Propuesta para evaluar el proceso de adopción de las innovaciones tecnológicas*
Proposal to evaluate the process of adoption of technological innovations
Blanca Isabel Sánchez Toledano1§, Jorge A. Zegbe Domínguez1 y Agustín F. Rumayor Rodríguez1
1 Campo Experimental Zacatecas. INIFAP. Carretera Zacatecas-Fresnillo, km 24.5.A. P. 18 Calera de V. R., Zacatecas. 98500. Tel. (478) 9-85-01-98 y 9-85-01-99. (jzegbe@zacatecas.inifap.gob.mx). §Autora para correspondencia: bsanchez@zacatecas.inifap.gob.mx.
]]>* Recibido: diciembre de 2012
Aceptado: junio de 2013
Resumen
Es de importancia para las instituciones involucradas en el desarrollo del sector agropecuario conocer el grado de adopción y la velocidad con que las innovaciones tecnológicas son aceptadas por los usuarios. Es decir, cómo una novedad o innovación tecnológica deja de ser experimental y se transforma en una práctica de uso común en el sector social. Las variables de respuesta y el número de observaciones que integran las muestras bajo estudio proporcionan información valiosa por la diversidad de temas que pueden ser estudiados. Sin embargo, las variables de respuesta investigadas normalmente son expresadas en diferentes escalas cualitativas. En consecuencia, la información es analizada inapropiadamente o ésta es presentada descriptivamente. Por lo tanto, el objetivo de esta propuesta es presentar el uso de técnicas estadísticas para analizar y evaluar el proceso de adopción de innovaciones tecnológicas. La metodología que se propone incluye escalas cualitativas para analizarse con técnicas multivariadas como prueba de normalidad multivariada, análisis por componentes principales, aglomerados y correlación canónica. El uso de estas herramientas estadísticas se ejemplificó con un estudio de adopción tecnológica realizada con productores de cebada.
Palabras clave: análisis multivariado, diseño de encuesta productores de cebada.
Abstract
It is of importance to the institutions involved in the development of the livestock sector to know the extent of adoption and speed with which technological innovations are accepted by users. I.e., how a novelty or technological innovation is no longer experimental and is transformed into a practice commonly used in the social sector. Response variables and the number of observations that integrate the samples under study provide valuable information for the diversity of topics that can be studied. However, the investigated response variables are normally expressed at different qualitative scales. Therefore the information is analyzed inappropriately or it is presented descriptively. Therefore, the aim of this proposal is to present the use of statistical techniques to analyze and evaluate the process of adoption of technological innovations. The proposed methodology includes qualitative scales to be analyzed with multivariate techniques such as the multivariate normality test, principal component analysis, clusters and canonical correlation. The use of these statistical tools exemplified by a study of technology adoption made with barley producers.
]]> Key words: multivariate analysis, survey design to barley producers.
Introducción
Es de importancia para las instituciones involucradas en el desarrollo del sector agropecuario conocer el grado de adopción y la velocidad con que las innovaciones tecnológicas son adoptadas por los usuarios. Es decir, cómo una innovación tecnológica dej a de ser experimental y se transforma en una práctica de uso común en el sector social.
La adopción de una innovación tecnológica se define como el proceso por el cual el productor agropecuario sustituye una práctica de uso común por otra novedosa; esto implica un proceso de aprendizaje y cambio del sistema de producción (Seré et al, 1990). Por ejemplo, una práctica nueva o innovación tecnológica puede ser el desarrollo de un herbicida más económico y eficaz en el control de malas hierbas; otras podrían ser la generación de semilla mejoradas, una nueva raza de ganado, prácticas de prevención de incendios para el bosque, un ajuste en la fecha y densidad de siembra, maquinaria agrícola nueva, el cambio en la forma de siembra o de cosecha de un producto, entre otros (Seré et al., 1990). También, una innovación tecnológica puede estar integrada por diferentes componentes tecnológicos, los cuales pueden ser fácilmente distinguidos por los usuarios (Hernández y Porras, 2006).
