
Predicción de la producción y rendimiento de Pinus rudis Endl. en Aloapan, Oaxaca
Prediction of Pinus rudis Endl. production and yield in Aloapan, Oaxaca
Octavio S. Magaña Torres1, Juan Manuel Torres Rojo2, Carlos Rodríguez Franco3, Heriberto Aguirre Díaz4 y Aurelio M. Fierros González5
1 Instituto Nacional de Investigaciones Forestales, Agrícolas y Pecuarias. Campo Experimental Valle de México, km 18.5 Carr. México-Lechería, AP 307, CP 56101, Texcoco, Edo. de México. magana.octavio@inifap.gob.mx
]]> 2 Centro de Investigación y Docencia Económicas A.C., Carr. México-Toluca 3655 Col. Lomas de Santa Fe 01210 México D.F. juanmanuel.torres@cide.edu3 USDA Forest Service. Rosslyn Plaza, Bldg. C 1601 N. Kent Street Arlington, VA. U.S.A.
4 Prestador de Servicios Técnicos Forestales
5 Colegio de Posgraduados. Programa Forestal. km 36.5 Carr. México-Texcoco, Montecillo, Texcoco, Edo. de México. amfierros@colpos.mx
Manuscrito recibido el 7 de abril de 2006
Aceptado el 10 de septiembre de 2006
RESUMEN
Se muestra la estrategia metodológica para el desarrollo de un sistema de ecuaciones para predecir el rendimiento y producción de Pinus rudis Endl. Los datos para la construcción del modelo fueron obtenidos de dos mediciones en sitios permanentes de muestreo ubicados en Aloapan, Oaxaca. El modelo de predicción es un modelo de rodales completos con proyección de estructuras diamétricas a través de la distribución Weibull. La predicción de atributos del rodal se realiza en forma explícita e implícita. La primera se basa en modificaciones a los modelos compatibles de área basal y volumen; la segunda en la recuperación de distribuciones diamétricas predichas a partir del método de predicción de parámetros. Todos los modelos, incluso los de predicción de parámetros de la distribución Weibull, mostraron una bondad de ajuste excelente.
]]> Palabras clave: Distribución Weibull, Pinus rudis Endl., predicción de producción, proyección de estructuras diamétricas.
ABSTRACT
The development of equations to predict yield and production of Pinus rudis Endl. is described. The data for model development were obtained from two measurements of a set of permanent plots located in Aloapan, Oaxaca. The prediction model is a whole stand model with a projection of diameter classes through the Weibull distribution. Stands attributes are predicted with both, explicit and implicit predictions. The explicit prediction is based on modifications to the basal area and volume compatible growth models. The implicit prediction is made by recovering the diameter distribution predicted through the parameter prediction method. All growth models, even those related to the Weibull distribution parameter prediction showed an excellent goodness to fit.
Key words: Weibull distribution, Pinus rudis Endl., prediction of production, projection of diametric classes.
INTRODUCCIÓN
Cualquier administrador, planificador o analista en el área forestal requiere realizar predicciones sobre las posibles consecuencias de diversas alternativas de uso de bosques y selvas. Tales predicciones pueden realizarse con una amplia diversidad de métodos que van desde simples extrapolaciones con proyecciones tabuladas y normalizadas (tablas de crecimiento y rendimiento) hasta modelos sofisticados que proyectan el crecimiento de árboles individuales de acuerdo a su tamaño y distribución espacial dentro de un rodal, como lo hacen los modelos de árboles individuales dependientes de la distancia. La selección de la estrategia de predicción depende de factores como la disponibilidad de información, el objetivo de las predicciones y los recursos adicionales para el desarrollo de la herramienta que permita realizar dichas proyecciones. Sin embargo, la mejor estrategia siempre será aquella que resulte ser más útil en la aplicación final, en términos tanto de la cantidad de información que provee como de la exactitud y detalle de la misma (Vanclay, 1994).
La aplicación de las proyecciones de crecimiento y rendimiento pueden variar respecto del periodo de proyección como del espacio de aplicación. En este último nivel de variación se pueden distinguir desde aplicaciones a nivel de población, tales como la evaluación del sitio, probar hipótesis de crecimiento, estimación de rendimientos esperados o variabilidad de los mismos, evaluación de alternativas silvícolas o calidad de la madera en pie y definición de regímenes óptimos de manejo, entre otras. También aplicaciones a nivel comunidad, como investigar la dinámica de la distribución espacial de los rodales, las estimaciones de oferta de productos maderables o una planeación estratégica de alternativas de manejo a gran escala.
Cualesquiera de estas aplicaciones requiere diferentes estrategias de modelaje. De hecho, no existen modelos de crecimiento que puedan satisfacer las demandas de todas las aplicaciones. Por lo que en el diseño de la herramienta de predicción siempre se debe buscar la mayor eficiencia para el o los objetivos de uso.
