Simultaneous Estimation of Hydrologic Annual Data Missing in Multiple Sites
Campos-Aranda Daniel Francisco1
1 Profesor jubilado de la Universidad Autónoma de San Luis Potosí. Correo: campos_aranda@hotmail.com
Artículo: recibido: marzo de 2014, ]]> Aceptado: mayo de 2014.
Resumen
La deducción de los datos anuales faltantes en los registros hidrológicos, es necesaria para integrar series con un periodo común, las cuales son requeridas en los estudios de simulación de los sistemas hidráulicos y en varios métodos regionales de estimación de crecientes. Además, las estimaciones estadísticas se vuelven más confiables y exactas conforme proceden de series completas más amplias. La regresión lineal múltiple (RLM) permite estimar datos anuales faltantes con base en los registros cercanos que tienen dependencia o correlación con la serie incompleta. El algoritmo de Beale-Little se basa en la RLM y considera cada registro como variable dependiente y el resto como regresores; emplea toda la información disponible, no únicamente el periodo común de datos y conduce a una estimación simultánea de los valores anuales faltantes en los registros procesados. Se describen tres aplicaciones numéricas del algoritmo de Beale-Little para estimar datos anuales faltantes de volumen escurrido y de gasto máximo, en el sistema del río Tempoal y en el Alto río Grijalva de las Regiones Hidrológicas Núm. 26 (Pánuco) y Núm. 30 (Grijalva-Usumacinta), que tienen cinco estaciones hidrométricas, cuatro de ellas completas. Las conclusiones destacan las ventajas del procedimiento descrito e ilustrado numéricamente y recomiendan su aplicación sistemática debido a que su implementación es sencilla.
Descriptores: algoritmo de Beale-Little, regresión lineal múltiple, coeficiente de correlación lineal, río Tempoal, Alto río Grijalva.
Abstract
The deduction of annual missing data in hydrological records is necessary to integrate series with a common period, which are required in simulation studies of hydraulic systems and several regional flood estimation methods. Besides, the statistical estimates become more reliable and accurate when full and extensive series are utilized. Multiple linear regression (MLR) allows estimating annual missing data based on close records that have dependence or correlation with the incomplete sequence. The Beale-Little algorithm is based in MLR where each record considered as a dependent variable and the rest as regressors; uses all available information, not only the common data period and leads to a simultaneous estimation of annual missing values in the records processed. Three numerical applications of the Beale-Little algorithm are described to estimate annual missing data of runoff volume and maximum flow in the system Tempoal River and Upper Grijalva River of the Hydro-logical Regions No. 26 (Panuco) and No. 30 (Grijalva-Usumacinta), which has five hydrometric stations, four of which are complete. The conclusions pointed out the advantages of the procedure described and illustrated numerically and recommend its systematic application given its ease of implementation.
Keywords: Beale-Little algorithm, multiple linear regression, linear correlation coefficient, Tempoal River, Upper Grijalva River.
]]> Introducción
En hidrología superficial las aplicaciones de la regresión lineal múltiple (RLM) más comunes, emplean diversas variables explicativas y una variable de respuesta. Con frecuencia, las variables explicativas o regresores son causales, como en el caso de la lluvia que origina el escurrimiento. En ocasiones, los regresores no son directamente causales, sino que establecen el escalamiento, como el tamaño de cuenca y la longitud o la pendiente del colector principal, en relación con las crecientes o gastos máximos. Cuando la RLM se emplea con varias variables de respuesta de manera simultánea, se trabaja en el campo del análisis multivariado (AM).
Una aplicación práctica del AM consiste en estimar datos hidrológicos anuales faltantes, tanto de escurrimiento como de lluvia o de gasto máximo; los cuales no existen debido a fallas o pérdida del equipo de muestreo, enfermedad o abandono de los operadores o simplemente por un inicio retrasado de la operación de la estación hidrométrica o pluviométrica. Los dos objetivos básicos de la estimación de datos faltantes son: 1) completar las series disponibles para poder realizar análisis hidrológicos del tipo de periodo común y 2) mejorar la calidad estadística de los parámetros que se estiman, al emplear series completas y más largas (Gyau y Schulte, 1994; Simonovic, 1995; Salas et al., 2008).