No obstante que el desarrollo de una tecnología es largo, una vez terminada, ésta enfrenta siempre la posibilidad de ser o no aceptada por el usuario potencial (i. e. por el agricultor, en este caso). Por lo tanto, conocer las razones que provocan uno u otro evento es útil para las instituciones dedicadas a la investigación agropecuaria y para otros organismos encargados de la difusión de la tecnología. Esto último facilita la búsqueda de estrategias que permitan incrementar la probabilidad de que las innovaciones tecnológicas sean adoptadas en el menor tiempo posible; pero además conocer el impacto de éstas en un sistema de producción en particular.
Al respecto, la FAO (1988) sugiere que la generación y adopción de las nuevas tecnologías deben realizarse paralelamente con el productor, tomando en consideración la propia idiosincrasia del productor, su cultura, sus intereses y las condiciones agroecológicas y económicas en la que éste se desarrolla. Estos aspectos representan, en la mayoría de los casos, una seria condición que limita la adopción de una tecnología. El análisis de encuestas a través de métodos multivariados proporciona una explicación clara y lógica de cuánto contribuye un determinado factor a la decisión sobre adopción (CIMMYT, 1993). El objetivo de esta propuesta es presentar el uso de técnicas estadísticas para analizar y evaluar el proceso de adopción de innovaciones tecnológicas. Esta metodología incluye escalas cualitativas para analizarse a través de técnicas multivariadas como análisis multivariadamente normal, aglomerados, componentes principales y correlación canónica. Estas técnicas, se ejemplifican con encuestas a productores de cebada como un caso de estudio.
Caso de estudio
Con el fin de ilustrar la propuesta metodológica se usó un trabajo en donde se estudió la adopción del sistema de siembra en surcos doble hilera con productores de cebada de temporal en el estado de Zacatecas. El objetivo de esa investigación fue evaluar el grado de adopción de la tecnología siembra en surcos a doble hilera y pileteo, caracterizar a los usuarios de la tecnología e identificar los factores asociados a la adopción de esta tecnología en el estado de Zacatecas. La encuesta se aplicó a una muestra de 135 productores a finales de 2009 y principios de 2010 a productores de cebada en los municipios de Sombrerete, Miguel Auza, Sain Alto, Morelos, Calera, Ojocaliente, Pánuco, Pinos y Fresnillo en el estado de Zacatecas. El método de muestreo fue aleatorio simple.
Diseño de encuestas
]]> Existen varios tipos de estudios que pueden realizarse para evaluar la adopción de tecnologías, sin embargo, en esta investigación se describe el diseño y análisis de una encuesta formal. Las encuestas formales generan información cualitativa discreta útil para quienes toman las decisiones, y con ellas se pueden explotar mejor aspectos complejos que son necesarios para comprender la variabilidad de la adopción entre los productores. Sin embargo, aún cuando los errores del muestreo aleatorio son minimizados a través de encuestas formales, los errores no muéstrales son frecuentes. Éstos son debidos al empleo de términos inadecuados al hacer las preguntas, falta de secuencia lógica en la presentación de éstas, preguntas fuera de contexto o innecesarias, ineficacia del encuestador al hacer la pregunta y la selección de un momento inoportuno para la aplicación de la encuesta (INEC, 2001). Por lo tanto, la aplicación de un encuesta piloto, minimiza esta fuente de errores (Malhotra, 2008).Indicadores cualitativos de la encuesta
En la carátula de la encuesta se recolectó información referente al folio, nombre del productor, municipio y comunidad, fecha, coordenadas geográficas u otra variable que permita identificar al productor informante. Posteriormente se incluyeron cinco indicadores que dieron respuesta a los objetivos e hipótesis enfocados a la adopción de tecnologías. Los indicadores fueron: a) el proceso de adopción de la innovación; b) factores que afectan el proceso de adopción; c) impactos (económicos, sociales o ambientales) percibidos por el productor con la adopción; d) otros factores en la adopción de la innovación; y e) restricciones para la adopción de la innovación. La división de una encuesta en varias partes es una práctica conveniente.
