











 nova página do texto(beta)
nova página do texto(beta) Inglês (pdf)
Inglês (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
Permalink1 Introduction
Multicriteria Decision Analysis (MCDA) provides a methodological framework for managing complex decision-making problems with multiple criteria in conflict. The purpose and scope of MCDA are to support decision-makers (DMs) while addressing complex decision-making problems.
The MCDA outranking approach involves ranking a set of alternatives in decreasing order of preferences. This is a multicriteria ranking problem, where there may be ties and incomparability among the alternatives [1, 2]. The ranking means a recommendation for the DM generated by the solution method.
The MCDA outranking methods combine the aggregation and exploitation phases. In the preference aggregation phase, the DM’s preference aggregation model is achieved, represented by an outranking relation, which usually does not present attractive mathematical properties such as transitivity and completeness [3].
In the exploitation phase, a partial preorder is deduced from the outranking relation, reflecting irreducible incomparability and indifference between the alternatives [4].
ELECTRE III [5] is a representative method of MCDA that constructs and exploits a fuzzy outranking relation.
The ELECTRE III method has been widely used to solve many real-world problems that can be formulated as multicriteria ranking problems. However, like any multicriteria method, it has weaknesses and limitations when using it for specific instances of the ranking problem. For example, ELECTRE III is inadequate regarding:
– Dealing with heterogeneous information: DMs must use numerical scales in ELECTRE III, which is inflexible as criteria can have varied descriptions and be assessed in different expression domains.
– Dealing with uncertainty: ELECTRE III cannot correctly handle the uncertainties and vagueness of subjective judgments.
This paper proposes an extension of the ELECTRE III method to reduce limitations in information management, incorporating a flexible heterogeneous evaluation structure in the decision criteria to analyze elements of uncertainty and vagueness that occur in many instances of the multicriteria ranking problem, which is more in line with the quantitative and qualitative essence of the decision criteria and with the experience of the DM.
The fusion linguistic approach converts heterogeneous information into a linguistic one [4, 5, 6]. The fusion approach for an MCDA method makes the computations possible and generates interpretable results [2]; however, it implies the need for utilizing Computing with Words (CW) procedures [7, 8].
Therefore, we employ the fuzzy linguistic approach based on the 2-tuple linguistic representation model [9, 10] and a linguistic-based distance measure [11, 12] to construct a fuzzy outranking relation in such a way that the DM can make his evaluations in different sets of linguistic terms according to his knowledge of the decision problem [6].
We consider a modified distillation procedure to derive a partial preorder of the alternatives for the exploitation phase of the fuzzy outranking relation based on 2-tuple linguistic representation modeling. This approach’s main advantage is tackling the uncertainty of criteria performances and DMs’ knowledge without losing information.
Thus, this new method will be helpful in multicriteria ranking problems whose DMs express their value judgments through heterogeneous values. In these kinds of issues, it is common for DMs to have different levels of knowledge and domains of the criteria.The organization for the rest of the document is presented as follows: Section 2 shows background about ELECTRE III and linguistic and heterogeneous information. Then, section 3 gives the linguistic ELECTRE III, and section 4 provides an illustrative example. Finally, section 5 points out the conclusions.
2 Background
This section briefly describes the ELECTRE III method and the use of linguistic and heterogeneous information in MCDA.
2.1 The ELECTRE III Method
The ELECTRE III method is a decision support technique under the category of outranking methods designed to solve problems involving multiple criteria [13, 14]. It is a multicriteria ranking method that is relatively simple in conception and application compared to other MCDA methods. It can be applied to situations where a finite set of alternatives must be prioritized, considering multiple, often contradictory, criteria (e.g. [15, 16]).
ELECTRE III needs a decision matrix with criteria evaluations for each alternative and preference information in the form of weights and thresholds. The model accounts for uncertainty in the assessments when defining the thresholds.
This method consists of two distinct stages. Initially, (i) it aggregates the input data to create a fuzzy outranking relation on the pairs of alternatives.
Subsequently, (ii) it exploits the fuzzy outranking relation to generate a partial preorder of alternatives [14]. Let us have the following notations:
The ELECTRE III method uses the fundamental principle of threshold values; an indifferent
And
The inclusion of the indifference threshold addresses the consideration of a DM’s sentiment toward practical comparisons of the alternatives. However, a marker still exists when a DM’s preference transitions from a state of indifference to a state of strict preference. Regarding conceptual understanding, it is beneficial to introduce a buffer region between indifference and strict preference.
