











 nova página do texto(beta)
nova página do texto(beta) Espanhol (pdf)
Espanhol (pdf)
 Artigo em XML
Artigo em XML Referências do artigo
Referências do artigo
 Enviar este artigo por email
Enviar este artigo por email Citado por SciELO
Citado por SciELO  Similares em
SciELO
Similares em
SciELO 
 Permalink
PermalinkClasificación JEL: G.
Introducción
Este artículo analiza la capacidad de las redes neuronales para predecir el signo de las variaciones mensuales de la economía de México, usando como insumos tanto el suavizamiento con junto como la proyección predictiva de dicho suavizamiento realizados con un proceso gaussiano bidimensional que, al integrar simultáneamente -tanto en el suavizamiento como en la proyección- a un índice de bonos soberanos con uno de acciones -ambos representativos del mercado de capitales - , proporciona a la red de los dos insumos (suavizamiento y proyección) que ésta requiere para predecir la tendencia futura (al alza o la baja) del índice compuesto (LEI) de México, considerado como un índice coincidente y no adelantado de la economía. La comparación por medio del método de Anatolyev y Gerko -desarrolla do para evaluar la precisión de un predictor- de los resulta dos obtenidos en este trabajo, con los de redes análogas desarrolladas con el mismo fin por dos de los autores del presente artículo en un trabajo anterior (Trigo y Costanzo, 2007), cuyos insumos son rezagos y promedios móviles de dichos índices, mostró que en este caso la metodología que incorpora procesos gaussianos en el preprocesamiento de los datos es mejor que la basada en rezagos. Para la aplicación tanto del presente artículo como del citado líneas arriba se utilizaron las mismas redes neuronales de alimentación frontal con algoritmo de aprendizaje de percolación reversa (una optimación del algoritmo de aprendizaje de propagación reversa). La evaluación de ambas metodologías se hizo sobre la base de conjuntos extramuestrales compuestos por un porcentaje fijo (10%) los datos totales. El desempeño relativo de las redes tanto en el artículo anterior como en el presente fue medido en términos de la suma de la magnitud de los movimientos del índice LEI, LEI, cuyos signos fueron predichos correctamente por éstas, suponiendo implícitamente para ello que el índice de actividad económica era "comerciable" y evaluando el resultado con la prueba estadística de precisión en el acierto direccional y magnitudinal de Anatolyev y Gerko (2005). Los resultados obtenidos mostraron que la capacidad predictiva de la red neuronal alimentada con datos provenientes del mercado de capitales preprocesados por un método gaussiano bidimensional es superior a la capacidad predictiva de redes similares alimentadas con los mismos datos preprocesados con rezagos y promedios móviles. En suma, el uso de procesos gaussianos para preprocesar los datos que reflejan el movimiento de los mercados de capitales, hace a la red que utiliza este insumo más apta para predecir el desempeño de la economía que las que utilicen los mismos datos preprocesados con métodos tradicionales.
El método más conocido para predecir los ciclos de negocios es el índice LEI o Composite Index of Leading Economic Indicators, índice de índole lineal que ha predicho cada una de las ocho últimas recesiones en los Estados Unidos. Este índice, publicado por el Conference Board para los Estados Unidos. y México entre otros, se compone de 10 índices económicos: horas promedio trabajadas a la semana por obreros de producción en industrias manufactureras; número promedio de reclamaciones de seguro de desempleo; nuevas órdenes de los manufactureros para bienes de consumo; velocidad relativa en que vendedores pueden entregar pedidos a compañías industriales, según el índice del National Association of Purchasing Managers; nuevas órdenes recibidas por manufactureros en bienes de capitales no relacionados con la defensa; número de permisos concedidos para edificios residenciales; cambio en el mercado de acciones; provisión monetaria M2 (ajustada por inflación); la dispersión del rendimiento, y el índice de expectativas del consumidor.
