
Una extensión del algoritmo MIMIC mediante Cópulas
A extension for MIMIC algorithm through Copulas
Rogelio Salinas Gutiérrez1, Arturo Hernández Aguirre1, Enrique Raúl Villa Diharce1
1 Centro de Investigación en Matemáticas, Guanajuato. México.
]]>Rogelio Salinas Gutiérrez. E-mail: rsalinas@cimat.mx
Recepción: 10-08-09
Aceptación: 03-09-09
Resumen
Una nueva manera de modelar dependencias probabilísticas en el algoritmo de Maximización de Información Mutua mediante Clústeres de Entrada (MIMIC) es presentada. Mediante cópulas es posible separar la estructura de dependencia de las distribuciones marginales en una distribución conjunta. El uso de cópulas como un mecanismo para modelar distribuciones y su aplicación a MIMIC es ilustrado en la función de prueba Rosenbrock.
Palabras Clave: Optimización global, Cómputo evolutivo, Algoritmos de Estimación de Distribuciones, Cópulas.
]]> Abstract
A new way of modeling probabilistic dependencies in Mutual Information Maximization for Input Clustering (MIMIC) algorithm is presented. By means of copulas it is possible to separate the dependence structure from marginal distributions in a joint distribution. The use of copulas as a mechanism for modeling distributions and its applicaction to MIMIC is illustrated on Rosenbrock test function.
Keywords: Global optimization, Evolutionary computing, Estimation of Distribution Algorithms, Copulas.
Introducción
El algoritmo de Maximización de Información Mutua mediante Clústeres de Entrada (MIMIC, por sus siglas en inglés) (De Bonet 1997) pertenece a una clase más general de algoritmos evolutivos llamados Algoritmos de Estimación de Distribuciones (EDAS, por sus siglas en inglés) (Larrañaga 2002). Los EDAs son utilizados para resolver problemas de optimización mediante búsqueda estocástica. A diferencia de otros algoritmos evolutivos, los EDAs usan modelos probabilísticos en lugar de operadores genéticos tales como cruza y mutación. El uso de modelos probabilísticos permite representar explícitamente dependencias entre las variables de decisión así como su estructura. Un pseudocódigo para EDAs se muestra en el Algoritmo 1.
Como puede observarse en el paso 3, las interacciones entre las variables de decisión son tomadas en cuenta a través del modelo estimado. La posibilidad de incorporar las dependencias entre variables dentro de la nueva población modifica favorablemente el desempeño de un EDA. En la actualidad, varios EDAs han sido propuestos para resolver problemas de optimización en dominios discretos y continuos. En particular, el algoritmo MIMIC utiliza un modelo probabilístico que solo considera dependencias en una secuencia lineal de variables. En este trabajo presentamos una generalización del algoritmo MIMIC en dominios continuos mediante el uso de funciones de cópula.
]]> Algoritmo MIMIC
Al igual que otros EDAs, el algoritmo MIMICCG para dominios continuos (Larrañaga, 1999) propone el uso de un modelo probabilístico ƒΠ (x) para aproximar la verdadera función de densidad ƒ (x) subyacente a un determinado problema de optimización. En particular el modelo ƒΠ (x) propuesto por MIMICCG es de la forma:
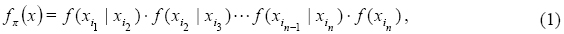
donde las funciones de densidad condicional y univariadas son distribuciones Gaussianas. El subíndice π = (i1, i2,...,in) representa una permutación de índices entre 1 y n.
Para el algoritmo MIMICCCG es importante determinar la permutación π que permita una mejor aproximación de ƒΠ (x) a ƒ(x). Para tal fin, se busca minimizar la divergencia Kullback-Liebler:
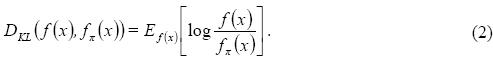
La divergencia Kullback-Liebler siempre es mayor o igual a cero y puede interpretarse como una distancia entre dos funciones. Mediante conceptos de entropía y de información mutua es posible expresar de manera equivalente la Ec. (2) como:
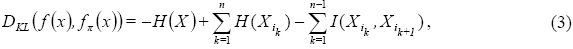
donde H(X) = –Eƒ(x)[logƒ(x)] denota la entropía de una variable aleatoria continua X con densidad  representa la información mutua entre las variables aleatorias
representa la información mutua entre las variables aleatorias 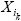 y
y  . Como puede observarse, los dos primeros términos de la Ec. (3) no dependen de la permutación π, por lo que minimizar la divergencia Kullbak-Liebler es equivalente a maximizar la suma de información mutua entre pares de variables. Determinar el orden en que la suma de información mutua es máxima permite encontrar la permutación óptima n. Debido a razones de eficiencia computacional se utiliza un algoritmo voraz con el cual se escoge una permutación adecuada.
