












 (pdf)
(pdf)




 SciELO
SciELO  SciELO
SciELO 
 Permalink
Permalink
1. Introducción
La deforestación y la degradación forestal son dos procesos que se han asociado con algunos de los conductores del cambio global como la pérdida de biodiversidad, emisiones de gases de efecto invernadero, degradación de la provisión de los servicios ambientales, entre otros (Giam, 2017; Kindermann et al., 2008; Pearson et al., 2017; Pimentel, 1997; Putz & Redford, 2010). Por ello, a nivel internacional se han planteado realizar acciones para reducir las tasas de deforestación y degradación forestal y promover un uso sostenible de los recursos forestales, como el Acuerdo de París, los Objetivos de Desarrollo Sostenible, las Metas de Aichi y el programa REDD+ (Deschamps Ramírez & Larson, 2017; UN, 2015, 2016; UNEP & CBD, 2010).
El primer paso para llevar a cabo acciones en este sentido es cuantificar la magnitud de estos fenómenos, y posteriormente, monitorearlos para identificar su comportamiento a través del tiempo y saber si se está avanzando en la reducción de las tasas de deforestación y degradación forestal (Bray & Klepeis, 2005; Fernández-Montes de Oca et al., 2021). Esto ha promovido que desde hace varios años se desarrollen métodos que permitan identificar y cuantificar estos procesos, hacerlo con mayor precisión, obtener estimaciones con menor error y con mayor resolución espacial y temporal (e.g., Hansen et al., 2013; Isaienkov et al., 2020; Simoes et al., 2021; Zhu & Woodcock, 2014).
La teledetección o percepción remota ha jugado un papel fundamental en el monitoreo de los bosques tropicales y sus procesos de pérdida y degradación, debido a su capacidad para fungir como un acervo histórico y monitorear superficies extensas (Aplin, 2004; Giri, 2020). Con el desarrollo de nuevos sensores con mayor resolución, espectral, espacial y temporal, también se han aumentado las capacidades para monitorear estos bosques (Hoeser et al., 2020; Melesse et al., 2007). Entre las imágenes gratuitas, las imágenes de la misión Copernicus, han permitido utilizar imágenes multiespectrales (MS) y de radar de apertura sintética (SAR) para monitorear la superficie terrestre (Malenovský et al., 2012). El uso conjunto de estas imágenes permite obtener información complementaria sobre la superficie incluyendo actividad fotosintética, humedad y propiedades geométricas (Hirschmugl et al., 2018; Joshi et al., 2016).
Además, el desarrollo y uso de nuevos algoritmos como los de aprendizaje profundo han permitido mejorar las capacidades para monitorear la superficie terrestre, en comparación con alternativas previamente disponibles (e.g., algoritmos de aprendizaje automatizado; Ortega Adarme et al., 2020; Hoeser et al., 2020). La principal ventaja de los algoritmos de aprendizaje profundo, en particular de las redes neuronales convolucionales, consta del uso de información en la dimensión espacial y temporal, además de la espectral para identificar las clases o procesos de interés (Kattenborn et al., 2021; Luo et al., 2019). Esto permite disminuir el error con el que se generan los productos de monitoreo, así como mejorar las capacidades para distinguir clases potencialmente difíciles de discriminar (e.g., bosques maduros, plantaciones y bosques secundarios).
En particular, la U-Net es un algoritmo de aprendizaje profundo ampliamente utilizado para realizar clasificaciones de cubiertas y usos del suelo, cuyo potencial ha sido probado en distintos sistemas y con resultados prometedores (Flood et al., 2019; Ronneberger et al., 2015; Wagner et al., 2019). Por ello, este trabajo pretende evaluar las capacidades del uso de la U-Net con imágenes MS y SAR para obtener información más detallada de la superficie terrestre, sobre todo para tratar de distinguir entre cubiertas arbóreas con distintas características y usos, i.e., bosque maduro, bosque secundario y plantaciones. Además, evaluará las capacidades de dicho procedimiento para detectar la pérdida de este tipo de cubiertas (i.e., deforestación) e identificar la degradación forestal, mediante la modelación de cambios en la biomasa aérea.
El trabajo contiene tres secciones principales. La primera presenta la evaluación de un algoritmo de aprendizaje profundo, la U-Net, para realizar una clasificación de tipos de vegetación y usos del suelo, utilizando imágenes MS (Sentinel-2) y SAR (Sentinel-1). Esta sección permitió probar si el método empleado era capaz de distinguir entre distintos tipos de cubierta arbórea (i.e., mejorar las capacidades para distinguir entre distintos tipos de cubiertas arbóreas). La segunda parte evalúa el uso de la versión 3D de este algoritmo, la U-Net 3D, la cual incorpora la dimensión temporal para detectar la deforestación y tratar de distinguir entre la pérdida de bosque maduro y bosque secundario o plantaciones. La definición de estas dos clases estuvo determinada por los resultados obtenidos en el capítulo anterior. La última sección aborda el potencial de una versión más compleja del algoritmo U-Net 3D, U-Net 3D con fusión tardía, para detectar el proceso de degradación forestal, identificado como una pérdida de biomasa aérea en el bosque.