Es muy conocido que, según la percepción de muchos operadores financieros exitosos, el rendimiento histórico de los mercados de acciones y bonos puede ser utilizado para predecir el rendimiento futuro de los mismos. Se puede ir aún más allá al afirmar que dicho rendimiento histórico puede ser también utilizado para predecir el movimiento futuro de otros índices económicos relevantes que acompañan a estos dos mercados en la composición del LEI. Esto induce a pregunta por qué y en qué medida en los Estados Unidos esos cambios históricos en los mercados de acciones y de bonos soberanos se corresponden con -y permiten predecir- los cambios en las estadísticas que influyen directamente en el crecimiento o la contracción económicas, como son los índices de ventas, sueldos, ingresos por impuestos y gastos de capital. Para explicar este efecto se recurre a dos argumentos. El primero es que los mercados de capitales (equity & debt) son la principal fuente de financiación de la economía y en esta capacidad actúan como estimulantes. El segundo recurre a una metáfora de las finanzas o comporta-mentalistas, según la cual en las economías con mercados de capitales maduros un alza del mercado de valores hace "sentirse próspero" al inversionista, estimulándolo a aumentar su consumo e inversión (Trigo y Costanzo, 2007).
Aun cuando ha habido cierto desacoplamiento entre el mercado de acciones y el de bonos soberanos debido al inusualmente largo mercado alcista de los años noventa en los Estados Unidos, tanto el uno como el otro están positivamente correlacionados con el LEI estadunidense a largo plazo, y documenta una correlación de 0.6089 entre este LEI y un simple oscilador del índice S&P500 durante el intervalo 1963-2001 (Ruggiero, 2001).
I. Redes neuronales
Antes de abordar el tema de la metodología y los datos utilizados en este estudio, cabe aquí dar una idea general de lo que son las redes neuronales y en particular, de las características de las utilizadas por nosotros, así como de su entrenamiento. Centramos nuestro análisis en el empleo de las redes neuronales multicapas con aprendizaje supervisado, ya que son capaces de ajustarse a cualquier función y se desempeñan particularmente bien con las series de tiempo.
Al igual que otros modelos de proyección, como las regresiones y las extrapolaciones (por ejemplo, promedios móviles, suavizamientos), los modelos basados en redes neuronales utilizan entradas para generar un resultado que es una proyección. Sin embargo, lo que distingue a los modelos neuronales de otros modelos es su capacidad de aprender y adaptarse al entorno.
II. Metodología y datos
La metodología utilizada por los autores de este artículo para construir la red y optimar su entrenamiento comprende definir un número considerable de parámetros, como número de nodos, número de capas, tipo de función de transferencia, algoritmo de aprendizaje, tasa de aprendizaje, manejo del error, pesos iniciales, etc. Cada combinación posible de estos parámetros determina una red distinta, lo cual nos plantea el problema combinatorio de cómo hallar la red óptima.
Ya que este problema no ha recibido solución analítica, debemos recurrir a la sistematización de un método de prueba y error. Por esta razón optimamos las redes por medio de dos programas complementarios: i) un algoritmo de búsqueda del programa de redes neuronales (Braincel) capaz de generar y evaluar diversas arquitecturas de redes con base en las diferentes combinaciones de parámetros posibles, y ii) un programa elaborado por los autores capaz de optimar el entrenamiento las redes candidatas obtenidas con i).
El programa Braicel, utilizado para generar todas nuestras redes neuronales es un Add-in de EXCEL producido por Promised Land Technologies cuyo algoritmo de búsqueda requiere que el cuerpo de datos se divida en tres conjuntos: de entrenamiento, de entrenamiento con prueba y de prueba o validación -aquí llamado conjunto extramuestral-. El primer conjunto (entrenamiento) proporciona los datos para que la red "aprenda" o se entrene en la búsqueda de pautas, comparando sus predicciones con las históricas. El segundo conjunto (entrenamiento y prueba) sirve para supervisar el entrenamiento de la red con el objetivo de eliminar el sobreajuste. El tercer conjunto (extramuestral) se compone de datos completamente nuevos para la red que permiten evaluar su desempeño. En general se recomienda utilizar 60% de los datos como conjunto de entrenamiento, 30% de los datos como conjunto de entrenamiento con prueba y 10% de los datos como conjunto extramuestral.