Escala y medición
Se usó una escala discontinua ordinal finita (1-5) como se indica: 1= total desacuerdo, nula, muy bajo, muy poca; 2= desacuerdo, bajo, poco; 3= indistinto, regular, medio; 4= acuerdo, bueno, alto, mucho, y 5= total acuerdo, muy bueno, muy alto. También, el uso de escalas diferentes, en la encuesta, no limita el proceso de análisis, debido a que éstas se pueden estandarizar antes de analizarse (Fernández, 2004). Sin embargo, los enunciados de las diferentes preguntas se plantean como aseveraciones, en vez de cuestionamientos (Sánchez et al, 2012). En todos los casos, las respuestas se formulan de forma tal que, los informantes respondan ágilmente para clasificar la situación en relación al grado de adopción de una práctica o insumo de una manera suficientemente sencilla. Esto reduce el margen de error en las respuestas.
Análisis estadísticos
Las investigaciones sociales proporcionan cuantiosa información por la diversidad de temas enfocados en ellas así como por el gran número de observaciones que integran las muestras (Poza, 2008). La técnica matemática que permite el análisis simultáneo de dos o más variables, la reducción de los datos, la descomposición en factores del fenómeno social, la clasificación y el ordenamiento de las unidades investigadas, es el análisis multivariado (INEI, 2002).Cada técnica multivariada tiene distintos fines y su aplicación depende de los objetivos e hipótesis a probar.
Análisis de normalidad multivariada
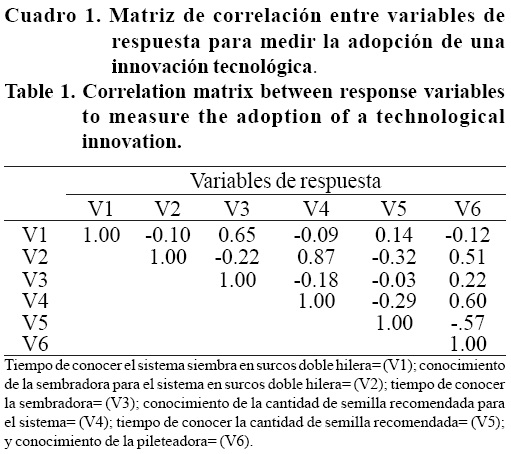
En el análisis de datos estadísticos, una de las asunciones fundamentales es que una variable aleatoria se distribuye normalmente (Park, 2008). Cuando se viola el supuesto de normalidad, la interpretación e inferencia sobre esta variable puede no ser válida ni fiable (Shapiro y Wilk, 1965). Sin embargo, probar la normalidad de una variable (análisis univariado) es relativamente fácil y existen varias formas de corregir la falta de normalidad a través de transformaciones apropiadas a una variable en particular (Steel et al, 1997). En contraste, la normalidad multivariada implica en el sentido univariado, que un grupo de variables individuales son normales, si la combinación de éstas es también normal. Es decir, si un grupo de variables sigue una distribución multivariadamente normal, entonces cada una de las variables tiene una distribución univariadamente normal (Hair et al., 1998). Por lo tanto, probar una normalidad multivariada resulta más difícil de ejecutar. Para ejemplificar esta primera parte, se utilizó una encuesta a productores de cebada de donde, al azar, se seleccionaron las siguientes variables: tiempo de conocer el sistema siembra en surcos doble hilera (V1), conocimiento de la sembradora para el sistema en surcos doble hilera (V2), tiempo de conocer la sembradora (V3), conocimiento de la cantidad de semilla recomendada para el sistema (V4), tiempo de conocer la cantidad de semilla recomendada (V5) y conocimiento de la pileteadora (V6), respectivamente. Para ese grupo de variables, la hipótesis nula se planteó que las seis variables consideradas multivariadamente no son significativamente diferentes de una distribución normal.
De acuerdo con Park (2008), la prueba de normalidad univariada para cada una de las seis variables incluidas en este ejemplo, fue rechazada según el estadístico de Kolmogorov-Smirnov (D) con p= 0.01. Este último resultado fue consistente cuando la normalidad de estas variables fue considerada colectivamente. Consecuentemente, los datos de estas variables fueron trasformados (normalizados) a la raíz cuadrada del valor original más 0.5 (Steel et al., 1997). Con esta transformación, no se rechazó la hipótesis nula con p= 0.089. Es decir, que las seis variables ahora transformadas y consideradas colectivamente no son significativamente diferentes a una distribución normal, y por lo tanto, los datos transformados pueden ser analizados colectivamente (Hair et al, 1998).
