











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkIntroducción
La no linealidad inherente en los datos financieros y económicos ha sido observada por mucho tiempo; algunos investigadores han reconocido las limitaciones de técnicas econométricas que suponen una relación lineal como una aproximación. El supuesto de linealidad se ha usado convenientemente en parte porque el coeficiente estimado de estos modelos es de fácil interpretación y porque la aplicación numérica era complicada en su momento.
Avances recientes en materia tecnológica computacional han relajado las restricciones o complejidades en calcular modelos y han llevado al desarrollo de técnicas econométricas no lineales como la regresión de regime-switching de Markov. Además, investigadores en la comunidad financiera recientemente han adoptado otras aproximaciones y técnicas de estimación no lineales usadas en las ciencias físicas y biológicas como son las redes neuronales artificiales (RNA).1 Aunque son sólo un tipo de los múltiples instrumentos estadísticos para modelar relaciones no lineales, parecen estar rodeadas de mucho misterio y algunas veces de una mala interpretación.
Debido a que tienen sus raíces en la neurofisiología y las ciencias cognoscitivas, las redes neuronales artificiales suponen cualidades similares al cerebro, como son la capacidad de autoaprendizaje, capacidad de encontrar solución a problemas, y finalmente cognición y autoconocimiento. Por otra parte, las redes son a menudo consideradas como una "caja negra" que produce predicciones con mucha exactitud con sólo un pequeño modelamiento.
Las redes neuronales son modelos elaborados para simular el funcionamiento del cerebro y, en particular, la manera como éste procesa información. Dentro del contexto del análisis de series de tiempo se clasifican como modelos no lineales capaces de realizar conexiones entre los valores pasados y presentes de una serie de tiempo y extraer estructuras y relaciones escondidas que rigen el sistema de información.2 El atractivo de este enfoque, inspirado en la neurología, es su capacidad para aprender, es decir, para identificar dependencias con base en una muestra finita, de manera que el conocimiento adquirido pueda ser generalizado a muestras no observadas (Herbrich et al, 1999). Aunque, como señalan Kuan y White (1994), las redes neuronales y sus algoritmos de aprendizaje asociados están todavía lejos de ofrecer una descripción acertada de cómo funciona el cerebro, éstas se han constituido en un marco de modelación muy poderoso e interesante, cuyo potencial ha sido comprobado en diversas aplicaciones en todas las ciencias.
Muchos investigadores son atraídos por ese enfoque porque las redes neuronales no están sujetas a supuestos restrictivos como la linealidad, que suele ser necesaria para la aplicación de los modelos matemáticos tradicionales; con este criterio han funcionado muy bien para la valoración de activos derivados y la determinación de cobertura,3 ya que la fórmula de Black y Scholes está restringida a la normalidad de sus variables.
La popularidad de las redes para manejar datos e información compleja puede haber contribuido considerablemente a la difusión e implantación de modelos de redes neuronales en la economía y la econometría. Herbrich et al (1999) señalan tres campos principales en los cuales se ha centrado la aplicación de estos modelos en la economía: i) clasificación de agentes económicos, ii) pronóstico de series de tiempo y iii) modelaje de agentes con racionalidad limitada. El segundo campo ha sido de particular importancia. Franses y Van Dijk (2000) señalan que anualmente se publican alrededor de 20 o 30 artículos relacionados con el pronóstico y modelación, con el uso de las redes neuronales, de precios de acciones, tipos de cambio, tasas de interés, producto interno bruto y la inflación, entre otros temas. Tanto estos autores como Tkacz y Hu (1999) atribuyen la creciente boga de estos modelos, y su aplicación a series de tiempo, a la capacidad que poseen para permitir relaciones no lineales muy generales entre las variables. En efecto, esto quiere decir que con suficientes nodos o capas ocultas (que se definirán líneas abajo), y en ciertas condiciones, una red neuronal puede aproximar cualquier relación, aun no lineal, no importando cuán extraño ni qué tipo de no linealidad.4 Asimismo, las RNA son un instrumento importante en la modelación de variables en las cuales la existencia de un modelo estructural no es clara, pues no parten de supuestos a priori de los datos para el pronóstico y todo lo que de ellas puede decirse es inherente a las observaciones (Evans, 1997). El objetivo de este trabajo es modelar el comportamiento de los índices accionarios de 25 países, incluido el Dow Jones y el Standard & Poor en los Estados Unidos, para encontrar regularidades entre ellos, contrastándolos con los modelos tradicionales autorregresivos según la metodología Box-Jenkins. Este estudio es una opción al realizado por Johnson y Soriano (2004), que a diferencia de encontrar asimetrías en los rendimientos de los índices bursátiles busca la no linealidad en esta variable.
El estudio se divide en tres secciones: la sección I muestra una revisión de la bibliografía acerca de las redes neuronales; la sección II presenta la metodología y datos que se utilizará en el trabajo; el análisis de los resultados se aborda en la sección III. Finalmente se presenta las conclusiones del estudio.
I. Motivación
Desde el hoy famoso enunciado de Keynes (1936) acerca de que la mayoría de las decisiones de los inversionistas "pueden sólo ser tomadas como resultado de espíritus animales, es decir, de un impulso espontáneo de actuar más que de permanecer quieto, y no como resultado de un promedio ponderado de beneficios multiplicados por probabilidades cuantificadas", muchas investigaciones han sido dedicadas a examinar la eficiencia en la estructura de precio de mercado de las acciones. Fama (1970) en su trabajo seminal establece que los rendimientos de los activos financieros, con particular hincapié en las acciones, no pueden ser predecibles. Aquí nace la noción de la hipótesis de mercados eficientes (HME).
