Validation Study on Artificial Neural Network-Based Selection of Time Series Forecasting Techniques
Acosta-Cervantes M.C.1, Villarreal-Marroquín M.G.2 y Cabrera-Ríos M.3
1 División de Posgrado en Ingeniería de Sistemas Facultad de Ingeniería Mecánica y Eléctrica Universidad Autónoma de Nuevo León Industrial Engineering Department University of Puerto Rico at Mayagüez. Correo: mcarmen8070@gmail.com
2 Integrated Systems Engineering Department The Ohio State University. Correo: villarreal-marroquin.1@osu.edu
3 Industrial Engineering Department University of Puerto Rico at Mayagüez. Correo: mauricio.cabrera1@upr.edu
]]>Información del artículo: recibido: julio de 2010.
Reevaluado: octubre de 2011.
Aceptado: marzo de 2012.
Resumen
En este trabajo se presenta un estudio de validación de un método para seleccionar técnicas de pronóstico de series de tiempo. En el método propuesto se utilizan Redes Neuronales Artificiales para predecir el desempeño de varios métodos estadísticos tradicionales de pronóstico para así seleccionar el de mejor potencial. Para llevar a cabo la validación, se emplearon dieciocho series de tiempo reales, correspondientes a actividades económicas del estado de Tamaulipas. Los resultados apuntan a que el método de selección propuesto es suficientemente confiable para devenir un recurso de fácil aplicación para personas con poco conocimiento estadístico. Tablas con los resultados del método se incluyen en este trabajo para hacer más conveniente la identificación del método estadístico tradicional de pronóstico sugerido.
Descriptores: redes neuronales artificiales (RNA), métodos de pronóstico, series de tiempo.
Abstract
]]> In this paper, a validation study for a method geared towards the selection of forecasting techniques for time series is presented. The proposed method makes use of artificial neural networks to predict the performance of several statistics-based forecasting techniques to help select the potential best one. Eighteen time series with real data related to economic activities in the state of Tamaulipas were used for validation purposes. The results indicate that the proposed method is sufficiently reliable to become a useful resource for people with modest level of training in statistics. It is also proposed that the method be tabulated for convenient access.Keywords: Artificial Neural Network (ANN), forecasting methods, time series.
Introducción
Con el fin de mantener su viabilidad y supervivencia, toda empresa requiere tomar decisiones con anticipación a los posibles cambios en su mercado. Estas decisiones se toman en tiempo presente con información histórica, así como con inferencias acerca del futuro, esto es, con pronósticos.
Existen muchas técnicas estadísticas de pronósticos en la literatura; sin embargo, en el grueso de las compañías medianas y pequeñas de México, es común que no se usen estas técnicas. Algunas veces se prescinde de su uso por desconocimiento de las mismas, otras por no conocer su aplicación correcta y en algunas otras, porque resulta difícil seleccionar la técnica más adecuada para cada caso. Esta situación se agrava cuando no se cuenta con paquetería computacional especializada para realizar pronósticos, y cuando no se tiene el tiempo suficiente para aprender cómo utilizar varias técnicas de pronóstico para seleccionar una con buen desempeño. Tener la capacidad de seleccionar un método adecuado de pronóstico podría entonces ayudar, en general, a mejorar la utilización de estas técnicas en el país y, en particular, resolver problemas fácilmente (Villareal, 2006).
Este trabajo resume la aplicación en dieciocho series de tiempo reales del método desarrollado en Villareal (2006) para seleccionar la mejor técnica de pronóstico entre ocho técnicas estadísticas. El método está basado en redes neuronales artificiales (RNA) para predecir el desempeño de cada técnica de pronóstico cuantificado por el error cuadrado medio (MSE por sus siglas en inglés). La capacidad predictiva de las RNA ha sido estudiada y matemáticamente demostrada para funciones analíticas en Hornik et al. (1989) y Salazar (2005), por ejemplo, se utilizaron redes neuronales artificiales para pronosticar la demanda en una compañía de telecomunicaciones.
