











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introducción*
Se ha dicho a menudo que, para realizar una clasificación dialectal basada en la entonación, la modalidad interrogativa -por encima de la declarativa- permite realizar mejores clasificaciones (Escandell 1999; Navarro Tomás 1974 [1944]; Prieto & Roseano 2010; Quilis 1985). Sin embargo, esta tesis surge de la observación de las isoglosas que se establecen a partir de ambas modalidades y de la apreciación de que las isoglosas creadas por interrogativas encajan más con las hipótesis de zonas dialectales de los investigadores. Se trata de un aserto, por tanto, que no se contrasta con datos numéricos de las diferencias que aporta cada modalidad.
Estas apreciaciones son particularmente llamativas cuando se hacen en estudios de dialectometría -en los que se usan medidas numéricas para clasificar dialectos, es decir, estudios que buscan la objetividad-; pero también desde la dialectometría se han justificado las clasificaciones que ofrecen los programas usando argumentos lingüísticos basados en el contorno de las interrogativas (Calvo e Rei 2015; Fernández-Planas et al. 2015; Prieto i Cabré 2013; Roseano et al. 2015 y 2017).
El propósito de este trabajo tiene tres directrices: en primer lugar, aspira a comprobar de manera objetiva si, efectivamente, las oraciones interrogativas difieren más en el espacio que las declarativas; en segundo, pretende cuantificar esa variación en el caso de la clasificación dialectal de algunos puntos del español y, en tercero, explora si los resultados obtenidos son extrapolables a otras variedades lingüísticas.
Para lograrlo se seguirá el siguiente esquema: en lo que queda de este apartado se presenta la dialectometría, su aplicación a la entonación y se pasa revista a los estudios dialectométricos de la entonación del español, que concluyen que la variedad declarativa es poco útil para la clasificación dialectal. Después, se explica el método que ayudará a cuantificar la aportación de cada modalidad a una clasificación dialectal concreta: primero se presentan los corpus, grabaciones e informantes; luego se detalla el método seguido para obtener las diferencias entre modalidades. Por último, la parte que precede a las conclusiones ofrece los resultados obtenidos para el español y para otras variedades románicas.
La dialectometría de la entonación
La dialectometría (Goebl 1982; Séguy 1971 y 1973) es una técnica que surge, como tantas otras en la lingüística de corpus e ingeniería de datos, para ayudar a los lingüistas a ordenar y resumir datos no comprensibles a simple vista. En el caso de la dialectometría se trata de los datos obtenidos en los grandes atlas lingüísticos que se recogieron en la primera mitad del siglo XX. Los atlas clásicos ofrecían a los usuarios una isoglosa (frontera de uso de una variante lingüística) para cada uno de los ítems estudiados. Eso hacía que el investigador tuviera que, de alguna manera, sobreponer las isoglosas de diferentes características para hallar una frontera dialectal allá donde coincidían más haces de isoglosas. Sin embargo, mediante esta técnica de trazado de diferencias se perdía información importante, ya que se acababan tratando de igual manera cambios como el que hay entre lumiago y lumiaco o lumiaco y babosa.
Con esta preocupación, y con el objetivo de encontrar un índice de la distancia entre variedades -que obviamente sería más cercano entre lumiaco y lumiago que entre lumiago y babosa-, se creó la dialectometría en los años setenta. Es importante recalcar que la dialectometría no busca sustituir el estudio tradicional de isoglosas, sino que pretende ofrecer un punto de vista diferente (el de la búsqueda de distancias) que antes no era posible.
La dialectometría consiste en una alianza metodológica entre la geolingüística y la taxonomía numérica (Goebl 1982). En ella se intenta establecer agrupaciones de la masa de datos empíricos obtenida en las investigaciones, juntando aquellos datos que se parecen; es decir, en última instancia, realiza particiones dialectales. Estas clasificaciones se suelen representar en forma de árbol jerárquico mediante dendrogramas. De ellas, probablemente las más conocidas sean las que representan las familias lingüísticas y las comparan con el genoma de las poblaciones humanas (Longobardi et al. 2015).
