












 (pdf)
(pdf)




 SciELO
SciELO  SciELO
SciELO 
 Permalink
PermalinkAbreviaturas:
IA |
Inteligencia Artificial |
InChI |
Identificador Químico Internacional |
PCA |
Análisis de Componentes Principales |
SMILES |
Especificación de Introducción Lineal Molecular Simplificada |
RNA |
Redes Neuronales Artificiales |
t-SNE |
Encaje Estocástico de Vecinos t-Distribuido. |
Introducción
La Quimioinformática (Figura 1) es una disciplina cuyo objetivo es la aplicación de los recursos informáticos para resolver problemas en Química (Gasteiger, 2020; Miranda-Salas et al., 2023). Estos problemas o aplicaciones abarcan frecuentemente: i) la falta de organización de la información en bases de datos moleculares (p. ej., quimiotecas) que facilite su búsqueda, acceso y actualización; este proceso es relevante y un desafío por el incremento exponencial de los datos químicos; ii) el análisis de las relaciones que hay entre las estructuras químicas y una o varias propiedades de interés (por ejemplo, el sabor, las propiedades biológicas, farmacéuticas o farmacológicas, etc.) de nuevos compuestos o de compuestos químicos existentes, y iii) la predicción de propiedades a partir de relaciones complejas. A su vez, la predicción de propiedades está directamente relacionada con otras dos acciones muy comunes en la Quimioinformática: A) diseñar nuevos compuestos de novo; y B) filtrar colecciones de compuestos conocidos para seleccionar los que tienen las propiedades deseadas; esta es una práctica empleada durante varios años, pero en constante mejora y optimización, conocida como cribado (del inglés, screening), tamizaje o evaluación computacional de bases de datos moleculares.
La Figura es de Creatividad Personal.
Figura 1 Aplicaciones de la química informática en la química de los alimentos.
La “Informática de la Química de Alimentos” (FoodInformatics) es una subdisciplina definida como la aplicación de métodos informáticos para resolver problemas en el campo de la Química de Alimentos. Entre sus aplicaciones están la sistematización de la información en bases de datos de compuestos químicos alimentarios, así como el análisis y la predicción de sus relaciones estructura-propiedad (por ejemplo, el sabor, el olor y las actividades biológicas, etc.). Actualmente, se habla por ejemplo de un diseño racional de odorantes contenidos en los alimentos o que se pueden utilizar de forma segura como aditivos alimentarios. El campo de la Informática en la Química de Alimentos comenzó su desarrollo en las últimas décadas; las primeras revisiones datan del año 2009 (Martínez-Mayorga & Medina-Franco, 2009), así como un estudio quimioinformático de los compuestos GRAS (Generally Recognized as Safe, Aditivos de Alimentos considerados Seguros) (Martínez-Mayorga, Peppard, López-Vallejo, Yongye & Medina-Franco, 2013); sin embargo, es alrededor del año 2014 que empieza a formalizarse y está en vías de una consolidación (Martínez-Mayorga & Medina-Franco, 2014).
El objetivo del presente artículo es discutir las bases de la Quimioinformática, la Inteligencia Artificial (IA) (Tseng, Chuang & Appell, 2023), y la Inteligencia Aumentada (Saldívar-González, Fernández- de Gortari & Medina-Franco, 2023) aplicadas al estudio de los compuestos químicos presentes en los alimentos.
Conceptos generales del estudio químico de los alimentos
Los primeros estudios modernos en el campo de la Química de Alimentos se remontan al siglo XIX, cuando algunos científicos de la época se interesaron en los componentes de los productos alimenticios. Entre ellos Justus von Liebig, quien, al realizar un análisis bioquímico, dividió a los alimentos en plásticos (nitrogenados o proteicos) y respiratorios (almidón, azúcar, gomas y grasas), reconoció su importancia en la alimentación y lo relevante de respetar determinadas proporciones. Desde entonces, el conocimiento sobre los alimentos continúa su progreso (Boatella, 2017). A continuación se da una breve descripción de los distintos grupos moleculares presentes en los alimentos.
Macronutrientes y nutrición
Los macronutrientes son compuestos químicos con aporte nutricional consumidos en cantidades significativas en la alimentación. Estos incluyen carbohidratos, proteínas y grasas, como fuentes de energía; son los componentes básicos de las células; además del agua, el oxígeno, la fibra y los elementos como el calcio, el magnesio, el sodio, el potasio y el cloro, fundamentales para la vida pero que no proporcionan energía. El análisis de los macronutrientes y su importancia en la nutrición humana ha sido objeto de una exhaustiva investigación científica, cuyo resultado es un entendimiento profundo de los elementos esenciales de la dieta que respaldan la vida y la salud; son los componentes dietéticos básicos de nuestra alimentación con una función central en la regulación de los procesos fisiológicos vitales.
La importancia de los macronutrientes va más allá de su valor calórico. Se extiende a las complejas vías metabólicas y las interacciones bioquímicas en el organismo. Por tanto, comprender en profundidad las propiedades químicas y estructurales de los macronutrientes resulta esencial para apreciar el impacto significativo que tienen en la nutrición y en la salud (Caballero, Trigo & Finglas, 2003).
Micronutrientes y productos naturales (metabolitos secundarios)
Los micronutrientes son minerales como el cobre, el zinc y el hierro, además de todas las vitaminas, que se consumen en pequeñas cantidades, pero su papel es crucial en la salud y el bienestar. Su presencia en los alimentos es un tema de gran interés en las ciencias de la nutrición y de la salud (Streit, 2023).
Los alimentos también contienen productos naturales, estos son compuestos químicos conocidos como metabolitos secundarios, por lo general con actividad biológica e impacto en la salud. Los productos naturales atraen cada vez más la atención por su diversidad química y su bioactividad, lo que resulta en una exploración a profundidad tanto de sus funciones como de una posible aplicación. Estos esfuerzos buscan aprovechar su utilidad como ingredientes en los productos alimenticios, por sus compuestos bioactivos para el ámbito de la nutrición e incluso para el ámbito farmacéutico. Un ejemplo es la cafeína, cuyo quimiotipo se ha utilizado en el diseño de inhibidores para distintas áreas terapéuticas (Faudone, Arifi & Merk, 2021). Las funciones versátiles que tienen los productos naturales subrayan su importancia y las diversas oportunidades que ofrecen para mejorar la salud, la nutrición y el bienestar (Romano & Tatonetti, 2019; Saldívar-González, Aldas-Bulos, Medina-Franco & Plisson, 2022).
Biotransformaciones y metabolitos
La biotransformación es un proceso metabólico fundamental que ocurre principalmente en el hígado y que tiene como objetivo facilitar la eliminación de sustancias, ya sean de origen externo (exógenas) o interno (endógenas). Este proceso implica una serie de reacciones químicas que modifican las estructuras moleculares de estas sustancias. La biotransformación es esencial para regular y eliminar compuestos químicos del cuerpo, contribuyendo a mantener un equilibrio en la función y la salud del organismo (Almazroo, Miah & Venkataramanan, 2017).