This intermediary region represents a state where the DM hesitates over indifference and preference, known as a weak preference. Like the preference relations indifference (
The selection of thresholds significantly impacts the determination of specific binary relations. In [14, 17], detailed information is provided on how to compute thresholds in ELECTRE III, including their nature, meaning, and form.
We must acknowledge that we have solely examined the basic scenario where the thresholds
ELECTRE III uses these thresholds in the aggregation procedure to create the outranking relation
i)
There are two principles that ELECTRE III incorporates to validate
Let
The initial stage involves creating a concordance assessment, represented by the concordance index
where:
And:
where k=1,2 ,…, n.
The second stage involves creating the discordance index, which integrates the veto
where
Finally, both measures, concordance, and discordance, must be fused to make a metric that reflects the power of the affirmation
where
Equation 6 operates under the idea that if the magnitude of the concordance exceeds that of the discordance, there is no need to alter the concordance value. However, if this condition is not met, we must question the assertion
In the scenario where the discordance value is 1.0 for any
Based on Eq. 6, we can create a fuzzy outranking relation
However, due to space limitations, we will not elaborate on the details of this procedure here. Instead, in the following subsections, we introduce basic concepts of computers with words.
2.2 Linguistic Information and Management of Heterogeneous Information in MCDA
This section provides an overview of approaches to handling the three types of information in the heterogeneous framework. It introduces the 2-tuple linguistic representation model, which is appropriate for our problem because it enhances the interpretability of the MCDA process, which are the main required features of our proposal.
2.2.1 The Heterogeneous Framework
Here, the evaluation framework calculates a global evaluation that condenses the gathered information and gives helpful decision-making results.
The DM can naturally declare his preferences in different information domains and obtain a heterogeneous structure [18]. The following expression domains are used in the linguistic extension of the ELECTRE III method:
– Numerical values
– Interval values
– Linguistic values
Assessing qualitative criteria is familiar to them. The linguistic approach is appropriate for representing data through linguistic variables. [19, 20].
2.2.2 The 2-tuple Linguistic Representation Model
Handling heterogeneous information can be done using processes based on computing with words [20]. The models most frequently used for the treatment of heterogeneous information are:
The semantic model utilizes linguistic terms as labels to represent fuzzy numbers, while the computations are performed directly on the fuzzy numbers.
The symbolic model that utilizes an order index of the linguistic terms to perform direct calculations on the labels.
This research uses the symbolic model to calculate the linguistic evaluations in the ELECTRE III method, using the 2-tuple linguistic representation model developed by [11]. In the rest of this section, we present the basics of the 2-tuple linguistic representation model.
Definition 2.1. [4]. Let
Based on this meaning, a linguistic representation model must be built that denotes linguistic information using a 2-tuple
Definition 2.2. [4]. Let
where round
Let
Note that to transform a linguistic term into a linguistic 2-tuple, append a value
Example 1. Let us suppose a symbolic aggregation operator, ϕ(.) whose input are different labels assessed in S = {nothing; very low; low; medium; high; very high; perfect}, obtaining the following results:
ϕ (medium; medium; medium; very high) = 3:21 = β1
ϕ (low; medium; very low; high) = 2:76 = β2
Being β1=3:21 and β2=2:76, then the 2-tuple linguistic values (Definition 2.2) of these symbolic results, which do not match with any linguistic term in S, are:
∆S(3:21) = (s3;0:21) = (medium, 0.21).
The symbolic translation (definition 2.1) α is 0.21.
∆S(1:75) = (s3;- 0:24) = (medium,-0.24). The symbolic translation α is -0.24.
2.2.3 Aggregation of 2-tuples
This process involves obtaining a single value representing a set of values of the same type; therefore, adding a series of linguistic 2-tuples must be a linguistic 2-tuple.
In the literature, we can find various 2-tuple aggregation operators (e.g., [4]) based on the classical aggregation operators, such as the arithmetic mean and weighted mean operators.
Definition 2.3. Let
Definition 2.4. Let
2.3 The Linguistic Fusion Approach for Heterogeneous Information based on the 2-tuple Fuzzy Linguistic Model
The approach used in this section to fuse heterogeneous information based on the 2-tuple linguistic model considers various transformation functions that go from numerical, interval, and linguistic information sources toward a common linguistic format [21].
1 Choosing the basic linguistic term set (BLTS)
2 Transformation of the heterogeneous information into fuzzy sets in a linguistic domain:
Each input value
where
For
where:
For
where:
This information fusion process [13] is illustrated in Figure 1.
