











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introducción
Capsicum spp (chile) tiene diversos usos, se emplea como hortaliza, condimento, y colorante alimenticio (Aliaga y Vega 2018, Konishi et al. 2019), medicinal, valor nutrimental, e industrial (Haralayya y Asha 2017), además de su contenido en proteínas, vitaminas, fibra y elementos minerales (Bosland y Votava 2000, Adeyemo et al. 2023), también se recurre a él en ceremonias y rituales (Wijaya et al. 2020), es fuente de carotenoides (provitamina A), flavonoides, vitaminas E y C (Solomon et al. 2019). Actualmente, no hay acuerdo del número de especies que forman al género de la familia de las Solanáceas a nivel internacional. Por ejemplo, Basu y De (2003), consideran que las especies que pertenecen al chile son 20, por otro lado, Ahmad y Anjum (2022) reportan 25, en cambio, Aliaga y Vega (2018), y Harishkumar et al. (2020), mencionan 30, mientras que Carvalho et al. (2015) indican 35, pero Barboza et al. (2020a) sugieren que son aproximadamente 41, mientras que Barboza et al. (2020b) indican 42, en tanto que Terefe et al. (2022) refieren que las especies que conforman el género Capsicum son 38. Pero, en lo que si hay coincidencia es en que Capsicum annuum L., C. pubescens L., C. chinense Jacq., C. frutescens L., y C. baccatum L., son las especies que se cultivan en todo el mundo (Bosland y Votava 2000, Mimura et al. 2012), y C. assamicum es una especie que ha sido identificada y se cultiva en la India (Chhapekar et al. 2016).
En los últimos años la diversidad genética de cultivos de importancia como el chile se ha estimado con marcadores moleculares, entre ellos, el de secuencias simples repetidas (SSRs) o microsatélites, los cuales son de los más empleados (Xiao-min et al. 2016, Meng et al. 2017). Ello se debe a que los SSRs son mucho más eficientes que otros marcadores moleculares como, por ejemplo: los de Polimorfismo en longitud de los fragmentos amplificados (AFLP), el de Amplificación aleatoria del ADN polimórfico (RAPDs), el Polimorfismo en longitud de los fragmentos de restricción (RFLP), las Inter-Simples Secuencias Repetidas (ISSR), o los de Polimorfismo de base única (SNP) (Islam et al. 2016, Taranto et al. 2016, Igwe et al. 2019).
En el sureste de la república Mexicana, el chile (Capsicum spp.) tiene gran importancia tanto cultural como económica. Por ello, el objetivo de esta investigación fue analizar la diversidad y estructura genética, mediante marcadores de secuencias simples repetidas (SSRs) para determinar la posible similitud y grado de parentesco entre las poblaciones de chiles silvestres de C. annuum L. y C. frutescens L. colectadas en diferentes localidades de seis regiones de Tabasco y norte de Chiapas.
Materiales y métodos
Colecta de material vegetal
Las 26 colecciones o poblaciones silvestres de Capsicum spp., empleadas en el presente estudio, fueron recolectadas de distintas localidades pertenecientes a seis regiones de dos estados (Tabasco y norte de Chiapas) del Sursureste de la república Mexicana (Tabla 1). Para la germinación de las colectas, correspondientes a las distintas poblaciones de Capsicum spp. se emplearon charolas de plástico de 200 cavidades, mismas que con antelación fueron desinfestadas usando cloro 5%, como sustrato para germinación se empleó Peat-moss de la marca Cosmopeat, en el cual se sembró una sola semilla por cavidad. Una vez que la siembra de las poblaciones a evaluar finalizó, las charolas se colocaron en invernadero con malla antiáfidos que está ubicado en la División Académica de Ciencias Biológicas (DACBiol) de la Universidad Juárez Autónoma de Tabasco. Según Ruíz-Álvarez et al. (2012), la DACBiol se localiza en los 17° 59’ 16.30’’ LN y 92° 58’ 11.65’’ LO y 9 msnm (metros sobre el nivel del mar), el clima del sitio experimental es cálido y húmedo, con lluvias intensas durante el verano y la temperatura media anual se sitúa alrededor de los 27 °C.