]]> Análisis por componentes principalesEl análisis de componentes principales (ACP) es una técnica multivariada de síntesis de información o reducción del número de variables originales involucradas en un estudio, preferiblemente dos o tres que expliquen el total de la variación en la información sin preocuparse por un agrupamiento específico de las observaciones (Cruz et al., 1994). El ACP maximiza la variación entre las variables originales, identifica tendencias en un grupo de datos y elimina redundancia en un análisis univariado cuando se involucra multicolincalidad en la información (Iezzoni y Pritts, 1991). Las nuevas variables generadas, no correlacionadas entre sí se denominan componentes principales. Estos últimos explicarán la mayor cantidad de la de la varianza total en los datos (Broschat, 1979).
Aplicación e interpretación
a) Matriz de correlación. El primer paso del ACP es ejecutar un análisis de correlación lineal simple entre todos los pares de variables de respuesta originales estandarizadas. Se seleccionaron las variables de la encuesta a productores de cebada que nos interesaban para el análisis, las cuales incluyeron el conocer, probar, adaptar, recomendar y adoptar. Para ejemplificarlo, se presenta la salida de las mismas seis variables cuya normalidad multivariada se probó en la sección anterior. En este caso se encontró una correlación de regular a buena entre las variables V1 y V3, V2 y V4, y V4 y V6. Las tres asociaciones indican una tendencia positiva (Cuadro 1). Por tanto, el análisis individual de estas variables se considera redundante, ya que las conclusiones serían similares para las variables. Mientras que las variables 5 y 6 presentaron una asociación regular pero negativa, es decir que mientras una de la variable incrementa su demisión, la otra la disminuye. Al efectuar el ACP, se espera que las variables con alta correlación sean incluidas en el mismo componente principal (CP).
b) Definición de componentes principales relevantes.
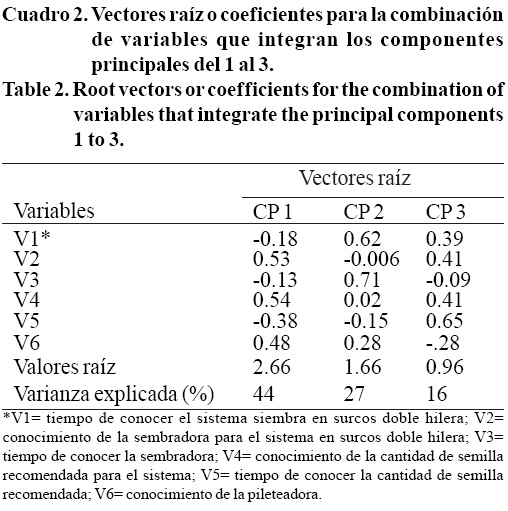
Con base en la matiz de correlación, las variables originales son trasformadas a factores o componentes principales (CPs) las cuales son combinaciones lineales de las variables estandarizadas no correlacionadas (ortogonales). Preferiblemente en los dos o tres CPs se busca que todas las variables estandarizadas expliquen la mayor cantidad de la varianza del grupo de datos. Generalmente se incluyen aquellas CPs que tienen un valor raíz igual o mayor a 1. En el ejemplo, se indica que el primer CP aporta 44% de la varianza (proporción o porcentaje de la varianza) e incluye casi tres CPs con una varianza total acumulada de 87% (Cuadro 2).
Así, el componente principal 1 (CP 1) se puede definir con la siguiente ecuación:
CP1=-0.18(V1) + 0.53(V2) - 0.13(V3) + 0.54(V4) - 0.38(V5) + 0.48(V6)
En el primer CP, los vectores raíz con mayor peso y positivos estuvieron asociados con las variables 2, 4 y 6; por lo tanto, esta multivariable fue designada como "conocimiento y evaluación de la tecnología de siembra en surcos doble hilera", para abreviarla conocimiento y evaluación de la tecnología, e incluyó las variables que tuvieron que ver con el conocimiento y evaluación del sistema de siembra y los componentes tecnológicos individuales, excepto el pileteo. Este primer CP explicó 44% de la variación total.