Diversos enfoques han sido aplicados en la estimación de datos hidrológicos faltantes, por ejemplo, Bennis et al. (1997) usan la regresión lineal para deducir los valores perdidos, corrigiendo estos con factores deducidos de la aplicación de dos procesos autorregresivos que operan hacia atrás y hacia adelante del periodo de datos faltantes. Khalil et al. (2001) toman en cuenta el efecto de las estaciones o épocas al usar grupos de registros hidrométricos y redes neuronales artificiales basadas en tal grupo, para estimar los datos faltantes. Ulke et al. (2009) calculan valores faltantes de carga de sedimentos en suspensión con base en datos de precipitación y gasto, usando diversos métodos como regresión lineal y no lineal múltiple, redes neuronales artificiales y sistemas de inferencia neurodifusa.
El algoritmo de Beale-Little, es una técnica del AM que permite estimar de manera simultánea los datos anuales faltantes en registros de estaciones hidrométricas o pluviométricas de una zona geográfica, los cuales muestran una correlación significativa, pero no tienen persistencia. Es únicamente apropiado para estimar datos faltantes que fueron perdidos de una manera aleatoria; consideración que es válida cuando hubo ausencia del operador, o una suspensión temporal por pérdida o mantenimiento del equipo, o bien, por mejoras en la instalación; sin embargo, no han cambiado las condiciones ambientales regionales. Por el contrario, cuando la parte baja de una cuenca grande es colonizada y se establecen estaciones de aforos en sus cercanías, estos datos no se pueden utilizar para ampliar los registros cortos de las estaciones hidrométricas que se ubicaron posteriormente en la zona alta con dificultades de acceso, pues tales registros seguramente estarán afectados por la deforestación, los desarrollos agrícolas, los aprovechamientos hidráulicos, o bien, la urbanización (Beale y Little, 1975; Clarke, 1994).
La ausencia de persistencia implica que los datos de cada serie no muestran correlación o dependencia serial, lo cual es una consideración aceptable cuando se procesan registros de valores anuales de gasto máximo de cuencas de cualquier tamaño; así como registros de escurrimiento anual procedentes de cuencas que no presentan un efecto de almacenamiento considerable, como son cuencas pequeñas montañosas con suelos someros, o cuencas medianas con áreas impermeables importantes que generan mucho escurrimiento directo. La condición de independencia serial deberá ser cuestionada en registros de volumen escurrido anual de cuencas grandes o medianas y pequeñas, pero con grandes áreas permeables o con almacenamiento importante en acuíferos de respuesta lenta (Clarke, 1994).
El objetivo de este trabajo consiste en exponer con detalle el procedimiento operativo del algoritmo de Beale-Little, describiendo dos aplicaciones numéricas en el sistema del Río Tempoal, de la Región Hidrológica Núm. 26 (Pánuco); la primera permite deducir los datos faltantes de volumen escurrido anual y la segunda los de gasto máximo anual (crecientes), en las cinco estaciones hidrométricas que se procesan simultáneamente, que son: Tempoal, El Cardón, Platón Sánchez, Los Hules y Terrerillos. Los resultados del algoritmo de Beale-Little se comparan con los obtenidos previamente empleando la RLM aplicada durante el periodo común de datos. La tercera aplicación numérica se desarrolla en cinco cuencas del Alto río Grijalva de la Región Hidrológica Núm. 30 (Grijalva-Usumacinta), tres de ellas incompletas en su registro de volumen escurrido anual.
Procedimientos aplicados
Descripción operativa del algoritmo de Beale-Little
]]> En Beale y Little (1975) se pueden consultar los aspectos teóricos del algoritmo y en Clarke (1994) los relativos a su aplicación práctica. Su proceso operativo consta de los cinco pasos siguientes:Paso 1: Recopilación de información disponible. El arreglo para la disponibilidad de información hidrológica, que concuerda con las matrices que resuelven la RLM, establece una matriz de R renglones y C columnas, donde los primeros pertenecen a los años de registro y las segundas a las estaciones hidrométricas o pluviométricas, indicando con un asterisco los datos faltantes. Lo anterior se ilustra en la tabla 1 siguiente.
Paso 2: Sustitución inicial de datos faltantes. Partiendo del arreglo matricial de disponibilidad de información, se comienza por identificar y anotar cada uno de los datos o secuencia de valores faltantes en los registros. Después se obtienen las medias aritméticas de cada columna y tales magnitudes se sustituyen en cada dato faltante del registro.
