











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
PermalinkClasificación JEL: C82, O18, P44, R12.
INTRODUCCIÓN
La homogeneización y elaboración de bases de datos económicos ha sido una de las ideas que ha recibido considerable atención en los decenios recientes. Dicho auge ha sido promovido por la creciente demanda que supone la realización de estudios económicos, para los cuales la disponibilidad de datos homogéneos, tanto temporales como espaciales, es una cuestión vital que garantiza la utilidad y comparabilidad de las conclusiones alcanzadas en los diferentes estadios de la investigación profesional.
Los ejemplos son numerosos y todos ellos coinciden en ofrecer como insumo una base de datos amplia y homogénea para muy diversas categorías, de la cual se puedan desprender estudios más realistas. En economía, las más conocidas son las bases de datos de Summers y Heston, las cuales comprenden una gran variedad de series históricas para un conjunto muy amplio de países, además de que son actualizadas y revisadas de manera constante; los esfuerzos realizados por Barro y Lee, principalmente para tener una serie homogénea del capital humano de un grupo amplio de países; las estadísticas del Fondo Monetario Internacional; las cuentas de producción del grupo de países de la OCDE; las bases de datos de países y regiones europeas en el programa Eurostat, y las series históricas de Maddison, por citar sólo algunas. Todas ellas han sido usadas de manera amplia en los estudios de economía y han facilitado y posibilitado la comparación entre países que derivan en la mejora paulatina de sus resultados.
La estimación de datos ha sido analizada con gran detalle y es utilizada en numerosos trabajos que demandan una gran cantidad de información como insumo, por ejemplo el caso de los estudios que descansan en el uso de series temporales. Este tipo de tareas ha recibido gran apoyo en los Estados Unidos, donde la generación de datos se ha convertido en una tradición de alta rentabilidad para los investigadores que difícilmente se puede conseguir en otros países. El producto nacional bruto (PNB), por ejemplo, ha sido estimado para periodos sin información oficial en por lo menos cuatro ocasiones: Kuznets (1941, 1946) usa diferentes métodos para elaborar datos para el periodo 1869-1918 y Shaw (1947) acude a datos de los censos manufactureros y de otras fuentes nacionales para derivar estimaciones del producto para varios años censales a partir de 1860.1 En fechas más recientes Romer (1989) actualiza las estimaciones de Kuznets para igual periodo introduciendo una regresión que incorpora una tendencia temporal para captar los ciclos de la economía, y Balke y Gordon (1989) establecen una metodología para estimar el PNB en los años anteriores a las guerras mundiales, basado en un enfoque de "componentes".
En general, puede afirmarse que esta mayor preocupación por tener bases de datos homogéneas y mejoradas en el ámbito nacional se ha traducido en la posibilidad de concretar una mayor cantidad de estudios cross-country que anteriormente no era posible. Sin embargo, una conclusión que emerge de los resultados de numerosos estudios es que el análisis con base en regresiones entre países puede ser muy agregado todavía como para poder captar el comportamiento propio de ciertos fenómenos económicos. Por ejemplo, en crecimiento económico numerosos estudios han documentado la falta de solidez en las regresiones cross-country en diferentes bases de datos, periodos de estudio y tamaños de muestra, al proporcionar resultados diferentes de un mismo fenómeno, por lo general atribuido a la heterogeneidad de los países. En este sentido han sugerido elevar el análisis a un nivel mayor de desagregación, como el que constituyen las propias regiones de un país.2 Sin embargo, las investigaciones en este ambiente son frenadas frecuentemente porque, en general, las bases de datos están más limitadas que en el nacional para ofrecer suficiente evidencia empírica.
Es decir, mientras que en el ámbito nacional a menudo se cuenta con amplias bases de datos de carácter oficial y de gran confiabilidad para el manejo estadístico, que permite la aplicación adecuada de métodos econométricos, en lo regional la plétora de estudios científicos es muy restringida por la menor existencia de información. Esta barrera es todavía más acentuada en los países en desarrollo.
La presente investigación responde a esta inquietud en la economía, al contribuir al entendimiento de los fenómenos económicos regionales mediante la generación de información respecto al producto estatal de México no asequible en fuentes directas, con propiedades agradables y supuestos razonables que permiten recoger las fluctuaciones cíclicas inherentes en el conjunto de economías regionales del país. La escasez de información regional no es privativa de México, tampoco lo es de los países en desarrollo; es en buena medida una barrera latente en la mayoría de los países que con frecuencia condiciona la aplicación de técnicas econométricas dentro de este entorno.
