











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introducción
La clasificación supervisada es una técnica para detectar regiones espectralmente similares al utilizar muestras de entrenamiento contenidas en una imagen (Abburu y Golla, 2015). Esta clasificación parte de un conocimiento previo del área de estudio, adquirido a través de experiencia o trabajo de campo (Aguilar-Rivera, Galindo y Fortanelli, 2012). En este contexto, el clasificador extrapola las propiedades espectrales a otras áreas de la imagen.
El amplio interés por la clasificación de superficies ha generado una gran cantidad de clasificadores supervisados, que se pueden categorizar en paramétricos y no paramétricos (Hubert-Moy, Cotonnec, Le, Chardin y Perez, 2001). Los paramétricos parten del supuesto de una determinada clase que tiene una distribución estadística, usualmente una distribución normal (Weng, 2012). Los no paramétricos no hacen suposiciones sobre distribuciones de probabilidad (Keuchel, Naumann, Heiler y Siegmund, 2003). Por lo tanto, estos últimos pueden considerarse robustos, ya que pueden funcionar correctamente para varias distribuciones de clases (Wieland y Pittore, 2014), siempre y cuando las firmas espectrales de las clases sean lo suficientemente distintas. Algunos de los algoritmos que más se utilizan para la clasificación de la cobertura del suelo agrícola son: distancia mínima (DM), máxima verosimilitud (MV), mapeador de ángulos espectrales (MAE) y random forest (RF); los tres primeros son paramétricos y el último es no paramétrico.
La clasificación de cultivos es una de las aplicaciones de la teledetección en la agricultura (Atzberger, 2013). Esta permite reconocer los cultivos de cada parcela, que es una información muy útil, tanto en escalas locales y regionales, como en escala global (Kussul et al., 2016). Además, la información que genera es esencial para la formulación de políticas agrarias, concesión y control de subsidios, seguridad alimentaria, manejo y control de cultivos agrícolas, estimación de rendimiento e inventario de cultivos agrícolas. Este último aspecto es especialmente relevante, ya que, al identificar los cultivos, es posible determinar de manera espacial y temporal los requerimientos hídricos, con el apoyo de técnicas de teledetección y sistemas de información geográfica (SIG).
La teledetección se puede utilizar con la tecnología de Sistemas de Información Geográfica (SIG) que brindan una mayor comprensión acerca de la cobertura del suelo (Rwanga y Ndambuki, 2017). Esta combinación proporciona una herramienta de análisis cuantitativo de los cambios en el uso y la cobertura del suelo (Chowdhury, Hasan y Abdullah, 2020), y para revisar y editar mapas a diferentes escalas (Rujoiu-Mare y Mihai, 2016). Las imágenes satelitales multiespectrales de resolución moderada y de acceso libre, como Landsat 7 y 8, MODIS, Sentinel-1 y Sentinel-2, se utilizan para el monitoreo y clasificación de cultivos agrícolas.
Entre estos satélites, Sentinel-2 se destaca como el más relevante y preciso para la clasificación de cultivos agrícolas, gracias a su resolución espacial de 10 m y su capacidad multiespectral. Song, Huang, Hansen y Potapov (2021) evaluaron la utilidad de los sensores Landsat 7 y 8, Sentinel-1 y Sentinel-2 para la clasificación supervisada de maíz, identificando a este último como el sensor más valioso y preciso. Este desempeño sobresaliente se atribuye principalmente a la inclusión de bandas específicas, como el borde rojo, el infrarrojo cercano y el infrarrojo de onda corta, que mejoran significativamente la detección y discriminación de cultivos. Por otro lado, Saini y Ghosh (2018) realizaron un estudio comparativo de la clasificación supervisada de la cobertura agrícola usando imágenes Sentinel-2 y dos algoritmos de aprendizaje automático: Random Forest y máquina de vectores soporte. En este análisis, Random Forest obtuvo los valores más altos de precisión global e índice Kappa, destacándose como el algoritmo más efectivo para este propósito.
Por otro lado, el complemento gratuito y de código libre Semiautomatic Classification Plugin (SCP) del software QGIS.org (2020) realiza una clasificación semiautomática con base en múltiples satélites (ASTER, MODIS, SPOT, RapidEye, Landsat, Sentinel, etc.). Además de la clasificación, SCP integra herramientas para el procesamiento previo y posterior de imágenes espectrales, lo que convierte a SCP en una herramienta importante en todo el flujo de trabajo para el mapeo de cobertura de suelo (Leroux, Congedo, Bellón, Gaetano y Bégué, 2018). Algunos investigadores han utilizado el SCP para monitorear los cambios de cobertura de suelo (Vincent, Varalakshmi, Nithya, Sona y Thomas, 2022), mapeo y clasificación de cobertura terrestre (Leroux et al., 2018; Rolando, D’Uva y Scandiffio (2023).
En los últimos años el cultivo de maíz forrajero se ha consolidado como el principal cultivo en la Región Lagunera, donde se ubica el Distrito de Riego (DR) 017; ya que se han establecido 54 000.00 ha de una superficie total de riego de 167 000.00 ha (Reyes-González, Zavala, de Paul, Cano y Rodríguez, 2022). El ensilaje de maíz es uno de los principales ingredientes de la dieta del ganado lechero, pues constituye entre 30 y 40% de la ración (en materia seca) de las vacas de producción (González-Castañeda, Peña, Núñez y Jiménez, 2005). De 2011 a 2021 el número de cabezas de ganado bovino lechero aumentó alrededor de 83 mil (SIAP, 2023), lo que ha llevado a un incremento en el área sembrada. Sin embargo, a pesar de la importancia de este cultivo en el DR 017, existe una carencia de información precisa y oportuna. Por lo tanto, un monitoreo exacto y actualizado de la cobertura de maíz forrajero, facilita la toma de decisiones en la gestión del recurso hídrico en las unidades de producción y distritos de riego.
