
A system based on the concept of linguistic majority for the companies valuation
Jesús M. Doña,1 Antonio M. Gil,2 David L. La Red,3 José I. Peláez4
1 Department of Information Systems, Health Management Area North of Málaga, Antequera 29200, Spain. Email: jesusm.dona.sspa@juntadeandalucia.es
2 Department of Languages and Computer Sciences, University of Málaga, Málaga 29071, Spain. Email: amgil@ugr.es
3 Department of Financial Economics and Accounting, Granada 18071, Spain. Email: lrmdavid@exa.unne.edu.ar
]]> 4 Department of Computer Sciences, National Northeastern University, Corrientes 3400, Argentina. Email: jignacio@lcc.uma.es
Recepción: 29/09/2010
Aceptación: 31/08/2011
Abstract
Nowadays, it is common the use of qualitative information expressed by experts to solve the problems of economic-financial assessment in uncertainty environments. Two are the difficulties presented in this type of problems; the first one focuses on the information given by the expert, which can be represented in different domains of expression, and the second one is relative to the obtained final solution, which must be representative for most of the experts involved in the process. To solve the first problem, the information representation has been proposed by means of the fuzzy model of linguistic 2-tuples, which allows treating as an homogeneous form the information expressed by the experts in different domains. To solve the second problem, in this work it is proposed to make use of the concept of majority through the OWA operators.
Keywords: Companies valuation, linguistic 2-tuples, OWA Operators.
Clasificación JEL: C44, Q25, D81.
]]> Resumen
Hoy en día es común el uso de información cualitativa expresada por expertos para resolver los problemas de evaluación económico-financiera en entornos de incertidumbre. Dos son las dificultades que se presentan en este tipo de problemas, la primera de ellas se centra en la información dada por el experto, que puede representarse en diferentes dominios de expresión y la segunda es relativa a la solución final obtenida, que deberá ser representativa de la mayoría de los expertos que participaron en el proceso. Para resolver el primer problema se ha propuesto la representación de información por medio del modelo difuso de 2-tuplas lingüísticas, que permite tratar de una forma homogénea la información expresada por los expertos en diferentes dominios. Para resolver el segundo problema, en este trabajo se propone hacer uso del concepto de mayoría a través de los operadores OWA.
Introduction
The search of the company value is a common problem that has become a basic pillar in finance. In fact, the financial target of the company is not other than its maximization. Such circumstance has turned the valuation into a challenge for any analyst or agent. The methodology that makes easy the obtaining of this value arises from the evolution of the Financial Theory, being its fundamental idea that the value of assets is the update of the financial flows that is capable of generating in the future.
It is understood by value that conventional quality of the object that is attributed to as consequence of a calculation or of an expert's report; in this manner the value is not a fact, but an opinion. On the other hand, it is estimated that the price paid as consequence of a transaction, unlike the value, is a tangible fact, a real piece of information. It can happen that the full price be regarded as real madness relative to the considered reasonable value. This does not prevent that the full price is a fact, whereas the value, no matter how important it is, will not have any more consistency than that of an opinion (Besaun et al., 2004, Brilman et al., 1990 y Levrat et al., 1997).
The value is searching its support in a logical or mathematical basis being as rigorous as possible. It looks for the objectivity, neutrality and independence opposite to the parties, the relations of forces on the market and even the market situation itself. An important question to raise around the concept of company value is if it is only or on the contrary different values can be determined for the same company (Ansón et al., 1997).
First of all, it is necessary to bear in mind that the calculation procedure of the company value means the need to predict future scenarios in which its activity is going to be developed, so that, and as consequence of the uncertainty existing in the above mentioned prediction, it will be impossible to determine an only value, and we will have to limit ourselves to establishing a range of values, among which the most probable company value will be found. Secondly, the value is always going to be influenced by the particular characteristics of the subject that is carrying out the valuation, who will project his preferences on it. Therefore, each one will obtain a different value. Thirdly and last, it will be necessary to bear in mind the aim of the valuation, since depending on it different values can be obtained, so we will talk about value for tax purposes, liquidation value, value of a running company, etc.
Therefore, in valuating a company, we try to determine an interval of reasonable values inside which the definitive value will be included. Valuating a company is a question of obtaining an estimation that, on the other hand, never is an exact and only number, but it will depend on the situation of the company, the moment of the deal and the used method. To determine the value it is necessary to establish hypotheses and future scenarios. These hypotheses generate uncertainty so that the final result will be an interval or series of values and not just one. Finally, the information derived from the valuation report prepared by the experts will serve as base for the negotiation between the parties, from which the definitive transaction price will arise (Kaufmann et al., 1993).
Within the last few years, with the globalization of the markets, their technological development and the appearance of new financial instruments have promoted new valuation techniques improving the ones already existing. Among all these methods, we can emphasize the so called Operative or Mixed Analysis, in which the company value has basically two components, the Static Value and the Potential Capital Gain, also named Goodwill; or the Discounted Cash-Flow method, based on the future liquidity that the company is able to generate, also bearing in mind the cost of opportunity and the risk of undertaking such investments (Fernández, 2005, Ruiz et al., 2004). In this work, because of the proposed aims, the Operative or Mixed Analysis method will be used.
]]> As it has been pointed out, the valuation methods use future estimations that, in many cases, are expressed by experts according to their experience or perception of reality. In these conditions, it is necessary to have tools that allow to operate with the uncertainty of the expressed opinions, which normally are defined in linguistic values in different domains of expression; and that these tools be capable of adding the opinions in a value representative of themselves (Copeland et al., 2000, Cross et al., 2006, Herrera y Martínez, 2000, Kaufmann et al., 1986, Keenan et al., 1997).In this work, a new system of company valuation based on the Operative Analysis method is presented and compared, that allows to obtain information of greater quality for the making of business decisions, synthesizing linguistic information through the 2-tuples model of representation (Herrera y Martínez, 2000), and the majority concept through the LAMA OWA operators of aggregation (Peláez et al., 2003a, 2003b, 2005).
The article structure is the following: In the second section, the Operative or Mixed Analysis method is introduced; in the third section, the information representation appears using linguistic tags with the 2-tuples model and the LAMA aggregation operator; in the fourth section, a linguistic alternative model of companies valuation is presented, and a detailed example of application is developed; finally, the results are compared with other models and the conclusions are shown.
Economic-financial valuation of companies
The company value, by means of the Operative or Mixed Analysis method, is given by the sum of two components:
• Static Value, for which we propose the Real Net Asset.
• Potential Capital Gain or Goodwill, for which we take the difference updated between the due benefit and the cost of opportunity that the investor assumes by carrying out the acquisition of the company in question without applying his resources in other alternative investments.
Mathematically:
]]>
Where:
Ve = Company value.
ANR = Real Net Assets
B: Profits before interest and after taxes.
CPNE: Permanent Capitals Needed for Operation.
R : Average Rate of Return of the assets in the sector where the company deals.
K : Update rate.
an-K : Current value of a unitary income, constant, post payable and immediate, which amount is given by:

• Hypothesis 1: ANR = CPNE, that generically will be called ANR.
• Hypothesis 2: R = K, that generically will be called interest rate i.
The simplified expression that gives us the company value would be, therefore:

In case the estimation of benefits and interest rates for future periods shows different values in each period, the company value will be determined by the following expression:

Nevertheless, the calculation carried out this way presents a series of disadvantages that are necessary to consider and try to avoid to be able to establish a valuation as closest as possible to reality.
Among these disadvantages there is the way in which the estimations are expressed and the way in which the information is added. Both the valuations of the interest rates and the expected future benefits must be carried out by experts, in which case a mechanism that facilitates the obtaining and later aggregation of the above mentioned information has to be established. To express the estimations, not being able to obtain it through a quantitative value, it is more feasible to obtain it in a qualitative way, so it is necessary to use a linguistic approach. Also, as it has been previously pointed out, it is very important that the aggregate value be a value that is representative, a value of majority, of the estimations obtained by the experts.
]]> Fuzzy linguistic approach
Actually, the concept of linguistic variable is widely used in those decision making problems with imprecise assessments given in a linguistic way for some of its elements. Usually, many aspects of different activities cannot be assessed in a quantitative form, but rather in a qualitative one, i.e., with vague or imprecise knowledge. In that case, a better approach may be to use linguistic assessments instead of numerical values. The fuzzy linguistic approach represents qualitative aspects as linguistic values by means of linguistic variables.
This approach is adequate in some situations, for example, when attempting to qualify phenomena related to human perception, we are often led to use words in natural language. This may arise for different reasons. There are some situations where the information may not be quantified due to its nature, and thus, it may be stated only in linguistic terms (e.g., when evaluating financial situations terms like "bad", "poor", "tolerable", "average", "good" can be used). In other cases, precise quantitative information may not be stated because either it is not available or the cost of its computation is too high, then an "approximate value" may be tolerated (e.g., when evaluating the cost of an infrastructure, terms like "expensive", "very expensive", "cheap" are used instead of numerical values). The fuzzy linguistic approach has been applied with very good results in different problems, such as, information retrieval, decision-making, etc.
One possibility of generating the linguistic term set consists of supplying a context-free grammar. However, this approach implies establishing previously the primary fuzzy sets associated with each term and the semantic rule that modifies them, and this task is not easy. An alternative possibility consists of directly supplying the term set by considering all terms distributed on a scale on which a total order is defined (Herrera et al., 2000). For example, a set of seven terms S, could be given as follows:

In this paper, we shall use labels with triangular membership (Figure 1) for simplifying the mathematical processing. For example, we may assign the following semantics (Table 1) to the set of seven terms, where the first and final values represent the start and the end of the triangular function and the centre value is the zenith.


The 2-tuple fuzzy linguistic representation model was presented in (Herrera et al., 2000), where different advantages of this formalism are shown to represent the linguistic information over classical models.
From this concept, in (Herrera et al., 2000) is developed a linguistic representation model which represents the linguistic information by means of 2-tuples (ri, αi), ri ∈ S and αi ∈ [-0.5, 0.5). ri represents the linguistics label center of the information and ai is a numerical value that represents the translation from the original result b to the closest index label in the linguistic term set (ri), i.e., the Symbolic Translation.
This linguistic representation model defines a set of functions to make transformations among linguistic terms, 2-tuples and numerical values:
Definition. Let si ∈ S be a linguistic term, them its equivalent 2-tuple representation is obtained by means of the function q as:

Definition. Let S = {s0, s1, ... , sg} be a linguistic term set and β ∈ [0, g] a value supporting the result of a symbolic aggregation operation, then the 2-tuple that expresses the equivalent information to β is obtained with the following function:

where round is the usual operation, si has the closest index label to "β" and "α" is the value of the symbolic translation.
Definition. Let S = {s0, s1, ..., sg} be a linguistic term set and (si, α) be a linguistic 2-tuple. There is always Δ-1 function, such that, from a 2-tuple it returns its equivalent numerical value β ∈ [0, g].
]]>
To aggregate the information in the voting process, the OWA operator is proposed. The OWA operator used in this work is the LAMA (Peláez et al., 2003a); due to this operator, it is adequate to synthesize linguistic information in decision making environments producing aggregated results with a majority semantic (Peláez et al., 2006, 2007).

with bj being the jth largest element of the ai, and ⊕ is the sum of labels and 7 is the product of a label by a positive real (Peláez et al., 2003b).
The weights used in the LAMA operator are usually calculated from majority process as follows:
Let δi the cardinality for the element i with δi > 0, then

where

and
]]>
The majority operators aggregate in function of δi that generally represents the importance of the element i using its cardinality. In the majority processes are considered the formation of discussion or majority groups depending on similarities or distances among the experts' opinions. All values with a minimum of separation are considered inside the same group. The calculation method for the value δi is independent from the definition of the majority operators.
An alternative model to value companies
In the second section, it was showed that the diverse criteria for the companies' valuation make use of references to futures to estimate both the interest rates and the expected benefits. A way to get these references to futures is by means of the opinion expressed by the experts, who making use of their experience and knowledge make a few judgments about them using qualitative information.
The proposal of this work is to incorporate the above mentioned information and the majority concept into the companies' valuation process using the method of Operative or Mixed Analysis, so that the prospects the experts do, both for the interest rates and the expected benefit, could be expressed by them making use of their own valuations and domains of expression, and that those values be representative of their valuations.
The steps to follow in the developed valuation model are the following ones: For every estimation to be carried out, the consulted experts will express their valuations inside their own domain of expression; next, all the domains will normalize in the only unified domain of expression, by means of the model of linguistic 2-tuples, on which the information will be added for every value of the interval to consider by making use of the LAMA operator. A standardization will be applied to the obtained results according to the unified domain of expression initially chosen.
In this point, to estimate the interests and future benefits, the following expression will be applied:

Being L1N, L 2N the standardized values after applying the LAMA operator to the linguistic labels.
]]> Finally, to obtain the company value, the following expression is applied
The calculation of the Real Net Asset (ANR) will be carried out in accordance to the criteria commonly accepted in the business evaluation. In any case, this information would be set in uncertain terms, by means of an interval that defines the possible value ascribed on which to operate in the same way described for the values of the interest rates and estimated future benefits.
Next, a detailed example of this model of valuation of linguistic companies is developed based on the concept of majority and 2-tuples. To that end, first of all the future interest rates are calculated, secondly the future benefits, and finally, the company value is estimated.
Future interest rates estimate (i)
In order to analyze the company value, the estimation process for the interest rates usually begins with an analysis that allows to consider the possible stretches between which it is expected that the interest rate will fluctuate for the periods that are to be considered in the study, so that these should serve as the beginning point in the process of negotiation between the parties that participate in it.
In the practical example that is intended to be explained, there has been established a period of analysis of three years, for which there have been considered the following stretches for the interest rates:

In order to reach a consensus on the validity of that information, it is feasible to turn to several experts so that they facilitate their conformity with each of the initial values. The information request, according to the considerations carried out in the previous sections, must be done so that each one can use terms usual to them. Thus, three different linguistic sets are obtained with the following semantics:
]]>
where Sij is the label number i of a linguistic set with j labels.
This way we obtain the following linguistic valuations for each domain where the experts evaluate each value of the interval, when the value is the same for both of them, only one label is represented (Table 2).

Firstly, it will be necessary to proceed to the standardization of the valuations established by the experts. For this it is necessary to determine the set of linguistic terms that will be used as a base to unify the information. In this case, since most of the experts have used the domain S9, this will be the chosen one, although it is possible to choose any other. This way the table results as follows:
With the information represented in linguistic 2-tuples and unified in the same expression domain, proceed to the process of aggregation of that information, consisting in obtaining a value that represents the set of values (the set of opinions) wanted to join so that we could introduce the majority concept and eliminate possible inherent problems in the aggregation.
To calculate the weights, we establish the cardinalities of the elements using the equality concept between tags defined in (Peláez et al., 2007).



So the future interest for this period will be:

Likewise it operates in the remaining periods, which enables it to establish the aggregate opinion of the experts obtaining more adjusted estimations for the interest rates than initially considered.

Future profits estimate (B)
The process of company valuation, as it was pointed out, needs to establish a few values on which buyers and sellers agree with regard to the possible benefits to obtain in the periods considered in the process. For this, first of all it is possible to start from a few intervals for the benefits quantification that will serve as reference to request the experts' opinion. These must be established by the buyer as well as the seller.
]]> To the operative effects of the practical resolution, there have been established the following indicative intervals of the possible benefits for the three analysis periods:
From the previous estimations, it is possible to request the collaboration of a group of experts to express their opinion by means of linguistic evaluations.
The previous information standardization process in a sole expression domain will be done following the same criteria as in the previous section.
Next, the unified information will be added, obtaining a value that represents the set of opinions collected from the different experts. In this regard, we proceed to carry out the aggregation, following the same methodology put into practice for the estimation of the interest rate. Therefore, from the information gathered in the previous table it will be possible to establish the cardinalities for the buyers and sellers valuations collected in tables 6 and 7 respectively.


The previous information allows to obtain the future benefits, although in order to avoid repeating the calculations, only the operations corresponding to the first period for the buyers are carried out.


Operating in the same way with sellers we get:

And for the remaining intervals

In an initial approach, for the first period, the aggregate opinion of the buying experts establishes a minimal value in 4.898. For their part, the sellers establish a maximum valuation of 5.361, so that a new interval would be to get [4.989, 5.361], in which there would appear all the opinions expressed by the experts.
]]> Therefore, a meeting point that serves as a base for the negotiating process is laid down, although a new assessment could be necessary for the obtained interval. In this case, you can proceed in a similar way as done with the initial intervals; it will allow to reduce again the uncertainty as it diminishes the base of the interval that would be obtained.Also, if it is needed to proceed to the movement of the obtained result, it would be possible to proceed to a parameterization process. Nevertheless, in order to facilitate the resolution of the raised example, the results obtained in the first process are accepted as valid, using therefore that information for the calculation of the company value.
Calculation of the entire value of the company (Ve)
As it has been said before, the basic formula for the estimation of the company value is the following one:

That can be simplified with the following nomenclature

Therefore, the expression of the estimated value would stay in the following way
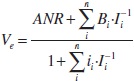
As for the value of the Real Net Asset (ANR), in order not to repeat calculation processes, it is assumed that is known and accepted in an amount of 3.000 monetary units. Therefore, the available information in order to proceed to the estimation of the company value is the following one:
]]>
The information on the interest rates allows to obtain the corresponding types of update rates:

The process to obtain the interest rates and the updated benefits for each of the periods of analysis is carried out based on the calculations stated next:

So that the company value is obtained:

The previous result allows ascertaining that the benefit will be neither lower than 12.047 nor will overcome 14.212 monetary units. The range of the interval must be an object of negotiation between the parties; although, if a lower uncertainty base is considered to be necessary, it would be possible to resort to a new assessment until that uncertainty could be negotiated between buyers and sellers.
Comparative of the method
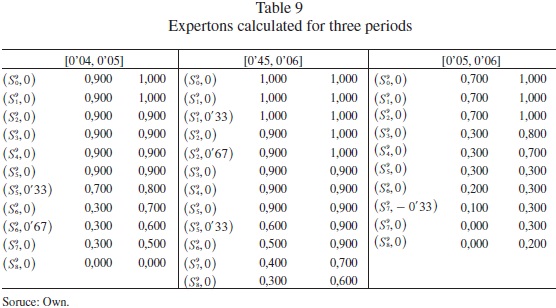
]]> To carry out the comparative of the process proposed in this work, we have chosen to apply the methodology of the expertons (Kaufmann, 1987), extended to the 2-tuples to carry out the process of aggregation of the experts opinions. The company value will be determined by the method of the Operative AnalysisDefined by Kaufmann (1987), the expertons are a method that allow adding the opinion of several experts, from the valuations given by them, where a statistics is carried out on all possible values, which will depend on the used scale. That statistics undergoes a standardization process according to the number of available opinions. Precisely, the complementary accumulated function is what is named experton.
In Table 9, the expertons (accumulation function) are shown for each range. While in Tables 10, 11 and 12, the R+-expertons of the method will be determined.



To the obtained values the mathematical expectation is calculated, resulting:

To calculate the future benefits, we must operate in a similar way, that is to say, the expertons must be calculated using the statistics for sellers and buyers. Later, the R+expertons are generated and the mathematical expectation is calculated. Finally, the following results are obtained for the buyers and sellers:

With that, a final company value is obtained after calculating the interest rates and the updated benefits for each of the periods of analysis:

Analysis of the two methods
Once the problem is solved with both methods, it can be seen that the results produced by the method of companies of majority valuation are comparable, the partial ones as well as the final outcome, to the ones obtained by the traditional method of the Expertons, being a light displacement of the final valuation range, prompted by the application of the majority concept in the valuations expressed by the experts. This fact allows us to establish that the results that this new method reproduces are not far from of an acceptable solution, as they are within the values that other traditional methods reproduce, as the method of the expertons.
]]> The final interval is displaced to the values most representatives of the expert's opinions because the new approach includes the majority concept through the LAMA operator in the aggregation process. This aggregation operator is able to reflect the expert's opinions where the aggregation value is more affected by the majority of opinions than traditional aggregation operator (Peláez et al., 2003, 2006 y 2007).A problem posed by some of the traditional methods of company valuation, also produced by the method of the expertons, is not monotony, as can be verified in the calculation of the purchase profit of the first interval, where the aggregation of the values {(S5,0), (S5,0), (S4,0), (S2,0), (S1,0)} and {(S7,0), (S5,0), (S5,0), (S4,0), (S2,0)} produce the same result. This problem is due to the concept of relative frequency on which the expertons are based, whereas these problems are eliminated by the method based on the majority concept, at the same time that avoids appearing problems of distribution in the decision making process (Peláez, 2003b).
Finally, another advantage that the method proposed in this work offers is that it allows pre calculating the weights of the valuations carried out by the experts, hence its reusing in other valuation processes, making the application of the method to be almost immediate, which is not possible with the traditional methods.
Conclusions
In this work, a linguistic alternative model of company valuation has been presented, based on the method of the Operative Analysis and the concept of linguistic majority. As it has been put forward, in the process of company valuation it is important that the obtained solution be representative of most of the valuations expressed by the experts. That's why the majority LAMA operator extended to the linguistic representation of 2-tuples has been used, which enables to work with a representation of multigranular information at the aggregation process.
The practical development has made possible to ascertain the validity of the system, through the comparison with the method of the expertons. The combined use of the linguistic majority operators and the 2-tuples enables the treatment of the information given by experts of each of the parties (buyer and seller) in a natural way, generating results more representative of the initial evaluations and contributing with the advantages of the majority concept making the consensus process in the final valuation easier.
As well as the previous advantages, this new method prevents problems like not monotony, and it makes possible to have the valuation weights by means of a precalculation process, which enables its reuse in other valuation processes, making the application of the method to be almost immediate, which is not possible with the traditional methods.
Acknowledgements
]]> This work is supported by the Ministry of Education and Science of Spain. Project TIN2006-14285.
References
Ansón Lapeña, José A. (1997). Valoración de empresas: análisis de los métodos utilizados en la práctica. Ediciones del Instituto de Auditores-Censores Jurados de Cuestas de España. [ Links ]
Besoun, Jean-Jaques, Jean-Jaques (2004). "El nuevo reto del director financiero: riesgo y beneficio". Revista Estrategia Financiera. Anuario. [ Links ]
Brilman, J. & Maire, C. (1990). Manual de Valoración de Empresas. Ediciones Díaz de Santos, S. A. [ Links ]
Copeland, T.; Koller, T.; Murrin, J. (2000). Valuation, Measuring and Managing the Value of Companies. McKinsey and Company. [ Links ]
Cross, R. L., Brodt, S. E. (2006). "El valor del juicio intuitivo en la toma de decisiones". Expansión/Harvard Deusto. Dirigir en la Incertidumbre, pp. 153-176. [ Links ]
Fernández, P. (2005). Valoración de empresas. Ed. Gestión 2000. [ Links ]
Herrera F., Martínez L. (2000). "A 2-tuple fuzzy linguistic representation on model for computing with words". IEEE Transactions on Fuzzy Systems 8:6, 746-752. [ Links ]
Kaufmann. (1988). "Theory of Expertons and Fuzzy Logic". Fuzzy Sets and Systems. Vol. 38. pp. 295-304. [ Links ]
Kaufmann, A. (1987). Les Expertons. Paris. Hermes. [ Links ]
Kaufmann, A., Gil Aluja, J. (1986). Introducción de la teoría de los subconjuntos borrosos en la gestión de empresas. Ed. Milladoiro, Santiago de Compostela. [ Links ]
Kaufmann, A., Gil Aluja, J. (1993) Técnicas especiales para la gestión de expertos. Vigo. Milladoiro. [ Links ]
Keenan E. L. and Westerstal D. (1997). "Generalized quantifiers in Linguistic and Logics". In van Benthem J., ter Meulen A. (eds) Handbook of logic and language, Amsterdam: North-Holland, 837-893. [ Links ]
Levrat, E., Voisin, A., Bombardier, S. y Bremont, J (1997). "Subjective Evaluation of Car Seat Comfort with Fuzzy Set Techniques". International Journal of Intelligent Systems. Vol. 12. Pgs. 891-913. [ Links ]
Peláez, J. I., Doña, J. M. (2003a). "LAMA: A Linguistic Aggregation of Majority Additive Operator". International Journal of Intelligent Systems. [ Links ]
Peláez, J. I., Doña, J. M. (2003b). "Majority Additive-Ordered Weighting Averaging: A New Neat Ordered Weighting Averaging Operators Based on the Majority Process". International Journal of Intelligent Systems, 18, 4, 469-481. [ Links ]
Peláez, J. I., Doña, J. M. (2005). "Majority Multiplicative Ordered Weighting Geometric Operators and Their Use in the Aggregation of Multiplicative Preference Relations". Mathware & Soft Computing, 107-120. [ Links ]
Peláez, J. I., Doña, J. M. (2006). "A Majority Model in Group Decision Making Using QMA-OWA Operators". International Journal of Intelligent Systems, 193-208. [ Links ]
Peláez, J. I., Doña, J. M., Gómez-Ruiz J. A. (2007). "Analysis of OWA Operators in Decision Making for Modelling the Majority Concept". Applied Mathematics and Computation. [ Links ]
Ruiz, R. J., Gil, A. M. (2004). El valor de la empresa. Instituto superior de técnicas y prácticas bancarias. Madrid. [ Links ]
Notas
We would like to thank the anonymous referee for helpful comments on an earlier draft. All remaining errors, however, are solely ours.
]]>