El análisis y predicción del perfil de los metabolitos en diversos grupos de pacientes es esencial para obtener información de los factores que inciden en la salud, como la progresión de la enfermedad y el metabolismo de los fármacos. En este ámbito, Xusheng Chen y autores propusieron tres metabolitos de los ácidos grasos como biomarcadores relacionados con la reducción de la eficacia de los medicamentos basados en el platino para combatir el cáncer de vejiga. En situaciones como esta son necesarias las herramientas que ofrece la Quimioinformática para determinar las causas de la reducción de la efectividad del medicamento (Chen, Zhang, Liao & Zhao, 2023; Ghosh, Zhang, Ghosh & Kechris, 2020).
La relación entre los alimentos y la Epigenética
La Epigenética estudia la regulación de la expresión de los genes más allá de su secuencia. Los factores que afectan su regulación están relacionados con la etapa de desarrollo del organismo y sus condiciones de exposición, como variables ambientales, la alimentación o la actividad física (Dupont, Armant & Brenner, 2009).
En el campo de la nutrición, la Epigenética tiene una importancia excepcional, pues es conocido que los nutrientes y componentes bioactivos de los alimentos pueden modificar los fenómenos epigenéticos y alterar la expresión de los genes a nivel transcripcional (Açar & Akbulut, 2023; Juárez-Mercado, Avellaneda-Tamayo, Villegas-Quintero, Chávez-Hernández, López-López & Medina-Franco, 2024; Voruganti, 2023). Un ejemplo clásico de cómo la alimentación puede afectar a la Epigenética es el caso de las abejas. Este insecto utiliza la alimentación para definir el desarrollo entre una abeja reina y obrera: las abejas reinas son alimentadas con jalea real mientras que las obreras son alimentadas con una mezcla de polen y néctar. Asimismo, en humanos se sabe que compuestos como la vitamina B12 presente en carnes, pescado, huevo o leche, es uno de los cofactores esenciales en los procesos epigenéticos como la metilación (Choi & Friso, 2010).
Nutracéuticos
La Nutracéutica está en desarrollo y rápido crecimiento gracias a la creciente conciencia de los posibles beneficios de los suplementos dietéticos utilizados en conjunto con los tratamientos farmacológicos (Tambe, Jain, Amin, Mali & Cruz, 2023). Se denomina nutracéutico en este contexto a los compuestos químicos de alimentos o derivados que ofrecen beneficios fisiológicos, normalmente de tipo preventivo o coadyuvando a terapias farmacológicas (Chopra et al., 2022).
Para algunas personas, la incorporación de los nutracéuticos en su dieta es una forma de lograr una alimentación saludable. No obstante, el desarrollo y el uso de los nutracéuticos forman parte de un debate más amplio sobre cómo las personas adaptan su patrón de alimentación en el contexto de condiciones ambientales cambiantes, estilos de vida en evolución y el creciente intercambio global de ideas y productos (Heinrich, 2019).
Introducción a la Ciencia de Datos e IA para el estudio químico de los alimentos
La IA comprende un vasto campo de trabajo acerca de la comprensión y la construcción de máquinas inteligentes, que calculen cómo actuar de forma efectiva y segura en una amplia gama de situaciones (Russell, Russell & Norvig, 2020). El primer trabajo en IA moderna es el de Warren McCulloch y Walter Pitts en 1943, sobre el modelado matemático de neuronas artificiales (McCulloch & Pitts, 1943). Desde entonces la IA continúa en evolución dividiéndose en subdisciplinas como: la IA simbólica, los sistemas expertos, el aprendizaje automático (machine learning) y más reciente, con la explosión en la capacidad de cálculo, el aprendizaje automático profundo (deep learning); actualmente todas muestran su gran utilidad y versatilidad a la hora de resolver una amplia gama de tareas. Este progreso se ha visto a su vez acompañado por un aumento exponencial en la cantidad, la variedad y la velocidad con la que se generan datos, dando lugar a lo que se conoce como Big Data (Zhu, 2020). Sin embargo, el crecimiento ha superado los recursos para procesar y analizar la información con eficacia, lo que deja en muchos casos a los métodos tradicionales limitados o insolventes, y plantea el reto de desarrollar metodologías más útiles.
El nacimiento de la Ciencia de Datos se da en este contexto por tratarse de una disciplina con herramientas y técnicas que extrae el conocimiento a partir de cantidades masivas de información, y con apoyo de la Estadística (Donoho, 2017). Por primera vez en los años sesenta John Tukey la definió (Tukey, 1962). Es un área con la ventaja competitiva que ofrece el aprendizaje automático para detectar patrones complejos y relaciones no lineales, llevando a término tareas de clasificación, regresión o de detección de anomalías (Donoho, 2017).
Es de reciente aparición el término “Inteligencia Aumentada” para referirse a la asociación entre los métodos y con las ventajas de funcionar con la creatividad, la intuición y el criterio humano (IA + IH) (Bazoukis, Hall, Loscalzo, Antman, Fuster & Armoundas, 2022; Saldívar-González et al., 2023).
Ejemplos de aplicaciones recientes de la IA al estudio químico de los alimentos
En la primera década de este siglo, se empezó a popularizar el uso de técnicas de aprendizaje automático y Ciencia de Datos en el campo de la Química de Alimentos. Algunos ejemplos de esto son: i) el trabajo de un análisis descriptivo de las características moleculares del espacio químico de los compuestos responsables de los efectos sensoriales como el olor y el sabor (Ruddigkeit & Reymond, 2014).; ii) el propuesto por H. Hopfer y autores, centrado en medir las alteraciones de las propiedades organolépticas del vino en función de la temperatura y el método de conservación (Hopfer, Buffon, Ebeler & Heymann, 2013). En el mismo ámbito se desarrolló una métrica para cuantificar las cualidades odorantes de los compuestos químicos con base en sus descriptores moleculares (Haddad, Khan, Takahashi, Mori, Harel & Sobel, 2008) y iii) la publicación de Sprous y Salemme, interesados en detectar las cualidades que compartían las moléculas responsables del sabor y de los fármacos (Sprous & Salemme, 2007).
A medida que avanzó la segunda década del año 2000, surgieron métodos de aprendizaje profundo con aplicación en investigación en la Química de Alimentos, de la mano de librerías de programación de libre acceso como Tensorflow o Pytorch; seguida de propuestas novedosas como la subdisciplina del emparejamiento de alimentos (Food-pairing). FlavorGraph es un buen ejemplo (Park, Kim, Kim, Spranger & Kang, 2021) por tratarse de un algoritmo de aprendizaje profundo cuya finalidad es sugerir combinaciones de productos alimenticios que sean equilibrados y aceptables al consumo, con base en su coocurrencia en recetas. En el ámbito culinario también se encuentra la publicación de Morales-Garzón y autores, quienes proponen un modelo basado en las representaciones de palabras (word embeddings) cuya finalidad es poder adaptar recetas de cocina a las preferencias del usuario (Morales-Garzón, Gómez-Romero & Martin-Bautista, 2021). Este tipo de funciones son muy útiles, por ejemplo, en la adaptación de alimentos a dietas vegetarianas. En lo que se refiere a la evaluación del estado de deterioro de los alimentos, la revisión de Hassan Anwar y autores presenta varios métodos de aprendizaje automático y de aprendizaje profundo para detectar las condiciones de distintos alimentos como la carne, la leche, el pescado, el café, el té, la margarina y ciertos tipos de aceites comestibles (Anwar, Anwar & Murtaza, 2023). Este tipo de algoritmos es conocido popularmente como narices robóticas.
