nova página do texto(beta)
nova página do texto(beta) Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
PermalinkClasificación JEL: C18, C81, D10, J24.
Introducción
Una preocupación constante en el análisis de encuestas que involucran la declaración de ingresos es el subreporte que puede haber por parte de individuos y hogares, el cual puede afectar tanto a diversas estimaciones que utilizan estos datos como a indicadores de incidencia de política pública basados en ellos. En la literatura pueden encontrarse estudios que muestran que no considerar los salarios no reportados en investigaciones sobre salarios e ingreso puede generar sesgos en diversas estimaciones, si bien estos estudios son generalmente para países desarrollados que cuentan con mejores bases de datos.
Por ejemplo, para el caso de Estados Unidos, utilizando la Encuesta de Población Actual (Current Population Survey, o CPS por sus siglas en inglés), (Lillard, Smith y Welch, 1986) encuentran un sesgo potencial en las estimaciones con la presencia de observaciones con salario no reportado, aunque con subestimaciones en ocupaciones muy detalladas.1 (Rubin, 1996) sugiere que más allá de la aleatoriedad de los faltantes, es importante proveer imputaciones, ya que no hacerlo crea estudios derivados de una muestra más pequeña. En general, si bien no hay un consenso para el mejor método de imputación, se trata de un tema que, al menos académicamente, debe ser tomado en consideración para su discusión en cuanto a las implicaciones que puede representar.
En algunos países, las oficinas de estadística reportan encuestas con ingresos directamente imputados. Por ejemplo, la CPS, levantada por el Bureau of Labor Statistics (BLS), y que es una de las más utilizadas en Estados Unidos para realizar diversos indicadores de políticas públicas, así como para llevar a cabo investigaciones académicas, hace una imputación de ingresos mediante observaciones donantes del mismo periodo en una primera fase, y posteriormente en periodos previos, con el fin de llenar las celdas de ingresos faltantes. La tasa de ingresos faltantes en esta encuesta llega hasta 30%. (Bollinger y Hirsch, 2006) analizaron si esta imputación causa algún sesgo en estimaciones de capital humano que incluyen las imputaciones, sugiriendo algunas alternativas de correcciones, y dejando al debate académico su aplicación o no. No obstante, estos autores no analizan los posibles sesgos en indicadores de política pública derivados de los ingresos faltantes en ciertas observaciones (p. ej., pobreza, desigualdad, etcétera).
En este sentido, México se ha vuelto un caso de análisis interesante, ya que las Encuesta Nacional de Ocupaciones y Empleo (ENOE), que trimestralmente captura tanto ingresos como otros indicadores laborales, ha experimentado un amplio crecimiento en observaciones con ingreso faltante, pasando de alrededor de 13% en 2005 a 24% en 2012; aunque las demás características sí se encuentran consignadas de forma normal en la encuesta. Esta cuestión ya ha sido analizada en dos estudios derivados de forma similar.
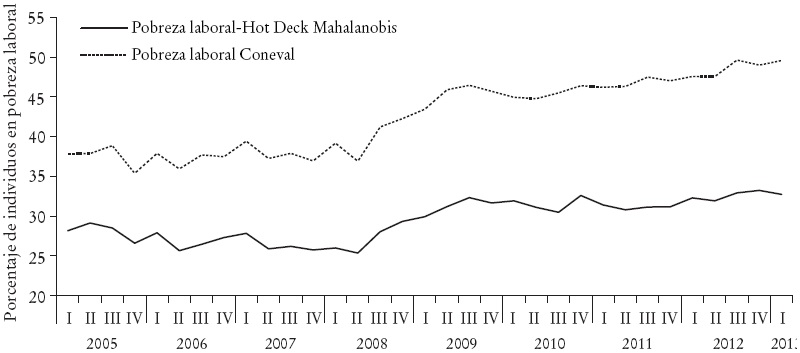
En el primero, (Rodríguez-Oreggia et al., 2012), utilizando un proceso de matching para imputar ingresos faltantes, encuentran que no considerar aquellas observaciones con ingresos laborales faltantes en la Encuesta Nacional de Ocupación y Empleo (ENOE) puede conllevar a sobreestimaciones en el indicador de pobreza laboral, calculado por el Consejo Nacional de Evaluación de la Política Social (Coneval, 2013). En términos generales, cuando se realiza esta estimación no se toman en cuenta los salarios faltantes y se le suma cero al ingreso del hogar para aquellos individuos que no reportan un salario pese a que, en realidad, lo perciben, por lo que existen hogares que pueden estar considerados dentro de pobreza laboral, cuando en realidad no necesariamente lo están.
En el segundo, (Vázquez-Campos, 2013) analiza la muestra que no reporta ingresos en la ENOE y encuentra que las tendencias de no reporte no son aleatorias. El autor realiza una revisión de las metodologías de imputación y aplica cuatro diferentes métodos de imputación (pareamiento por puntaje, Hot Deck, imputación en la mediana de un grupo con ruido, y pareamiento por promedios predictivos), encontrando un menor nivel y crecimiento de la pobreza laboral que el reportado por el Coneval, así como un incremento en la desigualdad al usar ingresos imputados.
Como resultado de estos estudios se deduce la necesidad no sólo de analizar la incidencia de los ingresos faltantes sobre indicadores como pobreza laboral sino, más allá de eso, de estudiar cuál es el papel que tiene la imputación de ingresos o el uso solo de ingresos reportados sobre estimaciones de capital humano, donde factores como la educación desempeñan un papel relevante. Como se señaló, los ingresos faltantes no ocurren de forma aleatoria en la encuesta, por lo que es posible que existan sesgos en la medición de factores relacionados con ingreso y pobreza laboral. Por ello, el objetivo de este artículo es analizar el posible sesgo que existe de ignorar los ingresos faltantes en la ENOE al medir los efectos de diversas variables sobre ingreso laboral y pobreza laboral, una vez imputados los ingresos mediante el método de Hot Deck. Para realizar esta contribución a la literatura, realizaremos algunos métodos de imputación y, posteriormente, estimaciones de capital humano considerando ingresos y pobreza laboral para medir estas posibles desviaciones.
El artículo se estructura como sigue. En una primera parte se presentan los mecanismos por los cuales pueden existir ingresos faltantes en las encuestas. Posteriormente, se analizan los faltantes en la ENOE y sus características comparadas con los reportados. A continuación se presentan los supuestos de imputación y el método de estimación. Después se analizan los resultados y finalmente, se delinean conclusiones y algunas recomendaciones.
I. Mecanismos de respuestas faltantes
El análisis de encuestas que involucran la declaración de ingresos se ha enfrentado constantemente a un subreporte en esta pregunta. Las razones por las cuales los individuos y hogares pueden no reportar su ingreso son muy diversas. (Groves, Singer y Corning, 1999) recuentan estas razones en una serie de múltiples factores que actúan en forma simultánea, desde los temas que va cubriendo la encuesta, la presencia de otras personas, el tema de confidencialidad, hasta factores socioeconómicos y físicos.