. Como puede observarse, los dos primeros términos de la Ec. (3) no dependen de la permutación π, por lo que minimizar la divergencia Kullbak-Liebler es equivalente a maximizar la suma de información mutua entre pares de variables. Determinar el orden en que la suma de información mutua es máxima permite encontrar la permutación óptima n. Debido a razones de eficiencia computacional se utiliza un algoritmo voraz con el cual se escoge una permutación adecuada.
De esta manera, el Algoritmo 2 determina el ordenamiento de las variables de decisión a través de una medida de dependencia como lo es la información mutua. El algoritmo MIMICCG fue propuesto bajo el supuesto de que las distribuciones entre pares de variables son Normales bivariadas, lo que permite encontrar la permutación π a través de fórmulas cerradas en términos de varianzas y covarianzas. En este trabajo se propone el uso de cópulas para generalizar el tipo de dependencia entre variables y separar esas asociaciones de las distribuciones marginales. De esta manera no es necesario restringirse al uso de distribuciones Normales.
]]>Funciones cópula
El concepto de cópula (Sklar, 1959) fue introducido para separar el efecto de dependencia del efecto de distribuciones marginales en una distribución conjunta. La separación entre distribuciones marginales y una estructura de dependencia explica la flexibilidad de modelado que tienen las cópulas y, por esta razón, han sido ampliamente usadas en muchas áreas de aplicación e investigación tales como Finanzas (Trivedi, 2007), Clima (Schölzel, 2008), Oceanografía (De-Waal, 2005), Hidrología (Genest, 2007), Geodesia (Bacigál, 2006) y Confiabilidad (Monjardin, 2007).
Definición 1. Una cópula es una función de distribución conjunta de variables aleatorias uniforme estándar. Esto es,
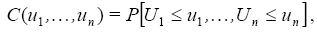
donde Ui ~ U(0,1) para i=1,... ,n.
El lector interesado puede consultar (Joe, 1997) y (Nelsen, 2006) para una descripción más formal de cópulas. El siguiente teorema establece la relación entre distribuciones marginales, cópula y función de distribución.
Teorema 1. (Teorema de Sklar) Sea F una función de distribución n-dimensional con marginales F1 ,F2,...,Fn, luego existe una n-Cópula C tal que para todo x en  ,
,
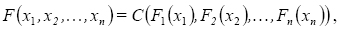
denota la recta real extendida [–∞,∞]. Si F1 ,F2,...,Fn son todas continuas, entonces C es única. En caso contrario, C está únicamente determinada en Ran(F1) x Ran(F2 )x ··· Ran(Fn), donde Ran indica rango de la función. De acuerdo al Teorema de Sklar, la densidad n-dimensional ƒ puede ser representada como
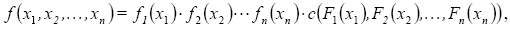
donde c es la densidad de la cópula C. Este resultado permite la elección de marginales diferentes y una estructura de dependencia dada por la cópula para luego ser usadas en la construcción de una distribución multivariada. Esto contrasta con la manera usual de construir distribuciones multivariadas, que tiene la restricción de que las marginales son usualmente del mismo tipo.
Hay muchas familias de cópulas y cada una de ellas está caracterizada por un parámetro o vector de parámetros. Estos parámetros miden la dependencia entre las marginales y son llamados parámetros de dependencia θ. En este artículo usamos cópulas bivariadas con un parámetro de dependencia θ. La Tabla 1 muestra información sobre las cópulas Frank y Gaussiana. Puede observarse la relación que hay entre el parámetro de dependencia y la medida de concordancia Tau de Kendall.
El parámetro de dependencia θ de una cópula bivariada puede estimarse mediante máxima verosimilitud. Para ello debe maximizarse la función log-verosimilitud dada en la Ec. (4),
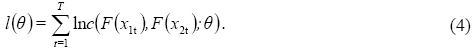
El valor de θ que maximiza la log-verosimilitud es llamado estimador de máxima verosimilitud 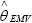 . Una vez que el parámetro θ es estimado, la cópula bivariada queda completamente definida. Para maximizar la función de log-verosimilitud utilizamos como aproximación inicial de a una estimación no paramétrica de θ dada por Tau de Kendall.
. Una vez que el parámetro θ es estimado, la cópula bivariada queda completamente definida. Para maximizar la función de log-verosimilitud utilizamos como aproximación inicial de a una estimación no paramétrica de θ dada por Tau de Kendall.
