












 (pdf)
(pdf)




 SciELO
SciELO  SciELO
SciELO 
 Permalink
Permalink1 Introduction
In recent years, our sleep habits have changed negatively due to the amount of time we dedicate to work, hobbies, and transportation. Moreover, the incorporation of new technologies into our lifestyle has also contributed to reducing the time we dedicate to sleep [3].
There are several studies [24, 27, 35, 43] that confirm that between 10% and 13% of the global population frequently suffer from fatigue. Lack of sleep in a minimum of recommended hours [22] drives to several conditions such as drowsiness, irritability, depression, low alertness, anxiety, tension, headache, among others [4, 19, 23, 32]. Drowsiness results in a decreased awareness and both physical and mental performance. It increases the risk of suffering traffic and work accidents [54, 20].
Car accidents tend to be more fatal when caused by drowsiness compared with other causes [13] and employees with sleep problems are 1.62 times more likely to suffer an injury compared to their peers without sleep problems [46].
Social and economic demands have soared in recent years. Nowadays, we spend little time at home and plenty of time at work or in our vehicles, driving from home to work (and vice versa), shopping, going on vacation or visiting other people. In addition, there are several dangerous practices that have become commonly accepted, such as working night shifts or staying up late for leisure after a long workday [15].
Due to our lifestyle, it is important to detect and alert drowsy people to avoid accidents while driving or performing different tasks at work. Nowadays, there are several techniques to detect drowsy people using different techniques [38] based on behavioral parameters, environmental parameters, or physiological parameters. This research will focus on drowsiness detection using behavioral parameters obtained from the right eye and mouth of people in different video sequences.
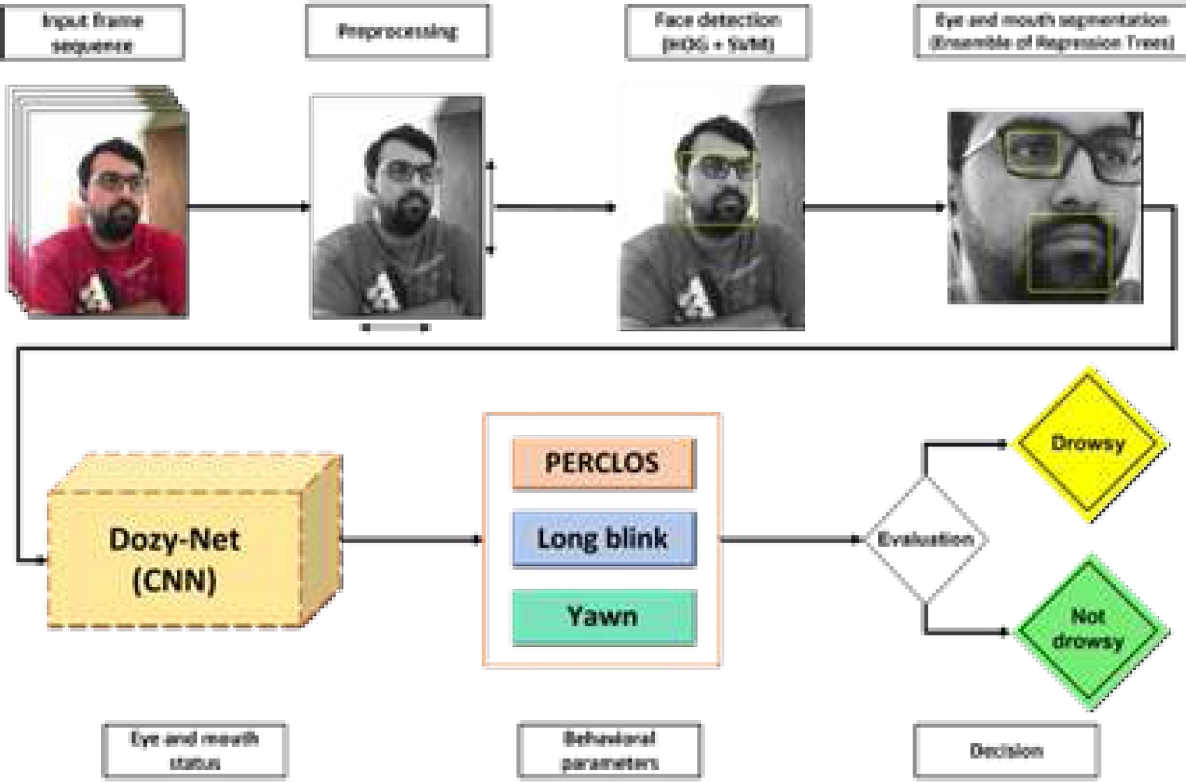
The aim is to classify everyone into one of two classes: drowsy and non-drowsy. This document is organized as follows: in Section 2, related research and state-of-the-art works will be presented.
Section 3 will introduce the methodology used in this research, along with the datasets used, the novel Convolutional Neural Network (CNN) model used for image classification, and the detailed drowsiness detection algorithm.
Section 4 will present the results obtained when detecting drowsy people. Section 5 will discuss the results from this research, and a comparison between state-of-the-art CNN models and our proposal will be presented. Finally, in Section 6, conclusions and future work will be established.
2 Related Works
Related work will be divided into three parts: those related to object recognition and tracking, those related to face and facial feature detection, and those describing drowsiness detection methods.
2.1 Object Recognition and Tracking
Object recognition is a fundamental task of computer vision and its goal is to recognize particular instances of a certain class in a more complex image. As one of the fundamental tasks of computer vision, object recognition is involved in many other tasks, such as object description or tracking. A vast literature on object detection is available but, in this paper only a few of the most recent works will be mentioned.