El concepto que encierra la HME es que los precios de los activos incorporan toda la información pasada y presente disponible hasta el momento de la valoración que se haga del mismo,5 por lo cual en un contexto de racionalidad implica que no es posible que un agente obtenga rendimientos anormales. Situándonos en el horizonte a lo largo del tiempo, ningún inversionista privado o institucional podría ganarle al mercado. Dado esto, la mejor representación de la capacidad predictiva se consigue con un camino aleatorio o random walk (RW) representado de la siguiente manera:
en la que Pt es el precio de la acción en el periodo t y εt es un choque aleatorio que se distribuye (μ, σ2). En otras palabras, el cambio en el precio de una acción es aleatorio, y por ende, impredecible.
Sólo la llegada de nueva información o noticias produciría un cambio en el precio,6 y por ende en el rendimiento del activo. Esta información no puede ser inferida de la información del pasado, por lo cual es independiente del tiempo e impredecible. Sin embargo, muchos han sido los esfuerzos de encontrar discrepancia entre los conceptos de eficiencia y predictibilidad. La causa radica en la existencia de un componente estructural o de largo plazo del mercado que es posible captar y proyectar en el tiempo. Keim y Stambaugh (1986) encuentran significación estadística de predictibilidad en los precios de acciones basado en ciertas variables. Lo y MacKinlay (1987) prueban la hipótesis de random walk y encuentran sólida prueba que la rechaza.
De acuerdo con lo anterior hay un creciente interés en construir modelos que permitan caracterizar el precio de la acción o su rendimiento. Debido a que en años anteriores el avance econométrico y computacional era limitado, éstos se enmarcaban en la determinación de modelos lineales, como las series de tiempo univariado (Box y Jenkins, 1970).
Dado los mayores avances que muestra la econometría y en particular la financiera en el estudio de series de tiempo, el uso y estimación de relaciones económicas no lineales hacen atractiva la implantación de las redes neuronales artificiales. Este estudio profundiza el presentado por Shahmurove y Witkowska (2000) en el sentido que intenta adicionar a las predicciones, las regularidades no lineales. Además cubre una amplia gama de países, incluyendo los menos desarrollados, y tiene un amplio periodo muestral. Asimismo se incluyen pruebas para determinar el rendimiento de las predicciones.
1. Revisión
Ahora, antes de ir a un análisis formal de las redes neuronales, se dará un ejemplo financiero sencillo7 que motiva el interés en modelos no lineales. Este ejemplo, sugerido primero por Merton, incluye la asignación de activos o riqueza cada mes entre los pagarés y el índice S&P 500, que empieza en enero de 1926 y termina en diciembre de 1993. Si tenemos un dólar de inversión en pagarés reinvertido mes a mes, crece hasta 12 dólares al final de los 67 años, mientras que la misma inversión colocada en el S&P 500 rendiría unos 800 dólares. Qué sucede si se tiene las habilidades de un perfecto market-timing de manera que al inicio de cada mes se sabe con seguridad qué clase de activo tendría un mejor desempeño. Si se empieza con la misma inversión de un dólar en enero de 1926 y se cambia cada mes entre pagarés o S&P 500 según la mejor opción se tendría la cantidad de 1 038 317 644 dólares. Lo anterior no es un error tipográfico, con habilidades perfectas en la asignación de activos, un dólar habría crecido a más de mil millones de dólares.
Por supuesto, nadie tiene las capacidades perfectas para asignar activos; por tanto, el rendimiento en la práctica será una pequeña fracción de 1 038 317 644 dólares. Sin embargo, no se toma una fracción del monto anterior para poder superar los 800 dólares que redituó el S&P 500. Este es quizá el mayor aspecto en la administración que agobia a los inversionistas: aun una pequeñísima ventaja en un mercado muy competitivo se puede traducir en atractivos rendimientos con el tiempo. Descubriendo y modelando no linealidades se debe proporcionar estas pequeñas ventajas.
Las redes neuronales intentan resolver de manera eficiente problemas que pueden encuadrarse dentro de tres extensos grupos: optimación, reconocimiento y generalización.8 Éstos abarcan un gran número de situaciones, lo que hace que el campo de aplicación de las redes neuronales en la gestión empresarial sea muy amplio.
Dentro de los problemas de optimación se intenta determinar una solución que sea óptima, aplicando generalmente redes neuronales realimentadas, como el modelo de Hopfield (1982), redes de adaptación probabilística, de memorias autoasociativas, que aprenden a reconstruir las pautas de entrada que memorizaron durante el entrenamiento. En la gestión de empresa, son decisiones de optimación hallar los niveles de tesorería, de producción, política de inventario, construcción de carteras óptimas, etc. Asimismo, en los problemas de reconocimiento se entrena una red neuronal con insumos como sonidos, números, letras y se procede a la fase de prueba presentando esas mismas pautas con ruido. Este es uno de los campos más fructíferos en el desarrollo de redes neuronales y casi todos los modelos: perceptrón, también redes de Hopfield, mapas autoorganizados de Kohonen,9 etc., han sido aplicados con mayor o menor éxito. Finalmente en los problemas de generalización la red neuronal se adiestra con unas variables de entradas y la prueba se realiza con otros casos diferentes. Los problemas propios de la generalización son los de clasificación y predicción.