Ante la falta de estudios que comparen específicamente los algoritmos DM, MV, MAE y RF en el cultivo de maíz forrajero en regiones con características agroclimáticas similares a las de la Región Lagunera, este estudio tiene como objetivo evaluar y comparar el desempeño de los cuatro algoritmos de clasificación supervisada (DM, MV, MAE y RF) en la identificación, mapeo y cuantificación del maíz forrajero en los módulos de riego X (Masitas) y XII (El Porvenir) del Distrito de Riego 017 (DR017). Para lograrlo, se utilizó información espectral obtenida de imágenes del satélite Sentinel-2 en tres fechas específicas de evaluación, que coincidieron con un periodo clave en el desarrollo del cultivo.
Materiales y Métodos
Área de estudio
El estudio se realizó en el ciclo primavera-verano (PV) 2021 en los módulos X (Masitas) y XII (El Porvenir) del DR 017 Región Lagunera. Las coordenadas extremas que definen el área de estudio son: Por el Norte, el Módulo XII llega hasta los 25° 54’ 39.27” N y 103° 18’ 43.61” O en el ejido Batopilas, municipio de Francisco I. Madero, Coahuila. Por el Sur, el Módulo X llega hasta los 25° 33’ 22.23” N y 103° 27’ 22.17” O en el ejido Las Huertas, municipio de Gómez Palacio, Durango. Por el Oeste, el Módulo X llega hasta los 103° 31’ 20.72” O y 25° 45’ 4.30” de N en el ejido La Luz, municipio de Gómez Palacio, Durango. Por el Este, el Módulo XII llega hasta los 103° 15’ 17.74” O y 25°46’ 27.92” N en el ejido Nuevo Linares, municipio de Francisco I. Madero, Coahuila. Ambos módulos cubren una superficie de 14 276.70 ha. La pendiente de la zona de estudio es suave, de aproximadamente 0.05%, con dirección de sur a norte (Figura 1), y la elevación oscila entre 1104 y 1123 m (INEGI, 2013).
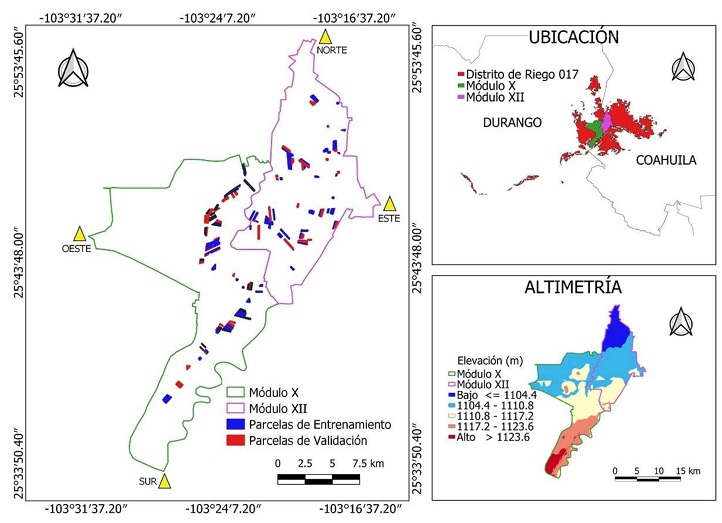
Datos de campo, tamaño de la muestra y fechas de evaluación
El maíz forrajero es el cultivo importante en el área de estudio, con una superficie de siembra programada para el ciclo agrícola PV 2021 de 2405.00 ha para el módulo X y 1510.00 ha para el módulo XII (información oficial que proporciono el personal administrativo de los dos módulos), Que representan 57.8 y 53.3% de la superficie total de riego programada con agua superficial (agua de río) en ambos módulos de riego, respectivamente.
Algunos productores de estos módulos cuentan con derechos de riego para usar tanto agua superficial (río) como subterránea (pozo). El agua subterránea se utiliza para el riego de aniego o presiembra, y el primer riego de auxilio del maíz forrajero. Los riegos de auxilio posteriores se realizan con agua superficial.
Para determinar el tamaño de la muestra se utilizó el método propuesto por Murray y Larry (2009); se empleó como referencia la superficie de siembra programada de maíz forrajero para el ciclo PV 2021. Resultó un tamaño de muestra de 331.00 ha para el módulo X y 306.00 ha para el módulo XII, con un nivel de confianza de 95%, y un error deseado del 5 por ciento.
Se establecieron tres fechas para realizar la evaluación de los algoritmos de clasificación supervisada: 1) 22 de mayo de 2021 (día juliano 142); 2) 11 de junio de 2021 (día juliano 162); y 3) 26 de junio de 2021 (día juliano 177). Estas fechas correspondieron al periodo de las etapas fenológicas del maíz forrajero entre VT (panojamiento) y R3 (etapa reproductiva: grano lechoso). Las fechas se definieron mediante la predicción fenológica del maíz forrajero, por medio de los grados días de desarrollo (GDD) utilizando el método racional (Snyder, 1985). Para ello, se tuvo en cuenta una temperatura base de 10 °C y una temperatura máxima de 30 °C. También, se consideró el acumulado de GDD del maíz forrajero reportado por Delgado-Ramírez, Bolaños, Quevedo, López y Estrada (2023) en trabajos previos en el área de estudio, el cual fue de 1526.1 GDD para maíz irrigado con agua subterránea (fecha de siembra: 26 de febrero) y 1722.6 GDD con agua superficial, para una fecha de siembra en el 9 de abril.