Las series de tiempo utilizadas en este trabajo fueron obtenidas del sitio de internet del Instituto Nacional de Estadística y Geografía e Informática (INEGI, 2007) en la sección del Banco de Información Económica (BIE). Además, se obtuvieron datos de la página de internet de la Secretaría de Agricultura, Ganadería, Desarrollo Rural, Pesca y Alimentación (SAGARPA, 2007). Todas las series de tiempo se relacionan con actividades económicas del estado de Tamaulipas para establecer la pertinencia del estudio a un nivel regional.
Los ocho métodos de pronóstico de series de tiempo (datos disponibles por los autores) utilizados en este trabajo son: (T1) método ingenuo, (T2) promedio, (T3) promedio móvil, (T4) promedio móvil autorregresivo integrado o "ARIMA" (0, 1, 1) acrónimo del inglés Autoregressive Integrated Moving Average, (T5) suavizado exponencial simple, (T6) regresión lineal, (T7) ARIMA (0, 2, 2) y (T8) suavizado exponencial doble. El método ingenuo (T1), promedio (T2), promedio móvil (T3) y suavizado exponencial (T5) se utilizan comúnmente cuando los datos históricos son relativamente constantes en el tiempo. Si los datos presentan una tendencia lineal, creciente o decreciente, el método de regresión lineal (T6) y el método de suavizado exponencial doble (T8) son los más recomendados. Los métodos ARIMA (0, 1, 1) (T4) y ARIMA (0, 2, 2) (T7) son equivalentes al suavizado exponencial simple y doble, respectivamente, con la diferencia de que pueden aplicarse a series de tiempo constantes y de tendencia con estacionalidades, esto es, a series de tiempo donde los datos presentan un patrón repetitivo cada k unidades de tiempo. Detalles de cada método pueden consultarse en Hillier y Lieberman (2001) y Makridakis et al. (1998).
Todos los métodos de pronóstico, a excepción de los ARIMA y el de regresión lineal, se codificaron en MS Excel para medir su desempeño de predicción por medio del MSE. Para los métodos ARIMA y regresión lineal se utilizó el paquete computacional estadístico MINITAB.
]]>Método para predecir la mejor técnica de pronóstico
En Villarreal (2006), se desarrollaron varias RNA para estimar el desempeño de predicción de los ocho métodos de pronóstico mencionados. El objetivo es seleccionar el método de pronóstico más competitivo dadas dos características de la serie de tiempo bajo análisis: el número de datos históricos disponibles (t) y el orden máximo de un polinomio (n) ajustado a la serie de tiempo con un nivel de aproximación de más de 80%. El presente trabajo aplica este método a series de tiempo reales.
El método propuesto por Villarreal et al. (2009) se apoya en la capacidad de aproximación de las RNA para predecir el desempeño de varias técnicas de pronóstico. Los pasos del método, partiendo de que se tiene una serie de tiempo con más de doce datos, son como sigue:
1. Escalar los datos al intervalo [-1, 1]. Los datos de la serie de tiempo se normalizan para que caigan en un rango de [-1, 1] con el objetivo de eliminar efectos de dimensionalidad.
2. Caracterizar la serie de tiempo. Se determinan dos parámetros que caracterizan la serie: el número de períodos de la serie de tiempo (t) y el grado del primer polinomio (n) que se ajuste a los datos de la serie con un coeficiente de determinación, R2 >80%.
Los dos parámetros que se necesitan para esta caracterización se pueden obtener fácilmente. El parámetro t resulta de un conteo directo de datos y el parámetro n de una prueba secuencial de aproximación ejecutable en MS Excel. Ambos se pueden obtener a partir de una gráfica de dispersión de Datos vs. Periodo. Para encontrar n, basta usar la opción de ajustar una línea de tendencia de tipo polinomial a los datos y presentar en pantalla tanto el valor de R2 como la expresión polinomial. El objetivo es determinar el orden del polinomio de manera creciente a fin de detectar el primero con el que se obtenga un R2 >80%. Para los casos donde las series necesitaban un valor de n más grande que el obtenido por la opción de Excel, se realizó un ajuste d curvas por medio de mínimos cuadrados y así se obtuvo el valor de R2 deseado.