Sin embargo, como se verá, en esta revisión, no todos los tipos de IA en la Química de Alimentos son utilizados para tareas culinarias (Tseng et al., 2023).
Bases de datos disponibles
Las bases de datos actuales son el resultado de un gran esfuerzo realizado durante la última década, ya que en años anteriores la información disponible (y gratuita) era más limitada (Martínez-Mayorga, Peppard, Ramírez-Hernández, Terrazas-Álvarez & Medina-Franco, 2014). Esto suponía un problema, ya que una de las principales dificultades al entrenar cualquier modelo de IA es la gran cantidad (y calidad) de datos que son requeridos (Martínez-Mayorga, Rosas-Jiménez, González-Ponce, López-López, Neme & Medina-Franco, 2024). En la actualidad existen numerosos repositorios de acceso abierto, y de acuerdo al tipo de información que contienen, se dividen en tres grupos (Tseng et al., 2023): i) bases de datos con información sobre la composición química de los alimentos, incluyendo nutrientes, compuestos bioactivos y compuestos tóxicos; ii) bases de datos con información sobre los compuestos químicos presentes en los alimentos, incluyendo su estructura química, propiedades y función; por último, iii) los repositorios con información de las moléculas que contribuyen al sabor y olor de los alimentos. La Tabla I resume las bases de datos públicas más conocidas en la Química de Alimentos.
Tabla I Ejemplos de bases de datos de acceso libre más comunes en la Química de Alimentos (modificado de Tseng et al., 2023).
| Base de datos | Tipos de base de datos | Descripción |
|---|---|---|
| FoodData Central | Composición de los alimentos. | Creada y en mantenimiento por el Departamento de Agricultura de los Estados Unidos. Debe su origen a la fusión de cinco bases de datos. Contiene información nutricional detallada de la composición de una amplia variedad de alimentos. |
| FooDB | Composición de alimentos y de los compuestos químicos. | Contiene datos de la composición y los compuestos químicos de los alimentos. |
| FlavorDB | Propiedades organolépticas. | Registra los compuestos que contribuyen a los sabores y aromas de los alimentos. |
| InFoods | Composición de los alimentos. | Permite obtener detalles de la composición de los alimentos segmentada por continentes y países. |
| EuroFIR | Composición de los alimentos. | Refiere al contenido energético de los macronutrientes, los minerales y las vitaminas presentes en los alimentos. |
| BitterDB | Compuestos químicos y propiedades organolépticas. | Aporta conocimiento de los compuestos amargos según diferentes criterios. Incluye otras funciones como la exploración de receptores humanos del sabor amargo, entre otras. |
| VirtualTaste | Compuestos químicos y propiedades organolépticas. | Además de ser una base de datos del sabor de los compuestos naturales y de las drogas, también tiene un modelo capaz de asignar un sabor a un compuesto químico. |
| ChEMBL/PubChem/ChemSpider | Compuestos químicos y actividades biológicas | Aunque no presenta información química específica de los compuestos alimenticios, los incluye, como son: su estructura, sus propiedades físicas, cinética molecular, actividad química e interacción con las proteínas, entre otras. |
A pesar de los grandes avances logrados en los últimos años, es notoria la necesidad de aumentar el contenido de las bases de datos confiables y de acceso abierto para acelerar el avance en el campo de la Quimioinformática de alimentos, y robustecer la simbiosis entre los trabajos en IA y el acceso abierto (Miljković & Medina-Franco, 2024). Esto se evidencia al compararlo con la cantidad y el tamaño de las bases de datos que existen para el estudio de los productos naturales (Sorokina & Steinbeck, 2020).
Aplicaciones de la Quimioinformática y la Química Computacional
Tan amplio como la Química aplicada al estudio de los alimentos, o el avance de la Ciencia de Datos en las últimas décadas, son las herramientas que presenta la Quimioinformática en su versatilidad, en su aplicación y en sus ejemplos de éxito. En esta sección se describen conceptos clave de la Quimioinformática, que son utilizadas en la Química de Alimentos.
¿Qué es la Quimioinformática?
El desarrollo de la ciencia aporta una cantidad considerable de datos experimentales, de parámetros y de resultados, así como de cálculos teóricos. En Química, son ejemplos de lo anterior, las condiciones de una reacción y sus correspondientes resultados en rendimiento y especificidad, el desplazamiento químico de una señal en resonancia magnética nuclear para sustancias químicas homólogas, la energía libre de Gibbs calculada para un conjunto de átomos, o una actividad celular específica con relación a un estímulo. El almacenamiento, tratamiento y procesamiento de los datos es lo que permite extraer información de forma inductiva a partir de ellos. La búsqueda de patrones y el modelado estadístico necesita por tanto de la construcción y mantenimiento de las bases de datos. Estos procesos son a lo que se denomina Informática. Cuando la información está relacionada con la Química, se habla de Química Informática o Quimioinformática. Así mismo, por medio de la generalización de la información obtenida a partir de los datos, es posible la construcción de modelos y teorías, que se transforman en conocimiento. El término “Quimioinformática“ lo usó por primera vez Frank Brown en el año 1998, definido como la “mezcla de recursos informáticos para transformar los datos químicos en información y la información en conocimiento, con la pretensión de tomar mejores decisiones y rápidamente” (Brown, 1998). Si bien, originalmente se aplicó de forma específica al diseño y descubrimiento de fármacos, actualmente se ha extendido a otras áreas como la síntesis orgánica, la Química Analítica y la Química de los Alimentos, entre otras aplicaciones (López-López, Bajorath & Medina-Franco, 2021).
La Quimioinformática se traslapa de forma importante con disciplinas como la Química Computacional, la Quimiometría, y la Bioinformática, pero utiliza representaciones específicas, así como métodos y herramientas propias que la diferencian de las demás. Los objetivos y alcances de la Quimioinformática son marcadamente distintos a los otros campos mencionados (López-López et al., 2021).
Un desarrollo didáctico y en español de las herramientas abordadas en este artículo puede consultarse en su versión en línea (Saldívar-González et al., 2024).
¿Cómo las computadoras ven e interpretan las moléculas?