En este estudio los conjuntos de datos tienen las siguientes fechas: 5 de noviembre de 1995-11 de noviembre de 1998, entrenamiento y entrenamiento con prueba México; 12 de noviembre de 1998-11 de noviembre de 2001, extramuestral México. Dado el número de observaciones disponibles para este estudio decidimos incluir como entradas a las redes dos de los 10 índices componentes del LEI, esto es, un índice del mercado accionario y un índice del mercado debo nos soberanos. Los índices utilizados como entradas fueron: México, i) MSCI Mexico Former Dead-Price Index (~MP), y ii) JPM Elmi Mexico (L) Dead-Return Ind. (OFCL).
En principio podemos usar cualquier conjunto crudo de datos para entrenar nuestras redes. Sin embargo, en la práctica suele ser de gran importancia realizar un preprocesamiento apropiado de los datos antes de alimentar con ella a la red. Dicho preprocesamiento, de ser adecuado, ayuda a la red a aprender mejor. En el caso del presente artículo, cada variable de entrada de la red fue optimada (preprocesada) antes de alimentar a la red con ella.
Preprocesamiemto de los datos
En la práctica, realizar un preprocesamiento apropiado de los datos antes de alimentar con ellos a la red neuronal ayuda a que ésta aprenda mejor. En este artículo se utilizó un modelo no paramétrico basado en una regresión no lineal de procesos gaussianos que es fácil de manejar e interpretar y que efectivamente ayuda a la red a mejorar la predicción.
III. Los procesos gaussianos
Para comprender el modelo utilizado se debe comenzar por entender lo que es un proceso gaussiano. Se puede pensar en un proceso gaussiano (PG) como una generalización de una distribución gaussiana aplicada a un vector de infinitas variables (función), así que la inferencia toma lugar en el espacio de las funciones, de allí que el modelo es no paramétrico, es decir, no se fija de antemano el número y la naturaleza de los parámetros.
En la comunidad estadística existen muchas teorías para modelos con procesos gaussianos en series de tiempo, pero aunque han sido conocidos por largo tiempo, su uso puede quizá ser establecido desde el final del siglo XIX y su aplicación a problemas reales está aún en la fase inicial. En términos formales, un proceso gaussiano es una sucesión de variables aleatorias indizadas en la que cualquier subconjunto resulta tener distribución conjunta gaussiana.
En este trabajo, y = f (x) es el índice LEI (variables aleatorias) y el proceso está indizado respecto a א, el conjunto de posibles variables explicativas de (el índice de acciones y el índice de bonos). El proceso se especifica completamente con una media m(x) y una función de covarianza k(x, x') y se denota
1. Modelo
El modelo utilizado en el preprocesamiento (Rasmussen, 1996, Rasmussen y Williams 2005), está definido en términos de una combinación lineal de funciones de base fijas dadas por los elementos del vector Φ (x) de modo que:

en que x es el vector de entrada y w representa el vector de pesos. En general, los modelos lineales empleados hasta ahora en la bibliografía para predecir ciclos económicos presentan baja capacidad predictiva, sin embargo, éste modelo lineal utilizado para preprocesar los datos no tiene el mismo inconveniente como muestra líneas abajo.
