











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introducción
La irrupción de la comunicación política y los medios masivos ha dejado una huella significativa en la vida cotidiana y ha impactado de manera notable en diversos ámbitos de la vida pública. Uno de los espacios en los que su influencia ha sido más relevante es en los contextos electorales. Gracias a dichos medios, durante un contexto electoral, las propuestas e ideas de los candidatos y las candidatas, los programas de los partidos y la confrontación de ideas ha llegado de manera directa a amplios segmentos de la ciudadanía.
Este fenómeno de comunicación se manifiesta especialmente en los debates electorales, cuya función principal es la de proporcionar un espacio en el cual quienes contienden en una elección puedan presentar de manera clara y concisa sus propuestas, ideas y posturas. Retomando el clásico ejemplo, gracias al éxito de audiencias alcanzado por los debates televisados entre Richard Nixon y John F. Kennedy, en las elecciones presidenciales de 1960 en los Estados Unidos, los debates se convirtieron en una práctica común en muchas elecciones (CPD, 2020, Pietrusza, 2008).
Los debates constituyen un hito en las campañas electorales modernas, y han sido objeto de estudio prácticamente desde su emisión. Tal fue su impacto, que incluso se han construido mitos populares alrededor de ellos, como el que sostiene que aquellos que vieron el debate por televisión declararon a Kennedy como ganador, mientras que aquellos que lo siguieron por radio consideraron a Nixon como el vencedor; o que la imagen mucho más cómoda y elegante de Kennedy durante el primer debate le consiguió a este 2 millones de votos (Bruschke & Divine, 2017). Otro ejemplo paradigmático sucedió en México, en las elecciones presidenciales de 1994, en las que se ha dicho que el debate lo ganó el candidato del Partido Acción Nacional (PAN) y en consecuencia podría ganar la elección, sin embargo no hay evidencia que sostenga dicha posibilidad de triunfo (Valdez, 2006).
A pesar de su importancia, en términos generales, aún no es claro si los debates electorales influyen de manera definitiva en las decisiones de los votantes. Por ejemplo, McKinney y Warner plantean la hipótesis de que los debates de las elecciones primarias son más influyentes que los de las elecciones generales, pero señalan que dadas las características de las campañas y las respuestas de los espectadores a estos, se debe continuar con las investigaciones para establecer teorías generales sobre los efectos de los mismos (McKinney y Warner, 2013).
Lo que sí parece ser claro de los debates de 1960, es la importancia que las campañas políticas dan a la imagen mediática que se construye de los candidatos. Dicha construcción de la imagen se ha convertido en una parte fundamental de las estrategias modernas de las campañas electorales, sobre todo a partir de la llegada de internet y las redes sociodigitales.
Aunque todas las redes sociodigitales son importantes en las campañas electorales, la plataforma X (antes Twitter), se ha consolidado como una herramienta esencial para la discusión política debido a su capacidad para proporcionar información en tiempo real, facilitar la participación ciudadana directa y permitir la rápida difusión de los mensajes políticos; destacándose durante las jornadas electorales o los debates (Bruns y Burgess, 2011). Esto, a pesar de la reciente adquisición por Elon Musk, los cambios que ha sufrido la plataforma implementados por esta nueva administración e incluso cierta pérdida de popularidad de la plataforma en tiempos recientes. Asimismo, debido a la existencia de una API1 la cual hasta mediados de este año contaba con un acceso académico para la búsqueda y recolección de grandes cantidades de datos, era posible la aplicación de metodologías y estrategias de análisis computacionales, como las usadas en este trabajo, para el estudio de la comunicación política y su impacto e interpretación de las audiencias.
Dado el dinamismo de las redes durante los debates electorales, la ciudadanía no solo escucha las propuestas y posturas de los candidatos, sino que además reacciona haciendo comentarios de su aspecto, capacidad de oratoria y el lenguaje corporal (Kalsnes et al., 2014). Esta dinámica de Twitter, que ha sido llamada como tecnología del fandom, muestra que “existen comunidades de fans establecidas que usan las redes sociales para discutir la cobertura en vivo y elogiar, ridiculizar o criticar la transmisión” (Highfield et al., 2013). De fondo, lo que se busca es disputar en el espacio digital el sentido común y así posicionar una narrativa dominante en el discurso público.