La estadística ha afrontado el problema de ingresos faltantes en encuestas mediante la imputación de salarios a aquellos individuos que no reportan un salario de diversas maneras. Primero, para realizar una imputación de salarios es importante considerar tres mecanismos de respuesta resumidos en (Rubin, 1987) y (Little y Rubin, 2002): salarios faltantes completamente de forma aleatoria (MCAR, por sus siglas en inglés), salarios faltantes de forma aleatoria (MAR, por sus siglas en inglés), y salarios faltantes de forma no aleatoria (MNAR, por sus siglas en inglés). La estrategia a seguir para tratar los salarios no reportados va a depender de cuál sea el mecanismo de respuesta de los individuos que no reportan un salario.
Un dato faltante completamente de forma aleatoria implica que la probabilidad de no reportar es independiente de la variable de análisis y de las variables del modelo explicativo; en este caso, no reportar un salario sería independiente del salario mismo y de las variables que lo explican. Si se diera ese caso, entonces no existiría un sesgo en las estimaciones al no considerar las observaciones que no reportan un salario. Cabe señalar que encontrar este mecanismo en datos faltantes es algo muy raro empíricamente.
Por otro lado, un dato faltante de forma aleatoria implica que la probabilidad de no reportar es independiente del verdadero valor de la variable en cuestión, pero es dependiente al menos de una de las variables explicativas del modelo (Treiman, 2009). En este sentido, si se diera este caso, entonces una simple estimación del salario sin considerar el problema de las observaciones con salario no reportado podría estar sesgada. Para evitar un sesgo en las estimaciones es importante realizar una imputación a la variable de salarios para aquellos individuos que no reportan un salario.
Finalmente, se puede presentar el caso de datos faltantes de forma no aleatoria. En este escenario, la probabilidad de no reportar es dependiente de la variable en cuestión y de las variables explicativas del modelo, de tal forma que se tiene un problema de selección en variables no observadas. Por ejemplo, con este mecanismo de respuesta los individuos con mayores salarios podrían tener una probabilidad mayor de no reportar comparados con los individuos con salarios medios, de tal manera que no reportar está correlacionado con el nivel del salario. Esto lleva a un problema adicional de no observables en la imputación, lo cual todavía no está resuelto en la literatura estadística existente.
II. Mecanismo de respuesta de las observaciones con salario no reportado en la ENOE
En México, el Instituto Nacional de Estadística y Geografía (INEGI) levanta trimestralmente la encuesta ENOE, a hogares e individuos de forma rotativa por cinco trimestres consecutivos, preguntando acerca de características socioeconómicas, así como detalles de características laborales, como si tiene una ocupación o no, en su caso ingreso laboral, horas trabajadas, tipo de ocupación, sector de actividad, prestaciones, etc., para todos los integrantes de un hogar de 14 años de edad en adelante. Se trata de una encuesta que se utiliza para dar seguimiento a indicadores agregados como el desempleo, actividades formales, entre otros usos.
La ENOE captura el ingreso laboral a través de dos preguntas en secuencia. En la primera se pregunta directamente a las personas ocupadas que deben recibir un pago: “¿Cuánto ganó o en cuánto calcula sus ingresos?” La pregunta incluye la periodicidad, y en las bases de microdatos del INEGI ya se reporta el monto estandarizado mensual.2 Si los individuos contestan esta pregunta, entonces se pasa a la parte de prestaciones laborales. Sin embargo, si no se responde a esta pregunta, el cuestionario pasa a una segunda pregunta para tratar de determinar el ingreso laboral: “Actualmente el salario mínimo es de (cantidad) ¿la cantidad que obtiene al mes por su trabajo es...?” Y se detallan algunos rangos acotados en niveles de salarios mínimos. Si se contesta -o no se desea hacerlo- esta segunda pregunta el cuestionario avanza igualmente a la parte de prestaciones laborales, dejando a una parte de individuos sin respuesta en ambas preguntas sobre ingresos.
La muestra que analizamos a continuación abarca a individuos de 14 años o más, que forman parte de la población económicamente activa (PEA) y están ocupados en categorías que implican un pago. Esto es, se excluye de la muestra a individuos que caen en la categoría de ocupados sin pago. El periodo de análisis va desde el primer trimestre de 2005 al primer trimestre de 2013.
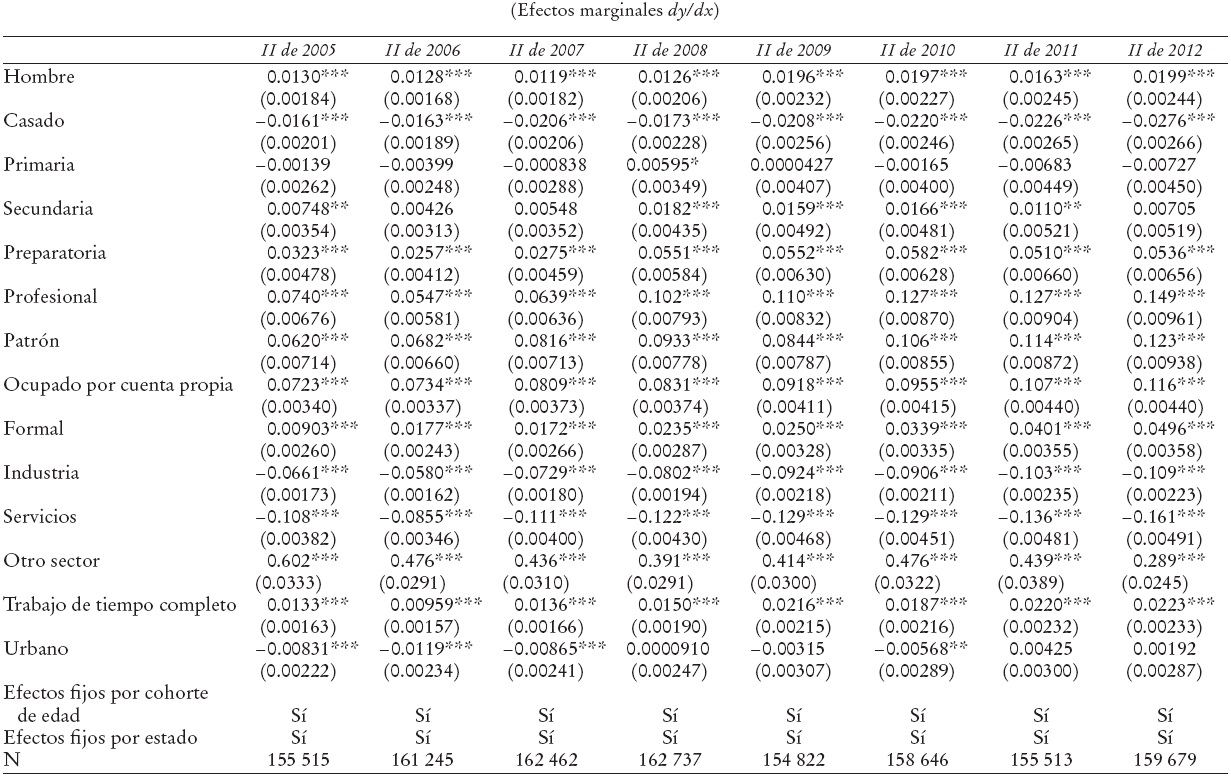
Como se puede observar en la Gráfica 1, existe una tendencia creciente en el porcentaje de individuos que no reportan un salario en la ENOE, tomando en cuenta solamente la pregunta principal de “en cuánto calcula su ingreso laboral”. En el primer trimestre de 2005, 14.61% de los ocupados de 14 años o más que deberían reportar un salario, no lo reportan; para el primer trimestre de 2013 este porcentaje aumenta a 24.03%.3 El porcentaje máximo de observaciones que no reportan un salario se observa en el tercer trimestre de 2012, alcanzando 24.25%. De la gráfica se puede deducir que, a lo largo del tiempo, el porcentaje de observaciones que no reportan un salario ha aumentado de forma constante. Lo anterior reafirma que el mecanismo de respuesta de las observaciones que no reportan un salario no es comple tamente aleatorio y que pueden existir algunas características observables, y no observables, correlacionadas con el mismo.