White (1992) y Kuan y White (1994) popularizaron el enfoque de redes neuronales en economía. Desde entonces ha sido utilizado para analizar decisiones para otorgar créditos bancarios (Witkowska, 1999; Olmedo y Fernández, 1997; Zurada, 1998), clasificación de obligaciones tanto internacionales como locales (Singleton y Surkan, 1995), adquisiciones y fusiones corporativas (Fairclough y Hunter, 1998), detección de quiebras (bankruptcy) (Shah y Murtaza, 2000; Tan y Dihardjo, 2001),10 resultados corporativos (Wilson, Chong y Peel, 1995) y proyecciones macroeconómicas y financieras (Moshiri et al, 1999; Martin et al, 1997; Qi, 1999; Yao et al, 1999; El-Shazly y El-Shazly, 1999, y Fu, 1998).11 Wu y Wang (2000) usan una red neuronal para clasificar postulaciones de crédito en grupos factibles de ser aceptados o rechazados, y compara los resultados del modelo con las decisiones reales tomadas por los analistas de crédito. Ellos encuentran que las redes neuronales poseen una capacidad predictiva superior y que son muy útiles para mejorar las decisiones de otorgamiento de créditos.
Son todavía muy pocos los artículos que se encuentran publicados en revistas internacionales, aunque el Financial Analysts Journal o The Journal of Banking and Finance están empezando a recoger artículos relacionados con las aplicaciones de redes neuronales, alguno de ellos firmado por investigadores tan renombrados como Altman, Marco y Varetto (1994). Sin embargo, el primer artículo de redes neuronales que maneja información financiera fue realizado por White (1988), quien estudió la predicción de los precios de las acciones con un modelo de red neuronal. El modelo predecía mejor que el modelo de series temporales que utilizaba, un modelo lineal autorregresivo. El perceptrón multicapa es utilizado como análisis técnico, sin incluir variables fundamentales.
El enfoque de redes neuronales también ha sido muy útil en el campo del análisis de los precios de activos. Dada la alta frecuencia de la información diaria o intradiaria disponible su uso radica en la proyección de precios o rendimientos. En Chile hay un estudio (Bach y Hansen, 2002) que presenta predicciones de los rendimientos accionarios de ENDESA con información intradiaria, y demuestra la superioridad de estos modelos respecto a las opciones lineales. Otra aplicación en las finanzas es el estudio de efectos contagio entre diferentes índices. Lim y McNelis (1998) analizan la influencia que el Nikkei (Japón) y el Standard & Poor (Estados Unidos) tienen en el índice accionario australiano (Australian All-Ordinaries Index). Basándose en estadísticos que evalúan proyecciones, encontraron que los modelos de redes tienen un mejor desempeño que modelos estructurales tradicionales, como son los mínimos cuadrados y los de volatilidad lineal tipo GARCH-M.
Sin ir muy lejos, McNelis investiga la reacción en los precios de las acciones de Brasil a choques en los mercados de los Estados Unidos y de la América Latina, utilizando tanto modelos lineales como las RNA. Concluye que el mercado chileno, en contraste con el mexicano o el estadunidense, es el más determinante en los movimientos del índice accionario de Brasil. Al igual que los estudios anteriores demuestra una mejor confiabilidad en los modelos no lineales que los modelos de aproximación lineal o GARCH.
En la evaluación del comportamiento de las acciones en el mercado de valores, Aaltonen y Östermark (1993) comparan los tres modelos estadísticos más utilizados en la predicción del fracaso empresarial: análisis discriminante, logit y particiones recursivas con el perceptrón multicapa. En este estudio la variable dependiente, en otras palabras, calificar a la empresa positiva o negativamente, proviene de los mercados financieros, según el valor estimado de la β. La β de un valor es una medida del riesgo sistemático, es decir atribuible al movimiento del mercado en su conjunto y se calcula mediante regresiones que relacionan los movimientos del título con los del índice general de precios del mercado. Las empresas son agrupadas a priori como de alto o bajo riesgo, dependiendo de si el valor de su β está por encima o por debajo de la media de la β calculada para todas las empresas y todos los años. En los resultados se produce un empate, ya que todos los modelos fallan en la prueba de las mismas tres observaciones.
Yoon y Swales (1991) intentan dividir las empresas en dos grupos, según si sus acciones hayan tenido o no un buen comportamiento en los mercados financieros. Los datos incluyen información contable cuantitativa y cualitativa, pues examinan la carta que el presidente de la compañía envía a los accionistas. Comparan los resultados del análisis discriminante con los del perceptrón multicapa. El perceptrón sin capa oculta obtenía 65% de acierto, resultado similar al del análisis discriminante. Al añadir una capa oculta mejoran los resultados situándose en 77%. Añadir otra capa oculta no mejora significativamente la eficacia del modelo.
En la macroeconomía también se ha hecho presente la modelización con redes neuronales y se han enfocado sobre todo en las variables de tipos de cambio, demanda de dinero, inflación y crecimiento.12 Evidencia de no linealidades en información macroeconómica chilena puede encontrarse en McNelis (1996) y Soto (1995). Ambos examinan la demanda por dinero en Chile y encuentran una alta no linealidad en la demanda de dinero de largo plazo. Johnson y Vergara (2004) explican la política monetaria en Chile con una aproximación neuronal; concluyen que la balanza de cuenta corriente (o la diferencia entre el ingreso y el gasto) y la inflación no esperada son las variables con el mayor peso en la implantación de esta política.
Tkacz y Hu (1999), del banco central de Canadá, emplean información financiera y monetaria entre 1985-1998 para estimar una red neuronal artificial y proyectar el PIB; concluyen que esos modelos tienen una mayor capacidad predictiva (de 15 a 19% más precisos) que sus modelos contrapartes de regresión lineal y de series de tiempo y que la predicción en un horizonte de más de un año es mejor que las de corto plazo (por ejemplo, un trimestre).