En dichas discusiones, las comunidades de simpatizantes expresan opiniones que son reflejo de las emociones y sentimientos que las personas usuarias tienen respecto de un tema. Al respecto, se sostiene que en dichos contextos de discusión se forman cámaras de eco afectivas, en las que los usuarios interactúan con otros “afines”, exponiéndose principalmente a mensajes con sentimiento similar: positivo, neutro o negativo (Himelboim, et al., 2014). Este campo que vincula, desde una perspectiva cuantitativa, las emociones con la política electoral en Twitter, ha generado hallazgos importantes. Por ejemplo, a partir del Análisis de Sentimiento en las publicaciones de los usuarios de dicha plataforma en los debates, es posible determinar su orientación política (Belcastro, et al., 2020), y predecir los resultados electorales mediante la proporción de tweets negativos o positivos en la conversación pública (Yavari, et al., 2022), así como la relación entre las opiniones antes, durante y después de las elecciones con los resultados electorales (Chaudhry, et al., 2021).
Este corpus de investigaciones se ha enfocado en las elecciones estadounidenses, por lo que resulta relevante profundizar en el fenómeno de investigación en México y, particularmente, en el Estado de México, por ser la elección más reciente. Asimismo, es importante indagar cuáles son y cómo cambian las emociones a medida que la transmisión del debate electoral se desarrolla. Sin embargo, esta tarea resulta compleja por dos razones. La primera es que las emociones son en sí mismas “complejos” multidimensionales de formas biológicas, cognitivas y sociales de la experiencia humana (Van Rythoven 2015, 462) y extraerlas de un texto no es a priori una tarea sencilla. La segunda razón es que, normalmente, los debates suelen ser discutidos por millones de internautas que pueden emitir cientos de miles de mensajes en cuestión de horas. Esto hace que analizarlos uno por uno sea una tarea que resulta prácticamente imposible.
Para abordar estas dificultades, una solución efectiva reside en la aplicación de técnicas computacionales, ciencia de datos y análisis estadístico de textos (Cambria & White, 2014). Estas técnicas no solo facilitan el manejo de grandes volúmenes de datos, también ofrecen aproximaciones para determinar si un texto tiene una connotación positiva o negativa, por lo que resultan muy útiles para analizar las conversaciones en Twitter en torno a un debate electoral.
El objetivo principal de este trabajo es analizar el sentimiento expresado en los tweets generados por las comunidades o fandoms políticos durante las transmisiones de los debates electorales que tuvieron lugar el 20 de abril y el 18 de mayo de 2023, en el contexto de la campaña electoral para la gubernatura del Estado de México. Además, se explorará cómo dicho sentimiento cambió en las horas previas y posteriores a los debates.
Para este análisis se usa la técnica denominada Análisis de Sentimiento. En términos generales, el Análisis de Sentimiento se puede entender como una metodología computacional para evaluar cuantitativamente el sentimiento de un texto, asignándole un valor numérico. Para ello se necesita un modelo de Machine Learning que permita identificar si un texto tiene un sentimiento positivo o negativo. Un ejemplo relevante de esta perspectiva para el análisis de la conversación en redes sociodigtales alrededor de debates electorales, es el desarrollado por Kalsnes et al. (2014) que, aunque no hacen uso de un corpus extenso ni una aproximación computacional y de análisis estadístico de textos, analizan el sentimiento y temáticas de 2,391 publicaciones en X (antes Twitter) durante el desarrollo de los debates de las elecciones locales Noruegas en septiembre de 2011. En dicho trabajo, identifican que la conversación en X sigue el desarrollo de los debates televisados, pero también se complementa y contrasta la discusión con comentarios no directamente relacionados con los temas que se discuten durante los debates generados por los fandoms de cada candidata, lo que han denominado como “meta conversación”. Para los autores, X no solamente provee un canal indirecto para la reflexión de los temas discutidos en los debates, sino también un canal para la expresión de apoyo y crítica hacia quienes participan en ellos.
El trabajo se divide de la siguiente manera. Primero, se aporta una breve explicación sobre las metodologías usadas en este trabajo. Posteriormente, se muestran los resultados de aplicar el Análisis de Sentimiento a los tweets recopilados a lo largo de los debates. Finalmente, se discuten los hallazgos y se presentan las conclusiones.
Metodología
Para analizar las conversaciones durante los debates electorales, utilizamos dos herramientas metodológicas: un modelo de clasificación de Machine Learning basado en redes neuronales; y el Term Frequency Inverse Document Frequency que es una métrica que permite identificar las palabras clave en un corpus de textos. A continuación, se explican brevemente estas metodologías.
