











 nova página do texto(beta)
nova página do texto(beta) Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink
1. Introducción
1.1 Cartografía epidemiológica y epidemiología espacial
Aunque no hay definición estandarizada sobre el campo de la epidemiología, se trata del estudio de la distribución de los fenómenos de enfermedad a nivel poblacional (Celentano & Szklo, 2020), aunque textos fundacionales incluyen su dimensión temporal y espacial (Susser, 1991). A pesar de esto, los estudios sobre la variación geográfico-espacial de las enfermedades suelen ser menos frecuentes, en comparación con los ensayos clínicos y los estudios temporales (Kirby et al., 2017). No obstante, su relevancia se ha comentado en Iberoamérica desde hace casi cuatro décadas (Narro Robles & Ponce de León, 1986).
Con ello, la epidemiología espacial se ha desarrollado como un campo especializado, sobre todo en Reino Unido y Norteamérica (Walter, 2000). Las contribuciones a este campo suelen venir de las matemáticas y la estadística aplicadas (Diggle, 2023; Elliot et al., 2001; Kirby et al., 2017; Moraga, 2019), en conjunto con la medicina. Por el contrario, las contribuciones de la geografía, en lo general, han sido menos frecuentes, con la excepción de la geografía de Reino Unido (Cliff & Haggett, 1989; Gatrell et al., 1996; Gatrell & Elliott, 2015). Así, este campo se entiende como aquel enfocado en describir y comprender la variación espacial del riesgo sobre enfermedades, particularmente en áreas pequeñas. De manera general, se subdivide en cuatro grandes áreas, que en la práctica se encuentran estrechamente relacionadas: 1) mapeo de enfermedades, 2) estudios de correlación geográfica, 3) la evaluación del riesgo con respecto de una fuente lineal o puntual, y 4) la detección de conglomerados (clusters) de alguna enfermedad en cuestión (Elliot et al., 2001).
Además, una característica fundamental de esta subdisciplina es que se estudia de manera específica al riesgo relativo como la variable de interés (Elliot et al., 2001). Partiendo de que la mayoría de los casos registrados de una enfermedad están estrechamente ligados con la cantidad de población en un área dada (Figura 1), el interés cambia inmediatamente a 1) buscar zonas en las que los casos se encuentran bastante por encima (o por debajo) de lo esperado con respecto de la población subyacente, y 2) a intentar explicar estas variaciones a partir de otras covariables. En este sentido, se utilizan una variedad de mediciones e indicadores de carácter relativo, como las aplicadas en este trabajo.
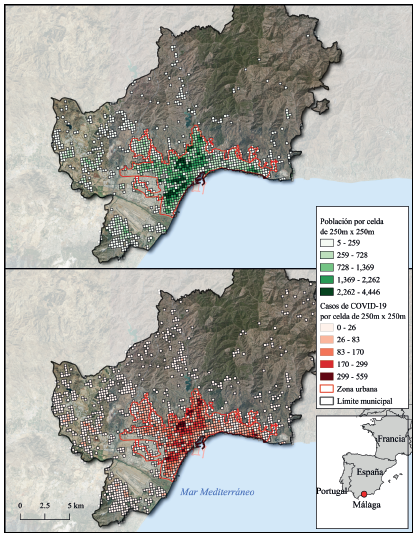
Fuente: elaboración propia con base en datos de la Tabla 1
Figura 1 Málaga. Ubicación geográfica de la zona de estudio y distribución espacial de la población y de casos positivos de COVID-19 entre 2020 y 2022. Método de clasificación de los intervalos por quiebres naturales, dada la distribución sesgada del indicador (Slocum et al., 2023).
1.2 Cartografía epidemiológica en la escala intraurbana, área de oportunidad en Iberoamérica
La cartografía y el análisis espacial en geografía de la salud con Sistemas de Información Geográfica (SIG) tiene una importante trayectoria en Iberoamérica, principalmente en el estudio de la distribución de equipamientos sanitarios, y en mediciones de accesibilidad a los mismos, con ejemplos en México (Garrocho & Campos, 2006; Reyna Sevilla et al., 2013; Terán-Hernández, 2017), Argentina (Briatore et al., 2024: Villanueba, 2010) y España (Escalona Orcao & Díez Cornago, 2003), por mencionar algunos.
Por otro lado, hay esfuerzos de instituciones de salud pública nacionales para la caracterización territorial de los problemas de salud más importantes dentro de sus fronteras, en forma de atlas. Estos trabajos suelen presentar cartodiagramas y mapas coropléticos en escalas nacionales o regionales. En el caso de México, el Atlas Nacional de Salud en México (Alcántara-Ayala et al., 2010), y en España, el Atlas Nacional con un subsegmento destinado a la Sanidad, aunque enfocado en la infraestructura sanitaria en el país (Instituto Geográfico Nacional, s/f). El de Colombia, por otro lado, sí utiliza mediciones de riesgo relativo, aunque en una escala regional (MINSALUD, 2015).
Y a pesar de que en diferentes latitudes de la región se ha reconocido el potencial de los SIG en epidemiología, los trabajos disponibles en la literatura arbitrada son tribunas o editoriales que dan un breve panorama general para incentivar su uso (Ascuntar-Tello & Jaimes, 2015; Valbuena García & Rodríguez Villamizar, 2018). En otros casos, se aplican métodos de análisis espacial basados en funciones de distancia, las cuáles que ya no utilizan a la cartografía como resultado principal (Abellán et al., 2002).