2. Métodos y materiales
2.1 Sitios de estudio
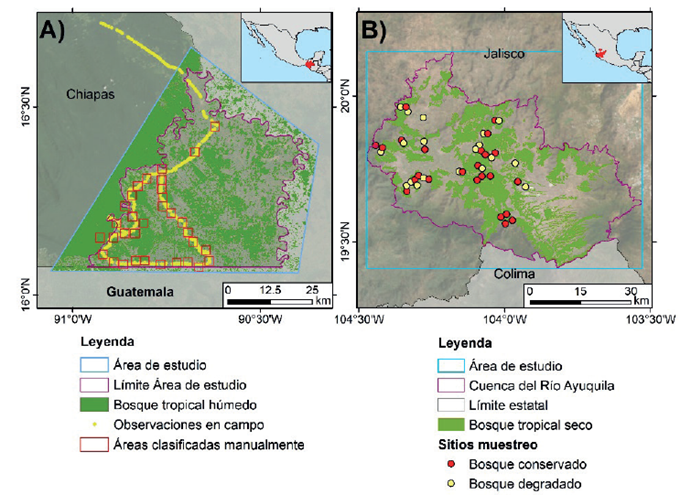
El trabajo se realizó en dos sitios de estudio: 1) un área que cubre el municipio de Marqués de Comillas y Benemérito de las Américas, así como áreas aledañas en el municipio de Ocosingo y 2) La zona de estudio correspondió a la parte occidental de la cuenca del río Ayuquila en Jalisco, la cual se encuentra en los siguientes municipios: Autlán de Navarro, Ejutla, El Grullo, El Limón, Tolimán, Tonaya, Tuxcacuesco y Unión de Tula. En la primera zona de estudio domina el proceso de deforestación, mientras que, en el segundo, la degradación forestal. Por ello, cada sitio fungió como un objeto de estudio ideal para monitorear estos dos procesos.
La primera área de estudio abarcó aproximadamente 5,900 km2 y forma parte de la región de la Selva Lacandona, la cual se caracterizar por presentar una temperatura media anual de 24 a 26 °C y una precipitación media anual de 2 266 mm concentrada en los meses de mayo a diciembre (Centro Nacional de Investigaciones Agrarias, 1982; SEMARNAP, 2000). La altitud de la zona de estudio varía entre los 50 y 700 msnm y el tipo de vegetación predominante es Selva Alta Perennifolia o Bosque Tropical Húmedo (Carabias et al., 2015; SEMARNAP, 2000).
La segunda zona de estudio abarca aproximadamente 3,500 km2 y presenta una temperatura media anual entre 18 y 24 °C, así como una precipitación media anual de 1000 mm, concentrada en los meses de junio a octubre (Cuevas & Guzmán, 1998; García, 1998). La altitud de la zona de estudio se encuentra entre los 500 y 3800 msnm y presenta dos tipos de vegetación, el bosque tropical caducifolio que es el más abundante en las partes bajas (500-2500 msnm) y el bosque templado, en las partes más altas de la cuenca (2500-3800 msnm; Borrego & Skutsch, 2019; Cuevas & Guzmán, 1998). El bosque tropical caducifolio se caracteriza por estar dominado por especies arbóreas de la familia Fabaceae, tales como Lysiloma sp., Acacia sp. y Vachellia sp. Figura 1.
2.2 Imágenes
Como insumos para realizar las distintas tareas con el modelo U-Net, se utilizaron imágenes SAR y MS registradas por los sensores Sentinel-1 y -2, respectivamente. Para las imágenes SAR, consultó la información de la colección de imágenes Sentinel-1 GRD (Ground Range Detected), la cual contiene la información de retrodispersión en dB (σ0) en dos bandas VV (polarización vertical-vertical) y VH (vertical-horizontal). Posteriormente, estas imágenes fueron corregidas utilizando el ángulo de registro de la información (γ0; Small, 2011). En el caso de las imágenes MS, se consultó la colección Sentinel-2 2A, que corresponde a la reflectancia debajo de la atmosfera (bottom of atmosphere), y únicamente se utilizaron las bandas de mayor resolución espacial (10 m): azul (B), verde (G), rojo (R) e infrarrojo cercano (NIR).
Para el trabajo de clasificación de tipos de vegetación y usos del suelo se usó la imagen Sentinel-2 más cercana a la fecha de registro de datos de campo, mientras que para las Sentinel-1 se usó un mosaico del promedio de la retrodispersión de un mes. En el caso del trabajo enfocado en detectar la deforestación se usaron compuestos multitemporales de imágenes Sentinel-1 y -2. Estos compuestos se definieron como la ventana temporal más pequeña en la que se pudieran obtener compuestos multiespectrales sin nubes (i.e., 3-5 meses, febrero-abril, mayo-septiembre, octubre-enero). En este caso, se construyeron compuestos Sentinel-1 para las mismas ventanas temporales. Finalmente, en el último capítulo se usaron compuestos mensuales Sentinel-1, mientras que en Sentinel-2 se usaron compuestos cuatrimestrales. Todas las imágenes utilizadas para hacer las predicciones contaron entonces con seis bandas: 4 MS (B, G, R, NIR) y 2 SAR (VV y VH). Todo este procedimiento se realizó en la API de Javascript de Google Earth Engine (Gorelick et al., 2017).