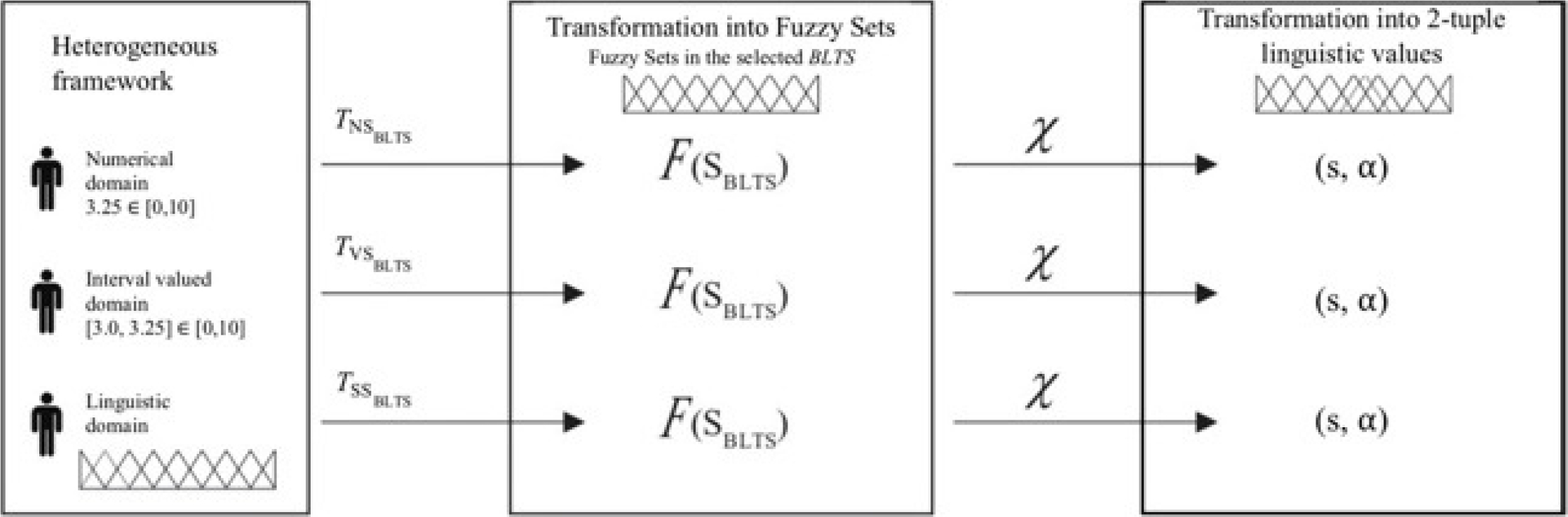
2.4 Transformation of Fuzzy Sets into Linguistic 2-tuple Values
Here, the fuzzy sets are converted into linguistic 2-tuples over the BLTS through the function
where
3 The Linguistic ELECTRE III Method
This section presents our proposal for the linguistic extension of the ELECTRE III model; to this end, a procedure is defined to model the partial and global concordance indices, the discordance indices by criterion, the thresholds of the criteria, and the credibility index linguistically so that they can accept 2-tuple linguistic values.
Consequently, the linguistic ELECTRE III method provides a more realistic operability of the qualitative criteria when solving multicriteria ranking problems.
Within this procedure, a linguistic difference function allows for the calculation of the linguistic difference for each pair of alternatives for each decision criterion. The linguistic output provided by the linguistic difference function serves as the linguistic input of the linguistic concordance and discordance indices for each criterion.
The output of the concordance and discordance indices are expressed in the same linguistic scale to preserve interpretability. Figure 2 schematically presents the process for modeling the linguistic outranking index in three phases.