Mención aparte merece la cuantiosa producción de trabajos enfocados en la COVID-19, los cuáles siguieron técnicas clásicas en cartografía como los atlas nacionales previamente mencionados. Como ejemplo de lo anterior, los mapas de vulnerabilidad a nivel municipal en México (Suárez Lastra et al., 2020) la cartografía producida por el Instituto Geográfico Nacional de España sobre los casos por COVID-19 a nivel de comunidad autónoma (Sancho Comíns & Olcina Cantos, 2021), o la cartografía por sección sanitaria para la provincia de Castilla y León en el mismo país (Andrés López et al., 2021). De manera cercana a la propuesta de este trabajo, García-Morata et al. (2022) comparan tasas a nivel de sección censal contra un estudio de casos y controles a nivel puntual en Albacete.
Para Málaga también hubo trabajos enfocados en la descripción de los patrones geográficos de dicha enfermedad, como respuesta a la emergencia sanitaria (Marín-Cots & Palomares-Pastor, 2020; Perles et al., 2021; Roselló et al., 2021, 2021). En estos trabajos se hicieron propuestas novedosas para analizar y representar la variación geográfica de dicha enfermedad en la escala intraurbana, aunque el uso de los métodos propios de la epidemiología espacial ha quedado pendiente.
No obstante, fuera de Iberoamérica, la producción científica y académica en epidemiología espacial con datos desagregados sí ha sido más cuantiosa, tanto para la COVID-19, como para otras enfermedades. Así, se han elaborado superficies de riesgo relativo a nivel de país para toda Inglaterra (Elson et al., 2021), a nivel de ciudad para Berlín, Alemania (Lambio et al., 2023), así como análisis de autocorrelación espacial con unidades discretas en Irán (Jesri et al., 2021) y Slovakia (Vilinová & Petrikovicová, 2023). Sin embargo, una característica común en estos trabajos es que no se comparan distintas unidades espaciales y medidas epidemiológicas, ni se discuten las implicaciones de estas diferencias (excepto por García-Morata et al., 2022). Por lo tanto, en este trabajo se busca hacer una contribución al respecto, al comparar tres métodos de cartografía epidemiológica aplicados al análisis de la variación geográfica del riesgo relativo por COVID-19 dentro de la ciudad de Málaga, con los objetivos de 1) caracterizar dicho fenómeno, y 2) de explorar las ventajas y limitaciones de estos métodos, dada su importancia para la toma de decisiones en salud pública en su dimensión territorial.
2. Metodología
2.1 Zona de estudio
El municipio de Málaga se encuentra en la costa sur de España, dentro de los límites de la comunidad autónoma de Andalucía. Forma parte de la zona denominada Costa del Sol, a las orillas del Mar Mediterráneo. Su ubicación geográfica en conjunto con su patrimonio histórico y cultural, han establecido a esta ciudad como un importante destino turístico.
Demográficamente, en toda su extensión habitan aproximadamente 578,063 personas, aunque la mayoría se concentra en la zona urbana, con ~545,000 habitantes.
Urbanísticamente hablando, se trata de una ciudad compacta y policéntrica, con una extensión de ~46 km2, en la que el grueso de las viviendas son edificios plurifamiliares. De allí que su densidad poblacional promedio sea de 11,800 personas por km2.
Sobre el fenómeno de interés, y como puede notarse, el patrón de la densidad poblacional está estrechamente ligada con el de los casos totales (Figura 1), lo que refuerza el interés de la epidemiología espacial por el análisis del riesgo relativo.
2.2 Materiales
Para el análisis se utilizó el conjunto de datos de casos positivos de la enfermedad, y datos censales de población. Los primeros son el total de datos a nivel domiciliario de casos de COVID-19 (n= 60,165) detectados por pruebas PCR y de antígenos, provistas por el Hospital Regional de Málaga. Cabe mencionar que estos datos no están disponibles para el público en general, en concordancia con la legislación de España (Ley Orgánica 3/2018), las regulaciones de la Unión Europea (2016/679) y la Declaración de Helsinki (Principio 24).
Dichos datos se geocodificaron siguiendo los procedimientos diseñados por Perles, Sortino y Mérida (2021) para obtener una capa de datos vectoriales con la ubicación puntual de los casos positivos, pues estos autores trabajaron con un subconjunto de estos datos cuando la pandemia estaba en curso.
Para los datos poblacionales se utilizaron los resultados del Censo Anual de Población 2024, del Instituto Nacional de Estadística de España (INE).
Sobre las capas base utilizadas, es recurrente que, en términos administrativos y de gestión de datos, aquellos recolectados por instituciones públicas sean agregados en diferentes niveles y tipos de unidades geográficas, como regiones, estados, comunidades o departamentos, por mencionar algunos ejemplos en Iberoamérica.
La unidad más pequeña suele tomar la forma de bloque, sección o distrito censal, generalmente a escala intraurbana. Éstos son polígonos de áreas y formas muy variadas, lo que vuelve difícil su comparación, y expone el Problema de la Unidad de Área Modificable (MAUP por sus siglas en inglés), en el cual los resultados del análisis (como la detección de conglomerados o la correlación entre variables) están condicionados por el tamaño y forma de los polígonos con datos agregados (Openshaw & Taylor, 1979).
Para superar estas limitaciones, el Instituto de Estadística y Cartografía de Andalucía (IECA) desarrolló una rejilla con datos censales para una resolución mayor, con cuadrantes de 250x250 metros, lo cual permite superar algunas limitaciones de otro tipo de polígonos administrativos (Escudero-Tena et al., 2023), aunque el tamaño y la forma de la celda son problemas en sí mismos. En la Tabla 1 resume el conjunto de datos utilizados en el trabajo.