2. Redes neuronales artificiales
Las redes neuronales son modelos estadísticos no lineales y no paramétricos utilizados principalmente para la clasificación y predicción de datos y variables. "No paramétrico" significa que no necesitan de supuestos paramétricos, como la normalidad en la distribución de los errores, que se presentan en los característicos modelos de regresión lineal. Es su intento de imitar algunos mecanismos de procesamiento de información que ocurren en el sistema nervioso de los organismos biológicos; como producto de la selección natural dichos mecanismos deben ser efectivos y eficientes.
Todos los modelos, ya sean lineales o no lineales, tienen como objetivo servir de aproximaciones útiles de la realidad, y nunca tienen la pretensión de sustituirla, por tanto las redes neuronales artificiales son simplificaciones útiles de las naturales. Biológicamente la unidad básica de procesamiento de las redes biológicas es la neurona. En términos generales, una neurona es una célula con tres partes principales: el cuerpo central que contiene el núcleo; unas extensiones o filamentos llamados dendritas las cuales reciben las señales o estímulos que llegan a la célula desde los censores o transductores, y una extensión de salida llamada axón que transporta el resultado del procesamiento de los datos hacia las dendritas de otras células. Si la suma ponderada de los estímulos de entrada sobrepasa cierto umbral, la neurona emite una señal de salida por el axón de magnitud fija. Las señales enviadas hacia la siguiente neurona hacen contacto en los puntos llamados sinapsis, entre el axón de una neurona y las dendritas de la siguiente; en estos puntos el estímulo se pondera; esto es, se puede dejar pasar, atenuar o inhibirse.
Actualmente, con el propósito de simplificar la función neuronal aproximamos la salida binaria, modelo introducido por McCulloch y Pitts en 1943, por una salida limitada, por ejemplo al intervalo para el cual podemos usar un modelo logit o al intervalo [-1,1], para lo cual utilizamos una función de tangente hiperbólica o una sigmoidal; estas funciones de trasmisión serán explicadas en la siguiente sección.

A diferencia de las redes biológicas, en las que cada neurona puede tener miles de conexiones con otras células, con las redes artificiales estas conexiones entre neuronas son pocas por las limitaciones en las técnicas de estimación y datos disponibles. Una red neuronal artificial común consiste en capas de neuronas que procesan y transportan la información de la entrada a la salida. En la primera capa todas las neuronas reciben los datos de entrada, los ponderan por sus coeficientes de entrada, restan el umbral, por ejemplo, la constante en el logit, y pasan el resultado a cada una de las neuronas de la capa siguiente. La salida final puede hacerse por medio de una sola neurona, o de manera lineal ponderando y sumando las salidas de las neuronas de la última capa, más una constante si se considera necesario. Las capas que se encuentran entre la entrada y la salida se conocen como capas ocultas.
Aunque existe una gran variedad de opciones de elaboración de redes, algunas con múltiples salidas (por ejemplo para análisis multivariado) y otras con realimentación de salida a entrada, la red característica suele tener una salida y una o dos capas escondidas con un número de neuronas cercano al número de variables de entrada.
El tema de la realimentación, tan importante en las redes biológicas, puede incorporarse en las redes artificiales al reestimar el modelo con la llegada de nuevos insumos. Esta reestimación, que obviamente se hace comparando la salida con la realidad observada, modifica los parámetros del modelo para ajustarse a las nuevas observaciones. De otra manera, la incorporación de ecuaciones de realimentación explícitas en el modelo introduciría complejidades adicionales en la estimación.
3. Especificación
Una red sencilla con dos variables de entrada x1 y x2, una capa escondida con dos neuronas y una neurona de salida, tendría la siguiente ecuación:
en la que β0 y α0 son los niveles de umbral (la constante) de cada neurona. Como puede observarse, la salida es un logit, lo cual muestra una expresión no lineal, o también se podría especificar un logit de logits, sobre todo si el número de capas y neuronas aumenta.
Analíticamente, una red neuronal puede ser representada por la expresión (1), en la que y es la variable dependiente (que podría ser un vector de variables), yj para j = 1, 2..., son variables independientes o exógenas, y f representa a una función no lineal.
En el modelo de regresión lineal, f representa una función lineal, pero en esta estructura de redes f puede ser cualquier forma no lineal.
Consideremos la estructura tradicional de una red neuronal, que se alimenta hacia delante (feed-forward) y que se presenta en la Figura 2. Una red neuronal tradicional consiste en una colección de insumos (inputs) y neuronas procesadoras de información, arregladas e interconectadas por capas conocidas como capa de entrada (input layer), capa escondida (hidden layer) y capa de salida (output layer). La capa de entrada sólo recibe información sin procesarla. Una vez que esta información haya pasado a la capa escondida, ésta es procesada y analizada, y posteriormente trasmitida a la capa de salida mediante funciones matemáticas de transferencia, que son funciones de las neuronas procesadoras que definen las variables de salida. Para facilitar su comprensión, y según la figura, suponga que tenemos cuatro series de tiempo (x1, x2, x3, x4)para explicar nuestra variable dependiente y. Cada nodo neuronal se une por medio de una función matemática:
en la que ωij representa el parámetro entre insumo i y neurona j. La función f corresponde a la función de transferencia, modelada como se dijo líneas arriba, una función sigmoidea o tangente hiperbólica, representada respectivamente por:
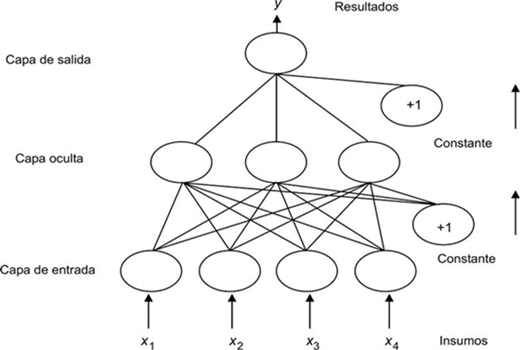
Al decidir resolver un problema mediante las redes neuronales tenemos que optar por la estructura que mejor se adapte a dicho problema. Relacionado con cada estructura está el tipo de aprendizaje por utilizar, el cual puede ser supervisado, no supervisado o tal vez una combinación de ambas (aprendizaje híbrido). Además de la decisión de tipo de aprendizaje es necesario decidir la manera sistemática en que se van a analizar los pesos o ponderadores.