En México la generación de información básica es decisiva hoy en día a nivel de entidad federativa.3 La información disponible condiciona el uso de algunas técnicas de análisis de reciente creación, como las de series temporales, ya que es muy limitada como para realizar estudios de mayor profundidad. Al respecto se tiene información del producto estatal sólo para los años censales (1970, 1975, 1980, 1985, 1993 y 1998) y a partir de 1993 para cada año de manera oficial. Esta información es organizada y publicada por el Instituto Nacional de Estadística, Geografía e Informática (INEGI), el organismo en México encargado de recabar, recopilar y organizar la información económica del país.4
Algunos esfuerzos previos en México para estimar la información son los trabajos de Appendini (1978), Unikel et al (1978) y Esquivel (1999), en los que se han elaborado series estatales para diferentes periodos, aunque con intervalos de 5 o 10 años. Entre los antecedentes más inmediatos también se cuentan los trabajos de Álvarez (1981), Puig y Hernández (1989) y Mendoza (1997).5 Los dos primeros apoyan las estimaciones en estudios econométricos que incluyen información de variables auxiliares (como la captación financiera de las entidades), mientras que el último utiliza un modelo matemático de interpolación y extrapolación de la distribución de las participaciones del PIB estatal.
Mientras que no existe información oficial de una serie del producto regional tan larga en México, la que derivamos está basada en supuestos plausibles del comportamiento a corto plazo de las economías estatales. Básicamente, generamos una secuencia homogénea del PIB estatal para cada año desde 1940 hasta 1992 y la enlazamos con la serie anual del INEGI que inicia en 1993, dado que son compatibles, para conformar una sola base uniforme. Para ello nos apoyamos en la información generada para los años de 1940, 1950 y 1960 en el trabajo de Appendini (1978),6 en una serie de producto estatal no oficial, en los censos económicos de 1970, 1975, 1980, 1985 y 1993 y a partir de este año en las series de producto estatal publicadas por el INEGI y, finalmente, en la serie de producto nacional desde 1940 también publicada por el INEGI.7
Convertimos esas bases de datos en una secuencia homogénea de estimaciones del PIB usando un procedimiento de regresión que estima la sensibilidad de los movimientos cíclicos del PIB estatal y del nacional. Usando esta sensibilidad estimada generamos la serie para cada uno de los años desde 1940. Para ello nos apoyamos en la metodología de estimación establecida en Romer (1989), basada en un enfoque de "indicadores" para pronosticar el producto de los Estados Unidos en un periodo en el que no existe información oficial. Sin embargo, el procedimiento seguido aquí se distingue del de Romer en dos importantes aspectos.
Primero, la variable empleada como regresor en la ecuación de estimación del trabajo de Romer es el valor del producto mercantil (el PNB sin los sectores de servicios), mientras que aquí usamos la variable producto nacional bruto. Romer selecciona esta variable como indicador por ser una información de la que se compone el PNB. La intención, por tanto, es realizar la estimación utilizando el indicador que más se aproxime a la variable por estimar. Lamentablemente, en nuestro caso no disponemos de información alguna relacionada con el PIB por entidad federativa. Esto nos obliga a tener que olvidar el referente "entidad" y pasar a uno territorial de referencia superior, es decir, el que constituye México. Cuando se trabaja a nivel agregado, la información que aflora es mucho mayor. Así, el INEGI publica el valor del PIB a precios constantes y corrientes para México desde 1895. Al ser esta una información compuesta por la agregación del PIB de los estados, nos será de utilidad para realizar la estimación que proponemos. Esto no implica, como se profundiza líneas abajo, que se imponga la misma tendencia nacional a la estatal. Por lo contrario, la clave del método reside en que permite discriminar los comportamientos cíclicos de cada región al captar su propia tendencia en la ecuación de regresión estimada.
Segundo, a los pronósticos calculados de esta manera aplicamos el método de conciliación transversal de errores propuesto por Van der Ploeg (1982) para el ajuste apropiado de datos de la contabilidad nacional que han tenido un proceso de estimación. Es decir, ajustamos las estimaciones preliminares distribuyendo los residuos mediante un procedimiento de optimación. Los resultados finales muestran que el ajuste de las series conciliadas de esta manera es pertinente para la obtención de un balance congruente de las cuentas de producto estimadas.
El resultado de este proceso es la disposición de una serie histórica homogénea para cada uno de los 32 estados del país, que permite realizar estudios regionales con un grado mayor de congruencia y confiabilidad a los obtenidos mediante bases de datos quinquenales o de periodos de información muy cortos, que en algunos casos no llegan a ser compatibles.
Debido a que la información usada para generar las 32 series del PIB estatal fue transformada a precios constantes de 1993, las series producidas también se hallan a precios de 1993, lo que permite comparaciones en el tiempo respecto al ajuste de cada secuencia a las variaciones cíclicas de la economía nacional y de la propia economía estatal. Por ejemplo, se observa que las estimaciones de producto de los estados petroleros reflejan los distintos criterios utilizados en la contabilidad del petróleo, al mostrar una tendencia algunas veces excesiva, e insuficiente en otras. Así, también se observa que los periodos de crisis y abundancia tuvieron efectos diferenciados al interior de cada entidad federativa.8
Formalmente el artículo está organizado de la manera siguiente. La sección I introduce la especificación econométrica usada y la técnica de conciliación de cuentas aplicada a las series obtenidas de manera preliminar. En el apéndice se ofrece una explicación detallada de esta técnica. La sección II describe cómo están formadas las bases de datos utilizadas como insumo y sus principales características. También explica cómo se formaron los valores en tendencia y su uso para elaborar series de producto. La sección III presenta los resultados de la estimación y analiza los detalles de su elaboración; asimismo realiza un análisis descriptivo en comparación con otros trabajos anteriores. Al final se destaca algunas conclusiones.