Tabla 1 Conjuntos de datos utilizados
| Conjunto de datos | Fuente | Disponibilidad |
| Casos positivos de COVID-19 | Hospital Regional de Málaga | Datos no disponibles al público en general |
| Población total por sección censal | Censo Anual de Población 2024 | Instituto Nacional de Estadística (España) |
| Capa de secciones censales | Cartografía secciones censales y callejero de Censo Electoral | Instituto Nacional de Estadística (España) |
| Malla estadística 250m x 250m | Datos espaciales en malla estadística | IECA |
| Polígono municipal de Málaga | Datos Espaciales de Referencia de Andalucía | IECA |
| Área urbana de Málaga | Datos Espaciales de Referencia de Andalucía | IECA |
| Ortofotografía en color, pancromática e infrarrojos a 0,25 metros/píxel (año 2022) | Imágenes y ortofotografías | IECA |
Fuente: elaboración propia.
2.3 Instrumentos y herramientas
Todas las medidas epidemiológicas calculadas, así como la cartografía resultante, fueron producidos con software libre y de código abierto, lo que puede permitir que este tipo de análisis pueda replicarse con mayor facilidad y apertura.
Para el procesamiento general de capas y el diseño cartográfico, se utilizó QGIS ver. 3.40 Bratislava. El cálculo del exceso de riesgo, así como de los conglomerados mediante la I de Moran local, fue realizado con GeoDa ver. 1.22.0.2 (Anselin, 2019). Finalmente, el cálculo de la superficie de riesgo relativo fue realizado mediante el lenguaje de programación R, y, en específico, las librerías especializadas en estadística espacial sobre datos puntuales spatstat (Baddeley et al., 2016) y en epidemiología espacial sparr (Davies et al., 2011, 2018).
2.4 Mediciones
La tasa de prevalencia (Celentano & Szklo, 2020; Villa Romero et al., 2011) es una medida puntual en el tiempo t que estima el total de casos en relación con la población en la cual podría ocurrir. Puede expresarse como proporción, porcentaje o tasa con algún número de base 10. En este caso, a la notación también se añade el área i, que puede representar una sección censal dada, o una celda dentro de la rejilla disponible. El resultado se multiplica por 1000, para tener una tasa por cada 1000 habitantes, y así facilitar la interpretación del resultado mostrado cartográficamente (Ecuación 1).
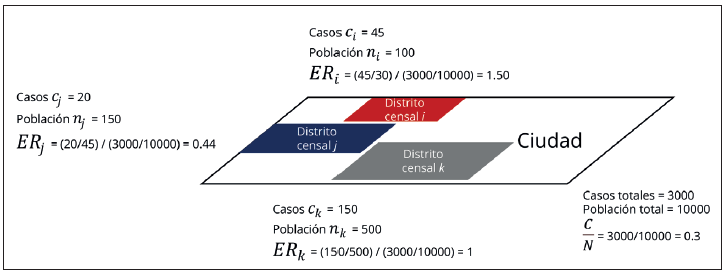
El Exceso de Riesgo ERi (Anselin, 2024) aparece con varios sinónimos en la literatura especializada, por lo que también se le conoce como Razón de Incidencia Estandarizada (SIR por sus siglas en inglés), y como Razón de Mortalidad Estandarizada (SMR por sus siglas en inglés) cuando se trata de defunciones (Anselin, 2024; Moraga, 2019).
Con esta medición se busca describir si hay más o menos riesgo con respecto de una línea base, como lo puede ser la prevalencia general. Nominalmente, se adopta el término propuesto por Luc Anselin, dado que así está implementado en el SIG GeoDa. Pero, para su exposición, formalmente se adopta una expresión similar a la usada por el Centro de Control de Enfermedades (CDC por sus siglas en inglés) (2022), dada su sencillez de cálculo (Ecuación 2).
En la que ci/ni representa la proporción casos observados con respecto de la población dentro de una unidad de observación i (barrio, sección censal, condado, celda en una rejilla), y C/N representa la proporción de casos totales, con respecto de la población total en la ciudad o región de interés. Para Málaga, considerando la fase aguda como un periodo en sí mismo, esta es de 60,165/578,063= .104, o 10.4%.
Su interpretación es como sigue: si ERi = 1, el riesgo en la zona i es igual a la tasa general; si ERi < 1, el riesgo en la zona i es menor que lo esperado; finalmente, si ERi > 1, el riesgo es mayor que lo esperado.
Nótese que el cálculo tiene como base la tasa de prevalencia mencionada, pero en lugar de tratar con cantidades específicas, se busca dilucidar si en una zona dada la enfermedad es mayor o menor a la proporción general de toda el área de estudio (Figura 2). De allí que se intente medir el exceso de riesgo.
Luego, es posible evaluar espacialmente a las dos mediciones previas mediante el Índice Ii de Moral Local (Anselin, 1995, 2024).
El objetivo principal de este procedimiento es el de hacer inferencias sobre la distribución y configuración espacial de la variable de interés (Fotheringham & Brunsdon, 2004); en este caso, la tasa de prevalencia y el exceso de riesgo. Así, la hipótesis nula corresponde con una configuración aleatoria, mientras que se cuenta con dos hipótesis alternativas: la dispersión o la concentración de unidades similares en cuanto a la variable de interés.
Formalmente, se toma el estadístico global I de Moran, que resume la autocorrelación espacial en una sola medida resumen para toda el área de estudio (Ecuación 3).
En la que Zi=xi-x Luego, éste se adapta para cada una de las unidades de observación (sección censal, celda de malla), en donde autocorrelación sólo se calcula únicamente para los polígonos vecinos j (Ecuación 4).
La significancia estadística de Ii se evalúa mediante permutaciones de los valores calculados (habitualmente entre 99 y 99,999), para estimar la probabilidad de que el arreglo espacial observado fuera producto del azar. Esto permite reclasificar a todo el conjunto de unidades espaciales en cinco categorías, en función de su ubicación en el diagrama de dispersión de la I de Moran global: sin significancia, alto-alto, bajo-bajo, alto-bajo, y bajo-alto (Anselin, 1995, 2024).