Con el aprendizaje no supervisado la variable final no se define y la red clasifica los insumos de acuerdo con las características del problema por resolver. Los modelos planteados aquí suelen ser simples monocapas y con algoritmos sencillos y rápidos, más próximos a la biología. Con el aprendizaje supervisado, la segunda metodología, por mucho la más utilizada, la red se prueba con los insumos y el resultado, lo que permite un procedimiento de aprendizaje que minimiza el error entre los valores proyectados y efectivos de la variable endógena.
La metodología utilizada en la estimación se denomina back-propagation (BP), y calcula la diferencia entre valores observados y proyectados desde la última capa, propagando hacia atrás los errores de predicción ponderados. La ponderación estándar usa el método de gradiente descendiente.
4. Aprendizaje por propagación hacia atrás con métodos de gradiente
Definamos el error cuadrático de una neurona por:13
en el que el subíndice p se refiere a la pauta u observación
pth, y representa el valor actual o deseado de la variable
dependiente y ŷ indica la predicción de la neurona. La ecuación (5) determina finalmente al
término de error general denotado por
El cambio en los ponderadores para cualquier neurona será proporcional al efecto del peso desde esta neurona en la diferencia previa εp. Este cambio se expresa por la siguiente ecuación:
Similarmente, la contribución de la suma ponderada de los insumos respecto a la proyección de la red desde cualquier neurona está dada por:
Para la unidad h de la capa escondida conectada a la neurona n, esta contribución estará dada por:
Una vez especificado el modelo, la estimación consiste en escoger los valores de las ponderaciones (coeficientes) y el umbral (constante) para cada neurona (logit). Por la naturaleza no lineal de la ecuación, la estimación de las redes neuronales debe hacerse por algún método de optimación numérico. Muchos de ellos son, en esencia, métodos de mínimos cuadrados no lineales.
Uno de los métodos más populares es el llamado de propagación hacia atrás (back propagation o delta method), que consiste en partir de coeficientes y umbrales iniciales (que pueden ser arbitrarios) y calcular el error entre la salida estimada y el valor verdadero, y usar este error para devolverlo por la red, ajustando los coeficientes y umbrales de las neuronas de las capas por medio de un algoritmo un poco ad hoc. Lo mismo se hace para la segunda observación de la muestra, luego para la tercera y así sucesivamente, hasta completar la muestra. Después se repite el proceso hasta lograr un juego de coeficientes que minimicen la suma de errores al cuadrado. Existe software especializado en el mercado para aplicar este algoritmo de propagación hacia atrás.
Sin embargo, si el tamaño de la red y la muestra lo permiten la estimación puede realizarse por medio del software de mínimos cuadrados no lineales, disponible en la mayoría de los programas estadísticos. Casi todos los programas econométricos incorporan algunos algoritmos de estimación numérica adecuados para este propósito. La estimación requiere paciencia, ya que no siempre converge fácilmente, pues depende de manera decisiva de los valores iniciales escogidos.
La estimación puede requerir un buen número de iteraciones, 100, 1000 o 5000 son comunes, de manera que los criterios de parada del algoritmo deben ajustarse apropiadamente o, en su defecto, debe reiniciarse la iteración.
5. Evaluación
El objetivo principal de las redes neuronales no es el modelaje estructural, ni siquiera la forma reducida, sino la predicción, por lo cual se puede tolerar algún grado de redundancia o específicamente multicolinealidad. La capacidad predictiva es más importante en la evaluación que las pruebas t, los sobrecoeficientes individuales, que con frecuencia no resultan todos significativos. El r2, el error estándar, la verosimilitud estimada y criterios como los de Akaike, Schwartz o el de Hannan-Quinn sirven de guía, de manera simultánea a las pruebas de significación individual.
Es recomendable utilizar parte de la muestra para la validación cruzada; esto es, usar por ejemplo 75% de la muestra para estimación y el resto para probar y evaluar la capacidad predictiva. Deben calcularse medidas de predicción, como la raíz del error cuadrado medio o el error cuadrado medio absoluto. En lo referente a la estabilidad del modelo puede estimarse omitiendo sucesivamente algunos periodos finales de la muestra o agregando observaciones que no hayan sido utilizadas antes en la estimación.
El hecho de que la estimación no converja no implica que sea imposible mejorarla. Comenzar con otros valores iniciales, al menos en algunos coeficientes, puede mejorar la estimación o bien validarla. Asimismo el hecho de que la estimación dé un buen ajuste en la muestra no forzosamente garantiza un buen desempeño predictivo.
II. Metodología y datos
En diferentes mercados de valores de los países estudiados, Reuter y Bloomberg han sido la fuente del siguiente estudio. Los datos utilizados son los diversos índices de 27 países del mundo incluyendo el Standard & Poor 500 y el Dow Jones en los Estados Unidos. La frecuencia es diaria desde enero de 1990 hasta finales del primer mes de 2004. Los datos no encontrados (debido a días feriados nacionales y religiosos) son remplazados por la observación que la precede. La elección de una periodicidad semanal se justifica para minimizar los sesgos originados por el efecto día de la semana (Lo y Mackinlay, 1987; LeBaron, 1993) y el efecto fin de semana (véase Zhang y Hu, 1998).