2.3 Creación de datos de entrenamiento y validación
Para cada uno de las secciones del trabajo se crearon datos de entrenamiento mediante interpretación visual usando imágenes Planet, Google, Bing y Yandex y en algunos casos, utilizando observaciones de campo. En algunos casos se observaron pequeños desfases entre las imágenes de muy alta resolución y las que utilizó el modelo para reconocer las clases; por lo cual, para minimizar el efecto de estos desfases, todos los datos de entrenamiento, validación y prueba se digitalizaron de acuerdo con la información de las imágenes Sentinel-1 y Sentinel-2. En todos los casos se hizo un aumento artificial de los datos mediante un submuestreo de las áreas de entrenamiento y creando versiones en espejo en un sentido vertical y horizontal de ellas.
En el trabajo enfocado en realizar una clasificación de tipos de cubierta, los datos de entrenamiento constaron de clasificaciones manuales de 33 áreas de 256 × 256 píxeles. Estas áreas se clasificaron manualmente en diez clases: bosque maduro, bosque secundario, vegetación inundable, plantaciones maduras, plantaciones jóvenes, pastizales/agricultura, suelo, caminos, agua, asentamientos humanos. En el trabajo enfocado en detectar la deforestación, los datos de entrenamiento correspondieron a 330 cuadros con por lo menos un área deforestada. En el caso del trabajo realizado para detectar la degradación forestal, los datos de entrenamiento correspondieron a 41 sitios de muestreo en campo donde se contó con los datos de la biomasa. Este procedimiento se realizó en R 4.0.3 (R Core Team, 2021) utilizando los paquetes raster (Hijmans, 2020), rray (Vaughan, 2020) y reticulate (Ushey et al., 2020).
El total de datos después de realizar el aumento artificial constó de 891 cuadros de 128 x 128 para la primera sección, 2205 de cuadros de 128 x 128 pixeles para el segundo y 187 cuadros de 3 x 3 pixeles para la última parte. La división de datos para crear la clasificación de tipos de cubierta, así como para detectar la deforestación fue de 70% para entrenamiento y 30% para verificación; mientras que para identificar la degradación forestal fue de 60 % datos de entrenamiento y 20% de validación y 20% de prueba. En esta división de datos, todas las submuestras derivadas de una muestra original fueron al conjunto de datos de entrenamiento o verificación.
2.4 Algoritmos utilizados
Para las tres secciones del trabajo se entrenó el algoritmo de aprendizaje profundo, U-Net, con los insumos MS y SAR juntos y por separado; mientras que el algoritmo de aprendizaje automatizado se entrenó con MS + SAR en la tarea de clasificación, MS+SAR y MS en la tarea de detección de la deforestación y MS + SAR, SAR y MS en la tarea de detección de degradación forestal.
2.4.1 U-Net
Para construir la arquitectura U-Net se utilizó el paquete unet (Falbel & Zak, 2020), mientras que el entrenamiento del modelo se realizó utilizando el software R 4.0.3 y el paquete keras (Allaire & Chollet, 2018) con tensorflow (Abadi et al., 2016) como backend. Para la primera parte se utilizó una U-Net clásica, mientras que para la detección de la deforestación se incorporaron las convoluciones en la dimensión temporal (U-Net 3D) y para la detección de la degradación forestal, se utilizó una U-Net 3D con fusión tardía.
Por su parte, para realizar una búsqueda de la combinación de hiperparámetros óptimos se realizaron varias iteraciones utilizando el método de early stopping para evitar el sobreajuste, en el cual, el entrenamiento se detuvo cuando la métrica de precisión no aumentó en una centésima después de 10 épocas. Además, se exploraron hiperparámetros como el tamaño de lote (16, 32, 48), el número de capas ocultas (2, 3, 4), el número de filtros en la primera capa (32, 64) y la probabilidad de dropout (0, 0,1, 0,2, 0,3, 0,4, 0,5). Otros parámetros del modelo incluyeron el uso de filtros convolucionales de 3 x 3 píxeles, el optimizador Adam, una normalización por lote y una inicialización normal de He para inicializar los pesos de los filtros. La exploración de hiperparámetros se realizó utilizando el paquete tfruns (Allaire, 2018). Para la primera y segunda sección del trabajo se utilizó la función de entropía cruzada categórica como función de pérdida, mientras que, para la tercera, el error cuadrático medio.