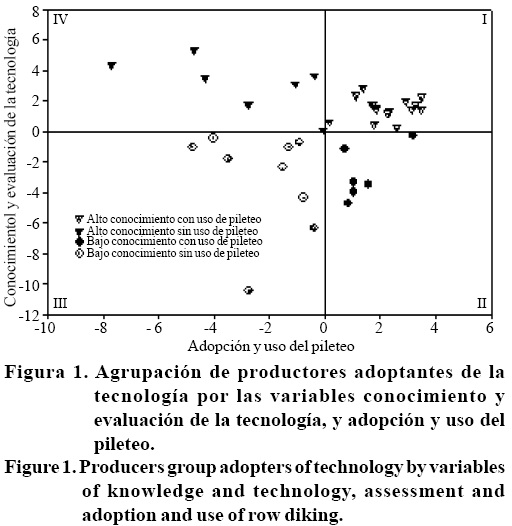
En el segundo CP, los mayores pesos positivos fueron obtenidos por las variables 1 y 3, se le asignó el nombre de "conocimiento, experimentación, adopción y resultado económico de la pileteadora", abreviada como adopción y uso del pileteo, e incluyó las variables que implicaron tener información sobre este componente tecnológico y el proceso de evaluación por el productor. Este segundo CP explicó 27% de la variación total. Los dos CPs explicaron 71% variación total; mientras que el CP3 sólo contribuyó con 16% de la variación total y su valor raíz fue menor que 1. Por lo tanto, se usaron los dos primeros CPs para la interpretación gráfica con la cual se pudo diferenciar cuatro grupos de productores (Figura 1).
Análisis por aglomerados
El análisis por aglomerados (AA) es una técnica de análisis exploratorio de datos para resolver problemas de clasificación. El objetivo de esta herramienta consiste en ordenar objetos (personas, cosas, animales, plantas, variables, etc.) en grupos (aglomerados) de forma que el grado de asociación (similitud) entre miembros del mismo aglomerado sea mayor que el grado de similitud entre miembros de otros aglomerados (Hair et al, 1998; Rencher, 2002). Es decir, cada aglomerado describe un conjunto de miembros con características similares, sin indicar en qué característica (s) son similares.
El AA es un método que permite descubrir asociaciones y estructuras en los datos que no son evidentes a priori pero que pueden ser útiles una vez que se han encontrado. Los resultados de un AA pueden contribuir a la definición formal de un esquema de clasificación tal como una taxonomía para un conjunto de objetos, sugerir modelos estadísticos para describir poblaciones, asignar nuevos individuos a las clases para diagnóstico e identificación, entre otros.
]]> Se pueden encontrar dos tipos fundamentales de métodos de clasificación: jerárquicos y no jerárquicos (Rencher, 2002). En los primeros, la clasificación resultante tiene un número creciente de clases anidadas; mientras que en el segundo las clases no son anidadas. Los métodos pueden dividirse en aglomerativos y divisivos. En los primeros se parte de tantas clases como objetos tengan que clasificarse y en pasos sucesivos se obtiene clases de objetos similares. En el segundo se parte de una clase única formada por todos los objetos que se van dividiendo en clases sucesivamente. En este documento se describe fundamentalmente el método jerárquico aglomerativo.En forma general, se anotan los pasos requeridos para una clasificación jerárquica de la siguiente manera:
a) decidir qué datos se colectarán en el AA para cada uno de los casos. Generalmente, se toma un número grande de variables todas del mismo tipo (continuas, categóricas, etc.) o dos variables como mínimo, ya que es difícil procesar distintas escalas; b) elegir una medida de la distancia entre los objetos a clasificar, que serán los aglomerados o clases iníciales. Para ello, existen multitud de métodos como son: ward, averange, vecino más próximo, vinculación inter-grupos, entre otros; c) identificar qué aglomerados u objetos son más similares; d) unir aglomerados en un nuevo aglomerado que tenga al menos 2 objetos, de forma que el número de aglomerados irá decreciendo; e) calcular la distancia entre un nuevo aglomerado y el resto; y f) repetir desde el paso tres hasta que todos los objetos formen un solo aglomerado.
Para medir la similitud entre dos objetos, se usan diferentes métodos, uno de los más usados es la distancia euclidiana. La distancia euclidiana es el intervalo entre dos puntos en un espacio euclidiano, la cual se deduce a partir del teorema de Pitágoras.