Hemos adelantado ya algo que será de vital importancia en nuestro estudio: la dialectometría surge para tratar datos de los atlas de la primera mitad del siglo XX. Ello hace que se encuentre optimizada para trabajar con corpus orales transcritos, ya sea en forma de transliteración o como transcripción fonética. A partir de esas transcripciones se pueden extraer datos fonológicos segmentales, morfológicos, léxicos o incluso sintácticos, pero no recuperar el audio de las grabaciones. Por lo tanto, salvo por notorias excepciones (Heeringa et al. 2009), la dialectometría no se ha aplicado al estudio fonético acústico del habla. Esta imposibilidad ha hecho que los primeros estudiosos dedicados a la entonación, cuando quisieron buscar similitudes entre patrones entonativos, hayan tenido que crear, previamente (Hermes 1998), o adaptar, en algunos casos, las fórmulas ahora disponibles para trabajar con datos acústicos, lo cual supone un problema metodológico a la dialectometría tradicional.
La dialectometría como disciplina ha estado siempre muy ligada a su mayor promotor, Goebl y la escuela de dialectometría de Salzburgo (Goebl 2006); su metodología, medidas de distancia y de similitud aprobadas son únicamente aquellas que se han implementado en el programa Visual Dialektometrie, o en otros, como GabMap o DiaTech. Todas ellas se especializan en buscar similitudes y diferencias en datos nominales, es decir, utilizan adaptaciones de fórmulas como Levenshtein para evaluar cuánto se parecen dos palabras (Aurrekoetxea et al. 2013; Goebl 2006; Nerbonne et al. 2011).
Precisamente la creación de esas fórmulas es lo que se considera el nacimiento de la dialectometría y su mayor aportación: cómo convertir los textos en distancias numéricas. Por lo tanto, para estas escuelas, hacer dialectometría es la aplicación de esas fórmulas o la búsqueda de otras nuevas para resolver el mismo problema: determinar la distancia entre dos caracteres.
En fonética no existe el inconveniente de tener que pasar datos nominales (texto) a distancias numéricas; los fonetistas siempre hemos trabajado con datos numéricos o escalares; por lo tanto, las matemáticas más clásicas, como la distancia euclídea derivada del teorema de Pitágoras, ya sirven a nuestros propósitos. En ningún caso se pueden usar las fórmulas que caracterizan el estudio dialectométrico tradicional, ya que éstas no son aptas para datos numéricos. Desde el punto de vista de la dialectometría clásica, no hay un problema matemático que resolver en los datos fonéticos. Podemos aplicar cualquier medida de distancia usada en análisis de la señal, desde la trigonometría de la Antigüedad hasta las técnicas más avanzadas de aprendizaje automático que se usan en reconocimiento del habla.
Como decíamos, esto se debe a que trabajamos con señales acústicas -la dialectometría perceptiva es completamente diferente a este respecto. En concreto, en el caso de la entonación, las descripciones útiles para la variación dialectal se basan en datos de frecuencia, duración e intensidad, habitualmente medidas en hercios (o semitonos), segundos (o milésimas de segundo) y decibelios (o Pascales), respectivamente. Las soluciones adoptadas para realizar medidas de similitud para datos numéricos suelen pasar por calcular, o bien la distancia euclídea (Roseano et al. 2017), o bien la correlación entre dos curvas de frecuencia (Calvo e Rei 2015; Moutinho et Coimbra 2011; Rilliard et Lai 2008; Romano 1999; Romano et al. 2011).
Esta diferencia metodológica entre la dialectometría “textual” y la dialectometría “sonora”, que incluso puede parecer trivial a simple vista, ha hecho que surjan cuestionamientos acerca de si los estudios de distancias fonéticas (con datos acústicos y no transcripciones) pueden considerarse dialectometría, puesto que en ellos no se usan las técnicas (fórmulas) de la disciplina y sólo mantienen su objetivo y tipos de observación. Asunto secundario para los doctos en la materia, ya que el propósito (buscar diferencias entre dialectos) es el mismo que en la dialectología tradicional basada en glosas, y la observación de los resultados, algo meramente estético.
Estudios de dialectometría y comparaciones de declarativas e interrogativas en español
Entre los estudios de prosodia, son abundantes los que, para caracterizar dialectos, se han referido a declarativas e interrogativas. Desde los estudios clásicos en asuntos de fonética, se ha hecho referencia a la entonación específica de las preguntas en algunos puntos del dominio lingüístico del español, al mencionarse, por ejemplo, la entonación circunfleja (Navarro Tomás 1974 [1944]; Quilis 1985; Sosa 1999). También los estudios de gramática han destacado la entonación descendente de algunas interrogativas del español (Escandell 1999).
