nova página do texto(beta)
nova página do texto(beta) Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
PermalinkClasificación JEL: D31, D63, I32.
Introducción
Tal y como la bibliografía del crecimiento propobre ha puesto de manifiesto, los cambios en la pobreza presentada en un territorio económico no dependen sólo de la variación de la renta per capita, sino también de la evolución de la desigualdad (véase, por ejemplo, Kakwani, 2000; Ravallion y Chen, 2003; Son, 2004, o Kakwani, 2008). Este razonamiento puede ser extendido al análisis de las diferencias en pobreza que se puedan dar entre dos diferentes territorios en el mismo periodo: dichas diferencias dependerán no sólo de la diferencia en renta media sino también de la distinta distribución de dicha renta. En este sentido, puede ser interesante analizar hasta qué punto distintas tasas de pobreza vienen dadas por la brecha del ingreso entre las dos economías analizadas. En otras palabras, cabe preguntarse: si el país (o la región) A tuviese la misma renta media que el país B, ¿mostraría la misma pobreza?
Este trabajo desarrolla un instrumento para dicho análisis apoyándose en la dominancia estocástica. Cuando se emplea un determinado índice de pobreza para realizar un análisis como el citado pueden surgir varios problemas. En efecto, todo índice de pobreza implica ciertos juicios de valor que no siempre son bien conocidos (Sen, 1973) ni unánimes (esto es conocido como el problema de la multiplicidad de índices Bishop y Formby, 1994). El enfoque de la dominancia estocástica ofrece una solución a este problema. Si se acepta un pequeño conjunto de juicios de valor (el principio de anonimidad de Pareto y el de transferencias de Pigou-Dalton) se puede ordenar distribuciones de renta en función del bienestar económico asociado a ellas con resultados no ambiguos. Además, es importante tener en cuenta que los análisis de pobreza y desigualdad se efectúan en la mayoría de los casos con datos muestrales. Para solventar este problema, en este trabajo se utiliza inferencia estadística a partir de la prueba de Bishop, Formby y Thistle (1989) y se desarrolla las varianzas necesarias para realizar esta prueba en el contexto del análisis.
El artículo se divide en tres secciones. En la primera se analiza el marco teórico empleado y se desarrolla una nueva descomposición de las ordenadas de la curva de Lorenz generalizada. La sección II repasa la bibliografía reciente de la pobreza y desigualdad en España y sus regiones. Finalmente, los resultados obtenidos se aplican a las regiones españolas, empleando para ello los datos de la Encuesta de Condiciones de Vida referentes a 2003 y 2007. Se cierra el artículo con las conclusiones.
1. Dominancia estocástica de segundo orden (dominancia generalizada de Lorenz)
Los instrumentos desarrollados en este artículo para medir la naturaleza propobre del crecimiento económico tienen sus raíces en la dominancia estocástica de segundo orden, por lo que en este punto se introduce brevemente esta técnica. El conocido teorema de Atkinson (1970) de dominancia de Lorenz, extendido por Dasgupta, Sen y Starret (1973), es aplicable tan sólo a los casos en los que las medias de las dos distribuciones comparadas son iguales. Sin embargo, como apuntó Sen (1973), esta restricción se cumplirá en contadas ocasiones. Shorrocks (1983) resuelve este problema introduciendo la curva de Lorenz generalizada.
Sea X(u) la inversa de la función de distribución de la renta y la media de dicha distribución. Según Gatswirth (1971), la curva de Lorenz puede ser definida como:
 (1)
(1)
y la curva de Lorenz generalizada será (Shorrocks, 1983):
 (2)
(2)
Sea Ws una función (de bienestar social) S concava y creciente. Se llega entonces al siguiente teorema, demostrado por Shorrocks (1983):
GL Dominancia:
Las implicaciones de este teorema son inmediatas: si se considera dos supuestos ampliamente aceptados como son el principio de Pareto (a mayor renta mayor bienestar económico) y el principio de transferencias de Pigou-Dalton (una transferencia de un individuo a otro con menor renta que no revierta el orden de rentas aumenta el bienestar), se puede ordenar el bienestar asociado a dos distribuciones de ingreso.
2. Dominancia truncada de segundo orden y pobreza
Foster y Shorrocks (1988) relacionan la dominancia de segundo orden y la pobreza. Para ello parten del índice conocido como brecha de pobreza:
 (3)
(3)
en el que r es el estadístico ordenado que corresponde a la línea de
pobreza, z, y xi denota la renta
del i-ésimo individuo. De acuerdo con la dominancia truncada,
la distribución X dominará a la distribución
Y, algo que se puede escribir como
Esto implica que si se trunca la distribución para una determinada línea de pobreza
3. Efecto desigualdad y efecto renta media
La pregunta que se quiere responder en este análisis es: si una región A tuviese la misma renta media ¿que otra región B tendría la misma pobreza, más o menos?
