
Model for Adjustment of Aggregate Forecasts using Fuzzy Logic
Escobar–Gómez E. N.1, Díaz–Núñez J. J.2 y Taracena–Sanz L. F.3
1 Departamento de Ingeniería Industrial, Centro de Ingeniería y Desarrollo Industrial, Instituto Tecnológico de Tuxtla Gutiérrez Chiapas, E–mail: enescobarg@hotmail.com
2 Instituto de Ingeniería, División de Estudios de Posgrado e Investigación de la Universidad Autónoma de Ciudad Juárez Chihuahua, E–mail: jjdiaz@yagerdiaz.org
3 División de Estudios de Posgrado e Investigación, Instituto Tecnológico de Querétaro, Querétaro, E–mail: fermail@att.net.mx
]]> Recibido: agosto de 2008
Resumen
La presente investigación sugiere una contribución en la aplicación de modelos de pronósticos. El modelo propuesto se desarrolla con el propósito de ajustar la proyección de la demanda al escenario de las empresas y se fundamenta en tres consideraciones que provocan que en muchos casos los pronósticos de la demanda disten de la realidad, como son: 1) uno de los problemas más difíciles de modelar en los pronósticos es la incertidumbre relacionada con la información disponible; 2) los métodos tradicionalmente utilizados por las empresas, para la proyección de la demanda, se basan principalmente en el comportamiento pasado del mercado (demanda histórica), y 3) estos métodos no consideran en su análisis a los factores que están influyendo para que se dé el comportamiento observado. Por lo tanto, el modelo propuesto se basa en la implementación de lógica difusa, integrando las principales variables que afectan el comportamiento de la demanda del mercado y que no son consideradas en los métodos estadísticos clásicos. El modelo se aplicó a una embotelladora de bebidas carbonatadas y con el ajuste de la proyección de la demanda se obtuvo un pronóstico más confiable.
Descriptores: planeación de la producción, pronóstico agregado, modelo de pronóstico, demanda, lógica difusa e inteligencia computacional en ingeniería industrial.
Abstract
This research suggests a contribution in the implementation of forecasting models. The proposed model is developed with the aim to fit the projection of demand to surroundings of firms, and this is based on three considerations that cause that in many cases the forecasts of the demand are different from reality, such as: 1) one of the problems most difficult to model in the forecasts is the uncertainty related to the information available; 2) the methods traditionally used by firms for the projection of demand mainly are based on past behavior of the market (historical demand); and 3) these methods do not consider in their analysis the factors that are influencing so that the observed behaviour occurs. Therefore, the proposed model is based on the implementation of Fuzzy Logic, integrating the main variables that affect the behavior of market demand, and which are not considered in the classical statistical methods. The model was applied to a bottling of carbonated beverages, and with the adjustment of the projection of demand a more reliable forecast was obtained.
Keywords: Production planning, aggregate forecasts, model forecast, demand, fuzzy logic and computational intelligence in industrial engineering.
]]>Introducción
Para que las empresas sean competitivas deben administrar sus recursos en forma óptima, siendo la planeación una de las principales actividades a desarrollar. La planeación de la producción establece los límites y niveles para las operaciones en el futuro, para lo cual debe de disponer de proyecciones confiables.
Gaither et al. (2000) y Schroeder (2005), señalan que con el fin de planear las organizaciones generalmente identifican tres tipos de horizontes de planeación: corto, mediano y largo plazo. El periodo depende del tiempo que se precise para completar la ejecución, así como del ambiente operacional de la organización. La planeación a mediano plazo, también llamada planeación agregada, es el desarrollo de las tasas de producción agregada y los niveles agregados de inventario para grupos de productos dentro de las restricciones de una determinada instalación. El horizonte de planeación abarca un periodo que inicia de 1 a 2 meses y termina de 12 a 18 meses; sus límites dependen de las restricciones de tiempo para cambiar los niveles de producción en una situación particular; y tiene al menos la misma duración que el tiempo de obtención más largo del producto.
Cuando se desarrolla un plan agregado de producción, el administrador de operaciones normalmente debe enfrentarse a una demanda fluctuante y poco segura. Asimismo, y dada la brecha que existe entre la teoría y la práctica de la planeación agregada de la producción, muchos administradores, al tomar decisiones, prefieren usar reglas basadas en su experiencia en lugar de los modelos matemáticos.
