











 nova página do texto(beta)
nova página do texto(beta) Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
PermalinkIntroducción
En la actualidad existen necesidades de formación crecientes que no pueden ser satisfechas con los métodos tradicionales de enseñanza, debido a lo cual los modelos de aprendizaje electrónico, electronic learning, e-learning, están cobrando cada vez mayor relevancia. El desarrollo del e-learning ha llevado a la propuesta de varias definiciones, algunas enfatizando los aspectos del uso de Internet y del uso de la tecnología respectivamente. Al respecto, Rosenberg (2001) define este término como “el uso de las tecnologías de internet para entregar un amplio conjunto de soluciones que mejoran el conocimiento y desempeño” (p. 28). Otra definición es la de Rosset y Sheldon (2001), quienes lo describen como “una amplia combinación de procesos, contenidos e infraestructura para usar las computadoras y redes para escalar o mejorar una o más partes significativas de una cadena de valor de aprendizaje, incluyendo administración entrega” (p. 187).
A partir de la definición de Rosset y Sheldon, es claro que el e-learning involucra la gestión del conocimiento y el proceso por medio del cual es puesto al alcance del educando, por lo cual los Sistemas de Gestión del Aprendizaje, Learning Management Systems, LMS, se han convertido en una herramienta fundamental para el e-learning. Con el desarrollo del nuevo paradigma de educación en línea surgen nuevos retos para adaptar los procesos de enseñanza y aprendizaje en éste nuevo entorno, siendo una de sus partes fundamentales el diseño instruccional. Uno de los LMS más populares en el mundo es el sistema MOODLE, Modular Object Oriented Distance Learning Environment, debido a que es un software de distribución libre y su diseño está basado en el enfoque pedagógico constructivista social. Posee una arquitectura modular, lo que permite incorporar una gran diversidad de componentes y funcionalidades. Implementa una interfaz de navegador de tecnología sencilla, ligera, eficiente y compatible (Dougiamas y Taylor, 2003).
De acuerdo a lo anterior es claro que las necesidades de formación del profesorado deben hacer énfasis en el uso de las herramientas utilizadas para el e-learning resultando de primera importancia aquellas que se encuentran en los LMS en los cuales se están implementando éstos nuevos modelos de formación académica. Sin embargo, la implementación de estrategias de formación docente no es una tarea sencilla, porque en las instituciones educativas se presenta un ambiente heterogéneo en las competencias y en el uso de las tecnologías para la educación en línea; razones por las que resulta complicado adaptar el aprendizaje a un conjunto de profesores con diferentes niveles de conocimientos y habilidades para el desarrollo de cursos en línea.
Una estrategia que pudiese resultar de ayuda para personalizar la formación de los profesores es usar el aprendizaje adaptativo el cual es definido por Dāboliņš y Grundspeņķis (2013), como el proceso de generar una experiencia de aprendizaje única para cada educando y se basa en su personalidad, intereses y desempeño para alcanzar metas como el mejoramiento académico del estudiante, la satisfacción del usuario, efectividad en el proceso de aprendizaje, entre otras. Estos mismos autores, mencionan que los sistemas de tutoría inteligente, Intelligent Tutoring System, ITS, son tecnologías que implementan técnicas de aprendizaje adaptativo de acuerdo con las necesidades del individuo, tomando en cuenta factores del conocimiento del tema por parte del estudiante o profesor, sus emociones y estilo de aprendizaje. El uso de estos sistemas permite añadir flexibilidad a los materiales de aprendizaje, modificando el enfoque didáctico de acuerdo con las competencias y particularidades del usuario y la tarea de aprendizaje.
Debido a la capacidad de los ITS para adaptarse a las necesidades del usuario, resultan de gran utilidad dentro de entornos con necesidades heterogéneas de formación y en el caso particular de la investigación que se desarrolló, ofrecen un área de oportunidad para apoyar en la formación de los profesores de interacción con el entorno de un sistema de gestión del aprendizaje.
El presente trabajo de investigación tiene por objeto el desarrollo, implementación y evaluación de un sistema de tutoría inteligente para asistir al profesorado en el desarrollo de actividades específicas dentro del entorno del sistema de gestión del aprendizaje MOODLE. La metodología implementada sigue el enfoque de la investigación-acción en sistemas de información, el cual se ha convertido en uno de los principales métodos de investigación cuantitativa en el campo de los sistemas de información y en la ingeniería del software (Ruiz et al., 2002).
Marco teórico
En esta sección se describen los conceptos más importantes relacionados con la propuesta desarrollada:
Descubrimiento de conocimiento
El descubrimiento de conocimiento implica diversos conceptos con los que está relacionado, tales como datos, información, gestión de la información y la gestión del conocimiento. Los datos consisten en hechos, imágenes o sonidos. Cuando se combinan con la interpretación y el significado, se convierte en información. Por lo tanto, la información consiste en datos que han sido formateados, filtrados y resumidos (Chen, 2001). En cuanto a la gestión del conocimiento, se define como una disciplina emergente cuyo objetivo es generar, compartir y utilizar el conocimiento tácito y explícito existente en un determinado espacio para dar respuesta a las necesidades de los individuos y de las comunidades en su desarrollo (Alavi y Leidne, 2001). Finalmente, el descubrimiento del conocimiento en bases de datos, Knowledge Discovery in Databases, KDD, se define como “el proceso no trivial de identificar patrones válidos, novedosos y potencialmente útiles y en última instancia, comprensible a partir de los datos” (Fayyad, Piatetsky-Shapiro y Smyth, 1996, p. 41). El KDD es un proceso iterativo e interactivo y de acuerdo con (Hernández, Ramírez y Ferri, 2004) su taxonomía se puede organizar en cinco fases: (A) integración y recopilación, (B) selección, limpieza y transformación, (C) minería de datos, (D) evaluación e interpretación y (E) difusión y uso.
Minería de datos en educación
Como se mencionó anteriormente, la minería de datos es una etapa crucial de las técnicas incluidas en el proceso KDD. Se define como “el proceso de extraer conocimiento útil y comprensible, previamente desconocido, desde grandes cantidades de datos almacenados en distintos formatos” (Fayyad et al., 1996). La minería de datos trabaja con grandes volúmenes de datos, procedentes en su mayoría de sistemas de información, con los problemas que ello conlleva, ruido, datos ausentes, intratabilidad, volatilidad de los datos, entre otros, y aplica técnicas adecuadas para analizar estos datos y extraer conocimiento novedoso y útil (Hernández et al., 2004).
De forma específica, la minería de datos en educación o minería de datos educativa, Educational Data Mining, EDM, es la aplicación de técnicas de minería de datos a información generada en los entornos educativos. La EDM se define como “el proceso de transformar los datos en bruto recopilados por los sistemas de enseñanza en información útil que pueda utilizarse para tomar decisiones informadas y responder preguntas de investigación” (Heiner et al., 2006).
La aplicación de minería de datos en sistemas educativos es un ciclo iterativo de formación de hipótesis, pruebas y refinamiento. El conocimiento descubierto, una vez filtrado, sirve de guía, facilita y mejora el proceso de aprendizaje a través de la toma de decisiones. De acuerdo con Romero y Ventura (2007), los educadores, investigadores y responsables académicos son los encargados de diseñar, planificar, crear y mantener los sistemas educacionales y los alumnos usan e interactúan con él.
Sistema de tutoría inteligente
Este concepto fue definido por Stankov, Glavinic y Rosic (2011), quienes afirman que los ITS son un tipo particular de sistemas de e-learning asíncrono basados en conocimiento, diseñados para dar soporte y mejorar el proceso de enseñanza y aprendizaje para cierto dominio de conocimiento respetando la individualidad del estudiante como en una tutoría tradicional. Adicionalmente, los autores Keles y Keles (2011), afirman que son programas de computadora diseñados para incorporar técnicas de la comunidad de inteligencia artifical para proveer tutores que sepan lo que enseñan, a quién lo enseñan y cómo enseñarlo. Adicionalmente, se menciona que de acuerdo a Urban-Lurain (2003), estos sistemas se caracterizan por la habilidad inteligente de adaptar sus estrategias de enseñanza al conocimiento y habilidades de sus alumnos de manera que la instrucción sea tan efectiva y eficiente como sea posible. Finalmente, se destaca que Lee y Sapiyan (2006), definen este concepto como un software avanzado de entrenamiento que imita a un tutor humano para proveer aprendizaje individualizado. En resumen, podemos definir un ITS como un sistema que evalúa acciones del usuario y desarrolla un modelo del conocimiento, habilidades y dominio de la materia del estudiante, para proveer pistas, ofrecer explicaciones y demostraciones basadas en el modelo obtenido. Este enfoque es defendido por Romero y Ventura (2007) así como por Keles, Ocak y Gülcü (2009).