The Histogram of Oriented Gradients (HOG) [12] is a feature descriptor which, when combined with a classifier, such as a support vector machine (SVM), can detect objects. The HOG is still widely used despite being a pre-deep learning approach. For example, a vehicle recognition method using a combination of HOG and SVM was recently presented [36] and also a proposal on diabetic retinopathy detection using HOG, and a k-nearest neighbor classifier (KNN) [21].
With the rise of deep learning, it became possible to create more accurate, precise, faster, and more capable models. In this context, the You Only Look Once model (YOLO) is suitable for object tracking due to its high speed on detecting objects [39]. The evolution of YOLO continues to these days and their different versions have been used in a wide variety of applications.
A model for detecting and counting olive fruit flies [29], a vehicle recognition and tracking system in real time [6] and a real time recognition and tracking people during nighttime based on YOLOv3 [30] are some examples.
2.2 Face Detection
Face detection is a particular case of object recognition. Its aim is to identify faces in an image regardless of the identity of the person to whom it belongs. Face detection is important to develop different applications, such as a model that detects faces through a hybrid model that combines the Haar cascade classifier and a skin detector for developing an automatic video surveillance [17].
New techniques have been developed to improve facial expression recognition, such as feature descriptors based on geometrical moments [44] or reducing the HOG vector corresponding to the eyes and mouth area using the graph signal processing (GSP) [31].
Thanks to Deep Learning techniques, it has become possible to detect faces even under very difficult conditions, as demonstrated in works where the importance lies in the design of a CNN capable of detecting faces with various alterations that make them difficult to detect, such as blurring, noise or low illumination [7].
2.3 Drowsiness Detection
Drowsiness detection methods can be classified into three main categories: techniques based on behavioral parameters [14, 33, 53], environmental parameters [5, 9], or physiological parameters [10, 40, 52].
Environmental parameters-based methods work using data collected by one or more sensors. An example of fatigue detection using this method is the design of a steering wheel that can detect fatigue through eleven features calculated from two driving parameters: steering wheel angle and steering wheel angular velocity.
Both parameters are obtained at a rate of 25 Hz. Steering wheel was tested on ten people (3 women and 7 men) using a driving simulator and the prediction was performed using three models: an SVM, a multilevel ordered logit (MOL) and a neural network. The best accuracy obtained was 74.95% using MOL [9].
The main limitations for using this type of methods are related to the sensors. Installation and cost of the sensors could be high, and external factors can affect the measurements. For example, in driver drowsiness detection, measurements can be affected by pavement or weather conditions.
Physiological fatigue detection methods have been widely used due to the good results obtained with this type of measurements. Electroencephalograms (EEGs) are one example of the physiological measurements and parameters. For example, a work was carried out in the Chinese province of Liaoning, where 16 men took part and EEG signals were obtained through the Emotiv EPOC headset.
The EEGs obtained were processed through a twelve-layer convolutional neural network (CNN) getting an average accuracy of 97.02% [10]. Fatigue detection through physiological parameters is intrusive due to the need of wearable devices, which can cause discomfort in users on everyday activities, making them difficult to implement in vehicles or work scenarios.
Methods based on behavioral parameters have been gaining popularity in recent years due to the capability of non-intrusive drowsiness detection using parameters such as the PERcentage of eyelid CLOSure (PERCLOS) over the pupil, facial expressions, blinks, head position, yawns, analysis of physiological patterns over time series [28]. One example of drowsiness detection through PERCLOS and yawning is a model which detects drowsiness if within two minutes a person has yawned at least 3 times or if the PERCLOS value is greater than 0.4.


This method was tested using 10 videos from the YawDD dataset [1] plus one video belonging to one of the authors, achieving an accuracy of 95.91% [49]. Despite the high accuracy percentage, few videos were used to test the model.
Another example is a method that uses the mouth and eye region, PERCLOS and Frequency Of Mouth (FOM) parameters and a Multi-tasking Convolutional Neural Network for drowsiness detection.
This method was tested on the YawDDD [1] and NTHU-DDD [50] datasets achieving an accuracy of 98.72% and 98.91% on YawDD and NTHU-DDD datasets, respectively. Although the performance is good, drowsiness detection is not performed in real time, and the datasets do not take into account truly drowsy people [41].
An example of a work [37] that uses modern recurrent neural networks (RNNs) to classify segments of videos from the eyes and then detects drowsiness with an overall accuracy of 82% with RNNs and 95% with convolutional RNNs. A recent research work in which three descriptors are used to extract information from facial images: the histogram of oriented gradients (HOG); the covariance descriptor (COV); and the local binary pattern were used.
The results provided by each of the descriptors are processed by an SVM and the final decision is reached by merging the individual decisions of each one. The model was tested on the NTHU-DDD [50] dataset which is divided into three sets: training set, evaluation set and test set, scoring an accuracy of 79.84% [33].
In the same way, our proposal focuses on a non-intrusive method that uses several behavioral parameters. Our major contribution in this work is a novel and minimalist CNN, called Dozy-Net, that classifies eye blinking to compute PERCLOS index. that same CNN classifies mouth opening to detect if a person is yawning. As a result, a combination of features allows us to detect drowsy people using only video footage of their faces, trying to avoid further accidents in work or everyday life scenarios.