* Se incluye sólo la pregunta sobre el ingreso y no la indirecta sobre los salarios mínimos. La muestra incluye observaciones con 14 años o más que forman parte de la PEA, ocupados y que no entran dentro de la categoría de ocupados sin pago. Datos de la ENOE.
Gráfica 1 Porcentaje de observaciones con salario no reportado en pregunta principal*
En este sentido, es importante identificar si los factores correlacionados con la probabilidad de no reportar son aquellas variables explicativas del salario (Treiman, 2009). Para ello, se realizan pruebas de media con las variables explicativas del salario entre los individuos que reportan un salario y los individuos que no lo hacen. Si existe una diferencia en las medias del vector de características, entonces la probabilidad de no reportar un salario está correlacionada con las mismas.
En el Cuadro 1 se presentan los resultados de las pruebas de media para el segundo trimestre de 2005 de un vector de variables explicativas del nivel del salario.4 Como se puede observar, existen diferencias significativas a lo largo del tiempo en las medias de las variables entre las observaciones que reportan un salario y las observaciones que no lo hacen. En este sentido, no reportar un salario no se da de forma completamente aleatoria; la probabilidad de no reportar un salario está correlacionada con el vector de variables explicativas del mismo.
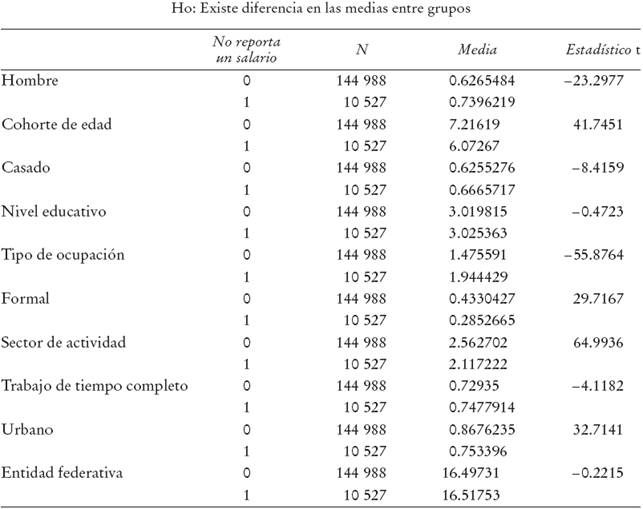
* La muestra incluye a observaciones con 14 años o más que forman parte de la PEA, ocupados y que no entran dentro de la categoría de ocupados sin pago. 1 = no reporta un salario, 0 el caso contrario. Salario reportado pertenece a la pregunta principal de cuánto calcula su ingreso laboral.
Cuadro1 Pruebas de diferencia en medias*
Una forma adicional de probar la robustez de este resultado es estimar un modelo probit en donde la variable dependiente es una dummy, donde 1 son aquellas observaciones que no reportan un salario y 0 el caso contrario. Los resultados se muestran en el Anexo 1. Por simplificación, las estimaciones se presentan para los segundos trimestres de 2005 a 2012. Los resultados muestran una fuerte correlación entre el vector de variables explicativas del salario y la probabilidad de no reportarlo. Adicionalmente, en los resultados se puede observar que, con respecto a las mujeres, los hombres tienen una mayor probabilidad de no reportar un salario. De igual forma, los individuos con estudios profesionales tienen mayor probabilidad de no reportar un salario, al igual que los trabajadores formales y los trabajadores de tiempo completo. Por lo tanto, dado que existen factores observables correlacionados con la probabilidad de no reportar un salario, se descarta la posibilidad de que el mecanismo de respuesta de las observaciones con salario faltante en la ENOE sea faltante de forma completamente aleatoria.
No existe una prueba formal para mostrar que la estructura de las observaciones con salario no reportado es faltante de forma no aleatoria (MNAR). Es difícil probar que la probabilidad de no reportar un salario esté correlacionada con el nivel del salario en cuestión, al menos de forma directa. (David, Little, Samuel y Triest, 1986), utilizando la CPS, encuentran para Estados Unidos que, aunque existe evidencia de que el mecanismo de respuesta sea no aleatorio, en la práctica no es cualitativamente importante. En este sentido, en el presente artículo se asume que la probabilidad de no reportar un salario no guarda una correlación directa con el nivel del mismo.5 Por lo tanto, de las pruebas anteriores se concluye que la estructura de las observaciones que no reportan un salario en la ENOE es del tipo MAR, es decir, existe una correlación entre la probabilidad de no reportar un salario y las variables explicativas del mismo, pero en las categorías del vector de estas variables se da de forma aleatoria.
En este sentido, dada la existencia de observaciones con salario no reportado en la ENOE, probaremos los posibles sesgos en estimaciones y mediciones de indicadores al considerar sólo la variable de ingreso reportado, con aquellas derivadas de añadir ingresos imputados. En la siguiente sección se presentan los supuestos necesarios para realizar una imputación de salarios y la metodología a utilizar.
III. Supuestos de la imputación
La metodología a utilizar está basada en un aparejamiento (matching) entre características observables tanto demográficas de cada individuo y de su hogar, como laborales, de forma que se busca un donante que tenga las mismas características del individuo que no reporta un salario.
Una vez que se prueba que la estructura de las observaciones que no reportan un salario es del tipo MAR, es importante definir los supuestos bajo los cuales se realiza la imputación de salarios entre donantes y receptores. En el presente artículo, yi
es la variable de interés para la observación i; zi
es el vector de variables explicativas de yi
para la observación i, y zi
es el vector de variables para la observación i bajo las cuales se realiza la imputación. Se debe cumplir que
Supuesto 1: Existen datos faltantes únicamente en algunas observaciones de la variable yi.