Como se puede apreciar, a pesar de la variedad de definiciones existentes en la literatura todas tienen en común la capacidad de los ITS de generar un modelo del conocimiento, habilidades, perfil de usuario y de adaptar el aprendizaje de forma individual utilizando técnicas de aprendizaje apropiadas para cada usuario. Muchos autores señalan como componentes clave de los ITS la extracción del perfil del usuario, el conocimiento de técnicas de enseñanza y la adaptabilidad de los procesos de enseñanza y aprendizaje. A menudo se menciona que el conocimiento pedagógico y el conocimiento de la materia son componentes separados dentro del sistema y el ITS tiene la capacidad de usar ambos para personalizar dichos procesos.
Existe variedad en las arquitecturas utilizadas para implementar los ITS, de hecho no es común encontrar dos sistemas con la misma arquitectura, lo cual es un resultado de la naturaleza experimental del trabajo en el área (Keles y Keles, 2011), por lo que no existe una clara división para una arquitectura general para ellos (Yazdani, 1986) pues algunos son desarrollados con base en teorías psicológicas (Künzel y Hämmer, 2006), otros se desarrollan para dominios de aplicación específicos (Bergin y Fors, 2003) y algunos más son utilizados para realizar pruebas de conceptos científicos de la computación (Martens y Himespach, 2005). Esta heterogeneidad en la aplicación de los dominios de implementación de los ITS aumenta las diferencias entre sus arquitecturas. Sin embargo, hay un consenso general en la literatura que identifica cuatro módulos básicos para los ITS (Bonnet, 1985), los cuales son: conocimiento de la materia, conocimiento del estudiante y del profesor, tutoría e interfaz.
El módulo de conocimiento de la materia, representa el conocimiento del dominio de estudio para el cual el ITS es implementado. Es la parte que contiene reglas, información, preguntas y soluciones relevantes a la materia que será presentada al estudiante/profesor. Durante los últimos años se han desarrollado varios formalismos en la inteligencia artificial para la representación del conocimiento: reglas simbólicas, grafos conceptuales, lógica difusa, redes bayesianas, redes neuronales, razonamiento basado en casos, minería de datos, entre otros. La mayoría de estas técnicas han sido utilizadas para representar el conocimiento en los ITS (Bulut Özek, Akoplat y Orhan, 2013).
El módulo de conocimiento del estudiante y del profesor, recolecta información acerca de estos y el grado de dominio que tiene sobre la materia de estudio, conceptos correctos y erróneos, así como información acerca de las preferencias y estilo de aprendizaje (Lavandelis y Bicans, 2011). Las técnicas comunes para extraer este conocimiento incluyen redes bayesianas y lógica difusa (Pek y Poh, 2005), mientras que otras se apoyan en el análisis de actividades (Hafdi y Bensebaa, 2013) y en cuestionarios para determinar el estilo de aprendizaje (Bulut, Akoplat y Orhan, 2013).
El módulo de tutoría, contiene información pedagógica acerca de la forma de enseñar y estrategias de enseñanza e instrucciones para implementar el proceso de enseñanza (Pek y Poh, 2005). Existen algunas implementaciones interesantes de este módulo desde la perspectiva de psicología de la educación que utilizan estrategias colaborativas y utilizan el sistema para generar actores pedagógicos capaces de producir aprendizaje por disturbio (Aimeur, Frasson y Dufort, 2000). El módulo de interfaz se emplea a menudo como un canal de comunicación, bien sea entre los diferentes componentes del sistema o entre el sistema y el usuario.
Agentes conversacionales
Este concepto se denomina en inglés conversational agent o chatbot y son programas de software que permiten a las personas interactuar con sistemas informáticos utilizando diálogos de lenguaje natural. Los agentes conversacionales se han desarrollado para servir a múltiples funciones pedagógicas, como tutores, entrenadores o compañeros de aprendizaje (Haake y Gulz, 2009). En sistemas expertos, como tutores (Greaser et al. 2005), las interfaces son intuitivas y útiles para involucrar a los usuarios en la discusión, como lo demuestran los autores (Tegos, Demetriadis y Karakostas, 2015). Cabe destacar que pueden agregar capacidades de diálogo natural a los ITS pero no se usan con frecuencia ya que su desarrollo es complejo y requiere mucho tiempo, además de requerir experiencia en la creación de códigos de programación que permitan el diálogo (O’shea, Bandar y Crockett, 2011). Los agentes conversacionales se implementan utilizando dos enfoques principales: coincidencia de patrones y el análisis semántico.
La mayoría de los agentes conversacionales o chatbot de coincidencia de patrones se desarrollan utilizando pares de estímulo-respuesta ya que son eficaces para tratar expresiones sintácticas mal formadas. Sin embargo, el desarrollo de estos a menudo implica definir el alcance del chatbot y la creación de guiones especializados. Otra consideración para estos agentes conversacionales es el hecho de que es difícil agregar nuevos conocimientos al sistema debido a que requieren la modificación de secuencias de comandos por parte de un experto para adaptarlo a la tecnología de codificación del sistema, generalmente se utiliza AIML, Artificial Intelligence Markup Language.
En los chatbot de análisis semántico latente, las palabras se representan como vectores y la similitud entre los conceptos se mide de acuerdo con la distancia entre estos. Este enfoque tiene dificultades para lidiar con un lenguaje deficiente o fallas tipográficas. Además, si se necesita añadir conocimiento nuevo, el corpus de palabras debe ser aumentado y recalculado manualmente.
Metodología
La metodología que se propone, se basa en un ITS que utiliza reglas de conocimiento extraídas de la interacción de los profesores con el entorno de un LMS:
Como se observa en la Figura 1, el profesor interactúa con sus cursos en línea a través del entorno de un LMS, el cual registra los datos de uso. A partir de la información almacenada, se generan tablas de información en las que se tienen datos relacionados a la actividad del profesor con las diferentes herramientas del entorno.
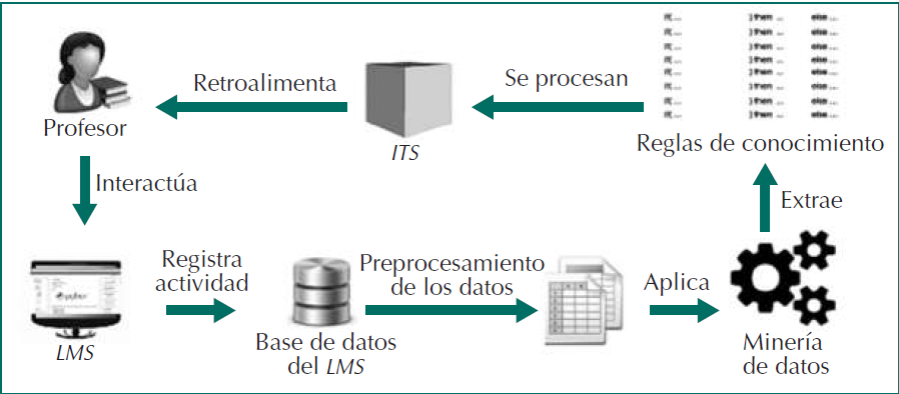
Dichas tablas pasan por un proceso de preprocesamiento de la información y posteriormente se aplicarán técnicas de minería de datos para extraer los patrones de comportamiento del profesorado, los cuales se convierten en reglas de conocimiento que serán proporcionadas al tutor inteligente, el cual adapta su comportamiento tomando como base las reglas generadas y el perfil del usuario para ofrecer retroalimentación al profesor (Camacho, Zapata, Menéndez y Canto, 2018). Lo anterior, es un ciclo continuo por medio del cual se pueden personalizar las necesidades formativas de cada profesor.
El ITS se enfocará en la retroalimentación al usuario acerca del uso de las herramientas del entorno del LMS mediante un enfoque híbrido, utilizando secuencia de currículo al permitir que el profesor pregunte acerca de las herramientas de su interés, ofreciendo tutoría basada en restricciones para brindar recomendaciones de herramientas al profesor de acuerdo con su perfil y los datos extraídos a partir del uso del LMS. El ITS está conformado por cuatro módulos principales:
1. Perfil del usuario: se enfoca en determinar el perfil al que pertenece un usuario que utiliza el sistema, para conocer los aspectos fundamentales que se deben reforzar tomando en cuenta la información de las reglas de conocimiento proporcionadas al sistema.