Es importante notar que, de manera predeterminada, el nivel de significancia estadística establecido por este algoritmo es de p<0.05, el cual puede ser demasiado laxo en análisis basados en permutaciones, limitando su utilidad a una exploración inicial de patrones espaciales. Por lo anterior, Luc Anselin (2024), desarrollador del método y del software recomienda trabajar con niveles más bajos (p< 0.01 o incluso < 0.001), para filtrar con mayor certeza las ubicaciones en las que los valores son demasiado atípicos como para ser producto del azar, y que pueden deberse a otras covariables de interés.
Finalmente, para representaciones continuas, puede calcularse una superficie de riesgo relativo (Davies et al., 2018).
El detalle técnico y formal de las superficies de densidad tipo kernel es abordado en otros trabajos (Baddeley et al., 2016; Fotheringham et al., 2024; O’Sullivan & Unwin, 2010). Básicamente, se trata de cuantificar la densidad de puntos dentro de un ancho de banda (bandwidth) determinado. De esta manera, se pasa de la representación vectorial de puntos, a la representación continua tipo ráster, lo que permite visualizar con mayor facilidad las zonas con mayor concentración del fenómeno de interés (Figura 3).
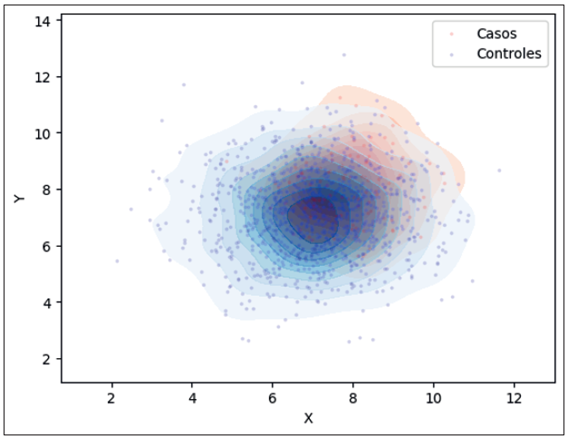
Fuente: elaboración propia.
Figura 3 Esquema del cálculo de las superficies de densidad tipo kernel para casos y controles con valores artificiales.
Así, se trata del cálculo de una tasa simple, pero a nivel de píxel en una capa tipo ráster, en lugar de una unidad discreta como una sección censal. Y al igual que con el exceso de riesgo, se trata de una medida estandarizada, aunque en una escala logarítmica para evitar que divisiones entre valores muy pequeños arrojen sobreestimaciones artificiales. Formalmente, la superficie de riesgo relativo se expresa como sigue (Davies et al., 2018; Sarojinie Fernando & Hazelton, 2014) (Ecuación 5):
En donde RR es el riesgo relativo, f (x) es la densidad de probabilidad de la capa de puntos de casos, y g (x) la de los controles, o, en otras palabras, la población susceptible, la cual generalmente se trata de una capa de puntos que simula a la población subyacente, con base en la cantidad de población en cada polígono de una capa con datos censales (Gatrell et al., 1996; González & Moraga, 2023). En términos de SIG, se trata de la producción de dos “mapas de calor” con un ancho de banda similar.
Sin embargo, la selección del ancho de banda es un aspecto crucial en este tipo de análisis, pues la extensión del fenómeno, en este caso el riesgo relativo, puede ser fácil y arbitrariamente reducido o expandido. En ese sentido, la paquetería sparr está diseñada específicamente para superar limitaciones de los algoritmos tradicionales en distintos SIG, pues en lugar de un ancho de banda fijo, el paquete utiliza uno adaptativo (Davies et al., 2018), es decir, que en zonas con muchos casos, el ancho de banda disminuya (para evitar sobreestimaciones), y en zonas con pocos, aumente (para evitar subestimaciones).
Con la selección del ancho de banda adaptativa, ambas capas son sometidos a una operación de álgebra de mapas, en la que el ráster de densidad de casos se divide entre el ráster de densidad de controles. A dicha división se aplica el logaritmo natural, lo que resulta en una superficie en escala logarítmica. Su interpretación es similar al Exceso de Riesgo. Así, RR = 0 implica un riesgo relativo similar al general de toda el área de estudio; RR > 0 implica un riesgo relativo mayor al esperado, y RR < 0, un riesgo relativo menor.
2.5 Procedimientos
En esta sección se indican, de manera resumida, las herramientas y los (geo)procesos utilizados en cada una para lograr los resultados presentados. En principio, este flujo de trabajo puede ser replicado para cualquier área de estudio y evento de salud-enfermedad de interés, siempre que se dispongan de los datos necesarios.
El proceso comienza en QGIS, cargando las capas necesarias: puntos que representan casos y polígonos como secciones censales o una malla cuadriculada. Para contar los puntos dentro de los polígonos, se utiliza la herramienta “Contar puntos en polígonos”, lo que genera un nuevo atributo en la capa de polígonos con el conteo correspondiente. Este resultado se guarda como un archivo shapefile con coordenadas proyectadas.
Luego, para generar una capa combinada de casos y controles, se crean puntos aleatorios limitados por los polígonos seleccionados, tomando como referencia el atributo de población para definir el número de puntos. Un aspecto importante de este algoritmo es que los puntos pueden asignarse en ubicaciones en las que no hay viviendas o asentamientos humanos, por lo que es importante contar con una capa de referencia, de manzanas o edificios, que permita asegurar que no se están creando controles en lugares deshabitados. Los puntos generados se combinan con los casos existentes, y la capa resultante se guarda en formato shapefile, con coordenadas proyectadas.