3 Methodology / Proposal
Drowsiness usually exhibits characteristics such as yawning, closed eyes for large periods of time and increased frequency of blinking. This drowsiness detection method is based on three behavioral parameters obtained through video frame analysis: PERCLOS, long blinks and yawns. Considering that the average blink duration is between 174 and 191 milliseconds [34] it is possible to detect them without processing every single frame of the video, thus in this model half of the frames are processed. For example, in a 10-frame sequence (
Both extracted images of facial features are resized and normalized before being classified through our custom designed Dozy-Net, to determine their status. Then, drowsiness is detected through three parameters: Yawning, PERCLOS and long blinks. These behavioral parameters are obtained from the number of continuous frames in which the mouth or eye has been open.
The right eye was tracked since the camera was placed at the right in most of the UTA-RLDD videos [18], making easier to detect and track it. PERCLOS is calculated every 200 frames and since not every frame is processed, it is needed to modify the way that the number of frames is counted and how the PERCLOS value is calculated:
PERCLOS is computed according to equation 1, where
3.1 Datasets
3.1.1 Eyes Dataset
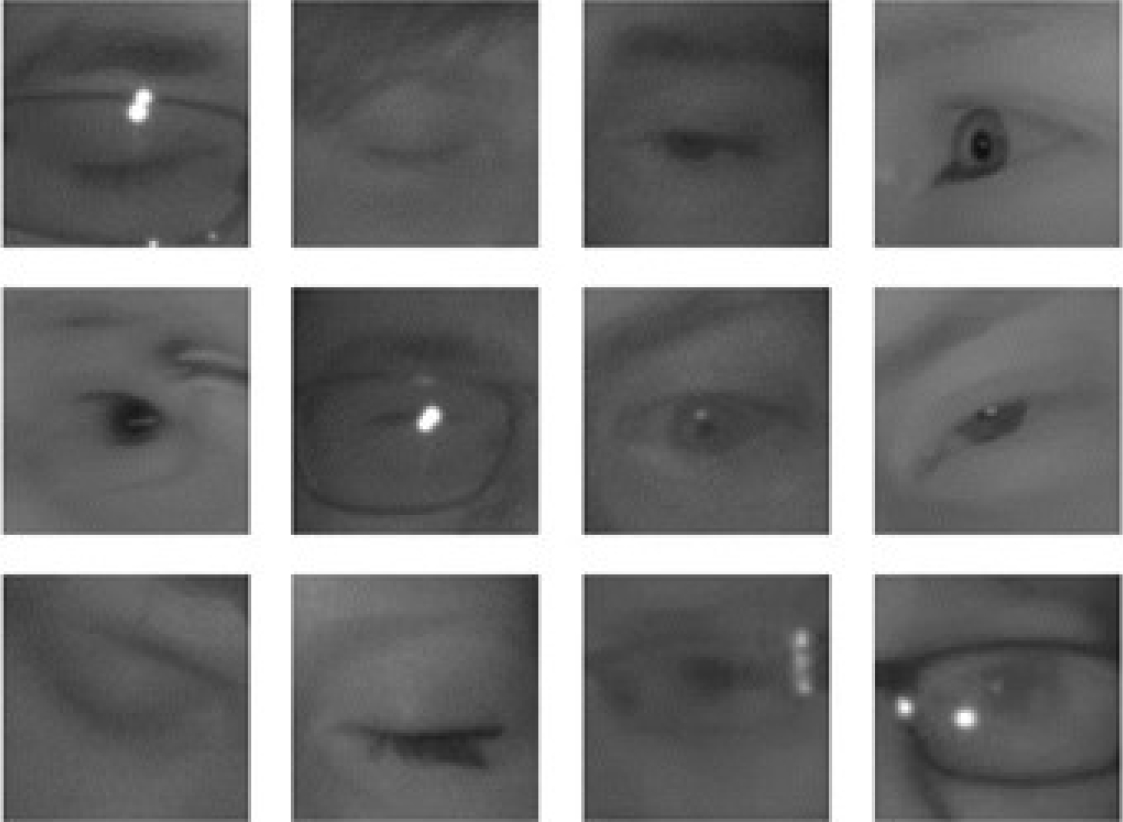
To train our model to classify and detect eye blinking, we have used the MRL Eye Dataset [16]. This dataset contains 84,898 infrared images from 37 persons from which there are 41,945 images of closed eyes and 42,953 of open eyes. 24,001 images are from people that wear glasses. Also, from the total of images, 66,060 do not contain any reflections; 6,129 images contain low reflection levels; and 12,709 contain high reflection levels. From the total of images, 53,630 have poor illumination conditions and the remaining 31,268 have good illumination conditions. MRL Eye Dataset is publicly available at http://mrl.cs.v sb.cz/eyedataset. 2 shows a sample of eye images from the dataset.
3.1.2 Mouths Dataset
There are no publicly available datasets of yawning people that segment the mouth region. Therefore, we build our own dataset from internet-based images from Google, Yandex, and Getty images. We obtained 5,657 images from people with open and closed mouths.