2. Pedagógico: el cual contendrá la información relacionada con la descripción y uso de las herramientas del LMS, la cual será utilizada para retroalimentar al usuario.
3. Tutoría: se encarga de combinar la información obtenida a partir de los módulos de perfil de usuario y pedagógico para generar recomendaciones personalizadas al usuario utilizando un enfoque híbrido de tutoría.
4. Interfaz: es el encargado de comunicarse con el LMS y presentar por medio de un complemento integrado en su entorno la información al usuario.
A continuación, en la Figura 2 se muestra un esquema de comunicación e interacción del ITS con el profesor. En esta figura se ilustra el esquema de comunicación e interacción del tutor inteligente con el profesor, el proceso de extracción de reglas de conocimiento y la interacción con los componentes del ITS. El análisis de la interacción del entorno del LMS con profesores de perfiles similares permitirá la creación de perfiles iniciales que pueden ser utilizados para realizar recomendaciones a usuarios de los cuales no se tiene historial, por ejemplo, los profesores nuevos. La estrategia mencionada con anterioridad permite minimizar el impacto del arranque en frío (Son, 2016) que se da en los sistemas adaptativos cuando se carece de información del usuario.
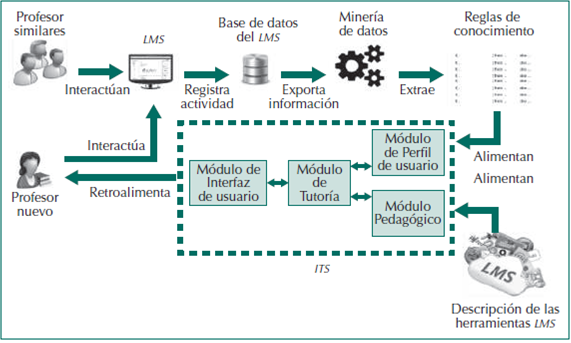
El módulo de usuario del ITS se alimentará de los perfiles iniciales extraídos como reglas de conocimiento lo que permitirá que el sistema pueda discernir qué herramientas debe ayudar a conocer a un nuevo usuario. La descripción y los ejemplos de uso de las herramientas del LMS alimentarán el módulo pedagógico del ITS para brindar información relevante al usuario acerca de las mismas. Estas respuestas pueden ser redactadas de la manera que se considere adecuada para enriquecer la formación de los profesores e inclusive puede incluir contenido multimedia incrustado para mejorar la experiencia de interacción y la eficiencia del sistema.
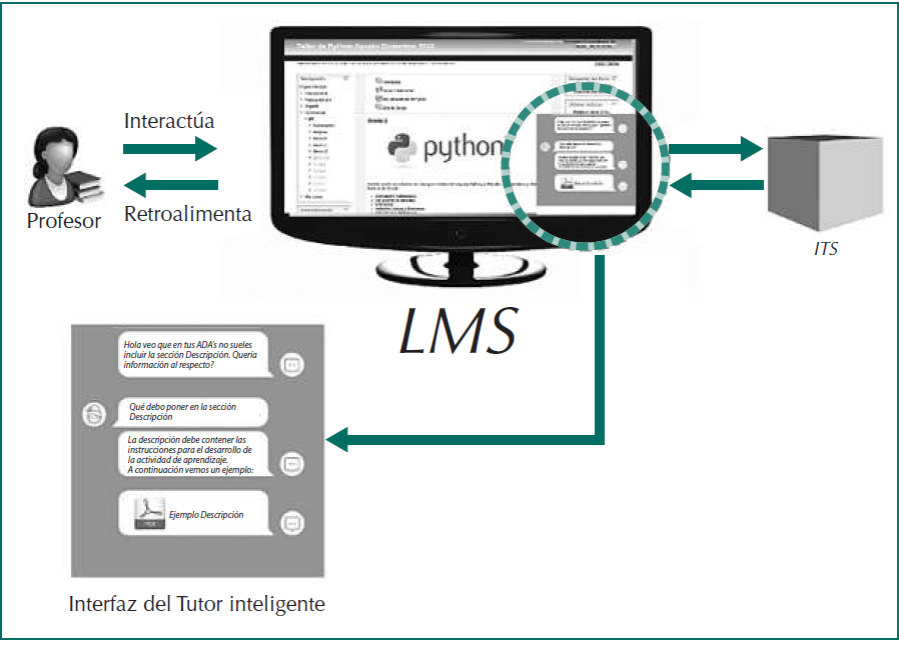
Como se observa en la Figura 3, el profesor se comunica con el ITS por medio de una interfaz de texto incrustada en el entorno del LMS. El profesor podrá realizar preguntas en lenguaje natural que el sistema interpretará para brindar información acerca de la herramienta de interés para el profesor, enfatizando aquellas que han sido definidas como prioritarias de acuerdo a su perfil de usuario. Finalmente, se destaca que la interfaz además de responder con texto, podrá cargar imágenes y archivos que ayuden a profundizar el conocimiento del profesor sobre la herramienta del entorno del LMS de su interés.
Desarrollo e implementación de un prototipo
Para la validación del marco arquitectónico propuesto se implementó un sistema de tutoría inteligente para asistir al profesorado en el uso de las herramientas de MOODLE denominado MITS, MOODLE Intelligent Tutoring System, que se planteó como un ITS conversacional debido a su buena capacidad para involucrar al usuario en el uso del sistema (Kerly, Ellis y Bull, 2008). Los sistemas conversacionales tienen la capacidad de transmitir la información de forma directa, por lo que resultan útiles para consultas específicas y dudas puntuales por parte del usuario. Esto los convierte en un buen instrumento para interactuar con usuarios de varios niveles de conocimiento y dominio del tema, como es el caso de los profesores.
Se decidió trabajar con el sistema MOODLE debido a que es de código abierto, por lo que su programación y componentes son accesibles para desarrolladores externos, además de tener una estructura sólida y desarrollada para la incorporación de componentes externos a través de complementos. Otra ventaja es el grado de penetración que tiene el entorno MOODLE en multitud de instituciones educativas de todos los niveles educativos alrededor del mundo. Esta proyección de uso de este sistema tiene como consecuencia que las herramientas y desarrollos realizados para este entorno puedan llegar a un gran número de usuarios, lo cual permitirá una validación extensa de la propuesta por usuarios de diferentes formaciones, latitudes y formas de interactuar con los LMS.
La interfaz del chatbot se encuentra integrada dentro del entorno de MOODLE como una ventana emergente ubicada al pie de la página, permitiendo que el profesor pueda minimizarla y maximizarla en los momentos en que decida interactuar con el sistema. Lo anterior se realizó con el objetivo de permitir una interacción dinámica con el profesor en el momento que esté diseñando sus cursos en línea.
Como se observa en la Figura 4, el módulo de chatbot del sistema MITS puede dar formato a la información obtenida para incrustar elementos HTML, HyperText Markup Language, y de esa manera enriquecer la experiencia del usuario con contenido y material interactivo. La interacción con el agente conversacional se realiza a través de coincidencia de patrones, que buscan intenciones y entidades previamente configuradas en una base de conocimientos almacenada en archivos XML, Extensible Markup Language. Esta arquitectura presenta ventajas, es decir, en relación a los agentes conversacionales implementados mediante AIML, debido a la simplicidad de su modelación y facilidad de extensión hacia diferentes dominios del conocimiento, todo esto permite que el tutor se adapte a diferentes asignaturas.