Paso 3: Se calcula la RLM de cada registro y se obtienen nuevas estimaciones de datos faltantes. Se obtiene la RLM de cada registro Xij, considerado como variable dependiente (Y) y el resto de los registros tomados regresores Xij. Con base en tal RLM se define una nueva estimación de cada dato faltante del registro procesado.
Paso 4: Se calculan las diferencias entre el dato anterior y el nuevo. En el primer ciclo del algoritmo de Beale-Little corresponden a las diferencias entre las medias del registro y la nueva estimación de cada dato faltante. Estas diferencias ayudarán a definir cuando terminan los ciclos del algoritmo; lo anterior cuando estas son muy reducidas o tienden a ser despreciables; por ejemplo, menores de una unidad.
Paso 5: Se remplazan las estimaciones anteriores por las nuevas y se realiza otro ciclo. Cada nuevo ciclo inicia sustituyendo las nuevas estimaciones por las anteriores y se repiten los pasos 3 y 4.
Antes de aplicar el algoritmo de Beale-Little se debe verificar que los registros involucrados tienen las características estadísticas siguientes:
1) Se puede aceptar que proceden de distribuciones normales, lo que implica que los datos Xij tienen una distribución multivariada normal. Lo anterior se puede verificar con alguna prueba estadística, por ejemplo el Test W de Shapiro y Wilk (1965), o el cociente de Geary (Machiwal y Jha, 2012). Cuando los datos no son normales se usa una transformación, la más simple consiste en emplear los logaritmos de los datos.
]]> 2) Una estrategia apropiada cuando se estiman valores hidrológicos anuales faltantes, recomienda emplear el mayor número de registros posibles o columnas en la matriz definida en la tabla 1, siempre y cuando tales registros estén correlacionados. Por lo anterior, es aconsejable antes de aplicar el algoritmo de Beale-Little, verificar que las correlaciones entre los registros (rxy) son importantes; por ejemplo superiores a 0.80.3) El algoritmo de Beale-Little requiere que no exista correlación entre los datos de cada renglón de la matriz de la tabla 1, lo cual significa que no exista persistencia en los registros procesados. Entonces el algoritmo de Beale-Little no es adecuado para estimar valores anuales faltantes de gasto mínimo o de cualquier otro indicador de sequías hidrológicas, pues tales parámetros por lo general reproducen el comportamiento de las secuencias de años secos.
Formulación matemática de la RLM
Considerando que existen p variables independientes o regresores la RLM establece el modelo siguiente (Ryan, 1998):
Aceptado que se tienen n observaciones de Y, X1 X2, . . . . ., Xp, la expresión anterior en notación matricial será

cuyas matrices son
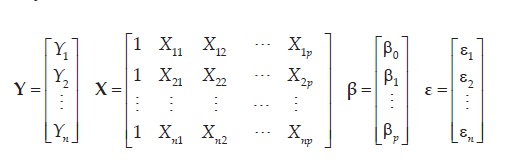
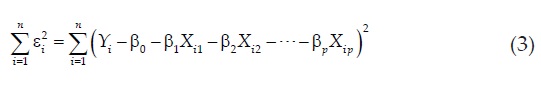
La diferenciación del lado derecho de la ecuación anterior con respecto a β0, β1, β2, . . . , βp, por separado e igualada a cero, produce p ecuaciones con p parámetros desconocidos, las cuales se conocen como ecuaciones normales, su notación matricial es

y cuya solución es

En la ecuación anterior, XT es la matriz transpuesta de X y (XT·X)—1 es la matriz inversa de XT· X.
Programa de cómputo desarrollado
A continuación se describen los aspectos relevantes del programa de cómputo generalizado desarrollado para este trabajo, el cual se modifica según cada aplicación numérica.
]]>Aspectos relevantes:
1) Los datos disponibles en cada registro completados con sus medias, se guardan en vectores renglón, que después se acomodan como vectores columna al formar las matrices Y y X correspondientes a cada RLM. En estos vectores renglón es donde se sustituyen las nuevas estimaciones de cada dato faltante.
2) Las matrices Y y X se forman en arreglos bidimensionales: Y(n,1) y X(n,p), donde n es el número de años de los registros y p el número de regresores. La matriz X en su primera columna tiene a la unidad.