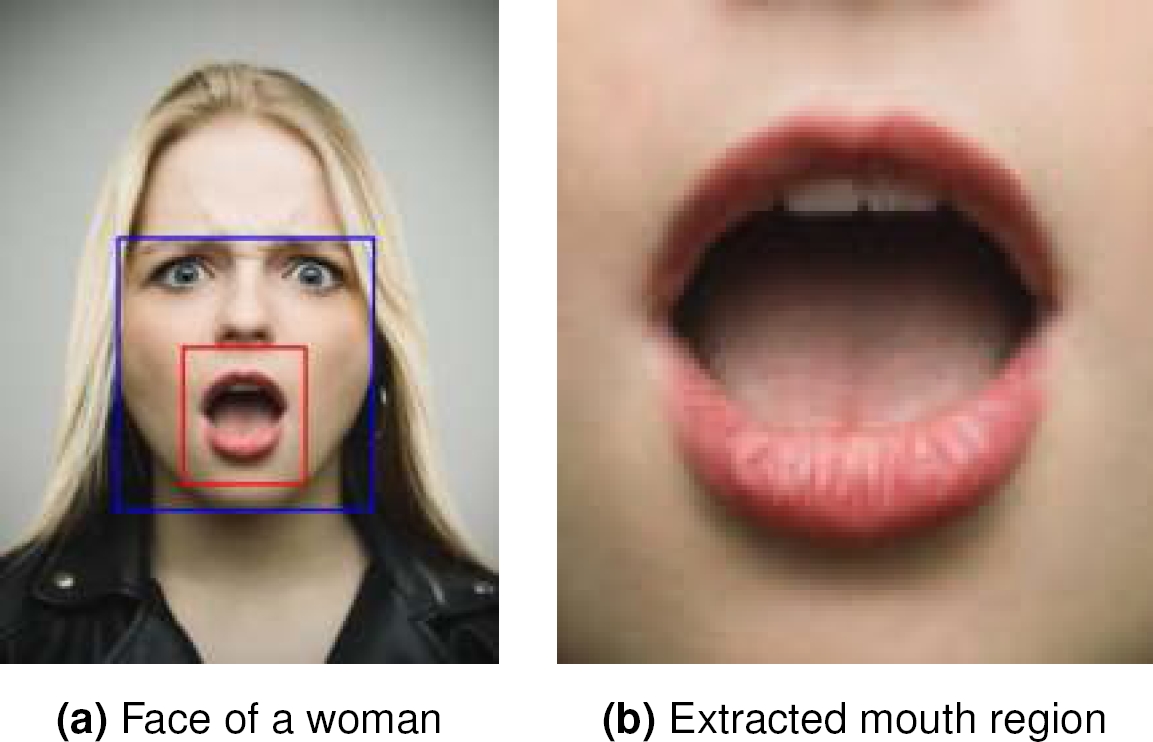
Then, we segmented the region of the mount 3 to build the Mouths dataset which contains 2,805 images from open mouths, and 2,852 images from closed mouths. This dataset is publicly available at https://www.kaggle.com/davidvazquezcic/yawn-d ataset. 4 shows an example of the images from the dataset.
3.1.3 Yawn Dataset
We used the YawDD dataset [1], to train our model to detect if a person is yawning or is simply opening its mouth for another casual activity (talking, singing). This dataset contains videos from 57 men and 50 women from different ages and different ethnicities.
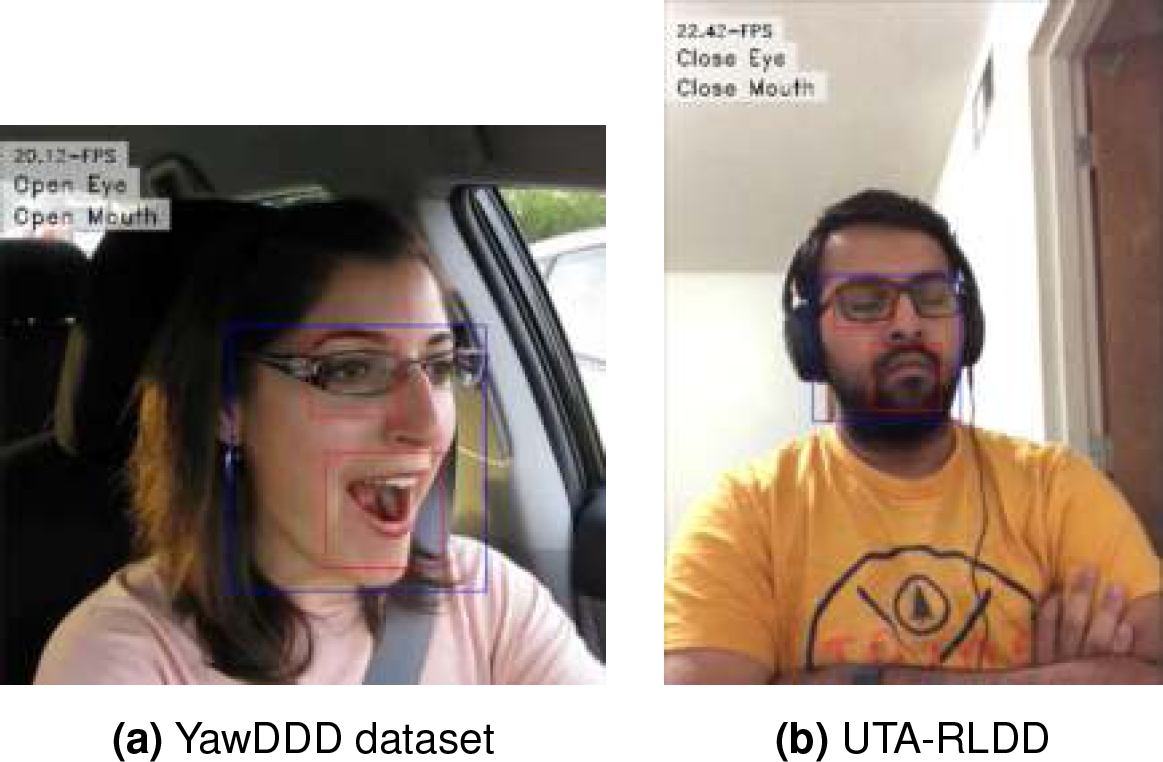
Length of videos are between 15 and 40 seconds. The class “yawn” contains 58 videos, and the class “no-yawn” contains 82 videos. In addition, it is important to mention that all videos of YawDD dataset are from people “acting”. Therefore, real-life behavior could vary and that is the reason we only used this dataset to detect yawning and not for detecting drowsy people from the “yawn” class. YawDD is publicly available at https://ieee-datap ort.org/open-access/yawdd-yawning-detection-d ataset. 5 shows an example of the content of the YawDD dataset.