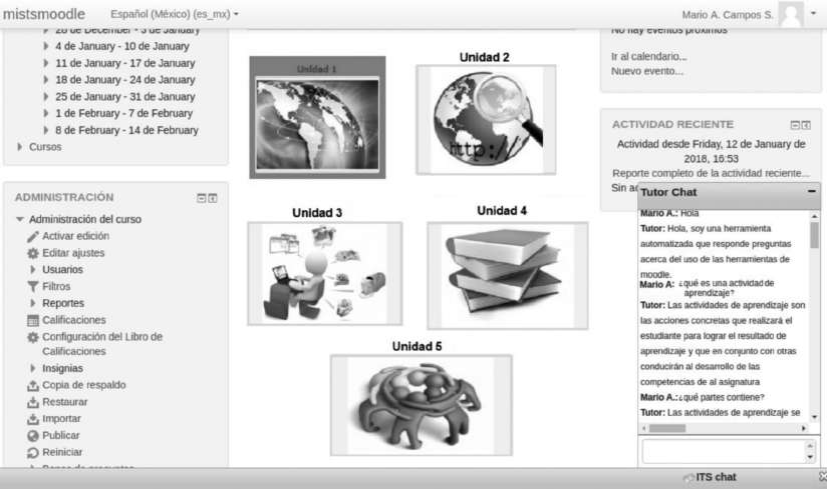
Las consultas efectuadas por el usuario se realizan a través de la detección de intenciones y entidades en las expresiones. Con respecto a la intención se refiere a la propiedad o característica que el usuario desea consultar sobre un tema específico. En cuanto a la entidad, esta modela el tema de interés estudiado. La base de conocimiento del agente se compone de archivos XML en donde se almacenan las estructuras de intenciones y entidades con sus ejemplos de consulta.
Las intenciones se modelan utilizando un archivo XML que contiene un identificador de la intención, así como ejemplos por medio de los cuales los usuarios pueden referirse a dicha intención empleando lenguaje natural. En cuanto a las entidades, se encuentran modeladas como ontologías las cuales contienen propiedades con la información de los elementos que modelan. Se tiene un archivo XML por cada una de las herramientas de MOODLE acerca de las cuales el sistema puede brindar información. La resolución de una consulta se realiza mediante la búsqueda de patrones de intenciones, que estén contenidos en la ontología de la entidad expresada por el usuario. Este vínculo se genera por medio del identificador de la intención, que coincide con las propiedades modeladas en la ontología de la entidad.
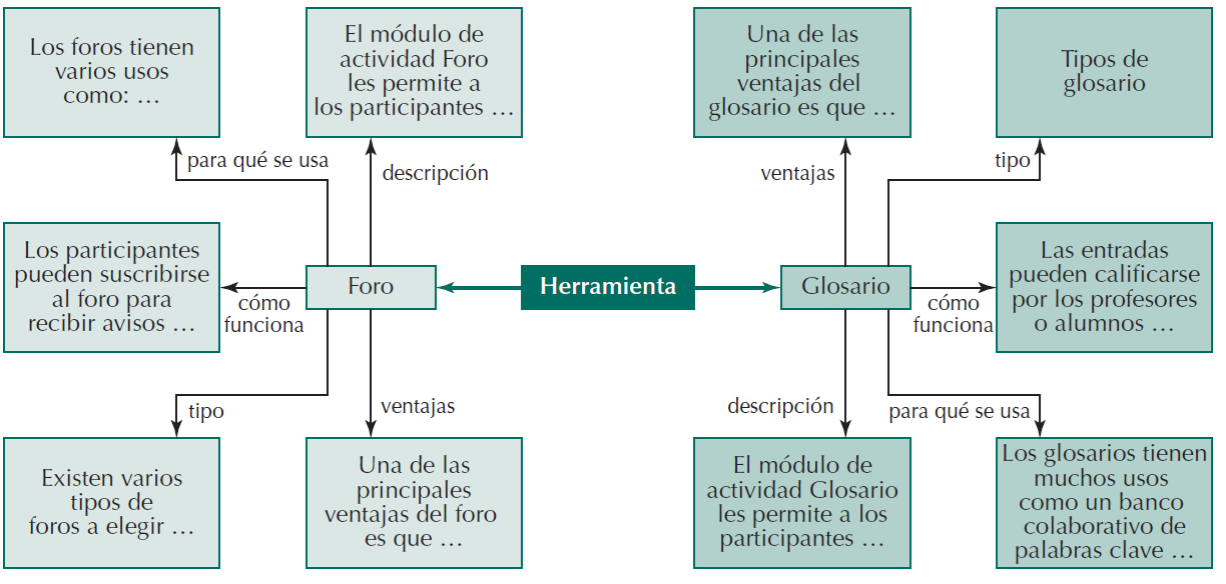
El sistema MITS permite brindar retroalimentación al profesorado con las 21 entidades o herramientas disponibles en el entorno de MOODLE, que son 15 actividades y 6 recursos. En cuanto a las intenciones, el sistema es capaz de gestionar diversas expresiones para la consulta de temas específicos, Figura 4. Para encontrar las intenciones y entidades en las consultas realizadas por el profesor se aplica una medida de similitud de cadena, para los elementos configurados en la base de conocimiento y, por medio de una ventana deslizante, así verifica si el texto analizado contiene las expresiones configuradas en la base de datos, tanto para las intenciones como para las entidades. Si la distancia pasa un límite de similitud, el módulo del agente conversacional considera que la expresión se encuentra en el texto, así construye una consulta hacia la base de conocimientos para obtener la información asociada que debe contestar.
En la Figura 5 se muestra un diagrama que ilustra el modelado de la base de conocimientos de las entidades o herramientas del entorno de MOODLE, que vinculan los elementos clave definidos como intenciones del sistema con las respuestas que debe arrojar para cada una de las herramientas. Para la medida de similitud entre las cadenas de búsqueda se utilizó una versión normalizada de la distancia de Levenshtein (Yujian y Bo, 2007), lo que derivó en la siguiente formula:
donde P X,Y es un camino de edición para transformar la palabra X en la palabra Y, W(P X,Y ) es el peso del camino de edición P X,Y , |X| es el número de símbolos en la palabra X y |Y| es el número de símbolos en la palabra Y. Se escogió esta distancia debido a que ha sido reportada como una buena medida de similitud entre cadenas, y siendo ampliamente utilizada para el reconocimiento de patrones de texto, además de proporcionar tolerancia a errores tipográficos y a elementos semánticos complejos.
Cada profesor es representado por un vector de uso de las herramientas del entorno de MOODLE, en donde cada una es calificada con una escala de uso del 1 al 5, donde 1 indica un uso muy bajo de la herramienta y 5 un uso muy alto de la misma. Esta representación tiene la ventaja de ser escalable en cuanto el número de herramientas que se desean utilizar para modelar el perfil del usuario. Una vez que se decide el nivel de uso de cada herramienta para el profesor se genera un vector de características. Para definir el perfil se verifica la distancia entre el vector de uso del profesor y los perfiles proporcionados al sistema. Para ello, se tomaron en cuenta dos medidas de similitud: la diferencia promedio normalizada y la distancia de coseno suave, las cuales se describen:
donde s i,j indica la similitud entre la característica i y la característica j, a i el iésimo elemento del vector a y b i el iésimo elemento del vector b. Se eligió esta medida de comparación debido a los buenos resultados reportados por Sidorov, Gelbukh, Gómex-Adorno y Pinto (2014), en la comparación de características específicas dentro de espacios vectoriales. La medida de comparación añade versatilidad a la hora de realizar las comparaciones, pudiendo definir los grados de similitud por parte del usuario. De igual manera, verificamos la similitud entre vectores, utilizando el valor promedio de las diferencias normalizadas entre las diferencias de los elementos de los vectores:
donde s indica la escala de los valores máximos del vector, a i el iésimo elemento del vector a y b i el iésimo elemento del vector b. Esta métrica fue seleccionada debido a su bajo costo computacional y por ser una alternativa viable para comparaciones de perfil simples. Una vez que el perfil del usuario se ha decidido, se elige qué herramienta retroalimentar al usuario calculando la mayor diferencia entre las herramientas del perfil y las herramientas del vector del usuario.
Experimentación y resultados
En esta sección se presenta la validación de los resultados obtenidos de la investigación mediante experimentos automáticos y con usuarios reales.
Prueba automatizada
La personalización de las recomendaciones del sistema MITS hacia los usuarios necesita información generada por el profesor mediante su interacción con el entorno de MOODLE. Sin embargo, en el contexto en el que se realiza esta investigación se carece de un historial de uso de las herramientas por parte de los profesores. Con el fin de probar el desempeño de MITS como tutor inteligente capaz de personalizar los contenidos mostrados al profesor de acuerdo con su perfil, se generó un caso de uso automatizado en donde se introducen perfiles iniciales y se verifica la clasificación del perfil del usuario según las métricas de diferencia promedio normalizada, así como la similitud de coseno suave descritas previamente. Para la experimentación de este caso se cargaron previamente tres perfiles de usuario predefinidos con las siguientes 10 herramientas del sistema MOODLE: (1) asistencia, (2) cuestionario, (3) encuesta predefinida, (4) foro, (5) glosario, (6) HotPotatoes, (7) lección, (8) taller, (9) tareas y (10) wiki. Adicionalmente, se definieron cinco niveles de uso de las herramientas, donde 1 significa un nivel bajo y 5 un nivel muy alto.