Algoritmo MIMIC con cópulas
]]> Un resultado que utilizaremos para determinar la información mutua entre dos variables y que involucra la entropía de una cópula (Davy, 2005) es el siguienteH (U1, U2) = –1 (X1, X2),
donde U1 = F (X1) y U2 = F (X2).
Para el algoritmo MIMIC usaremos dos funciones de dependencia diferentes: cópula Frank y cópula Gaussiana. Estas cópulas son seleccionadas debido a que su parámetro de dependencia tiene asociado todo el rango de valores de la medida Tau de Kendall. Esto significa que dependencias positivas y negativas entre marginales son consideradas en ambas cópulas. Sin embargo, las cópulas Frank y Gaussiana difieren en la manera en que ellas modelan valores extremos y centrados. Por ejemplo, una cópula Frank es más adecuada para datos con débil dependencia en los extremos y fuerte dependencia entre valores centrados.
El algoritmo MIMIC que se propone en este trabajo consiste en estimar la entropía de la cópula asociada a cada par de variables para calcular la información mutua. Las dos variables con la información mutua más grande son seleccionadas como las primeras dos variables de la permutación π. Las siguientes variables de la permutación π son escogidas de acuerdo a la información mutua con respecto a la variable anterior (Algoritmo 2).
Para una cópula Gaussiana hay una manera directa para calcular su entropía e información mutua; para una cópula Frank estimamos su entropía mediante una aproximación numérica.
Una vez que una permutación π es encontrada, la generación de muestras sigue el orden establecido por la Ec. (1). Para realizarlo, primero se muestrea la variable Uin de una distribución uniforme estándar y posteriormente se muestrean las variables Uik de la distribución de cópula condicionada de Uik dado el valor de Uik+1 para k = n–1,...,1. Después de lo anterior, se utilizan los valores simulados de Ui para determinar los cuantiles Xi mediante la ecuación  .
.
Es importante mencionar que mediante el uso de cópulas es posible escribir la Ec. (1) como
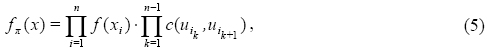
donde  y
y 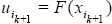 . Esto significa que MIMICCG puede obtenerse como un caso particular de la Ec. (5) al utilizar cópulas Gaussianas y marginales Gaussianas.
. Esto significa que MIMICCG puede obtenerse como un caso particular de la Ec. (5) al utilizar cópulas Gaussianas y marginales Gaussianas.
Para estimar los parámetros de las densidades que aparecen en la Ec. (5) usamos el método de Inferencia para Marginales (Cherubini, 2004). Este método está basado en el método de Máxima Verosimilitud y consiste en estimar los parámetros de las distribuciones marginales y después utiliza esas estimaciones para estimar los parámetros de las cópulas.
Experimentos
Se implementan cuatro algoritmos para optimizar la función de prueba Rosenbrock de 10 dimensiones. Una descripción de la función Rosenbrock se muestra en la Tabla 2. Uno de los algoritmos es MIMICCG y los otros tres son extensiones del mismo:

a) un algoritmo con cópulas Frank y marginales Beta 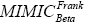
b) un algoritmo con cópulas Frank y marginales Gaussianas 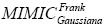
c) un algoritmo con cópulas Guassianas y marginales Beta
 .
. Cada algoritmo es ejecutado 30 veces utilizando un tamaño de población de 200 individuos. El número máximo de evaluaciones es de 300,000. Sin embargo, cuando es detectada convergencia a un mínimo local la ejecución es detenida. Una mejoría menor a 1x10-6 en 25 iteraciones es considerada como convergencia.
Resultados
En la Tabla 3 se muestra un resumen descriptivo de los valores de aptitud logrados por los cuatro algoritmos para la función de prueba Rosenbrock. La información acerca del número de evaluaciones requeridas por cada algoritmo se reporta en la Tabla 4.
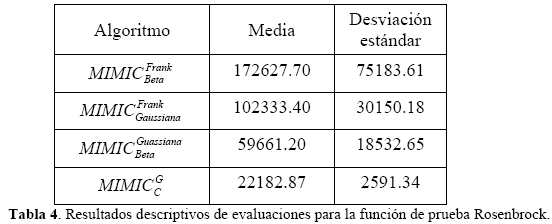
Como puede observarse en la Tabla 3, el algoritmo obtiene en promedio el mejor valor de aptitud aunque tiene asociada una mayor dispersión respecto a los demás algoritmos. En cuanto al número de evaluaciones de función puede verse en la Tabla 4 que MIMICCG es el algoritmo que en promedio requiere menos evaluaciones de la función Rosenbrock, además de ser el más consistente, pues obtiene la desviación estándar más pequeña.