Quienes desarrollan y emplean la Química, han armonizado la representación de los compuestos a lo largo de los años. Se han utilizado abreviaturas para simbolizar los átomos de un elemento en particular, ubicadas en vértices de grafos, así como líneas que representan la conectividad y las propiedades del enlace químico, además de describir la disposición de los electrones en el enlace. Sin embargo, un problema más complejo es la representación molecular adecuada para que sea interpretada por las computadoras con el fin de que la modifiquen y la usen en diferentes tipos de cálculos (David, Thakkar, Mercado & Engkvist, 2020). Esta representación consiste en un proceso y lenguaje estandarizado y sistemático para ingresar la información, procesarla y almacenarla, cubrir diferentes propiedades de las moléculas como su conectividad, su disposición tridimensional, sus cargas y sus propiedades fisicoquímicas, entre otras (ver Figuras 2A a 2D). Las representaciones deben ser compactas para almacenar una gran cantidad de datos moleculares, que permitan el acceso rápido en las búsquedas entre grandes cantidades de información. A pesar de que las primeras aproximaciones a una representación legible por computadoras estuvieron enfocadas al trabajo con moléculas orgánicas pequeñas (menores a 1,000 Da = 1,000 g * mol-1), actualmente se han hecho comunes las que representan macromoléculas como los macrociclos, los péptidos, las proteínas y las reacciones químicas. Esto favorece las aplicaciones computacionales como las ciencias ómicas, la Bioinformática y el modelado de proteínas para el desarrollo y descubrimiento de fármacos.
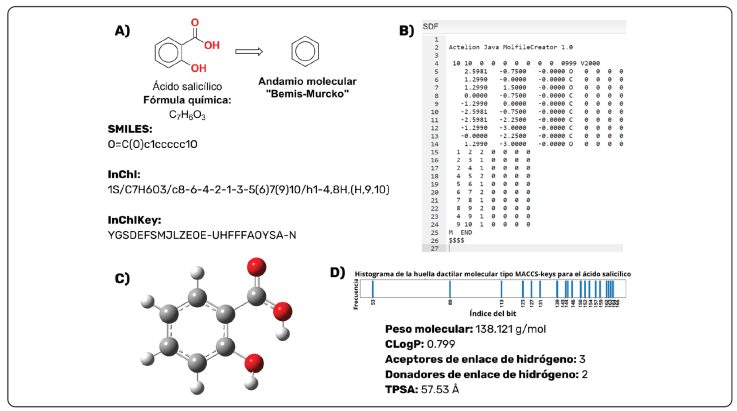
La Figura es de Creatividad Personal.
Figura 2 Representaciones moleculares comunes en química computacional y quimioinformática. (A) representaciones unidimensionales y bidimensionales. (B) representación tipo Ctab en formato SDF. (C) representación tridimensional para modelado molecular. (D) representaciones unidimensionales de tipo huella dactilar molecular (fingerprint) y descriptores moleculares.
Grafos moleculares
Si bien la representación gráfica de las moléculas se realiza a través de notaciones o fórmulas condensadas, a través de múltiples formatos, la representación de las moléculas en las computadoras se da internamente en forma de grafos moleculares del tipo G = (V, E). Esta aproximación coincide con la imagen habitual que tiene un químico de la estructura molecular. Los grafos moleculares están compuestos por nodos V y aristas E. Cada uno de los nodos determina la naturaleza del átomo, por ejemplo, a modo de número atómico, e incluye propiedades como el tipo de enlaces que puede adoptar, las coordenadas tridimensionales, la carga, la configuración isotópica o la quiralidad. Las aristas, por su parte representan la conexión entre los nodos del grafo y representa al enlace químico en las moléculas. Sin embargo, la naturaleza del enlace no está descrita por la arista en sí misma, sino por las propiedades del nodo. El orden de procesamiento del grafo es determinado a través de diferentes algoritmos de la teoría de grafos, que de forma consistente dan lugar a la misma molécula. Para esto, diferentes arquitecturas de algoritmos de lectura son implementados por los programas de procesamiento de información química disponibles en la actualidad (Bondy & Murty, 1976). La Figura 2A es un ejemplo de una representación bidimensional de tipo grafo para la molécula de ácido salicílico.
Si bien el grafo es un tipo de formato descriptivo y específico que representa la estructura de una molécula en aplicaciones computacionales, el tamaño de las moléculas con las que trabaja de forma óptima es limitado debido a un alto uso de recursos de cómputo (procesamiento) y de almacenamiento (memoria y espacio en el disco). Además, no todas las moléculas pueden ser representadas por grafos moleculares.
Tablas de conectividad y archivos tipo MOL
En contraste a los grafos moleculares, las tablas de conectividad (Ctab) consisten en seis matrices que describen diferentes características de las moléculas como son: la identidad elemental de los átomos que la componen, los enlaces químicos presentes y su naturaleza, las coordenadas espaciales bidimensionales o tridimensionales (calculadas o experimentales), el conteo de los átomos y enlaces, atributos específicos de un átomo o enlace (quiralidad, tridimensionalidad del enlace, etc.), y los atributos específicos de la molécula como la carga formal (Figura 2B). Regularmente los átomos de hidrógeno se mantienen implícitos por medio de un modelo de valencia, en que aparecen como propiedades del resto de los átomos (Hanson, 2017). Las tablas de conectividad se han convertido en el formato estándar de uso de la computadora para representar las estructuras químicas, y son la base de los archivos tipo Mol (David et al., 2020). A medida que se resuelven las necesidades emergentes en la representación molecular de los sistemas más complejos, se desarrollan nuevas versiones (y herramientas de software para interpretarlas), como son: MOL III, capaz de representar múltiples moléculas, o MOL V, que puede representar estructuras aromáticas que hacen explícita la conjugación presente. Para el formato MOL XII es posible especificar inequívocamente moléculas con quiralidad, tautomerismo, o resonancia en subestructuras no aromáticas (Hanson, 2017).
Notación lineal
Las representaciones descritas en las secciones anteriores requieren un alto consumo de espacio de almacenamiento en el disco, y su manejo a gran escala para los análisis quimioinformáticos (las bases de datos de compuestos con miles o millones de compuestos) resulta complicado y lento. A raíz de esto, se han desarrollado y estandarizado formas lineales compactas, más baratas en recursos computacionales. Las más comunes y ampliamente usadas son los formatos de Especificación de Introducción Lineal Molecular Simplificada (SMILES, por su nombre en inglés, Simplified Molecular Input Line Entry Specification), (Weininger, 1988) y el Identificador Químico Internacional (InChI, por su nombre en inglés, International Chemical Identifier), (Heller, McNaught, Pletnev, Stein & Tchekhovskoi, 2015), o la versión abreviada de este último, el formato InChIKey (Southan, 2013), (ver Figura 2A).
Los SMILES, introducidos por Weininger en 1988, son un sistema que abrevia la conectividad entre los átomos de forma lineal, en que se especifica con números el inicio y el final de una estructura cíclica, y usa letras minúsculas para las subestructuras aromáticas. Consiste en un sistema legible e intuitivo para las personas, pero no es unívoco por depender del orden en que se numeran los átomos en la estructura. Este formato permite especificar enlaces dobles y triples, quiralidad, multiplicidad de grupos funcionales y estados de carga formal. Además es legible por diferentes librerías quimioinformáticas, como RDKit (Landrum, s/f) y MolVS (Swain, s/f). Los SMILES pueden ser transformados a un formato unívoco por medio de diferentes métodos (Weininger, 1988). El más usado actualmente consiste en enumerar la estructura a partir del InChI, que sí es una descripción única.