Aplicación e interpretación
El resultado del Sistema de Análisis Estadístico (SAS) incluye dos aspectos: la historia del aglomerado y el número de aglomerados que se formaron con una base de datos. Estos dos aspectos se ejemplifican con el estudio de adopción para el sistema de siembra en surcos doble hilera con productores de cebada de temporal en el estado de Zacatecas.
a) Historia del conglomerado. En el programa SAS usando la declaración PROC CLUSTER, al inicio de la salida del resultado se obtiene el historial del aglomerado. A través de éste se puede llevar a cabo el seguimiento en la formación de aglomerados de productores de cebada encuestados en el proceso de adopción de la tecnología del sistema de siembra en surcos doble hilera.
b) Definición de aglomerados relevantes. La representación gráfica del agrupamiento se hace a través de un dendograma (Figura 2). En el eje de la X se anotan todos los sujetos (productores); mientras que en el eje de Y, se anota la distancia promedio entre productores. Si en el dendograma se coloca una línea horizontal paralelo al eje de X, será posible definir el número de aglomerados, los productores incluidos en cada aglomerado e identificar las variables que hicieron diferentes a los grupos. El primer criterio integra tres aglomerados y el segundo integra ocho grupos de productores, de acuerdo con la altura a la que se dibuja la línea horizontal (Figura 2).
Con este análisis se pueden definir dos grandes grupos de productores, los adoptantes (aglomerado A) y los no adoptantes (aglomerado B) de la innovación tecnológica, además de un grupo atípico (aglomerado C) (Figura 2). Otra alternativa podría ser declarando ocho grupos de productores, cinco dentro de los adoptantes y otros tres grupos en los no adoptantes. La decisión sobre el número óptimo de aglomerados es subjetiva, especialmente cuando se incrementa el número de objetos. En este sentido, la experiencia del investigador es clave para definir los aglomerados o grupos de objetos relevantes.
Correlación canónica
]]> El análisis de correlación canónica (ACC) es un método de análisis multivariante desarrollado por Hotelling (1936). El objetivo de ACC es buscar las asociaciones y relaciones que puede haber entre dos grupos de variables y la validez de las mismas (Rencher, 1992). A diferencia de la correlación múltiple, el ACC estandariza las variables originales y luego correlaciona variables de dos grupos de variables (Rencher, 1988; Manly, 1986). Es decir, el ACC examina la relación lineal entre un grupo de variables, X, y un grupo de variables Y. La técnica consiste en encontrar una combinación lineal de las variables X, conocida ahora como variable V (V1=b1X1+b2X2+...+bpXp) y otra combinación lineal de las variables Y, conocida como variable U (U1=a1Y1+a2Y2+...+aqYq), de tal manera que la correlación entre U y V sea máxima (Hardoon et al., 2003).Después, podría ser necesario encontrar otras dos combinaciones lineales para cada grupo de variable V2 y U2, que tenga correlación máxima, pero menor a la primera, y así sucesivamente se encuentran un conjunto de combinaciones lineales para cada grupo de variables que presenten correlación entre las diferentes Us y Vs (Vicario et al., 1989). Estas combinaciones lineales se denominan variables canónicas, y las correlaciones entre los correspondientes pares de variables canónicas se denominan correlaciones canónicas (Hair et al, 1998).
Después se interpretan las cargas canónicas para determinar la importancia de cada variable en cada función canónica. Las cargas canónicas reflejan la varianza que la variable observada comparte con el valor teórico canónico. Este análisis resulta similar al de componentes principales, en donde de acuerdo con el autovalor (valor raíz), se seleccionan aquellas variables con mayor peso dentro de cada variable canónica y se le asigna un nombre genérico.