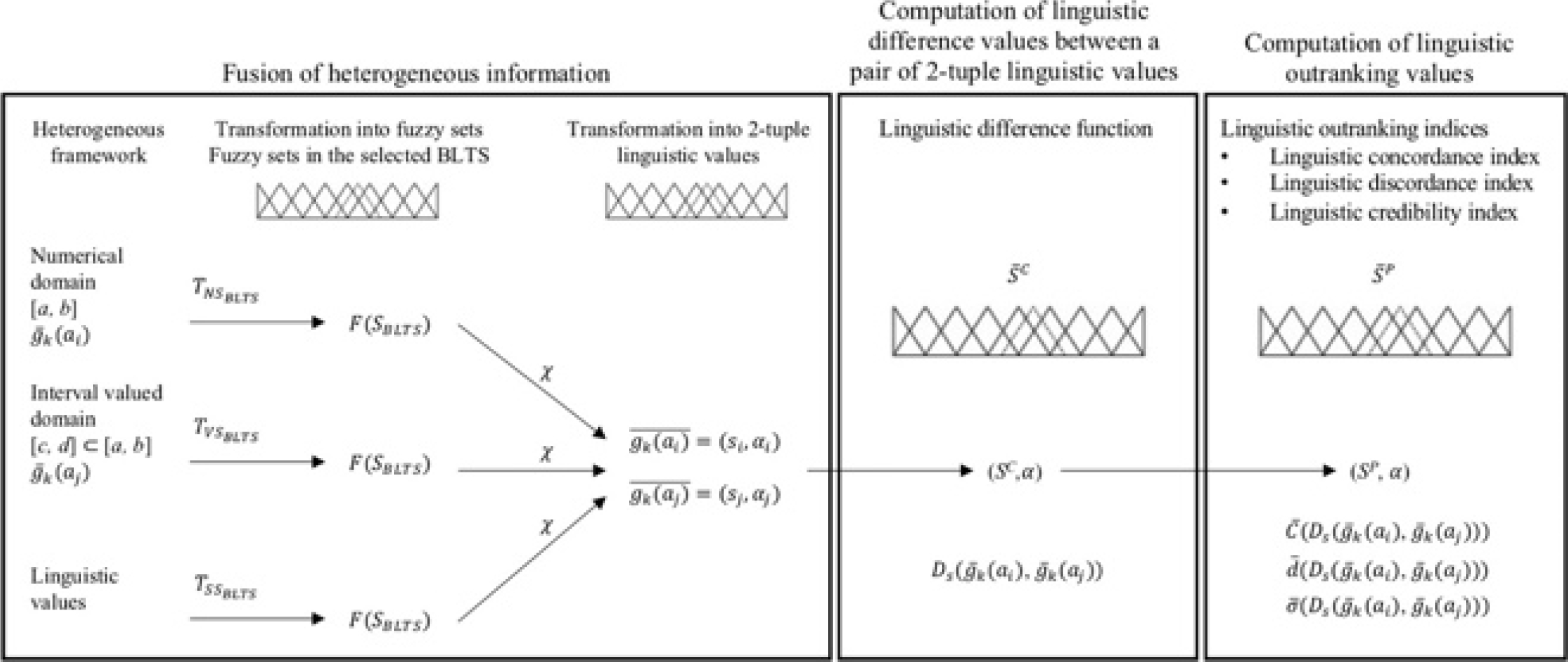
3.1 Fusion of Heterogeneous Information
In a multicriteria ranking problem with a heterogeneous information environment, alternatives are evaluated using diverse expression domains based on the uncertainty and criteria type, as well as each DM's experience.
3.1.1 Transformation into Fuzzy Sets
The expression domains (numerical, interval, and linguistic) used in the heterogeneous framework are presented in this part of the first phase. The fusion approach handles these three types of information.
Previously, a unification domain
3.1.2 Transformation into 2-tuples Linguistic Values
Then, the process transforms the fuzzy sets into 2-tuple linguistic values in
3.2 The Linguistic Difference Function
This function is introduced to facilitate the computation of the linguistic concordance and discordance indices because the input values of the indices and thresholds must be linguistic values for a correct interpretation.
To compare two linguistic values, we need a comparison scale that can measure the linguistic difference between them. The scale's granularity will depend on the decision maker's knowledge, who needs to interpret the difference between the two alternatives using a bipolar scale [23]. This type of scale is convenient because it has a neutral point, which separates the positive differences from the negative ones [5].
In short, this function's linguistic output is the input of the linguistic concordance and discordance indices. The linguistic difference function is expressed in the linguistic scale, and the threshold parameters are stated accordingly. Consequently, a proper linguistic difference function between linguistic preference values is necessary for developing an extension of ELECTRE III dealing with fuzzy linguistic information.
Definition 3.1. Let
The proposed linguistic difference function satisfies the following properties:
– The difference between the same value of
– The difference between the minimum (maximum) and maximum (minimum) values of
The proof of these properties is trivial. We propose the following syntax for
Example 2. In this example, we perform the linguistic difference of the 2-tuple linguistic values
With the linguistic terms
3.3 Linguistic Concordance and Discordance Indices
The linguistic concordance and discordance indices defined in this section have 2-tuple linguistic values as input and output.