I. ESPECIFICACIÓN Y MÉTODO DE ESTIMACIÓN
La estimación derivada en este trabajo está basada en la metodología seguida por Romer (1989) para generar el PNB de los Estados Unidos en el periodo 1869-1908. En dicho trabajo la autora deriva estimaciones nuevas del PNB usando la relación observada en un periodo con datos reales entre el PNB y la variable producto mercantil, lo que permite que esta relación varíe en el tiempo mediante una ecuación de regresión con datos conocidos de dos periodos combinados: 1909-1928 y 1947-1985.9 Como resultado, las estimaciones nuevas tienen propiedades cíclicas que se ajustan mejor a la relación sugerida por la teoría económica y la evidencia empírica entre PNB y producto mercantil.10
Al apoyarse en la relación observada entre estas dos variables Romer busca hacerlo con el mejor indicador posible para el cual se dispone de información real.11 En el ejercicio actual hemos procedido de igual manera; sin embargo, ante las limitaciones de información por estado hemos optado por el PIB nacional que parece ser el indicador disponible que mejor ajusta la relación con el PIB de los estados.12 El PIB nacional tiene la ventaja de que es una serie disponible año con año y para un gran periodo como para cubrir ampliamente las exigencias de esta base de datos, además de que al estar integrado por la suma de producto de los 32 estados permite recoger los movimientos cíclicos del producto estatal que están muy relacionados al producto nacional. Debido a que el PIB de México se compone de la agregación estatal, es posible que constituya una representación muy próxima a la serie que se pretende estimar.
El método que aplica Romer (1989) se puede resumir en las siguientes fases. En primer lugar estima la relación entre las desviaciones porcentuales de tendencia del PNB y el producto mercantil en un periodo en el que existen datos verdaderos para ambas series y después usa esta relación estimada para formar estimaciones del PNB de los años anteriores a 1909. Similarmente, en este trabajo nos apoyamos en la relación estimada entre las desviaciones porcentuales de tendencia del PIB estatal y del nacional para pronosticar el producto estatal de los años intercensales y de los años anteriores a 1970.
En segundo lugar, la autora usa esta serie obtenida mediante las desviaciones porcentuales de tendencia como insumo para calcular los coeficientes de sensibilidad entre producto estatal y nacional mediante una ecuación de regresión por mínimos cuadrados ordinarios. De acuerdo con Romer (1989), en este trabajo especificamos la siguiente relación:
en la que el subíndice t es el año de referencia; pebi,t es el logaritmo del producto bruto en el estado i, en términos reales; pibt representa el logaritmo del producto interno bruto nacional, también en términos reales; tend significa una variable que mide la tendencia lineal en el tiempo, y las barras sobre una variable indican valores en tendencia (también en logaritmos). La especificación permite que los datos decidan si efectivamente la relación entre el producto estatal y el nacional ha cambiado en el periodo de estimación. Mediante la introducción de una tendencia lineal los pronósticos de producto estatal no estarán condicionados al mismo ciclo de la serie nacional.
Como muestra la ecuación (1) este procedimiento permite que la medida de sensibilidad del producto estatal a nacional cambie en el tiempo. En este sentido, el coeficiente estimado reflejará un efecto neto diferente en 1940, por ejemplo, de lo que éste puede ser en cualquier otro año, de los cambios estructurales que causan la relación entre producto estatal y nacional. Por otro lado, en regresiones de este tipo es natural encontrar que la influencia de los errores correlacionados es tan importante como para influir en la precisión de las estimaciones; sin embargo, al adoptar el método Cochrane-Orcutt para corregir la autocorrelación hemos obtenido estimaciones congruentes y eficientes sin perturbaciones de esta naturaleza.