3.1.4 Drowsiness Dataset
In order to evaluate the effectiveness of our proposal, we used the University of Texas at Arlington Real-Life Drowsiness Dataset (UTA-RLDD) [18]. This dataset provides videos from tired people that guarantee realness in the expressions of the participants. UTA-RLDD contains RGB videos of approximately 10 minutes and were obtained from web cameras and smartphone cameras.
There are videos from 51 men and 9 women of ages from 20 to 59 years old and different ethnicities. There are a total of 180 videos (60 per class) divided in three classes: alert, low vigilant, and drowsy. UTA-RLDD is publicly available at https://sites.google.com/view/utarldd/ho me. 6 shows an example of the content of the UTA-RLDD dataset.
3.2 Network Architecture
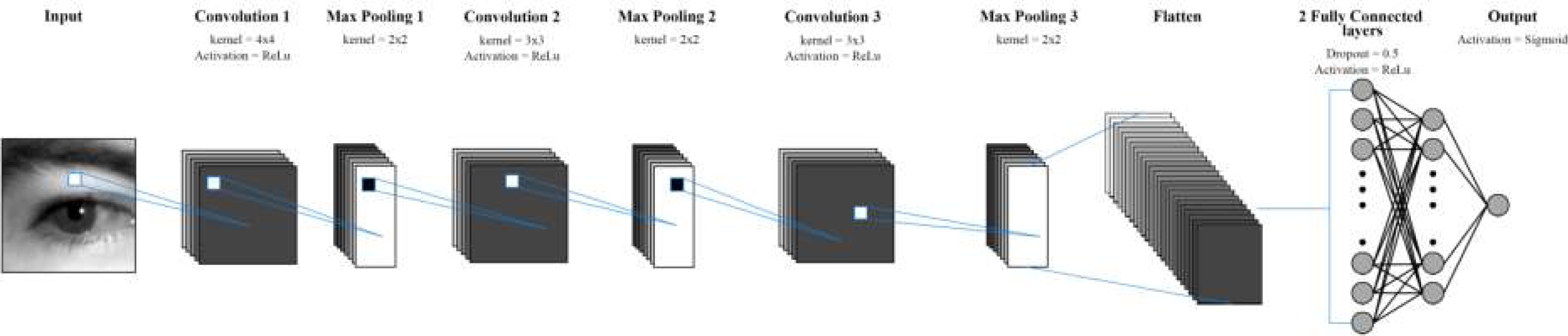
There are a variety of algorithms capable of determining the state of selected facial features such as associative memories [2] or associative classifiers [47], in this article, a convolutional neural network is used based on the LeNet classical network, Dozy-Net identifies eye and mouth closure by classifying images of these facial features.
Unlike some famous neural network models belonging to families such as EfficientNet or ResNet which can also achieve good results in facial feature image classification, Dozy-Net is considerably more compact and performs facial feature image classification in a significantly shorter time. The complete Dozy-Net architecture is shown in 7. In CNNs, convolution is used to extract features [26]. The input image is considered as a matrix of size

This input is convolved with a kernel
The number of kernels for the first, second and third layers are 32, 16 and 8 respectively. A one-pixel stride is applied for all convolutional layers. No padding was used. After each convolutional layer, a max-pooling layer with a kernel size of 2x2 was added. After the max-pooling 3rd layer, data is converted to a 1-dimensional array through flattening.
Feature integration is achieved using two fully connected (FC) layers. The first FC layer has 40 neurons, and the second FC layer has 12 neurons. Finally, classification is performed through a sigmoid activation function neuron. To prevent overfitting, we used the Dropout technique [45] with a dropout probability of 50% in the two FC layers.
3.3 Preprocessing and Segmentation
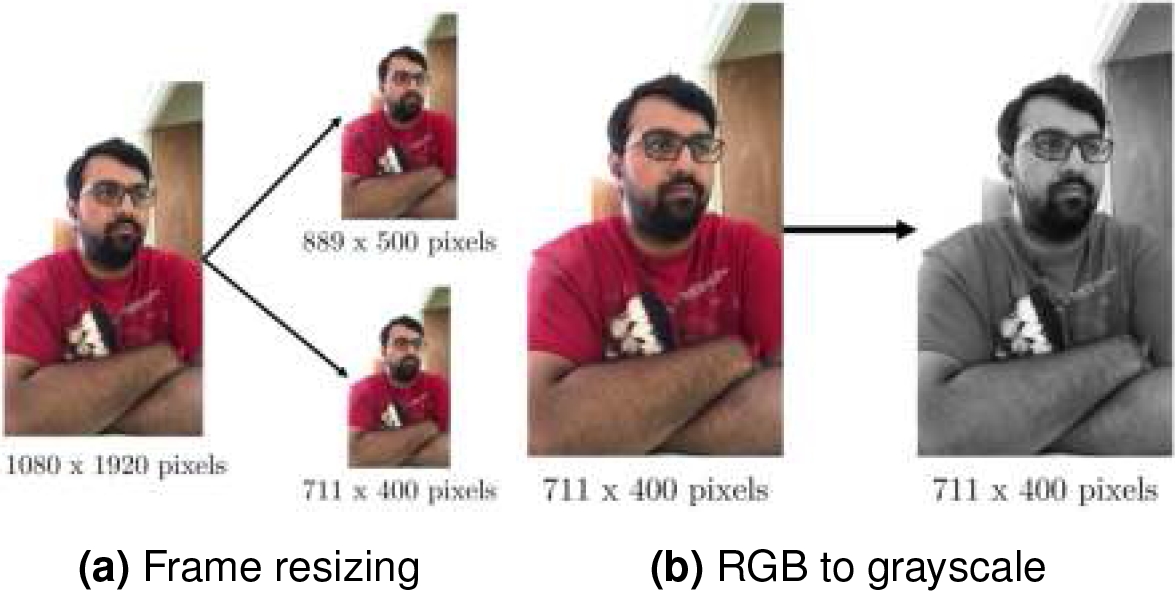
Each frame from the input video is processed according to the following steps:
1. Resize the frame to two different sizes (Display size and learning size, shown in 8a), according to 2.
2. Convert learning size from RGB image format to grayscale image ( 8b):
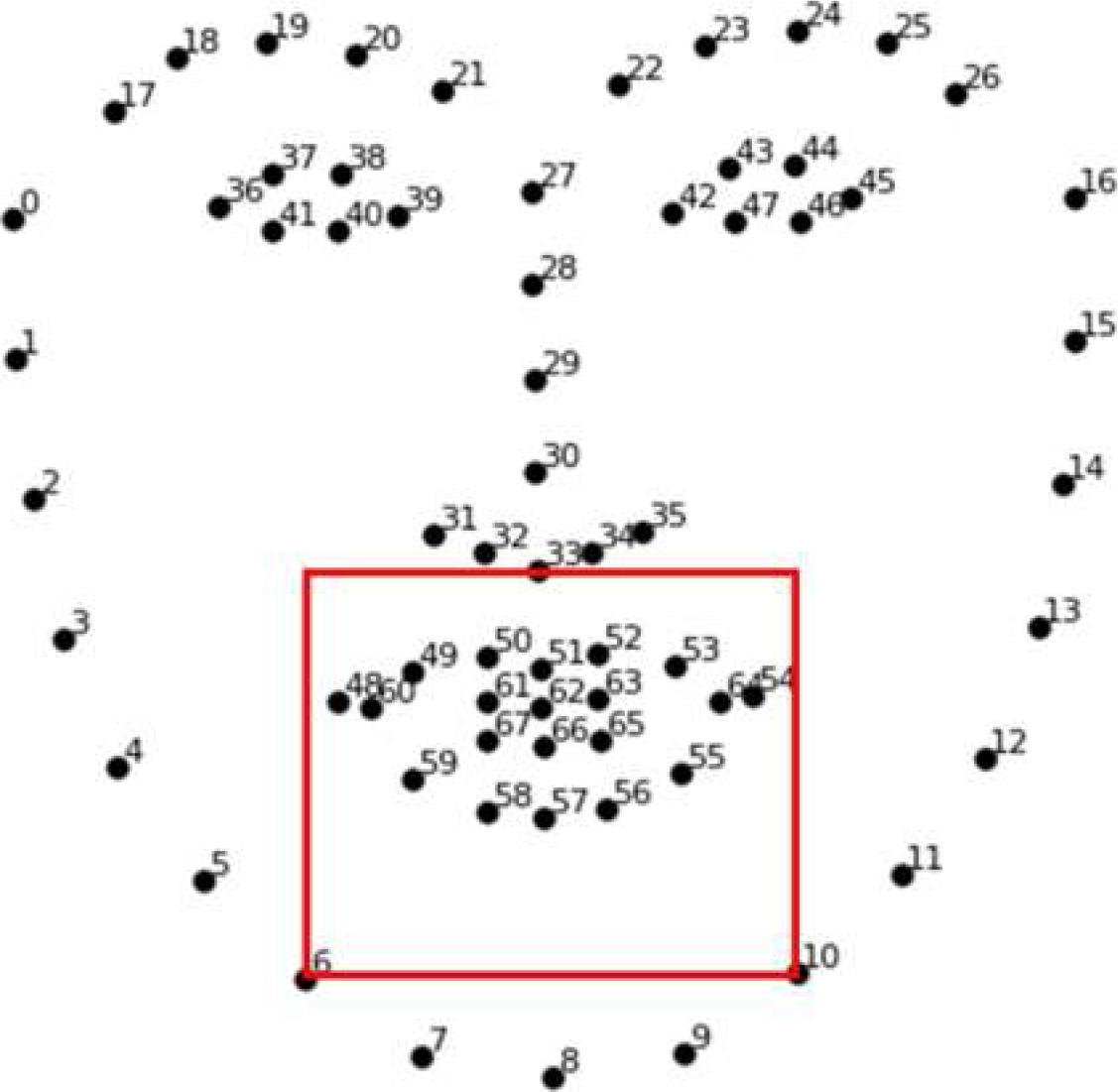
Once the preprocessing is complete, we segmented the face from the grayscale image using HOG+SVM. Moreover, once we obtained the face, we used a regression tree-based algorithm [25] contained in the dlib library for Python programming language to get 68 points of interest (POI) from the extracted face 9.
All images are segmented as shown in 9. Therefore, once the POI is obtained, we extract the face features used in this research to detect drowsiness.
3.4 Eye and Blinking Detection
We segmented the right eye from each extracted face through a box that contains the eye, using points 18, 21, 38, and 40 ( 10). Then, we adjust the height of the box 3 to guarantee that the eye is completely extracted:
where
We used a threshold of 7 frames (equivalent to approximately 233.8 ms) to determine if a blink was longer than normal [34]. We also use PERCLOS, which is one of the most used behavioral parameters for drowsiness detection [51]. If the PERCLOS value is greater than 0.07, the person is considered to be drowsy.