Supóngase que se parte de dos regiones, A y B, cuyas curvas de Lorenz generalizadas se pueden representar como:
 (4)
(4)
Como se muestra en la expresión (4), las diferencias en las ordenadas de las curvas de Lorenz generalizadas se deben a diferencias en μ (diferencias en renta media), en L(p) (diferencias en desigualdad) o a una conjunción de ambos factores. A partir de una serie de axiomas, Kakwani (2000) descompone el cambio de un índice cualquiera de pobreza entre dos periodos en dos partes: la que se debe al cambio en la renta media y la que se debe al cambio en la desigualdad del ingreso. Este enfoque puede ser modificado para emplearse en el caso que nos ocupa, es decir, para el análisis transversal con curvas de Lorenz generalizadas, llegándose a la siguiente descomposición:
 (5)
(5)
 (6)
(6)
siendo:
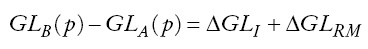 (7)
(7)
La ecuación (7) descompone la diferencia entre las ordenadas de las curvas de Lorenz generalizadas de las dos regiones en dos partes: una debida al efecto distribución (que mide el efecto que tiene la distinta distribución del ingreso en dicha diferencia) y otra que se debe al efecto renta media (que mide el efecto de la diferencia en renta media entre ambas regiones). La curva de Lorenz generalizada de la región B que tiene en cuenta la diferencia en desigualdad entre las dos regiones se puede escribir como:
 (8)
(8)
Es interesante observar que (8) muestra las diferencias que se dan entre las dos regiones debido a la diferencia en la desigualdad, medida por medio de la curva de Lorenz, que hay entre las mismas. Las consecuencias de dicha expresión en la pobreza y el bienestar económico son equivalentes a las que se han visto en la subsección anterior, algo que podemos formular en el siguiente teorema:
Teorema: Si
4. Aplicación de la inferencia estadística
El teorema que se acaba de obtener ofrece un instrumento interesante para estudiar el efecto de la desigualdad en las diferencias en pobreza y/o bienestar que se dan entre distintas regiones o países. Sin embargo, es importante considerar que al emplear datos muestrales se pueden cometer errores de muestreo que lleven a conclusiones erróneas. Por este motivo, la inferencia estadística puede desempeñar un papel importante en el análisis, por lo que en este punto se deriva la varianza de las ordenadas de la curva generalizada de Lorenz que se construye teniendo en cuenta el efecto desigualdad.
La prueba que se va a emplear se puede formular como:

 (9)
(9)
La hipótesis nula implica que el efecto desigualdad no tiene ningún efecto en las diferencias en el bienestar asociado a la renta entre las distribuciones analizadas. Si dicha hipótesis es rechazada, se tienen cinco posibles resultados:
Dominancia de Lorenz generalizada débil: si para algunos cuantiles
Dominancia de Lorenz generalizada fuerte: si para todo i
La curva de Lorenz generalizada se corta: para algunos cuantiles
Si
Por último, si
El estadístico de prueba será:
 (10)
(10)
La distribución de
II. Pobreza y desigualdad en españa
La bibliografía centrada en la evolución de la desigualdad y la pobreza en España es extensa, si bien ofrece interesantes puntos de encuentro. Desde el punto de vista territorial se puede citar el trabajo de Ayala, Jurado y Pedraja (2006), quienes emplean la Encuesta Básica de Presupuestos Familiares (EBPF) de los años 1973, 1980, 1990 y la Encuesta Continua Presupuestos Familiares (ECPF, 2000) longitudinal anualizada. Las principales conclusiones que alcanzan estos autores son las siguientes:
Existen, para cualquiera de los índices empleados, diferentes grupos de comunidades autónomas en función de la desigualdad que existen en las mismas. Así, regiones como Navarra, País Vasco, Murcia y Castilla La Mancha muestran menor desigualdad que la media de España, mientras que otras, como Andalucía, Canarias, Cantabria y Madrid presentan una desigualdad más alta, si bien, "salvo en el caso de Andalucía, los indicadores son sólo un poco más altos que los del conjunto nacional" (Ayala, Jurado y Pedraja, 2006, p. 13).
Las diferencias en la desigualdad intraterritoral explican cada vez más parte de la desigualdad total.