Aplicación e interpretación
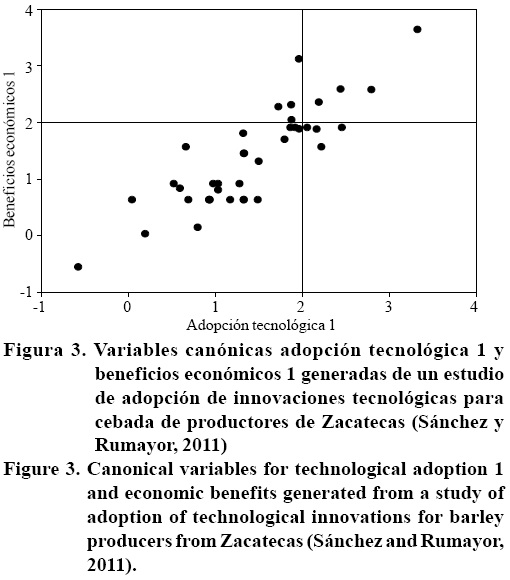
El procedimiento e interpretación del ACC se ejemplifica con datos recabados en un estudio de adopción de innovaciones tecnológicas en cebada con productores de Zacatecas (Sánchez y Rumayor, 2011). El primer grupo incluyó diez variables (V13, V14,..., V22) que describieron los componentes de adopción tecnológica. Éstas fueron designadas como variables "X" .En el segundo grupo de datos se consideraron seis variables que definieron los beneficios económicos percibidos por los productores al adoptar la innovación (V7,.,V12). Éstas se designaron como variables "Y". A través del ACC, las variables "X" y "Y" se convertirán en variables "V" y "U", respectivamente (Hardoon et al, 2003).
a) Correlación dentro de variables X y Y. Las variables originales (no estandarizadas) de adopción tecnológica (X) mostraron una asociación positiva de regular a buena (r= 0.51 - r= 0.87) entre ellas, excepto por el bajo coeficiente de correlación entre las variables V7 con V14 (r= 0.21), V9 con V14 (r= 0.35), V10 con V14 (r= 0.27), V11 con V12 (r= 0.37), V11 con V14 (r= 0.15), V14 con V15 (r= 0.32) y V14 con V16 (r= 0.42). En contraste, la asociación entre variables originales de beneficios económicos (Y), en términos generales, fue positiva y buena (r= 0.63 - r= 0.91).
b) Correlación entre variables X y Y. La asociación entre variables de adopción tecnológica y beneficios económicos mostraron una correlación de regular a moderadamente alta y positiva, excepto por la correlación entre las variables V14 y V18, V14 con V20 y V22, y V12 y V21, cuyos coeficientes fueron moderadamente bajos y positivos (Cuadro 3).
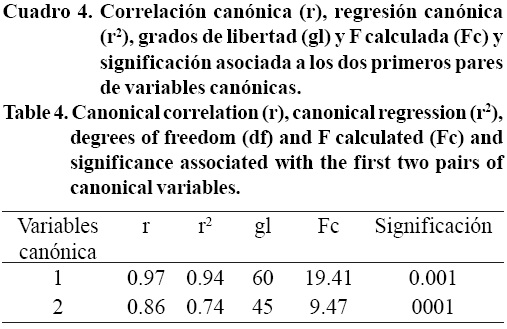
c) Correlación canónica y prueba de hipótesis. Los dos primeros pares de correlaciones canónicas generaron coeficientes de correlación altos y positivos. Aún cuando ambos fueron significativos (p= 0.0001), el primero explicó, en términos de regresión, 94% de la variación de las variables de beneficios económicos con respecto a las variables de adopción tecnológica (Cuadro 4). Esto último fue apoyado por el valor propio que para ambos pares de correlaciones canónicas fueron 79% y 13%, respectivamente.
Conclusiones
El protocolo propuesto puede seguirlo cualquier investigador con interés en llevar a cabo estudios de adopción. La aplicación de este tipo de análisis depende de los objetivos e hipótesis plateados en una investigación en particular. También, el uso de las técnicas multivariadas dependerá de la innovación tecnológica, escala utilizada, de la diversidad de clases entre variables y el juicio del investigador.
Se espera que con la metodología propuesta, los investigadores dedicados a esta área de investigación, dispongan de una estrategia para el diseño de encuestas, definición de una escala y técnicas de análisis estadísticas adicionales a las univariadas.