Supuesto 2:
Supuesto 3:
Supuesto 4:
Supuesto 5: Los valores imputados de yi son seleccionados aleatoriamente de la función de distribución
El primer supuesto parece un poco redundante. Sin embargo, es importante notar que únicamente se podrá hacer las imputaciones si la única variable con datos faltantes es la variable y. Las observaciones con datos faltantes en alguna de las variables del vector z no serán consideradas para la imputación.
El segundo supuesto es muy importante y está relacionado con la condición MAR. EO [·]; es la esperanza condicional de yi para las observaciones con salario reportado; EM [·] es la esperanza condicional de yi para las observaciones con salario no reportado y E[·] es la esperanza condicional de yi para la población. El supuesto implica que la media condicionada de la variable yi es igual entre donantes y receptores, de tal forma que no existe un problema de selección entre donantes y receptores. Este supuesto permite considerar datos faltantes de forma aleatoria dado que la distribución de (xi , zi ) puede variar entre donantes y receptores, pero se garantiza que en promedio el salario es el mismo dentro de cada celda. (Bollinger y Hirsch, 2006) llaman a esta condición como media condicional faltante de forma aleatoria (CMMAR, por sus siglas en inglés).
El tercer supuesto establece que el vector de variables con las que se realiza la imputación es un subconjunto del vector de variables explicativas de análisis. Adicionalmente, el vector z puede agregar al vector x en categorías más amplias. Por ejemplo, considérese los años de educación como una variable explicativa del salario. Una forma de agregar estos años es mediante categorías: nivel de instrucción primaria, secundaria, preparatoria o profesional. De esta manera, se tiene que, si se conocen los años de educación, entonces se puede conocer su agregación, pero lo contrario no necesariamente se cumple.
El cuarto supuesto implica que la relación entre el vector de variables explicativas y la variable dependiente es lineal y que no existe una relación entre el vector z y la variable dependiente más allá de la que se contiene en el vector x.
Finalmente, el quinto supuesto establece que los valores imputados de la variable dependiente son independientes de cualquier variable no observada o no incluida en el vector z. Esto permite que los valores imputados sean seleccionados de manera aleatoria para evitar subestimaciones en la varianza de la variable dependiente.
IV. Método de imputación
Los métodos de imputación han sido ampliamente estudiados en la literatura. En general, lo que tratan de hacer es asignar un valor conocido o estimado a aquellas observaciones con datos faltantes condicionado a un vector de características sociodemográficas.6 Esta sección revisa brevemente algunos métodos, ya que otros estudios contienen descripciones más detalladas (por ejemplo Frick y Grabka, 2003). Utilizando la ENOE, (Campos-Vázquez, 2013) compara cuatro diferentes métodos de imputación sobre el cálculo del indicador de pobreza laboral y concluye que todos arrojan resultados similares, sugiriendo que se utilice el que represente menos complicaciones para estimar.
Uno de los métodos más utilizados es el método no paramétrico de celdas de Hot Deck. Este método permite identificar individuos similares en celdas construidas con el vector de variables sociodemográficas, para posteriormente imputar un salario a las observaciones con salario faltante de manera aleatoria o con base en una función de distancia.
En el presente artículo el método utilizado para la imputación de salarios será el de Hot Deck con dos variantes. Primero, se realizará la imputación mediante una asignación aleatoria. Luego, se realizará una imputación mediante una función de distancia de Mahalanobis. Ambos métodos son utilizados por el Bureau of Labor Statistics (BLS) para la imputación de salarios en la CPS, y se ha demostrado que son robustos a otros métodos paramétricos de imputación (West et al., 1990). Adicionalmente, la ventaja de estos métodos consiste en que mantienen la misma distribución de características para cada celda k (Kalton y Kasprzyk, 1982).
1. Hot Deck con imputación aleatoria
Este método consiste en identificar las observaciones en celdas construidas con base en un vector de variables sociodemográficas, y asignar de manera aleatoria el salario de individuos donantes a individuos receptores para cada celda. De tal manera, se tiene que:
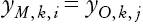
en la que yM es el salario no reportado, y yO es el salario reportado. Existen k celdas, en donde i son los individuos que no reportan un salario y j son los individuos seleccionados aleatoriamente (con reemplazo) que reportan un salario para cada celda k.
Es importante considerar que, de acuerdo con (Little y Rubin, 2002), una imputación simple puede generar sesgos en la varianza de la variable de interés debido a que se realiza una imputación de manera aleatoria en cada celda k. Sin embargo, (Rubin, 1987) establece que estos problemas se pueden solucionar mediante una imputación múltiple, en la que se simulan de manera aleatoria m imputaciones, en donde m > 1. Después de las m simulaciones, se promedia el valor imputado para cada simulación y se asigna este valor a las observaciones con valores no reportados. Esto evita sesgos en la estimación de la varianza de la variable de interés, por lo que puede realizarse inferencia. En general, m = 5es suficiente para tener una buena imputación. Por lo tanto, en el presente artículo se realizan cinco simulaciones.
1. Hot Deck con función de distancia
El método de Hot Deck que considera una función de distancia es muy similar al anterior, con la particularidad de que la imputación en cada celda k se hace mediante la minimización de una función de distancia, en este caso, una función de distancia de Mahalanobis. Algunos estudios utilizan una función de distancia euclidiana (p. ej. West et al., 1990); sin embargo, en el presente artículo se considera la función de distancia de Mahalanobis debido a que pondera por la matriz de varianzas y covarianzas del vector de covariables utilizadas para realizar la imputación. De tal manera, se tiene que:
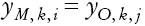
en donde las observaciones i (receptor) y j (donante) cumplen con la minimización de la siguiente función de distancia:
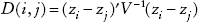
En la que V -1 representa la matriz inversa de varianzas y covarianzas de las covariables utilizadas para la imputación.
V. Resultados
En esta sección se presentan los resultados de la imputación considerando los criterios descritos anteriormente, y se demuestra el sesgo potencial en las estimaciones con salario no reportado. (Bollinger y Hirsch, 2006) utilizan la encuesta de población actual (CPS) de Estados Unidos para estudiar el sesgo potencial en estimaciones de capital humano que consideran únicamente el salario reportado comparando con las que imputan los ingresos. En este sentido, en el presente artículo se quiere identificar el sesgo potencial y su dirección en los parámetros comúnmente estimados en estudios laborales en México que utilizan la ENOE, y en parte seguiremos el artículo mencionado.
En la Gráfica 2 se puede observar el porcentaje de imputaciones realizadas en cada etapa. La muestra abarca individuos de 14 años o más, que forman parte de la PEA, ocupados, y que no caen dentro de la categoría de ocupados sin pago. En una primera etapa, a aquellas observaciones que no reportan la pregunta principal, pero sí la de salarios mínimos, se les asigna un salario estimado en el rango que se manifiesta. A lo largo del periodo, estas observaciones representan en promedio alrededor de 50.1% de las observaciones totales que no reportan un salario en la ENOE (Gráfica 1). A las observaciones restantes se les realiza la imputación con las variantes del método Hot Deck. Primero, se realiza una imputación perfecta condicionada al siguiente vector de variables sociodemográficas (z): género del individuo, cohorte de edad (12 cohortes), estado civil (soltero o casado), nivel de instrucción completo (sin instrucción, primaria, secundaria, preparatoria y profesional), tipo de ocupación (asalariado, cuenta propia, patrón), trabajador formal, sector de ocupación, trabajo de tiempo completo, área urbana y entidad federativa. La descripción de las variables se presenta en el Anexo 2.

