











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkClasificación JEL: G.
Introducción
La drástica reducción de tiempo de computación requerido para generar y procesar modelos no lineales basados en inteligencia artificial ha estimulado su aplicación a temas macroeconómicos que antes eran considerados complejos. Parte de este impulso se debe a que hoy en día se duda que los modelos lineales puedan predecir los ciclos de negocios. Varios estudios (Kaiser y Maraval, 1999; Verbrugge, 1997, y Kim et al, 1996, entre otros) han establecido que los ciclos de negocio son asimétricos. Otros estudios recientes (Granger y Terasvirta, 1993; Diebold y Rudebusch, 1993; Swansen y White, 1995, y Jaditz et al, 1998) han demostrado que los modelos de predicción macroeconómica mejoran cuando incluyen componentes no lineales. Con base en el ejemplo de Natter et al (1994), Moody et al (1993), White (1996), Tkacz (2000) y Jadric (2003), quienes han creado modelos de predicción macroeconómica basados en redes neuronales que se desempeñan mejor que los modelos lineales, el objetivo de este estudio es reconfirmar la validez de los modelos no lineales con base en redes neuronales para la proyección macroeconómica, mas de tal manera que sean de utilidad para la comunidad de inversionistas potenciales. En este estudio utilizamos la medida estadística de la precisión en el acierto direccional y magnitudinal establecida por Anatolyev y Gerko (2005).
El método más conocido para predecir los ciclos de negocios es el índice LEI (Leading Economic Indicators) o índice compuesto —de índole lineal—, que ha predicho cada una de las pasadas ocho recesiones en los Estados Unidos. Este índice, publicado mensualmente por la Conference Board para los Estados Unidos y México entre otros, se compone de 10 índices económicos: i) horas promedio trabajadas a la semana por obreros de producción en industrias manufactureras (.1946); ii) número promedio de reclamos de seguro de desempleo (.0268); iii) nuevas órdenes de los manufactureros para bienes de consumo (.0504); iv) velocidad relativa en que vendedores pueden entregar pedidos a compañías industriales, según el índice de la National Association of Purchasing Managers (.0296); v) nuevas órdenes recibidas por manufactureros en bienes capitales no relacionados con la defensa (.0139); vi) número de permisos concedidos para edificios residenciales; (.0205); vii) cambio en el mercado de acciones, según el precio de las acciones en el índice Standard & Poor’s 500 (.0309); viii) provisión monetaria M2 (ajustada por inflación) (.2775); ix) la dispersión del rendimiento, esto es, la diferencia entre la tasa de interés a largo plazo (bonos soberanos a diez años) y la de corto plazo (el interés libre de riesgo o notas del tesoro) (.3364), y x) el índice de expectativas del consumidor (.0193).
Aunque la Conference Board le asigna al cambio en el mercado de acciones un factor de estandarización de sólo .0309, según el masivo compendio publicado en 1961 por Geoffrey Moore del National Bureau of Economic Research, los precios accionarios fueron clasificados como indicadores adelantados 31 veces, como coincidentes 14 veces y como rezagados sólo cinco veces. Renshaw (1995) muestra que aun cuando el mercado de acciones no predice bien las recesiones económicas, sí es un excelente predictor de las recuperaciones. Respecto al yield spread que recibe de la Conference Board el segundo factor más alto de estandarización, Estrella y Mishkin (1997, 1998) y Dotsey (1998), entre otros, documentan la efectividad de la dispersión de los bonos soberanos como predictor de los ciclos de negocios, en particular de las recesiones.
Es muy conocido que, según la percepción de muchos operadores financieros exitosos, el rendimiento histórico de los mercados de acciones y bonos puede ser utilizado para predecir el rendimiento futuro de los mismos. Se puede ir aún más allá al afirmar que dicho rendimiento histórico es también utilizado para predecir el movimiento futuro de otros índices económicos relevantes que acompañan a estos dos mercados en la composición del LEI. Esto induce a preguntarse por qué y en qué medida en los Estados Unidos esos cambios históricos en los mercados de acciones y de bonos soberanos se corresponden con —y permiten predecir— los cambios en las estadísticas que influyen directamente en el crecimiento o la contracción económicas, como son los índices de ventas, sueldos, ingresos por impuestos y gastos de capital. Para explicar este efecto se puede recurrir a dos argumentos: i) que los mercados de capitales (equity & debt) son la principal fuente de financiación de la economía y en esta capacidad actúan como estimulantes; ii) recurre a una metáfora de las finanzas comportamentalistas según la cual en las economías con mercados de capitales maduros un alza del mercado de valores hace “sentirse próspero” al inversionista, estimulándolo a aumentar su consumo y su inversión. Ruggiero (2001) arguye que aun cuando ha habido cierto desfase entre el mercado de acciones y el de bonos soberanos debido al inusualmente largo mercado alzista de los años noventa en los Estados Unidos, tanto uno como el otro están positivamente correlacionados con el LEI estadunidense a largo plazo, y documenta una correlación de 0.6089 entre este LEI y un simple oscilador del índice S&P500 durante el intervalo 1963-2001. Situemos pues nuestro estudio dentro de esta polémica, del lado de los que arguyen que las expectativas de la economía no estimulan los mercados de capitales sino que la relación apunta más bien hacia la dirección opuesta. Además, a fin de comprobar si la metáfora comportamentalista tiene valor general, hemos escogido proyectar el LEI de dos países cuyos mercados de capitales tienen distintos grados de madurez y participación: México y los Estados Unidos.