3) Una subrutina llamada CALBETA aplica la ecuación 5, después que se han formado las matrices Y y X relativas a cada RLM. En esta subrutina se comienza por obtener la transpuesta de X, para multiplicarla por la matriz Y y así definir la matriz XT·Y. Después se multiplican las matrices XT por X y se obtiene su inversa. Por último, se multiplican las matrices, inversa de XT·X por XT·Y, para obtener el vector columna de coeficientes βi. Calculada cada RLM se obtienen las nuevas estimaciones de datos faltantes. Al término de cada ciclo del algoritmo de Beale-Little el programa pregunta si se imprimen sus resultados parciales.
Modificaciones particulares: En cada aplicación numérica se ubican o definen los datos faltantes de cada registro, los cuales se estiman con cada RLM, que se calcula considerando tal registro como variable dependiente y el resto como regresores. Calculados los datos faltantes de todos los registros incompletos, se muestran sus valores anteriores y los del ciclo que se está realizando, así como sus diferencias, para definir si se efectúa otro ciclo o si ya estas son muy reducidas o despreciables; por ejemplo, menores de la unidad.
Resultados y su análisis
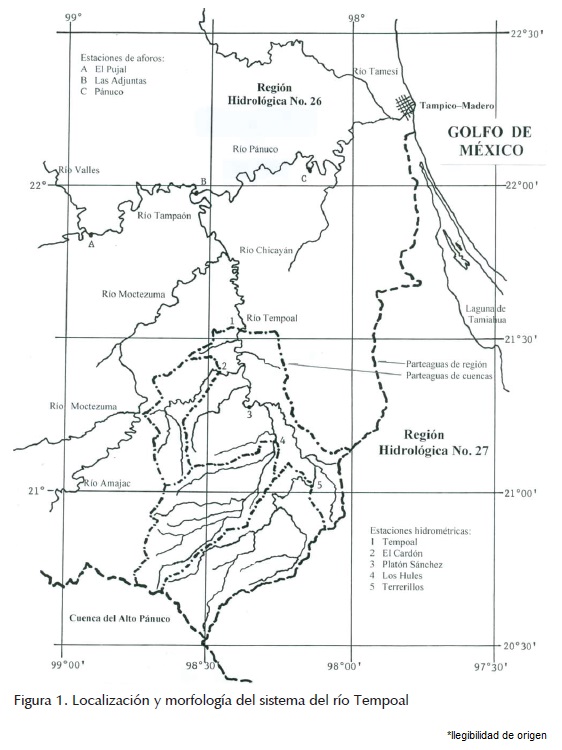
]]> Primera aplicación numéricaEl río Tempoal pertenece a la Región Hidrológica Núm. 26 (Pánuco), es el último afluente importante del río Moctezuma que junto con el Tampaón forman el río Pánuco. En la figura 1 se muestra la morfología y localización geográfica del sistema del río Tempoal. En este río existen cinco estaciones hidrométricas, cuyos datos disponibles en el sistema BANDAS (IMTA, 2002), de volumen escurrido anual en millones de metros cúbicos (Mm3) se muestran en la tabla 2.
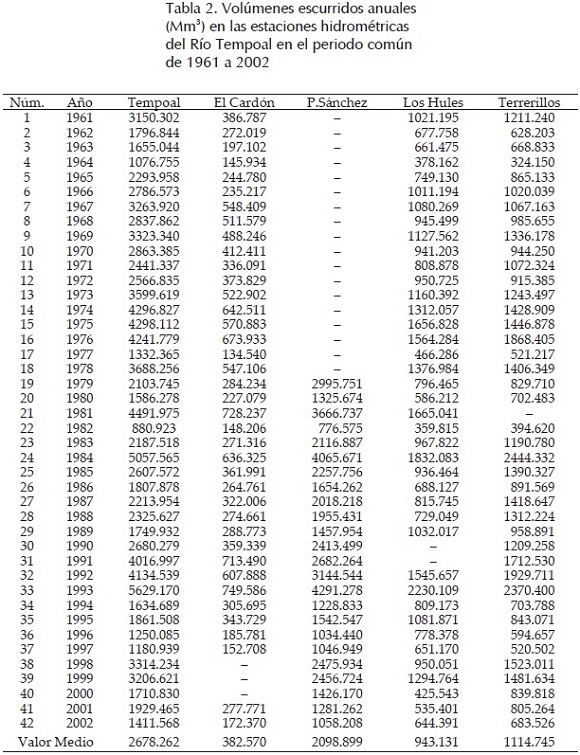
Campos (2011b) procesó esta información, verificando primeramente que tales muestras pueden ser consideradas procedentes de poblaciones normales, además encontró que tales registros tienen fuerte dependencia, con valores del coeficiente de correlación lineal (rxy) que varían de 0.858 a 0.949. Después, aplicó la RLM en el periodo común de datos de 1979 a 2002 con 18 datos en cada registro y el método de selección óptima de regresores, para obtener la secuencia inicial faltante en Platón Sánchez, los resultados adoptados se exponen en la segunda columna de la tabla 3.