Además, la metodología propuesta por el proyecto Atlas Multimedia de la Prosodia del Espacio Románico (AMPER) ha promovido la comparación entre estas dos modalidades encada punto que encuesta y propiciado, por tanto, una multitud de artículos en los que únicamente se describe la entonación de esas dos variedades; por ejemplo: Alvarellos et al. 2011; Congosto 2005; Dorta 2013 y 2018; Dorta & González Rodríguez 2019; Dorta y Hernández 2004; Fernández Rei 2011; Gurlekian y Toledo 2008; Martínez Celdrán y Fernández-Planas 2003; y Mora Gallardo et al. 2008.
De estas dos modalidades estudiadas, a menudo se ha destacado el papel de las interrogativas para las clasificaciones dialectales, tanto acústica como perceptivamente (Congosto Martín 2011; Fernández-Planas et al. 2019; Toledo & Gurlekian 2009), y se le han dedicado artículos específicos (Fernández Rei 2011; Martínez Álvarez 1997; Oosterzee et al. 2007; Szmidt y Labraña 2013; Toledo y Gurlekian 2009), cuyo análisis muy pocas veces se ha centrado en la variación de las declarativas (Martín Butragueño 2004).
Desde la dialectometría, cuando se ha buscado dar a las clasificaciones sentido lingüístico, las explicaciones también se han apoyado en las diferencias que hay en las oraciones interrogativas y no tanto en las que conciernen a las declarativas; es decir, la pertenencia de los diferentes puntos de encuesta a uno de los dos primeros grandes grupos que se crean en el árbol de clasificación se suele sustentar en preguntas ascendentes o descendentes. Y lo cierto es que los dos patrones mayoritarios de las interrogativas del español L* H% y ¡H* L% tienen contornos completamente contrarios: el patrón ascendente (L* H%) muestra un inicio bajo, un pico en la postónica del pretonema, una bajada y un ascenso final, lo que hace que la mayor parte del cuerpo de la frase esté en un rango tonal bajo y sólo al final de la frase haya un ascenso. Mientras tanto, el patrón descendente (¡H* L%) tiene un inicio alto que se mantiene durante todo el cuerpo de la frase y sólo desciende al final. Esta característica las hace particularmente susceptibles a las fórmulas de comparación dialectométricas, puesto que, durante gran parte de la duración de las frases, la correlación de las curvas sería una correlación negativa casi perfecta (cercana a -1). Es lo que ocurre en los estudios dialectométricos de variedades del español, donde las clasificaciones en dos grandes grupos se justifican por la existencia de preguntas ascendentes o descendentes. Esto ha dado lugar, respecto del español peninsular, a la acuñación del término español atlántico, que comprende las variedades peninsulares de interrogativas descendentes, las propias de las islas Canarias y de la cornisa cantábrica, básicamente (Fernández-Planas et al. 2015). En los estudios dialectométricos que incluyen variedades americanas con el mismo patrón en las preguntas (Dorta 2018), también se ha destacado que las interrogativas son más útiles para la clasificación; incluso, en estudios del español junto con otras lenguas románicas (Elvira-García et al. 2018) y en estudios dialectométricos de gallego, catalán y portugués europeo (Fernández-Planas et al. 2011 y 2015a; Fernández Rei et al. 2005; Moutinho et Coimbra 2011), las interrogativas se han probado más útiles.
En definitiva, el análisis lingüístico lleva a argumentar que las interrogativas aportan más al análisis dialectal porque las características de los datos de esa modalidad los hacen más prominentes, esto es, más característicos de cada zona.
Método
Corpus, puntos de encuesta, hablantes y grabaciones
El corpus utilizado es el llamado fijo del conjunto de datos que se graban en el proyecto AMPER (Fernández Planas 2005; Romano et al. 2005); corpus de 63 frases en dos modalidades (declarativa e interrogativa) con la estructura SVO y, opcionalmente, un complemento del nombre en el sujeto o en el objeto, que contiene los tres tipos acentuales del español -palabras esdrújulas: cítara, clásico, clásica, pánico; llanas: guitarra, española, italiano, finita, paciencia; agudas: saxofón, magrebí, obsesión, amor. El diseño del corpus del español se puede consultar en Fernández-Planas 2005.
Los informantes que se han utilizado son un hombre y una mujer en cada uno de los puntos que aparecen en la Tabla 1 (Barcelona, Granada, León, Madrid, Palencia y Soria, de España, y Cuernavaca, de México), lo que hace un total de 4 536 frases. Los puntos escogidos representan variedades bien estudiadas en la bibliografía y que constituyen además un conjunto de datos equilibrado, toda vez que se cuenta con diferentes contornos entonativos.