A las estimaciones obtenidas de esta manera les aplicamos el método de conciliación para datos transversales propuesto por Van der Ploeg (1982). Este método consiste en ajustar una secuencia de observaciones compuesta por componentes cíclicos y de tendencia con los residuos generados en la regresión de estimación mediante la siguiente ecuación.13
La ecuación (2) se interpreta de la manera siguiente: el vector de estimaciones estatales conciliado (P*) es el resultado de ajustar las estimaciones preliminares (Y), obtenidas mediante la ecuación (1), en función de la discrepancia observada (AY), teniendo en cuenta la estructura de varianzas y covarianzas de las estimaciones preliminares. El procedimiento trabaja del siguiente modo: primero, la magnitud de las revisiones (en valor absoluto) es tanto mayor cuanto mayor es la varianza de la estimación inicial (σii); segundo, si se considera que una determinada estimación preliminar se conoce con exactitud absoluta (σij = 0), entonces no se realiza ajuste alguno: Pi* = yi; éste sería el caso del total nacional, y, tercero, si la incertidumbre en la estimación de dos variables evoluciona en el mismo sentido (σij > 0), sus revisiones también lo harán en dicho sentido: las dos a la alza o las dos a la baja. Si, por lo contrario, su covariación es negativa los ajustes se realizarán en sentidos opuestos: una a la alza y la otra a la baja o viceversa. De esta manera, las estimaciones de la ecuación (2) satisfacen la restricción de que la suma del PIB de los estados es igual al nacional.14
II. DESCRIPCIÓN DE LOS DATOS FUENTE Y DE LOS VALORES EN TENDENCIA
1. Datos fuente
En este trabajo nos apoyamos en tres conjuntos de información para generar las series de producto del periodo 1940-1992. Un primer grupo lo constituye la base de datos estatal compuesta por los valores del producto a precios corrientes para los años censales (1970, 1975, 1980 y 1985) y por la serie anual a partir de 1993, ambos publicados por el INEGI. Un segundo grupo está compuesto por dos bases de datos estimados de manera no oficial para realizar los pronósticos del periodo 1940-1969: una serie de producto estatal de 1970-200215 y las estimaciones realizadas en el trabajo de Appendini (1978) para 1940, 1950 y 1960. Estos últimos datos están a precios de 1950 y el procedimiento para igualar ambos conjuntos de información fue calcular el deflacionador implícito del producto nacional, aprovechando que la serie nacional existe tanto a precios corrientes como a precios constantes, después cambiando la base a 1993 para retornar la serie a precios de ese año. Este método de usar un índice nacional es estándar y también es usado en algunos trabajos acerca de las regiones de México (véase por ejemplo Esquivel, 1999).16 Finalmente, un tercer conjunto de información usado para el periodo entero lo conforman los datos de producto nacional desde 1940, a precios constantes, también publicado por el INEGI.
2. Valores en tendencia
El método usado para calcular los valores en tendencia fue la interpolación lineal entre los años elegidos como "pivote" de los logaritmos del producto estatal y del producto nacional. Para estimar la ecuación (1) y conformar las series de producto estatal, primero calculamos los valores en tendencia para ambas secuencias, producto estatal y producto nacional, en el periodo completo 1940-2004. Los años usados como "pivote" fueron 1940, 1950, 1960, 1970, 1975, 1980, 1985, 1993, 1998 y 2004. La decisión de los años base para calcular valores en tendencia puede ser un procedimiento un tanto arbitrario e imperfecto, sin embargo como se observa, aquí hemos elegido hacerlo con los años de información real. Con estos años base se calcularon los valores en tendencia mediante interpolación lineal y después fueron utilizados en las regresiones mediante la ecuación (1).17
III. RESULTADOS
1. Estimación de las series del producto estatal
Una vez definidos el procedimiento y la estructura de los datos usados podemos, ahora, estimar la ecuación (1). Los resultados usando mínimos cuadrados ordinarios acusan una alta correlación serial de los residuos. El estadístico Durbin-Watson (D-W) fluctuaba en cifras por debajo de la unidad y el análisis del correlograma de los residuos indicaba la presencia de gran correlación serial. Este es un fenómeno esperado en series de tiempo, ya que constituye un indicador de que los movimientos del producto estatal que no están correlacionados con el producto nacional pueden ser muy persistentes. En su solución, a las estimaciones mediante la ecuación (1) aplicamos el procedimiento Cochrane-Orcutt y cuidamos que las estimaciones resultaran eficientes y congruentes.
Por otro lado, en muchas ocasiones es natural esperar que las series temporales como las aquí relacionadas tiendan a moverse en la misma dirección, lo que refleja una propensión creciente o decreciente. En consecuencia, al efectuar la regresión de las variables PIB estatal y nacional menos su valor en tendencia y obtener un valo R2 alto, éste puede no reflejar la verdadera asociación entre las variables, sino sencillamente la inclinación común presente entre ellas y dar lugar así a lo que en econometría se conoce como relación espuria.
Para asegurarnos de que dicha asociación espuria no está presente en las series de tiempo que analizamos hemos aplicado pruebas de raíces unitarias. Como resultado, el estadístico Dickey-Fuller ampliado (DFA) fue muy significativo en todas las series, pudiendo rechazar la hipótesis nula de raíz unitaria. Se infiere con esto que la relación planteada no puede ser producto de la casualidad, ya que las variables resultaron ser estacionarias. Una vez considerados estos detalles podemos ahora analizar las principales salidas de las regresiones mediante la ecuación (1), que se presentan en el cuadro 1. Sobresalen dos aspectos de esas estimaciones. Primero, la sensibilidad estimada del producto estatal al producto nacional es mayor a la unidad en muchos de los casos, lo que indica que los cambios en el producto nacional afectaron de manera importante el producto de esas entidades.