]]> Dentro de la amplia variedad de estrategias metodológicas para modelar el crecimiento y rendimiento de bosques coetáneos y uniespecíficos sobresalen, por su sencillez y precisión, los modelos de totalidad del rodal con proyección de distribuciones diamétricas (TRPDD). Estos modelos, además de predecir las variables de estado básicas, como volumen y área basal de la población, revelan características importantes de la estructura de tamaños de ésta. Ello a través de la estimación de una distribución diamétrica. De aquí que pueden ser usados en aplicaciones que requieren identificar el comportamiento de las diferentes cohortes de una población. Por otro lado, son modelos de fácil elaboración y bastante fiables.Los modelos TRPDD se introdujeron en la década de los ochentas y se aplicaron fundamentalmente en plantaciones (Avery y Burkhart, 1983; Clutter et al., 1983). La metodología es relativamente simple, ya que sólo requiere de una proyección de las variables de estado básicas: volumen, área basal y número de individuos (mortalidad e incorporación), que se usa para realizar una predicción de la distribución de tamaños, generalmente expresada a través de clases diamétricas. Existen múltiples variaciones metodológicas en el desarrollo de modelos de TRPDD. Su origen se debe a la variabilidad en las estrategias de predicción y métodos estadísticos usados en cada uno de los componentes de predicción. Por ejemplo, la predicción explícita de las variables de estado puede incluir modelos compatibles (Clutter, 1963) o simples modelos de predicción (MacKinney y Chaiken, 1939). Por su parte, en la predicción de la distribución diamétrica se han usado varias distribuciones de densidad como la Gram-Charlier (Meyer, 1930), Beta (Prodan, 1953), Weibull (Bailey and Dell, 1973) y la S de Johnson (Hafley and Schreuder, 1977). De estas distribuciones la Weibull y la S de Johnson han probado ser las más apropiadas para la predicción de estructuras diamétricas en rodales coetáneos (Gadow, 1984).
El presente documento tiene por objetivo mostrar la estrategia metodológica para la elaboración de un sistema de ecuaciones de predicción explícita del crecimiento, integrado a un modelo de predicción de distribuciones diamétricas. El desarrollo metodológico se ejemplifica con datos obtenidos de parcelas de muestreo permanente establecidas por el INIFAP en San Miguel Aloapan, Distrito de Ixtlán, Oaxaca. La aportación marginal del documento es mostrar el uso de las estimaciones de predicción explícita para corregir las estimaciones de predicción implícita, en el ajuste de un sistema de ecuaciones que integran un simulador de crecimiento para Pinus rudis Endl .
METODOLOGÍA
Descripción del área de estudio
La base de datos proviene de 64 parcelas permanentes con dos remediciones (1986 y 1990) en un Sitio Permanente de Investigación Silvícola (SPIS) ubicado en la comunidad de San Miguel Aloapan, Distrito de Ixtlán, Oaxaca, cuyo centroide se ubica en los 17°24'43" de latitud norte y 96°41'30" de longitud oeste. El clima es el más seco de los climas templados subhúmedos, con lluvias en verano, un cociente precipitación/temperatura de 43,2, con verano fresco y temperatura del mes más caliente de 22°C. Los suelos predominantes se clasifican como luvisol vérticos, caracterizados por tener una acumulación de arcilla en el subsuelo, son de color rojo o claros y moderadamente ácidos. También son frecuentes los litosoles, que son suelos sin desarrollo y con una profundidad menor de 10 cm, así como regosoles éutricos, que son de textura fina. Las principales asociaciones vegetales de la región son bosques de pino-encino, bosques de pino y bosques de encino. La especie más frecuente de pino es Pinus rudis Endl., seguida de P. patula Schl. et Cham, P. pseudostrobus Lindl., P ayacahuite Ehren. y P. oaxacana Mirov.; además de las especies Abies hickelii Flous et Gauss., y A. oaxacana Mart. Las especies de encino más importantes son: Quercus circinata Née., Q. crassifolia Humb. y Q. candicans Née. Asimismo, existen otras especies de latifoliadas como Arbutus glandulosa Mart. y Alnus acuminata Kunth. Las 64 parcelas están establecidas en bosques puros o casi puros (frecuencia superior al 95%) de Pinus rudis Endl.
Trabajo de campo
Las 64 parcelas permanentes se subdividen, cada una, en cuatro cuadrantes de 25 x 25 m. Dada la diferencia entre cuadrantes cada uno de ellos fue considerado un sitio de muestreo, con lo que se tuvieron un total de 256 sitios de muestreo de 625 m2 cada uno. De este total se seleccionaron en forma aleatoria 16 sitios (6,25%), mismos que fueron usados en las pruebas de validación de modelos. En cada sitio se lleva registro de ubicación de cada árbol, especie y tipo, así como registro continuo de variables como diámetro normal, diámetro del tocón, grosor de la corteza, condición de daño, altura total, altura del fuste limpio, clase o dominancia, piso, vitalidad, tendencia dinámica y proyección de copa, con lo cual es posible monitorear la dinámica de la población.