La revisión de la literatura señala que muchos de los métodos tradicionalmente utilizados en planeación agregada no consideran en su análisis la naturaleza estocástica de los factores; en otras palabras, no contemplan la incertidumbre o imprecisión de la información disponible. Esto ocasiona que, en muchos casos, los planes de producción desarrollados no se adecuen al escenario de la empresa. Sin embargo, en los últimos años se ha empezado a utilizar la lógica difusa en el desarrollo de este tipo de modelos. Dai et al. (2003) plantean un modelo que se basa en la estructura tradicional de programación lineal e incorporan cierta difusidad; es decir, además del objetivo y restricciones lineales tradicional les, en el modelo se considera a un objetivo difuso como restricciones a ecuaciones e inecuaciones lineales difusas, que involucran el nivel de mano de obra y la demanda. Para transformar las restricciones difusas y resolver el modelo, se utiliza la programación paramétrica, considerando al parámetro de variación r como el complemento del nivel de corte—α.
Asimismo, Fung et al. (2003) formulan un modelo de planeación agregada de la producción multiproducto con restricciones financieras, demanda difusa y capacidad de producción difusa. Para resolver el modelo utilizan la programación paramétrica, considerando al parámetro devariación θ para denotar el nivel de posibilidad en el que se cumple la demanda del mercado, y al parámetro devariación γ para expresar el nivel de satisfacción del tomador de decisiones con el consumo de la capacidad de producción.
Además, uno de los insumos para el desarrollo de un plan son los pronósticos. Heshmaty et al. (1985) y Sheng–Tun et al. (2007), entre otros, han propuesto modelos que emplean series de tiempo con Lógica Difusa para determinar pronósticos; Mahabir et al. (2003) han empleado lógica difusa para prever el abastecimiento de agua.
Por lo tanto, y considerando que el grado de incertidumbre relacionado con el pronóstico de la demanda disminuye en la medida en que se incrementa el conocimiento de los factores que lo influencian, se propone un nuevo modelo para el ajuste de los pronósticos agregados que utiliza lógica difusa basada en reglas, como a continuación se describe.
]]> Modelo propuesto
Uno de los principales objetivos de las empresas es utilizar en forma óptima los recursos para satisfacer las necesidades de los clientes. Estas necesidades se determinan a través de una proyección de la demanda y se integran en la demanda agregada. Para la proyección de la demanda, normalmente se utilizan métodos de series de tiempo o métodos causales. Estos métodos, en gran parte, basan su análisis en el comportamiento pasado, ya sea de la demanda o de alguna otra variable, sin tomar en cuenta a la incertidumbre involucrada. Por lo tanto, a esta proyección y para que la demanda agregada sea más adecuada al escenario de la empresa, se le realizará un ajuste a través de lógica difusa.
Para que el ajuste del pronóstico sea adecuado al entorno de la empresa, deben seleccionarse las variables que están afectando el comportamiento de la demanda del mercado. Las principales variables que tienen influencia sobre el comportamiento de la demanda son: inflación, poder adquisitivo, paridad del peso con monadas extranjeras, tasa de crecimiento económico, nivel de ingresos de los clientes, turbulencia política, demanda total, época del año, nivel de satisfacción de clientes en compras anteriores, tasa de empleo, precio del producto, alicientes ofrecidos por la competencia, percepción de las personas hacia el producto, lanzamiento de productos competidores, oferta total, efectividad del esfuerzo de ventas, creación de nuevas empresas, apertura de fronteras y valor de las UDIS. Después de un análisis exhaustivo, se seleccionaron las variables que tienen mayor relación con el comportamiento de la demanda, las cuales son: temporada, competencia, y percepción del cliente. En la siguiente sección se definen estas variables.
Como se observa en la figura 1, el modelo está formado por cinco elementos, como son: variables lingüísticas (3 de entrada y 1 de salida), proceso de difusificación, base de reglas difusas, mecanismo de inferencia y proceso de desdifusificación. Con la implementación de lógica difusa se obtiene una demanda agregada más acorde al comportamiento del mercado, y por ende, se establecerá un plan más adecuado al escenario de la empresa.
En los apartados siguientes se describirán cada uno de los elementos del modelo propuesto.
Variables lingüísticas
La lógica difusa se utiliza para tomar decisiones a partir de datos inciertos o con conocimiento subjetivo, los cuales son normalmente presentados a través de variables lingüísticas. Como ya se mencionó con anterioridad, existen tres variables que están relacionadas con el comportamiento de la demanda, las cuales son las variables lingüísticas de entrada, además se tiene una variable de salida, como se muestra en la figura 1. En los párrafos siguientes se describirán cada una de estas variables.
La Temporada, como variable lingüística, es la expresión que se refiere al comportamiento de la demanda en un periodo dado con relación al mismo periodo de años anteriores. El comportamiento es normalmente influenciado por factores como: el clima, eventos deportivos o culturales, festividades o celebraciones de la comunidad, lanzamiento de nueva publicidad y promociones, entre otros.
]]> En esta variable se consideran tres casos y cada uno de éstos define a un conjunto difuso, los cuales son:• Temporada baja: Periodo en el cual se considera que existirá una disminución de la demanda con relación al mismo periodo de años anteriores. El conjunto difuso es Baja.