Cuadro 1 Indicadores econométricos para generar las series del PIB estatala

aLas variables fueron medidas en logaritmos y regresadas por medio de mínimos cuadrados ordinarios a partir de la ecuación pebi,t - pebi,t= (α + β • tend) (pibt - pibt) + εi,t, ∀i=1, ..., 32, en la que pebi , t es el producto del estado i en el año t; pibt, el producto nacional en el año t; las barras sobre una variable indican valores en tendencia mediante interpolación lineal; tend, representa la tendencia lineal y εi,t es el término de perturbación. Además: s.e. indica el error estándar de la variable; D-W, la prueba Durbin-Watson; R2, el coeficiente de determinación, y n. e. indica que el coeficiente no fue estimado.
Segundo, los diversos cambios estructurales que podrían haber ocurrido en el producto nacional tuvieron efectos diferentes entre las entidades. Este hecho se infiere de la significación mostrada en el coeficiente de tendencia. En algunos estados (14 en el panel A y 8 en el B) el coeficiente estimado no fue significativamente diferente de cero, lo que sugiereuna función muy débil del tiempo, mientras que en el resto su significación fue importante, es decir su producto constituye una función fuerte del tiempo. Este resultado puede ser indicativo de que los diversos cambios estructurales que se esperaría que afecten la relación entre producto estatal y producto nacional han tenido, en realidad, poco efecto para el grupo de estados en el que la tendencia resultó débil, y mayor efecto para el grupo en el que la tendencia fue significativa. También se puede inferir que los cambios no fueron suficientemente importantes en algunos estados o, bien, tuvieron efectos diferenciados y tendieron a cancelarse de manera mutua.
Los coeficientes estimados mediante la ecuación (1), y que se muestran en el cuadro 1, fueron utilizados para elaborar las estimaciones preliminares del producto estatal, pronosticando hacia atrás para cada uno de los años. El método consistió en utilizar la sensibilidad estimada para crear estimaciones puntuales del producto estatal; después esas estimaciones fueron agregadas a las series obtenidas antes mediante valores en tendencia. Como se indicó, esos valores de tendencia fueron calculados interpolando linealmente entre años base. Por último, aplicamos el método de conciliación mediante la ecuación (2) para obtener estimaciones finales ponderando las series por los errores de regresión.
El resultado fue la estimación del PIB estatal, en términos reales, para el periodo 1940-1992, que se presenta en el cuadro 2, junto a la serie oficial, para conformar el periodo 1940-2002.
Cuadro 2 Producto interno bruto por entidad federativa, 1940-2001

FUENTE: Estimaciones propias de 1940 a 1992. De 1993 a 2001, cifras de INEGI, Sistema de Cuentas Nacionales.
Las gráficas 1 y 2 pueden ser útiles para tener una idea más precisa de la tendencia que presentan las nuevas series de producto. Hemos considerado dos grupos separados, mostrando en uno diferente a los estados de mayor ingreso, para una mejor observación. En esas gráficas se observa cómo las diferentes series evolucionan de manera distinta presentando una amplia dispersión, en valores absolutos, a fines del periodo. También se aprecia una amplia diferencia entre los estados de mayor y menor volumen de producto. Los primeros corresponden a economías que históricamente han sido de mayores ingresos.
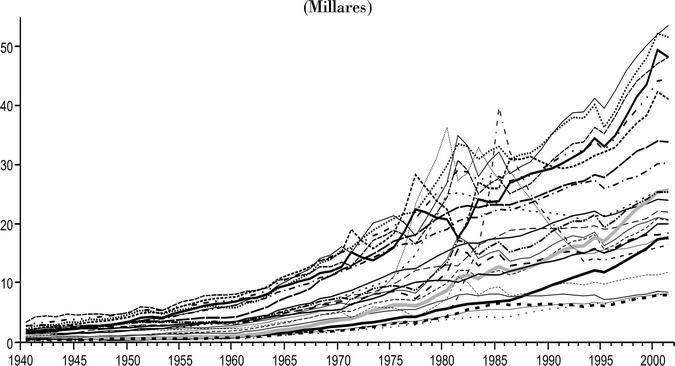
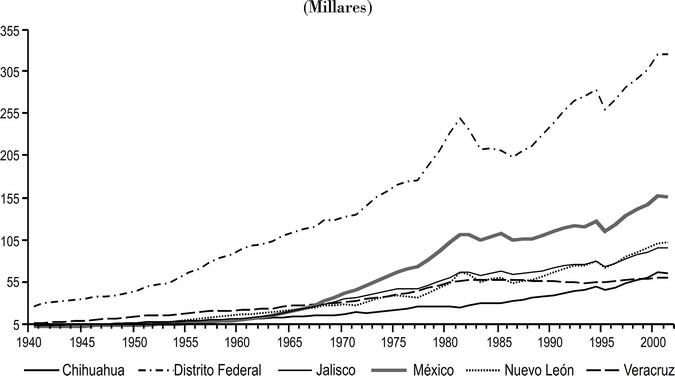
Individualmente las series parecen coincidir en una misma tendencia temporal, sin embargo es fácil advertir tres grupos diferentes. En un primer grupo se sitúa al Distrito Federal, ya que destaca del resto de estados porque su producto es mucho mayor. Un segundo grupo es el que gráficamente describe un pico en la tendencia desde fines del decenio de los setenta hasta alrededor de mediados de los ochenta. Estos estados son Campeche, Tabasco y Chiapas. Una explicación posible de este desempeño puede ser encontrada en las diferentes maneras en que se ha contabilizado el petróleo en el país, ya que son entidades de importante producción petrolera. Por último, en un tercer grupo se concentra el resto de entidades federativas, caracterizadas porque sus ingresos son más o menos homogéneos y describen una trayectoria creciente y regular en el periodo de estudio. Aunque se podría intentar corregir el efecto de este cambio en la contabilidad del PIB para esos estados, dicha tarea queda fuera de los objetivos del presente trabajo, por lo que se registran tal y como fueron generados.