Estructura y desarrollo del modelo de predicción de crecimiento
]]> El modelo de predicción del crecimiento se conforma de dos estrategias de predicción: explícita e implícita. La predicción explícita consiste de tres sistemas de ecuaciones. El primero permite caracterizar variables de estado de la población como calidad de sitio (índice de sitio), densidad y mezcla de especies. En ese modelo de predicción no se utilizó un índice de densidad, ya que ésta se evaluó a través del área basal. Tampoco se calculó un índice de mezclas, dado que las poblaciones son puras y coetáneas. El segundo sistema integra ecuaciones que permiten estimar variables de cohortes o árboles individuales de una población dados parámetros poblacionales básicos como densidad, sitio y edad. El tercer grupo está formado por ecuaciones de predicción, tanto de variables de estado como de la distribución diamétrica, que utilizan información básica de los dos primeros sistemas. La figura 1 muestra los tres sistemas de ecuaciones y sus relaciones.En una predicción explícita se hace la estimación futura de las variables de estado (volumen del rodal, área basal y número de individuos) a través de un modelo compatible (Clutter, 1963). Estos modelos tienen la siguiente forma general:
en donde V2 representa el crecimiento o rendimiento en volumen (o área basal) por unidad de área a la edad de proyección A2; S es alguna función de calidad de sitio (generalmente índice de sitio) y δ2 representa alguna función de la densidad del rodal proyectada a la edad V2. Cuando la variable de respuesta es área basal (B) es común que los modelos usen una estimación de mortalidad para predecir el número de individuos a la edad de proyección (N2, misma que se puede obtener con una función de mortalidad o con una función que ayude a predecir el tamaño de la población a una edad determinada. Esta función regularmente es el cuello de botella en las estimaciones adicionales, dado que requiere una amplia superficie de respuesta para poder relacionar la mortalidad con diferentes condiciones de estructura y densidad de la población.
En los modelos de predicción explícita de distribuciones diamétricas, los parámetros de la distribución de tamaños se estiman ya sea a través del procedimiento de "recuperación de parámetros" o a través del procedimiento de "predicción de parámetros". El más usado es el segundo procedimiento, dado que el primero frecuentemente recupera distribuciones poco relacionadas con la distribución real. El primer procedimiento consiste en modelar las distribuciones diamétricas a través del modelo de distribuciones elegido (usualmente el modelo Weibull). Enseguida, los estimadores de parámetros de tales distribuciones se relacionan con variables poblacionales, de tal forma que se pueda asociar una distribución diamétrica con características propias de la población. Posteriormente, la distribución de tamaños se recupera al integrar la distribución predicha por categorías de tamaño (categorías diamétricas) y finalmente se recobra una tabla de inventario de la predicción con ayuda de estimaciones de altura promedio por categoría diamétrica y funciones de ahusamiento. La figura 2 muestra el diagrama de flujo que sigue una predicción de esta naturaleza.
Obsérvese que una vez recuperada la tabla de inventario de la proyección es posible calcular una nueva área basal (B'2 y un nuevo volumen (V'2) de la población a la edad de proyección (A2) por simple suma de las áreas basales y volúmenes de cada categoría diamétrica. Tales estimaciones usualmente se conocen como predicciones implícitas de las variables área basal y volumen de la población. Es de esperar que tales estimaciones sean diferentes de aquellas realizadas con las ecuaciones de predicción explícita, debido a que la estrategia de predicción es diferente. El procedimiento de "recuperación de parámetros" sugerido para recobrar distribuciones diamétricas (arriba señalado) asegura que la estimaciones de área basal realizadas en forma implícita y explícita sean iguales, no así las de volumen. Sin embargo, este procedimiento no ofrece una estimación de la distribución de tamaños tan buena como el procedimiento de predicción de parámetros. Las diferencias entre una proyección implícita y una explícita se pueden reducir en la medida en que tanto el sistema de ecuaciones que predice la distribución de tamaños, como el sistema de predicción de alturas medias de cada categoría diamétrica tengan una buena precisión.
Dado que la predicción implícita tiene más errores acumulados que una distribución explícita (se usan más ecuaciones de predicción para realizar la predicción implícita), esta última se usa para corregir las estimaciones de la primera. El procedimiento de corrección consiste en distribuir las diferencias de ambas proyecciones en área basal o volumen de acuerdo a la participación de cada categoría diamétrica en estas variables. El factor de corrección (FC) s e calcula como:

Donde V es el volumen (total del rodal) predicho de manera explícita y Vol es el volumen (total del rodal) obtenido de manera implícita.
Una vez realizada la corrección se vuelven a calcular las alturas medias de cada categoría, a fin de hacer compatibles, diámetros y alturas, con las estimaciones de volumen. De esta forma, las nuevas estimaciones de altura media permitirán corregir las estimaciones de volumen comercial y la tabla de inventario ajustada será compatible con la proyección explícita.
]]>RESULTADOS Y DISCUSIÓN
En esta sección se muestran las estimaciones de los modelos usados para realizar tanto la predicción explícita como la implícita del crecimiento de Pinus rudis Endl. en la región de Aloapan, Oaxaca. En algunos casos se realiza una breve discusión sobre las ventajas y desventajas de los modelos usados y los efectos al realizar una proyección.
Predicción de atributos a nivel rodal
Para la estimación del volumen total de cada parcela se determinó una ecuación de volumen (sin corteza) de dos entradas para Pinus rudis Endl., basada en 20 análisis troncales y tomando en consideración la metodología propuesta por Rodríguez-Franco y Moreno-Sánchez (1982). El modelo de mejor ajuste se presenta a continuación, donde los valores en paréntesis corresponden a los errores estándar de cada estimador:

donde VT representa el Volumen total árbol (m3), d identifica el diámetro a la altura de pecho (m); ht es la altura total de un árbol individual (m) y ln (.) es el logaritmo natural de la función entre paréntesis (.)
Los análisis troncales también se usaron para generar las curvas de índice de sitio en el área de estudio. El método utilizado para obtener las curvas de índice de sitio fue el método de la curva guía con el modelo de Schumacher. El modelo linealizado y de mejor ajuste tiene las siguientes características:

En esta ecuación H representa la altura dominante (m) y E la edad (años) del árbol. Para la predicción del índice de sitio a partir de la altura dominante edad, el modelo de la curva guía fue algebraicamente reordenado a la expresión siguiente:
]]> ln (S) = ln (H) + 18,493965 (1/E - 1/Eb) ...(3)donde: S representa el índice de sitio (m) y Eb es la edad base (50 años).
Utilizando la última expresión se definió una familia de curvas anamórficas altura-edad para Pinus rudis Endl. Esta familia de curvas mejoró el coeficiente de determinación obtenido con la familia de curvas polimórficas al momento de hacer la validación con el 10% de los datos disponibles que no fueron usados en el ajuste.
Para obtener una estimación explícita del área basal se utilizó el modelo diferencial sugerido por Clutter et al. (1983). El modelo de mejor ajuste tiene las siguientes características:

donde B1 identifica el área basal inicial (m2/ha) a la edad inicial (E1) y B2 representa el área basal proyectada (m2/ha) a la edad de proyección (E2), donde ambas edades están definidas en años. Por su parte, el modelo de predicción de la producción en volumen a la edad de predicción E2 (V2) fue estimado siguiendo las ecuaciones diferenciales propuestas por Clutter et al. (1983). Las características del modelo ajustado son las siguientes:

Predicción de atributos para arbolado de pequeñas dimensiones
Considerando que las funciones empleadas para predecir el crecimiento del arbolado dependen de las condiciones iniciales de los atributos del rodal (edad, área basal, número de individuos por unidad de superficie e índice de sitio), es indispensable conocer el crecimiento del arbolado desde sus etapas iniciales hasta que logra dimensiones en las cuales es posible medir variables, como el área basal (medida a la altura de pecho). Con objeto de estimar el crecimiento del arbolado de pequeñas dimensiones se consideraron las siguientes suposiciones:
]]> a) El crecimiento en cualquier variable dasométrica durante las primeras etapas de desarrollo depende sólo de la calidad de sitio y la edad.b) La densidad sólo tiene efecto en el crecimiento hasta que inicia la competencia.
c) Si la competencia inicia antes de que el rodal alcance el cierre de copas, ésta es ignorada.
Con base en el primer supuesto es posible hacer predicciones implícitas de área basal y volumen de arbolado de pequeñas dimensiones, considerando el crecimiento en diámetro y altura de árboles de crecimiento promedio, así como una expresión del volumen en función de estas variables. La mortalidad natural, sin considerar competencia, se expresaría entonces como una función del índice de sitio, que sería la única variable que afecte la sobrevivencia. De esta forma se tendrían todos los elementos para estimar las variables de interés del rodal en arbolado de pequeñas dimensiones.
Se probaron algunos modelos para la predicción de diámetro y altura usando los datos de los análisis troncales disponibles. Cabe aclarar que para disminuir la variación en el crecimiento a edades maduras, los datos de análisis troncales se restringieron a edades menores o iguales a 30 años. El modelo de mejor ajuste fue una modificación al modelo de Richards, para incluir el índice de sitio. Las características de este modelo se muestran a continuación:

donde las variables tienen la misma definición anterior y "e" representa la base de los logaritmos naturales.
Con el objeto de definir la densidad máxima que está exenta de competencia a un tamaño promedio dado, se ajustó un modelo para predecir diámetro de copa (DC) en función de diámetro normal (d), sólo para árboles de pequeñas dimensiones. La expresión de mejor ajuste es la siguiente:

Con esta función y asumiendo un arreglo hexagonal de copas es posible determinar el número máximo de individuos exentos de competencia (NSC) , dadas una edad y una calidad de sitio para el arbolado con edades menores de 20 años, edad que corresponde al límite inferior del rango de datos.
]]> Si el número de individuos a un tamaño dado es superior al número máximo de individuos sin competencia, entonces la predicción de crecimiento no puede ser hecha. Esto es probable que suceda cuando se simulan densidades de regeneración muy altas.La mortalidad que sucede en el establecimiento de la regeneración se asumió dependiente del índice de sitio. La tabla 1 muestra los porcentajes de supervivencia a los 10 y 15 años que se consideran de acuerdo a rangos de índice de sitio.