• Temporada media: Periodo en el cual se supone no existirán cambios significativos de la demanda respecto al mismo periodo de años anteriores. El conjunto difuso es Media.
• Temporada alta: Periodo en el cual se estima existirá un incremento de la demanda referente al mismo periodo de años anteriores. El conjunto difuso es Alta.
La Percepción del cliente es otro factor de gran importancia, en cuanto condiciona la fidelidad de los clientes hacia el producto, es decir, la probabilidad de recompra y la intensidad de su recomendación a terceros. Ahora bien, como variable lingüística se define la sensación que el cliente tenga acerca de la satisfacción de sus necesidades y expectativas.
Los conjuntos difusos que forman parte de esta variable son tres y son los casos que se considera podrían ocurrir:
• La percepción es mala: El cliente no está satisfecho con el producto y existe muy alta probabilidad de que cambie de marca. El conjunto difuso es Mala.
• La percepción es regular: El cliente "decide cada vez", no tiene hábito de recompra firme, la marca es la más frecuente, pero no existe alta fidelidad. El conjunto difuso es Regular.
]]> • La percepción es buena: El cliente tiene un compromiso personal con la marca, proporciona una publicidad positiva y disculpa errores. El conjunto difuso es Buena.
Además, cuando se establece la demanda agregada, comúnmente no se analiza la competencia. Entre los factores de mayor impacto que afectan a la competencia se encuentran:
• Apertura de fronteras
• Creación de nuevas empresas
• Lanzamiento de productos competidores
Por lo que, la Competencia, como variable lingüística, se define como el grado de competencia hacia el producto agregado analizado. Para esta variable se suponen tres casos, los cuales son considera dos como conjuntos difusos y presentados a continuación:
• El nivel de competencia es poco. El conjunto difuso es: Baja.
• El valor de competencia es medio. El conjunto difuso formado es: Media.
]]> • El grado de competencia es grande. El conjunto difuso es: Alta.
En la figura 2 se muestran las tres variables antes mencionadas y los conjuntos difusos que las componen, en donde la forma de los conjuntos difusos está directamente relacionada con las funciones de pertenencia, también llamadas funciones de membresía; siendo estas funciones las que expresan la certidumbre, medida de posibilidad, de que un elemento del universo pertenezca a un conjunto difuso, de acuerdo al criterio o experiencia del tomador de decisiones.
Por lo tanto, y considerando que existe una relación lineal en la medida de posibilidad de las variables difusas, como se aprecia en la figura 2, la forma de los conjuntos difusos de las variables Temporada, Percepción y Competencia son triangulares y trapezoidales.
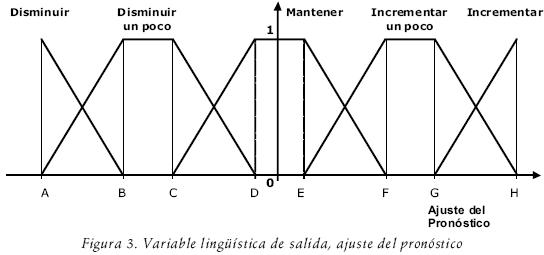
La variable de salida del modelo es el ajuste del pronóstico y es definida como el cambio en el nivel de la proyección de la demanda agregada en porcentaje.
Bajo esta consideración se presentan cinco casos, los cuales permiten definir los conjuntos difusos pertenecientes a esta variable, y éstos son:
• El Ajuste del Pronóstico debe disminuir respecto a la proyección de la demanda, el ajuste del pronóstico es negativo. El conjunto difuso es: Disminuir
• Se debe disminuir un poco respecto a la proyección de la demanda. El conjunto difuso es: Disminuir un poco.
• No existen cambios con relación a la proyección de la demanda, el Ajuste del Pronóstico se considera que es aproximadamente igual a cero. El conjunto difuso es: Mantener.
• Debe existir un pequeño aumento en cuanto a la proyección de la demanda. El conjunto difuso formado es: Incrementar un poco.
]]> • El Ajuste del Pronóstico debe tener un aumento considerable con relación a la proyección de la demanda. El conjunto difuso formado es: Incrementar.
Como se muestra en la figura 3, se utilizan funciones trapezoidales para representar los conjuntos difusos de la variable ajuste del pronóstico. La figura obtenida no es necesariamente simétrica.
Proceso de difusificación
El proceso de difusificación consiste en obtener los valores difusos, también llamados grados de pertenencia de los conjuntos de cada variable lingüística de entrada. Los grados de pertenencia se obtienen evaluando, a través de las funciones de pertenencia, los valores asignados a las variables lingüísticas de entrada. En las ecuaciones (1), (2) y (3) se presentan las funciones de pertenencia para las variables temporada y competencia; y en las ecuaciones (4), (5) y (6) se muestran las funciones para la variable percepción.