Tabla 1 Origen de las 26 poblaciones silvestres de Capsicum spp., evaluadas con marcadores secuencia simples repetidas (SSR).
| Región | Nombre | Acrónimo | Sitio de colecta |
|---|---|---|---|
| Norte | Garbanzo-Pico de Paloma | GaPPN | Macayo, Chiapas |
| Pico de Paloma Blanco | PPBN | Macayo, Chiapas | |
| Amashito Grande | AmGN | Macayo, Chiapas | |
| Sierra | Ojo de Sapo | OSS | Tapijulapa, Tabasco |
| Amashito | AmS | Tapijulapa, Tabasco | |
| Pico de Paloma | PPS | Tapijulapa, Tabasco | |
| Ojo de Cangrejo | OCS | Teapa, Tabasco | |
| Chontalpa | Garbanzo | GaCH | Cucuyulapa, Tabasco |
| Amashito Blanco | AmBCH | Miahuatlán, Tabasco | |
| Pico de Paloma | PPCH | Miahuatlán, Tabasco | |
| Habanero-Pico de Paloma | HaPPCH | Miahuatlán, Tabasco | |
| Centro | Amashito | AmC | DACBiol, Tabasco |
| Amashito Parecido | AmPC | González 1ª Secc., Tabasco | |
| Corazón de Gallina | CGC | Buenavista 3ª. Secc, Tabasco | |
| Ríos | Tabaquero-Pico de Paloma | TaPPR | Acatipa, Tabasco |
| Amashito | AmR | Acatipa, Tabasco | |
| Bolita de Gato | BoGR | Acatipa, Tabasco | |
| Pico de Paloma Blanco | PPBR | Acatipa, Tabasco | |
| Amashito Cruza | AmCR | Acatipa, Tabasco | |
| Pico de Paloma Cruza | PPCR | Acatipa, Tabasco | |
| Garbanzo | GaR | Acatipa, Tabasco | |
| Pantanos | Pico de Paloma Blanco | PPBP | Corralillo, Tabasco |
| Garbanzo | GaP | Bonanza 2a. Sección, Tabasco | |
| Garbanzo Blanco | GaBP | Ra. El Porvenir, Tabasco | |
| Amashito | AmP | Ra. El Porvenir, Tabasco | |
| Pico de Paloma Delgado | PPDP | Ra. El Porvenir, Tabasco |
Extracción de ADN de las poblaciones evaluadas
A los 40 días después de haber realizado la siembra de las poblaciones, se seleccionaron 10 plantas de cada población, y se cortaron dos hojas jóvenes de cada una de las plantas seleccionadas. El total de hojas (20) de cada población se mezclaron y de la mezcla se tomó tres repeticiones (muestras) de follaje fresco de 0.5 g cada una. La trituración de las muestras se realizó en mortero de porcelana con pistilo y nitrógeno líquido. El ADN de las muestras de cada población se extrajo mediante el uso del KIT comercial Wizard Genomic DNA Purification® (Promega), y con el procedimiento de Dellaporta et al. (1983).
Marcadores moleculares evaluados
Los cuatro marcadores de secuencias simples repetidas (SSRs) empleados en el estudio se presentan en la Tabla 2. La amplificación del ADN de las poblaciones evaluadas se realizó mediante una PCR múltiple en mezcla de reacción ajustada a un volumen final de 25 μL, que contenía H2O libre de Nucleasas (16.3 μL), primer´s sentido (0.5 μL a 10 mM), primer´s reverso (0.5 μL a 10 mM), dNTPs (0.5 μL a 10 mM), 5X Green buffer (5 μL), Taq polimerasa (0.125 unidades/μL) y 2 μL de ADN a 30 ng/mL. La amplificación del ADN mediante PCR se llevó a cabo utilizando un ciclo de desnaturalización inicial de 4 minutos a 94 °C, seguido de 35 ciclos consistieron en 1 minuto a 94 °C, 1 minuto a 65 °C, 2 minutos a 72 °C. Finalmente, se realizó una extensión de 12 minutos a 72 °C. Para evaluar la cantidad y calidad del ADN obtenido, se utilizó geles de agarosa al 1.2%, empleando una solución amortiguadora de ácido bórico de sodio 1X (solución SB) como medio conductor para la electroforesis de ADN, de acuerdo con los métodos descritos por Brody y Kern (2004).
