressions are not classified, and have different properties, e.g. they are not so often proper names.
We have decided to use Conditional Random Fields (CRF)15 , because they are regarded as the state-of-the-art method for NER. The baseline feature set consists of W, BoW, B, LD, and A. In our experiments, we extend this with the semantic features C and CB. The context for this task is defined as a five word window centred at the currently processed word.
5.2 Subtask 2: Aspect Term Polarity
Our aspect term polarity detection is based on the Maximum Entropy classifier, which works very well in many NLP tasks, including document-level sentiment analysis7.
For each aspect term, we create a context window ten words to the left and right of the aspect term. The features for each word and bigram in this window are weighted based on their distance from the aspect term given by weighing function. This follows the general belief that close words are more important than distant words, which is used in several methods16.
We have tested several weighing functions and selected the Gaussian function based on the results. The expected value 𝜇 and the variance 𝜎 2 of the Gaussian function were found experimentally on the training data. We omit the description of these experiments, as they are outside the scope of this paper.
The feature set for our baseline system consists of BoW and BoB, and we further experiment with BoC and BoCB.
5.3 Subtask 3: Aspect category extraction
The aspect category extraction is based on research in multi-label document 5 the same, although our documents are only single sentences and the labels are aspect term categories.
We use one binary Maximum Entropy classifier for each category. It decides whether the sentence belongs to the given category. The whole sentence is used as the context.
The baseline uses the features BoW, BoB, and T. We try to improve it with BoC and BoCB.
5.4 Subtask 4: Aspect Category Polarity
The aspect category task is very similar to document-level sentiment analysis7 when the document is of similar length. We create one Maximum Entropy classifier for each category. For a given category, the classifier uses the same principle as in global sentiment analysis. Of course, the training data are different for each category. The context in this task is the whole sentence.
We use the following features as a baseline: BoW, BoB, and T. In our experiments, we extend this with BoC and BoCB.
6 Experiments
In the following presentation of the results of the experiments, we use the notation BL for a system with the baseline feature set (i.e. without cluster features). Cluster features based on HAL are denoted by HAL. For other semantic spaces, the notation is analogous.
Because Czech has rich morphology we use stemming to deal with this problem (stemming is denoted as S). Also we use the stemmed versions of semantic spaces (the corpora used for training semantics spaces are simply preprocessed by stemming). The system that uses this kind of cluster features is denoted by S-HAL for the HAL model, and analogously for the other models.
The union of feature sets is denoted by the operator +. E.g. BL+S-BL+S-GloVe denotes the baseline feature set extended by stemmed baseline features and by a stemmed version of GloVe clusters.
The number of clusters for a particular semantic space is always explicitly mentioned in the following tables.
6.1 Unsupervised Model Settings
All unsupervised models were trained on the unlabeled corpora described in Section 4.
The implementations of the HAL and COALS algorithms are available in an open source package S-Space10, 1. The settings of the GloVe, CBOW, and Skip-gram models reflect the results of these methods in their original publications20,18 and were set according to a reasonable proportion of the complexity and the quality of the resulting word vector outputs. We used the GloVe implementation provided on the official website2, CBOW and Skip-gram models use the Word2Vec3 implementation and the LDA implementation comes from the MALLET17 software package.
The detailed settings of all these methods are shown in Table 2.
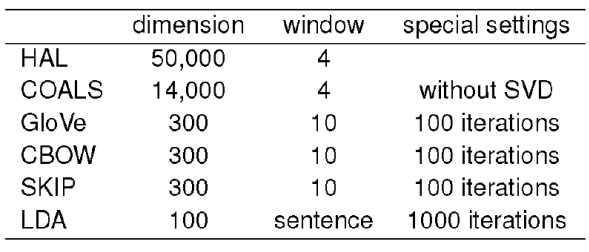
CLUTO software package11 is used for words clustering with the 𝑘-means algorithm and cosine similarity metric. All vector space models in this paper cluster the word vectors into four different numbers of clusters: 100, 500, 1000, and 5000. For stemming, we use the implementation of HPS4, 4 that is the state-of-the-art unsupervised stemmer.
6.2 Results
We experimented with two morphologically very different languages, English and Czech. English, as a representative of the Germanic languages, is characterized by almost no inflection. Czech is a representative of the Slavic languages, and has a high level of inflection and relatively free word order.
We provide the same evaluation as in the SemEval 201423 . For the aspect term extraction (TE) and the aspect category extraction (CE) we use 𝐹-measure as an evaluation metric. For the sentiment polarity detection of aspect terms (TP) and aspect categories (CP), we use accuracy.