Redes neuronales artificiales
Las Redes Neuronales Artificiales (RNA), son un conjunto de métodos computacionales inspirados en la actividad neuronal del cerebro y el sistema nervioso central (Walczak y Cerpa, 2003). Consisten en una colección de elementos interconectados (las neuronas artificiales2) que al recibir un conjunto de datos de entrenamiento, le permiten a una computadora “aprender” a realizar una cierta tarea. De esta manera, cuando la red conoce un nuevo conjunto de datos, puede procesarlos y proporcionar resultados gracias al entrenamiento (Hardesty, 2017).
Las Redes Neuronales son capaces de realizar cálculos y operaciones como: agrupamiento y clasificación de datos, reconocimiento de patrones, problemas de ajuste y aproximación de funciones (Steer et al., 2009), lo que ha permitido una gran diversidad de aplicaciones en distintas disciplinas. En el contexto particular del Análisis de Sentimiento de textos en redes sociodigitales, las Redes Neuronales se pueden utilizar como un algoritmo de clasificación que permite ordenar documentos de un corpus en dos categorías respecto al sentimiento subyacente en un texto: positivo y negativo (Zumaya, 2022).
El componente esencial de los modelos de clasificación de aprendizaje automático es el conjunto de datos de entrenamiento. Este conjunto desempeña un papel crucial al representar las características distintivas que definen cada una de las categorías presentes en los datos. Estas características son fundamentales para extrapolar a nuevas observaciones, permitiendo al modelo clasificarlas en las categorías correspondientes.
En el contexto de este trabajo, el corpus TASS3 resulta particularmente idóneo como conjunto de datos de entrenamiento. Este corpus ha sido desarrollado por el Taller de Análisis Semántico de la Sociedad Española para el Procesamiento del Lenguaje Natural (SEPLN). Su idoneidad radica en que está compuesto por textos extraídos de publicaciones en la plataforma Twitter, y el sentimiento de estos textos ha sido evaluado previamente (Villena-Román, 2013).
Con el corpus TASS se ha entrenado un modelo de Análisis de Sentimiento basado en RNA para determinar la probabilidad de que un tweet sea clasificado como positivo o negativo. Por ejemplo, al proporcionar un tweet como entrada, se obtiene como respuesta valores como P = 0.458 y N = 0.542 para el sentimiento positivo y negativo respectivamente. Estos números indican que el modelo asignó una probabilidad ligeramente mayor de asociar ese tweet con un sentimiento negativo que uno positivo. En este trabajo, se considera todos aquellos tweets cuya probabilidad asignada por el modelo sea mayor a 0.8, ya sea en la categoría positiva o en la negativa.
Según los datos de nuestro entrenamiento, el modelo que utilizamos tiene una precisión de 0.862817 para la categoría positiva y del 0.852878 para la categoría negativa. Esto implica que aproximadamente 15% de los tweets evaluados son clasificados incorrectamente (Zumaya, et al., 2022). Es importante señalar que el modelo tiende a cometer errores, principalmente en aquellos tweets con clasificaciones ambiguas, alrededor de 0.5 para las categorías positiva y negativa. Sin embargo, al trabajar exclusivamente con los tweets cuya clasificación es superior a 0.8, se reduce significativamente la tasa de errores en el modelo.
Term frequency Inverse Document Frequency
El Term Frequency-Inverse Document Frequency (TF-IDF), es una estadística numérica que trata de reflejar la importancia de cada una de las palabras del vocabulario que conforman a un conjunto de documentos (Banchs, 2017). El TF-IDF se define de la siguiente manera:
donde f t es la frecuencia de la palabra t, n t es el número de documentos (tweets) en los que aparece el término, y m es el número total de documentos en el corpus. Esta estadística se compone de dos partes. La primera es la frecuencia del término (term frequency TF) que contabiliza el número de veces que aparece una palabra en el corpus y, la segunda, es la frecuencia inversa del documento (inverse document frequency IDF), esto es el número total de documentos en los que aparece una determinada palabra. En este caso, cuantos más documentos contengan la palabra, menos importante es dicha palabra. Así, el TF-IDF es una competencia entre la frecuencia de una palabra y su importancia, entendida ésta como la fracción de documentos que la contienen (Banchs, 2017).
Resultados
En esta sección presentamos los resultados obtenidos al aplicar las técnicas previamente descritas a un conjunto de tweets recopilados durante los debates electorales en el contexto de la campaña que enfrentó a las candidatas Delfina Gómez abanderada de MORENA, PT y PVEM y, con Alejandra del Moral del PAN, PRI y PRD.