Tabla 2 Lista y descripción de los cuatro locus usados para caracterizar molecularmente las poblaciones de Capsicum spp., de Tabasco y norte de Chiapas, México.
| Locus | Unidad repetitiva | Iniciador | Tamaño (Pb) | Tm (oC) |
|---|---|---|---|---|
| HpmsCaSIG19 | (CT)6 (AT)8 (GTAT)5 | D-HEXcatgaatttcgtcttgaaggtccc | 216-223 | 54 |
| R-aagggtgtatcgtacgcagcctta | ||||
| Hpms1-106 | (AAAAAT)4 | D-HEXtccaaactacaagcctgcctaacc | 158-164 | 53 |
| R-ttttgcattattgagtcccacagc | ||||
| Hpms1-143 | (AG)12 | D-6FAMaatgctgagctggcaaggaaag | 220-232 | 53 |
| R-tgaaggcagtaggtggggagtg | ||||
| Hpms1-274 | (GTT)7 | D-HEX-tcccagacccctcgtgatag | 162-180 | 56 |
| R-tcctgctccttccacaactg |
PCR, electroforesis e identificación de bandas
Corroborada la correspondencia en cuanto al tamaño esperado del amplicón en cada uno de los productos de PCR, se colocaron en geles de agarosa al 1.2% donde se les aplicó 160 voltios (V) con intensidad de 50 miliamperes (mA) durante 100 minutos. El teñido de los geles fue Bromuro de etidio (Sambrook et al., 1989). Posterior a ello, en un transiluminador de luz ultravioleta (UV), los geles se visualizaron. El peso molecular de los fragmentos de ADN obtenidos se visualizó con la ayuda de un marcador de 100-1 000 pares de bases ADN Ladder (PROMEGA). La cuantificación de las bandas obtenidas se realizó de forma visual, mediante una escala binaria de presencia (1) y ausencia (0), y se generó una matriz de 1 y 0 para cada uno de los marcadores usados.
Análisis estadístico de los datos
Las distancias genéticas entre las poblaciones evaluadas se calcularon de acuerdo con la matriz binaria 1/0, donde 1 corresponde a presencia y 0 a ausencia de un alelo en un locus. Para realizar el (AMOVA) análisis de varianza molecular, se usó GenAlEx V6.5 (Peakall y Smouse 2012). La variabilidad genética entre regiones, entre poblaciones y dentro de poblaciones se estimó con el AMOVA (Balzarini et al., 2010). Los índices o estadísticos de fijación PhiRT, PhiPR y PhiPT (similar a FST), se calcularon según lo muestra Wright (1965), con estos análisis se determinó la estructura genética de las poblaciones objeto del presente estudio. La estimación de la relación filogenética entre las poblaciones se llevó a cabo con SAS OnDemand for Academics (SAS 2024). El clúster o dendrograma de las poblaciones estudiadas se realizó mediante el método UPGMA (método de ligamiento completo por agrupamiento de promedios aritméticos no ponderados por sus siglas en inglés) con distancia Euclidiana.
Con la ayuda del software Structure 2.3.4 (Pritchard et al. 2012), se generó un análisis de inferencia bayesiana, donde se asumieron 26 poblaciones con parámetros de 450 000 periodos de rodaje ‘burn in periods’, y 400 000 repeticiones de Cadenas de Markov-Monte Carlo (MCMC), lo anterior con base en lo propuesto por Sung-Chur (2013), para obtener el valor de deltaK (ΔK) óptimo que represente el número de poblaciones diferenciadas de Capsicum spp., después de los periodos de rodaje ‘burn in periods’, con un modelo de coancestría mezclado y frecuencia de alelos correlacionados, el número de poblaciones óptimo se estimó con el software en línea Structure Harvester (Earl y vonHoldt 2012).
Resultados
Los marcadores microsatélites usados en la presente investigación identificaron 278 alelos, 92 (33.1%) de ellos fueron polimórficos. El oligonucleótido HpmsCa19 amplificó 97 alelos (mayor número), mientras que el marcador Hpms1-274 amplificó 53 alelos (menor número). El promedio de bandas por primer o marcador fue de 69.5.