I. Redes neuronales
Antes de abordar el tema de la metodología y los datos utilizados en este estudio, cabe aquí dar una idea general de lo que son las redes neuronales y, en particular, de las características utilizadas en este estudio así como de su entrenamiento. Centramos nuestro análisis en el empleo de las redes neuronales multicapas con aprendizaje supervisado ya que (como veremos líneas abajo) son capaces de ajustarse a cualquier función y se desempeñan particularmente bien con las series de tiempo.
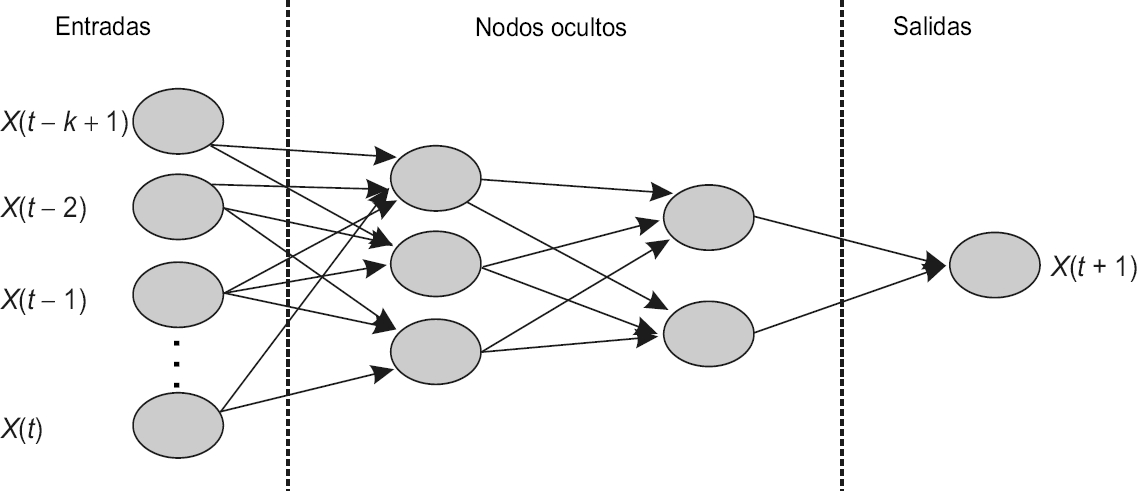
Al igual que otros modelos de proyección, como las regresiones y las extrapolaciones (promedios móviles, suavizamientos), los modelos basados en redes neuronales utilizan entradas para generar un resultado que es una proyección. Sin embargo, lo que distingue a los modelos neuronales de otros modelos es su capacidad de aprender y adaptar se al entorno. Las redes neuronales se componen de tres elementos fundamentales: i) unidades de procesamiento o nodos capaces de operar de manera paralela; ii) funciones de transferencia (o funciones de activación) que transforman la información en los nodos, y iii) pesos de conexión que determinan la importancia relativa entre nodos. Estos tres elementos se utilizan para construir una red que puede ser de una o más capas. En el caso de las redes multicapas de alimentación frontal (MLP o Multi Layer Perceptron), las salidas de una capa constituyen la entrada a la próxima capa, tal y como se muestra en la gráfica 1a. Al hablar de una red de N capas, la capa de entrada es la capa 0 y la de salida es la capa N. La(s) capa(s) intermedia(s) se llama(n) —por consenso— capa(s) oculta(s).

Las redes neuronales aprenden y se adaptan modificando los pesos asociados a las conexiones entre los nodos. Los factores comprendidos en el aprendizaje realizado por redes multicapas son los siguientes:
El propósito del entrenamiento o aprendizaje por la red neuronal es minimizar los errores de salida en un conjunto particular de datos de entrenamiento haciendo una serie de actualizaciones de los pesos conectores
Definimos una función error
Derivadas parciales de la función error
La tasa de aprendizaje
Sólo las salidas de la capa final aparecen en la función error. Sin embargo, este error dependerá de todas las capas de pesos anteriores y un componente del algoritmo de aprendizaje llamado propagación en reversa los ajustará todos. La propagación en reversa automáticamente ajusta las salidas de las capas ocultas anteriores de tal manera que las capas formen representaciones intermedias (ocultas) apropiadas.