]]> Una RNA, en el contexto del método propuesto, es en esencia un modelo matemático no lineal que contiene parámetros conocidos como "pesos". Cuántos más pesos tenga una RNA, mayor no linealidad se podrá representar con ella. Para encontrar estos pesos se utilizan algoritmos de optimización que minimizan una función de errores cuadrados de aproximación. En el área de redes neuronales, varios de estos algoritmos de optimización se clasifican bajo el nombre de "algoritmos de retropropagación". Por otro lado, encontrar un conjunto de pesos que permitan una aproximación adecuada a datos conocidos se le denomina "entrenamiento".3. Someter a la red neuronal artificial. Se utiliza una red neuronal artificial previamente entrenada, donde se usan como entradas t y n y como salida la predicción del error cuadrado medio para cada uno de los métodos de pronóstico.
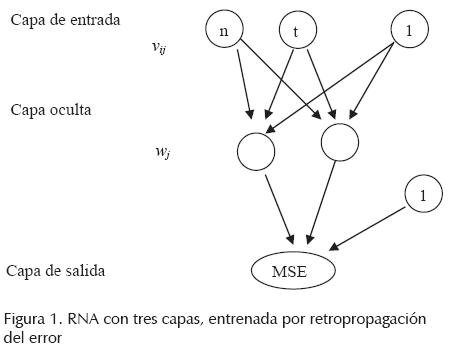
La RNA que se propone en esta etapa se representa como se muestra en la figura 1. Esta RNA cuenta con 3 capas: una capa de entrada que recoge los valores de t y n, una capa oculta que procesa esta información, y una capa de salida por la que se obtiene el MSE predicho para un método de pronóstico en particular.
En la Figura 1, vij es un peso de la conexión que llega a la j-ésima neurona de la capa oculta procedente de la i-ésima neurona de la capa de entrada y wj es el peso de la conexión que llega a la neurona de salida procedente de la j-ésima neurona de la capa oculta. Estos pesos se usan para ponderar las salidas generadas por las neuronas de la RNA. Los pesos que se aplican a las conexiones provenientes de neuronas que vemos con valor constante de uno se denominan sesgos. Información más detallada sobre las RNA puede consultarse en Hagan y Demut (1995) y en Zhang et al. (1998).
4. Establecer un orden entre los métodos y escoger los tres me-ores. Por último, se ordenan los métodos de acuerdo a su MSE predicho y se escogen los tres mejores, éstos serán los que tengan el MSE más pequeño. Los métodos resultantes son los que se deben utilizar para generar los pronósticos.
Series de prueba
El método descrito se aplicó a dieciocho series correspondientes al sector económico del estado de Tamaulipas. Como se detalló antes, las series fueron obtenidas de los sitios de internet oficiales del Instituto Nacional de Estadística y Geografía e Informática (INEGI, 2007), en la sección del Banco de Información Económica (BIE) y de la Secretaría de Agricultura, Ganadería, Desarrollo Rural, Pesca y Alimentación (SAGARPA, 2007). Las series representan lo siguiente:
]]> SERIE 1. Consumo privado por finalidad en el sector turismo, cuenta satélite de turismo (1993-2004). Valor de todas las compras, bienes o servicios realizados por individuos, empresas o instituciones privadas sin intención de lucro.SERIE 2. Número de establecimientos (unidad de medida: número de establecimientos en activo), principales características de la industria maquiladora de exportación, estadísticas de la industria maquiladora de exportación (EIME), enero-diciembre de 2006. Número de unidades activas en operación con disposición de un programa de maquila de exportación.
SERIE 3. Materias primas (unidad de medida: miles de pesos), componentes de valor agregado de exportación, estadísticas de la industria maquiladora de exportación (EIME), enero-diciembre de 2005. Valor de la actividad de maquila de exportación referente a la materia prima por transformación de bienes, ensambles o servicios.
SERIE 4. Insumos importados (unidad de medida: miles de pesos corrientes), principales características de la industria maquiladora de exportación, estadísticas de la industria maquiladora de exportación (EIME), enero-diciembre de 2006. Valor de los materiales importados para la transformación de la industria maquiladora de exportación.
SERIE 5. Camarón (unidad de medida: kilogramos), producción acuícola en sistemas controlados, pesca Tamaulipas (1990-2004). Kilogramos de camarón producidos en sistemas acuícolas controlados.