En GeoDa, se importa el shapefile que contiene el conteo de casos. Así, se calculan las tasas crudas a partir de los atributos de casos y población, y también el exceso de riesgo, guardando ambos resultados como nuevos atributos en la tabla de datos. Posteriormente, se genera una matriz de pesos espaciales de tipo “Reina” para analizar las relaciones espaciales entre polígonos vecinos. Con esta matriz, se realiza un análisis de autocorrelación espacial utilizando la de I Moran Local, identificando patrones espaciales significativos que también se guardan como atributos adicionales. Finalmente, el shapefile enriquecido se exporta para ser utilizado en pasos posteriores.
En R (R Studio), se preparan los datos cargando librerías especializadas como spatstat, sparr, raster y sf. Las capas de puntos y el polígono de la zona de estudio se importan para crear un objeto de tipo “colección de puntos” (ppp), que luego se subdivide (subset) en entre casos y controles. Usando estas colecciones, se calcula un ancho de banda óptimo y se genera una superficie de riesgo relativo, adaptando el análisis para identificar zonas de riesgo con significancia estadística. Estas zonas se exportan como archivos ráster que representan tanto la superficie de riesgo como las áreas con p-valores significativos (p < 0.05).
Finalmente, en QGIS se realiza la composición cartográfica y la comparación de resultados. Se cargan las capas enriquecidas y los rásteres generados, configurando mapas temáticos con simbología adecuada para visualizar tasas, exceso de riesgo, y resultados del I de Moran Local. Los rásteres de riesgo relativo y significancia estadística se representan con bandas de pseudocolor y con una paleta de colores opuestos. Para complementar el análisis, se superponen las áreas de mayor riesgo con datos poblacionales mediante una intersección geoespacial, permitiendo estimar el tamaño de área y la población afectada en las zonas identificadas como de mayor riesgo.
Para las unidades discretas (áreas censales y celdas de la malla estadística), se pueden resumir el área y población totales del conglomerado alto-alto del exceso de riesgo, y así comparar los resultados entre indicadores y unidades espaciales.
3. Resultados
En esta sección se presentan las diferencias entre mediciones epidemiológicas y tipos de unidades espaciales, así como la comparación entre el área y población de riesgo relativo resaltado por cada método, y la comparación entre el riesgo relativo alto estadísticamente significativo contra la prevalencia base para la zona urbana de Málaga, al ser el epicentro de la crisis sanitaria. Las implicaciones de estos aspectos, así como los de su representación cartográfica, se comentan detalladamente en la discusión.
Primero, al utilizar secciones censales de gran extensión, sobresalen aquellas que aparecen marcadas con una tasa de prevalencia alta (Ecuación 1), dando la impresión de un problema de gran extensión. No obstante, cuando el mismo indicador se expresa con ayuda de una rejilla regular que únicamente marca zonas en donde hay población, es evidente que se trata de una zona despoblada (Figura 4).
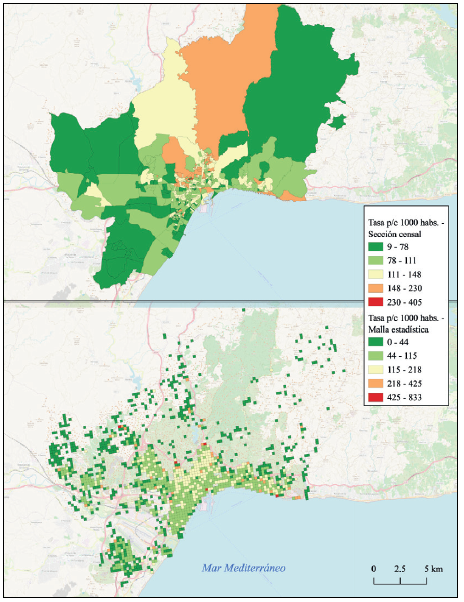
Fuente: elaboración propia con base en datos de la Tabla 1
Figura 4 Tasa de prevalencia de COVID-19 p/c 1000 habs. Comparación entre secciones censales y malla estadística. Método de clasificación de los intervalos por quiebres naturales, dada la distribución sesgada del indicador (Slocum et al., 2023).
Por ello, cuando se toma un fenómeno de salud-enfermedad medido a través de una tasa de prevalencia, es notorio cómo puede distorsionarse la variación geográfica de la distribución de una enfermedad cuando se utilizan secciones censales como unidades geográficas.
No obstante, el problema se mantiene cuando se utiliza una medición estandarizada. Así, cuando se expresa la distribución y variación geográfica de una enfermedad a través del exceso de riesgo (Ecuación 2), la variabilidad en forma y tamaño de las secciones censales puede tener el efecto de que dos zonas distintas de la ciudad parezcan similares, las cuáles desaparecen cuando se utiliza una rejilla regular (Figura 5).
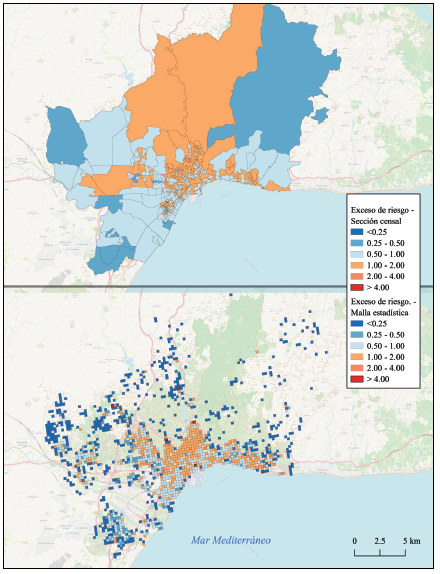
Fuente: elaboración propia con base en datos de la Tabla 1
Figura 5 Exceso de riesgo de COVID-19. Comparación entre secciones censales y malla estadística. Método de clasificación por intervalos iguales, dada la simetría propia del indicador. Paleta de colores orientada al contraste de valores divergentes (Anselin, 2019).