El AMOVA (análisis molecular de varianza) de las colectas o poblaciones silvestres de Capsicum spp. (annumm L., y frutescens L.), coleccionadas en seis regiones en Tabasco y norte de Chiapas, detectó (Tabla 3), una mayor variación dentro de poblaciones (70.51%) que entre poblaciones (27.12%), y regiones (11.16%). El mayor porcentaje de variaciones dentro de poblaciones pone de manifiesto que el chile no es totalmente una planta autógama como se le ha clasificado.
Tabla 3 Análisis molecular de varianza de las poblaciones de C. annuum y C. frutescens colectadas en los estados de Tabasco y norte de Chiapas, México, y evaluadas con cuatro marcadores de secuencias simples repetidas (SSR).
| FV | Gl | SC | CM | VarEst. | %VarEst. |
|---|---|---|---|---|---|
| Regiones | 5 | 17.636 | 3.527 | 0.112 | 11.16 |
| Poblaciones/Regiones | 20 | 30.377 | 1.519 | 0.271 | 27.12 |
| Dentro/Poblaciones/Regiones | 52 | 36.667 | 0.705 | 0.705 | 70.51 |
| Total | 77 | 84.679 | 100 | ||
| Índices de Fijación | Valor | ||||
| PhiRT | 0.103* | ||||
| PhiPR | 0.278* | ||||
| PhiPT | 0.352* |
FV = Fuente de variación, Gl = Grados de libertad, SC = Suma de cuadrados, CM = Cuadrados medios, VarEst = Varianza estimada, %VarEst = Porciento de varianza estimada, PhiRT = Deficiencia o exceso de heterocigotes, PhiPR = Deficiencia o exceso de heterocigotes promedio en un grupo de poblaciones, PhiPT = Índice de fijación.
La Figura 1 muestra los resultados del análisis de conglomerados (clúster), y a una distancia Euclidiana de 11 (once), las poblaciones evaluadas formaron cinco conglomerados o clústers. El conglomerado o clúster I (CI) se formó por seis poblaciones, cuatro de ellas (PPBR; AmCR, AmR, BoGR) de la región de los Ríos, y