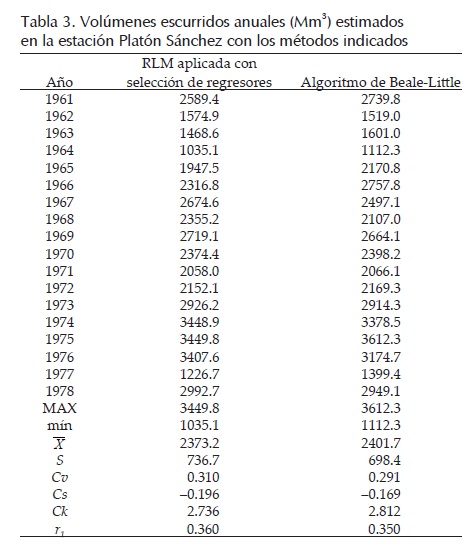
Para el arreglo mostrado en la tabla 2, se tiene n = 42 y p = 4. En la estación El Cardón están faltantes los renglones (años) 38, 39 y 40; en Los Hules los renglones 30 y 31; en Terrerillos el renglón 21 y por último, en Platón Sánchez falta el lapso inicial de 18 renglones (años). Se utilizaron en los registros de las cuatro estaciones incompletas los siguientes valores medios: 383, 943, 1115 y 2099 Mm3, respectivamente y después de 80 ciclos se obtuvieron las estimaciones siguientes: en El Cardón 473.1, 478.1 y 231.0 Mm3; en Los Hules 1007.6 y 1510.8 Mm3; en Terrerillos 1773.2 Mm3 y en Platón Sánchez la secuencia mostrada en la columna tres de la tabla 3.
]]>Segunda aplicación numérica
También se realiza en el sistema del río Tempoal, pero ahora se completan los datos disponibles de gasto máximo anual (m3/s), procedentes del sistema BANDAS (IMTA, 2002), los cuales se exponen en la tabla 4.
Se observa que los lapsos disponibles y los datos faltantes son escasamente diferentes a los de la aplicación anterior. Campos (2011a) utilizó la RLM para estimar la secuencia inicial de datos en la estación hidrométrica Platón Sánchez; la aplicó en el periodo común de 1978 a 2002, empleando 20 datos en los registros auxiliares. Como en los registros de gasto máximo anual no se puede aceptar que provengan de una distribución Normal, trabajó con los logaritmos naturales de los datos. Los resultados obtenidos se muestran en la segunda columna de la tabla 5.
La aplicación del algoritmo de Beale-Little con n = 43, p = 4 y datos transformados (Zij = ln Xij), después de 35 ciclos aporta las estimaciones mostradas en la tercera columna de la tabla 5, para la secuencia inicial de datos faltantes en la estación Platón Sánchez y los valores siguientes en El Cardón 271.9 y 185.5 m3/s. En la estación Los Hules se estimaron 3463.7 y 1072.2 m3/s y por último, en Terrerillos 1151.3 m3/s, como datos faltantes.
Tercera aplicación numérica
Se ubica dentro de la Región Hidrológica Núm. 30 (Grijalva-Usumacinta) y corresponde a cinco cuencas de la vertiente de margen izquierda del Alto Río Grijalva, pues estas se localizan antes de la Presa Netzahualcóyotl (Malpaso). En la figura 2 se muestra su ubicación geográfica y en la tabla 6 sus registros disponibles de volumen escurrido anual en millones de metros cúbicos (Mm3).
Campos (2014) primeramente verificó que las muestras de la tabla 6 pudieran ser consideradas procedentes de distribuciones normales. Por otra parte, como las estaciones hidrométricas Santa María y Las Flores II comenzaron a operar en 1962, para completar el periodo común de datos de 18 años de 1956 a 1973 que define la estación incompleta Santa Isabel; Campos (2014) estimó sus primeros seis valores faltantes por regresión lineal con la estación El Boquerón II, tales magnitudes se muestran en la tabla 6 entre paréntesis.