2.4.2 Random forests y SVM
Los algoritmos de aprendizaje automatizado evaluados fueron random forests (RF) y Support Vector Machines (SVM), los cuales son de los más frecuentemente utilizados en trabajos de aprendizaje automatizado con imágenes satelitales (Dabija et al., 2021; Lary et al., 2016; Sheykhmousa et al., 2020). El algoritmo RF es un método de ensamble basado en árboles de decisión, en el cual se entrenan varios árboles a partir de un conjunto de observaciones y variables predictivas muestreadas al azar. Después el algoritmo asigna la clase de cada píxel como aquella que obtuvo más votos en los árboles individuales (Breiman, 2001). RF se utilizó para obtener una clasificación de tipos de vegetación y usos del suelo, así como para obtener una regresión para predecir la biomasa aérea (AGB, por sus siglas en inglés) e identificar la degradación forestal. Por su parte, el SVM funciona identificando un hiperplano para discriminar entre las clases de interés. En particular, el SVM con la función de base radial, es de los más utilizados en aplicaciones de percepción remota. Por ello, en este trabajo se usó este algoritmo para identificar la deforestación en una de las regiones de estudio.
2.4.3 Métricas de evaluación
Las métricas para evaluar los dos algoritmos entrenados fueron la exactitud total (OA) y el promedio del F1-score (avgF1-score) obtenido para cada clase (Ecuaciones 1 y 3). La métrica F1-score por clase se calculó como el promedio armónico de la precisión y la sensibilidad de las clases predichas (Ecuación 2).
Donde OA corresponde a la exactitud total, TP a los verdaderos positivos, TN a los verdaderos negativos, FP a los falsos positivos, FN a los falsos negativos. F1 al F1-score, C al total de clases, c a cada clase y avgF1 al promedio de F1-scores.
Para el caso de los modelos enfocados en detectar la degradación forestal, las métricas utilizadas para evaluar los algoritmos fueron la raíz cuadrada del error cuadrático medio y la raíz del error cuadrático medio relativo (Ecuación 4 y Ecuación 5):
Donde corresponde al AGB predicha por el modelo y AGB al AGB observada (obtenida mediante el muestreo en campo). Esta métrica se evaluó sobre los datos de entrenamiento, validación y prueba. Finalmente, para obtener los intervalos de confianza (IC), estos se calcularon como 1,96 * RMSE.
3. Resultados
3.1 Clasificación de tipos de vegetación y usos del suelo
Al comparar el F1-score obtenido con la U-Net para clasificar el área de estudio en las distintas cubiertas, se observó que el algoritmo que logró obtener el avgF1-score y la exactitud total más alta sobre los datos de validación fue U-Net MS + SAR (Tabla 1). Además, en las diferentes clases de cubierta arbórea, U-Net MS + SAR obtuvo los F1-score más altos (Tabla 1). A pesar de ello, en algunas clases U-Net MS obtuvo mejores resultados, e.g., agua, caminos. El mapa final de las clases de tipos de vegetación y usos del suelo permitió identificar la distribución espacial de las distintas cubiertas (Figura 2). La versión detallada de este trabajo se puede consultar en Solórzano et al. (2021).
Tabla 1 F1-score y su diferencia respecto al valor más alto (ΔF1-score) para cada clase con las tres U-Net MS + SAR, MS, SAR, así como RF MS + SAR
| Clase | U-Net | RF | ||
| MS + SAR | MS | SAR | MS + SAR | |
| Agua | 0,96 | 0,97 | 0,94 | 0,94 |
| Asentamientos humanos | 0,87 | 0,87 | 0,45 | 0,29 |
| Bosque maduro | 0,86 | 0,86 | 0,79 | 0,69 |
| Bosque secundario | 0,45 | 0,34 | 0,20 | 0,33 |
| Caminos | 0,35 | 0,43 | 0 | 0,23 |
| Pastizales / Agricultura | 0,78 | 0,77 | 0,69 | 0,63 |
| Plantaciones jóvenes | 0,11 | 0,03 | 0,01 | 0,11 |
| Plantaciones maduras | 0,62 | 0,54 | 0,47 | 0,43 |
| Suelo | 0,65 | 0,64 | 0,30 | 0,57 |
| Vegetación acuática | 0,15 | 0,10 | 0 | 0,04 |
| Exactitud total (OA) | 0,76 | 0,76 | 0,65 | 0,53 |
| avgF1-score | 0,58 | 0,55 | 0,39 | 0,43 |
Fuente: Solórzano et al. (2021). Abreviaturas: MS, bandas multiespectrales; SAR, bandas de apertura sintética y RF, Random forests.