Luego, un problema compartido tanto por la tasa de prevalencia como por el exceso de riesgo es la dificultad de detectar visualmente conglomerados de valores altos de una u otra medición. En este sentido, los indicadores locales de asociación espacial (LISA por sus siglas en inglés) como la I de Moran Local (Ecuaciones 3 y 4) son de gran utilidad para detectar conglomerados estadísticamente significativos. En este sentido, se vuelve indistinto calcular estos conglomerados a partir de la tasa de prevalencia o del exceso de riesgo, pues el segundo se construye con base en el primero (Figura 6).
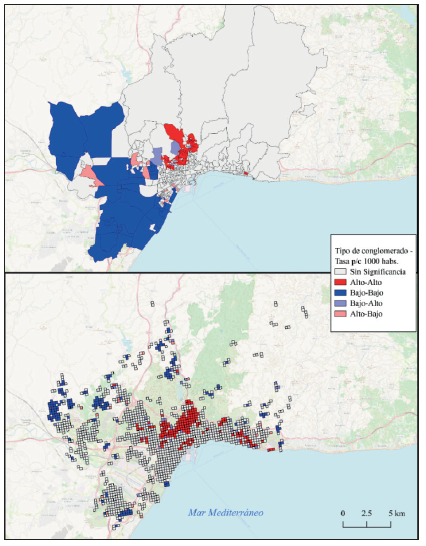
Fuente: elaboración propia con base en datos de la Tabla 1.
Figura 6 Conglomerados estadísticamente significativos de valores altos de la tasa de COVID-19 p/c 1000 habs. Comparación entre secciones censales y malla estadística.
Por otro lado, las superficies continuas de riesgo relativo se muestran particularmente sensibles al cambio en escala de la unidad de análisis. En este tipo de representación se superan las limitaciones presentes en los distintos tipos de unidades administrativas, a saber, su arbitrariedad. Pero, al tratarse de una representación “difuminada”, la variación geográfica puede representarse más o menos concentrada en función de la extensión del área de estudio.
Así, el riesgo relativo muestra márgenes mayores y zonas con significancia estadística en un área de mayor extensión, como el municipio de Málaga en su totalidad, y, al contrario, cuando sólo se considera la zona urbana, que es en donde se concentran la gran mayoría de los casos (Figura 7).
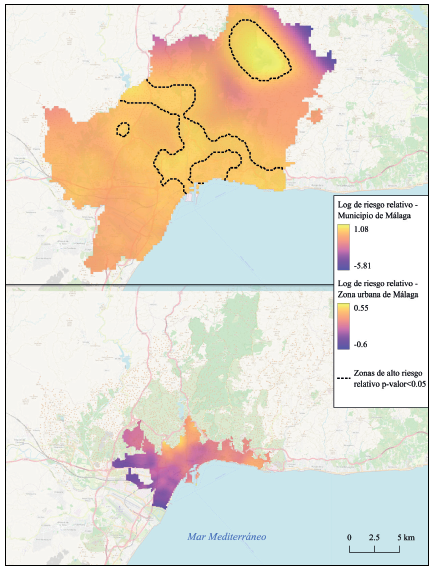
Fuente: elaboración propia con base en datos de la Tabla 1
Figura 7 Riesgo relativo de COVID-19. Comparación entre el municipio de Málaga y su zona urbana.
Finalmente, ha de notarse que el área de mayor riesgo relativo, así como la población que habita en ellas, se incrementa conforme aumenta la especificidad del tipo de representación cartográfica. Mientras la capa de secciones censales aparenta ser mucho mayor, el área de mayor riesgo relativo y la población en ella aparecen subestimados.
Por el contrario, el resultado con la superficie de riesgo relativo es más específico, a la vez que permite detectar una zona de riesgo relativo más alta, y, consecuentemente, una cantidad mayor de población susceptible de estar en mayor riesgo relativo (Tabla 2).
Tabla 2 Comparación de resultados entre indicadores y tipo de unidad espacial
| Unidad territorial | Indicador | Comparación de área de mayor riesgo | Comparación de población en el área de mayor riesgo | ||||
| Área total (km2) | Área total zonas de riesgo más alto (km2) | % del área total | Pob. total | Pob. total en zonas de riesgo más alto | % Pob. total | ||
| Sección censal | Tasa/Exceso de riesgo | 390 | 7 | 1.79% | 586,000 | 63,655 | 10.86% |
| Malla estadística | Tasa/Exceso de riesgo | 94 | 10 | 10.64% | 140,441 | 23.97% | |
| Superficie de riesgo (zona urbana) | Log. de riesgo relativo | 46 | 16 | 34.78% | 545,000 | 206,910 | 37.97% |
Fuente: elaboración propia con base en los procedimientos realizados sobre los datos de la tabla 1.
Estas diferencias en resultados indican que, dependiendo del tipo de dato espacial y medición utilizados, se pueden tomar decisiones de mayor o menor extensión y alcance. Así, el uso de secciones censales como dato espacial base puede tener por efecto la subestimación del riesgo en su extensión y población afectada.
Luego, dentro de la zona urbana es posible estimar que la población en la zona estadísticamente significativa tiene un riesgo doble en comparación con el riesgo base de la ciudad (Tabla 3). Esto permite cuantificar la diferencia potencial de riesgo dentro de una misma ciudad.