Campos (2014) procesó la información de la tabla 6 a través de la RLM de tipo Ridge y estimó la secuencia faltante de 21 años en la estación Santa Isabel con un parámetro de sesgo (k) de 0.350, la cual se muestra en la segunda columna de la tabla 7.
]]>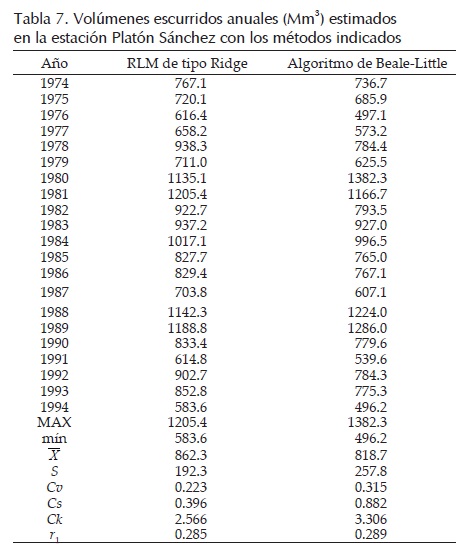
La aplicación del algoritmo de Beale-Little con n = 39 y p = 4, se realizó considerando faltantes los seis valores iniciales de las estaciones Santa María y Las Flores II; después de 95 ciclos estima los siguientes seis valores en la primera: 1467.4, 929.4,1208.4, 943.1,1203.7 y 859.9 Mm3 y estos seis en la segunda: 748.1, 335.5, 524.8, 251.9, 554.0 y 245.8 Mm3. La secuencia obtenida de 21 años en Santa Isabel se tiene en la tabla 7. Se observa que ambas series estimadas en Santa Isabel tienen el mismo comportamiento serial, pero la procedente del algoritmo de Beale-Little tiene mayor dispersión y sesgo, así como menor valor promedio.
Análisis de los resultados
Los resultados mostrados en las tablas 3 y 5, tienen el mismo comportamiento secuencial de valores y ello genera confianza en tales estimaciones, ya que proceden de periodos comunes bastante diferentes. La similitud serial observada también se detecta en la semejanza que muestran los parámetros estadísticos, sobre todo los de la tabla 3; un poco menos en la tabla 5. Tal similitud se debe a la correlación general que guardan los registros procesados de volumen escurrido anual, la cual se muestra en la parte superior de la tabla 8 para los registros incompletos y en su parte inferior, para tales series completadas con los datos estimados con el algoritmo de Beale-Little.
Se observa en la tabla 8 que la mayoría de los coeficientes rxy aumentan ligeramente con los registros completos, lo cual indica que la aplicación del algoritmo de Beale-Little es conveniente desde un punto de vista estadístico. Esta correlación elevada entre todos los registros genera un problema de multicolinealidad al aplicar la RLM (Montgomery et al, 1998); problema que se detecta y evalúa con los factores de inflación de la varianza y el análisis de residuos (Campos, 2011b).
Respecto a la segunda aplicación numérica, en la tabla 9 se observa que la estimación de datos faltantes con el algoritmo de Beale-Little en la estación hidrométrica Platón Sánchez, mejora todas sus correlaciones con las otras estaciones, lo cual destaca la conveniencia de tal deducción. Lo contario ocurre en la estación Los Hules, cuyos valores estimados para los años 1990 y 1991 con el algoritmo de Beale-Little resultan con magnitud inversa a la que presentan las estaciones El Cardón, Terrerillos y Tempoal (tabla 4), y debido a ello su correlación disminuye al procesar los registros completos.
En la porción superior de la tabla 9 se observa que el registro de la estación El Cardón no presenta correlación con el resto y que únicamente tiene una dependencia baja (rxy = 0.729) con la estación Tempoal; además con la estación Platón Sánchez es la que presenta menor correlación (rxy = 0.401). Debido a lo anterior, se considera conveniente aplicar el algoritmo de Beale-Little sin tal registro, entonces ahora se tienen n = 43 y p = 3. Empleando datos transformados y después de 20 ciclos se obtuvieron las siguientes estimaciones: en Los Hules 3819.5 y 872.2 m3/s, en Terrerillos 1421.1 m3/s y en Platón Sánchez la secuencia mostrada en la cuarta columna de la tabla 5.