dos (OSS y PPS) de la Sierra. La población OCS (Ojo de Cangrejo Sierra), formo el clúster II. La separación de esta población con las demás poblaciones se debe a que morfológicamente es diferente, principalmente en el fruto que es pequeño y con punta definida, y una mancha morada, que le da la apariencia de ojito de cangrejo. Esta coloración la presenta el fruto sin influir el ambiente en que se desarrolle la planta (sombra o sol). Actualmente, es muy poco frecuente encontrarlo actualmente en el área estudiada. El CIII fue formado por las poblaciones: AmS-Amashito Sierra, GaCH-Garbanzo Chontalpa, y TaPPR-Tabaquero Pico de Paloma Ríos.
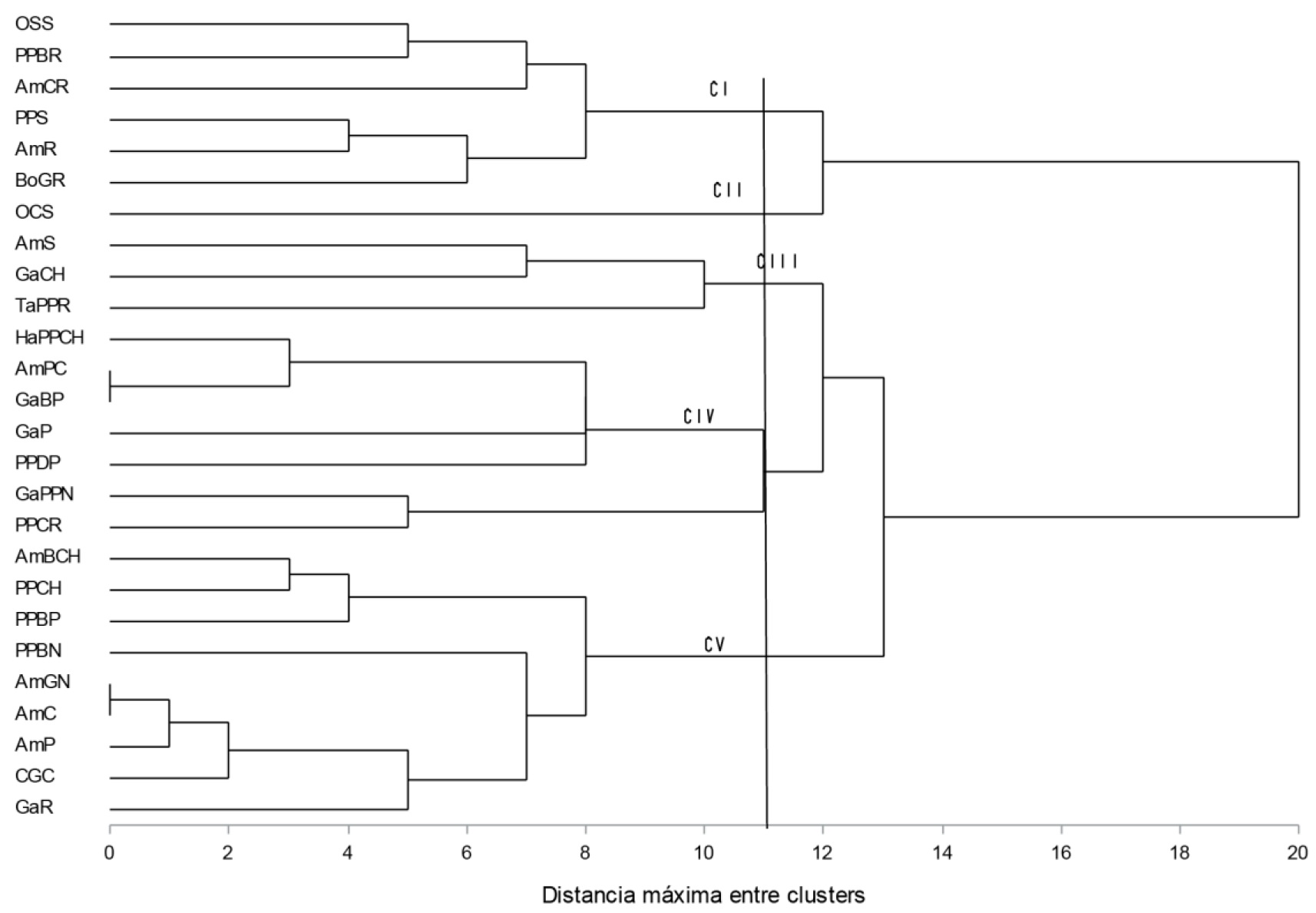
Figura 1 Dendrograma de 26 poblaciones de Capsicum spp. realizado con la distancia Euclidiana y el método de ligamiento completo por agrupamiento de promedios aritméticos no ponderados UPGMA (Unweighted pair group method with arithmetic mean), obtenidos a partir de los datos generados por PCR y visualizados en gel de agarosa al 1.2%.
Los clústers IV y V, fueron los que agruparon al mayor número de poblaciones, el CIV se formó por siete poblaciones, tres del tipo Garbanzo (GaBP,-Garbanzo Blanco Pantanos, GaP-Garbanzo Pantanos, GaPPN-Garbanzo Pico de Paloma Norte) y las otras cuatro fueron PPCR-Pico de Paloma Cruza Ríos, AmPC-Amashito Parecido Centro, HaPPCh-Habanero Pico de Paloma Chontalpa, y PPDP-Pico de Paloma Delgado Pantanos. Y el CV (clúster V) por nueve poblaciones (AmBCH-Amashito Blanco Chontalpa, PPCH-Pico de Paloma Chontalpa, PPBP-Pico de Paloma Blanco Pantanos, PPBN-Pico de Paloma Blanco Norte, AmGN-Amashito Grande Norte, AmC-Amashito Centro, AmP-Amashito Pantanos, CGC-Corazón de Gallina Centro, GaR-Garbanzo Ríos).