SERIE 6. Índice de productividad (indicadores anuales, unidad de medida: índice base 1993=100), Tamaulipas, división IX otras industrias manufactureras, industria maquiladora de exportación (1990-2004). Índice de productividad laboral en la industria manufacturera.
SERIE 7. Índice de productividad total (indicadores anuales, unidad de medida: índice base 1993=100) Tamaulipas, industria maquiladora de exportación (1990-2004). Índice de productividad total en la industria maquiladora de exportación producción/consumo total
SERIE 8. Índice de productividad (indicadores anuales, unidad de medida: índice base 1993 = 100). Tamaulipas, división V sustancias químicas, derivados del petróleo, productos de caucho y plástico, industria maquiladora de exportación (1990-2004). Índice de productividad para la industria maquiladora de exportación, división V sustancias químicas (producción/consumo).
SERIE 9. Bagre (unidad de medida: kilogramos), producción acuícola en sistemas controlados, pesca Tamaulipas (1990-2004). Kilogramos de Bagre producidos en sistemas acuícolas controlados.
SERIE 10. Ingresos por remesas familiares por entidad federativa (unidad de medida: millones de dólares), Tamaulipas, sector externo. Trimestres 1, 2, 3 y 4 de 2003, 2004, 2005 y 2006, trimestre 1 de 2007. Millones de dólares recibidos por remesas familiares.
]]> SERIE 11. Petroquímicos por producto total (indicador anual, unidad de medida: miles de toneladas), subsector petrolero, producción de petróleo y elaboración de productos petrolíferos y petroquímicos, sector energético (1980-2002). Miles de toneladas producidas de productos petrolíferos y petroquímicos en el sector energético.SERIE 12. Carbón (indicadores anuales, unidad de medida: petajoules), producción de energía primaria, sector energético (1970-2004). Petajoules de carbón producidos del sector energético.
SERIE 13. Petróleo crudo (indicadores anuales, unidad de medida: petajoules), producción de energía primaria, sector energético (1970-2004). Petajoules de petróleo crudo producidos del sector energético.
SERIE 14. Promedio diario del salario base de cotización al Instituto Mexicano del Seguro Social (unidad de medida: pesos), Tamaulipas, empleo y desempleo. Doce periodos de 2002, 2003, 2004, 2005, 2006 y seis periodos de 2007. Promedio diario del salario base de cotización ante el IMSS.
SERIE 15. Ingresos del sector público total (unidad de medida: millones de pesos a precios corrientes), finanzas públicas e indicadores monetarios y bursátiles, finanzas públicas. Doce periodos de 1995 al 2006 y tres periodos de 2007. Millones de pesos ingresados al sector público.
SERIE 16. Carbón mineral no coquizable (unidad de medida: toneladas), volumen de producción minerometalúrgica por principales productos, metales y minerales siderúrgicos, sector minero. Doce periodos de 1990 hasta 2006 y cuatro periodos de 2007. Toneladas producidas de Carbón mineral no coquizable.
SERIE 17. Petróleo crudo (unidad de medida: miles de barriles por día), volumen de producción de petróleo crudo y gas natural, sector minero. Doce periodos de 1990 hasta 2006 y cinco periodos de 2007. Miles de barriles de petróleo crudo producidos diariamente en el sector minero.
SERIE 18. Gas natural (unidad de medida: millones de pies cúbicos por día), volumen de producción de petróleo crudo y gas natural, sector minero. Doce periodos de 1990 hasta 2006 y cinco periodos de 2007.
Aplicación del método de selección a series de prueba
]]> Siguiendo los pasos del método de selección de técnicas de pronóstico descrito, todas las series de datos fueron escaladas en el rango de [-1, 1]. Posteriormente, se ajustó un polinomio con coeficiente de determinación mayor a 80%. Como ilustración, la figura 2 muestra la SERIE 7 escalada, el pronóstico con el método ARIMA (0, 2, 2), el ajuste polinomial, la ecuación representativa del polinomio junto con el R2 asociado. De los datos anteriores se puede observar que la serie de tiempo 7 tiene un valor t = 15 y n = 6.Como tercer paso se predice el MSE de cada método de pronóstico utilizando una RNA. Finalmente se hace un ordenamiento de los MSE predichos para seleccionar el que tenga menor error. En la tabla 1 se indica que el método T7 (ARIMA (0, 2, 2)) se predice como el mejor método de pronóstico para una serie de tiempo con características como la SERIE 7.