Tabla 3 Variación del riesgo relativo en la zona urbana
| Tipo de zona | Casos | Controles | % afectado | Exceso de riesgo |
| Riesgo relativo ≤ prevalencia general | 33,143 | 376,964 | 8.79% | 0.83 |
| Riesgo telativo > prevalencia general | 23,800 | 163,036 | 14.60% | 1.38 |
| Prevalencia general | 56,943 | 540,000 | 10.55% | 1.00 |
Fuente: elaboración propia con base en los procedimientos realizados sobre los datos de la tabla 1.
4. Discusión
4.1 Disponibilidad y utilidad de datos puntuales en epidemiología y salud pública
El análisis presentado muestra la relevancia de contar con datos a nivel puntual para el abordaje de problemas en salud pública, pues los resultados muestran que, con este tipo de datos, la estimación, tanto en área como en cantidad de población en mayor riesgo, se duplica (Tabla 3). Y aunque tanto la literatura fundacional como contemporánea en métodos epidemiológicos se reconoce la importancia de estos datos como el insumo principal para los métodos más precisos (Baddeley et al., 2016; Elliot et al., 2001; Gatrell et al., 1996; González & Moraga, 2023), también es cierto que, a nivel administrativo y de trabajo de investigación, son los más difíciles de conseguir dadas las implicaciones éticas y legales en cuanto a la privacidad y protección de datos personales. La misma Organización Panamericana de la Salud reconoce que, por estos motivos, los datos abiertos en salud pública se presentan de manera agregada (D’Agostino et al., 2018).
Como alternativas a este problema, se han propuesto datos puntuales a nivel de código postal, como hacen Elson et al. (2021) para toda Inglaterra. Pero esto sólo es útil cuando se trata de estudios a niveles regionales o de país, lo cual permite que una ubicación puntual no esté directamente asociada con la dirección personal de algún paciente.
Cuando se trata de estudios intraurbanos, la ubicación puntual de casos puede hacerse con menor precisión, registrando los casos de interés de manera aleatoria dentro de un rango de distancia pequeño, para que no se aluda al domicilio específico de alguna persona, sin perder precisión de la ubicación, como fue hecho por García-Morata et al. (2022) en Albacete.
Sin embargo, el levantamiento de datos en salud pública de estas maneras depende principalmente de decisiones administrativas y gubernamentales, aunque el estudio previo sugiere una idea plausible sobre cómo hacerlo.
Por otro lado, los resultados que emanan de estudios con datos de alta resolución y especificidad permiten evaluar con más precisión aquellas zonas en de mayor riesgo relativo, derivando en acciones focalizadas y certeras. Para el caso específico de Málaga, resultados como los presentados pueden integrarse en instrumentos de toma de decisiones como los atlas municipales de riesgo, no sólo para la COVID-19, sino para enfermedades respiratorias infecciosas similares, y, en lo general, para cualquier otra enfermedad infecciosa, e incluso crónico degenerativas.
Como ejemplos de lo anterior, se han producido superficies de riesgo relativo a enfermedades como el cáncer de laringe en Lancashire, Inglaterra (Diggle, 1990), la leucemia en Londres, (Gatrell et al., 1996), e, incluso, dentro de la epidemiología veterinaria, como se ha hecho con la fiebre aftosa (foot and mouth disease) en el ganado (Gerbier et al., 2002). En todos estos casos, los insumos son prácticamente los mismos que en este trabajo: capas puntuales para casos, una capa poligonal con datos censales para crear puntos simulados de controles, y un polígono que represente la zona de estudio.
4.2 El Problema de la Unidad de Área Modificable y la distorsión de resultados a partir de la unidad espacial seleccionada
Como se mencionó, la disponibilidad de datos a nivel puntual suele ser limitada e incluso nula, por lo que se vuelve necesario recurrir a la siguiente mejor opción posible, como las capas de unidades discretas con datos agregados. En el caso presentado, los resultados muestran el efecto que diferentes unidades de agregación pueden tener sobre los patrones observados y representados cartográficamente, y refuerza la tesis de Mark Monmonier (1991) sobre cómo un mapa es uno de “infinitos” mapas posibles, que pueden construirse sobre el mismo fenómeno.
Las representaciones con base en áreas censales pueden ser las más fáciles de producir por su disponibilidad, con la desventaja mayor variabilidad y arbitrariedad en su delimitación, pues obedecen a criterios administrativos. En el caso específico de Málaga, esto es notorio en las zonas de baja densidad poblacional, en la que una gran área prácticamente inhabitada sirve de base para una sección censal individual, lo que implica importantes distorsiones visuales en cuanto a la magnitud y extensión del riesgo alto o bajo (Figura 4). Esto podría obstaculizar la focalización de medidas de mitigación en caso de que se redirigieran a zonas con un alto riesgo sobre o subestimado por distorsiones propias de las unidades espaciales.
Por el contrario, las mallas regulares muestran ventajas importantes, pues permiten representaciones consistentes y de mayor granularidad. Esto es particularmente notorio en las zonas poco pobladas, pues las estimaciones o mediciones sobre la prevalencia y riesgo de una enfermedad se vuelven muy específicas (Figura 5). No obstante, la creación y disponibilidad de estos insumos no está generalizada.
Por ejemplo, los países de la Unión Europea, a través de la Oficina de Estadísticas de la Unión Europea (Eurostat) han desarrollado rejillas o mallas regulares de 1km2 con datos censales en unidades territoriales estandarizadas y más desagregadas, bajo el programa GISCO. En Iberoamérica, México ha replicado esta iniciativa con la malla geoestadística que llega a una resolución de 500x500 m, aunque en ambos casos, los datos disponibles sólo son en cuanto a cantidad de población, y no incluyen datos en salud pública.