Por su parte, Ahamdanech, García y Prieto (2010) estudian la convergencia en distribuciones de renta para el periodo 1990-1991, con la Encuesta de Presupuestos Familiares (EPF) y 2003, con la nueva Encuesta de Condiciones de Vida (ECV). Una de las conclusiones alcanzadas es que, desde el punto de vista de la desigualdad, se puede distinguir básicamente entre dos grupos de regiones en 2003: aquellas con menor desigualdad que la que se presenta en España, entre las que se encuentran Aragón, Cataluña, Cantabria, el País Vasco o Madrid. Por otra parte, existe un grupo de regiones en las que la desigualdad es más pronunciada, como las Castillas, Andalucía o Extremadura.
Sin embargo, esta pauta de comportamiento, válida hasta mediados del primer decenio del siglo XXI, parece haber cambiado. Como apunta el informe Foessa (2008) que analiza la distribución de la renta entre 1994 y 2007 en las regiones españolas, existen regiones españolas con menor renta media y menor desigualdad que la media, como Murcia o Castilla La Mancha, mientras que otras con una renta media superior, como Cantabria o Madrid, muestran mayor desigualdad.
1. Datos
La disponibilidad de datos para estudios de carácter regional en España ha sido limitada, pues desde la Encuesta de Presupuestos Familiares (EPF) de 1991 y hasta la aparición de la ECV en 2004 no ha habido ninguna encuesta que recabe datos de renta con fiabilidad, a excepción de la muestra ampliada del Panel de Hogares de la Unión Europea (PHOGE) de 2000. Este trabajo se basa en los datos de la ECV de 2004 y 2008, referidas a los años 2003 y 2007, respectivamente.
Para el estudio se ha buscado una aproximación al poder adquisitivo de los individuos, por medio de una medida comprensiva de la renta, que incluya las transferencias y deduzca los impuestos y las contribuciones a la seguridad social. Asimismo, se ha considerado que todos los individuos del mismo hogar disfrutan del mismo bienestar económico. A tal fin, se ha empleado la renta por hogar dividida por la escala de equivalencia de la OCDE modificada, pero teniendo en cuenta el número de individuos por hogar a la hora de estimar las medidas de pobreza. Es decir, para cada región y para España, se construye una distribución de la renta personal de manera que cada hogar recibe una ponderación que considera el número de sus miembros. En consecuencia, los datos de rentas, procedentes del fichero de hogares de la encuesta, se han ponderado utilizando los pesos correspondientes al hogar debidos a la elaboración de la encuesta y el número de miembros por hogar. Por último, las rentas han sido deflacionadas con el IPC regional publicado por el INE.
2. Resultados
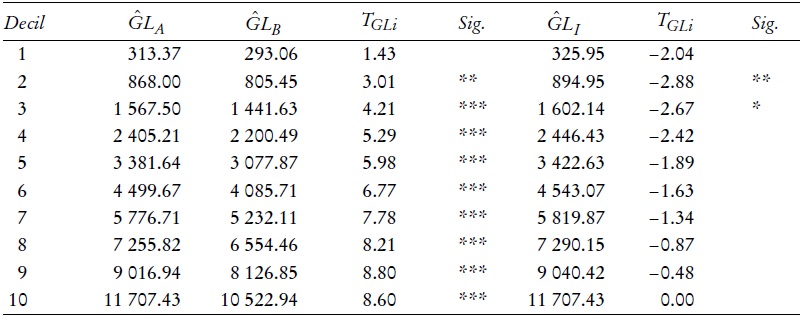
En este artículo se intenta medir la influencia de las diferencias en desigualdad entre las regiones en los distintos niveles de pobreza. A modo de ejemplo, el Cuadro 1 muestra los resultados de la aplicación de la prueba desarrollada para la comparación de Andalucía y España en 2003 (en el apéndice se muestra los cuadros para todas las regiones).

Cuadro 1 Dominancia generalizada de Lorenz y dominancia con efecto desigualdad. España-Andalucía (2003).
Las columnas 2 y 3 del Cuadro 1 recogen las ordenadas de las curvas generalizadas del Lorenz para el conjunto nacional y Andalucía, respectivamente, mientras que en las columnas 4 y 5 se presenta el estadístico de contraste (para el análisis inferencial de las diferencias de las ordenadas generalizadas de Lorenz) y su significatividad. En la columna 6 se muestra el valor de las ordenadas de la curva generalizada de Lorenz de Andalucía que se construye a partir de la distribución de España teniendo en cuenta sólo el efecto distribución; las columnas 7 y 8 muestran el valor del estadístico de prueba y su significación, respectivamente.2 Como se infiere del Cuadro 1, el bienestar económico asociado a la renta fue en España superior al de la región de Andalucía para 2003. Sin embargo, si se aísla el efecto renta media se llega a la conclusión de que las dos distribuciones comparadas son estadísticamente equivalentes. En otras palabras, si se tiene sólo en cuenta la desigualdad, la pobreza y el bienestar asociado a la renta serían iguales en Andalucía y en España. Las Gráficas 1 y 2 muestran las diferencias entre ambos casos.