En promedio, con este proceso se logra imputar un salario a 86% de las observaciones que no lo reportan sin incluir a las que se les asignó un ingreso laboral con múltiplos de salarios mínimos. El 14% restante se debe a que existen celdas en las que no existe un donante o un receptor para realizar la imputación. Para solucionar este problema, siguiendo la metodología del BLS (Bollinger y Hirsch, 2006), en una segunda etapa se realiza una imputación imperfecta a las observaciones que no se les pudo asignar un salario en la primera etapa. Esta etapa consiste en seguir la misma metodología propuesta de imputación, pero ampliando las categorías de ciertas variables del vector de variables sociodemográficas. En este caso se agregan los niveles de instrucción en tres categorías: nivel de instrucción bajo, medio y alto. Adicionalmente, se agregan las entidades federativas en tres regiones: norte, centro y sur. Al finalizar este proceso, en promedio 99.8% de las observaciones totales de la muestran cuentan con un salario asignado.
1. Sesgo en las estimaciones
Una vez que se realiza la imputación es importante identificar los sesgos potenciales en estimaciones que no toman en cuenta las observaciones con salario no reportado. Para ello, se estima una ecuación minceriana (Mincer, 1974), en donde la variable dependiente es el logaritmo del salario mensual real; se especifica el modelo con un vector de variables sociodemográficas x, en donde z ⊆ x. Posteriormente, se estima un modelo probit en donde la variable dependiente es una variable dummy donde 1 son todos aquellos individuos que caen en pobreza laboral (de acuerdo con la línea mínima de bienestar determinada por el Consejo Nacional de Evaluación de la Política de Desarrollo Social [Coneval]), y 0 el caso contrario; se especifica el modelo utilizando las variables sociodemográficas incluidas en la ecuación minceriana.7
Es importante notar que, para estimar los errores estándar, se asume que las observaciones son independientes entre sí. Sin embargo, como se realiza una imputación de salarios de un donante a un receptor, tal supuesto no necesariamente se mantiene. Este problema puede ser corregido considerando un remuestreo a través de bootstrap. Este proceso se realizará para la muestra de imputados, y el total de la muestra sumando informantes más imputados. Para la muestra que sólo comprende los ingresos reportados, estimamos errores estándar robustos que nos permiten ponderar por los factores de expansión de las observaciones reportados en las encuestas; de tal manera, la matriz de varianzas y covarianzas estimada es A'VA, donde A es una matriz que corrige el sesgo.8
De forma adicional, y siguiendo a (Bollinger y Hirsch, 2006), se puede sospechar que los coeficientes varían entre trabajadores con diferentes características en el caso de considerar sólo a los que sí reportan un ingreso, dado que, al no ser faltantes aleatorios, la muestra que incluye únicamente observaciones que reportan un salario puede diferir de la muestra total, afectando las estimaciones. Estos autores proponen una corrección muestral basada en un remuestreo de los ponderadores considerando el peso de las observaciones con ingreso faltante y como alternativa a la imputación. Para ello, primero se estima un modelo probit para determinar si contesta o no a la pregunta principal de ingreso, sujeta a una serie de características (en este caso, las características utilizadas para la imputación de ingresos) y, posteriormente, se calcula el inverso de la probabilidad de esta estimación, la cual se utiliza como ponderador en las estimaciones. En nuestro caso sería realizarlo invirtiendo la predicción de la variable dependiente de las estimaciones en el Anexo 1. Las estimaciones con este ponderador para aquellos que reportan ingreso se presentan en la segunda columna del Cuadro 2.
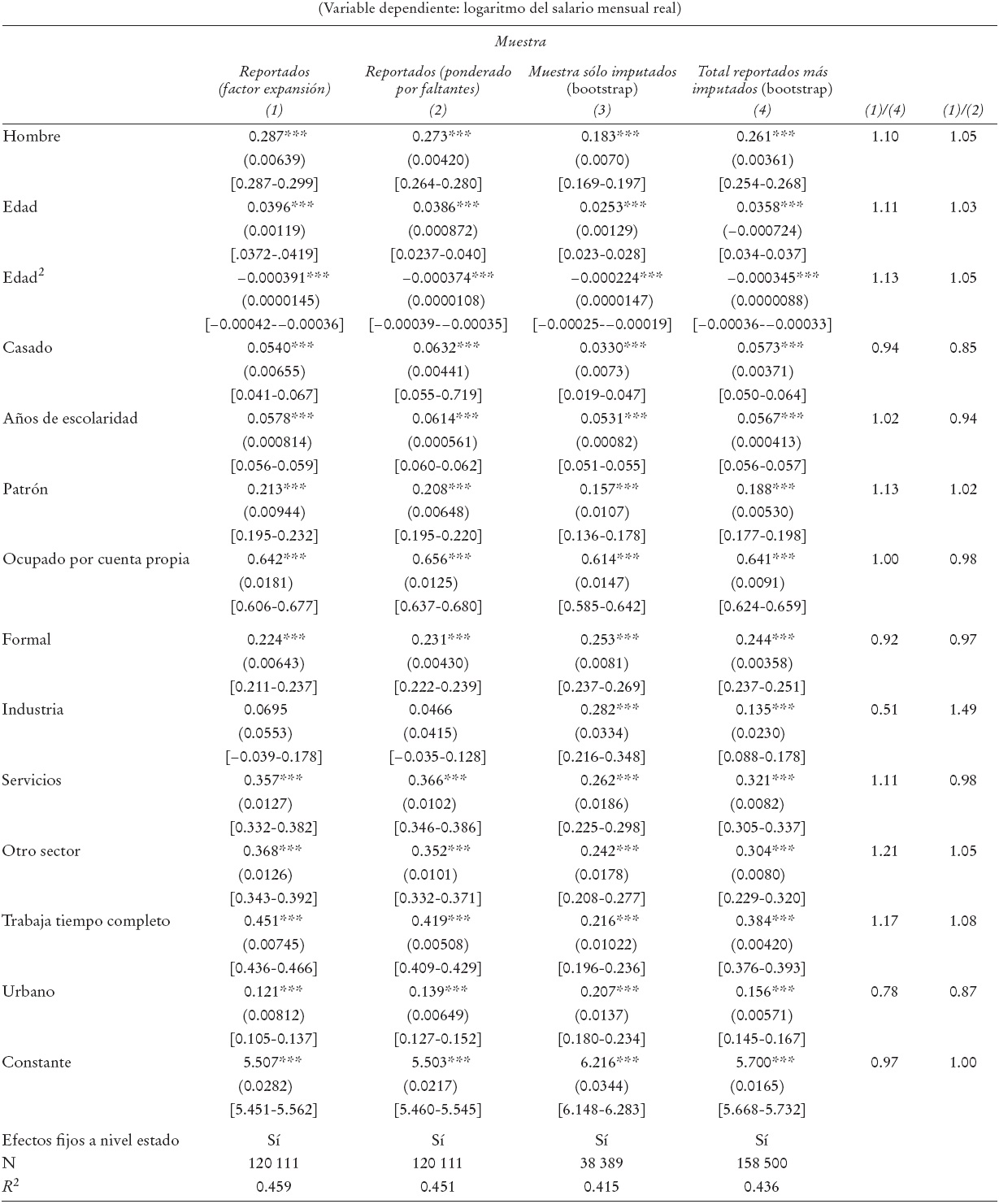
a Errores estándar entre paréntesis; intervalos de confianza a 95% entre corchetes. En (1) y (2) errores estándar robustos; en (1) ponderados por el factor de expansión reportado en la ENOE; en (2) ponderados por el inverso de la probabilidad de reportar ingreso; en (3) y (4) con bootstrap con 500 replicaciones de remuestreo. *** p < 0.01. Categorías base: asalariados, agricultura. Las columnas (3) y (4) consideran las imputaciones mediante el método de Hot Deck con función de distancia de Mahalanobis; los resultados son robustos a las estimaciones considerando el método de Hot Deck con pareamiento aleatorio.