La tabla 1 muestra además el lugar que ocupó cada método de pronóstico (del primero hasta el octavo lugar) de acuerdo con la comparación del pronóstico real y el pronóstico predicho por el método de Villarreal et al. (2009) descrito en Villarreal (2006) para las 18 series de tiempo bajo estudio.
Tomando como ejemplo la SERIE 1 con t = 12 y n = 1, los tres mejores métodos de pronóstico predichos son: el T7 ARIMA (0, 2, 2), el T6 regresión lineal y el T8 suavizado exponencial doble, respectivamente. De acuerdo con el pronóstico real, el mejor método es el T7 ARIMA (0, 2, 2), el segundo es el T8 suavizado exponencial doble, el tercero es el T6, la regresión lineal.
En los casos donde se observan dos o más etiquetas, éstas corresponden a empates de métodos (mismo valor de MSE), por ejemplo, en la SERIE 16 con t = 208 y n = 27; de acuerdo con el pronóstico predicho, el T5 suavizado exponencial simple ocupa el primer lugar, en cambio con el pronóstico real, el primer lugar está ocupado por tres métodos tradicionales, el T4 ARIMA (0, 1, 1), T5 suavizado exponencial simple y T8 suavizado exponencial doble. Las etiquetas T1 a T8 se definieron en la sección de introducción.
De la tabla 1, se puede ver que en las 18 series, el método fue capaz de recomendar el mejor método real para pronosticarlo dentro de los 3 primeros lugares en 14 ocasiones. De las 4 series restantes, en dos de ellas se recomienda el segundo método y en las otras dos, el tercero. Dado que los usuarios objetivo no tienen una alta capacitación estadística, con estas instancias el método habría permitido ahorrar tiempo y esfuerzo para seleccionar una técnica adecuada para cada serie. La selección de técnicas aquí presentada, aunque no es exhaustiva, es estándar y se considera confiable en la literatura de pronósticos.
Aplicación del método de selección por medio de tablas
En esta sección se presentan los resultados del método desarrollado por Villarreal et al. (2009) en forma tabulada, con el objetivo de hacer más conveniente su uso. Las tablas 2, 3 y 4 muestran el mejor método, el segundo y tercero respectivamente, para una serie de tiempo con combinaciones de n (eje horizontal) y t (eje vertical) particulares. Por lo tanto, después de haber determinado los valores de t (número de datos) y n (orden polinomial) el usuario puede consultar las tablas 2, 3 y 4 para seleccionar los mejores 3 métodos de pronóstico. Por ejemplo, si tenemos una serie de tiempo de grado polinomial 5 y 36 períodos, basta identificar las intersecciones de la combinación (n = 5, t = 36) en estas tablas para identificar los tres métodos de pronóstico sugeridos. De esta forma, siguiendo el ejemplo, se tiene que el primer mejor método para pronosticar es el promedio, el segundo es el promedio móvil y el tercero es el suavizado exponencial doble.
]]> Conclusiones
En este trabajo se presentó la validación del método de Villarreal et al. (2009) para la selección de técnicas de pronóstico. Se pudo constatar, por medio de 18 series de tiempo reales, que el método trabaja competitivamente. Adicionalmente se propuso la utilización de tablas de fácil acceso para un usuario que busque aplicar dicho método. Se espera que los resultados aquí presentados y el formato descrito incidan en la adopción de este método por personas con poco entrenamiento estadístico que requieran seleccionar un método de pronóstico. Los resultados alientan a buscar caracterizaciones prácticas que faciliten la utilización de métodos cuantitativos para la toma de decisiones en las compañías mexicanas.