Descarga de imágenes de satélite
Se utilizaron tres imágenes multiespectrales de los satélites Sentinel 2A (22 de mayo y 11 de junio de 2021) y Sentinel B (26 de junio de 2021), sin nubosidad, las cuales cubren satisfactoriamente el área de estudio (malla de barrido = T13RFJ). En el Cuadro 1 se presentan las características generales de las doce bandas en las que captan información espectral los sensores a bordo de los satélites Sentinel-2 para la clasificación supervisada.
Cuadro 1: Características de las bandas utilizadas del satélite Sentinel-2 para la clasificación supervisada en los dos módulos de estudio
Table 1: Table 1. Characteristics of the Sentinel-2 satellite bands used for the supervised classification in the two study modules (Source: ESA, 2012).
| Bandas Sentinel-2 | Longitud de Onda Central | Ancho de Bandas | Resolución (m) |
| - - - - - - - - - - nm - - - - - - - - - - | m | ||
| Banda 1 - Aerosol | 443 | 20 | 60 |
| Banda 2 - Azul | 490 | 65 | 10 |
| Banda 3 - Verde | 560 | 35 | 10 |
| Banda 4 - Rojo | 665 | 30 | 10 |
| Banda 5 - Borde Rojo 1 | 705 | 15 | 20 |
| Banda 6 - Borde Rojo 2 | 740 | 15 | 20 |
| Banda 7 - Bordo Rojo 3 | 783 | 20 | 20 |
| Banda 8 - Infrarrojo Cercano (NIR) 1 | 842 | 115 | 10 |
| Banda 8A - Infrarrojo Cercano (NIR) 2 | 865 | 20 | 20 |
| Banda 9 - Vapor de Agua | 945 | 20 | 60 |
| Banda 11 - Infrarrojo Onda Corta (SWIR) 1 | 1610 | 90 | 20 |
| Banda 12 - Infrarrojo Onda Corta (SWIR) 2 | 2190 | 180 | 20 |
(Fuente: ESA, 2012). Table 1: Characteristics of the Sentinel-2 satellite bands used for the supervised classification in the two study modules (Source: ESA, 2012).
Las imágenes se descargaron gratuitamente desde el sitio web Copernicus Open Access Hub (Copernicus Programme, 2024) con un nivel de procesamiento 2A, también denominado reflectancia a nivel de suelo (ESA, 2015). Este nivel garantiza que las imágenes están calibradas radiométricamente, corregidas geométricamente y con valores de reflectancia calculados en la superficie terrestre (Kuhn et al., 2019).
Determinación de clases
Para realizar la clasificación supervisada en los dos módulos de riego, se definieron tres clases que abarcan la mayoría de la superficie: 1) maíz forrajero, 2) otros cultivos, y 3) suelo desnudo o vacante. En el Cuadro 2 se muestran las clases y superficie evaluadas mediante los algoritmos de clasificación supervisada. En el módulo X se evaluó una superficie total de 764.20 ha en 92 parcelas y en el módulo XII fueron 783.49 ha en 109 parcelas. Asimismo, se puede constatar que la superficie evaluada de maíz forrajero (Clase 1) corresponde al tamaño de muestra previamente calculada para los dos módulos de estudio.
Cuadro 2: Clases y superficies evaluadas con los algoritmos de clasificación supervisada en los módulos X y XII del DR 017.
Table 2: Classes and surfaces evaluated with the supervised classification algorithms in modules X and XII of ID 017.
| No. Clase | Nombre de la Clase | Cultivos | Módulo X | Módulo XII | ||
| No. Parcelas | Superficie | No. Parcelas | Superficie | |||
| ha | ha | |||||
| Clase 1 | Maíz Forrajero | Maíz Forrajero | 34 | 332.96 | 25 | 306.05 |
| Clase 2 | Otros Cultivos | Sorgo Forrajero | 14 | 78.10 | 20 | 117.09 |
| Nogal | 7 | 80.88 | 2 | 21.59 | ||
| Algodón | 14 | 98.80 | ||||
| Alfalfa | 5 | 40.15 | ||||
| Clase 3 | Vacante | Vacante (22 mayo 2021) | 8 | 51.83 | 27 | 137.35 |
| Vacante (11 junio 2021) | 4 | 30.18 | 25 | 137.41 | ||
| Vacante (26 junio 2021) | 6 | 51.30 | 10 | 64.00 | ||
Vacante = Suelo desnudo (sin cultivo).
Vacant = Bare soil (no cultivation).
La delimitación de las parcelas correspondientes a la Clase 1 (Maíz Forrajero) y la Clase 2 (Otros Cultivos) se realizó en campo mediante la utilización de un GPS marca Garmin modelo Etrex 32x. En cuanto a la Clase 3 (Vacante), se seleccionaron las parcelas con valores comprendidos entre el rango de 0.08 y 0.10 del Índice de Vegetación de Diferencia Normalizada (NDVI) en cada una de las imágenes clasificadas. Estos valores de NDVI corresponden a suelo desnudo (denominada línea de suelo). El NDVI se calculó con la Ecuación 1 propuesta por Rouse, Jr, Haas, Schell y Deering (1974).
NDVI es el índice de vegetación de diferencia normalizada (adimensional), NIR es la reflectancia en la banda del infrarrojo cercano (%) y R es la reflectancia en la banda del rojo (%). Según las bandas espectrales que contienen las imágenes Sentinel-2; B8 corresponde a la banda NIR y B4 a la banda R, ambas con una resolución espacial de 10 metros.