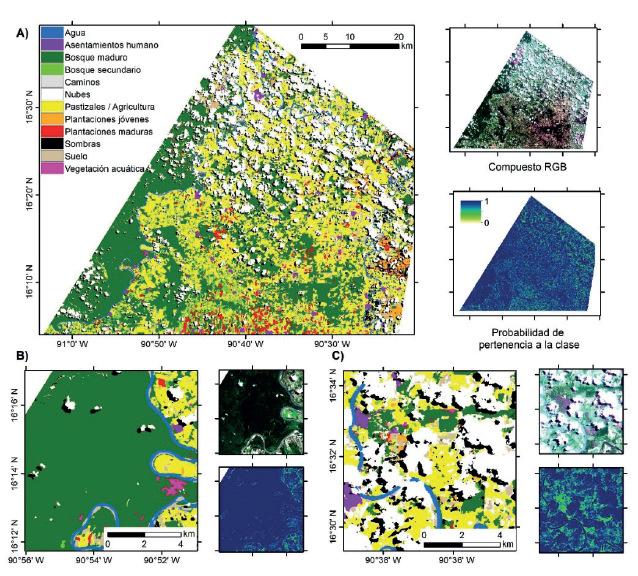
Fuente: Solórzano et al. (2021)
Figura 2 A) Clasificación de cubierta y usos del suelo del área de estudio completa utilizando la U-Net MS + SAR, así como el compuesto RGB y los mapas de probabilidad de pertenencia a la clase correspondiente. B) Ejemplo de un sitio dominado por bosque maduro con altas probabilidades de pertenencia. C) Ejemplo de un área recientemente quemada con una alta presencia de nubes y sombras, donde se observan valores bajos de pertenencia.
3.2 Detección de áreas deforestadas
En el trabajo enfocado en detectar la deforestación, la U-Net 3D MS fue la que obtuvo los mejores resultados en la OA, avgF1-score y F1-score por clase sobre los datos de validación (Tabla 2). Por su parte, con SVM el modelo SVM MS + SAR fue el que obtuvo los mejores resultados (Tabla 2). El mapa final permitió localizar las áreas deforestadas en el paisaje estudiado (Figura 3). La versión detallada de este trabajo se puede consultar en Solórzano et al. (2023).
Tabla 2 Exactitud total y avgF1-score para cada clase con las tres U-Net 3D MS, SAR y MS + SAR, así como SVM MS + SAR y MS
| Algoritmo | Imágenes | OA | avgF1-score | Per class F1-score | ||
| No defores-tación | Pérdida de bosque maduro | Pérdida de bosque secundario o plantación | ||||
| U-Net 3D | MS* | 0,99 | 0,73 | 1 | 0,73 | 0,45 |
| SAR | 0,98 | 0,62 | 0,99 | 0,51 | 0,24 | |
| MS + SAR | 0,99 | 0,70 | 1 | 0,68 | 0,44 | |
| SVM | MS + SAR* | 0,95 | 0,52 | 0,98 | 0,35 | 0,24 |
| MS | 0,95 | 0,51 | 0,97 | 0,36 | 0,18 | |
Nota: Abreviaturas: MS, bandas multiespectrales, SAR, bandas de apertura sintética, SVM, Support Vector Machines. Evaluación sobre los datos de validación sin aumento artificial de los datos. La arquitectura que obtuvo el mayor avgF1-score se indica con un *.
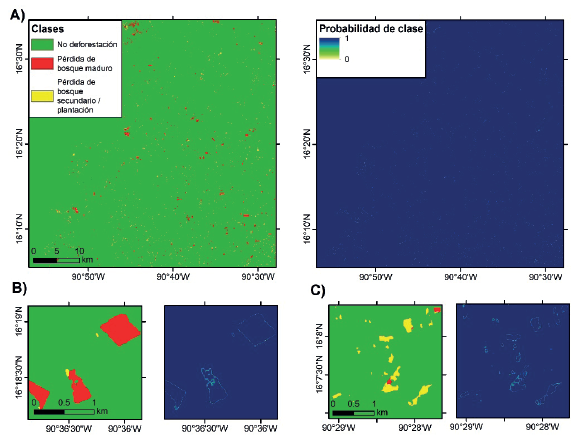
Fuente: Solórzano et al. (2023)
Figura 3 A) Clasificación de las áreas deforestadas de 2019 a 2020 en el área de estudio utilizando la U-Net 3D MS y su mapa de probabilidad de pertenencia a la clase correspondiente. B) Ejemplo de un sitio dominado por deforestación de bosque maduro. C) Ejemplo de un área dominada por deforestación de bosque secundario o plantaciones.
3.3 Detección de la degradación forestal
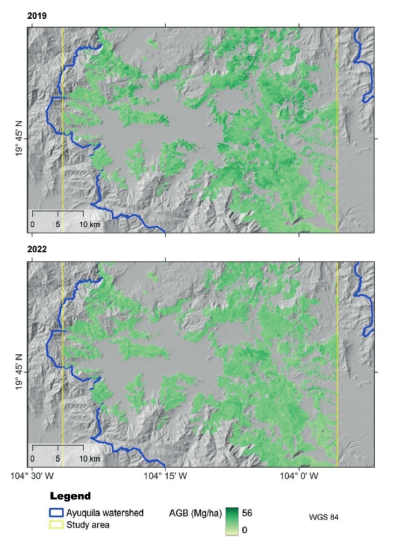
En los resultados obtenidos para la detección de la degradación forestal, RF MS + SAR obtuvo el menor error en los datos de prueba (RMSE; Tabla 3). Usando este modelo se hicieron las predicciones de biomasa para 2019 y 2022 (Figura 4). Debido a que el error del mejor modelo fue alto (rRMSE = 64,40%), se concluyó que la confiabilidad de las predicciones no permitió identificar con suficiente confiabilidad las áreas degradadas, es decir, aquellas que sufrieron una disminución de biomasa entre 2019 y 2022.