We use 10-fold cross-validation in all our experiments. In all the tables in this section, the results are expressed in percentages, and the numbers in brackets represents the absolute improvements against the baseline.
We started our experiments by testing all the unsupervised models separately. In the case of Czech, we also tested stemmed versions of all the models. For English, we did not use stemming, because it does not play a key role7 . The results are shown in Tables 3 and 4.
Table 3 Aspect term and category extraction (TE, CE) and polarity (TP, CP) results on English dataset
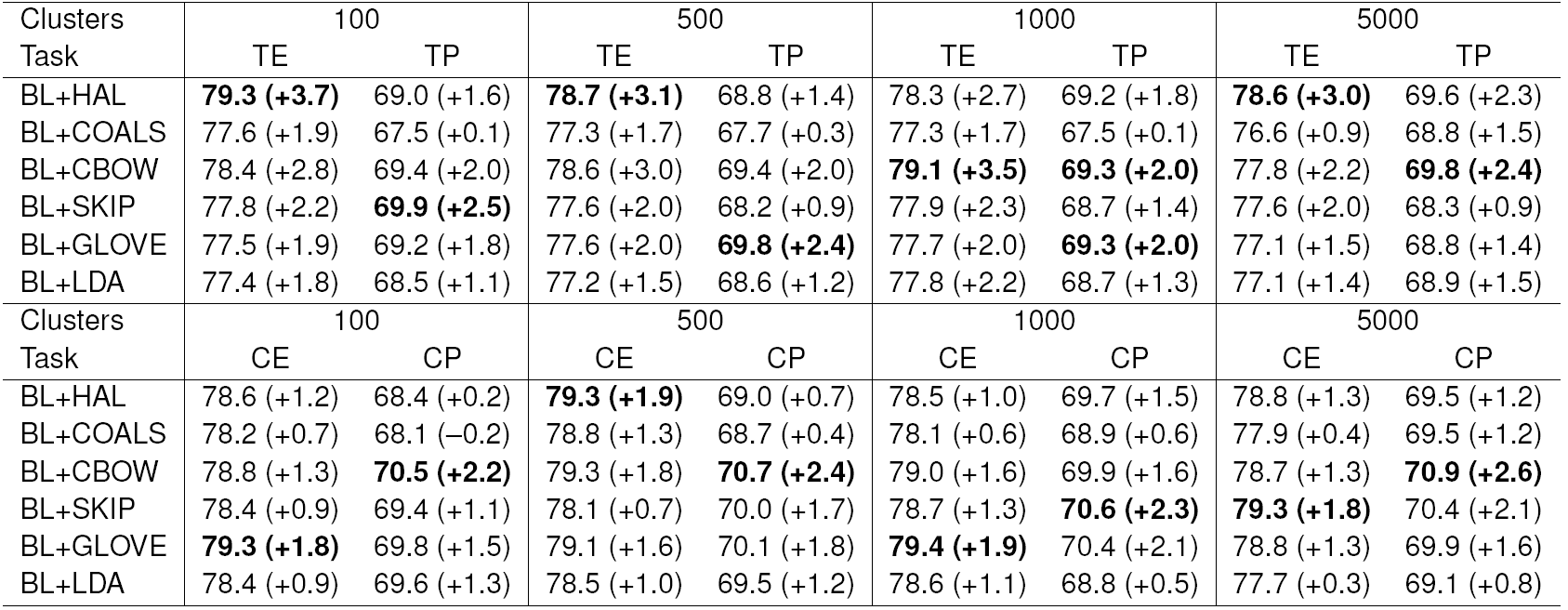
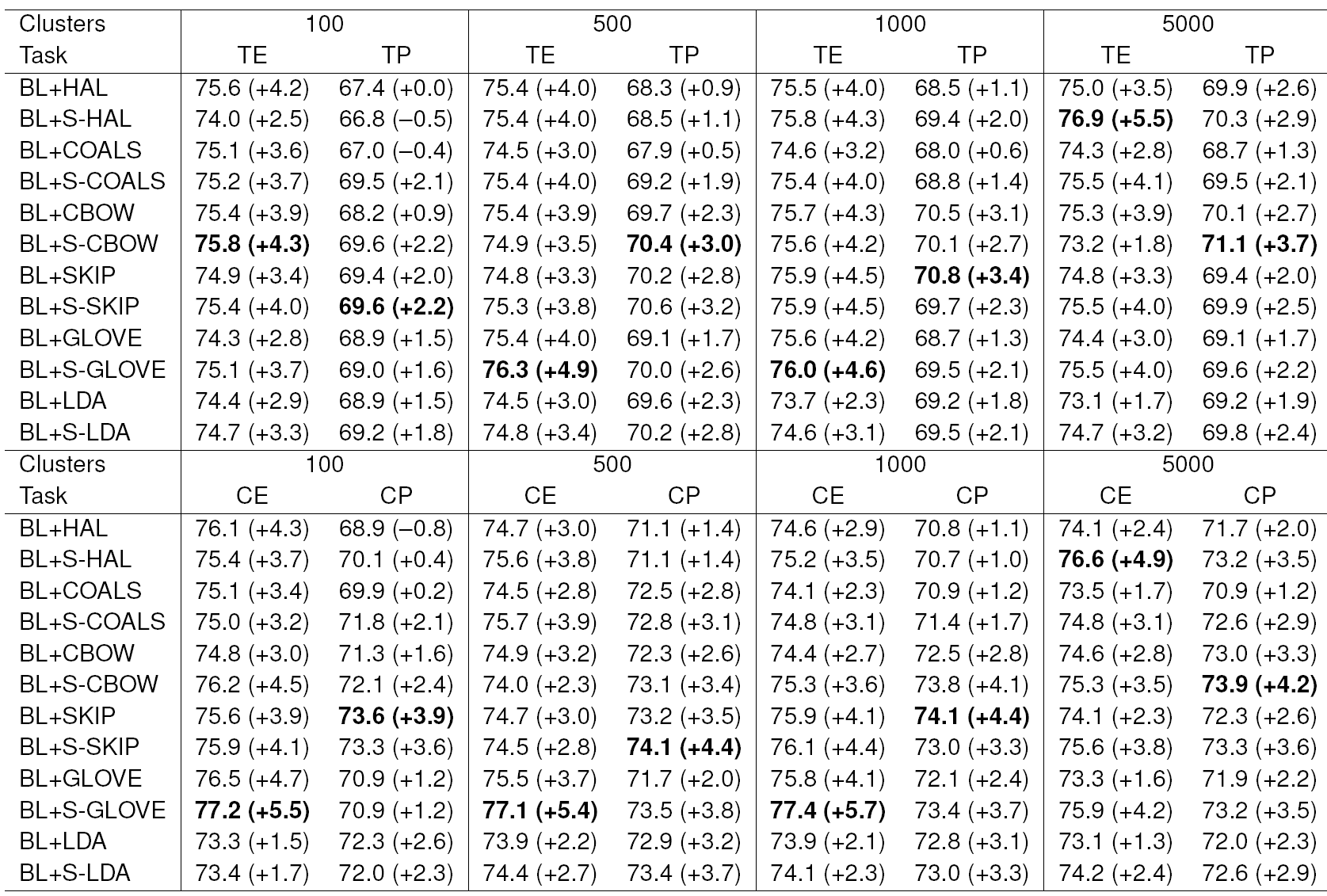
Each model brings some improvement in all the cases. Also, the stemmed versions of the models are almost always better than the unstemmed models. Thus, we continued the experiments only with the stemmed models for Czech. The stems are used as a separate features and are seen to be very useful for Czech (see Table 6).
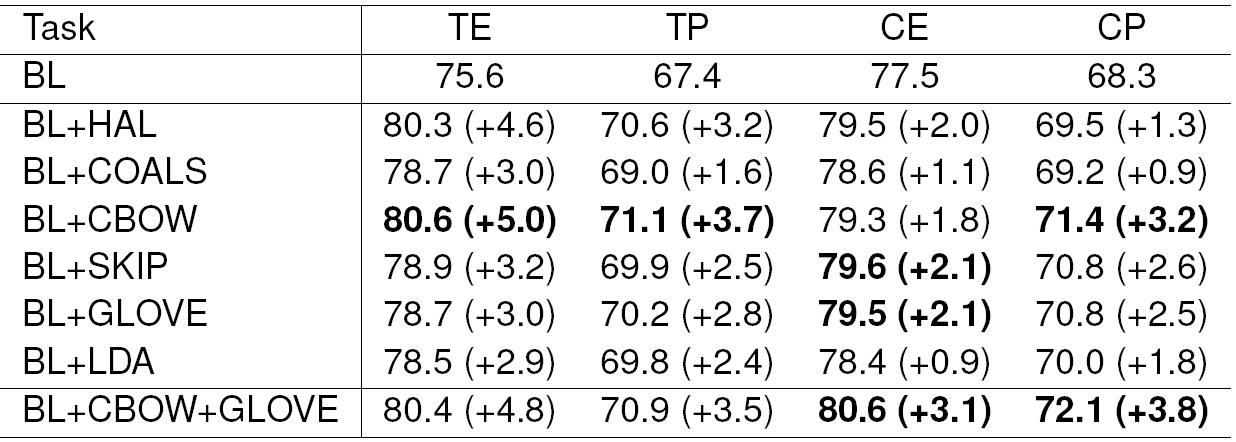
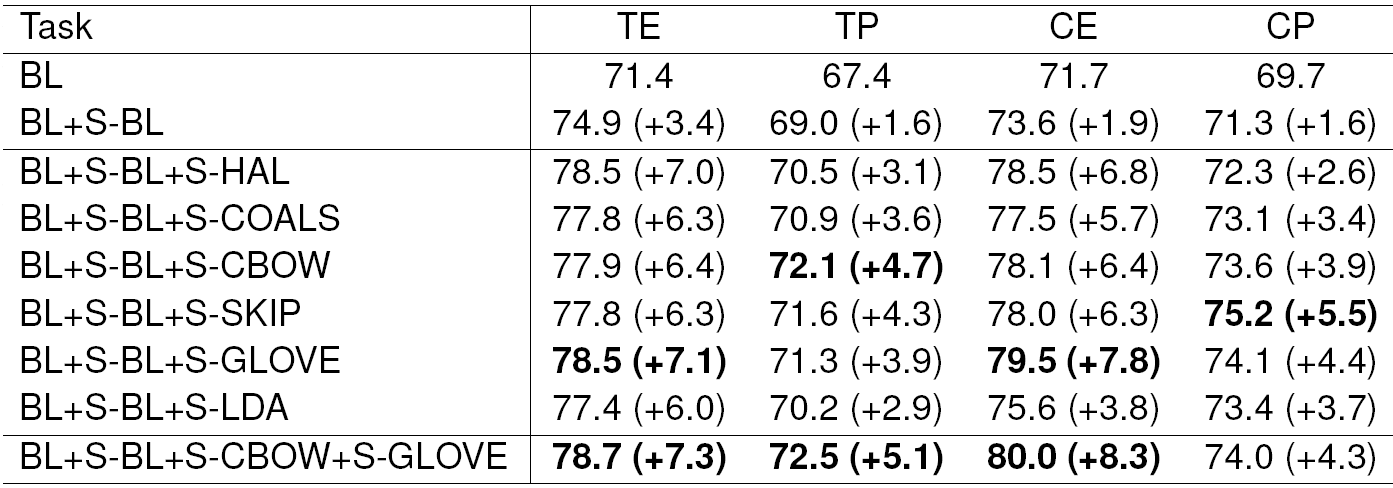
In the subsequent experiments, we tried to combine all the clusters from one model. We assumed that different clustering depths could bring useful information into the classifier. These combinations are shown in Table 5 for English and Table 6 for Czech. We can see that the performance was considerably improved. Taking these results into account, the best models for ABSA seem to be GloVe and CBOW.