La línea de suelo es fácil de definir, pero su valor no es universal y depende del conjunto de datos considerado (Gilabert, González y García, 1997). Algunos autores estimaron valores de la línea de suelo del NDVI de 0.10 (Delgado-Ramírez et al., 2023) y 0.12 (Gilabert et al., 1997). Con base en la delimitación de las parcelas en ambos módulos de riego, se asignaron aleatoriamente las áreas de entrenamiento y validación, se consideró el 70 y 30%, respectivamente. La determinación del porcentaje de áreas de entrenamiento se fundamentó en las investigaciones de Argañaraz y Entraigas (2011), quienes demostraron que la precisión global se mejora significativamente al ampliar el intervalo de áreas de entrenamiento desde un 2.5% hasta un 70 por ciento.
Algoritmos de clasificación supervisada
En el área de estudio, la clasificación supervisada se llevó a cabo mediante la implementación de tres algoritmos paramétricos: distancia mínima (DM), máxima verosimilitud (MV) y mapeador de ángulos espectrales (MAE). Adicionalmente, se empleó un algoritmo no paramétrico, Random Forest (RF), que se configuró con dos variantes de árboles de decisión: 20 (k = 20) y 100 (k = 100). Los cuatro algoritmos se describen a continuación:
Distancia mínima (DM). Es un clasificador sencillo y de rápida ejecución. Utiliza las áreas de entrenamiento para determinar el promedio de las clases seleccionadas y luego coloca cada pixel en la clase con el promedio más cercano según la medida de distancia euclidiana (Avogadro y Padró, 2019; Ghayour et al., 2021). DM ignora las varianzas en los vectores espectrales promedio de diferentes clases (Altamirano, Rubio, López y Guerra, 2020). Sin embargo, brinda buenos resultados, sí no existe un gran traslape de clases. Como siempre hay una clase adyacente, no hay espacio para pixeles sin clasificar, incluso si están lejos del centroide de la clase (Sathya y Deepa, 2017). El cálculo de la distancia euclidiana se realiza con la Ecuación 2 (Richards, 1999; Mohamed, Belal y Shalaby, 2015).
Dist representa la distancia de la puntación promedio al pixel desconocido, μck es el vector promedio de la clase c en la banda k y μcl es el vector promedio de la clase c en la banda i.
Máxima verosimilitud (MV). Es el algoritmo más utilizado en teledetección debido a su facilidad de aplicación e interpretación de resultados. Además, se considera uno de los métodos de discriminación más precisos y eficaces (Herbei, Sala y Boldea, 2015; Makandar y Kaman, 2021), siempre y cuando los datos sigan una distribución normal (Mondal, Kundu, Chandniha, Shukla y Mishra, 2012; Topaloğlu, Sertel y Musaoğlu, 2016). En la fase de aprendizaje, el MV crea una “imagen espectral” para cada clase, a partir del promedio y la varianza/covarianza de los sitios de entrenamiento que se localizan en la imagen (Otukei y Blaschke, 2010). Durante la fase de clasificación, la probabilidad de que cada pixel pertenezca a cada clase se calcula en función de su respuesta espectral de acuerdo a la Ecuación (3) (Richards, 1999; Otukei y Blaschke, 2010). Finalmente, el pixel se asigna a la clase con mayor probabilidad de pertinencia.
D es la distancia ponderada que indica la probabilidad de pertinencia, c representa la clase especificada, X es el vector de mediación del pixel deseado, M c es el vector promedio de la clase c y COV C representa la matriz de covarianza de los pixeles de la clase c.
Mapeador de ángulos espectrales (MAE). Es un clasificador espectral supervisado autogenerado, que se utiliza para determinar la similitud espectral entre los espectros de una imagen determinada y los espectros de referencia en el espacio dimensional, calculando el ángulo entre los espectros (Petropoulos, Vadrevu, Xanthopoulos, Karantounias y Scholze, 2010; Tang et al., 2015). Los espectros de referencia se adquieren mediante investigación de campo o directamente a partir de imágenes satelitales. Estos espectros funcionan como firmas espectrales para la clasificación de imágenes satelitales (Li, Ke, Gong y Li, 2015). El MAE se basa exclusivamente en información angular para determinar el espectro de los píxeles. Este algoritmo asume que el espectro de reflectancia observado, representado en forma vectorial, que se encuentra en un espacio multidimensional, donde el número de dimensiones es equivalente al número de bandas espectrales (Talukdar et al., 2020). La discrepancia entre los espectros de la imagen y los espectros de referencia se cuantifica mediante el ángulo espectral en el espacio vectorial multidimensional. Un ángulo pequeño indica una alta similitud, mientras que un ángulo grande representa una baja similitud (Kumar, Gupta, Mishra y Prasad, 2015). El ángulo espectral o similitud se determina utilizando la Ecuación (4) (Tembhurne y Malik, 2012; Tang et al., 2015).
x, r∈Rq, q es el número de la banda, x representa un pixel vector espectral, r representa una referencia de clase vector, (x, r) es el producto escalar de los valores característicos x y r, y ‖.‖ es el módulo vectorial. El criterio de clasificación asigna al píxel en cuestión la etiqueta de clase que minimiza el ángulo θ definido en la Ecuación (4).