Los periodos de análisis de este documento abarcan las horas previas y posteriores a los dos debates (entre las 19:00 y 23:59 horas). El primero se realizó el 20 de abril y, el segundo, el 18 de mayo de 2023. Para los dos casos, recopilamos todos los tweets que hacían mención explícita a las candidatas Delfina Gómez y Alejandra del Moral; así como los hashtags relativos a los debates: #DebateEdoMex, #ConAleAlDebate2023 y #DelfinaGanaDebate, entre otros. De esta manera se obtuvieron las reacciones antes, durante y después de los debates.
Primer debate electoral (20 de abril)
El primer debate entre las candidatas a la gubernatura del Estado de México se llevó a cabo el 20 de abril de 2023 a las 20 horas de la Ciudad de México. Para analizar el sentimiento en torno a este debate, recopilamos los 21,209 tweets originales que se realizaron entre las 19:00 y las 23:59 horas del 20 de abril.
Como se puede observar en la Figura 1, los hashtags más utilizados en estos tweets se refieren en primer lugar a las candidatas, #DelfinaGobernadora y #AleGobernadora; seguidos por #AleGanoElDebate2023 y #DelfinaGanaDebate respectivamente.
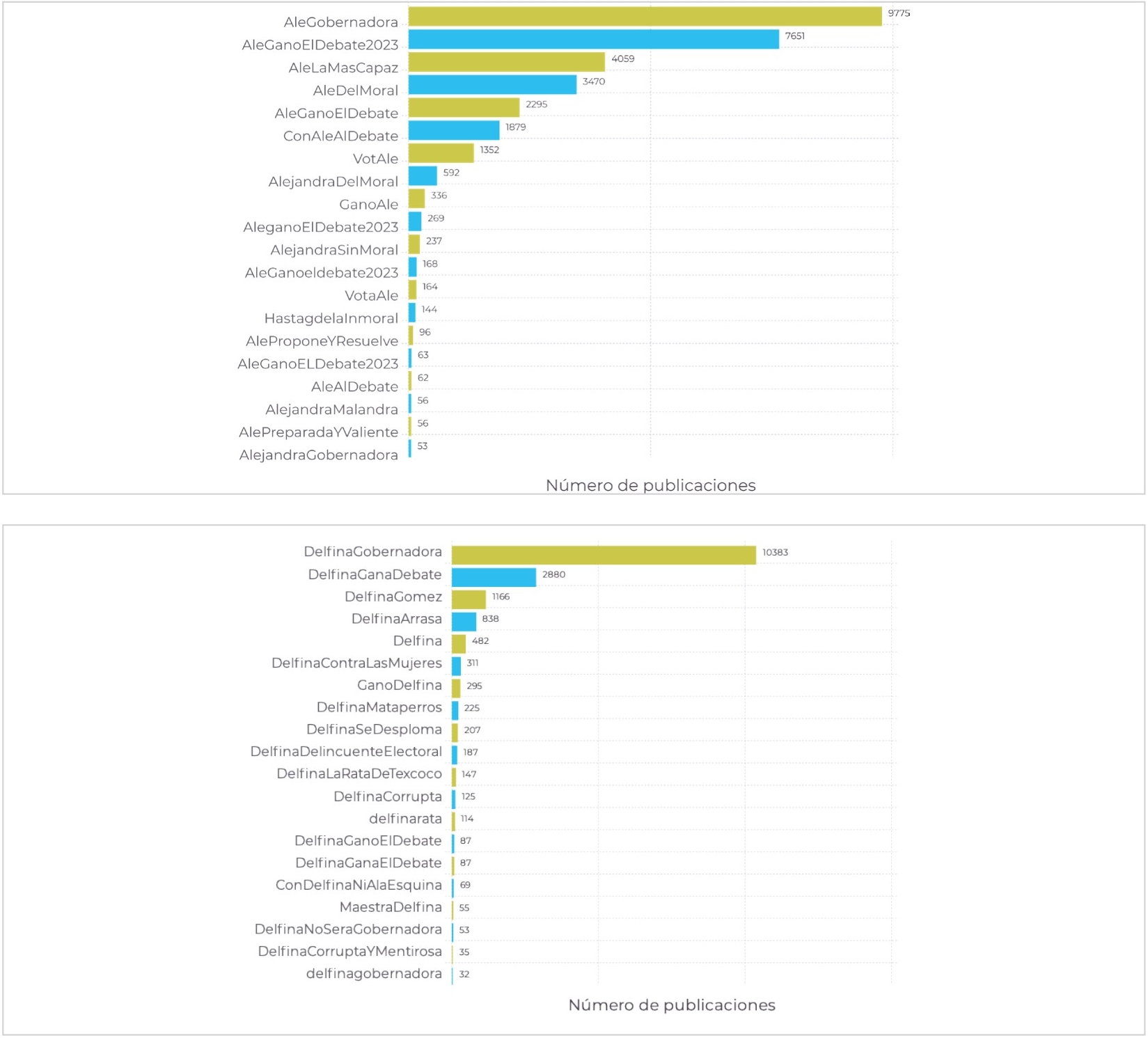
Figura 1 Hashtags que aparecen en las publicaciones durante el primer debate entre las candidatas del Moral (arriba) y Gómez (abajo).