3.3.1 The Linguistic Concordance Index
The linguistic concordance value of
where
Here,
The concordance index
The indifference and preference thresholds
Definition 3.2. The linguistic concordance index concerning a criterion
With
The concordance index
3.3.2 The Linguistic Discordance Index
For each criterion
It should be mentioned that any outranking of
So, if
Definition 3.3. The linguistic discordance index
with
3.4 The Linguistic Outranking Relation in the Linguistic ELECTRE III
The linguistic outranking relation
The linguistic credibility index is the comprehensive linguistic concordance index reduced by the linguistic discordance indices. In the nonappearance of such linguistic discordance criteria,
This linguistic credibility value is decreased in the occurrence of one or more linguistic discordant criteria
where:
The formula for determining the linguistic value of
3.5 The Ranking Algorithm in the Linguistic Extension of ELECTRE III
The second phase of the linguistic ELECTRE method is to exploit the linguistic outranking relation
In the descending distillation, the procedure ranks the alternatives from the best to the worst; on the contrary, in the ascending distillation, the process ranks the alternatives from the worst to the best.
In the following, we modify the distillation procedure of ELECTRE III. In the linguistic ELECTRE III distillation procedure, we state a set of linguistic credibility cutting levels
where
where
In the rest of this section, we explain the descending and ascending distillation algorithms in detail as follows: Let
qualification of alternative
Consequently, at the end of the
Let
The distillation process is condensed in the following way:
Set
Set:
Put
Choose the maximum value from the linguistic credibility scores that are less than
Calculate the
Obtain the maximum or minimum
Construct
If
else, do
Put
If
Otherwise, end of the distillation.
During the same distillations, when advancing from step
where
The analyst can fix one value for the distillation coefficients
We obtain two complete preorders at the end of the distillation procedure. In each preorder, the alternatives are regrouped in a partition of equivalence classes, forming a ranking from the best to the worst alternatives.
Each class includes at least one alternative. A partial preorder of the alternatives is constructed utilizing the intersection of both preorders, which specifies the comparisons between alternatives and emphasizes the possible incomparabilities as follows:
– Alternative
– Alternative
– Alternatives
To illustrate the proposed method, we present in the following section a step-by-step example of the linguistic ELECTRE III method for ranking a set of alternatives.
4 An Illustrative Example
We will use a case study from [25] to demonstrate the proposed approach. This case study is an Environmental Impact Significance Assessment problem in which heterogenous data (qualitative and quantitative judgments) obtained from a DM are used to determine the environmental impacts that a set of projects or industrial activities can have on a petrol station's usual operations.
This case study aims to evaluate seven ecological effects that can occur between the interactions of four industrial activities and four environmental factors in a petrol station. The evaluation seeks to rank the identified impacts from the most to the least significant. Each step of the linguistic extension of the ELECTRE III method is explained below.
Step 1. Formulation of the multicriteria ranking problem. Given a set of activities from a petrol station A = {
For convenience, we define EI =
Table 1 Criteria set description
| Name | Description | Expression Domain | |
| Intensity | How the action impacts the factor | Linguistic: L | |
| Extension | The range within which the action affects the site | Linguistic: L | |
| Moment | The duration from the action’s onset to the time the factor begins to be affected | Numerical: N | |