Donde, μBaja(X), μMedia(X) y μAlta(X) representan el grado de pertenencia a los conjuntos difusos Baja, Media y Alta, respectivamente.

Donde, μMala(X), μRegular(X) y μBuena(X) representan el grado de pertenencia a los conjuntos difusos de la variable Percepción.
]]> Base de reglas difusasLas reglas difusas son un modo de representar estrategias o técnicas apropiadas cuando el conocimiento proviene de la experiencia o de la intuición. Las reglas difusas están compuestas por variables lingüísticas que forman la premisa de la condición y una conclusión, son escritas como pares antecedentes–consecuentes de oraciones IF–THEN y guardadas en forma tabular. La combinación de las etiquetas lingüísticas de las variables difusas forma la base de reglas difusas. Como el modelo propuesto está forma do por tres variables difusas con tres etiquetas lingüísticas cada una, la base de reglas difusas está constituida por 27 reglas.
Mecanismo de inferencia
Como se aprecia en la figura 1, para llevar a cabo el mecanismo de inferencia se requieren las entradas difusas y haber definido la base de reglas difusas. El mecanismo de inferencia considera a los valores de entrada y a la base de reglas difusas para determinar el conjunto de reglas que se activa y a las conclusiones relacionadas; siendo estas conclusiones los conjuntos difusos de la variable difusa de salida. Para conocer el valor difuso de la regla activada se utilizan las operaciones entre conjuntos difusos, empleando la intersección para calcular el valor difuso de una regla activada, y la unión para determinar el valor difuso de un conjunto de reglas activadas con la misma conclusión. Para generalizar las funciones que definen la intersección y la unión de conjuntos difusos son utilizadas la norma triangular y la conorma triangular, respectivamente.
Se han definido algunas funciones de la norma triangular; no obstante, el operador mínimo permite considerar el grado de pertenencia que está incluido en los conjuntos difusos que constituyen la regla activada, analizándose la relación entre las variables difusas de entrada, como se presenta en la ecuación (7).

Donde:
 representa el grado de pertenencia de la regla activada, A es un conjunto difuso de la primer variable lingüística, B es un conjunto difuso de la segunda y C es un conjunto difuso de la tercer variable, además, μA(x1), μB(x2) y μC(x3) representan los grados de pertenencia a los conjuntos difusos.
representa el grado de pertenencia de la regla activada, A es un conjunto difuso de la primer variable lingüística, B es un conjunto difuso de la segunda y C es un conjunto difuso de la tercer variable, además, μA(x1), μB(x2) y μC(x3) representan los grados de pertenencia a los conjuntos difusos.
Por otro lado, también se han desarrollado algunas funciones conorma triangular; sin embargo, el operador máximo permite que se incluyan los grados de pertenencia de las diversas reglas activadas con la misma conclusión, obteniéndose la mayor superficie posible. Por lo que se hace necesario aplicar la ecuación (8), criterio máximo – mínimo, para conocer el grado de pertenencia de cada uno de los conjuntos difusos de la variable de salida.

 representa la unión (operador máximo) y
representa la unión (operador máximo) y  a la intersección (operador mínimo).
a la intersección (operador mínimo). El proceso de desdifusificación
En el apartado anterior se presentan los resultados de la variable de salida, obtenidos a través del proceso de inferencia, los cuales son valores difusos y sin ningún significado práctico. Para convertirla salida del mecanismo de inferencia a información que pueda ser interpretada por el administrador se utiliza el proceso de desdifusificación. El resultado obtenido es el ajuste del pronóstico agregado.
Para realizar el proceso de desdifusificación se utiliza el método del centro geométrico, también llamado centroide o primer momento. Este método consiste en los siguientes cuatro pasos:
1. Descomponer el área formada por los valores difusos de los conjuntos que forman la variable de salida en figuras regulares. Para determinar las figuras regulares que se forman, se analiza la relación que existe entre los grados de pertenencia de dos conjuntos difusos adyacentes, como se observa en la figura 4, de este análisis se definen dos casos: El primer caso implica que el grado de pertenencia al primer conjunto difuso es menor o igual al valor de pertenencia al segundo conjunto, y en el segundo caso, el grado de pertenencia al primer conjunto es mayor al grado de pertenencia al segundo conjunto. Donde, el grado de pertenencia al primer y segundo conjunto se representan por μ1(DA) y μ2(DA). Considerando lo anterior, del análisis de la variable difusa de salida se determinan 15 áreas, y considerando la relación de los grados de pertenencia de los conjuntos difusos las áreas forman triángulos o rectángulos (figura 5).
2. Calcular la superficie de cada figura obtenida en el paso 1. Para el cálculo de estas superficies se utilizan las fórmulas ya conocidas. Para el rectángulo se calcula multiplicando la base por la altura. Mientras que, para el triángulo se obtiene al dividir entre dos la multiplicación de la base por la altura.