Continuamos paso a paso a través del espacio de pesos hasta que los errores son “suficientemente pequeños”.
Si escogemos funciones de activación (transferencia) neuronales con derivadas que asumen formas particularmente sencillas, podemos hacer que los cómputos para la actualización de los pesos sean muy eficientes.
II. Entrenamiento de una red multicapas (MLP)
i) Tomamos el conjunto de pautas de entrenamiento que deseamos que la red aprenda
Entonces tenemos una red neuronal entrenada. Como se deduce de esto, el entrenamiento de una red implica la definición de un número significativo de parámetros lo cual hace posible la sobreparametrización del modelo o sobreajuste del modelo a la data. Existe una técnica para optimar el entrenamiento de las redes neuronales evitando el sobreajuste que presentamos líneas abajo, pero para comprenderla hay que entender cómo surge este sobreajuste en el caso de las redes neuronales. Esto es lo que intentamos esbozar a continuación.
III. Poder computacional de las redes multicapas
El teorema de la aproximación universal para un MLP probado independientemente por Cybenko (1989) y Hornik et al (1989) dice que cualquier función continua capaz de mapear intervalos de números reales a algún intervalo-salida (output) de números reales puede ser aproximada arbitrariamente cercana por un MLP con sencillamente una capa oculta. Este resultado es cierto sólo para clases restringidas de funciones de activación o transferencia, como lo son las funciones sigmoidales o de distribución logística. En otras palabras, sea
es una realización aproximada de
IV. Metodología y datos
Explicado en qué consiste una red neuronal y lo que es capaz de aprender, queda por analizar la metodología utilizada por los autores de este trabajo para construirla y optimar su entrenamiento. Hemos visto que la construcción y optimación de una red neuronal implica definir un número considerable de parámetros, como número de nodos, número de capas, tipo de función de transferencia, algoritmo de aprendizaje, tasa de aprendizaje, manejo del error, pesos iniciales, etc. Cada combinación posible de estos parámetros determina una red distinta, lo cual nos plantea el problema combinatorio de cómo hallar la red óptima.
Puesto que este problema no ha recibido solución analítica, debemos recurrir a la sistematización de un método de prueba y error. Por esta razón decidimos optimar las redes por medio de dos programas complementarios: i) un algoritmo de búsqueda del programa de redes neuronales (Braincel) capaz de generar y evaluar diversas arquitecturas de redes, con base en las diferentes combinaciones de parámetros posibles, y ii) un programa elaborado por los autores capaz de optimar el entrenamiento de las redes candidatas obtenidas con i).
El algoritmo de búsqueda de Braincel requiere que el cuerpo de datos se divida en tres conjuntos: i) de entrenamiento, ii) de entrenamiento con prueba y iii) de prueba o validación aquí llamado conjunto extramuestral. El primer conjunto (entrenamiento) aporta los datos para que la red “aprenda” o se entrene en la búsqueda de pautas comparando sus predicciones con las históricas. El segundo conjunto (entrenamiento y prueba) sirve para supervisar el entrenamiento de la red con el objetivo de eliminar el sobreajuste. El método utilizado es la interrupción temprana del entrenamiento y el suavizamiento de los datos, como se explica líneas abajo.
Para los algoritmos iterativos de gradiente descendente (como propagación reversa en lotes y gradientes conjugados), el error de la red disminuirá según vaya aumentando el número de épocas de entrenamiento. Por esto, al inicio, el error en la data de entrenamiento y prueba disminuirá según se vaya reduciendo el subajuste, pero finalmente, este error comenzará a aumentar de nuevo según ocurre el sobreajuste. La solución natural para obtener la mejor generalización, es decir el error más bajo en el conjunto de entrenamiento y prueba, es la utilización del método de interrupción temprana del entrenamiento. De manera sencilla, una red se debe entrenar hasta que el error asociado a la data de entrenamiento y prueba comience a subir de nuevo, para entonces interrumpir el entrenamiento. En este punto se espera que el error de generalización también comience a subir. El tercer conjunto (extramuestral) se compone de datos completamente nuevos para la red que permiten evaluar su desempeño. En general se recomienda utilizar 60% de la data como conjunto de entrenamiento, 30% como conjunto de entrenamiento con prueba y 10% como conjunto extramuestral.
En este estudio los conjuntos de datos tienen las siguientes fechas: 7 de octubre de 1986-7 de octubre de 2001 (entrenamiento y entrenamiento con prueba Estados Unidos); 8 de octubre de 2001-1 de octubre de 2004 (extramuestral Estados Unidos); 5 de noviembre de 1995-11 de noviembre de 1998 (entrenamiento y entrenamiento con prueba México), y 12 de noviembre de 1998-11 de noviembre de 2001 (extramuestral México).