Cuadro 2: Estimaciones de la ecuación minceriana. III de 2012a
El Cuadro 2 muestra los resultados obtenidos de la estimación de la ecuación minceriana para el tercer trimestre de 2012. La columna 1 muestra los resultados obtenidos únicamente con las observaciones que reportan un salario y ponderando con el factor de expansión usual de la ENOE, es decir, como se realizaría de forma común. La columna 2 muestra los resultados para los reportados corregidos con los nuevos ponderadores mencionados anteriormente por ingresos faltantes. La columna 3 muestra los resultados obtenidos sólo para aquellas observaciones con imputaciones, y la columna 4 con toda la muestra, en ambos casos utilizando bootstrap con 500 replicaciones de remuestreo para estimar los errores estándar. En cada estimación se presentan los coeficientes, errores estándar entre paréntesis, y entre corchetes los intervalos de confianza al 95%. Las dos últimas columnas presentan razones entre los estimadores obtenidos para determinar los posibles sesgos.
Para conocer la dirección del sesgo en las estimaciones que no consideran las observaciones con salario no reportado, en la quinta columna se muestra una razón de los parámetros obtenidos entre las observaciones que reportan un salario y la muestra total. Si la razón es mayor a 1, existe un sesgo hacia la derecha, y si la razón es menor a 1, entonces existe un sesgo hacia la izquierda.9 En general, como se puede observar en el cuadro, existe un sesgo hacia la derecha cuando no se consideran las observaciones que no reportan un salario. La segunda columna muestra los parámetros obtenidos con la ponderación por remuestreo con base en la muestra que reporta un salario; en general presentan coeficientes dentro del rango de las estimaciones obtenidas con la muestra que reporta un salario y la muestra total que incluye las observaciones con salario imputado. Esto es similar a los resultados obtenidos en (Bollinger y Hirsch, 2006), aunque en algunos casos, los resultados son mayores a ese rango, como en el del coeficiente de educación.
Ahora bien, por cuestión de espacio, el cuadro anterior muestra sólo un periodo como ejemplo, pero es importante identificar el sesgo en las estimaciones a lo largo del tiempo. Para ello, en las siguientes subsecciones, se analizan dos variables como ejemplo de interés ampliamente estudiadas para el caso de México: retornos a la educación y premio a la formalidad, y sus efectos sobre salarios y pobreza laboral.
2. Retornos a la educación
Los retornos a la educación han sido ampliamente estudiados en México (p. ej. Psacharopoulos et al., 1996; Bracho y Zamudio, 1994; López-Acevedo, 2001; Rodríguez-Oreggia, 2014); sin embargo, ninguno de estos estudios considera el sesgo potencial en las estimaciones por no incluir las observaciones con salario no reportado. En la Gráfica 3 se muestran los retornos a la educación por trimestres en México de 2005 a 2013, medidos como el porcentaje de retorno promedio por cada año adicional de educación. Se incluyen los resultados obtenidos con la muestra que reporta un salario (con ambas ponderaciones), y con la muestra total.10 Para que los resultados sean robustos a la imputación se incluyen los resultados obtenidos con los dos criterios de imputación Hot Deck propuestos; además se calculan los intervalos de confianza al 95% en cada caso.
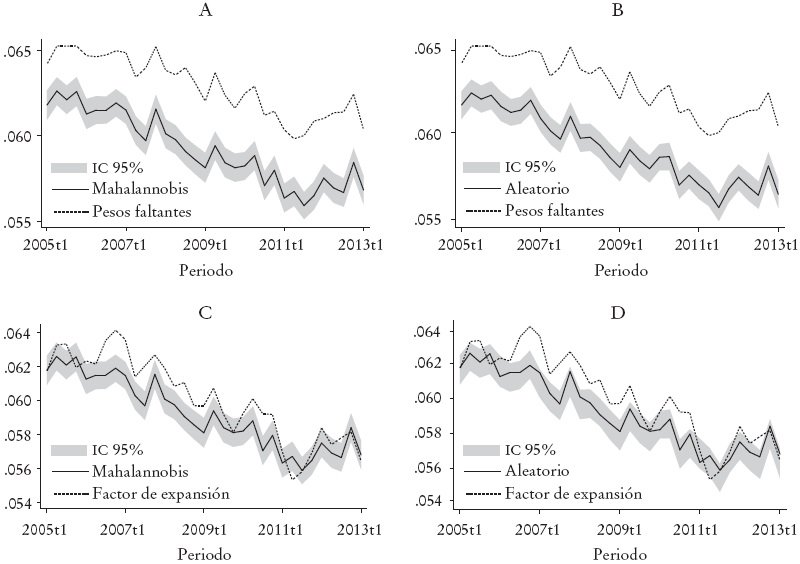
* Intervalos de confianza a 95%. Se incluyen los resultados obtenidos con los dos criterios de impu tación (HD-A: Hot Deck con imputación aleatoria; HD-M: Hot Deck con función de distancia de Mahalanobis), en ambos casos los errores estándar se calcularon utilizando bootstrap con 500 replicaciones de remuestreo; así como la muestra sólo reportada ponderada por ingresos faltantes y la reportada con factor de expansión de la ENOE. Se controló por género, experiencia laboral y su cuadrado, estado civil, tipo de ocupación, formalidad, sector, trabajo de tiempo completo, área urbana y entidad federativa. En los paneles A y B se compara las estimaciones de la muestra total considerando ambos métodos de imputación con las estimaciones utilizando los pesos faltantes. En los paneles C y D se compara las estimaciones de la muestra total considerando ambos métodos de imputación con las estimaciones utilizando el factor de expansión resportado en la ENOE.