Random forest (RF). Es una herramienta de regresión y clasificación supervisada con base en aprendizaje automático (Machine Learning), la cual es ampliamente utilizada, ya que proporciona los mejores resultados y la mayor precisión para la obtención de información agrícola (Dash, Pearse y Watt, 2018; Zhao et al., 2019). Este método entrena una gran cantidad de árboles de decisión (k) y cada árbol, a su vez, entrena un subconjunto de los datos de entrenamiento obtenidos mediante bootstraping (Chen, Hou, Huang, Zhang, y Li, 2021). El bootstraping es una técnica de re-muestreo estadístico, que implica muestrear aleatoriamente el conjunto de datos con reemplazo (Valbuena, Maltamo y Packalen, 2016). El algoritmo RF requiere solo dos parámetros, m (el número de variables aleatorias o variables predictoras en cada división) y k (el número de árboles de clasificación) (Thanh-Noi y Kappas, 2017). Un árbol de decisión se construye mediante consultas binarias sucesivas sobre los datos de entrenamiento establecidos en subconjuntos (nodos) de homogeneidad creciente. Esta homogeneidad está determinada por el índice de Gini (G), una medida del grado de “impureza” del nodo (Raileanu y Stoffel, 2004). Un valor del índice G igual a cero indica que los datos pertenecen a una sola clase, mientras que un índice mayor que cero y un valor máximo de uno indica nodos donde los datos pertenecen a varias clases (Cortés-Macías et al., 2023). El índice G se determina con la Ecuación (5).
C es el número total de clases y P representa la probabilidad de pertinencia de un elemento a la clase i.
Para aplicar el algoritmo Random Forest (RF) se utiliza el complemento Semi-Automatic Classification plugin (SCP) versión 7.10.11 (Congedo, 2021), es crucial tener en cuenta los siguientes parámetros: el tamaño de la muestra de entrenamiento (número de píxeles) y la cantidad de árboles de decisión (k). Algunos autores consideran que por defecto el valor óptimo de k es 500 (Thanh-Noi y Kappas, 2017; Rodríguez-Valero y Alonso-Sarria, 2019). Sin embargo, otros autores como Cortés-Macías et al. (2023) y Ramírez et al. (2020) lograron valores de precisión global más altos con k = 20 y con k = 100, respectivamente. Por lo tanto, en este trabajo se utilizaron los valores de k de 20 y 100 para la implementación de RF.
Los cuatro algoritmos se desarrollaron con el software de libre acceso QGIS.org (2020) mediante el complemento SCP y la herramienta Region Of Interest (ROI). El software QGIS.org (2020) es un sistema de información geográfica que permite usar formatos ráster y vectoriales, así como una base de datos. Entre sus atribuciones se encuentran: el análisis vectorial y ráster, el muestreo, el geoprocesamiento, la geometría y la gestión de bases de datos. El complemento SCP permite la clasificación supervisada de imágenes multiespectrales de satélites, aeroplanos o drones, cuenta con herramientas para el preprocesamiento y postprocesamiento de imágenes, permite crear áreas de entrenamiento (ROIs), cuenta con algoritmos de clasificación supervisada y no supervisada. Asimismo, permite evaluar la precisión de los resultados de la clasificación.
La clasificación de la cobertura agrícola se realizó a partir de un archivo ráster virtual compuesto por las bandas especificadas en la Cuadro 1. Este archivo permitió la delimitación de polígonos que representan las áreas de entrenamiento para cada clase (regiones de interés o ROIs), y la generación de una firma espectral, característica para cada una. Posteriormente, se utilizó el complemento SCP para clasificar la totalidad de la imagen utilizando las firmas espectrales definidas. Asimismo, con SCP se elaboró la matriz de confusión, utilizando las parcelas de validación de cada clase y los resultados obtenidos de cada algoritmo de clasificación. La matriz es una tabla que muestra el número de instancias de verdad fundamental de una clase particular en comparación con el número de instancias de clase previstas. Esta tabla permite determinar la precisión y concordancia del algoritmo utilizado en la clasificación supervisada.
Evaluación de la precisión y concordancia
La precisión de los algoritmos de clasificación supervisada se evaluó al analizar la matriz de confusión (Kohavi y Provost, 1998), que se generó para cada imagen clasificada. La matriz en cuestión contiene datos que representan el valor total o el porcentaje de observaciones y estimaciones para cada característica clasificada. A partir de esta información, es posible calcular los parámetros de evaluación propuestos por Congalton (1991) mencionados en el Cuadro 3.
Cuadro 3: Parámetros utilizados para la evaluación del desempeño de los algoritmos de clasificación supervisada en el área de estudio.
Table 3: Parameters used for performance evaluation of supervised classification algorithms in the study area.
| Parámetro | Unidad | Ecuación | |
| Precisión Global (P) | (%) |
|
(6) |
| Precisión del Productor (PP) | (%) |
|
(7) |
| Precisión del Usuario (Pu) | (%) |
|
(8) |
| Índice Kappa (K̂) | (Adimensional) |
|
(9) |
m es el número total de clases, N es el número total de píxeles en las m clases de referencia, x
ii
son los elementos de la diagonal principal de la matriz de confusión, x
∑i es la suma de los píxeles de la clase
Para interpretar el valor del índice (K̂), Landis y Koch (1977) propusieron utilizar una escala de la fuerza de concordancia, donde valores menores de cero se clasifican como pobres, de 0.01 a 0.20 como leves, de 0.21 a 0.40 como aceptables, de 0.41 a 0.60 moderadas, de 0.61 a 0.80 considerables o buenas, de 0.81 a 1.00 casi perfectas.
La integración de datos de campo, imágenes Sentinel-2 y algoritmos de clasificación supervisada (paramétricos y no paramétricos) permitió identificar, mapear y cuantificar la superficie cultivada con maíz forrajero en los módulos de riego X y XII. El complemento SCP en QGIS.org (2020) facilitó la generación de firmas espectrales y la evaluación del desempeño de los algoritmos, garantizando resultados confiables para cumplir los objetivos del presente estudio.