Para el intervalo de tiempo elegido, usamos el modelo de machine learning para estimar el sentimiento (positivo o negativo, con probabilidades mayores a 0.8), de los tweets que hicieron mención explícita a las candidatas. Como se muestra en la Figura 2, identificamos una mayor proporción de menciones negativas en los tweets que aluden a la candidata Gómez, ya que una proporción de 81 % del total de las menciones fueron calificadas por el modelo como negativas, frente a 19 % de menciones positivas. Para el caso de las menciones a la candidata del Moral, observamos que el sentimiento predicho por el modelo es mayormente positivo (55 %).

Figura 2 Análisis de sentimiento de Tweets publicados antes, durante y después del debate del 20 de abril.
Para analizar específicamente la manera como el sentimiento predicho por el modelo cambió durante el debate, determinamos el número de menciones positivas y negativas hechas por minuto durante el intervalo de tiempo monitoreado.
En la Figura 3, se observa el sentimiento como función del tiempo, antes, durante y después del debate. En concordancia con la Figura 2, en esta gráfica también se aprecia que la candidata Del Moral tiene un mayor número de menciones positivas por minuto que la candidata Gómez (panel superior de la figura); y a su vez, la candidata Gómez tiene mayor número de menciones negativas por minuto que la candidata Del Moral (panel inferior de la figura).

Figura 3 Comportamiento temporal del Análisis de Sentimiento para las publicaciones por minuto que mencionan a las candidatas. El panel superior corresponde a las menciones positivas y el inferior a las negativas. La línea roja corresponde a Alejandra del Moral y la línea negra a Delfina Gómez. Las líneas punteadas marcan momentos importantes del debate, en particular aquellos cuando comienza el debate de cada uno de los temas seleccionados: Tema 1, combate a la corrupción, Tema 2, violencia de género, Tema 3, servicios públicos y Tema 4, cultura y recreación.
La Figura 3, muestra también que los momentos de mayor actividad, caracterizados por un aumento significativo en el número de tweets, se concentran en los minutos previos y posteriores al cierre del debate. En el post-debate, se pueden identificar diversos picos tanto en la expresión de positividad como de negatividad. Es en estos momentos cuando los seguidores de las candidatas emiten mensajes donde manifiestan el triunfo y, a su vez, critican a la candidata contraria; siendo evidente que la candidata Gómez es quien más mensajes negativos recibe.
Llama la atención la presencia de un pico de negatividad durante el debate, en torno al Tema 1, que se centró en la corrupción. Esto encuentra su explicación al considerar que la lucha contra la corrupción es un tema recurrente y sumamente debatido en las campañas electorales en general, y en las elecciones mexicanas en particular. Dada la relevancia de este tema, no es sorprendente que genere una atención particular de las comunidades participantes en la conversación de Twitter.
Para determinar si los otros temas debatidos estuvieron presentes en la conversación digital de Twitter, usamos un análisis de TF-IDF, para encontrar las palabras más importantes durante la hora del debate.
De la Figura 4, se puede concluir que de los temas debatidos: combate a la corrupción, violencia de género, servicios públicos y cultura y recreación, solo los dos primeros fueron retomados por las audiencias, ya que los términos corrupción, mujer, violencia y género se observan con tamaños más grandes que el resto de términos. También vale la pena destacar que la palabra moderadora tiene una relevancia especial en la nube de menciones a la candidata Gómez, puesto que su fandom consideró que la moderadora del debate, la periodista Ana Paula Ordorica, no fue imparcial.