Para hacer la estimación de los parámetros del modelo se utiliza un enfoque bayesiano, por lo cual imponemos una distribución apriori para w de la forma: p(w) = N(w|0,α-1 I), en la que a representa la precisión de la distribución. Nótese que cada w induce una función de probabilidad en f (x). Con la estructura especificada, el modelo es un proceso gaussiano. En efecto, si queremos evaluar f (x) para valores específicos del vector x, digamos x 1,...xN , estamos interesados en la distribución conjunta de f(x 1),..., f(xN ). Al denotar f como un vector de componentes fn = f(xn ), n = 1,..., N se tiene que f = Φ w. Entonces, por ser f (x) una combinación lineal de variables aleatorias gaussianas independientes, resulta también gaussiana y el proceso está definido por:

en que K donde tiene elementos
De esta manera, el modelo presentado es un proceso de ruido con distribución gaussiana de la forma p (y | f, α-1 IN ) , en el que y = (y 1,..., yN )-t y f = (f 1,..., fN )-t y, de la definición de proceso gaussiano, resulta que la distribución marginal de p(f) es N (f | 0, K). Así, la marginal es p(y) es N (y | 0, C), con C matriz de covarianza con elementos:

2. Predicción
Dado un conjunto de datos de entrenamiento y = (y 1,..., yN )-t correspondientes a los vectores x 1,...,xN , la idea es predecir el valor yN + 1 , lo cual requiere evaluar la distribución predictiva p (yN + 1 | y). Para encontrar p (yN + 1 | y), se coloca p (yN + 1 ) = N (yN + 1 |0, CN + 1 ), en que CN + 1 es una matriz de covarianza que se particiona de la siguiente forma:

con CN de dimension N 𝗑 N para i, j = 1,..., N, el vector k con elementos para i = 1,..., N y el escalar c = (xN + 1, xN + 1 ) + α-1. Luego, la distribución predictiva p (yN + 1 | y) es gaussiana con media y covarianzas dadas por:

3. Selección del kernel
Como la distribución predictiva depende del valor de xN + 1 sólo por medio de la función k(...), su selección es decisiva para la predicción. La función de covarianza define cercanía o similitud: entradas que son cercanas probablemente tendrán valores de respuesta y cercanos, además la covarianza debe llevar codificada las suposiciones que se tienen acerca de la función que deseamos estimar f.
En este artículo se usó la familia paramétrica exponencial cuadrada como kernel, esta es (véase Apéndice 2):
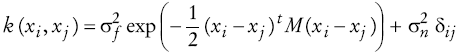
Los hiperparámetros del kernel (la precisión del ruido y los de k(...)) se infieren a partir de los datos, maximizando la verosimilitud p (y|θ) respecto a θ. La matriz
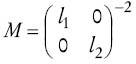
en la que l 1 y l 2 desempeñan el papel de parámetros de longitud-escala, es decir, cuán lejos se debe mover (a lo largo del eje de una cierta entrada) para que los valores de la función no estén correlacionados.
4. Datos o instrumentación
Los datos utilizados corresponden al país México, son mensuales y la serie va desde el 15 de enero de 1994 hasta el 15 de noviembre de 2001, es decir, el tamaño muestral es 95, en el que: y es el vector que deseamos estimar y corresponde al índice LEI en México; x 1 representa un vector de la primera variable explicativa que en este caso corresponde al índice de bonos soberanos JPM Elmi Mexico Dead-Return Ind; x2 denota un vector de la segunda variable explicativa que corresponde al índice del mercado accionario: MSCI Mexico Former Dead-Price Index.
El método descrito se usó como preprocesamiento de los datos en dos versiones: i) como predictor y ii) como suavizador de la serie. En ambos casos los resultados que se muestran se obtuvieron con los siguientes valores iniciales de los hiperparámetros:
5. Capacidad predictiva del modelo basado en PG
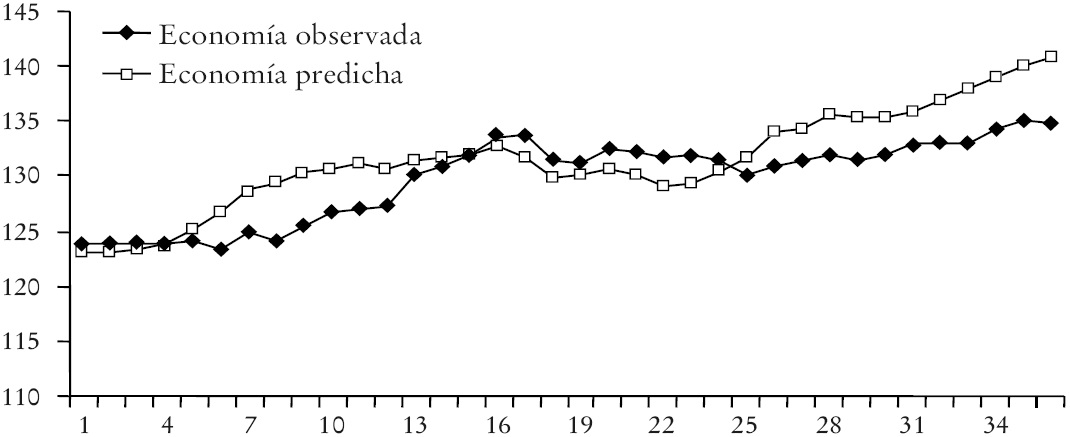
La manera más sencilla de evaluar la capacidad predictiva del modelo es graficar la economía observada versus la estimada por el modelo propuesto, lo cual corresponde a la Gráfica 1 y en la que la línea continua indica la media predictiva obtenida con el modelo y las barras grises las bandas de confianza asociadas a cada predicción a 95% de confianza. Las cruces representan los valores observados. Es evidente que los valores observados y los estimados siguen la misma tendencia y que el error en la predicción es pequeño. Resalta la capacidad del modelo para estimar la caída del LEI en los índices del tiempo entre 10 y 20.