Se observa que estas últimas estimaciones en la estación Platón Sánchez tienen semejanza serial con las anteriores y que sus parámetros estadísticos son similares. Como esta última secuencia es ligeramente más extrema que las dos anteriores, en sus valores: máximo, media y variabilidad, según su coeficiente de variación (Cv), es la que se recomienda adoptar por seguridad hidrológica, ya que las predicciones (crecientes) que se obtengan con tales datos seguramente serán mayores.
]]> Por el contrario, cuando se trate de seleccionar una secuencia de estimaciones de volumen escurrido anual, se recomienda adoptar por seguridad hidrológica de la disponibilidad, la de menor valor medio (volumen escurrido medio anual, VEMA) y Cv mayor, pues tal dispersión se reflejará en una mayor capacidad de regulación necesaria en el embalse que se dimensiona hidrológicamente para aprovechar un cierto porcentaje del VEMA.Por último, en la parte superior de la tabla 10 se muestran las correlaciones que tienen los registros de la tercera aplicación numérica, en el periodo común de 18 años de 1956 a 1973, definido este por los datos disponibles en la estación incompleta Santa Isabel. En la porción inferior de la tabla 10 se muestran las dependencias de los registros completados con base en las estimaciones del algoritmo de Beale-Little, se observa que todas las correlaciones de la estación Santa Isabel aumentan de manera importante, sobre todo con las estaciones más alejadas que son Santa María y Las Flores II.
También se observa que las correlaciones del registro completo de la estación El Boquerón II disminuyen con las de las estaciones Santa María y Las Flores II, pues ahora los valores faltantes en estas dos estaciones proceden de la RLM con cuatro regresores no únicamente de la regresión lineal con los datos de El Boquerón II, como se estimaron los indicados entre paréntesis en la tabla 6.
Conclusiones
Verificando previamente que los datos faltantes se perdieron de una manera aleatoria, o que no existen debido a un inicio posterior de la operación de la estación hidrométrica o climatológica, el algoritmo de Beale-Little es aplicable. Lo que se debe evitar es estimar datos faltantes que están asociados a condiciones severas del clima y que por ello, no se registraron. Caso común de las crecientes extremas que dañan las instalaciones de aforos, o de los periodos de sequía extrema en los cuales no se mide ni la lluvia ni el escurrimiento porque toda la población ya emigró.
El algoritmo de Beale-Little, permite utilizar toda la información hidrológica disponible, de una manera conjunta, no exclusivamente en el periodo común, como opera la regresión lineal múltiple (RLM). Lo anterior seguramente conduce a estimaciones más exactas para los datos faltantes.
Otra ventaja del procedimiento descrito, consiste en obtener de forma simultánea todos los datos anuales faltantes en los registros procesados, con lo cual queda integrado un grupo de series de datos hidrológicos en un periodo común. Esto permite aplicar técnicas hidrológicas de simulación de aprovechamientos hidráulicos o de estimación regional de crecientes, que requieren muestras que tienen un lapso común de registro.
Siendo el algoritmo de Beale-Little descrito, un procedimiento bastante simple de implementar, se recomienda su aplicación sistemática para procesar información regional que está correlacionada y obtener resultados que permitan verificar y complementar las estimaciones de la RLM, aplicada según los enfoques de selección óptima de regresores o de tipo Ridge, para el caso del volumen escurrido anual, o de su conveniencia estadística en la transferencia de información de gasto máximo anual (crecientes).