Las superficies continuas, por lo tanto, se muestran como una representación más específica y sensible a la variación espacial del fenómeno de interés, superando las limitaciones inherentes a las unidades discretas. No obstante, sí son más susceptibles a la distorsión causada por la extensión del área de estudio en sí misma (Figura 7), por lo que la delimitación del área de estudio en términos globales es crucial para este tipo de análisis. En el caso de este trabajo, se consideró que la delimitación a la zona urbana es más pertinente dado que en sus límites se encuentra casi la totalidad de la población del municipio.
4.3 Tipos de mediciones y su interpretación: un reto para la comunicación de resultados
Los resultados también muestran el efecto de utilizar distintas mediciones. La tasa de prevalencia (Ecuación 1) se interpreta de manera sencilla y directa, al mostrar la cantidad de casos que podrían esperarse en distintas zonas, considerando un número base de población en riesgo o susceptible de enfermar. Sin embargo, no se cuenta con referencia alguna sobre cuánto es más o menos riesgo.
Por el contrario, el exceso de riesgo (Ecuación 2) sí permite evaluar la preocupación anterior, pues la comparación contra la prevalencia general permite estimar en cuáles zonas se está por encima o por debajo del riesgo base, y por cuanto, en términos proporcionales. Sin embargo, se pierde la cantidad específica de casos.
Finalmente, la superficie de riesgo relativo (Ecuación 5) parte de un principio similar al exceso de riesgo, teniendo como principales diferencias que 1) se trata de una representación continua, en lugar de discreta, y 2) que la escala de referencia cambia a una logarítmica, lo que permite expresar los resultados de manera simétrica alrededor del 0 como valor neutro (riesgo igual a la prevalencia general). Su principal desventaja, al igual que con el exceso de riesgo, es que su interpretación se vuelve más abstracta, al contrario de un indicador concreto como la tasa de prevalencia. No obstante, en su cálculo también es posible incluir y representar las zonas de mayor significancia estadística, y, en este sentido, en un mismo mapa es posible presentar una medición estandarizada en conjunto con las zonas estadísticamente significativas (Figura 7).
4.4 Más allá de la cartografía: análisis de covariables y funciones de distancia
Las representaciones cartográficas en salud pública y epidemiología son instrumentos valiosos por varias razones, a saber, su carácter exploratorio, y, con ello, su potencial para establecer hipótesis sobre las causas o factores detrás de la variación geográfica observada (Baddeley et al., 2012; Elliot et al., 2001).
Por otro lado, las representaciones cartográficas son sólo el primer paso en el análisis espacial de un fenómeno epidemiológico. Luego de responder, siempre de manera tentativa, a la pregunta sobre la variación geográfica de una enfermedad, es necesario poner a prueba hipótesis sobre las posibles causas o factores subyacentes a esta variación. Empero, para esta pregunta es necesario recurrir a otro tipo de herramientas estadísticas, como los modelos de regresión lineal, tanto en su versión sencilla (Grekousis, 2020) como en su extensión geográficamente ponderada (A. S. Fotheringham & Brunsdon, 2004), y a funciones de distancia con respecto de covariables espaciales (Baddeley et al., 2012), por mencionar algunos ejemplos.
De esta manera, la cartografía sirve como una base que, acompañada de medidas resumen y métodos de inferencia estadística, puede representar los patrones de conglomerados que podrían ser parcialmente explicados por otras variables de interés, como factores ambientales, sociodemográficos y del entorno construido. Dichos factores también pueden ser analizados espacialmente en sí mismos, lo cual puede aumentar la complejidad y dificultad del análisis.
5. Conclusiones
En este trabajo se compararon tres métodos de cartografía epidemiológica sobre la variación geográfica del riesgo relativo para la COVID-19, en la ciudad de Málaga, España. Además, se ejemplificó el procesamiento y análisis de los datos con SIG y software libre y de código abierto, lo que puede contribuir a multiplicar análisis similares, a la vez que se señalaron problemas potenciales con los algoritmos utilizados.
Los resultados muestran, por un lado, el grado de distorsión que introduce el uso de diferentes unidades espaciales, principalmente sobre la extensión del área de estudio, y, a su vez, en la estimación de población afectada. Por el otro, se mostraron las diferencias en interpretación de los indicadores epidemiológicos utilizados, pasando de mediciones concretas sin dimensión clara del riesgo, a otras más abstractas que acentúan este aspecto.
Como muestran los resultados, es insuficiente tratar con una sola medición y tipo de unidad espacial, pues mediante su comparación es posible detectar zonas de sub o sobreestimación del riesgo, que, en el caso de Málaga, implicó una diferencia de área de mayor riesgo de 1.79% al 37.78%, y del 10.86% al 37.97% de la población en mayor riesgo. Por otro lado, el uso de mediciones estandarizadas, a pesar de su potencial estadístico, ya no refieren a cantidades concretas, lo cual puede ser útil en términos informativos y divulgativos.
La limitación principal en este tipo de análisis es la disponibilidad de datos epidemiológicos. Si bien la pandemia por COVID-19 trajo consigo la proliferación de datos abiertos en salud pública, su disponibilidad en términos georreferenciados generalmente se encuentra agregada en unidades territoriales variadas, mientras que los datos puntuales no están disponibles al público en general por motivos legales y éticos sobre la protección de la privacidad de las personas.
Finalmente, aunque la descripción de la variación espacial de una enfermedad es crucial en el ámbito de la salud pública, se trata del primer paso en su estudio, pues es necesario continuar con la búsqueda de factores o covariables que puedan ofrecer explicaciones tentativas a los patrones observados. Otros trabajos comentados sobre la COVID-19 y otras enfermedades ofrecen cursos de acción para el análisis de covariables que expliquen los patrones observados.