3. Determinar el centroide de cada figura.
4. Calcular el centroide total. Para obtener este valor se divide la suma de la multiplicación de la superficie de cada figura por su centroide entre la superficie total, el resultado es el valor de la desdifusificación de la variable de respuesta. En la expresión (9) se presenta la fórmula para el cálculo del centroide total.
5. Calcular la superficie de cada figura obtenida en el paso 1. Para el cálculo de estas superficies se utilizan las fórmulas ya conocidas. Para el rectángulo se calcula multiplicando la base por la altura. Mientras que, para el triángulo se obtiene al dividir entre dos la multiplicación de la base por la altura.
]]> 6. Determinar el centroide de cada figura.7. Calcular el centroide total. Para obtener este valor se divide la suma de la multiplicación de la superficie de cada figura por su centroide entre la superficie total, el resultado es el valor de la desdifusificación de la variable de respuesta. En la expresión (9) se presenta la fórmula para el cálculo del centroide total.


Procedimiento
Para aplicar el modelo para el ajuste de pronósticos agregados se utiliza el procedimiento siguiente:
]]>1. Obtener la demanda agregada. En este primer paso se concentra la demanda agregada proyectada (también llamado Pronóstico Agregado, PA).
2. Definir los parámetros para las variables lingüísticas. Teniendo definidas las tres variables lingüísticas de entrada, con sus conjuntos difusos y funciones de pertenencia, se deben establecer sus parámetros para el periodo analizado.
3. Determinar los valores de entrada y realizar la difusificación. En este paso, ya que están definidas las variables lingüísticas y sus componentes, se determinan los valores que toman en el periodo analizado. Con estos valores y las funciones de pertenencia se realiza la difusificación.
4. Verificar la validez de las reglas difusas. Teniendo definida la base de reglas difusas, y de manera conjunta con el personal ejecutivo de la empresa, se debe evaluar si para el escenario de la empresa el conjunto de reglas difusas es válido. Si el conjunto de reglas es válido se continúa con el paso número seis; caso contrario, se va al paso número cinco.
5. Redefinir las reglas. En caso de que la base de reglas difusas no sea representativa del entorno de la empresa, debe ser nuevamente definida. Posteriormente, se regresa al paso cuatro para probar la validez de la nueva base de reglas.
6. Aplicar el mecanismo de inferencia. Obtener la salida difusa.
7. Realizar la desdifusicación. El resultado de este paso es el ajuste del pronóstico, expresado en porcentaje (Factor de Ajuste, FA).
8. Establecer la demanda agregada ajustada. La demanda agregada ajustada se obtiene considerando a la demanda proyectada y el ajuste calculado (PA * FA).
]]> Aplicación
El modelo para el ajuste de pronósticos agregados se aplicó a la Embotelladora Central Chiapaneca, la cual se encuentra ubicada en la ciudad de Tuxtla Gutiérrez, Chiapas, México. El procedimiento utilizado es el sugerido en el apartado anterior, como a continuación se describe.
Obtener la demanda agregada
Primeramente se seleccionó al grupo de productos a través de las siguientes condiciones:
]]> Seleccionados los productos que cumplieron las condiciones antes mencionadas se formó el grupo de refrescos embotellados. De la condición número tres se deriva que la unidad de medida agregada de producción seleccionada sea el litro de refresco, ya que todos los productos seleccionados pueden ser medidos en esta unidad.a) Que los productos fueran elaborados en la planta de producción de la empresa o en su defecto, pudieran adquirirse a través de mecanismos de subcontratación.
b) Que los insumos fueran, en esencia, iguales entre los diferentes productos analizados.
c) Que los productos pudieran medirse en una unidad de medida común.
d) Que los productos seleccionados estuvieran vigentes en los programas de producción de la empresa.
e) Que todos los elementos de información necesarios para elaborar el plan agregado estuvieran disponibles por cada producto.
Para calcular la demanda agregada de los productos que conforman la Familia primero se obtuvieron, en número de cajas, los pronósticos individuales de demanda de cada producto para el mes analizado, conocidos generalmente como pronósticos de ventas. El método utilizado para el cálculo de estos pronósticos fue el suavizado exponencial doble. Como los pronósticos de ventas están expresados en la unidad de medida con la que trabaja la empresa (número de cajas) fue necesario convertirlos a la unidad de medida agregada seleccionada, es decir, a litros. Además, para calcular la demanda agregada se totalizaron los pronósticos de ventas, siendo esta de: 6,763,967 litros (PA).