El formato InChI apareció en el año 2006 como una respuesta al llamado de la Unión Internacional de Química Pura y Aplicada (IUPAC, por sus siglas en inglés) para la creación de una notación estándar de uso informático que fue realizado en el año 1949 (Division of Chemistry and Chemical Technology, 1964). Consiste en un sistema de código abierto para simbolizar moléculas en cadenas de texto de 1D. La codificación está dividida en capas (p. ej. la principal, de estereoquímica, de información isotópica) y cada capa en bloques (Heller et al., 2015). En el caso de la capa principal, por ejemplo, contiene la información de la fórmula química, la conectividad atómica y los átomos de hidrógeno. En esta notación, cada código es único, a diferencia de los SMILES.
Los InChIKey son códigos de veintisiete caracteres que resumen a la capa principal, la de estereoquímica e isótopos, y los protones presentes, generados a partir de un proceso matemático del InChI, diseñados para ser identificadores y estructuras únicas de las moléculas (Southan, 2013). Sin embargo, se pueden presentar ambigüedades en su uso, por lo que no necesariamente es posible regresar al InChI a partir del InChIKey, y aún con menos frecuencia al grafo molecular (Pletnev, Erin, McNaught, Blinov, Tchekhovskoi & Heller, 2012).
Andamios moleculares
Este tipo deriva del término en inglés, molecular scaffold, definido como el sistema cíclico base de la molécula junto con sus conectores, y busca generalizar algunas características presentes en todo el grupo de compuestos químicos que lo contienen. Estas características comprenden propiedades fisicoquímicas, biológicas (p. ej. bioactividad), etc.
Se han desarrollado aproximaciones para el análisis de los andamios moleculares (Langdon, Brown & Blagg, 2011), la más usada es la de Bemis y Murcko (Figura 2A). Consiste en romper todos los enlaces alquílicos de la molécula, para conservar los sistemas de anillos, así como los conectores entre ellos; es decir que todas las cadenas laterales de los ciclos son eliminadas, quedando únicamente los sistemas cíclicos con sus conectores (Bemis & Murcko, 1996).
Propiedades y descriptores
Posterior a representar una estructura química para que sea registrada por una computadora, se describe numéricamente por medio de “descriptores” que capturan cuantitativamente parte de la información o características de la molécula. Por ejemplo, su tamaño, el volumen (total y polar), la flexibilidad, la energía, la solubilidad o la lipofilicidad (ver Figura 2D). Si bien algunos de los descriptores se miden experimentalmente (por ejemplo, la solubilidad en agua), otros se calculan de forma computacional. Ejemplos de descriptores comunes usados en la Quimioinformática pueden clasificarse en: A) constitucionales; B) fisicoquímicos (Lipinski, Lombardo, Dominy & Feeney, 1997); C) cuánticos (Grisoni, Ballabio, Todeschini & Consonni, 2018; Todeschini, Consonni, Mannhold, Kubinyi & Folkers, 2010); D) huellas digitales moleculares (Yang, Cai, Zhao, Xie & Chen, 2022); y E) indicadores compuestos, como de compuesto tipo fármaco (Gleeson, 2008; Hughes et al., 2008; Shultz, 2013, 2014; Tian, Wang, Li, Li, Xu & Hou, 2015; Veber, Johnson, Cheng, Smith, Ward & Kopple, 2002), de compuesto tipo producto natural (Ertl, Roggo & Schuffenhauer, 2008), y la perspectiva de desarrollo del indicador de compuesto tipo alimento.
Los diferentes descriptores para la medición y el cálculo dependen de los objetivos del estudio o del propósito por el que se van a utilizar (Sheridan & Kearsley, 2002); seleccionarlos está en función de la naturaleza de las moléculas (p. ej., moléculas orgánicas pequeñas, péptidos, macrociclos, compuestos inorgánicos, organometálicos, etc.) y la cantidad de moléculas por analizar (la duración del cálculo es proporcional al tamaño, a la cantidad de compuestos y a la capacidad de cómputo invertida) (Medina-Franco, Sánchez-Cruz, López-López & Díaz-Eufracio, 2022b). En la mayoría de las aplicaciones de la Quimioinformática están involucradas cientos, miles o millones de estructuras, por lo que se utilizan huellas digitales moleculares (Yang et al., 2022).
Diversidad química
La diversidad química en las quimiotecas se emplea para cuantificar el grado de diferenciación de los compuestos presentes. Esto se logra a partir de diferentes métricas relacionadas con el concepto de similitud química. La similitud consiste en cuantificar las propiedades comunes entre un conjunto de moléculas y es dependiente de la forma en que a estas se les describe (representación molecular), y del tipo de métrica, de función o de algoritmo que se utilice en el estudio (Maggiora, Vogt, Stumpfe & Bajorath, 2014).
La similitud química es un concepto clave de la Quimioinformática. Se espera que compuestos químicos con estructuras similares posean similares propiedades y similares actividades biológicas frente a dianas terapéuticas (Johnson & Maggiora, 1990). En los últimos años se han desarrollado diversos métodos para calcular la similitud química o molecular, relacionando el número de propiedades comunes entre dos moléculas y el total de propiedades diferentes. Este es el principio que se aplica en los coeficientes de Tanimoto (Tanimoto, s/f; Willett, Barnard & Downs, 1998), Tversky (Tversky, 1977) o Dice (Willett et al., 1998), entre otros (Maggiora & Shanmugasundaram, 2004).
La Ecuación 1 muestra el cálculo general de la similitud por medio del coeficiente de Tanimoto Tc, donde a y b son el número de características en consideración, propias de las moléculas A y B, y c es el número de características que comparten (Maggiora et al., 2014). De acuerdo con la forma de la función, el índice de similitud o coeficiente de Tanimoto puede tomar valores entre 0 y 1, donde 0 significa ninguna característica en común, y 1 es la identidad entre las dos moléculas que se están comparando.
En la descripción de bases de datos, es útil comparar la similitud acumulada (Figura 3A) de todos los compuestos presentes entre sí, con el fin de verificar su diversidad. Una base de datos diversa presenta valores cercanos a cero, por lo que la curva de similitud acumulada presenta un aumento rápido a valores pequeños. Las quimiotecas menos diversas tienen valores más grandes de similitud, por lo que la curva presenta una pendiente menos inclinada (Medina-Franco, Martínez-Mayorga, Bender & Scior, 2009).
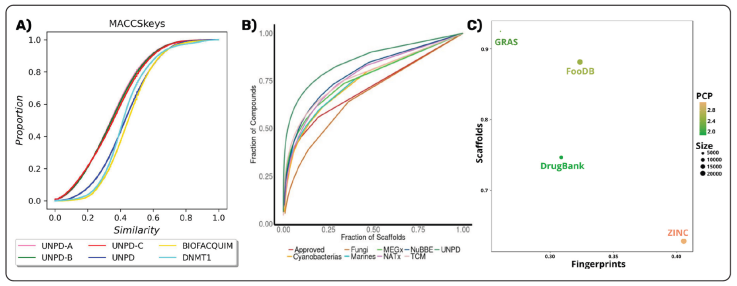
Figura 3 Ejemplos de métodos de visualización utilizados en el estudio de la diversidad química (A) Curvas de similitud acumulada (recuperado de Chávez-Hernández & Medina-Franco, 2023); (B) Curvas de recuperación de estructuras cíclicas (recuperado de Saldívar-González, Valli, Andricopulo, da Silva Bolzani & Medina-Franco, 2019); (C) Cuantificación y visualización de diversidad consenso (modificado de Naveja, Rico-Hidalgo & Medina-Franco, 2018).