Segundo debate electoral (18 de mayo)
El segundo debate entre las candidatas a la gubernatura del Estado de México se llevó a cabo el 18 de mayo de 2023 a las 20 horas de la Ciudad de México. Para analizar el sentimiento en torno a este debate, recopilamos 19,657 tweets originales que se realizaron entre las 19:00 y las 23:59 horas.
Procediendo metodológicamente de manera similar a la descrita anteriormente, identificamos distintos hashtags que mencionan a las candidatas. Al igual que el primer debate, los hashtags más utilizados fueron #DelfinaGobernadora y #AleGobernadora; usados en conjunto con hashtags que daban como ganadoras del debate a cada candidata respectivamente como se puede observar el la Figura 5.

Figura 5 Hashtags que aparecen en las publicaciones durante el segundo debate que mencionan a las candidatas Del Moral (arriba) y Gómez (abajo).
Por otro lado, el análisis del sentimiento de los tweets recopilados durante el intervalo de tiempo de estudio muestra que, en este segundo debate, las menciones a las candidatas tuvieron aproximadamente la misma proporción de menciones positivas y negativas. En este caso, la candidata del Moral tuvo 59 % de menciones positivas y 41 % de menciones negativas. La candidata Gómez, por su parte, tuvo 54 % de menciones negativas frente a 46 % de menciones positivas (Ver Figura 6).
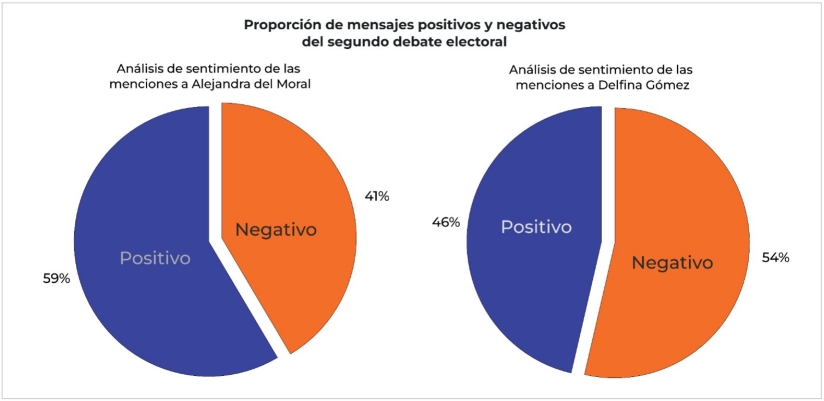
Figura 6 Análisis de sentimiento de tweets publicados antes, durante y después del debate del 18 de mayo.
En cuanto a las menciones por minuto durante el segundo debate, en la Figura 7, se puede observar cómo cambió el sentimiento estimado por el modelo de Machine Learning, durante el intervalo de tiempo analizado.

Figura 7 Comportamiento temporal del Análisis de Sentimiento para las publicaciones por minuto que mencionan a las candidatas. El panel superior corresponde a las menciones positivas y el inferior a las negativas. La línea roja corresponde a Alejandra del Moral y la línea negra a Delfina Gómez. Las líneas punteadas marcan momentos importantes del debate, en particular aquellos cuando comienza el debate de cada uno de los temas seleccionados: Tema 1, seguridad y justicia; Tema 2, economía y empleo; Tema 3, educación y Tema 4, medio ambiente y desarrollo sustentable.
En esta Figura, también se observa que los picos asociados a un mayor número de menciones positivas corresponden al final del debate; momento en que las comunidades expresaron el triunfo de cada una de sus candidatas. Llama la atención que durante dicho ejercicio cívico, el máximo de menciones positivas para la candidata Del Moral corresponde al Tema 2, economía y empleo; mientras que para la candidata Gómez, el mayor número de menciones positivas corresponde al Tema 3, educación.
Este último tema puede entenderse debido a que la candidata Gómez construyó su imagen alrededor de su profesión de maestra, además fue la titular de la Secretaría de Educación durante un periodo del gobierno de López Obrador Por lo tanto, sus seguidores podrían considerar que en este tema ella es experta. Además, no es de extrañar que la mayor cantidad de menciones positivas para Delfina Gómez durante el debate se haya dado sobre ese tema.