]]> Referencias
Beale E.M.L. y Little R.J.A. Missing values in multivariate analysis. Journal of Royal Statistical Society B., volumen 37, 1975: 129-145. [ Links ]
Bennis S., Berrada F. y Kang N. Improving single-variable and multivariable techniques for estimating missing hydrological data. Journal of Hydrology, volumen 91 (números 1-4), 1997: 87-105. [ Links ]
Campos-Aranda D.F. Transferencia de información de crecientes mediante regresión lineal múltiple. Tecnología y Ciencias del Agua, volumen 2 (número 3), 2011a julio-septiembre: 239-247. [ Links ]
Campos-Aranda D.F. Transferencia de información hidrológica mediante regresión lineal múltiple, con selección óptima de regresores. Agrociencia, volumen 45 (número 8), 2011b: 863-880. [ Links ]
Campos-Aranda D.F. Ampliación de registros de volumen escurrido anual con base en información regional y regresión tipo Ridge. Tecnología y Ciencias del Agua, volumen V (número 4), julio-agosto de 2014:173-185. [ Links ]
Clarke R.T. Statistical modelling in hydrology. Capítulo 7, Multivariate models, pp. 254-302, Chichester, Inglaterra, John Wiley & Sons, 1994. 412 p. [ Links ]
Gyau-Boakye P. y Schultz G.A. Filling gaps in runoff time series in West Africa. Hydrological Sciences Journal, volumen 36 (número 6), 1994: 621-636. [ Links ]
Instituto Mexicano de Tecnología del Agua (IMTA). Banco Nacional de Datos de Aguas Superficiales (BANDAS). 8 CD's. Secretaría de Medio Ambiente y Recursos Naturales-Comisión Nacional del Agua-IMTA, Jiutepec, Morelos, 2002. [ Links ]
Khalil M., Panu U.S., Lennox, W.C. Groups and neural networks based streamflow data infilling procedures. Journal of Hydrology, volumen 241 (números 3-4), 2001:153-176. [ Links ]
Machiwal D. y Jha M.K. Hydrologic time series analysis: theory and practice, capítulo 4, Methods for time series analysis, pp. 51-84, Springer Dordrecht, The Netherlands, 2012, 303 p. [ Links ]
Montgomery D.C., Peck E.A., Simpson J.R. Multicollinearity and biased estimation in regression, capítulo 16, pp. 16.1-16.27, en: Handbook of Statistical Methods for Engineers and Scientists, editado por: Harrison M. Wadsworth, 2a ed., McGraw-Hill, Inc, Nueva York, 1998. [ Links ]
Ryan T.P. Linear Regression, capítulo 14, pp. 14.1-14.43, en: Handbook of Statistical Methods for Engineers and Scientists, Harrison M. Wadsworth, editor, 2a. ed., Nueva York, McGraw-Hill Book Co., 1998. [ Links ]
Salas J.D., Raynal J.A., Tarawneh Z.S., Lee T.S., Frevert D., Fulp T. Extending short record of hydrologic data, capítulo 20, pp. 717-760, en: Hydrology and hydraulics, editado por: Vijay P. Singh, Water Resources Publications, Highlands Ranch, Colorado, 2008, 1080 p. [ Links ]
Shapiro S.S. y Wilk M.B. An analysis of variance test for normality (complete samples). Biometrika, volumen 52 (números 3-4), 1965: 591-611. [ Links ]
Simonovic S.P. Synthesizing missing streamflow records on several Manitoba streams using multiple nonlinear standardized correlation analysis. Hydrological Sciences Journal, volumen 40 (número 2), 1995:183-203. [ Links ]
Ulke A., Tayfur G., Ozkul S. Predicting suspended sediment loads and missing data for Gediz River, Turkey. Journal of Hydrologic Engineering, volumen 14 (número 9), 2009: 954-965. [ Links ]
Este artículo se cita:
Citación estilo Chicago
Campos-Aranda, Daniel Francisco. Estimación simultánea de datos hidrológicos anuales faltantes en múltiples sitios. Ingeniería Investigación y Tecnología, XVI, 02 (2015): 295-306.
Citación estilo ISO 690
Campos-Aranda D.F. Estimación simultánea de datos hidrológicos anuales faltantes en múltiples sitios. Ingeniería Investigación y Tecnología, volumen XVI (número 2), abril-junio 2015: 295-306.
]]> Semblanza del autor
Daniel Francisco Campos-Aranda. Obtuvo el título de ingeniero Civil en diciembre de 1972, en la entonces Escuela de Ingeniería de la UASLP. Durante el primer semestre de 1977, realizó en Madrid, España un diplomado en hidrología general y aplicada. Posteriormente, durante 1980-1981 llevó a cabo estudios de maestría en ingeniería en la especialidad de Hidráulica, en la División de Estudios de Posgrado de la Facultad de Ingeniería de la UNAM. En esta misma institución, inició (1984) y concluyó (1987) el doctorado en ingeniería con especialidad en aprovechamientos hidráulicos. Ha publicado artículos principalmente en revistas mexicanas de excelencia: 46 en Tecnología y Ciencias del Agua (antes Ingeniería Hidráulica en México), 18 en Agrociencia y 15 en Ingeniería. Investigación y Tecnología. Es profesor jubilado de la UASLP, desde el Io de febrero de 2003. En noviembre de 1989 obtuvo la medalla Gabino Barreda de la UNAM y en 2008 le fue otorgado el Premio Nacional "Francisco Torres H." de la AMH. A partir de septiembre de 2013 vuelve a ser investigador nacional nivel I.
]]>