Para determinar si existen diferencias significativas en los resultados se realiza una comparación estadística entre el algoritmo MIMICCG y cada una de las tres extensiones utilizadas en este trabajo. Para ello se utiliza una prueba de hipótesis basada en el método Bootstrap para diferencias de medias. De igual manera se determina mediante Bootstrap los intervalos de confianza del 95% para la diferencia de medias entre algoritmos comparados.
El valor-p reportado en la Tabla 5 para cada comparación de algoritmos indica que existe diferencia significativa entre los promedios de aptitud. Esto también puede apreciarse a través de los intervalos de confianza construidos para la diferencia de promedios, pues en todos los casos se excluye al cero. Dado que en la comparación de algoritmos los intervalos de confianza excluyen valores positivos, puede afirmarse que el algoritmo MIMICCG no obtiene una aptitud similar a la de los otros algoritmos. Esto quiere decir que en los algoritmos , y los promedios de aptitud son mejores que los de MIMICCG . Lo anterior significa que modificar la estructura de dependencia o modificar la distribución de las marginales en el algoritmo MIMIC puede ayudar a obtener mejores resultados en un problema de optimización.
Conclusiones
Se ha presentado una modificación del algoritmo MIMIC mediante el uso de cópulas. Las funciones cópulas permiten separar la estructura de dependencia de las distribuciones marginales, lo que permite una mayor flexibilidad de modelado en distribuciones conjuntas. Aunque la estructura de dependencia usada en los experimentos fue fijada al igual que las distribuciones marginales, esto no necesariamente debe ocurrir para todas las variables. Combinaciones de cópulas y de distribuciones marginales pueden ser utilizadas en un mismo modelo de probabilidad.
Los tres algoritmos que modifican su estructura de dependencia o la distribución de sus marginales obtienen mejores desempeños respecto al algoritmo MIMICCG. Esto sugiere que el uso de cópulas puede mejorar el desempeño de los EDAs, sin embargo, debe tenerse cuidado de escoger las cópulas y las distribuciones marginales más adecuadas para cada problema de optimización.
Referencias
Bacigál, T. y Komorníková, M. (2006). Fitting archimedean copulas to bivariate geodetic data. Compstat 2006 Proceedings in Computational Statistics. Physica-Verlag HD. [ Links ]
Cherubini, U., Luciano, E. y Vecchiato, W. (2004). Copula Methods in Finance. Wiley. [ Links ]
]]>Davy, M. y Doucet, A. (2005). Copulas: a new insight into positive time-frequency distributions. Signal Processing Letters, IEEE, 10(7): 215-218. [ Links ]
De Bonet, J.S., Isbell, C.L. y Viola, P. (1997). MIMIC: Finding optima by estimating probability densities. Advances in Neural Information Processing Systems (9): 424-430. The MIT Press. [ Links ]
De-Waal, D.J. y Van-Gelder, P.H.A.J.M. (2005). Modelling of extreme wave heights and periods through copulas. Extremes 8(4): 345-356. [ Links ]
Genest, C. y Favre, A.C. (2007). Everything you always wanted to know about copula modeling but were afraid to ask. Journal of Hydrologic Engineering 12(4): 347-368. [ Links ]
Joe, H. (1997). Multivariate models and dependence concepts. Chapman and Hall. [ Links ]
]]>Larrañaga, P., Etxeberria, R., Lozano, J.A. y Peña, J.M. (1999). Optimization by learning and simulation of bayesian and gaussian networks. Technical Report KZZA-IK-4-99, University of the Basque Country. [ Links ]
Larrañaga, P. y Lozano, J.A. (2002). Estimation of Distribution Algorithms: A New Tool for Evolutionary Computation. Kluwer Academic Publishers. [ Links ]
Monjardin, P.E. (2007). Análisis de dependencia en tiempo de falla. Tesis de maestría. Centro de Investigación en Matemáticas. Guanajuato, México. [ Links ]
Nelsen, R.B. (2006). An introduction to Copulas. Springer Series in Statistics. [ Links ]
Schölzel, C. y Friederichs, P. (2008). Multivariate non-normally distributed random variables in climate research - introduction to the copula approach. Nonlinear Processes in Geophysics 15(5): 761-772. [ Links ]
]]>Sklar, A. (1959). Fonctions de repartition à n dimensions et leurs marges. Publications de l'Institut de Statistique de l'Université de Paris (8): 229-231. [ Links ]
Trivedi, P.K. y Zimmer, D.M. (2007). Copula Modeling: An Introduction for Practitioners. Foundations and Trends in Econometrics (1). Now Publishers. [ Links ]
Nota
Artículo por Invitación.
]]>