Las características mostradas gráficamente son importantes, dan firmeza a las estimaciones y comprueban empíricamente el desempeño de las economías, en particular la trayectoria inusual del PIB de los estados petroleros por los años ochenta es un ejemplo palpable de su congruencia y certidumbre. No obstante, otra manera de considerar la seguridad de las estimaciones generadas puede ser a partir del análisis de la discrepancia estadística entre la suma del producto estatal estimado y la serie del producto nacional. En el cuadro 3 mostramos los resultados.

Como se observa, la discrepancia es de 0.02% en promedio para el periodo 1940-1992, mientras que en términos puntuales es posible destacar que la mayor discrepancia fue de sólo 0.075% ocurrida en 1941. Le siguen a esa cifra discrepancias de menor tamaño: 0.066% en 1942, 0.051% en 1944 y 1963. El resto del periodo observa discrepancias absolutas menores a 0.05%. Estos resultados garantizan que el modelo de estimación reproduce confiablemente el PIB nacional y que es compatible con la información publicada en fuentes oficiales.
Hay otra manera de considerar las propiedades de las estimaciones generadas. Nos referimos a una comparación de las trayectorias descritas por los valores de tendencia y los valores pronosticados. Con este objetivo graficamos los valores correspondientes a cuatro economías junto a los valores en tendencia que tendrían si el crecimiento entre un año base y otro hubiera sido a una tasa constante y uniforme en el tiempo. Los resultados se muestran en la gráfica 3.

Se observa cómo las estimaciones son sensibles a las fluctuaciones cíclicas de la economía, principalmente a partir de los años setenta, cuando ocurrieron movimientos cíclicos de mayor escala en el país. Cada trayectoria es diferente y en algunos casos las estimaciones suelen ser más sensibles que en otros a los efectos volátiles del ciclo. Esta observación constituye un elemento decisivo que fortalece el argumento planteado de que el método de estimación permite discriminar entre las diferentes estructuras que tienen las economías individualmente.
En la gráfica 3 es posible observar algunas economías en las que los efectos cíclicos tienen mayor suavidad y resultan más pequeños (Michoacán y Oaxaca); indica que para esos estados los ingresos son menos volátiles que en otros más integrados a la economía nacional (como Distrito Federal y Nuevo León) y que por tanto pueden resentir con mayor fuerza los efectos de las depresiones o crisis ocurridas en la esfera nacional. Este hallazgo sugiere que las estimaciones son mucho más volátiles en economías en las que el ciclo de negocios es más importante, mientras que son menos volátiles en economías donde los efectos del ciclo de negocios son menos importantes.
Existen otras características que poseen las series del producto estatal. Por ejemplo, dado que en las regresiones usamos datos del PIB nacional que incluyen el gasto total del sector público, los coeficientes estimados deben captar el comportamiento cíclico del gasto del gobierno. Por tanto, las series del PIB estatal formadas con esos coeficientes también deben incorporar el comportamiento característico del sector público en los estados.
Un análisis de las series generadas señala algunas ventajas. Primero, las estimaciones son compatibles con la información publicada por fuentes oficiales. El método tiene el atributo de que al realizar los pronósticos conserva los valores originales en los periodos con información real (como es el caso de los años censales), por lo que trabaja llenando los vacíos entre años censales con los indicadores de sensibilidad estimados y controlado por el total nacional del año de que se trate. Segundo, cubren un periodo largo (1940-1992) de información homogénea, lo cual las hace más atractivas para realizar estudios regionales de largo plazo que demandan una gran cantidad de información como insumo, por ejemplo la aplicación de técnicas econométricas de series temporales, análisis de cointegración, de corte transversal, y en general para tener una visión más amplia del desempeño regional del país. Por último, tienen la utilidad de que abarcan un periodo relativamente lejano que a menudo resulta complejo para el tratamiento de datos, ya que los primeros censos levantados hasta antes de 1970 sólo representan una parte de la economía (sobre todo de la industria y comercio) y en ocasiones la información entre un censo y otro no es compatible, lo que deriva en una visión parcial del desempeño estatal.