Gráfica 3: Retornos a la educación*
Como se puede observar en la Gráfica 3, en promedio, para todos los periodos analizados a mayor educación mayor salario, aunque existe una caída de los retornos en el tiempo. Es importante notar que las estimaciones de los retornos a la educación tienen un sesgo cuando no se incluyen las observaciones que no reportan un salario, aunque para el caso de los paneles C y D (cuando se comparan las estimaciones con imputación por ambos métodos con las estimaciones considerando factores de expansión) el sesgo no es necesariamente significativo para todos los periodos. No obstante, en general se puede decir que no incluir a las observaciones con salario no reportado podría generar sobreestimaciones en los retornos a la educación. Para este caso, la diferencia es más notoria cuando se consideran los pesos faltantes.
En la Gráfica 4 se muestran los efectos promedio de la educación sobre la pobreza laboral para cada trimestre de 2005 a 2013.11 Como se observa en los cuatro paneles de la gráfica (A, B, C y D), considerar únicamente las observaciones con salario reportado genera una subestimación en la magnitud del coeficiente de la educación sobre la pobreza laboral. El efecto promedio de la educación sobre la pobreza laboral es sustancialmente más bajo cuando no se considera la muestra total, aun con ambos tipos de ponderadores; incluso para ciertos periodos es no significativo. En cambio, para la muestra completa con ingresos imputados, la dirección del efecto de educación sobre la pobreza laboral está claramente de acuerdo con la teoría para todos los periodos, es decir, mayor educación reduce la probabilidad de caer en pobreza laboral; los resultados son robustos a ambos criterios de imputación.

* Intervalos de confianza a 95%. Se incluyen los resultados obtenidos con los dos criterios de impu tación (HD-A: Hot Deck con imputación aleatoria; HD-M: Hot Deck con función de distancia de Mahalanobis), en ambos casos los errores estándar se calcularon utilizando bootstrap con 500 replicaciones de remuestreo; así como la muestra sólo reportada ponderada por ingresos faltantes y la reportada con factor de expansión de la ENOE. Se controló por género, experiencia laboral y su cuadrado, estado civil, tipo de ocupación, formalidad, sector, trabajo de tiempo completo, área urbana y entidad federativa. En los paneles A y B se compara las estimaciones de la muestra total considerando ambos métodos de imputación con las estimaciones utilizando los pesos faltantes. En los paneles C y D se compara las estimaciones de la muestra total considerando ambos métodos de imputación con las estimaciones utilizando el factor de expansión resportado en la ENOE.
Gráfica 4: Efecto de la educación sobre probabilidad de caer en pobreza laboral*
De los resultados se concluye que en general, a mayor educación menor probabilidad de caer en pobreza laboral, considerando que los resultados son más consistentes utilizando la muestra completa con imputaciones. Esto es, la probabilidad estimada es más consistente en términos teóricos e intuitivos si se considera la muestra total que incluye las observaciones imputadas por salario no reportado.
3. Formalidad
La formalidad laboral es un tema amplio de estudio, sobre todo por su impacto en la productividad laboral y por sus implicaciones en la provisión de beneficios por seguridad social. En México, alrededor de dos tercios de los trabajos se encuentran en el sector informal de la economía y tienen un impacto muy bajo en la productividad de los trabajadores (Rodríguez-Oreggia, 2007 y 2010). En este sentido, para el caso de México es importante identificar el efecto de la formalidad en los trabajos sobre los salarios o sobre la pobreza laboral. En la Gráfica 5 se pueden observar los premios salariales a la formalidad laboral, medida como acceso a seguridad social por el trabajo, del primer trimestre de 2005 al primer trimestre de 2013, reportados en la ENOE. Como se puede observar en la gráfica, los premios salariales a la formalidad son positivos y elevados. En promedio, un trabajador formal gana 24.1% más que un trabajador informal.
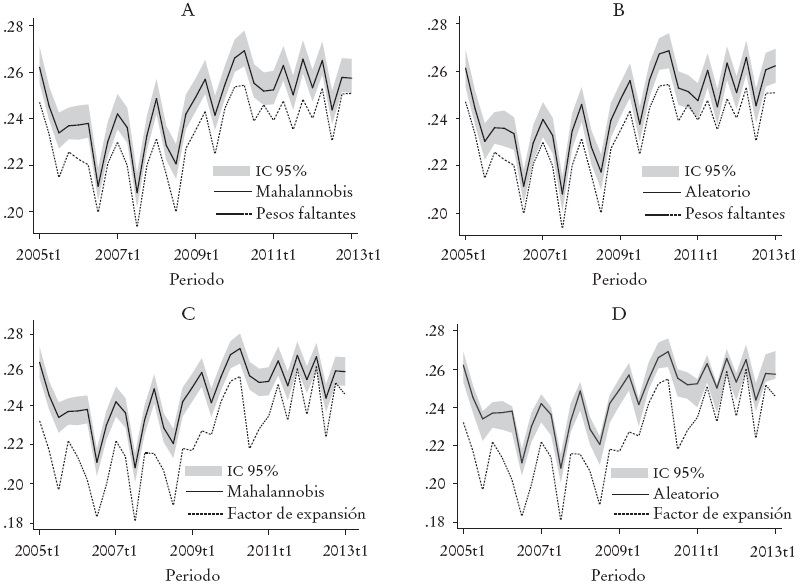
* Intervalos de confianza a 95%. Se incluyen los resultados obtenidos con los dos criterios de imputación (HD-A: Hot Deck con imputación aleatoria; HD-M: Hot Deck con función de distancia de Mahalanobis), en ambos casos los errores estándar se calcularon utilizando bootstrap con 500 replicaciones de remuestreo; así como la muestra sólo reportada ponderada por ingresos faltantes y la reportada con factor de expansión de la ENOE. Se controló por género, experiencia laboral y su cuadrado, estado civil, tipo de ocupación, formalidad, sector, trabajo de tiempo completo, área urbana y entidad federativa. En los paneles A y B se compara las estimaciones de la muestra total considerando ambos métodos de imputación con las estimaciones utilizando los pesos faltantes. En los paneles C y D se compara las estimaciones de la muestra total considerando ambos métodos de imputación con las estimaciones utilizando el factor de expansión resportado en la ENOE.
Gráfica 5: Premio salarial a la formalidad*
Sin embargo, es importante identificar el sesgo de los premios salariales a la formalidad al no considerar las observaciones con salario faltante. En la Gráfica 5 se pueden observar los premios salariales a la formalidad considerando las observaciones con salario reportado y el total de observaciones, e incluyendo aquellas con salario imputado. Como se puede observar en la Gráfica 5 (paneles A, B, C y D) existe una subestimación consistente en el tiempo del premio salarial cuando no se consideran las observaciones con salario no reportado comparado con las estimaciones considerando pesos faltantes y factores de expansión. No obstante, es importante notar que la subestimación es menor cuando se consideran los pesos faltantes (paneles A y B). Los resultados son robustos a ambos criterios de imputación.