3.5 Mouth and Yawning Detection
Like the eye detection, we segmented the mouth from the face, using points 6, 10 and 33 11. Once again, we pass the normalized extracted image to the Dozy-Net to classify each frame as “open” or “closed”. We used a threshold of 60 continuous frames (equivalent to approximately 2 seconds) to determine if a mouth opening is associated with the sensory yawning peak, which is the most open phase of a yawn [48].
4 Results
4.1 Experimental Framework
All experiments presented in this paper were performed on a PC with Intel i7-9750H processor; 8 GB of RAM; 512 SSD storage and an Nvidia GPU GTX 1650 with 4 GB GDDR5 memory. The drowsiness detection model was built in Python 3.7.0 and the main libraries used were Tensorflow-GPU 2.3.0 and Keras 2.4.3 for CNNs implementation, training, and testing; OpenCV 4.5.1 for video and image processing; and dlib 19.21.1 for face landmarks estimation.
Motivated by the good results that VGG-16, ResNet-50, MobileNet-V1, DenseNet-121, NASNet-Mobile and EfficientNet-B2 are able to achieve in image classification [8, 11] (; ; Fulton et al., 2019; Hong et al., 2021; Kundu et al., 2021; Umair et al., 2021; Wang et al., 2020; Yang et al., 2021), we compared the results obtained by the above networks against Dozy-Net.
To ensure a fair comparison, neither transfer learning nor fine-tuning were used, and synaptic weights were randomly initialized. In addition, we used the same learning hyperparameters for all neural networks except for the input size.
All neural networks were trained using a learning rate of 0.001 and binary cross-entropy as the cost function. In addition, we used Adam as an optimization algorithm with parameters
4.2 Validation Method
MRL Eye Dataset and mouth dataset were used to train and test the facial feature classification models. Therefore, they were divided into three sets following the hold-out validation method: training, validation, and testing.
YawDD was used to determine whether our drowsiness detection model can distinguish yawning from other activities such as singing or talking, and two classes of the UTA-RLDD were used to test our drowsiness detection model. 1 shows the number of patterns per set for each dataset, and the type of data used.
4.3 Metrics
Each dataset used in this work is balanced, meaning that there are about the same instances per class. We computed the correctly recognized examples (true positives); the correctly recognized examples that do not belong to each class (true negatives); the examples that were incorrectly assigned to the positive class (false positives); and the examples that were incorrectly assigned to the negative class (false negatives).
Table 1 Sets distribution after hold-out validation method
| Dataset | Set | Class 1 | Class 2 | Examples type |
| MRL Eye Dataset | Train | 24,873 | 24,539 | Images |
| Validation | 16,582 | 16,358 | ||
| Test | 1,497 | 1,497 | ||
| Mouths dataset | Train | 1,611 | 1,629 | Images |
| Validation | 1,074 | 1,086 | ||
| Test | 120 | 137 | ||
| YawDD | Test | 82 | 58 | Videos |
| UTA-RLDD | Test | 60 | 60 | Videos |
Table 2 Classification results on the eye dataset for all CNN models
| Model | Accuracy | Time per epoch (s) | ||
| Training | Validation | Test | ||
| VGG-16 | 50.32 | 50.33 | 50.00 | 91.82 |
| ResNet50 | 98.81 | 88.37 | 95.22 | 100.53 |
| DenseNet 121 | 98.87 | 85.42 | 94.09 | 75.25 |
| MobileNet | 98.59 | 89.07 | 94.26 | 53.77 |
| NASNet-Mobile | 98.81 | 58.79 | 87.11 | 74.10 |
| EfficientNet B2 | 98.72 | 88.96 | 94.49 | 97.31 |
| Dozy-Net | 96.16 | 92.26 | 95.02 | 49.07 |
Therefore, we used accuracy (4) to evaluate the overall effectiveness of different classifiers in a binary classification task [42]:
In addition, we also have evaluated the time per epoch that each model takes when training.
4.4 Eye Detection Results
The MRL Eye dataset is a balanced set. Therefore, accuracy was used to measure the performance of classification. 2 shows the results from the baselines compared with our Dozy-Net. From 2, we can observe that on validation and testing, our model takes the 1st and 2d place respectively. Moreover, there is a substantial difference in training time compared to our proposal that is twice as fast compared to the best result.
4.5 Mouth Detection Results
The own created Mouth dataset is balanced. Therefore, accuracy was also used to measure the performance of classification. 3 shows the results from the baselines compared with our Dozy-Net.
From 3, we can see that our proposal gives us competitive results and it is the fastest among all models. Dozy-Net is up to three times faster than the closer result and up to 2.5 times faster than the best result.
4.6 Drowsiness Results
In this section, we present the results obtained by our drowsiness detection model. We use Dozy-Net for facial feature classification in our drowsiness detection model, since it is the fastest.
The first 11,400 frames of each video were analyzed and PERCLOS value was estimated every 200 frames. Through several tests, we found the following judgment conditions for detecting drowsiness:
where
From the confusion matrix, shown in 13, we can observe that of the 60 cases, 42 people were correctly classified. 18 were misclassified. From the 60 cases where people were fully aware (non-drowsy class), 11 were misclassified and 49 correctly classified using our Dozy-Net. Therefore, the most difficult class for our model was the drowsy class.