Agradecimientos
Este trabajo fue elaborado parcialmente por el apoyo de los programas de verano científico de la Academia Mexicana de Ciencias, la Universidad Autónoma de Nuevo León y la Universidad Autónoma de Tamaulipas. Los autores agradecen también el apoyo del CONACYT por las becas otorgadas a los estudiantes involucrados en este trabajo.
Referencias
Hagan M.T. y Demut H.B. Neural Network Design, 1a ed., PWS Publishing Company, 1995. [ Links ]
Hillier y Lieberman. Investigación de Operaciones, 7a ed., México, Mc GRAW-HILL, 2001. [ Links ]
Hornik K., Stinchcombe M., White H. Multilayer Feedforward Networks are Universal Approximatiors. Neuronal Networks, volumen 2 (número 5), 1989: 359-366. [ Links ]
Instituto Nacional de Estadística y Geografía e Informática (INEGI). Sección del Banco de Información Económica (BIE) [en línea] [fecha de consulta 19 de octubre de 2007]. Series históricas consultadas en: http://dgcnesyp.inegi.gob.mx/bdiesi/bdie.html, Disponibles por parte de los autores. Nueva versión del sitio web del BIE actualizado en marzo 1 de 2012. Disponible en: http://www.inegi.org.mx/sistemas/bie/. [ Links ]
Makridakis S., Wheelwright S.C., Hyndman R.J. Forecasting Methods and Applications, 3rd ed., John Wiley & Sons, Inc., 1998. [ Links ]
Secretaría de Agricultura, Ganadería, Desarrollo Rural, Pesca y Alimentación (SAGARPA). Producción acuícola en sistemas controlados, pesca Tamaulipas [en línea] [fecha de consulta 19 de octubre de 2007]. Series históricas de camarón y bagre, consultadas en: http://www.tml.sagarpa.gob.mx/pesca/informacion.htm. Disponibles por parte de los autores. [ Links ]
Salazar M.A. Pronóstico de demanda por medio de redes neuronales artificiales (RNAs) en la industria de telecomunicaciones, tesis (maestría), México, Universidad Autónoma de Nuevo León, Nuevo León, 2005. [ Links ]
Villarreal M.M. Estudios de pronósticos en series de tiempo: Evaluación de métodos estadísticos y selección del mejor método con redes neuronales, tesis (licenciatura), México, Universidad Autónoma de Nuevo León, 2006. [ Links ]
Villarreal M.G., Acosta M., Martínez J.L., Cabrera-Ríos M. Time Series: Empirical Characterization and Artificial Neural Network-Based Selection of Forecasting Techniques. Intelligent Data Analysis. An International Journal, volúmen 13, 2009: 1-14. [ Links ]
Zhang G., Patuco E., Hu Y.M. Forecasting with Artificial Neural Networks the State of the Art. International Journal of Forecasting, volúmen 14 (número 1), 1998: 35-62. [ Links ]
Semblanza de los autores
Mary Carmen Acosta-Cervantes. Es ingeniera industrial por la Universidad Autónoma de Tamaulipas (2009). Realizó dos veranos de investigación científica en la UANL (2006 y 2007) promovida por la Academia Mexicana de Ciencias. Obtuvo la maestría en ciencias en ingeniería de sistemas en la Universidad Autónoma de Nuevo León (UANL) en 2012. Actualmente es estudiante de la maestría en ciencias en ingeniería industrial de la Universidad de Puerto Rico Mayagüez. http://ininweb.uprm.edu/.
]]> María Guadalupe Villarreal-Marroquín. Obtuvo la maestría en ciencias en ingeniería de sistemas en la Universidad Autónoma de Nuevo León (2007), así como la licenciatura en matemáticas en la misma universidad (2005). Actualmente es estudiante doctoral en el programa de ingeniería industrial y de sistemas de la Universidad Estatal de Ohio.Mauricio Cabrera-Ríos. Es doctor en ciencias (2002) y maestro en ciencias (1999) en ingeniería industrial y de sistemas por la Universidad Estatal de Ohio. Obtuvo el título de ingeniero industrial y de sistemas por el ITESM Campus Monterrey (1996). Actualmente es profesor asistente en el Departamento de Ingeniería Industrial de la Universidad de Puerto Rico-Mayagüez. http://ininweb.uprm.edu/.
]]>