Finalmente, en la Gráfica 6 se muestran los coeficientes de la formalidad laboral sobre la pobreza laboral. Como se puede observar, la formalidad laboral tiene un efecto promedio negativo sobre la pobreza laboral. Es decir, los trabajadores formales tienen menor probabilidad de caer en pobreza laboral comparado con los trabajadores informales.
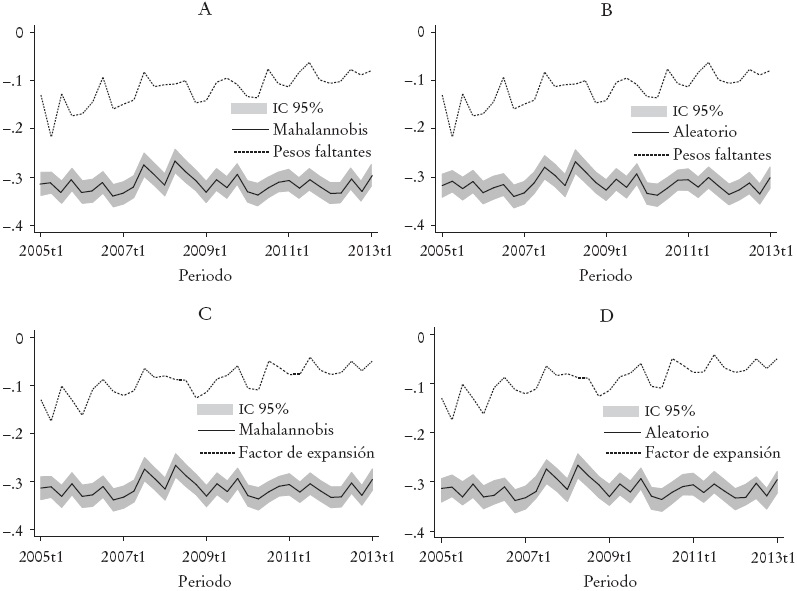
* Intervalos de confianza a 95%. Se incluyen los resultados obtenidos con los dos criterios de imputación (HD-A: Hot Deck con imputación aleatoria; HD-M: Hot Deck con función de distancia de Mahalanobis), en ambos casos los errores estándar se calcularon utilizando bootstrap con 500 replicaciones de remuestreo; así como la muestra sólo reportada ponderada por ingresos faltantes y la reportada con factor de expansión de la ENOE. Se controló por género, experiencia laboral y su cuadrado, estado civil, tipo de ocupación, formalidad, sector, trabajo de tiempo completo, área urbana y entidad federativa. En los paneles A y B se compara las estimaciones de la muestra total considerando ambos métodos de imputación con las estimaciones utilizando los pesos faltantes. En los paneles C y D se compara las estimaciones de la muestra total considerando ambos métodos de imputación con las estimaciones utilizando el factor de expansión resportado en la ENOE.
Gráfica 6: Efecto de la formalidad sobre probabilidad de caer en pobreza laboral*
De los resultados se puede observar claramente una subestimación del efecto promedio de la formalidad sobre la probabilidad de caer en pobreza laboral cuando no se considera la muestra total; la probabilidad de caer en pobreza laboral es aún menor cuando las estimaciones se realizan con la muestra total considerando las observaciones con salario imputado. Los resultados también son robustos a ambos métodos de imputación.
En general, se puede afirmar que existe una amplia diferencia entre resultados tanto en niveles de pobreza laboral como en estimaciones derivadas del análisis laboral involucrando sólo ingresos reportados, comparado con aquellas estimaciones que incluyen las observaciones con ingresos imputados. Las implicaciones parecen ser claras respecto al uso de la información de ingreso derivado de la ENOE: pareciera que el uso de imputación de ingresos puede ayudar a identificar mejor los efectos de determinadas variables sobre ingreso y pobreza laboral y, por ende, a focalizar mejor a grupos vulnerables (véase por ejemplo Rodríguez-Oreggia, López-Videla y Prudencio, 2013). Sin embargo, la selección del modelo con correcciones siempre depende de los datos que se tienen, así como del objetivo de cada investigación, pero siempre considerando algún método de corrección (para una discusión véase Bollinger y Hirsch, 2006). Lo que queda claro es que ignorar los ingresos no reportados conlleva a un sobrerreporte en el cálculo de los que caen en pobreza laboral, lo cual tiene implicaciones en estimaciones que involucran a esta variable.
Conclusiones
Las respuestas faltantes, sobre todo en ingresos, han sido materia de análisis en diversos países, especialmente en Estados Unidos. No obstante, en México ya se empieza a considerar el efecto potencial que puede tener este problema sobre indicadores de política pública, en especial sobre mediciones de la pobreza laboral (véanse Rodríguez-Oreggia et al., 2012, y Campos-Vázquez, 2013). En este artículo se ha buscado analizar el método de imputación de ingresos para la ENOE bajo dos variantes y sus efectos sobre estimaciones de capital humano, así como indicadores basados en estos datos, tales como pobreza laboral. En una primera etapa, se presentan los métodos de imputación con base en la secuencia de preguntas de ingreso de la ENOE. En seguida, se analizan los resultados de la imputación sobre ecuaciones mincerianas y sobre la probabilidad de caer en pobreza laboral comparándolos con los resultados ponderados que sólo incluyen en la muestra observaciones con ingreso reportado.
En general, se muestra que, al no considerar las observaciones con ingresos faltantes en la ENOE, el nivel de las estimaciones de pobreza laboral está sobreestimado. Adicionalmente, al comparar las estimaciones que incluyen la muestra con ingresos no reportados con las estimaciones, que incluyen únicamente la muestra con ingresos reportados, se detectaron sesgos en las estimaciones de capital humano y de pobreza laboral. Los retornos a la educación serían un poco más bajos al considerar la muestra imputada, alrededor de medio punto porcentual, pero mayor si se corrige muestralmente, tomando en cuenta que para el primer caso el sesgo no necesariamente es significativo para todos los periodos. El uso de la muestra imputada permite también obtener cálculos más consistentes sobre el efecto de la educación en la reducción de la pobreza laboral. También hay un efecto mayor de la formalidad en evitar caer en pobreza laboral al utilizar esta muestra. Además, se presentaron los resultados que utilizan una corrección muestral basada en ponderadores de peso por los que reportan efectivamente un ingreso laboral en la encuesta.
Las implicaciones en términos de políticas públicas se deriva de la identificación de los efectos de variables asociadas ya sea al ingreso laboral o a la pobreza laboral, y que permitiría una mejor focalización y un mayor impacto al establecer programas públicos enfocados en reducir la vulnerabilidad y/o aumentar ingresos. Los resultados sugieren que el uso de imputaciones en el ingreso para el caso de la ENOE merece una discusión académica seria y un replanteamiento en el cálculo de indicadores que utilicen esta variable por parte de organismos gubernamentales.