Específicamente, para las interrogativas, Barcelona, Granada, Madrid y Cuernavaca se han descrito como variedades entonativamente cercanas: siguen el patrón L* H% (Roseano et al. 2014). Hay que notar que, aun cuando en la bibliografía se presenta la entonación del centro de México como de ascenso final tardía (L* LH%) (Martín Butragueño 2014), Cuernavaca sigue el mismo patrón que las variedades peninsulares en los datos que se usan en este trabajo (Sagastuy y Fernández-Planas 2014). Las interrogativas de León, Palencia y Soria siguen, en cambio patrones descendentes o descendente-ascendentes, en todos los casos con un pretonema alto (Fernández-Planas et al. 2020): el bien conocido ¡H* L%, coincidente con el patrón canario y antillano, patrón que se podría describir como H* !H% en Soria y León, que en el caso de León convive con el clásico ¡H* L% y con ¡H* LH% (Elvira-García 2020).
Tabla 1 Puntos de encuesta, sexo del informante y número de frases grabadas en el corpus A.
Punto de encuesta |
Sexo del informante |
Núm. de frases |
Barcelona |
Hombre Mujer |
378 378 |
Granada |
Hombre Mujer |
378 378 |
León |
Mujer |
378 |
Madrid |
Hombre Mujer |
378 378 |
Cuernavaca |
Hombre Mujer |
378 378 |
Palencia |
Mujer |
378 |
Soria |
Hombre Mujer |
378 378 |
En lo que toca a las declarativas, mientras que todos los puntos peninsulares comparten el mismo patrón (L* L%), en el caso de Cuernavaca se esperan dos patrones en alternancia; por una parte el L*L%, común en todo el dominio del español y, por otra, el circunflejo, L*¡H L% (Martín Butragueño 2004).
Para poder dar una visión general y comprobar la aportación de diferentes modalidades en otras variedades y lenguas se ha analizado un segundo corpus (B) que contiene datos de la península italiana y la isla de Cerdeña, específicamente; tal y como se puede ver en la Tabla 2, los datos pertenecen al sardo, italiano y catalán. Se ha escogido tal información porque los estudios dialectométricos de estas variedades ya se han realizado y validado, lo que asegura un conjunto de datos revisado por más de un investigador (Roseano et al. 2015). En concreto, se ha sometido a análisis a 12 informantes, hombre y mujer, de los siguientes puntos de encuesta: Peruggia, Siena, Porto Torres (se grabó italiano regional y sardo), Villanova (se grabó italiano regional y sardo) y l’Alguer, el único punto de la isla de Cerdeña donde se habla catalán. De ellas, los datos de italiano peninsular de Siena y Peruggia tienen declarativas descendentes e interrogativas ascendentes, H * LH% (Gili-Fivela et al. 2015). Mientras tanto, los puntos de Cerdeña (Porto Torres, Villanova y l’Alguer) tienen declarativas con pretonemas con varios acentos tonales y configuraciones nucleares descendentes en las interrogativas (Vanrell et al. 2014). Específicamente, las declarativas de Cerdeña de los datos usados pueden mostrar dos patrones en oraciones con tres acentos léxicos: uno con L+H* L+H* H+L* L%, y otro con H*+L L+H* H+L* L%. Las interrogativas, en cambio, pueden tener dos patrones en la configuración nuclear: ¡H+L* L% y H*+L L%. Se puede ver una descripción fonética detallada de los datos en Roseano et al. 2015.
Tabla 2 Puntos de encuesta, sexo del informante y número de frases grabadas en el corpus B.
Lengua |
Punto de encuesta |
Sexo |
Núm. de frases |
Italiano |
Peruggia |
Hombre |
54 |
Peruggia |
Mujer |
54 |
|
Siena |
Hombre |
54 |
|
Siena |
Mujer |
54 |
|
Porto Torres |
Hombre |
54 |
|
Porto Torres |
Mujer |
54 |
|
Villanova (Biddanoa) |
Hombre |
54 |
|
Villanova (Biddanoa) |
Mujer |
54 |
|
Sardo |
Villanova (Biddanoa) |
Hombre |
54 |
Villanova (Biddanoa) |
Mujer |
54 |
|
Catalán |
L'Alguer |
Hombre |
54 |
L'Alguer |
Mujer |
54 |
En este caso, sólo se han utilizado las oraciones del corpus AMPER sin expansión, es decir, con una estructura sintáctica SVO, por lo que el cómputo de frases analizadas es de 648.