Por medio del análisis de andamios moleculares, también es posible caracterizar la diversidad de estructuras presentes en una quimioteca. La presencia de pocos, o muchos núcleos base, y el porcentaje de compuestos de la base de datos que presenten cada núcleo base, evidencian el objetivo de la preparación de la base de datos, ya sea para actuar sobre una diana biológica (regularmente baja diversidad de andamios moleculares) o hacia la mayor diversidad posible (con alta diversidad de andamios). Cada uno de estos ejemplos presenta una utilidad y retos propios (Langdon et al., 2011). Para cuantificar la diversidad en función del contenido de andamios moleculares, se toman como base: la entropía de Shannon, que determina el grado de esparcimiento de los datos a lo largo de las diferentes categorías, y las curvas de recuperación de estructuras cíclicas (Figura 3B). En un sentido análogo a la visualización de la similitud acumulada, esta herramienta indica la fracción de la quimioteca que es cubierta por cierta fracción de los núcleos base presentes. Una ascendente diagonal indica una mayor diversidad y una vertical que la mayoría de los compuestos están densamente distribuidos en una pequeña fracción de los núcleos base presentes (Medina-Franco et al., 2009).
Finalmente, una aplicación desarrollada por González-Medina y autores, consistió en determinar la diversidad global de una quimioteca con base en un consenso entre varios criterios (González-Medina, Prieto-Martínez, Owen & Medina-Franco, 2016). Así, es posible corregir el sesgo existente por la representación química empleada en la cuantificación de la diversidad. Esta técnica tiene en cuenta la diversidad de los andamios moleculares, de las huellas dactilares moleculares, así como de las propiedades fisicoquímicas, mediante una reducción de la dimensionalidad que resulta intuitiva en su interpretación, y útil en la clasificación de las bases de datos. Un ejemplo de uso de este método fue la caracterización realizada por Naveja y autores de los compuestos químicos de origen alimenticio presentes en FooDB (The Metabolomics Innovation Centre, 2020; Naveja, Rico-Hidalgo & Medina-Franco, 2018) (ver Figura 3C).
Estudio del espacio químico y su visualización
En la Quimioinformática, una forma de describir, clasificar y visualizar la distribución de los compuestos químicos en una quimioteca, de acuerdo con diferentes propiedades fisicoquímicas, estructurales o mecanocuánticas, se conoce como “espacio químico”. Es decir, todo conjunto de N moléculas, caracterizado por M descriptores, es un espacio químico (Saldívar-González & Medina-Franco, 2022; Varnek & Baskin, 2011).
Por otro lado, un multiverso químico recién se describió como un conjunto de N moléculas, y al mismo tiempo por conjuntos Mi (i = 1,...,j; j > 1) de descriptores (Medina-Franco, Chávez-Hernández, López-López & Saldívar-González, 2022a). Es decir, que el multiverso químico es un conjunto de múltiples espacios químicos para un grupo de moléculas.
Adicionalmente, la representación de un conjunto de moléculas por medio de un grupo de descriptores permite visualizar cualitativa y cuantitativamente las relaciones que hay entre las moléculas. La Figura 4 es un ejemplo de diferentes visualizaciones de espacios y multiversos químicos. La Figura 4A ilustra un espacio químico usando la técnica de ChemMaps, para FooDB y otras quimiotecas (Naveja et al., 2018). ChemMaps muestra parcialmente la base de datos de interés por medio del análisis de componentes principales (PCA) de diferentes descriptores moleculares de compuestos satélites, y los que están a su alrededor a través de la similitud pareada frente a los ya representados (Naveja & Medina-Franco, 2017). Este análisis indica que los compuestos de origen alimenticio presentan una mayor diversidad en términos de sus propiedades fisicoquímicas que los productos naturales y las aprobadas para uso clínico. También se puede inferir el carácter promisorio de los compuestos químicos de alimentos para llevar a cabo campañas de cribado con el fin de encontrar nuevas moléculas bioactivas, en la confianza de que son seguros para el consumo humano (Naveja et al., 2018). En la Figura 4B se observa un multiverso químico (en este caso, dos espacios químicos alternos, cada uno de ellos con una representación molecular diferente) para dos quimiotecas de origen natural: la Base de Datos de Productos Naturales de América Latina (LaNaPDB) (Gómez-García et al., 2023), la Colección de Productos Naturales Abiertos (COCONUT, por las siglas en inglés, Collection of Open Natural Products) y una quimioteca de moléculas aprobadas para su uso clínico por la FDA, con seis propiedades fisicoquímicas de interés farmacéutico, y una reducción de componentes por medio de PCA y Encaje Estocástico de Vecinos t-Distribuido (t-SNE) (Gómez-García et al., 2023; Sorokina, Meseburger, Rajan, Yirik & Steinbeck, 2021; Van der Maaten & Hinton, 2008; Wishart et al., 2018). Este análisis permitió demostrar la complejidad de las moléculas en LaNaPDB, y que tienen propiedades similares a las de COCONUT, y su multiverso químico se traslapa parcialmente con el de los medicamentos aprobados.