Literatura citada
Broschat, T. K. 1979. Principal component analysis in horticultural research. HortScience 14:114-117. [ Links ]
Centro Internacional de Maíz y Trigo (CIMMYT). 1993. La adopción de tecnologías: guía para el diseño de encuestas. Programa de economía. México, D. F. CIMMYT. 92 p. [ Links ]
Cruz, J.; Ganeshanandam, S.; Mackay, R.; Lawes, S.; Lawoko, O. and Woolley, J. 1994. Applications of canonical discriminant analysis in horticultural research. HortScience 29:1115-1119. [ Links ]
Organización de las Naciones Unidas para la Agricultura y la Alimentación (FAO). 1988. Extensión rural: partiendo de lo posible para llegar a lo deseable. 2ª edición. Oficina Regional de la FAO para América Latina y el Caribe. Serie Desarrollo Rural Núm. 2. 50 p. [ Links ]
Fernández, A. 2004. Investigación y encuestas de mercado. ESIC editorial. 2da. Edición. España. 156 p. [ Links ]
Hair, J.; Anderson, F. Tatham, R. and Black, C. 1998. Multivariate data analysis. Prentice-Hall Inc., New Jersey, USA. 730 p. [ Links ]
Hardoon, D.; Szedmak, S. and Shawe, J. 2003. Canonical correlation analysis; an overview with application to learning methods. Department of Computer Science Royal Holloway, University of London Technical Report CSD-TR-03-02. 39 p. [ Links ]
Hernández, C. y Porras, F. 2006. Estudio sobre la adopción de variedades mejoradas de frijol en las principales zonas productoras de frijol de la región Brunca de Costa Rica. Agronomía Mesoamericana 17(3):357-367. [ Links ]
Hotelling, H. 1936. Relations between two sets of variables. Biometrika 28(32):1-377. [ Links ]
Iezzoni, A. and Pritts, M. 1991. Applications of principal component to analysis in horticultural research. HortScience 26:334-338. [ Links ]
Instituto Nacional de Estadísticas y Censos (INEC). 2001. Encuesta Nicaragüense de Demografía y Salud. 431 p. [ Links ]
Instituto Nacional de Estadística e Informática (INEI). 2002. Guía para la aplicación del análisis multivariado a las encuestas de hogares. Lima, Perú. 59 p. [ Links ]
Manly, B. 1986. Multivariate statistical, methods: a primer. Chapman and Hall Ltd., London, UK.159 p [ Links ]
Malhotra, N. 2008. Investigación de mercados. 5ª edición. Prentice Hall. México. 811p. [ Links ]
Poza, C. 2008. Técnicas estadísticas multivariantes para la generación de variables latentes. Rev. Escuela deAdministración de Negocios. 64(3):89-99. [ Links ]
Rencher, A. C. 1988. Miscellanea on the use of correlations to interpret canonical functions. Biometrika 75:363-365. [ Links ]
]]>Rencher, A. C. 1992. Interpretation of canonical discriminant functions, canonical variates, and principal components. Amer. Statis. 46:217-225. [ Links ]
Rencher, A. C. 2002. Methods multivariate analysis. John Wiley and Sons, Inc. New York, USA. 708 p. [ Links ]
Sánchez, B.; Rumayor, A. y Espinoza, J. 2011. Adopción de la tecnología "siembra en surcos doble hilera y pileteo" en cebada maltera en el estado de Zacatecas: un análisis del proceso y los impactos. Campo Experimental Zacatecas. CIRNOC-INIFAP. Folleto técnico Núm. 31. 62 p. [ Links ]
Sánchez, T. B. I.; Zegbe, D. J .A.; Rumayor, R. A. F. 2012. Metodología para el diseño, aplicación y análisis de encuestas sobre adopción de tecnologías en productores rurales. Folleto Técnico No. 39. Campo Experimental Zacatecas. CIRNOC- INIFAP. 80 p. [ Links ]
Seré, C.; Estrada, D. y Ferguson, J. 1990. Estudios de adopción e impacto en pasturas tropicales. En: Investigación con pasturas en fincas. CIAT. Documento de trabajo Núm. 124. Palmira, Colombia. 38 p. [ Links ]
]]>Shapiro, S. S. and Wilk, M. B. 1965. Analy sis of variance test for normality (complete samples). Biometrika 52 (3-4):591-611. [ Links ]
Steel, R. G. D.; Torrie J. H. and Dickey, D.A. 1997. Principles and procedures of statistics. A biometrical approach. McGraw-Hill, Series in Probability and Statistics. United States of America. 666 p. [ Links ]
Vicario, A.; Mazón, L. I.; Aguirre, A. Estomba, A. and Lostao, C. 1989. Relationship between environmental factors and morph polymorphism in Cepaea Nemoralis, using canonical correlation analysis. Genome 32:908-912. [ Links ]
]]>