Predicción de la mortalidad
Una vez desarrolladas las ecuaciones para proyectar volumen y área basal, el problema de estimar futuros rendimientos se reduce a predecir el número de árboles por unidad de superficie que estarán presentes a la edad de proyección y sobre la cual se distribuirá el área basal y volumen proyectados. La predicción del número de individuos presentes a cierta edad se realizó con un modelo compatible. Esto es, un modelo que predice el número de individuos a la edad de proyección (N2), en función de variables de estado y que además cumpla con las siguientes características lógicas:
* Si A2 (edad de proyección) = A1 (edad inicial) entonces N2=N1 (número inicial de individuos).
* Para rodales coetáneos, si A2 > A1 entonces N2 ≤ N1.
* Para rodales coetáneos, si A2 es muy grande N2 debería tender a cero.
]]> * Los resultados deben ser transitivos, esto es, debe ser lo mismo predecir N3 a partir de N2 que a partir de N1.
Estas cualidades son fácilmente obtenibles con un modelo basado en una ecuación diferencial. Para el caso de Pinus rudis Endl., en Oaxaca se probaron varios modelos y el que brindó mejor ajuste fue el modelo donde la tasa de mortalidad proporcional es una función de la edad y el índice de sitio. Las características del modelo ajustado son las siguientes:

Proyección de estructuras diamétricas
Tal como se ha señalado, el procedimiento de proyección de distribuciones diamétricas denominado "predicción de parámetros" consiste en desarrollar un sistema de ecuaciones de regresión que lleven a predecir valores para los parámetros de alguna función de distribución de probabilidades (fdp), en función de estadísticos del rodal tales como la edad, número de árboles por hectárea, índice de sitio y otros. Para este sistema se usó el modelo Weibull, y la estimación de los parámetros se llevó a cabo con varios procedimientos usando el programa de cómputo WEST (Magaña-Torres y Torres-Rojo, 1991). Este programa calcula ocho conjuntos de estimadores para los parámetros de la distribución Weibull, usando cuatro procedimientos de estimación con percentiles, dos procedimientos de estimación con máxima verosimilitud, un procedimiento de estimación de momentos y un procedimiento a través de regresión no-lineal. Además, proporciona los estadísticos de bondad de ajuste Kolmogorov-Smirnov (KS) y ji-cuadrada (x2) para cada conjunto de estimadores.
Los criterios usados para determinar el conjunto de estimadores de mejor ajuste fueron, por orden de importancia: el estadístico KS, el estadístico x2, la suma de desviaciones absolutas y el valor del diámetro medio estimado.
Una vez que se determinó el mejor conjunto de estimadores para los parámetros de la distribución Weibull para cada sitio, se procedió a ajustar las ecuaciones para predecir estos estimadores en función de los atributos de cada rodal, siguiendo el procedimiento descrito por Torres-Rojo et al. (1992). Los ajustes mostraron las siguientes características:
El estimador del parámetro de localización (a) presentó alta relación con el estimador del parámetro de escala (b) y con el diámetro cuadrático promedio; los tres modelos de mejor ajuste siempre incluyeron estas variables y fueron:

donde B representa el área basal inicial (m2/ha), N es el número de árboles por hectárea, Dq indica el diámetro cuadrático promedio (cm), b es el estimador del parámetro de escala y A corresponde a la edad promedio del rodal (años).
]]> El estimador del parámetro de escala (b) mostró magnífica relación con la variable combinada B/N (Área basal / Número de árboles por hectárea). Los modelos de mejor ajuste fueron:
donde S representa el índice de sitio y H la altura dominante del rodal (m).
El estimador del parámetro de forma (c) mostró mayor relación con el diámetro cuadrático promedio y el índice de sitio. Los modelos de mejor ajuste fueron:

La selección de la combinación de modelos que mejor predicen la distribución diamétrica real se realizó a través de un programa que prueba todas las combinaciones posibles y califica la predicción de acuerdo a los estadísticos KS y x2. Tal calificación permitió identificar la mejor combinación de parámetros por rangos de diámetro y densidad, mismas que se muestran en la tabla 2.

Cabe mencionar que para todos los sitios de la base de datos, las predicciones hechas por los modelos fueron altamente significativas.
Modelos adicionales
]]> Predicción de alturas por categoría diamétricaUna vez que se determinan las frecuencias, por categoría diamétrica, es posible estimar los volúmenes en cada una de estas categorías. Una estrategia para realizar tal estimación es determinar la altura por categoría diamétrica, de tal forma que a través de una ecuación de volúmenes se pueda calcular el volumen en cada una de estas categorías. Este procedimiento requiere de una función que ayude a predecir la altura promedio estimada en cada categoría diamétrica en función del diámetro y atributos de cada rodal. El modelo de mejor ajuste fue:

donde las variables siguen la nomenclatura usada anteriormente.
Función de ahusamiento
Las ecuaciones de ahusamiento permiten conocer la tasa de disminución del diámetro del fuste en función de la altura. Estas tasas se emplean después para determinar el volumen de productos primarios, secundarios y celulósicos. Sin embargo, sólo sirven para definir el tipo de productos más no la calidad de los mismos. Esta última determinación debe hacerse a través de un inventario de distribución y calidad de productos y obviamente varía de acuerdo a las características del arbolado. De todos los modelos de ahusamiento probados, aquel con mejor bondad de ajuste fue el modelo de Bennet y Swindell (1972). Las características del ajuste son:

donde d(h) es el diámetro del árbol a una altura "h" (cm) y h es una altura definida (m); las demás variables tienen la misma nomenclatura que en secciones anteriores.
Usando cualquier procedimiento de "análisis numérico", es posible invertir la ecuación (13) y en lugar de determinar el diámetro del fuste a una altura "h", se determina la altura "h" a la que se encuentra el diámetro requerido. Para propósitos prácticos es importante conocer la altura a la que se tiene el diámetro mínimo de aserrío para la zona (30 cm). De esta forma es posible obtener el número de trozas que se pueden aserrar, su volumen y, por diferencia, el volumen de productos secundarios y/o celulósicos. Este procedimiento puede implementarse fácilmente en un simulador de crecimiento y rendimiento una vez que se hacen las estimaciones de diámetro y altura.
Predicción de diámetros y grosores de corteza
]]> Entre los modelos adicionales necesarios para integrar tanto tablas de inventario, como para poder hacer compatibles las predicciones implícita y explícita se encuentra un modelo de grosor de corteza. Dado que el grosor de corteza es muy variable, si se predice en función del diámetro se optó por ajustar una relación diámetro normal sin corteza (dsc) en función del diámetro normal con corteza (dcc) que tiene las siguientes características:
Otra relación importante para estimar el rango de predicción del modelo dentro de un simulador es la determinación del diámetro normal promedio de árboles individuales en función de la edad y el índice de sitio. La relación de mejor ajuste se presenta a continuación:

Integración de ecuación
Una sola predicción requiere integrar todo el conjunto de ecuaciones de predicción mostradas en las secciones anteriores. La figura 3 muestra el flujo con el cual se realiza una proyección y las verificaciones que se hacen de la misma para asegurar que la proyección se encuentra dentro del rango de predicción y no arrojen valores extremos para los cuales no hay información de predicción. Ya que la misma variabilidad de los modelos podría arrojar proyecciones inválidas.
Validación del modelo de predicción
Dado que en un modelo de predicción como el expuesto se tienen varios componentes interrelacionados que pueden variar significativamente una predicción es recomendable tener una validación no sólo de cada uno de los componentes, sino de la predicción total. Vanclay y Skovsgaard (1997) señalan que un sistema de predicción debe evaluarse desde varios puntos de vista tales como: consistencia lógica y biológica, sensibilidad de las estimaciones y una estimación del nivel de error. El sistema aquí presentado está compuesto por modelos compatibles y de consistencia biológica. En todos los casos no hubo una sola estimación que brindara signos contrarios a los esperados o estimadores de baja significancia. La estimación del error se realizó comparando las estimaciones de la proyección con los 16 sitios dejados fuera del análisis, contra las predicciones del sistema de ecuaciones aquí desarrolladas mediante un coeficiente de determinación (R2) también conocido en biometría como coeficiente de eficiencia (Vancla y, 1994), mismo que tiene la siguiente expresión:
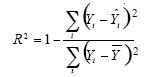
Donde Ŷ¡ representa los valores observados, son los valores predichos y Ȳ corresponde al valor promedio de los valores observados. Se calculó una R2 tanto para la predicción de volumen total explícita como para la implícita. Para la primera el valor fue de 0,924 y para la segunda de 0,876, valores que muestran en una muy buena precisión de todo el sistema de proyección.
]]>CONCLUSIONES
El presente trabajo muestra el uso de información proveniente de parcelas de muestreo permanente para el desarrollo de un sistema de ecuaciones que integra un predictor de crecimiento a nivel rodal, que brinda información de rendimiento por categoría diamétrica.
El predictor en su conjunto puede adaptarse a un sistema de cómputo a fin de integrar un simulador de crecimiento útil para definir óptimas secuelas de cosecha a nivel rodal o para evaluar el efecto de diferentes alternativas de manejo del mismo.
Este predictor mostró proyecciones de buena calidad con la información disponible. Lo más relevante resulta la precisión del sistema de proyección implícita. Sin embargo, resulta necesaria la validación de todo el conjunto de ecuaciones con una mayor cantidad de datos provenientes de sitios similares, principalmente en arbolado de pequeñas dimensiones, mismo que tiene una baja representatividad en la distribución de datos.
El trabajo muestra de forma sistemática la integración y relación de ecuaciones que conforman un predictor de crecimiento.
REFERENCIAS
Avery, T. E. y H.E. Burkhart. 1983. Forest measurements. 3a. ed. McGraw-Hill, Nueva York. 331 p. [ Links ]
]]>Bailey R.L. y T.R. Dell. 1973. Quantifying diameter distributions with the Weibull function. For. Sci. 19:97-104. [ Links ]
Bennett, B.A. y B.F. Swindel. 1972. Taper curves for planted slash pine plantations. USDA For. Serv. Res. Note SE-179. [ Links ]
Clutter, J. 1963. Compatible growth and yield models for Loblolly pine . For. Sci, 9(3) 354-371 [ Links ]
Clutter, J.L., J.C. Fortson, L.V. Pienaar, H.G. Brister y R.L. Bailey. 1983. Timber management: a quantitative approach. Wiley, Nueva York. 333 p. [ Links ]
Gadow, K.v., 1984. Die erfassung von durchmesserverteilungen in gleichaltrigen kiefernbeständen. Forstw. Cbl. 103:360-374. [ Links ]
Hafley, W.L. y H.T. Schreuder. 1977. Statistical distributions for fitting diameter and height data in even-aged stands. Can. J. For. Res. 7:481-487. [ Links ]
MacKinney, A. l. y L.E. Chaiken. 1939. Volume, yield and growth of loblolly pine in the mid-atlantic region. USDA For. Serv. Appalachian For. Exp. Sta. Technical Note No. 33. 30 p. [ Links ]
Magaña-Torres, O.S. y J.M. Torres-Rojo. 1991. WEST: Programa para calcular los parámetros de la función Weibull. 12 p. [ Links ]
Meyer, W.H., 1930. Diameter distribution series in even-aged forest stands. Yale Univ., School of Forestry, Bulletin 28. 105 p. [ Links ]
Prodan, M. 1953. Verteilung des vorrates gleichaltriger hochwaldbestände auf durchmesserstufen. Allg. Forst.- u. Jagdztg. 129:15-33. [ Links ]
Rodríguez-Franco, C. y R. Moreno-Sánchez. 1982. Elaboración de tablas de volúmenes a través de análisis troncales para Pinus montezumae Lamb. en el C.E.F. San Juan Tetla, Puebla. SF. Instituto Nacional de Investigaciones Forestales. Bol. Téc. No. 90. 37p. [ Links ]
Torres-Rojo, J.M., M. Acosta-Mireles y O.S. Magaña-Torres. 1992. Métodos para estimar los parámetros de la función Weibull y su potencial para ser predichos a través de atributos de rodal. A g r o-ciencia. Serie Recursos Naturales 2 (2):57-76. [ Links ]
Vanclay, J.K. 1994. Modelling forest growth and yield: applications to mixed tropical forests. CAB International, Wallingford, Reino Unido. 312 p. [ Links ]
Vanclay, J.K. y J.P. Skovsgaard. 1997. Evaluating forest growth models. Ecological Modelling 98:1-12. [ Links ]
Nota
Este documento debe citarse como: Magaña Torres, O.S., J.M. Torres Rojo, C. Rodríguez Franco, H. Aguirre Díaz y A. M. Fierros González. 2008. Predicción de la producción y rendimiento de Pinus rudis Endl. en Aloapan, Oaxaca. Madera y Bosques 14(1):5-19.
]]>