Cabe señalar que las redes construidas con Braincel utilizan como algoritmo de aprendizaje de red la llamada percolación reversa (Back-Percolation) —que es una modificación del algoritmo de propagación reversa—, establecida por Mark Jurik en 1984. El algoritmo de propagación reversa, ampliamente utilizado, tiene la desventaja respecto al de percolación reversa de que en el primero el error que posee el nodo de salida no se puede comunicar a todas las capas precedentes. Esto causa que la precisión de la red disminuya según se incrementa el número de nodos y capas. En contraste, la percolación reversa permite que el error se propague del nodo de salida hacia todos los demás nodos y capas precedentes y que el número de nodos y capas pueda aumentar sin empeorar el desempeño de la totalidad (Jurik, 1994, p. 85). Es notorio que ambos algoritmos de aprendizaje son equivalentes en el caso de redes cuya arquitectura consiste de una única capa oculta.
Es importante destacar que en el caso de este estudio el algoritmo de búsqueda de Braincel arrojó congruentemente que las redes asociadas a los mejores resultados son redes con una sola capa oculta, una capa de entrada y una capa (consistente en un nodo) de salida. Las características de las redes usadas para proyectar se presentan en el cuadro 1. Si tomamos como entradas de la red a varios cortes temporales (
Cuadro 1 Arquitectura de las redes neuronales utilizadas para proyectar las variaciones del LEI
| Salida | Capa 0 | Capa 1 (oculta) | Capa 2 |
| Funciones de transferencia | |||
| LEI Estados Unidos | Logística | Logística | Lineal |
| LEI México | Logística | Logística | Lineal |
| Capa 0 + bias | Capa 1 (oculta) + bias | Capa 2 | |
| Número de nodos | |||
| LEI Estados Unidos | 8 | 4 | 1 |
| LEI México | 8 | 4 | 1 |
| Aprendizaje | Intervalo de pesos iniciales | Error de entrenamiento | |
| Parámetros de aprendizaje | |||
| LEI Estados Unidos | 0.076 | 0.4 | 4.75 |
| LEI México | 0.187 | 0.4 | 4.82 |
La variable de salida de las redes que presentamos aquí está dada por la variación del índice adelantado macroeconómico de un país (el LEI en los Estados Unidos y el LEI en México, ambos publicados por la Conference Board) correspondiente al periodo
Desde el punto de vista heurístico, para que una red neuronal sea entrenada óptimamente conviene tener alrededor de 10 veces más observaciones que el número de pesos conectores que tenga la red. Como el número de entradas determina el número de pesos conectores, se debe reducir el número de entradas al permitido por el número de observaciones disponible. Por ejemplo, si una red tiene dos entradas y una salida, requerirá óptimamente (2 + 1)* 10 *10 = 300 observaciones, que dividido entre 12 meses es igual a 25 años de data. Dado el número de observaciones disponibles para este estudio decidimos incluir como entradas a las redes dos de los diez índices componentes del LEI, esto es, para cada país un índice del mercado accionario y un índice del mercado de bonos soberanos correspondientes. Los índices utilizados como entradas fueron para Estados Unidos: i) S&P 500 Composite-Price Index (dólares) y ii) JPM United States Govt. Bond (dólares)-Price Index; para México: i) MSCI Mexico Former Dead-Price Index (pesos) y ii) JPM ELMI México (L) Dead-Return Ind (OFCL).
En principio podemos usar cualquier conjunto simple de datos para entrenar nuestras redes. Sin embargo, en la práctica suele ser de gran importancia realizar un preprocesamiento apropiado de la data antes de alimentar con ella a la red. Dicho preprocesamiento, de ser adecuado, ayuda a la red a aprender mejor. En el caso del presente trabajo, cada variable de entrada de la red fue optimada (preprocesada) antes de alimentar a la red con ella. El método de optimación consistió en que cada variable de entrada fue utilizada para generar 24 variables de entrada consistentes en rezagos sucesivos de la variable de entrada original, cada una más rezagada que la próxima desde (X − 1 mes), (X − 2 meses), (X − 3 meses)... hasta (X − 24 meses). Cada variable de entrada rezagada se utilizó aisladamente para proyectar el LEI correspondiente mediante el siguiente procedimiento, que coincide con la estrategia de compraventa descrita por Anatolyev y Gerko (2005) (véase líneas abajo): i) se supone que el LEI es comerciable con precio igual al valor numérico del índice; ii) si la entrada y el LEI coinciden en la dirección del cambio (si ambos suben o ambos bajan), se suma al “patrimonio” o equity del agente una “ganancia” igual al valor absoluto de la diferencia entre el “precio t” y el “precio t − 1” del LEI, de lo contrario se resta esa misma cantidad como “pérdida”; iii) esto es, se construyeron 24 sistemas de compraventa del LEI, cada uno con una entrada rezagada distinta; iv) se calculó el cociente estadístico EP de estos 24 sistemas de compraventa, esto es, “Excess Profitability” o rentabilidad excedente (y la probabilidad de predicción asociada) de Anatolyev y Gerko (2005) (véase líneas abajo); v) los sistemas de compraventa se jerarquizaron con base en los resultados obtenidos; por ejemplo, para escoger el rezago apropiado del índice de acciones de México como predictor de la economía, se obtuvo una tabla de valores del índice de EP, gracias a la cual se escogió el rezago 20 como óptimo (véase cuadro 2).