| Persistence | The estimated duration of the action’s effect | Valor Interval-valued: I | |
| Reversibility | The potential for the factor to be naturally restored to its original state after being affected | Numerical: N | |
| Synergy | The strengthening of straightforward impacts | Linguistic: L | |
| Accumulation | The gradual escalation in the expression of the effect | Linguistic: L | |
| Effect | How the action’s impact on an environmental factor becomes apparent | Linguistic: L | |
| Recoverability | The potential for the factor to be restored with the help of human action | Linguistic: L | |
| Periodicity | The consistency in which the impact on the environmental factor is observed | Linguistic: L |
The DM uses a linguistic domain with five linguistic terms denoted by
Step 2. Collecting the heterogeneous information: The DM assessed each criterion for each impact in EI using a heterogeneous framework. The expression domain used for each criterion was according to its nature; for criteria
Table 2 Assessment for each criterion on each EI using a heterogeneous framework
| L | L | 0,00 | [0,0.2] | 1,00 | L | L | L | H | VL | |
| H | VL | 0,00 | [0,0.2] | 1,00 | M | M | M | VH | VL | |
| H | L | 0,00 | [0.4,0.6] | 10,00 | M | L | VH | L | M | |
| M | VL | 0,10 | [0,0.2] | 2,00 | L | VL | VL | M | H | |
| H | L | 0,10 | [0,0.05] | 10,00 | M | M | VH | L | M | |
| VH | L | 0,00 | [0.8,1.0] | 10,00 | M | M | VH | L | H | |
| VL | L | 1,50 | [0.8,1.0] | 10,00 | VL | L | VL | L | VH |
Step 3. Fusion of the heterogeneous information: The chosen linguistic domain to fuse the information is
Table 3 Fused information supplied by the DM
| (L,0) | (L,0) | (VH,0) | (VL,0.44) | (VL,0.4) | (L,0) | (L,0) | (L,0) | (H,0) | (VL,0) | |
| (H,0) | (VL,0) | (VH,0) | (VL,0.44) | (VL,0.4) | (M,0) | (M,0) | (M,0) | (VH,0) | (VL,0) | |
| (H,0) | (L,0) | (VH,0) | (M,0) | (VH,0) | (M,0) | (L,0) | (VH,0) | (L,0) | (M,0) | |
| (M,0) | (VL,0) | (VH,-0.04) | (VL,0.44) | (L,-0.2) | (L,0) | (VL,0) | (VL,0) | (M,0) | (H,0) | |
| (H,0) | (L,0) | (VH,-0.04) | (VL,0.17) | (VH,0) | (M,0) | (M,0) | (VH,0) | (L,0) | (M,0) | |
| (VH,0) | (L,0) | (VH,0) | (VH,-0.44) | (VH,0) | (M,0) | (M,0) | (VH,0) | (L,0) | (H,0) | |
| (VL,0) | (L,0) | (H,0.4) | (VH,-0.44) | (VH,0) | (VL,0) | (L,0) | (VL,0) | (L,0) | (VH,0) |
Step 4. Computing linguistic difference values between unified assessments: The linguistic difference value between a pair of 2-tuple linguistic values is stated in the linguistic comparison scale
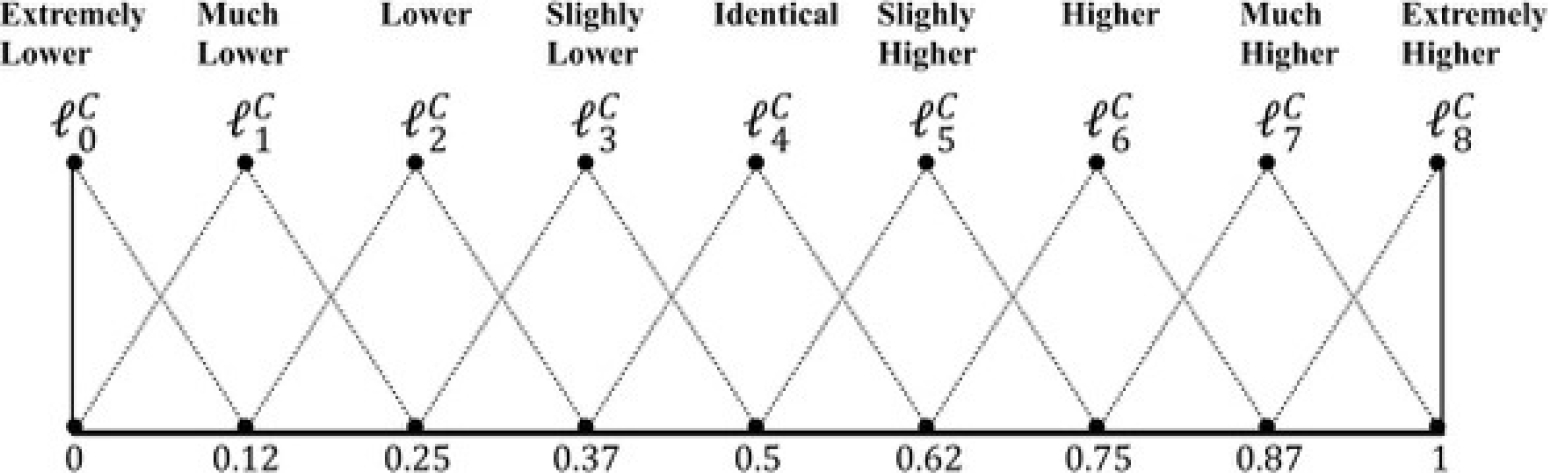
Step 5. Computing linguistic concordance values: Linguistic concordance index concerning a criterion
Calculations to get individual linguistic concordance values. Initially, the linguistic preference scale
Each linguistic concordance value for each alternative
The calculation of the linguistic outranking value for each criterion is given in a linguistic preference scale
Table 4 Indifference
| Criterion | |||
Example 3. Calculation of
Based on Eq. (31), since:
Then from interpolation, we calculate:
In this way, it is possible to get the linguistic concordance indices
For example, on the criterion
Table 5 Concordance indices on the criterion
The comprehensive linguistic concordance index
for the family of criteria. The value of
Proceeding in the same way, for all pairs of environmental impacts
Table 6 Comprehensive linguistic concordance matrix
Step 6. Computing linguistic discordance values d have been defined on criteria
Example 4. Calculation of
Since
In the same way, with this computation process, it is possible to obtain the linguistic discordance indices
Table 7 Linguistic discordance matrix on a criterion
Step 7. Computing the linguistic outranking relation. Based on the comprehensive linguistic concordance matrix and the partial linguistic discordance matrices, the value of
Since
For all pairs of alternatives representing the illustrative example, the linguistic credibility matrix or linguistic outranking matrix is obtained (see Table 8).