Resultados y Discusión
Precisión global e índice kappa
En el Cuadro 4 se muestran los valores de P y K̂ que se calcularon con todos los algoritmos de clasificación supervisada para cada imagen de Sentinel-2, en las tres fechas de evaluación. El algoritmo RF con un valor de k de 100 árboles de decisión (RF100) destacó como el más eficiente, obtuvo su mejor desempeño el 11 de junio de 2021, donde logró precisiones del 79.1% en el Módulo X y del 87.4% en el Módulo XII. Estos resultados reflejan una clasificación muy confiable, como lo sugieren estudios previos (Alrababah y Alhamad, 2006; Ikiel, Ustaoglu, Dutucu, y Kilic, 2012). Además, el valor estimado de K̂ indica una buena concordancia de la clasificación en ambos módulos (Landis y Koch, 1977).
Cuadro 4: Precisión global (P) e índice Kappa (K̂) calculados para los módulos X y XII en las tres fechas de evaluación.
Table 4: Overall precision (P) and Kappa index (K̂) calculated for modules X and XII on the three evaluation dates.
| Algoritmos | 22 mayo 2021 | 11 junio 2021 | 26 junio 2021 | |||||||||
| Módulo X | Módulo XII | Módulo X | Módulo XII | Módulo X | Módulo XII | |||||||
| P | K̂ | P | K̂ | P | K̂ | P | K̂ | P | K̂ | P | K̂ | |
| DM | 26.5 | 0.00 | 69.3 | 0.51 | 44.7 | 0.20 | 69.0 | 0.51 | 60.5 | 0.38 | 67.3 | 0.46 |
| MV | 57.1 | 0.33 | 75.6 | 0.63 | 75.2 | 0.58 | 77.7 | 0.64 | 74.9 | 0.60 | 71.3 | 0.51 |
| MAE | 32.2 | 0.09 | 67.5 | 0.49 | 40.4 | 0.15 | 68.0 | 0.49 | 42.1 | 0.14 | 44.2 | 0.21 |
| RF, k = 20 (RF20) | 62.2 | 0.36 | 84.8 | 0.75 | 77.9 | 0.61 | 85.9 | 0.77 | 76.9 | 0.61 | 83.5 | 0.70 |
| RF, k = 100 (RF100) | 64.3 | 0.40 | 86.5 | 0.78 | 79.1 | 0.63 | 87.4 | 0.79 | 77.6 | 0.62 | 84.0 | 0.71 |
DM = distancia mínima; MV = máxima verosimilitud; MAE = mapeador de ángulos espectrales; RF20 = random forest con 20 árboles de decisión; RF100 = random forest con 100 árboles de decisión.
DM = minimum distance; MV = maximum likelihood; MAE = spectral angle mapper; RF20 = random forest with 20 decision trees; RF100 = random forest with 100 decision trees.
En comparación con otros algoritmos, RF100 superó consistentemente a RF con 20 árboles (RF20) y a los métodos paramétricos evaluados. Entre los algoritmos paramétricos, el de MV mostró un desempeño competitivo, con precisión global y valores de K̂ superiores a los de los otros métodos de esta categoría. Sin embargo, su rendimiento fue inferior al de RF100, especialmente en el Módulo XII.
Estudios previos concuerdan con estos resultados. Por ejemplo, Ramírez et al. (2020) reportaron valores similares de P y K̂ al utilizar RF100 en imágenes Sentinel-2 para clasificar la cobertura de suelo agrícola. De manera similar, Chen et al. (2021) obtuvieron valores de P y K̂ cercanos a los estimados en el Módulo X al mapear la superficie de maíz con imágenes multitemporales de Sentinel-2 al emplear el mismo algoritmo RF. Por su parte, Saini y Ghosh (2018) obtuvieron valores de P y K̂ parecidos a los del Módulo XII al comparar los métodos de RF y máquinas de vectores de soporte (MVS) para la clasificación de cultivos, también utilizando imágenes Sentinel-2.
Por otra parte, Guerschman, Paruelo, Bella, Giallorenzi y Pacin, et al. (2003) obtuvieron valores similares de P y K̂ al clasificar las 14 clases de cobertura de suelo, incluidos maíz y soya, al utilizar imágenes Landsat TM con el algoritmo MV. Por otro lado, estudios posteriores han reportado valores de P superiores al 80% al clasificar los tipos de cobertura del suelo con el mismo clasificador MV e imágenes satelitales Landsat TM (Argañaraz y Entraigas, 2011) y Landsat 8 (Mahmon, Ya’acob y Yusof, 2015).
En términos generales, los valores más altos de P y K̂ se registraron el 11 de junio de 2021. Esto sugiere que las condiciones de captura de la imagen y la etapa fenológica de los cultivos pueden influir significativamente en la precisión de la clasificación. Estos resultados resaltan la robustez del algoritmo RF100 con 100 árboles de decisión (k) frente a alternativas paramétricas y no paramétricas.
Matriz de confusión y precisiones de productor y usuario de RF100
El Cuadro 5 muestra la matriz de confusión del algoritmo RF100 para el Módulo X, del día 11 de junio de 2021. La Clase 1 (Maíz forrajero) presentó una precisión de usuario (P u ) del 90.5%, lo que indica que el 100% de los píxeles clasificados como maíz forrajero fueron etiquetados correctamente, aunque 9.5% fueron erróneamente clasificados como Clase 2 (Otros cultivos) y ninguno fue identificado como Clase 3 (Vacante). En cuanto a la precisión de productor (P P ), esta fue del 75.4%, lo que implica que el 75.4% del total de los píxeles que fueron referenciados como maíz forrajero se clasificaron correctamente como maíz, el 17.7% como otros cultivos y el 6.9% como vacante.
Cuadro 5: Matriz de confusión del algoritmo Random Forest (RF) con 100 árboles de decisión (k = 100) para el módulo X (día 11 de junio de 2021).