Dado que se necesita las rentabilidades semanales, éstas se calcularon como la diferencia en logaritmo natural del valor de cada índice para cada semana consecutiva:
en la que rt es la rentabilidad semanal e It es el índice al final del día. Esta transformación ha llegado a ser común en el análisis financiero ya que permite obtener una serie estacionaria; puede ser interpretada como una rentabilidad y, además, se presenta como una variable de mayor interés para los operadores financieros (Brooks, 1996). No obstante, también se reconoce la posible ampliación del ruido en la serie (Soofi y Cao, 1999).
El Cuadro 1 muestra los siguientes resultados estadísticos: desviación estándar, Skewness, curtosis y el Jarque-Bera con la probabilidad respectiva de que este último exceda el valor observado con la hipótesis nula. Un valor cercano a 0 permitiría rechazar la hipótesis nula de que la serie analizada proviene de una distribución de densidad normal.

La primera conclusión es que los rendimientos muestran un alto valor en la curtosis, excediendo en muchos casos valor de 3, lo que sugiere que los rendimientos presentan leptocurtosis, una característica propia de los rendimientos de precios de activos financieros. El 50% de los datos presenta un valor negativo en el indicador del sesgo, lo que revela que la distribución tiene una larga cola hacia la izquierda. Finalmente la prueba de normalidad Jarque-Bera indica que no hay evidencia estadística para aceptar el supuesto de normalidad en los rendimientos.
El modelo de red neuronal adoptado en este artículo es del tipo feedforward (de alimentación hacia adelante) que considera una capa oculta, la cual tiene la siguiente forma:
en la que y es el resultado del modelo. Existen J insumos o inputs que alimentan la red, representados por xt. La función g(·) es conocida como la función de activación o transferencia en la capa oculta; aunque esta ecuación de transferencia puede ser especificada de otras maneras como lo mencionamos en la sección anterior, este estúdio escoge la forma funcional logística representada por g(z) = 1/(1 + e-z). La red tiene H neuronas en la capa escondida con pesos o intensidad de conexión definidos por el parámetro Фh. Todas las variables de entradas ingresan como argumentos en estas neuronas y sus influencias son medidas por los pesos de entrada, αhj. Se han especificado modelos univariados en los que las variablesd e entrada son los valores rezagados de la variable dependiente. El resultado es el rendimiento semanal que se indicó líneas arriba.
Como el motivo principal de este estudio es encontrar regularidades en los diferentes índices accionarios, se ha empleado hasta cinco rezagos con el propósito de observar si el comportamiento al incluir variables rezagadas es el mismo en cada país. Asimismo se ha asumido que los rendimientos son procesos puramente lineales, los cuales difieren de los modelos de Stock y Watson (1999), y los de Franses y Van Dijk (2000), quienes incluyen componentes lineales.
El tratamiento de los datos merece una breve explicación, ya que al utilizar funciones logits el resultado de las rentabilidades esperadas debería encontrarse en el rango (-∞, ∞); sin embargo, para evitar estos inconvenientes se han transformado las variables para convertirlas en valores logísticos y de esta manera acotarlas.
Con el fin de mostrar la superioridad de las RNA también se estimaron modelos lineales regresivos, tanto en sus variables como en sus términos de errores, con la metodología propuesta por Box-Jenkins. La evaluación empírica de las predicciones obtenidas por las RNA se hizo sobre una base extramuestral que partía del 30 de enero hasta el 16 de julio de 2004. El desempeño relativo de los modelos fue medido por el número de predicciones correctas del signo de variación de los diferentes índices, para lo cual se aplicó la prueba de certeza direccional propuesto por Pesaran y Timmermann (1992) y que se detallará a continuación.
A lo largo del trabajo se hace predicciones puntuales de la variación semanal con frecuencia diaria que tendrán los índices. Sin embargo, para poder evaluar el rendimiento de las redes neuronales en adelante se ha simplificado en sólo medir la variación que tendrá la rentabilidad, es decir, si va al alza o a la baja. La prueba establecida por Pesaran y Timmermann confirma la exactitud de una predicción cuando el objetivo de análisis es la predicción correcta del signo.
Sea xt = Ê (yt/Ωt-1) el predictor de yt formado con respecto a la información disponible en t -1, Ωt-1, y supóngase que hay n observaciones en (yt y xt). Esta prueba está basada en la proporción de veces que la dirección del cambio de signo en yt es correctamente predicha en la muestra y, además, no requiere información cuantitativa de las variables si se usa sólo información de los signos de yt y xt. Si los signos entre estas dos variables coinciden aumenta el poder de la red, en caso contrario, aumenta el error de la predicción. Se introduce las variables indicadores yt = 1 si yt > 0 y 0 de otra manera. Lo mismo aplica a la variable xt. Además, se define Zt = 1 si ytxt > 0 o 0 en caso contrario.
Sea Py =
Pr(yt>0) y
Px =
Pr(xt>0) y
expresemos
En el supuesto de que yt y xt
sean independientemente distribuídas (por ejemplo xt no
tiene poder de predicción en yt), n
En el caso general, esta prueba no paramétrica puede basarse en un estadístico estandarizado
en el que
y
El último término en la expresión
III. Resultados
Los Cuadros 2-6 presentan los resultados de las redes univariadas con los diferentes rezagos de los 27 países estudiados. Los modelos determinados (especificación 1) han usado en la capa oculta dos neuronas, como aconseja la mayoría de la bibliografía del tema (Zekić, 1998; Trippi y De Sieno, 1992). Los valores rezagados parten de un periodo hacia atrás hasta el quinto y se utilizan los mismos modelos con el fin de encontrar regularidades entre ellos.