En la Tabla 1 se muestran los perfiles de uso de las herramientas de parte del sistema, fueron seleccionados para ser claramente diferenciables y facilitar su clasificación por parte de un humano experto, poniendo énfasis en un uso muy alto de ciertas herramientas y muy bajo en las demás. En el primer perfil se muestra a un profesor que realiza un uso muy alto de las tres primeras herramientas: asistencia, cuestionario y encuesta, mientras que tiene un uso muy bajo para las demás. El segundo perfil se caracteriza por hacer un uso muy elevado de las herramientas foro, glosario, HotPotatoes y lección, mientras que realiza un uso muy bajo de las demás. El tercer perfil realiza un uso muy alto de las herramientas taller, tareas y wiki, mientras que utiliza muy poco las demás.
Tabla 1 Perfiles predefinidos de usuario del sistema MITS.
| Perfil | Datos |
|---|---|
| 1 | [5, 5, 5, 1, 1, 1, 1, 1, 1, 1] |
| 2 | [1, 1, 1, 5, 5, 5, 5, 1, 1, 1] |
| 3 | [1, 1, 1, 1, 1, 1, 1, 5, 5, 5] |
Con el objetivo de probar la eficiencia de la clasificación del módulo de perfil del usuario se generaron 30 ejemplos de manera aleatoria escalándolos para que tuvieran valores entre 1 y 5. Estos ejemplos fueron clasificados manualmente en uno de los tres perfiles predefinidos con la asesoría de un experto según su similitud. A continuación, se realizó la clasificación automática por medio del sistema MITS utilizando las medidas de diferencia promedio normalizada y la distancia de coseno suave.
La Tabla 2 describe los resultados del experimento. La primera columna establece las características de los 30 perfiles de usuarios generados de manera aleatoria, según el nivel de uso -valores de 1 a 5- de cada herramienta de MOODLE. La columna “Experto” indica el perfil predefinido que el experto considera se parece más el ejemplo. Los dos grandes bloques presentan los resultados, usan como algoritmo de similitud la distancia de coseno suave y la diferencia promedio normalizada. En cada bloque se presenta el perfil predefinido, que el sistema consideró más parecido según el grado de similitud establecido en la columna central. La columna de aciertos establece si la predicción del sistema es coincidente con el experto. Por ejemplo, para el primer ejemplo, los dos algoritmos de similitud establecieron que el perfil predefinido más parecido era el 1, que es coincidente con la decisión del experto por lo que tiene un acierto, pero mientras que con la distancia de coseno suave se tuvo una similitud de 80%, con la diferencia de promedio normalizada tuvo 60%.
Tabla 2 Resultados de pruebas automatizadas.
| Ejemplo | Experto | Sistema | Distancia coseno suave | Acierto | Sistema | Diferencia promedio normalizada | Acierto |
|---|---|---|---|---|---|---|---|
| 1,3,5,4,3,4,2,1,3,2 | 1 | 1 | 0.801 | 1 | 1 | 0.600 | 1 |
| 1,4,3,2,1,4,5,1,4,2 | 0 | 1 | 0.755 | 0 | 1 | 0.575 | 0 |
| 2,2,1,5,5,1,5,2,1,2 | 1 | 1 | 0.902 | 1 | 1 | 0.800 | 1 |
| 1,2,4,5,1,2,4,2,3,1 | 1 | 1 | 0.788 | 1 | 1 | 0.625 | 1 |
| 4,4,5,1,5,1,5,5,1,4 | 0 | 0 | 0.782 | 1 | 0 | 0.575 | 1 |
| 1,3,1,2,2,5,3,1,2,3 | 1 | 1 | 0.842 | 1 | 1 | 0.675 | 1 |
| 3,2,5,2,2,1,4,5,2,1 | 0 | 0 | 0.767 | 1 | 0 | 0.625 | 1 |
| 1,5,5,5,1,4,5,1,4,1 | 1 | 1 | 0.766 | 1 | 1 | 0.600 | 1 |
| 4,5,4,4,2,1,4,4,2,5 | 0 | 0 | 0.815 | 1 | 0 | 0.575 | 1 |
| 2,4,2,1,5,3,1,3,2,3 | 2 | 1 | 0.708 | 0 | 0 | 0.550 | 0 |
| 4,3,3,3,2,3,2,2,3,5 | 0 | 0 | 0.781 | 1 | 0 | 0.550 | 1 |
| 3,2,5,1,5,1,1,3,4,2 | 0 | 0 | 0.759 | 1 | 0 | 0.625 | 1 |
| 3,5,1,4,1,5,1,2,3,3 | 0 | 0 | 0.707 | 1 | 0 | 0.550 | 1 |
| 4,1,5,1,3,2,3,5,3,1 | 0 | 0 | 0.751 | 1 | 0 | 0.600 | 1 |
| 5,1,2,4,1,2,4,2,4,3 | 2 | 2 | 0.721 | 1 | 2 | 0.550 | 1 |
| 4,1,2,4,5,2,3,1,4,5 | 1 | 1 | 0.781 | 1 | 1 | 0.575 | 1 |
| 3,2,1,3,2,4,5,5,3,3 | 2 | 2 | 0.802 | 1 | 1 | 0.575 | 0 |
| 1,3,3,3,1,3,4,5,5,2 | 2 | 2 | 0.829 | 1 | 2 | 0.650 | 1 |
| 3,3,3,4,1,3,1,4,3,4 | 2 | 2 | 0.827 | 1 | 2 | 0.625 | 1 |
| 4,1,1,4,4,3,2,3,3,5 | 2 | 2 | 0.794 | 1 | 2 | 0.600 | 1 |
| 5,3,2,3,5,3,1,4,3,5 | 2 | 2 | 0.788 | 1 | 2 | 0.550 | 1 |
| 5,5,2,3,4,2,1,5,5,3 | 2 | 2 | 0.803 | 1 | 2 | 0.575 | 1 |
| 4,3,3,4,1,1,2,3,4,4 | 2 | 2 | 0.819 | 1 | 2 | 0.625 | 1 |
| 3,4,2,4,1,2,2,1,5,4 | 2 | 2 | 0.766 | 1 | 2 | 0.600 | 1 |
| 5,5,4,1,3,2,3,3,1,2 | 0 | 0 | 0.925 | 1 | 0 | 0.775 | 1 |
| 5,4,5,3,3,1,4,4,3,2 | 0 | 0 | 0.872 | 1 | 0 | 0.650 | 1 |
| 2,1,5,3,4,1,5,1,1,4 | 1 | 1 | 0.771 | 1 | 1 | 0.625 | 1 |
| 4,1,3,2,2,5,4,4,2,4 | 1 | 1 | 0.765 | 1 | 1 | 0.525 | 1 |
| 1,2,3,5,4,5,5,2,4,3 | 1 | 1 | 0.923 | 1 | 1 | 0.750 | 1 |
| 4,5,3,3,3,2,4,2,2,4 | 0 | 0 | 0.835 | 1 | 0 | 0.600 | 1 |
| Total: | 28 (93%) | Total: | 27 (90%) |
De acuerdo con los resultados obtenidos en la Tabla 2, el sistema mostró un buen desempeño en la clasificación de los perfiles de los usuarios siendo estos superiores al 90%. Un resultado destacable de las pruebas automatizadas es que la similitud de coseno suave demostró un desempeño ligeramente mejor que la diferencia promedio normalizada. Sin embargo, la diferencia no es significativa para la clasificación utilizando el vector de características generado por el sistema.
Prueba con usuarios
La fase de experimentación se realizó en la Universidad Autónoma de Yucatán (UADY) ubicada en el sureste de México, con el propósito de analizar el sistema MITS desde una perspectiva de uso. El experimento se realizó con un grupo de profesores de la Facultad de Educación quienes cuentan con una amplia experiencia utilizando el sistema UADY Virtual (https://es.uadyvirtual.uady.mx), el cual está basado en el software MOODLE. También se incluyó al personal del Departamento de Innovación e Investigación Educativa, quienes son los administradores de dicho sistema de gestión del aprendizaje en esa institución educativa. La hipótesis del experimento es que las personas participantes en el estudio consideran que el sistema MITS tiene una usabilidad buena.