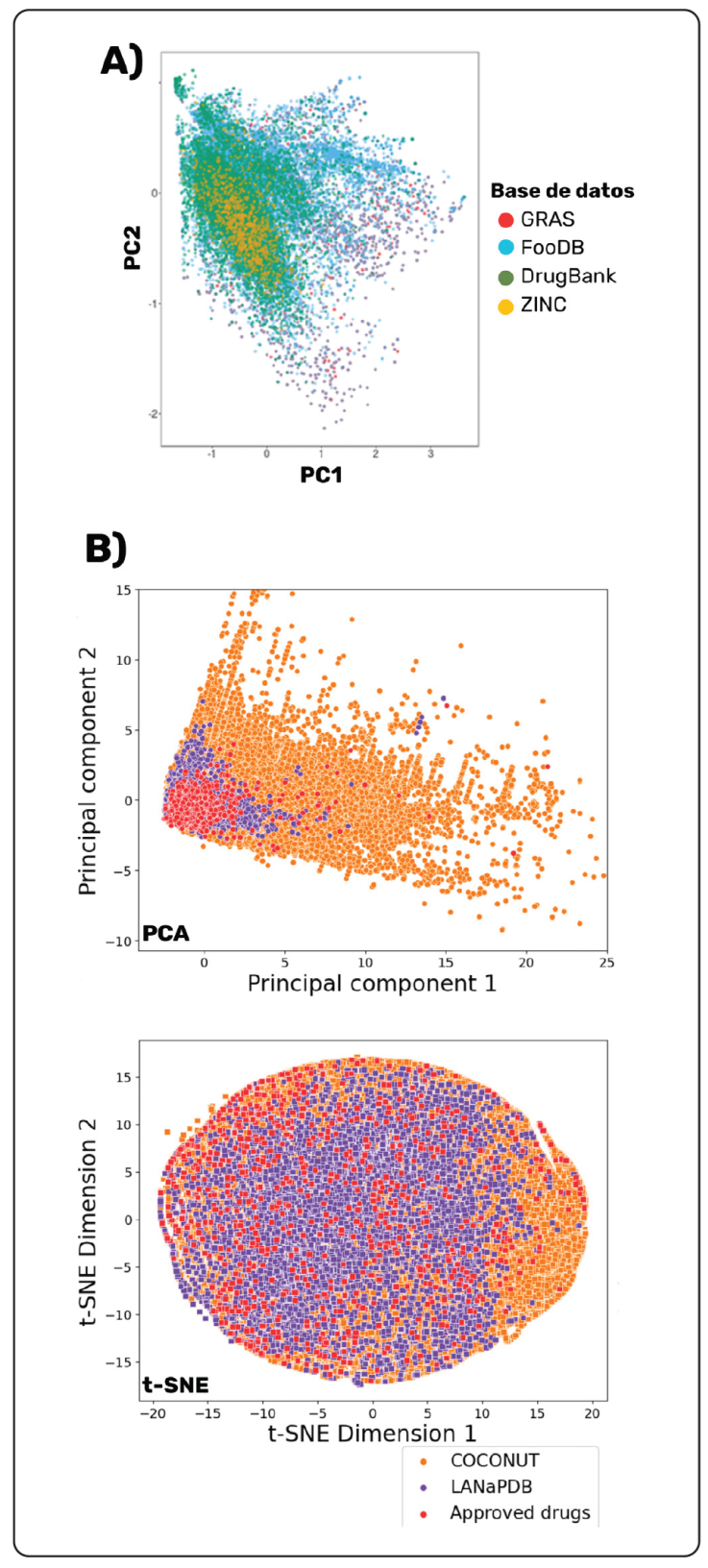
Figura 4 Ejemplo de representaciones visuales del espacio -y multiverso- químico de compuestos de alimentos. (A) ChemMaps comparativo entre FooDB , GRAS, productos naturales en ZINC y moléculas de uso clínico (recuperado de Naveja, Rico-Hidalgo & Medina-Franco, 2018); (B) PCA y t-SNE para LaNaPDB, COCONUT y medicamentos aprobados por la FDA, en términos de propiedades fisicoquímicas de interés farmacéutico (adaptado de Gómez-García et al., 2023).
Revisión de las aplicaciones y las tendencias de la Química Informática y la Inteligencia Artificial en el estudio de los alimentos
La aplicación de las técnicas de la computación, descritas en secciones anteriores (Quimioinformática, IA y Ciencia de Datos), a los compuestos de alimentos se ha ido extendiendo por múltiples vertientes en los últimos años, lo cual ha dado lugar a la acuñación del término “FoodInformatics” para describir este área de investigación. El vocablo dio título a un volumen publicado en el año 2014, con distintos trabajos en el tema (Martínez-Mayorga & Medina-Franco, 2014). Revisiones posteriores relacionadas a esta materia se publicaron en el año 2018 (Peña-Castillo, Méndez-Lucio, Owen, Martínez-Mayorga & Medina-Franco, 2018), y más recientemente, aunque centrado en las bases de datos, en el año 2023 (Tseng et al., 2023).
La temática es de interés por su aplicación: i) para el diseño de aditivos de alimentos, como conservadores (o conservantes), colorantes, odorantes, y saborizantes, así como en el diseño de nuevos ingredientes bioactivos para alimentos funcionales ii) para ayudar en la identificación del modo de acción de compuestos bioactivos de alimentos en la salud, por ejemplo, con un efecto positivo para la salud (preventivos y/o curativos), o bien para efectos indeseados (toxicidad, e interacción con los fármacos, etc.). También se han realizado estudios en los que se analiza por computadora la interacción de estas moléculas con los receptores humanos. Finalmente, la utilización de estas moléculas como fuente de quimiotipos para el diseño de fármacos, la cafeína, por ejemplo, es un paradigma pues ha sido la base para el descubrimiento de fármacos dirigidos a dianas moleculares como receptores de adenosina y fosfodiesterasas. Un ejemplo más es la celebración en el último congreso de la Sociedad Americana de Química (ACS, otoño de 2023), de dos simposios sobre: “Advances in Food Chemical Informatics, Knowledge Bases and Databases”, y “Artificial Intelligence (AI) applications for Food and Agriculture”.
En las secciones anteriores se mencionan los espacios químicos que están en las bases de datos de compuestos de alimentos como FooDB (The Metabolomics Innovation Centre, 2020), con probabilidad de ser la base de datos de compuestos de alimentos pública más completa. Naveja y autores la consultaron cuando contenía unos 24K compuestos, y observaron: i) que las moléculas presentaban una alta diversidad, tanto estructural como en sus propiedades fisicoquímicas, ii) complejidad estructural, iii) una proporción alta (~30%) de moléculas acíclicas, iv) que las moléculas con anillos eran principalmente monocíclicas, v) que comparten andamios moleculares típicos de los productos naturales (Naveja et al., 2018). Se utilizó adicionalmente el método ChemMaps para ver el espacio químico (Naveja & Medina-Franco, 2017). En una actualización de este análisis, Avellaneda -Tamayo y autores ampliaron los resultados con la versión más reciente de FooDB y obtuvieron más de 70K compuestos con las siguientes características: i) lipídicos que desplazan la tendencia de los diferentes descriptores constitucionales y fisicoquímicos hacia compuestos no polares, ii) una baja diversidad estructural entre las moléculas, iii) un traslape significativo entre los compuestos presentes en los alimentos y los aprobados para uso clínico, iv) un análisis quimioinformático de los compuestos de alimentos disponibles comercialmente (Avellaneda-Tamayo, Chávez-Hernández, Prado-Romero & Medina-Franco, 2024).
El perfil ácido/base de las moléculas en FooDB fue analizado por Santibáñez-Morán y autores con el siguiente resultado: i) un 41% de moléculas neutras, alrededor del doble que en fármacos aprobados, ii) un porcentaje comparativamente muy bajo de moléculas monobásicas 5% vs. 28% de los fármacos, iii) entre los grupos funcionales, los ácidos frecuentes fueron los fenoles (16%), los fosfatos (17%) y los carboxilatos (17%) (Santibáñez-Morán, Rico-Hidalgo, Manallack & Medina-Franco, 2019).