Gráfica 2 Curva generalizada de Lorenz para España y curva generalizada de Lorenz con efecto desigualdad para Andalucía.
Como se observa en el Cuadro 2, que muestra el resumen de los resultados para 2003, en la mayor parte de las regiones en las que el bienestar asociado a la distribución del ingreso es mayor (menor) que en el conjunto de España, el efecto desigualdad contribuyó a ese mayor (menor) bienestar. Sin embargo, en algunas comunidades este no fue el caso. En Baleares el bienestar asociado a la distribución de la renta fue superior al del conjunto de España, pero si se considera sólo el efecto desigualdad (es decir, se aísla el efecto renta media) la situación es la opuesta (España domina en segundo orden a Baleares). En Canarias, Castilla-León y Galicia se da el caso contrario, mientras que Castilla La Mancha y Navarra, si se tiene en cuenta el efecto desigualdad, resultan no comparables con el conjunto nacional. Nótese que estos resultados están en línea con lo que se vio en la sección II, es decir, redundan en la existencia de una cierta relación inversa entre renta media y desigualdad. Por su parte, el Cuadro 3 muestra los resultados para 2007

a El primer signo en cada celda se refiere a la comparación descriptiva mientras que el segundo a la comparación con inferencia. "+" significa dominancia de España sobre la región, "-" de la región sobre España, "X" indica un cruce y ":" que no hay diferencias estadísticamente significativas.
Cuadro 2 Resumen de la dominancia de Lorenz generalizada y dominancia sólo con efecto desigualdad (2003).a

a El primer signo en cada celda se refiere a la comparación descriptiva mientras que el segundo a la comparación con inferencia. "+" significa dominancia de España sobre la región, "-" de la región sobre España, "X" indica un cruce y ":" que no hay diferencias estadísticamente significativas.
Cuadro 3 Resumen de la dominancia de Lorenz generalizada y dominancia sólo con efecto desigualdad (2003).a
Como se ve la relación mayor renta media-menor desigualdad que se ha dado en los decenios recientes en las regiones españolas comienza a mostrarse menos clara. En efecto, si se mira, por ejemplo, Madrid, Extremadura o Murcia se observa que la relación de dominancia (en uno u otro sentido) que se da cuando se considera la dominancia de Lorenz generalizada se altera cuando se aísla el efecto desigualdad, hecho que se puede confirmar analizando los cuadros del apéndice. En los tres casos citados, cabe destacar que la evolución del empleo ha sido diferente: mientras que en la comunidad de Madrid apenas se redujo 1% entre 2003 y 2007, en Extremadura y Murcia lo hizo 4 y 3%, respectivamente.3 Por tanto, la evolución del empleo parece tener una importancia en la distribución del aumento de la renta media, aunque esta es una conclusión muy preliminar que debe ser contrastada considerando otra serie de factores, como los procesos de inmigración y la distribución funcional del ingreso.
Conclusiones
En este artículo se ha introducido una técnica para descomponer las diferencias en bienestar económico y pobreza entre dos regiones en efecto desigualdad y efecto renta media, es decir, para estudiar qué parte de la diferencia en pobreza se debe a diferencias en desigualdad y qué parte a diferencias en la renta media. La principal ventaja de este instrumento, además de las propias de la dominancia estocástica, es la posibilidad de introducir la inferencia estadística en el análisis, lo que lleva a resultados más precisos al evitar los problemas de errores de muestreo.
Desde el punto de vista empírico, se ha visto que, si bien en 2003 en general en las regiones con mayor bienestar económico (y menor pobreza) que en España el efecto desigualdad contribuyó a este hecho, esta pauta parece estar cambiando tal y como muestran los resultados obtenidos para 2007. La evolución del empleo puede tener mucha relación en dicho cambio, con las consecuencias de política económica que este hecho llevaría aparejadas. Sin embargo, un análisis en mayor profundidad y que considere otros factores podría añadir luz en las causas que subyacen a este cambio en la dinámica de la distribución de la renta en las regiones españolas.