Table 5: Confusion matrix of the Random Forest (RF) algorithm with 100 decision trees (k = 100) for module X (June 11, 2021).
| Datos de Clasificación | Datos de Referencia | ||||
| Clase 1 | Clase 2 | Clase 3 | Total | Pu | |
| Clase 1 | 7 554 | 790 | 0 | 8 344 | 90.5 |
| Clase 2 | 1 770 | 7 315 | 24 | 9 109 | 80.3 |
| Clase 3 | 694 | 805 | 620 | 2 119 | 29.3 |
| Total | 10 018 | 8 910 | 644 | 19 572 | |
| PP | 75.4 | 82.1 | 96.3 | ||
Clase 1 = maíz forrajero; Clase 2 = otros cultivos; Clase 3 = vacante (suelo denudo); Pu = precisión de usuario; Pp = precisión del productor.
Class 1 = forage maize; Class 2 = other crops; Class 3 = vacant (bare soil); Ua = user accuracy; Pa = producer accuracy.
Por otro lado, la Clase 3 tuvo la menor P u ya que del total de pixeles clasificados como Vacante el 32.8% fueron confundidos con Maíz forrajero y el 38.0% como Otros cultivos. Este nivel de error afectó significativamente la precisión global (P) del algoritmo de clasificación, que fue del 79.1 por ciento.
El Cuadro 6 muestra la matriz de confusión para RF100 aplicado al Módulo XII el mismo día (11 de junio de 2021). El Maíz forrajero reportó una P u del 90.3% y una P p del 90.1%, indicando que 90% de los píxeles fueron clasificados y referenciados correctamente como maíz forrajero. La Clase 2 tuvo el valor de P p más bajo, debido a que 21.2% de los píxeles referenciados como Otros cultivos fueron confundidos con Maíz forrajero, y el 8.4% fueron clasificados como Vacante.
Cuadro 6: Matriz de confusión del algoritmo Random Forest (RF) con 100 árboles de decisión (k = 100) para el módulo XII (día 11 de junio de 2021).
Table 6: Confusion matrix of the Random Forest (RF) algorithm with 100 decision trees (k = 100) for module XII (June 11, 2021).
| Datos de Clasificación | Datos de Referencia | ||||
| Clase 1 | Clase 2 | Clase 3 | Total | Pu | |
| Clase 1 | 8 277 | 893 | 0 | 9 170 | 90.3 |
| Clase 2 | 411 | 2 967 | 65 | 3 443 | 86.2 |
| Clase 3 | 494 | 355 | 4 075 | 4 924 | 82.8 |
| Total | 9 182 | 4 215 | 4 140 | 17 537 | |
| PP | 90.1 | 70..4 | 98.4 | ||
Clase 1 = maíz forrajero; Clase 2 = otros cultivos; Clase 3 = vacante (suelo denudo); Pu = precisión de usuario; Pp = precisión del productor.
Class 1 = forage corn; Class 2 = other crops; Class 3 = vacant (bare soil); Pu = user precision; Pp = producer precision.
Interpretación de los resultados de la clasificación
De acuerdo con los resultados de las matrices de confusión de los Cuadros 4 y 5, la Clase 1 (Maíz forrajero) mostró valores altos de P u y P p cercanos al 90% en ambos módulos, con excepción de la P p para el Módulo X, donde fue del 75.4%. La mejor precisión de P p se logró para el Maíz forrajero debido a las marcadas diferencias espectrales con respecto a las otras dos clases en la fecha de clasificación (11 de junio de 2021), ya que el maíz se encontraba entre las etapas fenológicas de panojamiento (VT) y grano lechoso (R3). En contraste, los otros cultivos (Clase 2), como el sorgo forrajero, se encontraban en buche (bota) o en grano lechoso - masoso; el algodón en floración y el nogal en desarrollo del fruto. Durante la etapa reproductiva, los cultivos sufren cambios en las propiedades ópticas (cambios en su coloración), que alteran su respuesta espectral (Paz-Pellat, Casiano, Zarco y Bolaños, 2013); situación que favoreció la separación entre las clases en esta fecha.
Además, las diferencias en la cobertura del suelo de los cultivos contribuyeron a su separación. El maíz forrajero, que alcanzó un valor del índice de área foliar (IAF) de 5, tiene una mayor cobertura que los otros cultivos (Montemayor-Trejo et al., 2012; Delgado-Ramírez et al., 2023), qué facilitó su diferenciación en las imágenes satelitales. Por el contrario, la baja precisión de P p en el Módulo X se debió a la confusión entre las Clases 1 y 2, ya que sus respuestas espectrales son muy similares en esa fecha de clasificación. El valor de P u para la Clase 1 en ambos módulos de riego reveló la clasificación del maíz forrajero fue la más confiable.
Algunos autores han reportado valores similares de P u para clasificar el maíz forrajero al utilizar el algoritmo RF y datos de imágenes satelitales Sentinel-2, con bandas de resolución espacial de 10 y 20 m (Akbari et al., 2020). Incluso, Abubakar et al. (2020) lograron valores de P u y P p superiores al 90% al mapear campos de maíz.