Tabla 3 Algoritmos que alcanzaron la menor raíz cuadrada del error cuadrático medio (RMSE) sobre los datos de prueba
| Algoritmo | RMSE (Mg / ha) | rRMSE (%) | ||||
| Prueba | Entrenamiento | Validación | Prueba | Entrenamiento | Validación | |
| U-Net 3D LF MS + SAR | 8,10 | 6,91 | 15,50 | 82,51 | 24,25 | 52,43 |
| RF MS + SAR | 4,10 | 2,38 | 16,10 | 64,40 | 8,35 | 54,44 |
Nota: Además, se muestra el RMSE sobre el conjunto de datos de entrenamiento, validación y prueba sin aumento artificial de los datos.
4. Discusión
4.1 Principales hallazgos
El objetivo principal de la tesis fue evaluar si los algoritmos de aprendizaje profundo son capaces de mejorar las capacidades para describir y monitorear la superficie terrestre. Debido a que estos algoritmos incorporan la dimensión espacial y temporal, aparte de la espectral, han permitido obtener resultados más precisos y ganado popularidad en los estudios de percepción remota (Isaienkov et al., 2020; Pelletier et al., 2019; Zhang et al., 2016). Este trabajo mostró que estos algoritmos permiten ayudar a mejorar las capacidades para algunas tareas (e.g., clasificación de tipos de vegetación y usos del suelo o detección de la deforestación); sin embargo, no para todas (e.g., detección de la degradación forestal como disminución de la biomasa arbórea). Estos resultados corresponden con los reportes previos en los que se menciona que la ventaja de estos algoritmos depende fuertemente de la tarea a realizar y del tamaño de datos disponibles para entrenar a los algoritmos (Chollet & Allaire, 2018; LeCun et al., 2015).
En este trabajo se comparó un algoritmo basado en la U-Net con alguno de los algoritmos de aprendizaje automatizado más populares para aplicaciones de percepción remota como RF y SVM (Dabija et al., 2021; Sheykhmousa et al., 2020). En los primeros dos capítulos se observó que los algoritmos de aprendizaje profundo (U-Net) superaron a los algoritmos de aprendizaje automatizado, similar a lo reportado en trabajos similares (Ortega Adarme et al., 2020; de Bem et al., 2020; Du et al., 2020; Giang et al., 2020; Ienco et al., 2019; Matosak et al., 2022; Robinson et al., 2019; Stoian et al., 2019). Esto quiere decir que la integración de información en la dimensión espacial (clasificación), espectral y temporal (deforestación) trajo beneficios para el trabajo de clasificación. Sin embargo, en el caso de la degradación forestal, el resultado fue contrario al reportado en estudios similares para modelar el AGB a partir de imágenes de percepción remota (Buxbaum et al., 2022; Castro et al., 2020; Dong et al., 2020; Ghosh & Behera, 2021; Hamedianfar et al., 2022; Moradi et al., 2022; Talebiesfandarani & Shamsoddini, 2022; Zhang et al., 2022; Zhang et al., 2019). El único otro artículo que reportó un mejor desempeño con un algoritmo de aprendizaje automatizado que uno profundo, justifica dicho resultado por el reducido tamaño de los datos de entrenamiento y la alta plasticidad de las redes neuronales convolucionales que provocó un sobreajuste mayor que el algoritmo de aprendizaje automatizado (Tamiminia et al., 2021). Nuestra conclusión fue la misma.
Los algoritmos de aprendizaje profundo, en particular los basados en redes neuronales convolucionales como la U-Net, parecen ser mejores para resolver tareas de clasificación, aun cuando se cuente con conjunto de datos relativamente pequeño. De igual manera, la complejidad del esquema de clasificación parece influir en las capacidades de discriminación (un mayor o menor número de clases; Solórzano et al., 2021). Estos algoritmos parecen requerir de un mayor número de datos para resolver tareas más complejas o una relación señal/ruido más grande para obtener buenos resultados. Por ejemplo, cuando hay una relación señal/ruido pequeña es difícil diferenciar entre una señal de la cubierta o proceso de interés y el ruido; mientras que al ser ésta grande, resulta fácil diferenciar entre la señal de interés (verdaderos positivos) y el ruido (falsos positivos). Por ello, es probable que otro tipo de métodos que requieren menos datos de entrenamiento y que suponen cierto tipo de respuesta, entre las variables predictivas y de respuesta como los modelos lineales o algoritmos de aprendizaje automatizado, permitan un mejor resultado en dichas circunstancias, como fue el caso de la detección de la degradación forestal.
Finalmente, este trabajo mostró la flexibilidad que tiene la U-Net para resolver distintas tareas. En las tres secciones del trabajo se utilizó una versión modificada de la U-Net para resolver tareas de clasificación y de regresión (i.e. sección de degradación forestal). En el primer caso se usó la U-Net clásica, en el segundo, una U-Net 3D y en el último una U-Net con fusión tardía. Cada una de ellas, está basada en la U-Net original, pero dependiendo de sus modificaciones permite incorporar la dimensión espacial, temporal o contar con entradas con distinto número de observaciones a través del tiempo.