Enseguida se utiliza el término “usabilidad” y nos referimos a un atributo de calidad que establece cuan fácil y útil resulta utilizar un sistema (Nielsen y Loranger, 2006). Esto, implica valorar si las personas interactúan con el sistema de la forma más fácil, cómoda e intuitiva posible (Dumas y Redish, 1999).
Para medir la usabilidad del sistema MITS se utilizó la métrica SUS (System Usability Scale) (Brooke, 1996), la cual se basa en un cuestionario de 10 reactivos cuyas respuestas tienen una escala Likert de 5 puntos, que van desde un rango de “completamente en desacuerdo” con un valor de 1, hasta “totalmente de acuerdo” con un valor de 5. Esto permite generar un valor entre 0 a 100 que representa el grado de usabilidad percibida, es decir, el grado en que una persona cree que el uso del sistema MITS estará libre de dificultad, le será más fácil de aprender y de usar, proporciona una interfaz amigable y flexible y permite una interacción clara y entendible.
Se implementó esta prueba dado que es sencilla de adminisrar a las personas, puede ser usada en pequeños grupos y permite diferenciar entre un sistema útil y uno que no lo es (usability. gov, 2017). De las 10 preguntas que conforman al instrumento, las impares son clasificadas como positivas y las pares consideradas como negativas en el ámbito de la facilidad de uso y utilidad de un sistema (Bangor et al., 2009). Si bien el rango que arrojan los resultados de la prueba va del 1 al 100, éste no debe interpretarse como un porcentaje de usabilidad, sino que debe normalizar los resultados y generar un rango de percentiles. Sin embargo, el hecho de tener una calificación mayor a 70 en la prueba categoriza a la usabilidad del sistema como una aceptable, mayor a 85 como excelente e igual a 100 como la mejor imaginable.
De acuerdo con Tullis y Stetson (2006), un pequeño grupo muestra de 8 a 12 personas, se pueden obtener resultados confiables de la percepción de facilidad de uso de un sistema, por lo tanto, se eligió una muestra de personas que fueran potenciales usuarios del sistema para la prueba.
La experimentación se llevó a cabo con 11 participantes, de los cuales 5 pertenecen a la Facultad de Educación de la UADY y 6 al Departamento de Investigación e Innovación Educativa de esa misma institución. Del total de participantes, 1 reportó tener licenciatura como grado máximo de estudios, 7 maestría y 3 doctorado. Con respecto al área de formación, 3 de los participantes pertenecían al área de ingeniería y tecnología, 1 al área de ciencias sociales y administrativas y 7 al área de educación, humanidades y arte. En cuanto a la experiencia docente de los participantes, 4 de las personas indicaron tener una experiencia menor a 5 años, 5 de las personas cuentan con una experiencia docente entre 5 y 10 años y 2 entre 10 y 15 años de experiencia. En la experiencia interactuando con sistemas de gestión del aprendizaje, 3 cuentan con una experiencia menor a los 5 años, 6 tienen una experiencia entre 5 y 10 años y 2 entre 10 y 15 años.
La experimentación se realizó a través de un servidor de MOODLE, el cual se instaló utilizando los servicios de la nube de la empresa Google con el objetivo de ser accesible desde internet. La instancia del servicio del sistema MITS se configuró en el mismo servidor que se ejecutaba en el sistema MOODLE.
Para la ejecución del experimento, primero se realizó una fase de entrenamiento donde las personas recibieron un curso teorico-practico de aproximadamente una hora sobre el sistema MITS. Esta fase se realizo con el fin de que las personas apliquen en las mismas condiciones la variable a examinar. Durante el entrenamiento se realizaron practicas guiadas para utilizar el sistema MITS, en las cuales se contaba con recursos proporcionados por el instructor.
Una vez finalizado el entrenamiento, se llevó a cabo el experimento. Durante la fase de ejecución el instructor presento a las personas un diseño instruccional que debían utilizar para crear un actividad de aprendizaje usando la herramienta “Tarea” en el entorno de MOODLE apoyándose del sistema MITS. Cabe señalar que se estableció un límite de 30 minutos para la realización de esta fase. Es importante mencionar que durante todo el proceso la persona podía solicitar asesoría del instructor.
La selección de la herramienta “Tarea” se debe a que en el trabajo (Camacho et al, 2018), se encontró que el uso de esta herramienta es la que registra mayor actividad en la UADY.
Al concluir el experimento las personas contestaron de manera anónima la encuesta de Escala de Usabilidad de Sistemas (SUS) para registrar su opinión con respecto a la utilidad y facilidad de uso del sistema MITS.
Resultados
Una vez concluido la fase de experimentación, se identificó que las personas realizaron 252 interacciones con el sistema MITS, promediando 22.91 interacciones por cada uno de ellos. De las 252 interacciones realizadas con el tutor, 112 (44%) se encontraban relacionadas con elementos contenidos en la base de conocimientos de MITS, y de estas el tutor contestó correctamente 92, lo que equivale al 82% de las preguntas hechas dentro de su dominio de conocimiento y al 35% de todas las interacciones con las personas.
En la Tabla 3 se presentan algunos datos estadísticos relacionados con las interacciones de las personas En la Figura 6 se muestra la distribución de dichas interacciones agrupadas por series, total de interacciones, preguntas válidas y respuestas correctas. Puede observarse que, en general, el desempeño de la propuesta resulta satisfactorio para resolver dudas relacionadas con su modelo de conocimiento y considerando los perfiles de las personas, esto a pesar de las interacciones de dos personas que dispersaron en gran medida los datos (M= 22.91, SD= 20.96). Si estas dos personas no fueran considerados en el experimento, el 52% de las interacciones hechas por las personas con el sistema MITS serían válidas y el 43% de las preguntas hechas al tutor hubieran sido contestadas correctamente.
Tabla 3 Estadísticas básicas de la interacción de las personas con el sistema MITS.
| Medida | Interacciones | Preguntas válidas | Respuestas correctas |
|---|---|---|---|
| Total | 252 | 112 | 92 |
| Media | 22.91 | 10.18 | 8.36 |
| Mediana | 15 | 9 | 6 |
| Desviación estándar | 20.96 | 4.58 | 4.67 |
| Máximo | 84 | 22 | 20 |
| Mínimo | 8 | 5 | 4 |
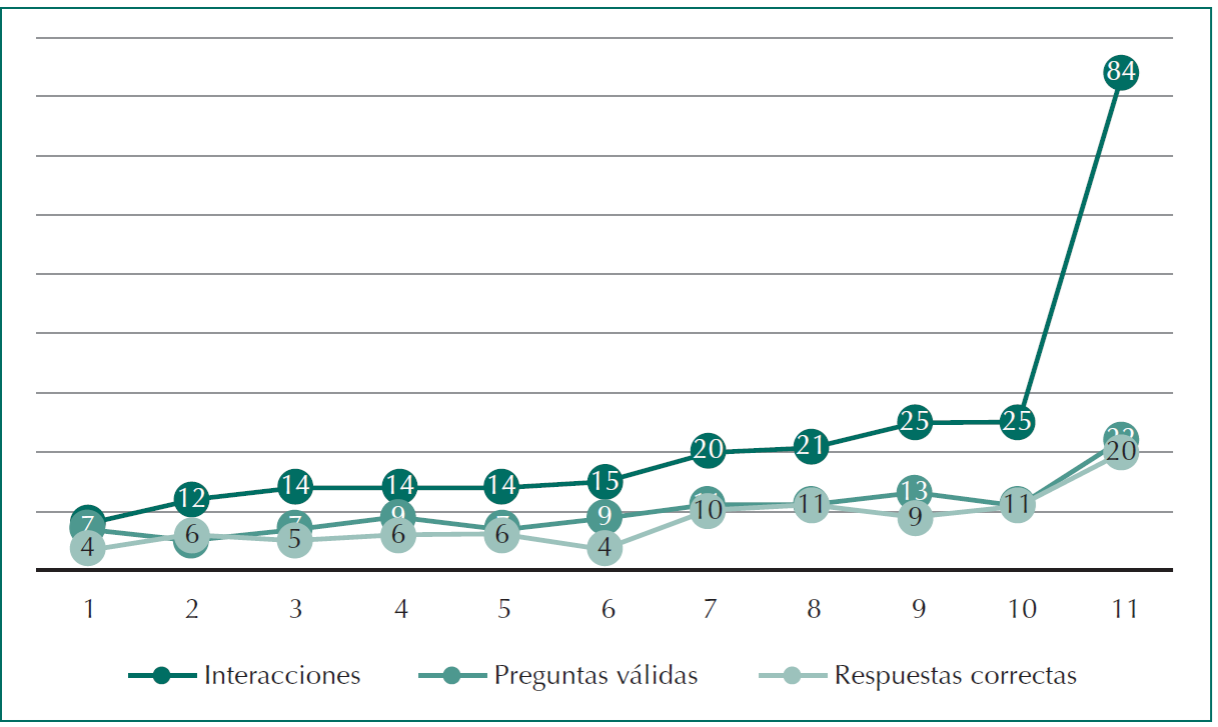
Figura 6 Interacción de las 11 personas con el sistema MITS en términos del total de interacciones realizadas, preguntas consideradas válidas y preguntas respondidas correctamente por el tutor.