a Exccess Profit de la red neuronal con PP gaussiano de los datos, 2.158; Prob. predictiva de la red neuronal de PP gaussiano de los datos, 0.969.
Gráfica 1 LEI observado vs LEI predicho por la red con preprocesamiento a
Con el fin de comparar los resultados de este modelo con los de la red neural publicada en un trabajo previo a éste (Trigo y Costanzo, 2007), se mide el desempeño del modelo por el número de predicciones correctas del signo de la variación del índice y suponiendo además para ello que el índice de actividad económica es "comerciable" a fin de aplicar la prueba estadística de precisión en el acierto direccional y magnitudinal (Anatolyev y Gerko, 2005).
Dado que el modelo basado en PG muestra un indicador de Anatolyev máximo, se pasa a calcular algo más refinado para determinar la rentabilidad, esto es, la curva de patrimonio acumulado inducido por las decisiones de mercado tomadas con base en las recomendaciones del modelo de PG.
En contraposición a la metodología descrita líneas arriba -en la que los insumos de la red son preprocesados mediante de un proceso gaussiano - , en un trabajo anterior (Trigo y Costanzo, 2007), se utiliza un método de optimación consistente en utilizar cada variable de entrada para generar otras 24 variables de entrada consistentes en rezagos sucesivos de la variable de entrada original, cada una más rezagada que la próxima, desde (X -1 mes), (X- 2 meses), (X-3 meses) ... hasta (X-24 meses). Cada variable de entrada rezagada se utilizaba aisladamente para proyectar el LEI correspondiente median te el siguiente procedimiento, que coincide con la estratégica de compraventa descrita por Anatolyev y Gerko (2005).
[...] Si se asume que el LEI es comerciable con precio igual al valor numérico del índice y la entrada y el LEI coinciden en la dirección del cambio (si ambos suben o ambos bajan), se suma al "patrimonio" o equity del agente una "ganancia" igual al valor absoluto de la diferencia entre el "preciot" y el "preciot-1" del LEI, de lo contrario se resta esa misma cantidad como "pérdida"; esto es, se construyeron 24 sistemas de compra-venta del LEI, cada uno con una entrada rezagada distinta y se calculó el cociente estadístico EP de estos 24 sistemas de compraventa, esto es, "Excess Profitability" o rentabilidad excedente (y la probabilidad de predicción asociada) de Anatolyev y Gerko (2005). Los sistemas de compraventa se jerarquizaron en base a los resultados obtenidos y se escogió en consecuencia al rezago 20 como óptimo [...].
Los resultados de la optimación de los rezagos llevaron a la siguiente selección: Mexico, MSCI Mexico former dead-Price Index (~MP) rezago 20 meses, y JPM Elmi Mexico (L) Dead-Return Ind. (OFCL) rezago15 meses. Cada una de las entradas de rezago seleccionadas se utilizó para construir tres promedios móviles que también fueron usados como entradas de la red. Estos tres promedios móviles se construyeron introduciendo tres valores distintos de a (0.1, 0.3 y 0.5) en la siguiente fórmula de suavizamiento: Promedio móvil, Mt = α * xt + (1 - α) * Mt - 1 .