4.2 Implicaciones para el monitoreo de las cubiertas arbóreas
El desarrollar métodos automatizados, como el uso de algoritmos de aprendizaje profundo, para monitorear los tipos de cubiertas, usos del suelo, su dinámica, y su contenido de biomasa permite obtener evaluaciones con un menor tiempo de procesamiento y recursos. Esto implica que pueden ser técnicas más costo eficientes que minimicen los pasos que requieran de interpretación visual o el registro de datos de campo. Además, este tipo de métodos se pueden incorporar en cadenas de trabajo donde se revisen los datos en un esquema activo para optimizar los recursos de interpretación visual (Ortega Adarme et al., 2020; Bragagnolo et al., 2021a). Por otro lado, estos métodos pueden utilizar datos antiguos e incorporar datos nuevos, lo cual representa una opción atractiva para plantear programas de monitoreo basados en información preexistente y la incorporación de nuevos datos. Por ello, es probable que el futuro de los sistemas de monitoreo de la superficie terrestre se base en este tipo de algoritmos (Bragagnolo et al., 2021b). Sin embargo, como con cualquier método automatizado, su potencial dependerá de la cantidad y calidad de datos con la que se puede alimentar este tipo de métodos.
A pesar de que la diferenciación entre tipos de cubiertas arbóreas permite obtener mayor detalle de los procesos que ocurren en la superficie terrestre, esta discriminación ha sido muy difícil de lograr mediante sensores remotos y algoritmos previamente disponibles. El interés principal por diferenciar entre bosque maduro, secundario y plantaciones radicó en las diferencias que presentan en cuanto a características como biodiversidad, carbono almacenado y servicios ecosistémicos provistos, así como prácticas de aprovechamiento de los recursos naturales (Fernández-Montes de Oca et al., 2021; Gibson et al., 2011; Putz & Redford, 2010; Tropek et al., 2014).
En los dos trabajos realizados en parte de la Selva Lacandona, se trató de separar las clases de cubierta arbórea, por lo menos en dos categorías. Esto permite describir los tipos de cubierta arbórea y sus transiciones con mayor detalle, lo cual puede ser crítico para determinar el efecto de algunas presiones internacionales o nacionales (demanda de ciertos cultivos o implementación de incentivos). En muchas ocasiones, el cambio de uso de suelo de bosque a plantaciones puede ir acompañado de diversas afectaciones tanto sociales como ambientales que incluyen el despojo de tierras, la explotación laboral, la alteración del ciclo hidrológico, la degradación de los suelos, la pérdida de hábitat, entre otras (Isaac-Márquez et al., 2016; Romero & Albuquerque, 2018). Por ello, estos capítulos no solo trataron de demostrar que los algoritmos de aprendizaje profundo permiten mejorar los resultados en términos de exactitud, sino también mejorar el detalle de algunos esquemas de clasificación. Esta información será de vital importancia para estimar de manera indirecta potenciales afectaciones en los territorios estudiados.
En el caso de la zona de estudio de Ayuquila, esta es una zona de acciones tempranas de REDD+, el programa de reducción de emisiones asociadas a la deforestación y degradación de los bosques. Por ello, en esta zona el estudio se enfocó a tratar de cuantificar la degradación forestal como una reducción en la biomasa del bosque. Estudios previos han reportado que la probabilidad de que un bosque se degrade está asociada con un índice de pobreza y el tamaño poblacional de las localidades cercanas a los bosques (Borrego & Skutsch, 2019; Morales-Barquero et al., 2015); aunque reconocen que esto no necesariamente implica causalidad. Por otro lado, el porcentaje de bosque degradado a nivel municipal en la región está relacionado de manera negativa con la distancia a carreteras y el porcentaje de tierras parceladas (Jiménez-Rodríguez et al., 2022). Sin embargo, estos estudios habían trabajado con la detección del bosque degradado como un problema de clasificación (i.e., bosque degradado vs. bosque conservado) y no como un proceso, es decir como una disminución de la biomasa. Aunque este enfoque resulta mucho más complicado, tiene la ventaja de que considera la variación espacial natural del AGB del bosque, en respuesta a algunas variables biofísicas como la pendiente, el tipo de suelo, entre otras. Aunque los resultados no fueron tan prometedores, se logró obtener un estimado del carbono almacenado en el bosque tropical caducifolio de la zona. Esta predicción no fue muy distinta de lo que se hubiera obtenido al multiplicar el área de bosque tropical caducifolio por el promedio de AGB contenido en una ha. Sin embargo, nuestros resultados permitieron obtener mapas de AGB con una variación espacial que puede ser más realista. En este sentido, consideramos que futuros métodos deberían estar encaminados en tratar de detectar la degradación forestal como un proceso, a pesar de que eso suponga un reto mucho mayor.