Table 8 Linguistic credibility matrix in the linguistic extension of the ELECTRE III
Step 8. Ranking of alternatives from the linguistic outranking relation
For illustration purposes, we describe the procedure followed to perform the first four descending distillations as follows:
Let:
With
Distillation 1.
Step 1: Let
Table 9 Crisp outranking relation
Table 10 Power, weakness, and qualification scores
The maximum
Distillation 2.
Step 1: Let
From this linguistic cutoff, we create the linguistic crisp outranking relation shown in Table 11. Then we calculate the
Table 11 Crisp outranking relation for iteration 1 in Distillation 2
| 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | |
| 1 | 0 | 0 | 1 | 0 | 1 | |
| 1 | 1 | 0 | 0 | 0 | 0 | |
| 1 | 0 | 0 | 1 | 0 | 0 | |
| 1 | 0 | 0 | 1 | 0 | 0 |
Table 12 Power, weakness, and qualification scores for iteration 1 in Distillation 2
Because
Distillation 3.
Iteration 1: Let
From this linguistic cutoff, we create the linguistic crisp outranking relation shown in Table 13. Then we calculate the
Table 13 Crisp outranking relation for iteration 1 in Distillation 3
| 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | |
| 1 | 1 | 0 | 0 | 0 | |
| 1 | 0 | 1 | 0 | 0 | |
| 1 | 0 | 1 | 0 | 0 |
Table 14 Power, weakness, and qualification scores for iteration 1 in Distillation 3
Iteration 2: Let
From this linguistic cutoff, we create the linguistic crisp outranking relation shown in Table 15. Then we calculate the
Table 15 Crisp outranking relation for iteration 2 in distillation 3
Table 16 Power, weakness, and qualification scores for iteration 2 in distillation 3
|
|
1 | 0 |
|
|
0 | 1 |
|
|
1 | -1 |
The maximum
Because
Distillation 4
Iteration 1: Let
Table 17 Crisp outranking relation for iteration 1 in distillation 4
| 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 0 | |
| 1 | 1 | 0 | 0 | |
| 1 | 0 | 1 | 0 |
Table 18 Power, weakness, and qualification scores for iteration 1 in distillation 4
The remaining steps for the next descending distillations and the ascending distillation steps are processed in the same way. After completing the descending and ascending distillations, we got two complete preorders whose intersection creates the final ranking of the alternatives.
Figure 4 depicts the two preorders (descending and ascending distillations) calculated with the distillation procedure. In the descending preorder (Fig 4. a), there is an equivalence class in the first rank with the environmental impacts
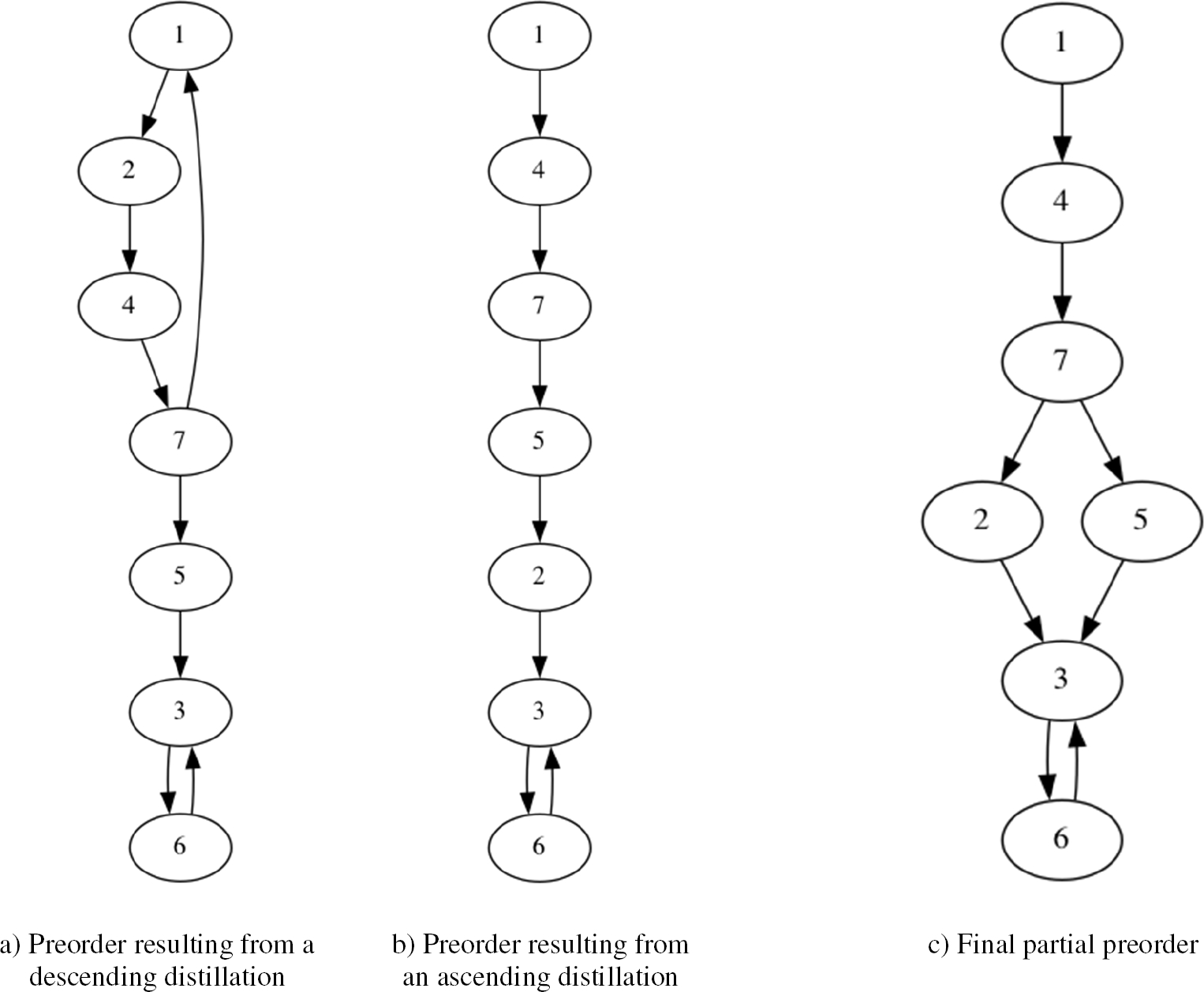
Figure 4. c depicts the final preorder resulting from the intersection of the two preorders.
The final partial preorder follows a decreasing order of preferences, meaning that environmental impacts at the top are more significant than those at the bottom.
Hence, the final rank suggests that the