Análisis de los datos
La información utilizada se ha analizado para su incorporación en el proyecto AMPER, por lo que la curva de F0 se extrajo siguiendo el procedimiento de ese grupo de investigación. El programa usado en ese proyecto, AMPER06 (López Bobo et al. 2007), permite cargar una a una las frases del corpus y realiza un espectrograma de manera automática; en ese momento, admite que el investigador segmente las vocales del enunciado. Una vez hecha la segmentación, el programa usa una autocorrelación basada en la transformada rápida de Fourier para realizar una predicción de los puntos de F0 en el inicio, centro y final de cada segmento vocálico. Luego de trazar esos puntos en una curva gráfica, permite que el investigador vuelva a tomar el relevo y corrija, si es necesario, aquellos puntos en que la F0 no es la esperada, ya sea porque el sonido estaba ensordecido en esa ventana de análisis, ya sea porque ha habido algún otro problema del algoritmo de detección de F0. El investigador, para hacer esa corrección, usa como referencia los puntos adyacentes de F0, en caso de que los haya, o su propia percepción de la melodía, en caso de que no haya ninguna pista acústica disponible. Una vez obtenida la curva de F0 corregida, el programa almacena la información en un archivo de texto; concretamente, guarda los datos de F0 en Hz y en semitonos; usando como referencia la media de la frase, también almacena datos de duración y de intensidad. Es ese archivo de texto el que sirve de entrada para el programa de dialectometría.
Por lo tanto, la entrada (input) para este estudio ha sido un fichero txt para cada una de las frases del corpus, en el cual se habían almacenado tres datos de F0 (inicial, medio y final) en semitonos para cada vocal del enunciado y un valor de duración y de intensidad asociado a cada una de esas vocales. A partir de esos datos, se han calculado las diferencias entonativas de los puntos de encuesta usando el software ProDis (Elvira-García et al. 2018). Se ha calculado la correlación de Pearson (Hermes 1998; Romano et al. 2011) ponderada por la duración y la intensidad de cada una de las frases del corpus. Esta ponderación permite dar más importancia (aumentar el valor de la correlación) a los casos en los que el punto de F0 tiene más duración o más intensidad. En la práctica, la inclusión de la duración en la fórmula (no incluida en el cálculo de Hermes 1998) supone que, en los datos del español, se da más importancia a lo que pasa al final de la frase -el tonema-, ya que las sílabas finales son más largas por el alargamiento prepausal (prepause lengthening). Este análisis se ha repetido para declarativas e interrogativas en los dos corpus utilizados. Los resultados que se presentan líneas abajo, en “Aportación de declarativas e interrogativas al análisis”, consisten en la representación visual de esas distancias obtenidas mediante dendrogramas, tal y como viene siendo habitual en los estudios dialectométricos.
A partir de estos datos de similitud entre las entonaciones de los puntos de encuesta seleccionados, se procede a estudiar la aportación de cada modalidad. Para ello, se realiza un análisis (con scripts de Matlab no incluidos en la versión ejecutable de ProDis) que observa y examina, con base en estadística descriptiva, las diferencias entre las dos modalidades.
Resultados
Resultados de clasificación
Los gráficos de la Figura 1 representan los resultados del análisis del corpus A. En ellos, los nodos del árbol denotan un grupo clúster y se nos da una indicación de cuántos son los grupos óptimos para cada análisis basado en el mejor valor de silueta obtenido
1.
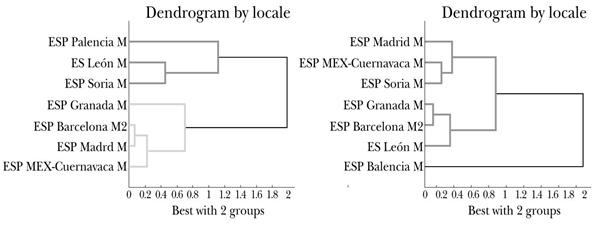
Figura 1 Dendrogramas del análisis del corpus A para interrogativas (izquierda) y declarativas (derecha)
En estos resultados se puede observar cómo, a partir de las interrogativas (izquierda), los puntos de encuesta se dividen en dos bloques: en el primero, arriba, figuran Palencia, León y Soria, todos ellos pertenecientes a la comunidad autónoma de Castilla y León en España; en el segundo, abajo, aparecen las ciudades españolas de Granada, Barcelona y Madrid, y la de Cuernavaca, en México.
Esta clasificación es fácilmente defendible para un lingüista; los puntos de encuesta de arriba muestran interrogativas ascendente-descendentes (¡H*L% en Palencia) o con un ascenso y una bajada a un punto medio al final, como en León y Soria. Por el contrario, la rama de abajo (Figura 1) contiene puntos donde las interrogativas muestran un pico en el pretonema y un ascenso final, L* H% (Figura 2).