Mapas de cultivos generados
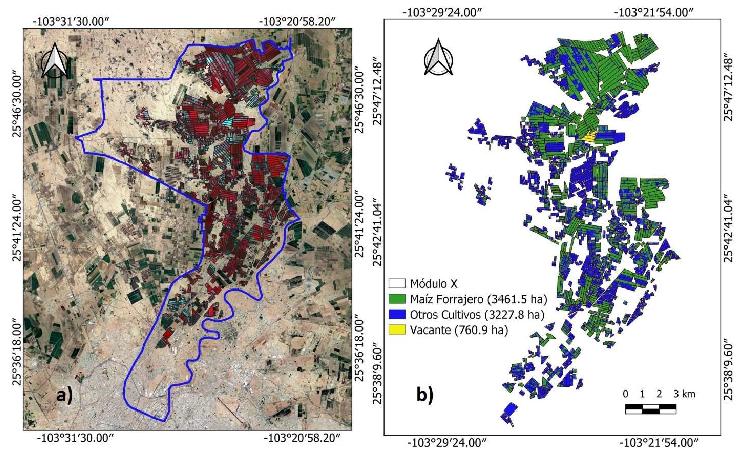
La Figura 2 muestra el mapa de clasificación de cultivos para el Módulo X generado con el algoritmo RF100. Los valores más altos de P (79.1) y K̂ (0.63) se obtuvieron con este clasificador, en la fecha de evaluación del 11 de junio de 2021 (día juliano 162). El algoritmo RF100 clasificó el 46.5% de la superficie del módulo como maíz forrajero, el 43.3% como otros cultivos (sorgo forrajero, nogal, algodón y alfalfa) y el 10.2% como vacante.
Figura 2: Superficie de cultivo del Módulo X del DR 017 del ciclo PV 2021 (imagen satelital del 11 de junio de 2021): a) Mapa de composición de falso color infrarrojo con las bandas 8, 4 y 3 del satélite Sentinel-2, y b) Mapa de clasificación de cultivos generado por el algoritmo RF con 100 árboles de decisión (k).
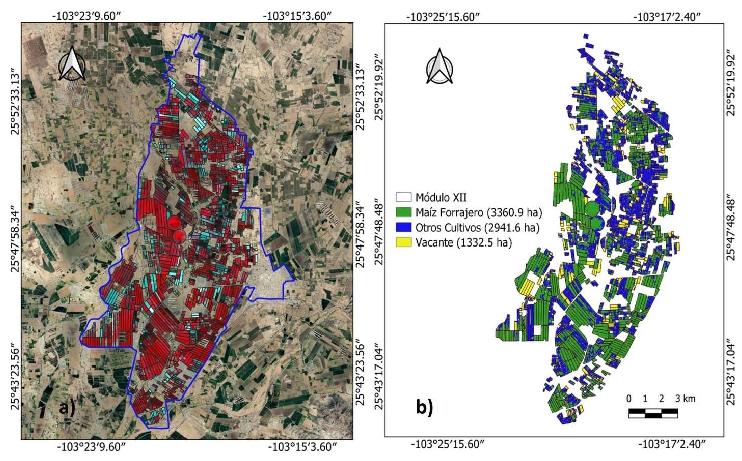
La Figura 3 muestra el mapa de clasificación de cultivos con tres clases para el Módulo XII del DR 017. Este mapa se generó con el algoritmo RF100, el cual alcanzó valores de precisión global (P) de 87.4 e índice Kappa (K̂) de 0.79 para la misma fecha (11 de junio de 2021). El RF100 clasificó el 43.9% de la superficie total como maíz forrajero, el 38.6% de otros cultivos (sorgo forrajero y nogal) y el 17.5% de áreas vacantes.
Figura 3: Superficie de cultivo del Módulo XII del DR 017 del ciclo PV 2021 (imagen satelital del 11 de junio de 2021): a) Mapa de composición de falso color infrarrojo con las bandas 8, 4 y 3 del satélite Sentinel-2 y b) Mapa de clasificación de cultivos generado por el algoritmo RF con 100 árboles de decisión (k).
Se confirma que el maíz forrajero es el cultivo dominante en términos de superficie cultivada en los módulos X y XII, que representan aproximadamente 45% del área total. Al comparar los cuatro algoritmos de clasificación supervisada utilizando imágenes Sentinel-2, el algoritmo RF con 100 árboles de decisión presentó el mejor rendimiento, que permitió identificar y mapear de manera confiable el maíz forrajero. Esta información puede facilitar la toma de decisiones en la gestión del agua a diferentes escalas, desde las unidades de producción, de los módulos o del distrito de riego.
Conclusiones
El presente estudio demostró la efectividad de los algoritmos de clasificación supervisada, con base en la información espectral contenida en imágenes de los satelitales Sentinel-2, que permitieron identificar el cultivo de maíz forrajero en los módulos de riego X y XII del distrito de riego 017, Región Lagunera. De los cuatro algoritmos evaluados, Random Forest con un parámetro k de 100 árboles de decisión mostró el mejor rendimiento, al alcanzar los valores más altos de precisión global e índice Kappa en ambos módulos de riego, lo que resalta su robustez frente a alternativas paramétricas y no paramétricas. El Módulo X presentó valores de precisión global de 79.1% e índice Kappa de 0.63, mientras que en el Módulo XII se registraron valores del 87.4% de precisión global y 0.79 de índice Kappa.
La imagen del 11 de junio de 2021 permitió obtener las mayores precisiones, debido a que la fenología del maíz forrajero y las diferencias en la cobertura vegetal entre los cultivos facilitaron su discriminación, siendo el maíz forrajero el que tuvo la mayor cobertura del suelo. Los resultados mostraron que la clasificación del maíz forrajero fue la más confiable en comparación con las demás clases evaluadas.
Además, se cuantificó una superficie irrigada de 3461.47 ha en el módulo X y 3360.86 ha en el módulo XII durante el ciclo primavera-verano de 2021, valores que superaron ampliamente la superficie programada en ambos módulos de riego. La identificación precisa del maíz forrajero, tanto en el espacio como en el tiempo, permite la creación de inventarios confiables y actualizados, lo que contribuye significativamente a mejorar la toma de decisiones en la planificación y manejo del cultivo, así como en la gestión eficiente de los recursos hídricos.