Los valores escogidos para a permiten considerar los tres casos posibles: en el cuerpo de datos, i) las últimas observaciones tienen importancia preponderante, ii) la última fracción considerable tiene importancia preponderante y iii) casi todos los datos son de importancia primordial. En total, cada red fue alimentada con ocho variables de entrada: seis suavizadas y dos sin suavizar (Trigo y Costanzo, 2007).
IV. Evaluación del desempeño de las redes: Descripción de la prueba Anatolyev y Gerko
La evaluación del desempeño de las redes relativa a los datos del conjunto extramuestral fue hecha con base en el número -y a la magnitud- de los aciertos en la predicción de la variación del índice por medio de la prueba estadística de precisión en el acierto direccional y magnitudinal -Excess Profitability o EP de Anatolyev y Gerko (2005)-, en el supuesto de que el índice de actividad económica es "comerciable". Los resultados mostraron: i) que las dos redes neuronales (la red con preprocesamiento gaussiano y la red con preprocesamiento simple) poseen capacidad predictiva -es decir, que en ambos casos tratados, la red predice al LEI con un margen de certeza de Anatolyev de más de 90% - ; ii) que la capacidad predictiva de la red con preprocesamiento gaussiano de los insumos es superior que la capacidad predictiva de la red con insumos preprocesados por medio de rezagos y promedios móviles, y iii) que la capacidad predictiva de ambas redes es superior a la de una regresión múltiple equivalente.
El instrumento usado tanto para evaluar la capacidad predictiva de la red y demostrar su congruencia como para compararla con la de una regresión es la prueba de predictibilidad de Anatolyev y Gerko, la cual mide la precisión en el acierto direccional y magnitudinal de un predictor y los sintetiza en dos parámetros llamados respectivamente Excess Profitability o EP y Probability of Prediction o "Prob.", la cual es la probabilidad de que una variable normal centrada en 0 y con desviación estándar igual a 1 cobre un valor ubicado dentro del intervalo que va de -EP a +EP, es decir, la probabilidad de no independencia de las predicciones y las observaciones (Anatolyev y Gerko, 2005).
Comparación de la capacidad predictiva de las redes neuronales (alimentadas con datos preprocesados respectivamente con metodología gaussiana y con metodología simple), con la de una regresión múltiple equivalente. La capacidad de los dos modelos de redes neuronales para predecir la variación del LEI -junto con la "rentabilidad" que un inversionista habría obtenido de haber seguido las recomendaciones de compra y de venta arrojadas por cada uno de los modelos-, es contrastada a continuación con la "rentabilidad" que éste habría obtenido de haber seguido las recomendaciones de compra y de venta señaladas por una regresión múltiple comparable.
V. Análisis de los resultados
Capacidad predictiva de las redes neuronales
A continuación se resume la capacidad predictiva de las redes dentro del conjunto extramuestral. Siguen las gráficas de las curvas de la economía observada (en azul marino) y estimada (en fucsia) por la red neuronal de preprocesamiento simple para México (Gráfica 1).