Entre las preguntas que las personas realizaron fuera del dominio de conocimiento del sistema se encontraron cuatro categorías diferentes:
1. Creación y diseño (33.57%): las personas preguntaron acerca de las formas de crear elementos y actividades dentro del sistema, así como la manera adecuada de diseñarlas. Un ejemplo de pregunta de esta categoría es: “¿cómo diseño una tarea?”
2. Recursos y opciones (19.29%): las personas preguntaron acerca de recursos que pudiera contener el sistema relacionados a la creación de los elementos en el sistema MOODLE, así como opciones específicas de las herramientas. También solicitaron asesoría para la creación de sus propios recursos de aprendizaje. Un ejemplo de pregunta de esta categoría es: “¿cuáles son los pasos para diseñar un recurso educativo?”
3. Edición de actividades (10.71%): las personas preguntaron acerca de las formas para realizar la edición de actividades del sistema. Una pregunta de ejemplo es “¿qué hace ‘activar edición’?”
4. Opciones varias (36.43%): las personas realizaron preguntas de variada naturaleza incluyendo herramientas no consideradas en el dominio de conocimiento del sistema como rúbrica y libro de calificaciones. Además, las personas hicieron consultas para verificar si el sistema podía realizar análisis de sus cursos. Como ejemplo de una pregunta de esta categoría podemos citar “¿Qué hay programado en el curso de prueba MITS?”
A partir de los resultados presentados, se observa que la creación y diseño de actividades es un tema de interés común entre las personas que participaron en el experimento.
En cuanto a la escala SUS se alcanzó validez experimental debido a que se desarrolló el experimento utilizando el número de personas adecuado según la literatura. A continuación, se muestra una gráfica donde se aprecian las calificaciones obtenidas como resultado de la evaluación hecha por las personas con relación a la usabilidad percibida según la encuesta SUS, cabe mencionar que los resultados están en porcentajes siendo 0 el menor y 100 el mayor (Figura 7).
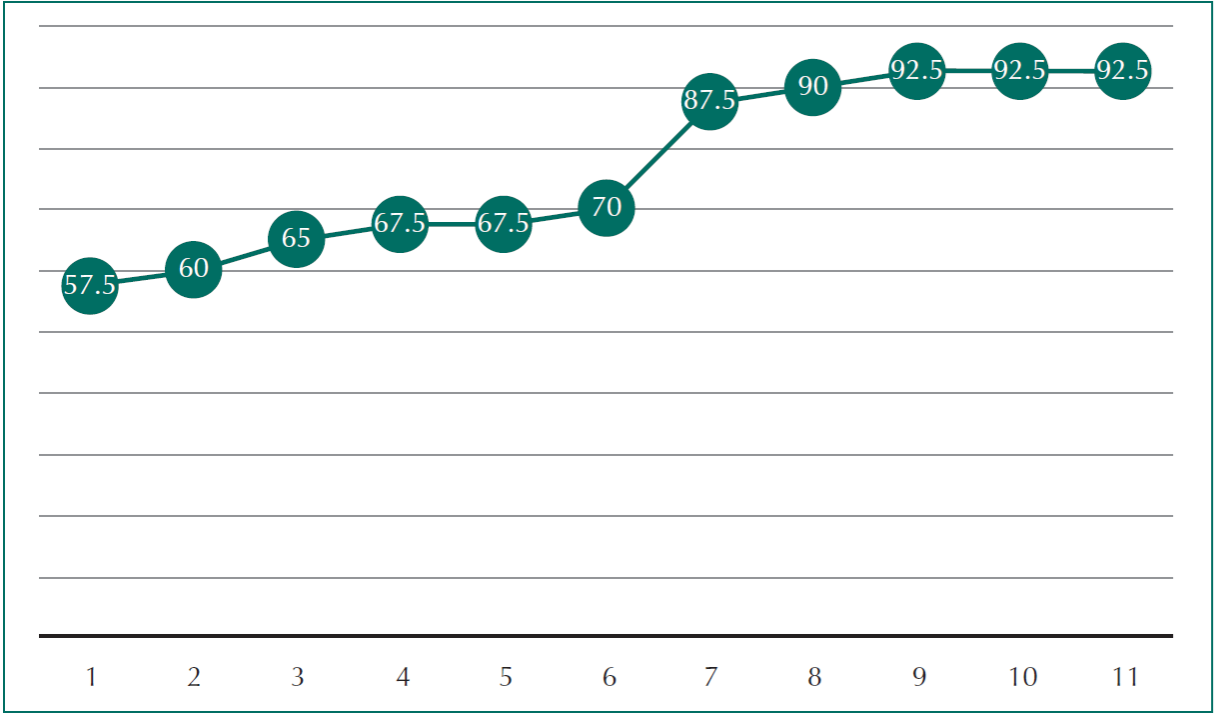
Promediando los resultados de la evaluación se tiene una calificación de 76.59 (Tabla 4), lo cual indica una usabilidad aceptable del sistema considerando a todos las personas en su conjunto. Cabe destacar la polarización entre los participantes debido a que 5 personas (45%) calificaron al sistema MITS con valores mayores a 85 en la escala, indicando una usabilidad excelente. Sin embargo, el 18% (2 personas) indicaron que la usabilidad percibida estaba por debajo de 65, lo cual influyó para que el sistema no fuera considerado con una usabilidad excelente en promedio.
Tabla 4 Estadísticas básicas de SUS con el sistema MITS.
| Medida | Valor |
|---|---|
| Media | 76.59 |
| Mediana | 70 |
| Desviación estándar | 14.29 |
| Máximo | 92.5 |
| Mínimo | 57.5 |
Tabla 5 Distribución de las respuestas de las personas en la encuesta SUS.
| Reactivos SUS | Valores | ||||
|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |
| Creo que me gustaría utilizar este sistema frecuentemente. | 64% | 36% | |||
| Encuentro este sistema innecesariamente complejo. | 27% | 55% | 9% | 9% | |
| Pienso que el sistema es fácil de usar. | 9% | 55% | 36% | ||
| Creo que necesitaría soporte técnico para hacer uso del sistema. | 45% | 10% | 18% | 27% | |
| Encuentro las diversas funciones del sistema bastante bien integradas. | 10% | 36% | 36% | 18% | |
| He encontrado demasiada inconsistencia en este sistema. | 36% | 27% | 27% | 10% | |
| Creo que la mayoría de la gente aprendería a hacer uso del sistema rápidamente. | 27% | 18% | 55% | ||
| He encontrado el sistema bastante incómodo de usar. | 45% | 45% | 10% | ||
| Me he sentido muy seguro haciendo uso del sistema. | 28% | 36% | 36% | ||
| Necesitaría aprender muchas cosas antes de manejar el sistema. | 55% | 18% | 18% | 9% | |
Un análisis de correlación entre las evaluaciones SUS obtenidas y las interacciones de las personas encontró una alta correspondencia positiva (r= 0.558 para SUS-interacciones; r= 0.583 para SUS-preguntas válidas; r= 0,695 para SUS-respuestas correctas), lo que se considera que explica los resultados obtenidos: a mayor interacción, pero especialmente a mayor número de respuestas correctas que proporcione el tutor, éste mejor será evaluado.
Un análisis a detalle de cada reactivo permite identificar claramente que el 64% de las personas está de acuerdo en utilizar frecuentemente el tutor y el 55% consideran que el sistema no es muy complejo y es fácil de usar. El 45% de los participantes cree que no necesitaría soporte técnico, además que tienen la percepción de que las funciones del sistema están bien integradas (72%) lo que hace que no haya inconsistencias en su utilización (36%). El 55% de las personas está completamente de acuerdo en que aprender a utilizar el tutor fue rápido y está en desacuerdo que resulte incómodo en utilizar (90%). El 72% de los usuarios se ha sentido seguro utilizando el sistema MITS y no considera que necesite aprender muchas cosas antes de usarlo (55%).