Definir los parámetros para las variables lingüísticas
Como se indicó anteriormente, las variables lingüísticas identificadas son tres: Temporada, Percepción del cliente y Competencia. Cada variable está formada por tres conjuntos difusos. Además, como se observa en la figura 2, los parámetros representan el valor en el cual los conjuntos difusos tienen un grado de pertenencia de 1. En la tabla 1 se presentan los parámetros de las tres variables. Estos parámetros se definieron en forma conjunta con el personal ejecutivo, utilizando los criterios siguientes.

Puesto que el parámetro representa el valor donde se pertenece completamente al conjunto difuso, y como se menciona en la definición de las variables lingüísticas, la variable temporada está en función del comportamiento de la demanda del mismo periodo de años anteriores, este comportamiento es influenciado por diversos factores; por lo que se asignan los valores 1, 2 y 3 para definir la pertenencia a los conjuntos baja, media y alta, respectivamente. Lo anterior implica que si dada la combinación de los factores se espera que la demanda disminuya, respecto de años anteriores, la variable temporada tendrá un valor de 1.
En caso de que la disminución esperada no sea grande se asigna un valor entre 1 y 2, dependiendo qué tanto se espere que cambie. Por otro lado, si la demanda esperada no cambia significativamente, el valor será de 2; y si se espera que la demanda aumente, el valor será de 3.
La variable percepción es definida en función del nivel de satisfacción de los clientes respecto al producto, en una escala del 1 a 10. Si el valor otorgado por el cliente es de 4 ó menos se considera una percepción mala, si el valor está entre 6 y 7 la percepción es regular, y si el valor otorgado es de 9 ó mayor la percepción es buena. Cuando el valor se encuentra entre 4 y 6 la percepción está entre mala y regular, por otro lado, si el valor está entre 7 y 9 la percepción está entre regular y buena.
La variable competencia está en función al grado en el que los competidores influyen en el mercado y no necesariamente de la cantidad de competidores, por lo que el valor de los parámetros es de 1, 2 y 3 para definir la pertenencia a los tres conjuntos difusos.
]]> Determinar los valores de entrada y realizar la difusificaciónTeniendo definidas las variables lingüísticas con sus conjuntos difusos y funciones de pertenencia, se determinó el valor de entrada para cada variable, es decir, se obtuvo el valor que toman las variables para las condiciones observadas. Estos valores se estimaron de manera conjunta con el personal ejecutivo. En la tabla 2 se presentan los valores definidos para las tres variables lingüísticas.

El valor asignado a la variable temporada está en función a la combinación de los comportamientos esperados de los factores que la definen. En este caso, se espera que la demanda aumente respecto al año anterior, por lo que la temporada es alta (3.00).
Para el periodo analizado se determinó que la Percepción tiene un valor de 7.75, entre regular y buena, tendiendo un poco más a regular. El grado de competencia se espera entre media y alta, 2.15, más próximo al grado de competencia media.
Una vez conocidos los valores de entrada, se procedió a la difusificación. Utilizando las funciones de pertenencia (ecuaciones (1), (2), (3), (4), (5) y (6)), se calculan los valores difusos para cada variable. Los resultados se presentan en la tabla 3 y representan los grados de pertenencia a cada conjunto.

En la figura 6 se muestran los valores de entrada de las variables lingüísticas y sus grados de pertenencia correspondientes. Si el grado es de 1, se pertenece completamente al conjunto difuso y cuando es menor a 1, se pertenece parcialmente al conjunto con un grado de pertenencia igual al valor calculado. Cuando el valor tiende a cero, se tiene menos relación con el conjunto analizado.
]]> Verificar la validez de las reglas difusasDadas las variables lingüísticas de entrada y sus conjuntos difusos, 3 variables con tres conjuntos cada variable, se tiene una base de 27 reglas difusas (3 x 3 x 3). En la base de reglas difusas se resume el conocimiento de los expertos consultados sobre la toma de decisiones relacionada con el ajuste de la proyección de la demanda, quedando estructurado como se muestra en la tabla 4. Cada regla difusa tiene una conclusión que representa a un conjunto difuso de la variable de salida (el número entre paréntesis indica el número de regla).
La base de reglas difusas se definió en forma conjunta con el personal ejecutivo y en forma particular para el ajuste del pronóstico agregado. Al analizar la base de reglas difusas se considera que son válidas y representativas del escenario analizado de la empresa.
Aplicar el mecanismo de inferencia
Conociendo los resultados de la difusificación (tabla 3), la base de reglas difusas (tabla 4) y aplicando el criterio Máximo – Mínimo, se realizó el proceso de inferencia. De la tabla 3 se observa que los conjuntos difusos con un grado de pertenencia mayor a cero son: Alta para la variable temporada, regular y buena para la variable Percepción y media y alta para la variable competencia. En la tabla 4 se aprecia que de la combinación de estos conjuntos se activan 4 reglas difusas, como son: 23, 24, 26 y 27.
En la tabla 5 se muestran las reglas activadas y su conclusión para el periodo analizado (conjunto difuso de la variable de salida).