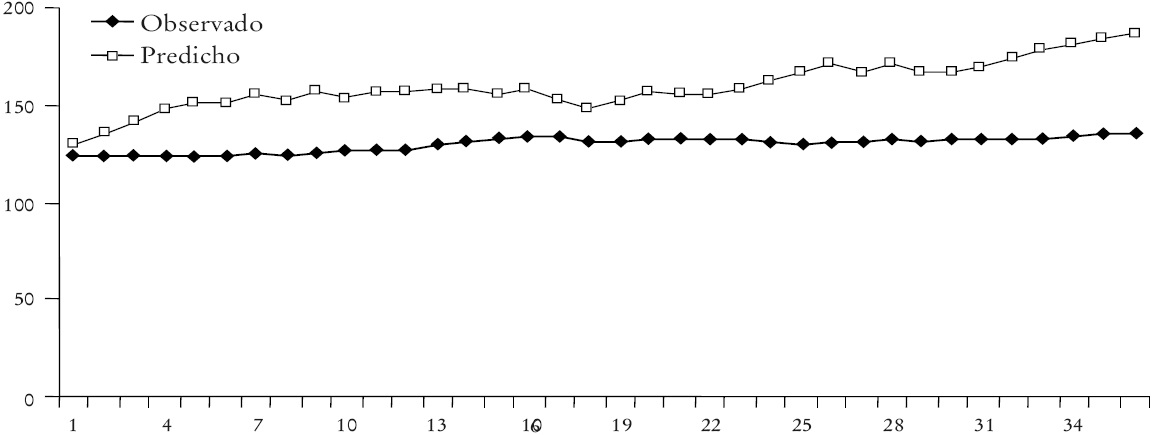
Adviértase a continuación la "adquisición" consistente de "ganancias" y la baja volatilidad de la curva de patrimonio acumulado correspondiente a la gráfica anterior -que en realidad representa el "éxito predictivo acumulado" de la estrategia utilizada por la red con PP simple para predecir el LEI de México. Las mismas observaciones son pertinentes para el caso de pre procesamiento gaussiano de los datos (PP gaussiano) presentadas en la Gráfica 3.

Gráfica 2 Curva de patrimonio acumulado de la estrategia de compraventa de la red neuronal con PP simple

Nótese en la Gráfica 4 la "adquisición" consistente de "ganancias" y la baja volatilidad de la curva de patrimonio acumulado correspondiente a la Gráfica 3 -que en realidad representa el éxito predictivo acumulado de la estrategia utilizada por la red con PP Gaussiano para predecir el LEI de México.

La regresión múltiple tuvo las mismas entradas (inputs) que las redes y fue efectuada con base en primeras diferencias de Durbin calculado en dos pasos (Trigo y Costanzo, 2007).
Conclusiones
En este artículo hemos constatado que la capacidad de las redes neuronales para predecir la dirección de la economía de México -representada por el LEI- depende no sólo de las variables independientes utilizadas, sino también de la calidad de esta última así como sus versiones simultáneas (suavizante y predictiva) que se puede hacer mediante del preprosesamiento de los datos con el uso de un proceso gaussiano alimentado por un índice de acciones y uno de bonos (ambos representativos del mercado mexicano). Dicho proceso gaussiano no sólo es capaz de suavizar simultáneamente el índice de acciones y el de bonos sin eliminar la dependencia (posiblemente no lineal) que podría existir entre las dos variables, sino que puede hacer lo mismo para cualquier número de variables independientes que se hubiesen utilizado en el análisis.
El poder predictivo de la red alimentada con datos suavizados por medio del proceso gaussiano es mayor que el de otros métodos, tal como lo muestra el Cuadro 1 de este artículo.

a La regresión múltiple tuvo las mismas entradas, que las dos redes y fue efectuada con base en primera diferencias de Durbin calcula o en dos pasos (Trigo y Costanzo, 2007).
Cuadro 1 Resumen de los resultados comparativos de las redes neuronales con PPS PPG & regresión para México a
Efectivamente, no sólo la probabilidad predictiva de la red neuronal sino también el Excess Profit son mejores (0.969 y 2.158, respectivamente) cuando se pre procesa los datos utilizando el proceso gaussiano que cuando se preprocesa utilizando rezagos o promedios móviles, o cuando se usa simplemente una regresión lineal. Dichos resultados generalizan y mejoran significativamente los hallados en un trabajo que precede al presente de Trigo y Costanzo (2007). Es de hacer notar que no hemos encontrado en la bibliografía académica trabajos similares que utilicen métodos de suavizamiento no paramétricos (de tipo gaussiano) de los datos para entrenar redes neuronales. Dicha idea ha resultado ser útil y fácil de aplicar para mejorar la calidad de los pronósticos hechos por medio de estgos instrumentos.