2. Análisis comparativo frente a otras estimaciones
Puesto que existen algunos esfuerzos anteriores de estimación regional en México, resulta interesante abordar un análisis descriptivo comparando esos resultados con los obtenidos en este trabajo. Los antecedentes más inmediatos son los trabajos ya mencionados de Álvarez (1981), Puig y Hernández (1989) y Mendoza (1997).18 En términos generales, las dos primeras aportaciones constituyen estudios econométricos de desagregación geográfica que pueden ser ejemplificados con el de Puig y Hernández. En particular, este modelo estima el producto estatal a precios de 1980 para el periodo 1970-1988 de acuerdo con el método propuesto por Chow y Lin (1971) para la desagregación de series de tiempo, a partir de dos fuentes de información: el PIB nacional y una serie auxiliar correlacionada con el comportamiento del producto estatal (la captación bancaria). Aunque este tipo de modelos tiene una serie de ventajas, como la de ajustar las predicciones con base en observaciones conocidas, impone una restricción inicial que puede dar lugar a ciertos sesgos. El hecho de que los residuales entre observaciones y predicciones no se toman en cuenta puede desembocar en una particular dificultad del modelo a la hora de predecir los comportamientos de las entidades que no tienen un desempeño en términos normales de la generación de producto y que por tanto muestran un comportamiento diferente a la del resto (algunos ejemplos pueden ser Campeche, Distrito Federal, Quintana Roo y Tabasco). Sin embargo, en general las proyecciones son satisfactorias y constituyen un buen referente de los esfuerzos de estimación regional.
Por otro lado, la metodología empleada en Mendoza (1997) consiste en elaborar un modelo que estima el PIB por cada entidad federativa para el periodo 1970-1995 al utilizar métodos de interpolación y extrapolación matemática. Este método tiene la ventaja de que no impone correlaciones estadísticas entre las variables que sesgan las proyecciones; sin embargo, y como la teoría estadística nos enseña, es posible que los valores promedio sean afectados por los valores extremos y, cuando son usados con fines de proyección, sesguen la verdadera naturaleza de las series pronosticadas, ya que tienen el efecto de suavizar los puntos extremos ("picos" en la curva) del ciclo económico. Aprovechando que las estimaciones de producto se hallan a precios de 1993 (al igual que en este trabajo) y se trata de una de las aportaciones más próximas, tanto en periodo de estimación como en fecha de publicación, resulta práctico realizar un ejercicio que relacione ambas estimaciones. Con este propósito hemos graficado, para cada estado, los productos brutos estimados de ambos trabajos. En la gráfica 4 exponemos los resultados para ocho estados.
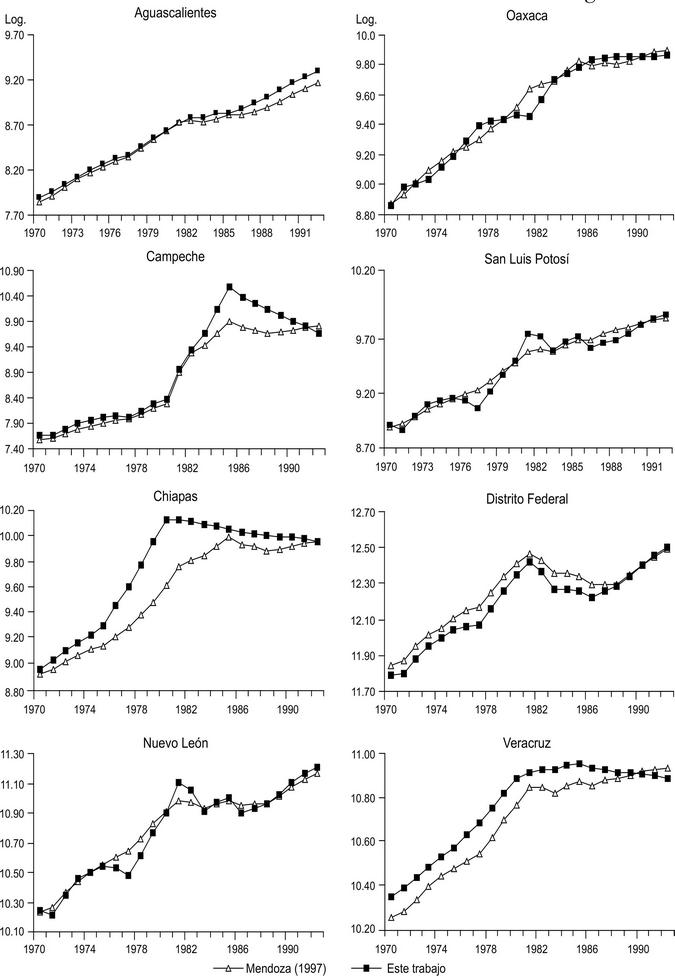
Los datos han sido transformados en logaritmos para mejor observación, y aunque la serie de Mendoza (1997) abarca el periodo 1970-1994 aquí no hemos considerado los últimos dos años con el fin de abordar los mismos años en ambos trabajos (1970-1992).