Figura 2 Contornos de las oraciones interrogativas“¿La guitarra se toca con paciencia?” en los siete puntos de encuesta2
La gráfica a la derecha de la Figura 1 representa los enunciados declarativos. En este caso se puede observar un gran grupo que contiene todos los puntos de encuesta, menos Palencia; o sea, todas las declarativas pertenecen al mismo grupo excepto esta localidad, la cual ha sido imposible de clasificar. Este análisis es menos útil para el lingüista por dos motivos. En primer lugar, porque no le aporta información mediante grandes grupos que le sirva para hacer clasificaciones dialectales y, en segundo, si hubiera un motivo lingüístico (fonológico) por el cual Palencia aparece en una rama independiente en el análisis, porque en la actualidad esa característica de sus contornos entonativos no figura en los libros de dialectología y tampoco es apreciable en la curva que, tal y como se puede observar en la Figura 3, sólo presenta un mayor rango que el resto de curvas.

Figura 3 Contornos de las oraciones declarativas “La guitarra se toca con paciencia” en los siete puntos de encuesta3
Aportación de declarativas e interrogativas al análisis
Tal y como se ha visto en el apartado anterior, desde un punto de vista estrictamente basado en la inspección visual de las curvas, es fácil argumentar que las oraciones interrogativas son más útiles que las enunciativas para clasificar las variedades dialectales; sin embargo, tales afirmaciones son imprecisas si no se compara realmente cuánto difieren las clasificaciones que se basan en estas dos modalidades.
La Figura 4 presenta la dispersión en los valores de correlación de cada punto de encuesta comparado con el resto de puntos de encuesta del corpus A. En él se muestran los datos para las declarativas (arriba) e interrogativas (abajo), y cada una de las cajas representa un punto de encuesta.
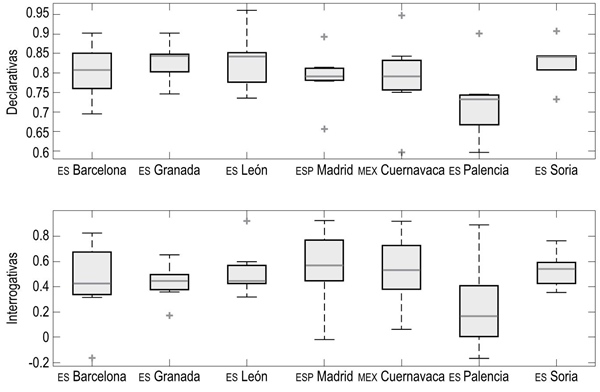
Figura 4 Gráficos de cajas y bigotes de las correlaciones de cada punto de encuesta con el resto de puntos de encuesta del corpus A.
En los gráficos de cajas y bigotes se puede observar, por tanto, que, en general, las declarativas suelen tener correlaciones más altas, es decir, las declarativas de los puntos estudiados se parecen más que las interrogativas. En concreto, las oraciones enunciativas tienen una correlación media entre ellas de r = 0.7982, mientras que las interrogativas tienen una correlación media de r = 0.4641. En la Figura 4 también se puede observar que la desviación de las interrogativas es más alta: σ = 0.2649, frente a σ = 0.0790 de las declarativas.
Siguiendo esta misma línea de pensamiento, nos podemos preguntar qué modalidad tiene más variabilidad en cada punto de encuesta, o sea, en qué modalidad hay más puntos que se parecen o diferencian en gran medida de ciertos puntos de la base de datos, ya que esto nos lleva a la modalidad que va a ejercer mejor una labor de clasificación. En este sentido, el mejor clasificador para las interrogativas sería Barcelona, ya que se perfila como la ciudad que muestra mayor rango: 0.9988; para las declarativas sería Cuernavaca, con un rango de 0.3512.
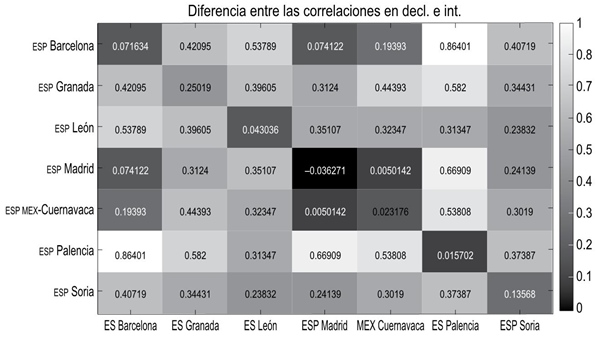
A este respecto resulta esclarecedor ver qué ciudades muestran más diferencias entre las correlaciones que ofrece el análisis de las declarativas y de las interrogativas en el corpus A. Tal y como se observa en la Figura 5, esa ciudad es Palencia.