To prevent overfitting, we cannot combine all the models and all the clustering depths together. Thus, we only combined the two best models (GloVe, CBOW). The results are shown again in Tables 5 and 6 in the last row. In all the subtasks, the performance stagnates or slightly improves.
Our English baseline extracts aspect terms with 75.6% 𝐹-measure and aspect categories with 77.6% ??-measure. The Czech baseline is considerably worse, and achieves the results 71.4% and 71.7% 𝐹-measures in the same subtasks. The behaviour of our baselines for sentiment polarity tasks is different. The baselines for aspect term polarity and aspect category polarity in both languages perform almost the same: the accuracy ranges between 67.4% and 69.7% for both languages.
In our experiments, the word clusters from semantic spaces (especially CBOW and GloVe models) and stemming by HPS proved to be very useful. Large improvements were achieved for all four subtasks and both languages.
The aspect term extraction and aspect category extraction 𝐹-measures of our systems improved to approximately 80% for both languages. Similarly, the polarity detection subtasks surpassed 70% accuracy, again for both languages.
7 Summary
In this paper, we explored several unsupervised methods for word meaning representation. We created word clusters and used them as features for the ABSA task. We achieved considerable improvements for both the English and Czech languages. We also used the unsupervised stemming algorithm called HPS, which helped us to deal with the rich morphology of Czech.
Out of all the tested models, GloVe and CBOW seem to perform the best, and their combination together with stemming for Czech was able to improve all four ABSA subtasks. To the best of our knowledge, these results are now the state of the art for Czech.
We created two new Czech corpora within the restaurant domain for the ABSA task: one labeled for supervised training, and the other (considerably larger) unlabeled for unsupervised training. The corpora are available to the research community.
Since none of the methods used to improve ABSA in this paper require any external information about the language, we assume that similar improvements can be achieved for other languages. Thus, the main direction for future research is to experiment with more languages from different language families.