Cuadro 2 Valores del índice de EP
| Rezago | EP Anatolyev | Rezago | EP Anatolyev |
| Lag_2 | 0.71339569 | Lag_14 | −0.95337281 |
| Lag_3 | −0.28314134 | Lag_15 | −2.74800468 |
| Lag_4 | −1-53075007 | Lag_16 | −0.46402437 |
| Lag_5 | −1.80635256 | Lag_17 | −0.09574475 |
| Lag_6 | −2.13690593 | Lag_18 | −0.43578441 |
| Lag_7 | −1.3699712 | Lag_19 | −0.01960145 |
| Lag_8 | 0.66849162 | Lag_20 | 2.25037464 |
| Lag_9 | 1.35038554 | Lag_21 | 2.04505793 |
| Lag_10 | 0.66499122 | Lag_22 | 1.2619383 |
| Lag_11 | −0.42872635 | Lag_23 | 0.90530506 |
| Lag_12 | −0.68200151 | Lag_24 | −0.39314648 |
| Lag_13 | −1.38125953 |
Los resultados de la optimación de los rezagos llevaron a la siguiente selección: para los Estados Unidos, i) S&P 500 Composite-Price Index (dólares), rezago 7 meses y ii) JPM United States Govt. Bond (dólares)-Price Index, rezago 4 meses; para México: i) MSCI México Former Dead′-Price Index (pesos), rezago 20 meses y ii) JPM ELMI México (L)′ Dead′-Return Ind (OFCL), rezago15 meses.
Cada una de las entradas de rezago seleccionadas se utilizó para construir tres promedios móviles que también fueron usados como entradas de la red. Estos tres promedios móviles se construyeron introduciendo otros tres valores de
V. Evaluación del desempeño de las redes
La evaluación del desempeño de las redes relativa a los datos del conjunto extramuestral fue hecha con base en el número —y magnitud— de los aciertos en la predicción de la variación del índice por medio de la prueba estadística de precisión en el acierto direccional y magnitudinal —Excess Profitability o EP de Anatolyev y Gerko (2005)—, suponiendo para ello que el índice de actividad económica es “comerciable”. Los resultados mostraron: i) que la red neuronal posee capacidad predictiva —es decir, que en ambos casos tratados, la red predice al LEI con un margen de certeza de más de 90%—; ii) que esta capacidad predictiva es congruente —es decir, que es estable durante el periodo de prueba—, y iii) que la capacidad predictiva de la red es superior a la de una regresión múltiple equivalente. Dado que el instrumento usado tanto para evaluar la capacidad predictiva de la red y demostrar su congruencia como para compararla con la de una regresión es la prueba de predictibilidad de Anatolyev y Gerko, ofrecemos a continuación una descripción de dicha prueba estadística que mide la precisión en el acierto direccional y magnitudinal de un predictor y los sintetiza en dos parámetros llamados respectivamente Excess Profitabilityo EP y Probability of Prediction o Prob., la cual es la probabilidad de que una variable normal centrada en 0 y con desviación estándar igual a 1 asuma un valor ubicado dentro del intervalo que va de −EP a +EP, es decir, la probabilidad de no independencia de las predicciones y las observaciones.
Según Anatolyev y Gerko (2005), “si
Esto es, un inversionista va largo si la predicción para el próximo periodo es positiva, y va corto si no lo es. Llamemos esta regla la estrategia de compraventa. Equipado con esta estrategia, el inversionista modifica su posición cada periodo de compraventa y cierra la posición al final de cada periodo. Entonces, el rendimiento durante un periodo de la estrategia de compraventa es:
en el que
La estrategia de compraventa (1) describe el comportamiento de un “analista técnico artificial” neutral al riesgo, si seguimos la terminología de Skouras (2001). La rentabilidad de la estrategia de compraventa (1) fue evaluada por Gençay (1998) como si las predicciones tuvieran valor económico en la práctica. Usando dos decenios y medio de DJIA Gençay (1998) encuentra que esta estrategia de compraventa es capaz de proporcionar ganancias perceptibles en comparación con las de una estrategia de buy and hold. Aquí se usa esta estrategia de compraventa para construir una prueba formal de predictabilidad promedio de los rendimientos, la cual se basa en la rentabilidad extramuestral de la estrategia de compraventa. El lector debe tener presente que el proceso de compraventa es tan sólo un experimento cerebral, y que no hace diferencia alguna el que haya límites de mercado (como costos de comercio y restricciones a la venta corta) que impidan o permitan la ejecución de la estrategia.