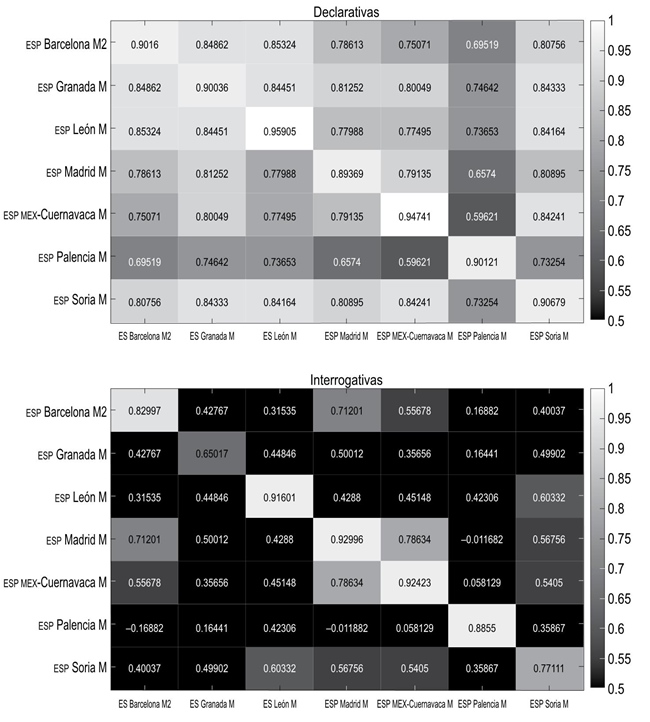
Estos datos se pueden explicar atendiendo a la correlación entre los puntos de encuesta separada por modalidad. La Figura 6 presenta las correlaciones para la modalidad declarativa (arriba) y para la modalidad interrogativa (abajo). Las correlaciones más altas (puntos que se asemejan entre ellos) aparecen en claro, y en oscuro, las correlaciones más bajas (puntos muy diferentes). Se puede observar, por tanto, que las declarativas tienen mayor correlación entre ellas que las interrogativas. También Palencia, aunque muestra las correlaciones más bajas del conjunto de datos, mantiene correlaciones de r > 0.6, que se considerarían moderadas. Sin embargo, en las interrogativas, al tener interrogativas descendentes, Palencia muestra correlaciones de menos de r < 0.5.
Resultados de otras lenguas
Después de ver estos resultados, cabe preguntarse si se repetirán para los datos de otras variedades o lenguas. Es decir, ¿hay diferencias entre lenguas en la aportación de declarativas e interrogativas a la variación dialectal?
La Figura 7 presenta los datos de correlación de interrogativas (izquierda) y declarativas (derecha) para los datos de italiano peninsular y de la isla de Cerdeña (italiano, sardo y catalán). De nuevo, las correlaciones más altas aparecen indicadas con un tono más oscuro. Sólo por el mapa de calor ya se puede apreciar que, en este caso, las interrogativas tienen correlaciones más altas, pese a que también en los datos hay una separación clara entre interrogativas ascendentes y descendentes. Específicamente, los datos de interrogativas tienen una correlación media de r = 0.7446, mientras que los atinentes a las declarativas presentan una correlación de r = 0.4519.
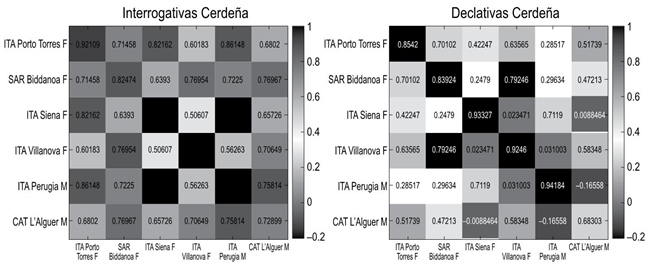
Figura 7 Correlaciones de declarativas e interrogativas para los puntos de encuesta de italiano peninsular y de la isla de Cerdeña
Como ocurría con los datos de español, también aquí las desviaciones son más altas para la modalidad con mayores diferencias dialectales; para las declarativas, 0.3278, y para las interrogativas, 0.1288.