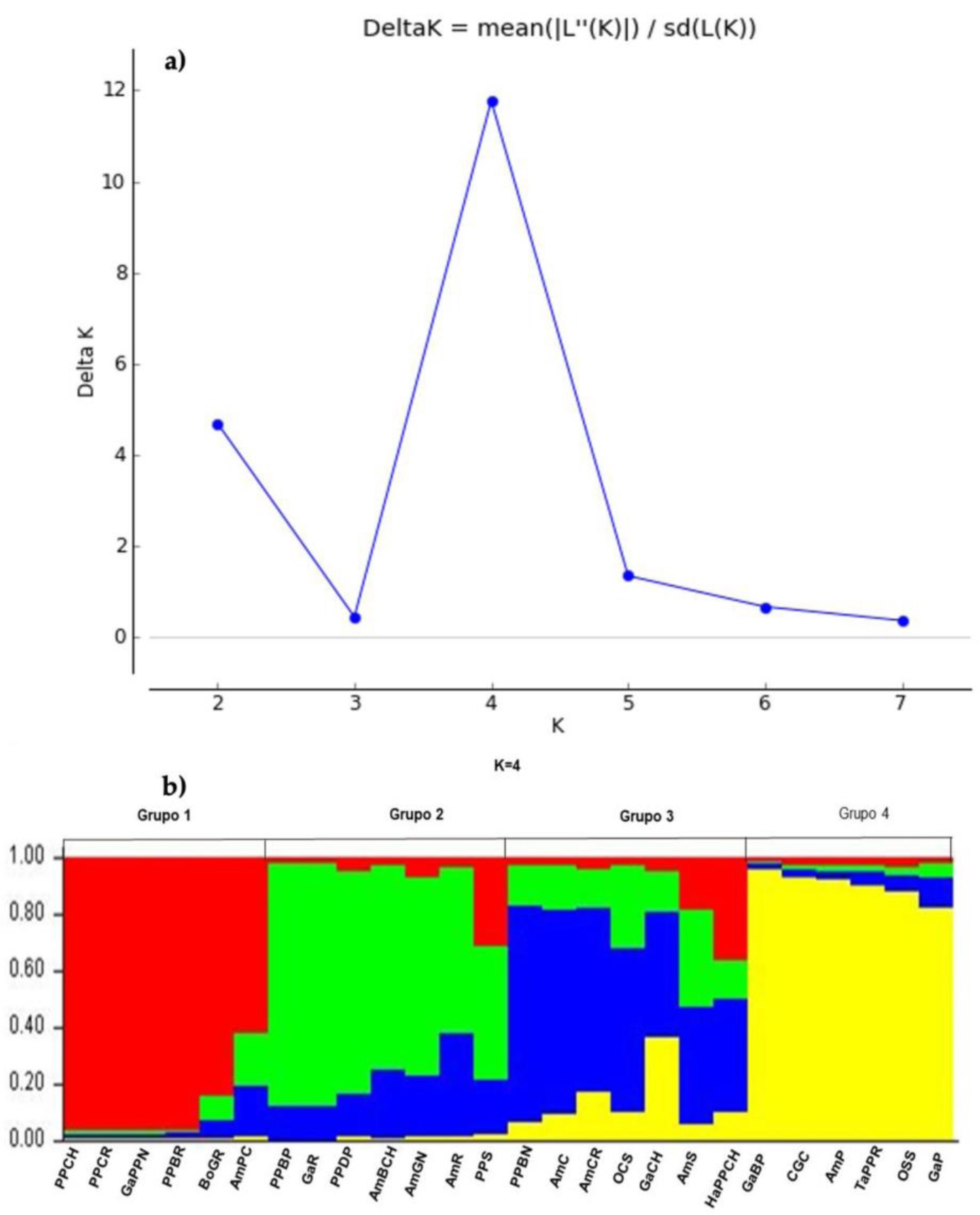
El análisis bayesiano mostró que el valor de ∆K (11.76) más alto (Figura 2a) se obtuvo al formarse cuatro grupos (DK) (Figura 2b). El grupo I reunió seis poblaciones (PPCH, PPCR; GaPPN, PPBR, BoGR y AmPC), Ninguna de ellas se encuentra en alguno de los clústers del dendrograma obtenido a partir de los datos producto de la amplificación por PCR (Figura 1). Mientras que las poblaciones que formaron los grupos II, III y IV, si se agruparon en alguno de los conjuntos del Análisis Bayesiano. Así se tiene, por ejemplo, que las poblaciones PPBP, GaR, AmBCH, y AmGN, del grupo II del análisis bayesiano, también estuvieron agrupadas en el clúster (CV), el resto de los grupos también coincidió en el agrupamiento de algunas de las poblaciones que en el dendrograma formaron alguno de los clústers.