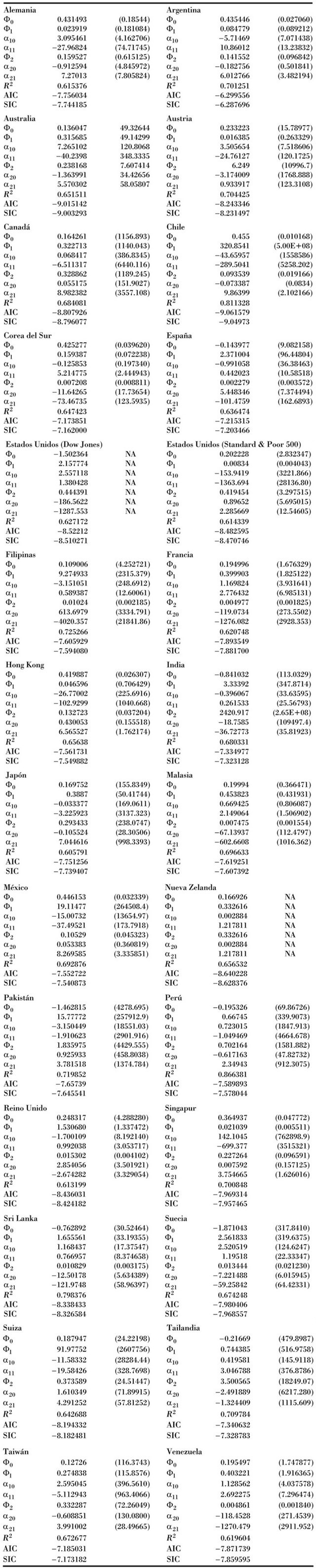




Los valores muestran el modelo escogido por el criterio Akaike y el r2. Analizando este último se observa que el mayor rendimiento lo tiene Perú con 89.60%, seguido de Chile y Sri Lanka con 84.39 y 83.22% respectivamente. En el caso contrario los peores resultados los obtuvieron Japón con 64%, Reino Unido, 65.06%. En los Estados Unidos su índice Dow Jones alcanzó 65.40%, superado un poco por el Standard & Poor 500 con 66.27%. Sin embargo, todos entran en un rango entre 64 y casi 90%, lo cual demuestra una buena relación utilizando las redes neuronales artificiales.
Asimismo, como se espera, el criterio Akaike nos muestra que los mejores modelos son los que utilizan cinco rezagos en la implantación de las redes. Este criterio predomina en todos los países, por lo cual se podría concluir en este estudio que el uso de más rezagos aporta una mejor modelización de las RNA de índices accionarios.
Como el valor de convergencia utilizado en los modelos propuestos ha sido muy pequeño (entre 1 × 10-5 y 1 × 10-8) se han necessitado aproximadamente entre mil a 6 mil iteraciones, dependiendo de la complejidad de las redes, y se espera que los mínimos obtenidos sean globales ya que para cada uno de ellos se han tomado distintos valores iniciales, que no tienen diferencias.
Con la finalidad de realizar una diferencia con los modelos presentados se ha realizado series de tiempo autorrezagado (especificación 2), según la metodología presentada por Box-Jenkins en 1970, utilizando los propios valores pasados que toman los mismos periodos que los utilizados en las RNA. También se encuentran que utilizando cinco rezagos los modelos obtienen una mejor valoración; sin embargo, los criterios Akaike y Schwarz son menores que los encontrados con las redes y los coeficientes de determinación también son inferiores. Los resultados se muestran en el Cuadro 7.

Para demostrar la superioridad de la redes neuronales se comparó las predicciones extramuestrales entre el mejor modelo, es decir la red neuronal de cinco rezagos, con un modelo simple ARIMA (1,1,1). La muestra con que se estimaron los modelos finalizaba el 29 de enero de 2004 y las predicciones dinámicas de los rendimientos comprendían un periodo desde el 30 de enero hasta el 16 de julio de 2004, con 121 observaciones. Las predicciones fueron de carácter dinámico, es decir, no se incluyeron los valores reales para reformular los modelos.
Con el fin de evaluar los resultados se contrastaron los valores estimados por los dos modelos para cada país con las rentabilidades reales. Se excluyeron Nueva Zelanda y Venezuela por disponibilidad de datos. La primera cambió la manera de composición de su índice original NZSE 40 a otro formado por 50 acciones. Si los datos reales concordaban con los estimados en su signo, se le asignaban valores de 1 y 0 en el caso contrario. Al final se promediaba la frecuencia de los aciertos con el total de las observaciones.
Los resultados obtenidos se muestran en el Cuadro 8; confirman que los aciertos de predicción de signo son mayores en las redes que en el modelo ARIMA en la mayoría de los casos. Chile muestra el menor porcentaje de error (94% de acierto) mientras que el menor valor lo tiene el Reino Unido con "apenas" 72%. Con los modelos ARIMA el mayor y menor porcentaje lo tienen Pakistán y Filipinas con 85 y 15%, respectivamente. Los únicos casos en los que el modelo simple lineal es mejor que las redes fueron Austria y Singapur, aunque la diferencia fue mínima. Así también, con mínimas diferencias en favor de las redes, tenemos los índices de Corea del Sur, México, Perú y Sri Lanka. Lo anterior es consecuencia de que los componentes residuales de estos países tienen gran ponderación en la explicación de sus valores. En el resto de los índices se observa que las redes neuronales artificiales tienen un mejor desempeño en la predicción del signo, es decir, movimientos al alza o a la baja.