De manera formal, la hipótesis nula es la de que hay independencia de media condicional,
Ciertamente, con la hipótesis nula
Para completar la construcción de la prueba, queda por computar la varianza de
La manera más simple de estimar esta varianza es
en la que hemos corregido por los grados de libertad al estimar la varianza de
es un estimador congruente de
según Anatolyev y Gerko (2005). Adviértase que la fórmula (6) no es más que un cociente de rendimientos/volatilidad, indicándonos la relación intrínseca entre EP y el cociente clásico de Sharpe que también calculamos líneas abajo.
1. Capacidad predictiva de la red neuronal
El cociente EP analiza la capacidad predictiva de la red neuronal en términos del tamaño del intervalo que va de −EP a +EP, en el que EP es una variable normal estándar centrada en 0 y con desviación estándar igual a 1. Se refuta la hipótesis nula de que hay independencia de media condicional
2. Congruencia histórica de la capacidad predictiva de la red
Para analizar la estabilidad de la capacidad predictiva de cada red se calculó la desviación estándar de la frecuencia acumulativa con que la red predijo correctamente —según el cociente EP—, la variación del LEI a lo largo de la duración del conjunto extramuestral.
3. Comparación de la capacidad predictiva de la red neuronal con la de una regresión múltiple equivalente
Por último, la capacidad de los modelos de redes neuronales para predecir la variación del LEI —junto con la rentabilidad que un inversionista habría obtenido de haber seguido las recomendaciones de compra y de venta arrojadas por el modelo— fue contrastada con la rentabilidad que éste habría obtenido de haber seguido las recomendaciones de compra y de venta hechas por una regresión múltiple comparable.
VI. Análisis de los resultados
1. Capacidad predictiva de la red neuronal
El cuadro 3 resume la capacidad predictiva de las redes dentro del conjunto extra muestral. Además del EP se calculó una serie de medidas secundarias, de las cuales la única que pudiera no ser de uso general es el drawdown. El drawdown en cualquier punto del tiempo es el de crecimiento en el valor neto de la cuenta del patrimonio desde el valor histórico máximode la misma (Wolberg, 2000, p. 39):
Cociente del nivel del patrimonio = nivel del patrimonio/nivel máximo del patrimonio
Drawdown = 1 − cociente del nivel del patrimonio (Equity Ratio = Equity/Max Equity. Drawdown = 1-Equity Ratio)
Cuadro 3 Capacidad predictiva de las redes
| Estrategia | EP | Profit | ROI |
Desviación estándar de ROI |
Proporción Sharpe |
Promedio Drawdown |
Maximum Drawdown |
| Red-LEI-Estados Unidos | 1.81 | 5.50 | 0.05 | 0.01 | 3.79 | 0.18 | 1.11 |
| Red_LEI-México | 2.06 | 17.75 | 0.15 | 0.05 | 3.09 | 0.07 | 0.29 |
| Porcentaje derecho | Promedio porcentual derecho | Desviación estándar del porcentaje derecho | Pérdida total | Porcentaje de pérdida | 95% del intervalo confidencial del porcentaje promedio derecho | ||
| Red-LEI-Estados Unidos | 0.67 | 0.67 | 0.10 | 3.30 | 0.33 | 0.63 | 0.70 |
| Red_LEI-México | 0.67 | 0.64 | 0.08 | 5.13 | 0.43 | 0.62 | 0.67 |
También se calculó la proporción Sharpe, cociente conocido en el mundo financiero y cuyo comportamiento se asemeja al del EP:
Además, para ambas redes la prueba EP muestra que dentro de un nivel de más de 90% de confianza podemos rechazar la hipótesis nula de independencia (falta de capacidad predictiva) y por tanto aceptar la hipótesis de la capacidad de las redes utilizadas para anticipar las fluctuaciones de las economías de los Estados Unidos y México. Como evidencia complementaria obsérvese que la media del porcentaje de aciertos está por encima de 50% y su estrecho intervalo de confianza, también está bien por encima de 50%. La proporción Sharpe mayor que 1 indica que los vaivenes de la ganancia o pérdida (asociados al riesgo) son menores que el ROI (la ganancia).