Esto también parece observarse en las nubes de palabras obtenidas a través del análisis TF-IDF. En la Figura 8, la palabra maestra es la más importante en las publicaciones que mencionan a la candidata Gómez. Por otro lado, la palabra más importante que hace referencia a la candidata Del Moral es propuestas. De la nube de palabras se infiere que los temas a los que mayor importancia dieron los seguidores de las candidatas fueron los relativos a sus propuestas en materia de seguridad y educación, siendo los otros temas menos relevantes para la audiencia durante este segundo debate.

Discusión y conclusiones
Discusión
Se ha visto que usando el método de clasificación por redes neuronales y Machine Learning, ha sido posible observar qué sentimiento está asociado a las publicaciones de Twitter, y cómo este cambió en las horas previas y posteriores a los debates electorales. Como se observó en las Figuras 3 y 7, la mayoría de los tweets, tanto positivos como negativos, ocurrieron justo al terminar los debates. En este post-debate, los fandoms políticos enfocaron sus esfuerzos en asegurar que sus respectivas candidatas habían resultado ganadoras.
Esto se puede corroborar al hacer un análisis TF-IDF para determinar las palabras más importantes asociadas a los tweets positivos en las horas posteriores al debate. En la Figura 9, se observan las nubes de palabras, donde se destacan los términos ganó/ganar, asociados a la vez a las dos candidatas. Identificamos también que el fandom de la candidata Gómez, usó ampliamente la palabra maestra para referirse a ella. Esto sugiere que la imagen que construyó la candidata tuvo una buena recepción por parte de su comunidad. No se puede decir lo mismo de la candidata Del Moral, ya que no se aprecia un uso destacado de la palabra valiente, que fue el término que ella acuñó y usó como su imagen al inicio de la campaña (Caloca Lafont & Ruiz Molina, 2023). Asimismo, las nubes de palabras sugieren que el término Ale, fue más usado por la comunidad que apoyaba a la candidata Del Moral.

Figura 9 Nube de palabras generadas mediante el cálculo del Term Frequency - Inverse Document para los tweets, calificados como positivos, recopilados tras terminar el primer debate (arriba) y segundo debate (abajo).
Aunque en las nubes de palabras también se destaca el término propuestas, no hay evidencia de que en el post-debate las comunidades discutieron sobre los temas abordados durante las transmisiones como se observa en la Figura 9. Esto sugiere que las temáticas, que en estricto sentido son la esencia de un debate, no son relevantes en la discusión en Twitter posterior al ejercicio cívico, debido a que lo importante es posicionar una ganadora.
Este fenómeno se evidencia al observar que, minutos después de concluir el debate, ambas candidatas publicaron tweets proclamándose como ganadoras en los dos debates analizados. Al sumarse a la “ola de triunfalismo” que se gestaba hacia el final de los debates, estos mensajes desencadenaron una cascada de respuestas positivas asociadas a la victoria. Parece que, para sus respectivos fandoms, en esos momentos del post-debate, lo crucial era resaltar la imagen del triunfo en lugar de profundizar en una discusión sobre las propuestas de las candidatas.

Figura 10 Capturas de pantalla con los tweets escritos por las candidatas minutos después del final de los debates del 18 de mayo y 20 de abril.
Nótese que, en las anteriores imágenes, la candidata Gómez aparece en un plano contrapicado, mientras que la candidata Del Moral tiene la mano derecha levantada. Estos planos y gestos suelen usarse para proyectar una imagen de fortaleza y liderazgo. Este tipo de mensajes publicados desde las cuentas de las candidatas ejemplifican lo que Constance Duncombe ha estudiado en relación con las emociones en la plataforma de Twitter. De acuerdo con esta investigadora, Twitter es una plataforma que tiene condiciones, tales como la limitación de los mensajes a 280 caracteres, o su ritmo acelerado, que la hacen apropiada para la expresión de emociones, tanto positivas como negativas y no necesariamente de ideas o argumentos; lo cual puede tener un impacto significativo en el discurso político (Duncombe, 2019).
Los picos de positividad al finalizar los debates, más los mensajes de las candidatas mostrándose como triunfadoras, motivaron a que la discusión se diera más en el plano emocional que en el de los argumentos y las propuestas. En ese sentido, a pesar de que Twitter es un espacio donde la comunidad puede conectarse y debatir, en realidad parecen usarlo más para expresar y propagar emociones.
Conclusiones
En este trabajo usamos metodologías computacionales tales como el Machine Learning y el Term Frequency - Inverse Document Frequency, para realizar un análisis del sentimiento de los tweets publicados durante los debates electorales en el marco de las elecciones a gobernadora en el Estado de México para el periodo 2023-2029.