Discusión
El número de alelos observados son similares a los reportados por Guzmán et al. (2020), quienes en 42 accesiones (colectas) de 11 especies de Capsicum, y 21 iniciadores, encontraron que el oligo HpmsCa19 fue el que identificó más alelos (12). Por otro lado, Harishkumar et al. (2020), emplearon los marcadores Hpms1-143, Hpms 1-274, y HpmsCaSIG19, en 37 genotipos de chile, reportando que HpmsCaSIG19 fue el marcador que identificó el mayor número de alelos (13), aunque en ambas investigaciones es una cantidad de alelos inferior a los encontradoe en el presente trabajo. Estás diferencias pueden ser por la diversidad de las colecciones o poblaciones estudiadas de Capsicum en cada trabajo de investigación, ya que tanto Guzmán et al. (2020), como Harishkumar et al. (2020), emplearon variedades comerciales de chile en sus respectivos estudios. Mientras que Rivera et al. (2016), evaluó en líneas endocriadas derivadas de variedades comerciales de chile, 20 marcadores y entre ellos HpmsCaSIG19 y Hpms1-143, contrando menos alelos (60) que los identificados en el presente estudio. También Nanayakkara (2018), de los 27 marcadores SSR del tipo CAMS que usaron en su investigación para estimar la diversidad molecular de 30 accesiones de Capsicum spp., detectaron 108 alelos, mientras que Sood et al. (2023) con 82 marcadores SSR en chile morrón detectaron 151 alelos, en tanto que Adeyemo et al. (2023) evaluaron 13 marcadores SSR que detectaron 54 alelos en 22 accesiones de C. annuum y C. frutescens, lo que pone de manifiesto la efectividad de los marcadores empleados en cada estudio son de gran importancia para identificar alelos en las poblaciones de Capsicum estudiadas. Otras investigaciones en las que se usaron marcadores microsatélites y en las que se encontró mayor número de alelos a los del presente trabajo de investigación son la de Saleh et al. (2016), quienes reportaron 352 alelos con 21 marcadores y Xiao-Zhen et al. (2019) con 28 marcadores reportan 459 alelos, mientras que el primer HpmsCaSIG19 incluido en su investigación identificó 16 alelos.
Al comparar los resultados del AMOVA con los reportados por Yu et al. (2021) en nabo sueco (colinabo), reportan que encontraron 94% de variación dentro de poblaciones, 5% entre poblaciones y 1% entre regiones, concluyendo que sus resultados tienen diferencias menores en todas las poblaciones de nabo o colinabo que evaluaron. Mientras que Singh et al. (2013) en arroz probaron marcadores SSR, en diferentes regiones de la India, reportando que el 1% de diversidad fue para regiones, 4% entre poblaciones, 70% entre individuos y el resto (24%) dentro de individuos. Por otro lado, Castañón et al. (2014) con marcadores AFLP, y Kuria et al. (2018) con ISSR, reportan para regiones, entre poblaciones y dentro de poblaciones varianza molecular de 26, 31 y 43%, y 2, 58 y 41%; porcentajes que en forma general no superan a los encontrados en la presente investigación. En su trabajo con cepas de seta china o shiitake (Lentinula edodes) en el que se usaron 20 marcadores de secuencias simples repetidas (SSR), Lee et al. (2020), encontraron 1% de variación para regiones, 66% entre y 33% dentro de cepas (poblaciones). El 33% dentro de cepas (poblaciones) es menor, pero el 66% entre cepas o poblaciones superó a los porcentajes de variación reportados en la presente investigación. Por otro lado, Islam et al. (2016), usaron marcadores TE-AFLP en 171 poblaciones de Capsicum annuum, de sus resultados encontrados reportan que la varianza explicada entre y dentro de poblaciones fue de 45 y 54%, lo cual indica que estos porcentajes de varianza superan a los porcentajes de varianza encontrados en el presente estudio. Es importante señalar, que en su investigación los autores mencionados no estimaron la varianza de las regiones. Esta es la posible explicación del porque hubo diferencias en las varianzas entre y dentro de las poblaciones analizadas en los dos estudios, en lugar de estar relacionado con el número de poblaciones evaluadas en cada uno de ellos.