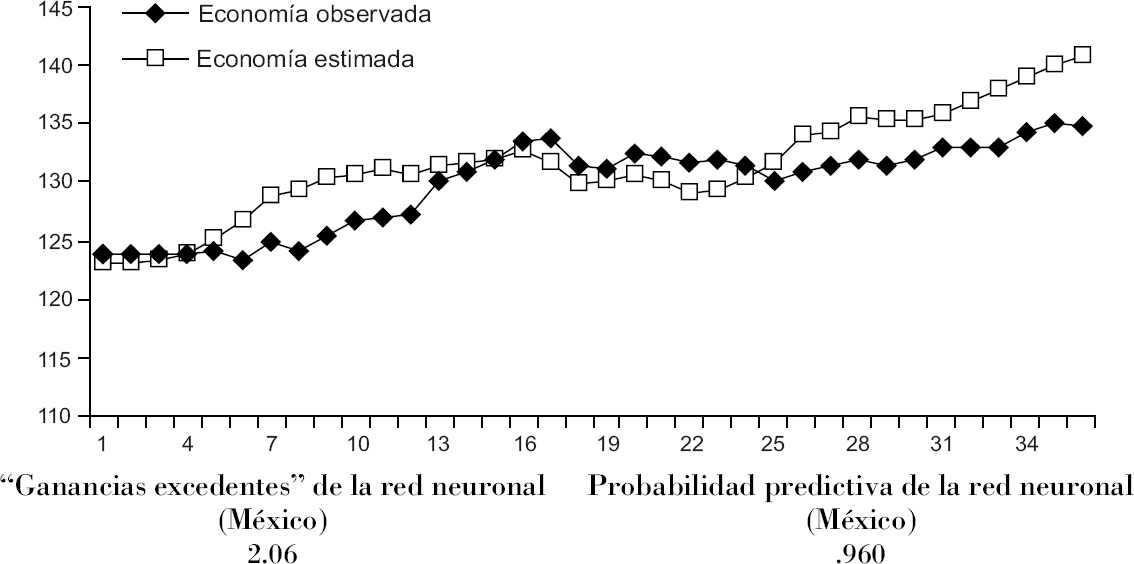
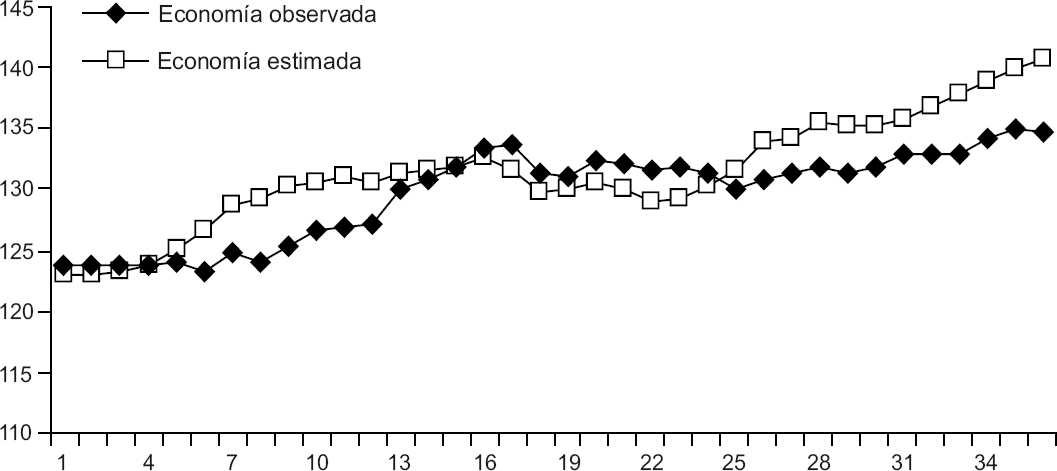
En la gráfica 3 mostramos las curvas de la economía observada y estimada por la red neuronal para México. Adviértase a continuación la adquisición congruente de rendimientos y la baja volatilidad de la curva patrimonio acumulado correspondiente a la gráfica 2 —que en realidad representa el “éxito predictivo acumulado” de la estrategia utilizada por la red para predecir el LEI de México—. Las mismas observaciones son pertinentes para el caso de los Estados Unidos.

2. Congruencia histórica de la capacidad predictiva de la red
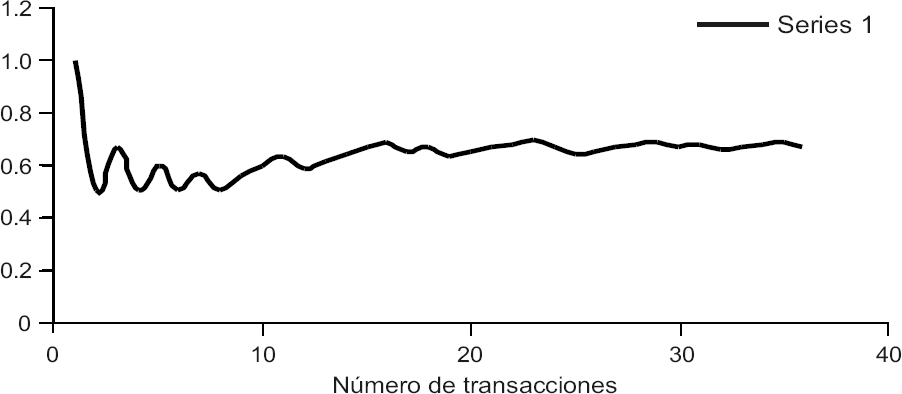
Las gráficas 6 y 7 muestran que la capacidad predictiva se mantiene a lo largo del tiempo dentro del periodo extramuestral. El porcentaje de aciertos mantiene una pendiente cercana a 0, lo cual sugiere que las redes mantienen a lo largo del tiempo una precisión constante en la proyección de la dirección del LEI.