En cuanto al reactivo positivo con mayor calificación (4.64%) fue “creo que me gustaría usar este sistema frecuentemente”. En contraste, el reactivo negativo con la mayor puntuación corresponde a “creo que necesitaría soporte técnico para utilizar este sistema” (4.27%). De lo anterior podemos concluir que el sistema presenta un alto grado de involucramiento por parte del usuario al fomentar el uso frecuente del sistema. Sin embargo, es necesario trabajar con la confianza del usuario en el sistema de manera que no necesiten de soporte técnico para interactuar con MITS.
Los resultados muestran una capacidad de respuesta a las preguntas del usuario con un porcentaje elevado considerando que la interacción se dejó libre para los usuarios. Los errores de clasificación que tuvo el sistema, en los casos en los que las preguntas del usuario si pertenecían a su dominio de conocimiento, obedecen a variantes no consideradas en la forma de expresar las intenciones por parte del usuario, se pueden corregir fácilmente enriqueciendo el léxico y las expresiones de las intenciones del agente conversacional.
Otro punto interesante es el hecho de observar qué tipo de interacción esperan los usuarios de un ITS para asistir al profesor en el uso de las herramientas de MOODLE, reflejado en aquellas preguntas que no se consideraron en el dominio del conocimiento inicial del sistema. Estos temas se pueden incorporar fácilmente mediante la captura y retroalimentación de dicha información en la base de conocimiento del sistema.
Al finalizar la experimentación se realizó una entrevista con los usuarios, quienes destacaron como factores positivos la facilidad de uso del sistema, la capacidad de reconocer variantes de lenguaje y la ventaja que ofrece al estar integrado en el entorno del sistema MOODLE. Las áreas de mejora que expresaron giraron en torno a hacer más llamativa la interfaz del usuario, por medio de la inclusión de avatares, un ícono que representa a un usuario o algo que lo describa o referencia. El hecho de incorporar contenidos más complejos que los ofrecidos por las diferentes ayudas del sistema MOODLE. De igual manera, se sugirió dotar al sistema de la capacidad de revisar el contenido de los cursos para informar al profesor sobre el mismo, así como diversos aspectos, tales como: tareas entregadas y en general, consultas acerca de sus cursos en línea.
Limitaciones
Cualquier experimento se enfrenta a ciertas limitaciones y amenazas de validez, que se deben tener en cuenta a fin de comprender en qué medida los resultados son válidos y en qué medida pueden ser usados. A continuación se describen las estrategias llevadas a cabo para minimizar las amenazas a la validez de acuerdo con Cook y Campbell (Aliaga, 2000):
► La participación de las personas de estudio fue voluntaria.
► No todas las personas estaban familiarizados con la actividad por lo que se les proporcionó un diseño instruccional para omitir esta parte debido a que no forma parte del experimento, y se les dio un curso, lo cual evitó en gran medida el desconocimiento del tratamiento.
► El instrumento fue revisado y aplicado a todos las personas con el fin de que los resultados observados puedan ser comparables.
► De manera general, las personas tienen los mismos perfiles y completaron en su totalidad el experimento, pero se observó que algunas personas estuvieron apáticos y mostraron poco interés y no estaban atentos a las instrucciones.
► La veracidad de las respuestas fue incentivada con el anonimato en el llenado del instrumento, para evitar que la persona coloque la respuesta que se desea obtener.
► El aspecto subjetivo de las respuestas de los participantes está presente, debido a que están basadas en sus percepciones acerca de la utilidad y facilidad de uso de la propuesta.
Sin embargo, de manera conservadora, los resultados del estudio pueden generalizarse a otras personas con caracteristicas similares a los participantes de este experimento.
Conclusiones
En esta propuesta se diseñó un marco metodológico y arquitectónico para el desarrollo de un sistema de tutoría inteligente integrado al entorno de un LMS denominado MITS. Dicho sistema fue evaluado tanto a través de pruebas automatizadas como con una muestra reducida de usuarios reales. De las experiencias obtenidas con el presente trabajo de investigación se resaltan los siguientes aspectos:
Se destaca que en el módulo para la obtención del perfil del usuario se utilizó un vector de características, generado a partir del uso de las herramientas del entorno de MOODLE por parte del usuario. Para su implementación se compararon las medidas de similitud de coseno suave y la diferencia promedio normalizada. Ambas estrategias tuvieron un desempeño de clasificación de alrededor del 90% comparado con un humano experto, siendo ligeramente mejor en la clasificación la similitud de coseno suave. Lo anterior verifica que la estrategia utilizada es viable para la clasificación de usuarios de acuerdo a perfiles previamente proporcionados al sistema.
En cuanto al módulo de agente conversacional, se implementó utilizando coincidencia de patrones mediante una medida de similitud de cadena basada en la distancia de Levenshtein normalizada (Yujian y Bo, 2007), donde se obtuvo un 82.14% de eficiencia en la clasificación de intenciones y entidades cuando las preguntas realizadas por el usuario se circunscriben a la base de conocimientos del sistema. El margen de error se originó por expresiones y ejemplos de intenciones y entidades que no habían sido cargados en el sistema al momento de la prueba, sin embargo pueden ser añadidos fácilmente a la base de conocimientos del sistema, lo cual presenta una poderosa ventaja en cuanto a la facilidad de extender el dominio de conocimiento, en comparación a otros agentes conversacionales de reconocimiento de patrones desarrollados con AIML, puesto que no requiere de un humano experto en el manejo de secuencia de comandos para añadir conocimiento al chatbot.
Otro elemento que destacó es la estrategia de búsqueda de patrones sintácticos implementada, la cual resultó con un excelente desempeño y en general la implementación del agente conversacional resultó exitosa y fácilmente extensible. Un aspecto destacable es el módulo de tutoría híbrido, el cual se probó desde la perspectiva de los usuarios, quienes solicitaron la extensión de los contenidos del sistema, así como la posibilidad de conectarse a bases de información para mejorar sus técnicas de inferencia. Las características de mayor relevancia son la facilidad de uso del sistema y que los usuarios consideraron que puede resultar en una herramienta útil tanto para la formación de profesores como para la interacción con sus cursos y tareas dentro del entorno de MOODLE. Finalmente, se destaca que el sistema obtuvo un desempeño aceptable en la escala SUS, indicando que puede ser adoptado fácilmente por una gran cantidad de usuarios. En cuanto a las recomendaciones y trabajo a futuro se destacan los siguientes aspectos:
► Extender las pruebas con diferentes técnicas de tutoría. El marco arquitectónico desarrollado permite la implementación de módulos de manera independiente por lo que un estudio comparativo con diferentes técnicas de tutoría podría arrojar información relevante acerca de las mejores maneras de asistir al profesorado a través de un ITS.
► Adaptar el chatbot a diferentes dominios de conocimiento. La experimentación en estas circunstancias permitirá generalizar los resultados obtenidos en la presente investigación y verificar si la estrategia conversacional implementada puede ser extendida a diferentes materias.
► Verificar la personalización del aprendizaje con datos reales de los profesores. Esta investigación realizó la validación de la clasificación de los perfiles de usuarios utilizando información generada de manera automatizada. Sin embargo, la interacción con usuarios reales pudiera ayudar a corroborar los resultados de clasificación obtenidos mediante las pruebas automáticas.
► Automatizar el proceso de recolección de perfiles iniciales mediante técnicas de agrupamiento de aprendizaje automático. Actualmente los perfiles de los usuarios del sistema se alimentaron de manera manual lo cual requiere el proceso de adaptar los perfiles a la evolución del uso de la plataforma por parte de los profesores.
► Retroalimentación automática de las expresiones de intenciones y entidades del sistema, el cual podría mejorar su desempeño significativamente utilizando un proceso de retroalimentación, que permita incluir expresiones no cargadas en la base de conocimiento y utilizando las interacciones de los usuarios con el agente conversacional.
► Experimentar con diferentes medidas de similitud. La medida empleada en el sistema es sencilla y directa. Sin embargo, hay una gran cantidad de formas de calcular el perfil del usuario. Verificar varias técnicas en diferentes entornos resultaría útil para conocer en qué condiciones resulta mejor utilizar una técnica de clasificación sobre otra.