Los índices F o de fijación (Wright 1965) (Tabla 3), presentaron valores grandes, un valor de PhiRT = 0.103, puede interpretarse como que la diversidad genética de las poblaciones evaluadas entre regiones es moderada. Por otro lado, el estadístico PhiPR = 0.278, entre subpoblaciones dentro de regiones (Poblaciones/Regiones) es alto, y PhiPT = 0.352 (similar de FST), indica que las poblaciones evaluadas presentaron diferenciación genética grandes. Un índice FST (PhiPT) de 0.352 es similar al reportado por Castañón et al. (2014) al comparar poblaciones en las que se estimó la diversidad genética con marcadores AFLP. Mientras que Toledo et al. (2016), con marcadores SSR que incluyeron a los cuatro oligos que se probaron en la presente investigación encontraron un FST = 0.308, que es un índice con valor inferior al encontrado en el presente trabajo. Esta diferenciación genética entre poblaciones que se detectó en la presente investigación se podría utilizar en un programa de mejoramiento genético con el propósito de formar nuevos y mejores cultivares de chile.
Los grupos o clústers formados por las poblaciones evaluadas puede deberse a que en algunas localidades en las que se recolectaron las poblaciones se les encontró creciendo cerca unas de las otras, por lo que se supone que pudo haber ocurrido entrecruzamiento entre las plantas de las poblaciones. Al respecto, se tienen reportes de que la alogamia en Capsicum puede ser menor al 10% (Álvarez y Pino 2018), pero otros como Cotter (1980), sostienen que llega hasta 30%. Por otro lado, Xiao-min et al. (2016) mencionan que en C. annumm el flujo génico es frecuente debido al cruzamiento natural y al tipo de reproducción de esta especie. Por lo anterior, es posible que alguna(s) de la(s) población(es) recolectadas, y a las que se les hizo el estudio de diversidad genética mediante ADN, fueron poblaciones segregantes o F1.
Al comparar los resultados del análisis bayesiano del presente estudio, con los de Taranto et al. (2016), y Adeyemo et al. (2023), quienes encontraron que el valor de ΔK estimado fue = 3, por lo que sus poblaciones o colecciones de chile comparadas o evaluadas fueron agrupadas en tres conjuntos, en cambio en el presente trabajo se obtuvo un valor de ΔK = 4 por lo que el análisis consideró cuatro grupos poblacionales (Figura 2 a, b ). En cambio, Lee et al. (2016) en su investigación reportan un valor de ΔK = 10, este resultado puede deberse al origen y la especie a que pertenecen las colecciones de chile que se evaluaron. Los grupos obtenidos en el análisis bayesiano de la presente investigación se formaron por poblaciones de la misma región geográfica, además del tipo de chile al que pertenece cada población.
La colecta ojo de cangrejo (OCS) es un material que se encuentra en vía de desaparición, pero, presenta características de tamaño y color distintivo en su fruto (mancha morada en sus frutos) que lo hacen diferente del resto de las colectas estudiadas, pero no se tiene conocimiento que demuestre su uso actual en programas de mejora genética.
Conclusiones
El análisis genético mediante marcadores SSR reveló el grado de similitud y diferencia entre las 26 poblaciones evaluadas. El marcador HpmsCaSIG19, mostró ser el más eficiente en la presente investigación y en investigaciones previas con Caspsicum spp. Por lo que sería importante, en nuevas investigaciones, considerar emplear este oligo para poder realizar una buena estimación de la diversidad genética y estructura de las poblaciones evaluadas. La mayor diversidad genética se encontró dentro de las poblaciones (Ind/Pob/Reg), una menor entre poblaciones y regiones. Las diferencias genéticas entre las poblaciones evaluadas tienen importancia, ya que pueden aprovecharse estas diferencias poblacionales en la selección y el mejoramiento genético para formar nuevos cultivares con características sobresalientes, más productivas y con mejor adaptación a las condiciones climáticas de los estados norte de Chiapas y Tabasco.