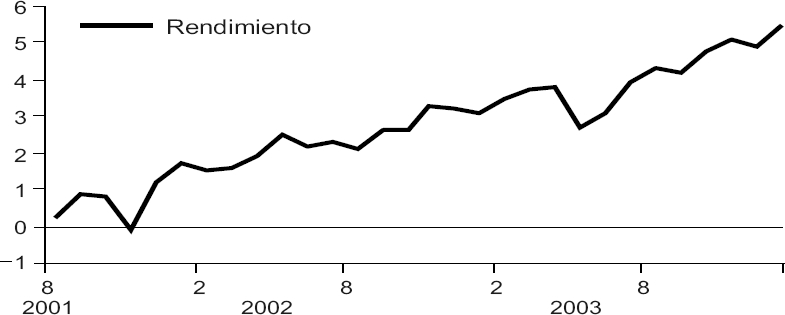
Gráfica 5 Estados Unidos: Curva de patrimonio acumulado de la estrategia de compraventa de la red neuronal. (Agosto de 2001-agosto de 2003)
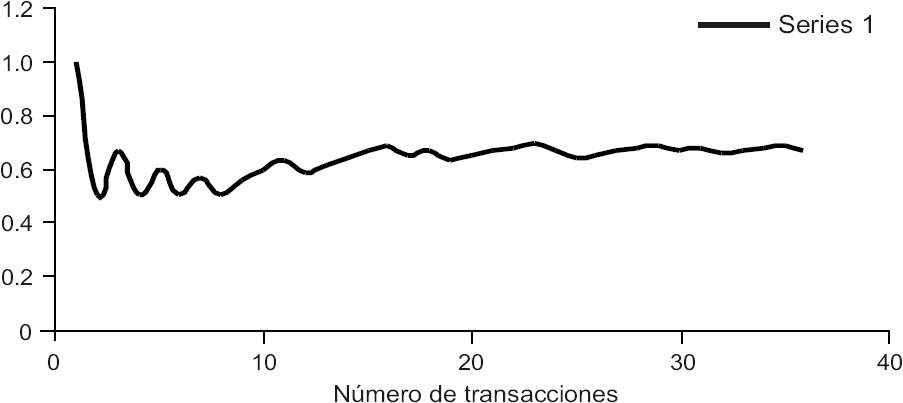
3. Comparación de la capacidad predictiva de la red neuronal con la de una regresión múltiple equivalente
Las regresiones múltiples tuvieron las mismas entradas (inputs) que las redes (esto es, los mismos rezagos del índice de bonos y de acciones) y fueron efectuadas con base en primeras diferencias con



Cuadro 4 Resumen de los resultados comparativos de la red neuronal vs regresión
| Red neuronal vs regresión (según Anatolyev) | Ganancias excedentes de la regresión | Probabilidad predictiva de la regresión | Ganancias excedentes de la red neuronal | Probabilidad predictiva de la red neuronal |
| México | 1.93 | .897 | 2.06 | .960 |
| Estados Unidos | 1.67 | .907 | 1.81 | .929 |
Conclusiones
Las redes neuronales tienen capacidad predictiva significativa y esa capacidad predictiva es estable durante un intervalo que queda por determinar. Esto significa que las redes neuronales debidamente entrenadas son una fuente valiosa de información al momento de invertir en una empresa ubicada en una economía foránea o local. Debido a que las entradas se rezagaron un mínimo de cuatro meses para la economía de los Estados Unidos y un mínimo de 15 meses para la mexicana, las redes proyectan con bastante anticipación, lo cual es conveniente para algunas estrategias de inversión.
La hipótesis comportamentalista de la relación entre los mercados de capitales maduros (el sentimiento de prosperidad) y la propensión al gasto —relación que serviría para explicar el crecimiento de la economía— obviamente no se aplica a países con mercados de capitales incipientes que afectan y son afectados de manera directa sólo por un grupo de inversionistas relativamente pequeño. En este trabajo los mercados de capitales mexicano y estadunidense sirven de entrada a redes que proyectan con éxito la economía de esos países. Este estudio confirma la pertinencia de los mercados de capitales como predictores del comportamiento macroeconómico y del de los ciclos de negocios (Wheelwright y Makridakis, 1985; Stock y Watson, 1989).