Conociendo las reglas activadas, y aplicando la fórmula (7) se determinó el valor de la variable de salida ajuste del pronóstico para cada una de estas reglas difusas. Los resultados se presentan en las expresiones siguientes:

En esta información se aprecia que para dos reglas activadas se concluye de la misma manera, reglas 23 y 27. Para conocer el valor difuso del conjunto Incrementar un poco se aplica la ecuación (8). El valor obtenido se presenta en la siguiente expresión.
En la tabla 6 se presentan los grados de pertenencia a los conjuntos difusos de la variable ajuste del pronóstico.

Realizar la desdifusicación
La desdifusificación, en este caso, significa definir el ajuste de la proyección de la demanda agregada. Para llevar a cabo el proceso de desdifusificación es necesario determinar los parámetros de la variable de salida, ajuste del pronóstico.
Como se presenta en la tabla 7, estos parámetros representan el porcentaje de ajuste del pronóstico agregado, los cuales fueron definidos de manera conjunta con personal ejecutivo de la empresa.
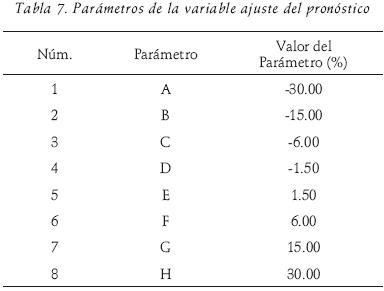

Como se describe en el apartado del proceso de desdifusificación, para obtener la salida se utilizó el método del centro geométrico, con un resultado de 14.037. Esto significa que para obtener el pronóstico agregado ajustado a la proyección inicial debe incrementarse 14.037 por ciento (FA).
Establecer la demanda agregada ajustada
En el primer apartado de la aplicación, para obtener la demanda agregada se determinó que el pronóstico agregado es de 6,763,967 litros. Además, en el proceso de desdifusificación se obtiene que el ajuste de la demanda es de 14.037 %. Por lo tanto, se obtiene que el pronóstico agregado ajustado es de 7,713,425 litros (PA * FA ó 6,763,967 * 1.14037).
La demanda en este periodo fue de 7,559,047 litros. Por lo tanto, como puede observar se en la tabla 8, se obtiene una menor dispersión en el pronóstico ajustado, siendo ésta de 154,378 litros.

En la tabla anterior se observa que el pronóstico agregado es 10.51% inferior a la demanda y que el pronóstico agregado ajustado es 2.04%, superior a la demanda. Esto implica que con el pronóstico agregado no se pueda satisfacer la demanda de los clientes, mientras que con el pronóstico agregado ajustado se tienen productos suficientes para satisfacer los requerimientos de los clientes (esto representa un buen nivel de servicio), aunque al final queda inventario.
]]> Para validar los resultados se evalúan tres periodos utilizando tres estadísticos: Desviación Media Absoluta (MAD, por sus siglas en inglés), Suma Acumulada de Errores (CFE, por sus siglas en inglés) y Error Porcentual Medio Absoluto (MAPE, por sus siglas en inglés). En la tabla 9 se presentan los pronósticos y demandas de los periodos analizados. El procedimiento para obtener los pronósticos agregados y los pronósticos agregados ajustados, es el explicado en apartados anteriores de este artículo.
En la tabla 10 se muestran los estadísticos MAD, CFE y MAPE aplicados al pronóstico y al pronóstico ajustado. Para los tres estadísticos la dispersión del pronóstico ajustado es menor a la del pronóstico. Además, proporciona un mayor nivel de servicio al final de los tres periodos, como se observa en la suma acumulada de errores. Por lo tanto, se puede concluir que los pronósticos ajustados con lógica difusa son más asertivos que los pronósticos iniciales.

Para facilitar y hacer más precisas las operaciones se desarrolló una hoja de cálculo. Además, se está trabajando en el desarrollo de un sistema informático.
Conclusiones
En esta investigación la implementación de lógica difusa permite modelar la incertidumbre de la demanda del mercado a través de tres variables lingüísticas: temporada, percepción del cliente y competencia, determinando un ajuste para el pronóstico de la demanda del mercado, y así obtener una proyección que sea representativa del escenario de la empresa.
]]> El modelo descrito provee una buena herramienta para los administradores de las empresas, con proyecciones de la demanda del mercado más asertivos y un alto nivel de servicio. Sin embargo, es conveniente mencionar que los que participen en la definición de los parámetros y de los valores de entrada deben ser expertos en el comportamiento de las variables difusas.Además, esta investigación da la pauta para que en futuros proyectos se aplique lógica neurodifusa para la optimización de los parámetros de las variables difusas, de manera que se obtengan mejores proyecciones de la demanda agregada. Finalmente, al tener un pronóstico más confiable se faculta para tomar mejores decisiones.