4.3 Comparación MS + SAR, MS y SAR
Además de poner a prueba distintos algoritmos, este trabajo contó con un segundo objetivo, el cual constó en evaluar estas herramientas con imágenes MS y SAR, y evaluar las posibles ventajas de utilizarlas en conjunto. Cada tipo de información o imagen generada mediante un sensor remoto tiene sus propias ventajas y desventajas. Por ejemplo, las imágenes MS permiten obtener información detallada de los tipos de cubiertas de una región; sin embargo, también son sensibles a la presencia de nubes y sombras, los cuales crean artefactos que pueden hacer más difícil trabajar con ellas. Las imágenes SAR prácticamente no son sensibles a nubes, por lo tanto, permiten obtener información sin artefactos meteorológicos (aunque sí presentan otro tipo de artefactos como los topográficos), pero no tienen la riqueza ni el detalle de las imágenes MS (Flores-Anderson et al., 2019; Heckel et al., 2020; Hirschmugl et al., 2020). A pesar de ello, estudios previos han reportado mejores resultados con MS + SAR para realizar clasificaciones de tipos de vegetación y usos del suelo (Heckel et al., 2020; Hirschmugl et al., 2020; Tavares et al., 2019).
A partir de nuestros resultados y estudios previos, la ventaja de utilizar MS + SAR parece depender de la aplicación, el área de estudio o el sistema de estudio, el sistema de clasificación, la resolución de las imágenes utilizadas, la correspondencia temporal entre las bandas SAR y MS y el método utilizado para analizar los datos (Ortega Adarme et al., 2020; Joshi et al., 2016). Por ello, aunque en principio se podría suponer que al usar las imágenes MS + SAR se obtendrían mejores resultados, creemos que difícilmente se podrá dar una conclusión a priori, por lo tanto, recomendamos probar con ambos tipos de imágenes. Sin embargo, sí se quiere simplificar el conjunto de variables predictivas, las bandas MS deberían brindar mejores resultados que solo utilizar las SAR.
4.4 Comparaciones con estudios similares
Al comparar el F1-score y OA de la clasificación de cubiertas con otras realizadas utilizando la U-Net, se observó que este trabajo se encontró entre los valores más bajos (Du et al., 2020; Flood et al., 2019; Giang et al., 2020; Isaienkov et al., 2020; Robinson et al., 2019; Stoian et al., 2019; Wagner et al., 2020; Wagner et al., 2019). Sin embargo, el avgF1-score y OA de la detección de la deforestación se encontró dentro de los valores reportados utilizando alguna arquitectura basada en la U-Net (Ortega Adarme et al., 2020; Bragagnolo et al., 2021a, 2021b; Isaienkov et al., 2020; Matosak et al., 2022). En el caso la detección de la degradación forestal, el error de la modelación de AGB mediante el uso de una arquitectura basada en la U-Net, fue mayor al reportado en trabajos previos utilizando arquitecturas basadas en redes neuronales convolucionales (Buxbaum et al., 2022; Dong et al., 2020; Huy et al., 2022; Moradi et al., 2022; Talebiesfandarani & Shamsoddini, 2022; Tamiminia et al., 2021; Zhang et al., 2022). A pesar de ello, hay que destacar que muchos de los trabajos con los que se estos estudios, se podrían considerar como sistemas de clasificación más sencillos (e.g., menos clases o clases más fáciles de discriminar) o sistemas más simples en comparación con los abordados en este trabajo (e.g., sistemas de monocultivos).
5. Conclusiones
Este trabajo demostró que los algoritmos de aprendizaje profundo basados en redes neuronales convolucionales son una alternativa atractiva para mejorar las capacidades para clasificar y monitorear la cubierta terrestre; sin embargo, su potencial estará limitado por la complejidad de la tarea a resolver, así como del tamaño de los datos de entrenamiento. En particular, este trabajo demostró que para crear una clasificación de tipos de vegetación y usos del suelo, así como para la detección de la deforestación, las arquitecturas basadas en redes neuronales convolucionales fueron capaces de obtener resultados más precisos que su contraparte de aprendizaje automatizado (i.e., RF o SVM). A pesar de ello, para la detección de la degradación forestal como una disminución de AGB, se observó lo contrario.
Por su parte, aunque en general el uso de las bandas MS y SAR fue beneficioso, no en todas las evaluaciones se obtuvieron mejores resultados utilizando ambas bandas en conjunto. Por ello, consideramos que el beneficio de utilizar ambos sensores depende de la aplicación y la tarea a realizar. No obstante, por sí solas, las bandas MS tendieron a contribuir con información más útil que la SAR.
El desarrollo de este tipo de trabajos brindará herramientas para establecer métodos que incorporen el uso de algoritmos de aprendizaje profundo en su flujo de trabajo y que permitan aumentar las capacidades de descripción y monitoreo de la superficie terrestre. Esto permitirá establecer líneas base más detalladas y precisas, así como determinar tendencias temporales más certeras sobre los procesos de deforestación y degradación forestal. Esto brindará información para determinar el avance en las metas nacionalmente determinadas, así como de algunos objetivos de desarrollo sostenible.