Mientras que ambos métodos realizan estimaciones muy similares, nuestros resultados muestran una tendencia un poco superior en algunos de los estados. Las distancias más amplias pueden notarse principalmente en los años ochenta. En este sentido, y a raíz del desempeño empírico de la economía nacional, el decenio de los setenta todavía fue de relativa estabilidad y crecimiento (razón por la que es posible que en ese periodo ambas estimaciones sean más coincidentes), mientras que los años ochenta estuvieron muy matizados por una aguda inestabilidad económica y tasas de crecimiento incluso negativas. Los efectos dejados por esta eventualidad nacional fueron más importantes en algunos estados que en otros y fueron recogidos en los pronósticos de producto. En efecto, en nuestras series se observa que algunos estados experimentaron decrementos repentinos, y otro grupo de estados incrementos rápidos. Mientras tanto, en Mendoza (1997) las series presentan una tendencia suave, uniforme, un poco creciente en el tiempo, que soslaya de cierta manera la fuerza de los movimientos cíclicos de esos años. Esta observación demuestra que el método utilizado aquí es más sensible a movimientos del ciclo económico y, por tanto, más susceptible en situaciones de mayor volubilidad económica. Sin embargo, ambas estimaciones resultan ser muy similares en periodos de mayor estabilidad económica.
Una muestra adicional de la seguridad de las estimaciones llevadas aquí frente a otras existentes se presenta al examinar el desempeño empírico de los estados petroleros (Campeche, Chiapas y Tabasco). La tendencia trazada por esta tríada de estados refleja la formación de un "pico" entre fines de los años setenta y 1985, aproximadamente. Algunos autores -véase Esquivel (1999), Cermeño (2001), entre otros-, que ya habían notado este irregular comportamiento, aluden que se debe a cambios en la contabilidad del petróleo. Mientras que las estimaciones de este trabajo dan buena cuenta de esos repentinos cambios, las series generadas en Mendoza (1997) parecen informar menos del cambio administrativo de esos años. Desde la gráfica 4 se observa cómo ambas secuencias parecen reencontrarse a inicios de los años noventa, disminuyendo las discrepancias y formando una misma tendencia en producto ya sea a la alza, en algunas economías, o a la baja, en otras.
En resumen, el método y las estimaciones generadas en este trabajo gozan de ciertas ventajas: el uso de una variable que presenta buen ajuste al comportamiento de las entidades, el uso de una ecuación de regresión que varía en el tiempo y permite que los datos decidan si efectivamente hubo o no una relación de regresión entre las variables, el hecho de que ajustamos las estimaciones preliminares tomando en cuenta el valor de las varianzas y covarianzas de los residuos19 y, por último, la homogeneización de un periodo más largo de información que puede ser altamente rentable para efectuar estudios de economía regional de largo plazo.
Finalmente, no hay que olvidar que las estimaciones generadas aquí son sólo eso, estimaciones, y al derivarlas hemos tenido especial cuidado en asegurarnos que la serie resultante sea tan congruente como sea posible con las series oficiales que abarcan periodos más recientes, tanto en representar desempeños temporales como en formar movimientos cíclicos. Sin embargo, el banco de datos estimado está consolidado con menos información y fue generado usando métodos que son muy diferentes a los utilizados con frecuencia por fuentes oficiales para elaborar los datos actuales. Como resultado nuestras estimaciones deben, seguramente, estar sujetas a un margen de error más amplio que el observado por los institutos oficiales dedicados a la recabación y generación de datos. No obstante (y teniendo en cuenta las limitaciones señaladas) en este trabajo se ha realizado un esfuerzo por complementar la información estadística de ámbito regional que existe para México, información que ha de posibilitar la realización de futuros estudios económicos respecto a los estados del país y que puede resultar muy útil para la toma de decisiones de política local y nacional.
CONCLUSIONES
El objetivo de este trabajo ha sido la creación de series homogéneas del producto interno bruto para los 32 estados de México que puedan ser enlazadas con la serie anual oficial para formar el periodo 1940-2002. Las series estimadas han sido derivadas con métodos indirectos que permiten captar el comportamiento temporal y los ajustes cíclicos de la actividad económica estatal. Se observa que la relación del producto estatal respecto al nacional es alta y significativa y que los cambios en el producto nacional han tenido efectos diferenciados entre los estados.
Las estimaciones generadas son muy similares y congruentes con las presentadas antes por otros trabajos con distintos métodos de estimación. Sobresalen algunas diferencias, principalmente en los años de mayor inestabilidad económica del país. En general, la técnica usada parece ser más sensible a los momentos de mayor fluctuación económica. Esta observación constituye evidencia de que el método tiene amplia receptividad de comportamientos cíclicos.
Mientras que el método utilizado en las estimaciones descansa en supuestos razonables que intentan captar el desempeño de las regiones, permanece el margen de error subyacente en los métodos indirectos de estimación. Estudios posteriores que apoyen sus investigaciones en las series generadas aquí deben tener presente esta restricción. No obstante, las bases de datos que hemos estimado son útiles en una variedad de formas: en análisis regional del comportamiento del gasto público, en estudios del crecimiento económico de los estados mediante análisis de series temporales y de cross-section, para pronóstico de los comportamientos de tendencia, como insumo en estudios de economía regional que ayuden a mejorar las decisiones de política local y, en general, para tener una visión más concreta del desarrollo económico regional del país.