Referencias
Chase R.B., Aquilano N.J. y Jacobs F.R. Production & Operations Management. USA. Mc Graw Hill Companies, Inc. 1998. [ Links ]
Dai L., Fan L. y Sun L. Agrégate Production Planning Utilizing a Fuzzy Linear Programming. Journal of Integrated Design and Process Science, 7(4):81—95. 2003. [ Links ]
Fung R., Tang J. y Wang D. Multiproduct Aggregate Production Planning with Fuzzy Demands and Fuzzy Capacities. IEEE Transactions on Systems, Man, and Cybernetics, Part A, 33(3):302—313. 2003. [ Links ]
Gaither N. y Frazier G. Administración de producción y operaciones. 4ª Edición. México. International Thomson Editores. 2000. [ Links ]
Heshmaty B. y Kandel A. Fuzzy Linear Regression and its Applications to Forecasting in Uncertain Environment. Fuzzy Sets and Systems, 15(2):159–191. 1985. [ Links ]
Krajewski L.J. y Ritzman L.P. Administración de operaciones. 5a edición. México. Prentice—Hall. 2000. [ Links ]
Mahabir C., Hicks F.E. y Fayek A.R. Application of Fuzzy Logic to Forecast Seasonal Runoff. Hydrological Processes, 17(18):3749–3762. 2003. [ Links ]
Martín–del Brío B. y Sanz–Molina A. Redes neuronales y sistemas borrosos. 3ª edición. México. Alfaomega. 2007. [ Links ]
Schroeder R.G. Administración de operaciones. Casos y conceptos contemporáneos. 2ª edición. México. Mc Graw Hill. 2005. [ Links ]
Sheng–Tun L. y Yi–Chung C. Deterministic Fuzzy Time Series Model for Forecasting Enrollments. Computers & Mathematics with Applications, 53(12): 1904—1920.2007. [ Links ]
Vollmann T.E. et al. Planeación y control de la producción. 5ª edición. México. Mc Graw Hill. 2005. [ Links ]
Semblanza de los autores
Elías Neftalí Escobar–Gómez. Realizó la licenciatura en ingeniería industrial en producción en el Instituto Tecnológico de Tuxtla Gutiérrez y la licenciatura en ingeniería civil en la Facultad de Ingeniería Civil de la UNACH. El Instituto Tecnológico de Orizaba le otorgó el grado de maestro en ciencias en ingeniería industrial. Los estudios de doctorado en ingeniería los cursó en el Centro de Ingeniería y Desarrollo Industrial. Ha laborado como profesor e investigador en el Instituto Tecnológico de Tuxtla Gutiérrez y en la Faculta de Ingeniería Civil de la UNACH. Ha colaborado en diversas empresas a través de proyectos de investigación relacionados con optimización, desarrollo de modelos de planeación de operaciones y pronósticos, utilizando lógica difusa. Actualmente es jefe de proyectos de investigación y profesor investigador del área de ingeniería industrial del Instituto Tecnológico de Tuxtla Gutiérrez.
Juan José Díaz–Núñez. Realizó la licenciatura en ingeniería mecánica–eléctrica en el Instituto Tecnológico y de Estudios Superiores de Monterrey. La North Dakota Satate University le otorgó los grados de maestro en ciencias en ingeniería industrial, de maestro en ciencias en estadística aplicada y de doctor en ciencias en ingeniería industrial. Ha laborado como profesor e investigador en el Instituto Tecnológico de Ciudad Juárez, St. Cloud State University, North Dakota State University, El Paso Community Collage, Instituto Tecnológico y de Estudios Superiores de Monterrey y la Universidad Autónoma de Ciudad Juárez. Ha colaborado como consultor en las áreas de Operations Management, automatización e ingeniería de métodos de diversas empresas de Latinoamérica. Actualmente es miembro de los CIEES, SME, APICS, IIE, ASA y de las comisiones de evaluación de los fondos de CONACYT, así como profesor investigador del Instituto Tecnológico de Ciudad Juárez y de la Universidad Autónoma de Ciudad Juárez.
León Fernando Taracena–Sanz. Realizó la licenciatura en ingeniería química en la UNAM. El Cranfiel Institute of Technology le otorgó el grado de maestro en ciencias en ingeniería industrial. Asimismo, la Oregon State University el grado de doctor en ciencias en ingeniería industrial. Ha laborado como profesor e investigador en el Instituto Tecnológico de Querétaro, Oregon State University y Universidad Iberoamericana. Ha colaborado como consultor de diversas empresas en las áreas de estadística y calidad, diseño de producto, mercadeo del producto, compras y control de inventarios. Actualmente es administrador de una fábrica de muebles en Querétaro y profesor investigador del Instituto Tecnológico de Querétaro.
]]>