En el campo del mecanismo de acción de compuestos de alimentos, más recientemente se ha investigado mediante métodos computacionales la presencia de agregadores y subestructuras “problemáticas” (del inglés nuisance substructures) en la FooDB. Los primeros (agregadores) son compuestos que se agregan formando coloides que desnaturalizan proteínas, resultando en falsos positivos en los ensayos bioquímicos en los que se prueban. Las segundas (subestructuras “problemáticas”) son partes de moléculas que se ha visto que están asociadas a promiscuidad y falsos positivos en ensayos por distintos motivos: unión covalente (Kaya & Colmenarejo, 2020) identificaron en el FooDB, con 26K compuestos de alimentos, subestructuras problemáticas utilizando distintos filtros quimioinformáticos (Baell & Holloway, 2010; Blake, 2005; Hann, Hudson, Lewell, Lifely, Miller & Ramsden, 1999), así como agregadores con la herramienta Aggregator Advisor (Irwin et al., 2015). También identificaron una gran cantidad de Panaceas Metabólicas Inválidas (del inglés, Invalid Metabolic Panaceas), que son productos naturales conocidos por su capacidad biomolecular para interactuar con múltiples dianas biológicas (Bisson, McAlpine, Friesen, Chen, Graham & Pauli, 2016). Posteriormente este análisis se repitió en 71,000 moléculas, con una versión actualizada del FooDB y un modelo de aprendizaje automático, el Scam Detective, para identificar los agregadores (Sánchez-Ruiz & Colmenarejo, 2021). En el mismo trabajo también se analizaron las propiedades fisicoquímicas y la distribución de los andamios moleculares, el resultado fue ver patrones muy diferentes en los subgrupos de acilgliceroles y no-acilgliceroles de las moléculas de alimentos, tanto entre ellos como al compararlos con las moléculas del DrugBank (Wishart et al., 2018).
En otro trabajo relacionado de los mismos autores se empleó el método de predicción de dianas basado en el ligando SEA+TC (Similarity Ensemble Approach-maximum Tanimoto Coefficient) con el fin de proponer interacciones entre los compuestos de alimentos presentes en el FooDB y las proteínas humanas (Sánchez-Ruiz & Colmenarejo, 2022). También llevaron a cabo un análisis sistemático de todas las interacciones de las moléculas de alimentos con las proteínas humanas de las que sólo el 1.6% se tenía evidencia publicada; la mayoría estaban concentradas en tres grupos químicos: fenilpropanoides y policétidos, compuestos organoheterocíclicos, y bencenoides. La utilización de SEA+TC permitió prever interacciones potenciales para 64% de los compuestos en FooDB, que se hicieron disponibles como material suplementario de la publicación. Esta lista de más de 88,000 predicciones representa un conjunto de hipótesis para la realización de ensayos rápidos efectuados por grupos experimentales y con una alta probabilidad de confirmación. De hecho, mediante análisis retrospectivos de ChEMBL y acoplamiento molecular (docking) los autores lograron validar setenta y cinco de estas interacciones. Asimismo, se realizó un análisis de andamios enriquecidos por clase química y grupo de dianas.
En este mismo marco de interacciones moleculares, pero entre fármacos y compuestos de alimentos, FDMine es un buen ejemplo de modelo de grafos para predecir posibles interacciones entre los fármacos y los alimentos, con base en el FooDB y DrugBank. Este tipo de predicciones pueden ser útiles para evaluar posibles efectos sinérgicos, en que un alimento mejore el efecto de un fármaco, o lo opuesto sea en detrimento de la efectividad del medicamento (Rahman, Vadrev, Magana-Mora, Leyman & Soufan, 2022).
Un modelo de aprendizaje profundo, DeepDDI, se puso a prueba y se utilizó para predecir las interacciones fármaco-fármaco y fármaco-alimento (Ryu, Kim & Lee, 2018). En este caso, el modelo se probó a partir de los datos del DrugBank, y fue aplicado para predecir las interacciones fármaco-alimento.
Otro trabajo se basó en la previsión, por aprendizaje automático, de las interacciones entre compuestos GRAS, los ingredientes inactivos, la glicoproteína-P (Pgp) y la uridina difosfato-glucuronosiltransferasa-2B7 (UGT2B7) en las propiedades farmacocinéticas de los fármacos.
En otra área alternativa, además de volver a sobresalir los compuestos de alimentos como una fuente de fármacos, y el uso de la cafeína como homotipo, también destaca la utilidad de estos compuestos en el combate contra la COVID19 vía identificación de nuevos quimiotipos basados en los compuestos de alimentos (Juárez-Mercado et al., 2023). Por ejemplo, varios compuestos de la FooDB se propusieron como inhibidores de la proteasa principal del SARS-CoV-2 a partir de estudios de acoplamiento y de dinámica molecular (Masand, Sk, Kar, Rastija & Zaki, 2021). En otro trabajo, se utilizó una combinación de varios métodos de cribado virtual para identificar potenciales inhibidores de la misma proteína, en este caso a partir no sólo de FooDB, sino también de la base de datos de la “materia química oscura” (Dark Chemical Matter, o DCM, conjunto de compuestos de baja o nula actividad reportada) (Santibáñez-Morán, López-López, Prieto-Martínez, Sánchez-Cruz & Medina-Franco, 2020). Para el caso del cáncer, el modelo de aprendizaje automático HyperFoods se desarrolló y aplicó a los compuestos de alimentos con el fin de identificar moléculas con posible actividad antitumoral (Veselkov et al., 2019). Una reciente creación es la base de datos anotada de libre acceso con compuestos de alimentos y cuya actividad está publicada con dianas epigenéticas, en la “Epi Food Chemical Database ” (Juárez-Mercado et al., 2024) . Las moléculas pertenecían a la FooDB o a bases de datos de productos naturales como Open Natural ProdUcTs y COCONUT.
Para finalizar, hay dos trabajos con una orientación químico-analítica. Uno de ellos consiste en una revisión del campo del análisis metabolómico de compuestos de alimentos, o foodomics, a la luz de la aplicación en el mismo de nuevas aproximaciones de aprendizaje automático (Jiménez-Carvelo & Cuadros-Rodríguez, 2021). El segundo es un trabajo que usó el método de aprendizaje automático para desarrollar un clasificador multi etiqueta de olores de tres alimentos: queso, licor, y aceite comestible, con datos de lecturas de un conjunto de sensores quimioresistivos (Schroeder et al., 2019).
Conclusiones y perspectivas
En este artículo se mencionaron conceptos, procedimientos y ejemplos de uso propios de la informática, con sus respectivas aplicaciones en la Química y especialmente en la Química de Alimentos, como son: la Quimioinformática, la Ciencia de Datos y la Inteligencia Artificial. La conclusión es que el campo de la Informática de la Química de Alimentos (FooInformatics), especialmente en combinación con la Inteligencia Artificial y la Ciencia de Datos, abre perspectivas para utilizar a los compuestos de alimentos con diferente fin en: i) dietas más saludables y personalizadas, ii) alimentos con una composición óptima, para protección de la salud, cuidando el sabor, el olor, el color y la conservación, iii) diseño de nuevos fármacos y nutracéuticos, iv) minimización de interacción con fármacos, etc. El uso de este tipo de herramientas en la computación permite el ahorro de tiempo y dinero en la experimentación, así como en la racionalización y en la compresión de una gran cantidad de datos, para futuras investigaciones. Los modelos desarrollados con estas técnicas permiten la realización de “experimentos en la computadora” y la posibilidad de nuevas hipótesis con aplicación en las áreas antes citadas, además de la creación de nuevos diseños. Sin embargo, existen retos como mejorar los datos que son confiables, un indicador quimioinformático “tipo-alimento” para identificar estructuras moleculares de uso alimentario y un diseño molecular computacional de compuestos de alimentos.