A pesar de la complejidad inherente en el Análisis de Sentimientos en un texto, las metodologías aquí usadas nos permitieron examinar los sentimientos presentes en aproximadamente 40 mil tweets. Clasificamos estos mensajes en categorías de positivos y negativos, además de identificar las palabras más importantes dentro de ellos. Cabe destacar que la ejecución se realizó en un tiempo razonable en una computadora personal de configuración de gama media. Esto sin duda representa una ventaja para analizar y entender cómo la sociedad experimenta los procesos electorales utilizando corpus más amplios que permiten tener una lectura general de los temas que se discuten alrededor de los debates electorales. Sin embargo ésta aproximación y metodología de análisis genera una tensión entre lo que se determina como lecturas distantes y cercanas en las humanidades digitales, es decir, técnicas que permiten el procesamiento de un corpus extenso, como los usados en este trabajo, en comparación con técnicas de análisis de un conjunto menor, pero curado cuidadosamente (Jänicke et al., 2015), consideramos que ambas técnicas pueden ser complementadas para tener una mejor comprensión de la conversación en las redes sociodigitales.
Asimismo, el Análisis de Sentimiento nos permitió observar cómo los fandoms políticos percibieron a las candidatas durante los debates. De los resultados obtenidos se desprende de manera evidente que los mensajes asociados a la candidata Gómez fueron percibidos con una carga negativa mayor en comparación con los tweets que mencionan a la candidata Del Moral. Se destaca que estas comunidades desempeñan una función dual, por un lado, manifiestan su respaldo a la candidata de su preferencia mientras emiten críticas y, por otro lado, atacan a la persona rival. Esta dinámica, ampliamente reconocida en la esfera de Twitter, parece manifestarse como una constante en elecciones contemporáneas en la era de las redes socio digitales.
A diferencia de otras investigaciones, que han realizado predicciones en torno a las elecciones con Análisis de Sentimiento, como las que se presentó en el apartado introductorio, en esta investigación identificamos que la candidata que más opiniones negativas recibió fue quien ganó las elecciones. Lo cual muestra un hallazgo contraintuitivo. Esto muestra que, para el caso mexicano, el ecosistema mediático está atomizado y las discusiones que suceden en el espacio digital, particularmente en Twitter, no son reflejo necesariamente de la opinión de la mayoría de las personas. A diferencia del mundo anglosajón, en México hay todavía brechas tecnológicas, digitales y, a manera de hipótesis, en X (antes Twitter) hay sesgos ideológicos entre quienes usan dicha plataforma. No obstante, esta última reflexión requiere mayor análisis.
Adicionalmente, analizamos la variación en el sentimiento tanto en las horas anteriores como posteriores a los debates. La metodología permitió tener una resolución temporal de minutos, lo cual hace que sea posible discernir entre picos de actividad, tanto positivos como negativos. Estos periodos de actividad se manifestaron principalmente al concluir los debates y en las horas subsiguientes. En dichos momentos se pudo evidenciar que la intención tanto de las candidatas como de sus respectivos seguidores fue la de proclamar un triunfo.
También fue posible explorar la conversación durante el debate. De este análisis se constató que, de entre los temas seleccionados para dichos encuentros, únicamente aquellos vinculados a la corrupción, la violencia de género, la seguridad y la educación adquirieron relevancia para las comunidades que siguieron y participaron en el debate a través de X. Esto responde a la relevancia de las temáticas en el contexto mexiquense y mexicano.
Esta perspectiva de análisis también nos ha permitido inferir que la estrategia en términos de construcción de imagen pública de Delfina Gómez, como la “maestra Delfina”, resonó de manera más efectiva en su comunidad en comparación con la estrategia de “valiente” empleada por Alejandra del Moral. Esta inferencia se sustenta en la constatación de que la palabra “maestra” figura prominentemente en muchas de las nubes de palabras obtenidas, mientras que la palabra “valiente” no ocupa un lugar destacado ni en los tweets ni en los hashtags que mencionan a la candidata Del Moral.
Las herramientas computacionales y de Análisis de Sentimiento pueden ser de gran utilidad para examinar en profundidad los debates electorales y sus implicaciones en los sectores de la sociedad que frecuentemente participan en las redes socio digitales, las cuales adquieren cada vez más relevancia en los contextos electorales. No obstante, es importante señalar que se requiere una mayor investigación y esfuerzo para ampliar el entendimiento sobre este tema y profundizar en su complejidad.