Table 3 Classification results on the mouths dataset for all CNN models
| Model | Accuracy | Time per epoch (s) | ||
| Training | Validation | Test | ||
| VGG-16 | 50.19 | 50.28 | 53.31 | 14.47 |
| ResNet50 | 96.32 | 87.13 | 96.50 | 14.56 |
| DenseNet 121 | 97.31 | 89.62 | 98.83 | 12.91 |
| MobileNet | 96.34 | 89.83 | 98.44 | 5.15 |
| NASNet-Mobile | 97.10 | 53.43 | 90.66 | 19.48 |
| EfficientNet B2 | 96.59 | 90.59 | 97.67 | 13.06 |
| Dozy-Net | 95.02 | 93.62 | 95.33 | 4.60 |
5 Discussion
Our proposal focuses on the detection of drowsiness from fatigued people. We trained our novel Dozy-Net to classify eyes from being open or closed. From 2, we observed our model obtained the best result of accuracy on the validation set with a 92.26% of accuracy. In addition, our proposal achieved the best result on the test set with 95.05% only after the ResNet50 with 95.22%. However, our model achieved that result from a training two times faster than ResNet50 with only 49.07 seconds per epoch, being the fastest among all CNNs.
Apart from eye detection, our methodology required to detect and classify the mouths of the people from being closed or open. From 3, again we can see that our model achieved the best classification on the validation set with a score of 93.62%.
On the test set we achieved fifth place (95.33%) after the DenseNet 121 (98.83%), MobileNet (98.44%), EfficientNet B2 (97.67%), and the ResNet50 (96.50%). We again obtained the faster training with only 4.60 seconds compared with the models with higher scores DenseNet 121 (12.91s), MobileNet (5.15s), EfficientNet B2 (13.06), and the ResNet50 (14.56).
Our proposal was 2.8 times faster than the best model and 3.1 times faster than the ResNet50. Therefore, in order to obtain the fastest model for fast classification, we performed the evaluation of the UTA-RLDD dataset using the Dozy-Net for eye and mouth classification. We evaluated different conditions for the behavioral parameters mentioned, such as PERCLOS, blink duration, and mouth opening.
We found that best results were obtained using the conditions from equation 5, from which we use a PERCLOS rate greater or equal to 0.07 (7%); for blinking, a number greater than 7 continuous frames; and a mouth opening equal or greater than 60 continuous frames. Only one of the above conditions is needed to classify drowsy people. As a result, we achieved an accuracy of 75.8% on the UTA-RLDD dataset.
On the other hand, from 4 there is no doubt that our Dozy-Net, in addition to being the fastest, has the fewest parameters with only 32.7 thousand compared to the 4.2 million (MobileNet-V1) which is the smallest of the reference models. In other words, our proposal has 128 times fewer parameters than the next in size.
On top of that, the storage size of Dozy-Net is 32 times smaller than the MobileNet-V1 with only 0.5MB compared to 16MB. The smaller storage size and fewer parameters makes our proposal more suitable to obtain faster processing rates and faster FPS in a final real-time application. Therefore, our proposal could be easily implemented on mobile and embedded devices with a fraction of processing power compared to a full-size GPU.
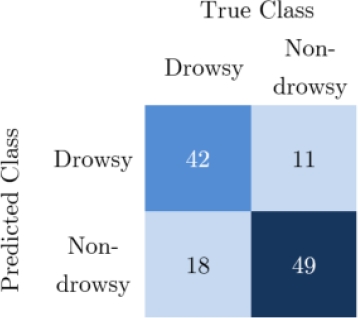
Table 4 Number of parameters and size of baseline models and Dozy-Net
| Model | Model size | Parameters |
| VGG-16 | 528 MB | 138.3 million |
| ResNet-50 | 98 MB | 25.6 million |
| MobileNet-V1 | 16 MB | 4.2 million |
| DenseNet-121 | 33 MB | 8.1 million |
| NasNet-Mobile | 23 MB | 5.3 million |
| EfficientNet-B2 | 36 MB | 9.1 million |
| Dozy-Net | 0.5 MB | 32.7 thousand |
6 Conclusions and Future Work
Drowsiness detection is very important for accident prevention. In this paper we introduce a novel drowsiness detection model based on two facial features and a novel compact convolutional neural network architecture suitable for eye and mouth image classification which we named Dozy-Net.
Dozy-Net proved to be competitive by achieving the shortest classification time among all tested models. It achieved 95.02% and 95.33% accuracy in the eye and mouth image classification test set, respectively, with only 32.7 thousand parameters compared to 25.6 million and 8.1 million parameters of ResNet-50 and DenseNet-121, which were the best performing models in eye and mouth classification, respectively. In addition, the size of Dozy-Net is extremely small being 32 times smaller than MobileNet-V1 and 1056 times smaller than VGG-16.
Finally, our drowsiness detection model combines three behavioral parameters obtained from two facial features. Dozy-Net can detect drowsiness at an average speed of 21.51 FPS using an entry-level GPU. We achieved an accuracy of 75.8% on the UTA-RLDD.
This dataset was selected because, compared to the most commonly used datasets in drowsiness detection, the UTA-RLDD contains information from real drowsy people and thus the exposed facial features are more accurate than synthetic datasets. As a result, our proposal is suitable for real-life scenarios and can positively help prevent and avoid different types of accidents in several real-life scenarios.
The contributions of this work are threefold: (1) the presented convolutional neural network model (Dozy-Net) showed its feasibility to identify critical fatigue features in selected facial features, having 128 times fewer parameters than MobileNet-V1 and 4,229 fewer than VGG-16.; (2) the exploration of thresholds and behavioral parameters suitable for non-intrusive drowsiness detection in real scenarios; and (3) a dataset suitable for yawning detection composed of 5,657 images; 2,805 of open mouths and 2,852 of closed mouths.
Based on the results of the study, we propose to increase the processing speed of Dozy-Net by (1) implementing a reflection removal algorithm on the obtained eye images, (2) binarizing the eye and mouth images through a threshold, and (3) implementing multi-thread processing and a queue data structure for frame storage.