Según las descripciones actuales sobre las variedades de Cerdeña en general (Vanrell et al. 2014) y sobre estos datos en particular (Roseano et al. 2015), los resultados podrían tener que ver con un pretonema en las declarativas con multitud de acentos tonales H*+L y L+H* en los que la alternancia entre la existencia o no de un pico asociado al acento léxico supone una correlación negativa entre los patrones. Esto se puede ver con detalle si se atiende a los valores de correlación de Siena y Peruggia (variedades de italiano peninsular) con puntos de Cerdeña como l’Alguer y Villanova, con las que tienen correlaciones negativas.
Además de los mayores cambios en la entonación, hay dos factores que se relacionan con la métrica de dialectometría usada y que pueden contribuir a dar más peso al pretonema en el caso de estas variedades. El primero es que, en una curva entonativa típica, el pretonema tiene más duración que el tonema; ello hace que el pretonema sea más importante para la fórmula. Para minimizar este efecto, como se ha dicho en el apartado de metodología, ProDis realiza una ponderación de las diferencias de F0 por la duración de la vocal de la sílaba que aprovecha el efecto del alargamiento prepausal para aumentar el peso del tonema en la fórmula. Pero, en el caso de las variedades de Italia, este ajuste de la fórmula no magnifica tanto el tonema como en las variedades del español, toda vez que las variedades de Italia, en general, cuentan con tónicas más largas que las del español. El segundo factor que contribuye a dar mayor peso al tonema en las interrogativas del español es su rango, el cual llega a ser muy elevado (entre 6 y 12 semitonos) y supone el mayor movimiento tonal de la frase (Fernández Planas et al. 2004; Sagastuy y Fernández-Planas 2014). Por ello, las diferencias que puedan tener con las interrogativas descendentes quedan muy bien reflejadas en la fórmula.
En el caso de las variedades lingüísticas de Italia, las declarativas sirven mejor que las interrogativas para realizar una clasificación dialectal por dos motivos: la mayor variabilidad entonativa de las declarativas frente a las interrogativas y el mayor rango de los movimientos tonales del pretonema con respecto a los del tonema.
Discusión y conclusiones
Los datos analizados para el español verifican el análisis lingüístico que afirma que los datos de las interrogativas aportan más información a la clasificación dialectal que las declarativas. Concretamente, en los datos analizados, las declarativas del español muestran que son muy semejantes entre ellas, mientras que las interrogativas tienen más diferencias, las cuales se pueden clasificar en dos grupos. De esta forma se ratifican los resultados documentados por Fernández-Planas et al. (2015) y Dorta (2018).
En cuanto al análisis de las variedades lingüísticas de Cerdeña, éste nos ha permitido comprobar que la mayor variabilidad de las interrogativas no es universal, tal y como harían pensar algunas teorías (Ladd 1980; Rietveld & Gussenhoven 1985; Gussenhoven & Chen 2000). Las variedades de Cerdeña tienen un patrón más semejante para las interrogativas que para las declarativas, que presentan más variabilidad. Un caso parecido se puede documentar para el catalán, lengua en la que el proyecto AMPER analiza tres modalidades oracionales, enunciativas, interrogativas e interrogativas encabezadas por la partícula átona que. Para los dialectos catalanes, la modalidad más distintiva resulta ser la de interrogativas encabezadas por que (Fernández-Planas et al. 2015a). Tal modalidad es también la que más variabilidad muestra según el punto de encuesta.
Este segundo análisis nos hace notar que los resultados obtenidos para las variedades de español incluidas en este estudio podrían no replicarse si se cambia la muestra de análisis. Los dialectos del español aquí analizados -principalmente del español peninsular- incluyen datos con declarativas únicamente descendentes, por lo que habría que verificar si la clasificación sería más clara usando las interrogativas en variedades lingüísticas con diferentes patrones entonativos en las declarativas. Sería de especial interés repetir el análisis con variedades que incluyan declarativas ascendentes y descendentes, variedades mexicanas en las que se puedan encontrar patrones ascendentes a un nivel medio M% y patrones ascendente-descendentes (Martín Butragueño 2014; Orozco 2016; Mendoza Vázquez 2019), además del consabido patrón descendente L* L%, que parece ser común a toda el habla hispana o el habla ascendente de Chiloé, en Chile (Muñoz-Builes et al. 2017).
En definitiva, y después de revisar los datos de los dos análisis, se puede afirmar que la modalidad que aporte más luz a la clasificación dialectal dependerá de cuál sea la que muestre diferencias más acusadas en la lengua y, en particular, de qué movimientos sean más prominentes en términos de rango de F0, punto esencial que hace que las clasificaciones dialectométricas no siempre coincidan con las clasificaciones que realizan los lingüistas.