5 Conclusions
This paper aimed to develop a linguistic extension of the ELECTRE III method that allows solving instances of the multicriteria ranking problem with input data defined in heterogeneous contexts.
The new proposal fuses the heterogeneous information into 2-tuple linguistic values, allowing the DM to provide their preferences using diverse expression domains, such as numerical domain, interval-valued domain, and linguistic domain, according to the nature and uncertainty of the decision criteria, and their level of knowledge and experience.
Consequently, the new method is appropriate to integrate quantitative and qualitative criteria and uncertain information into the elements of the multicriteria model. In the modeling process of the ELECTRE III linguistic method, concordance, discordance, and credibility indices are proposed to consider linguistic inputs and outputs. Also, a linguistic difference function is stated to compute the linguistic difference between a pair of 2-tuple linguistic values. The output of the linguistic difference function is the input of the linguistic concordance and discordance indices.
Therefore, the linguistic extension of the ELECTRE III method offers good quality interpretability and understanding throughout the decision-making process in instances of the multicriteria ranking problem where there is heterogeneous data, as demonstrated in the illustrative example presented in this document.
The proposed methodology is applicable to real-life situations that involve decision-making with multiple conflicting criteria. This methodology can be used for various purposes such as project selection, supplier selection, job candidate evaluation, product design, environmental policy, and more.
When making decisions in contexts that involve diverse perspectives or input data from various sources, applying the linguistic ELECTRE III method can significantly impact decision-making in business, government, or social environments. For example, it can enhance the consideration of decision-maker preferences, improve transparency and accountability, facilitate cross-sector collaboration, and enable adaptation to dynamic environments.
The linguistic ELECTRE III can help organizations and policymakers navigate complex situations, manage uncertainty, and make more informed and equitable decisions in various business, government, and social environments. It provides a systematic and structured approach to decision-making in diverse contexts.
Soon, we plan to develop a linguistic extension of the ELECTRE III method for a collaborative group of DMs, and a hierarchical linguistic extension of the ELECTRE III method. Also, it is contemplated to carry out more real-world applications of the multicriteria ranking problem using our proposal.