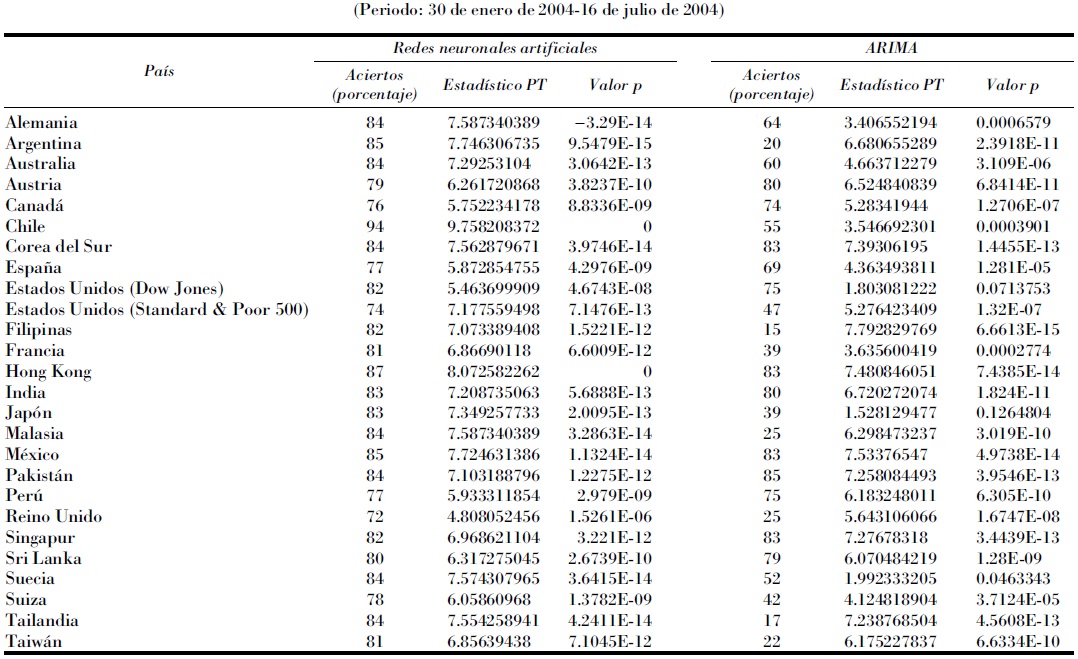
Cuadro 8 Cuadro comparativo entre la exactitud de las predicciones extramuestrales (porcentaje) obtenidas con las redes neuronales y el modelo ARIMA y las pruebas Pesaran y Timmermann
En el Cuadro 8 se observa también los resultados de la prueba de Pesaran y Timmermann, en la que se rechaza la hipótesis de que las variables reales y sus respectivas predicciones son independientemente distribuidas, que obtenidas en los estadísticos y sus valores p de probabilidad (pvalues) son superiores en las redes que los modelos ARIMA, con excepción de los casos de Austria, Filipinas, Pakistán, Perú, Reino Unido y Sri Lanka.
Debido al buen resultado obtenido con el modelo neuronal en la predicción de la bolsa chilena se podría pensar que se debe a un alto grado de inercia y larga regularidad; sin embargo, al observar la gráfica de la variación de su rentabilidad vemos que en el periodo de predicción hay múltiples cambios en la dirección de signo que es captado por las redes neuronales artificiales de excelente manera (Gráfica 1).

Conclusiones
La incapacidad de los modelos tradicionales para ajustar y predecir el precio y por ende la rentabilidad de la acción ha llevado a la búsqueda de nuevos modelos que sean capaces de percibir la dinámica de la serie. Ante esto surgen las redes neuronales artificiales, que tienen ventajas en varias dimensiones en relación con los métodos de análisis tradicionales. Primero, poseen la capacidad de analizar y aprender rápidamente pautas complejas y con un alto grado de precisión. Segundo, no están restringidas a la linealidad de las series, por lo cual se convierte en un instrumento econométrico muy poderoso. Finalmente, las RNA tienen un buen rendimiento con datos incompletos, característica que se encuentra en la mayoría de los mercados no desarrollados, lo que amplía las ventajas de los estudios e investigaciones.
Al utilizar 28 índices accionarios de países de diversas regiones se observó que las redes neuronales univariadas con cinco rezagos presentan un buen rendimiento predictivo en todos los países, e incluso en algunos de ellos su coeficiente de determinación llega a 90%, lo que puede ser un pobre avance en encontrar más evidencia que analice la hipótesis de los mercados eficientes.
Comparando con modelos lineales tradicionales se advierte que también en estos modelos la inclusión de más rezagos mejoraba la estimación; sin embargo, los valores de las pruebas de determinación con que uno puede comparar estos modelos versus los no lineales eran menores, demostrándose así que los otros modelos (no lineales) tienen un mejor rendimiento predictivo que los modelos tradicionales.
En la predicción dinámica extramuestral se observó que las redes neuronales artificiales fueron muy superiores a los modelos ARIMA tradicionales. Se encontró que en la mayoría de los casos el grado de exactitud fue mayor que sus símiles lineales. Chile es el país que mejor porcentaje obtuvo en aciertos de dirección de signo, es decir las redes neuronales tuvieron un mejor desempeño en pronosticar si el mercado iba a la alza o a la baja (94 por ciento).
Finalmente este estudio se puede extender en múltiples direcciones. Una de ellas es la ampliación a modelos neuronales multivariados, incorporando otras de variables tanto económicas como financieras, por ejemplo, índices accionarios de países vecinos en la misma red, y observar cómo aprenden ellos de la experiencia de la región. Con éstos se podría obtener un acercamiento mediante redes neuronales de los efectos causados por las crisis económicas con efecto mundial (crisis asiática, moratoria rusa, efecto tequila, entre otros).

