











 text new page (beta)
text new page (beta) Spanish (pdf)
Spanish (pdf)
 Article in xml format
Article in xml format Article references
Article references
 Send this article by e-mail
Send this article by e-mail Cited by SciELO
Cited by SciELO  Similars in
SciELO
Similars in
SciELO 
 Permalink
PermalinkIntroducción
Una de las variables claves para la acertada toma de decisiones en el manejo de los recursos maderables, es el volumen de los árboles en pie (Clutter et al. 1983). De forma convencional, el volumen de cada árbol se estima a partir del diámetro normal y la altura total, para luego extrapolar la información a todo el rodal o bosque bajo manejo (Carrillo et al. 2004). Para la estimación del volumen fustal, se debe contar con herramientas matemáticas precisas, que incorporen la menor cantidad posible de variables de bajo costo, lo que permite un estricto control de la extracción de madera en rollo, base para una mejor planificación del aprovechamiento sustentable de los bosques (Romahn y Ramírez-Maldonado 2010, Martínez-López y Acosta-Ramos 2014). Pero muchas veces se tiene una base de datos con individuos de diferentes edades y tamaños, lo que propicia una alta dispersión de la información, lo que causa que los valores más alejados de la media aritmética no sean explicados con propiedad por las técnicas de regresión convencionales, en particular, con el método de Mínimos Cuadrados Ordinarios (MCO) o en su forma no lineal (MCNL) que generan una línea y curva de regresión, según sea el caso, basada en el promedio (Galton 1890).
El uso de Mínimos Cuadrados (MC), tanto en su forma lineal como en su forma no lineal, implica asumir propiedades paramétricas como la distribución normal de los datos, la homogeneidad de la varianza, la independencia de los regresores y la ausencia de colinealidad (Dismuke y Lindrooth 2006). El incumplimiento de algunos de estos supuestos, limita su aplicación; por ejemplo, si se detecta colinealidad, no deben usarse los MCO, debido a que se contraviene al soporte teórico-matemático del método (Weeraratne 2016). Muchas veces, se deben transformar los datos originales sacándole raíz cuadrada, logaritmo natural, incluir variables de ponderación en los residuales o hacer cálculos adicionales para intentar solventar estas restricciones (Box y Cox 1964, Cailliez 1980, Zimmerman 1994). Una alternativa en silvicultura y ecología forestal, es la regresión de cuantiles (RC), que permite generar rectas de regresión a cualquier porción dada de una variable respuesta, definida por su distribución de probabilidad (Koenker y Bassett 1978, Cade y Noon 2003). Una de las ventajas de la RC radica en su flexibilidad para evaluar el efecto de una variable aleatoria sobre la distribución de una variable de interés, al generar una familia de modelos de regresión, uno para cada cuantil de la distribución condicional (Sosa-Escudero 2005), mientras que la regresión ordinaria sólo estima los efectos medios condicionales de las variables independientes (Koenker y Bassett 1978, Sosa-Escudero 2005).
La regresión cuantílica se usa principalmente en las ciencias sociales, y muy poco en las ciencias biológicas. En las ciencias sociales, se ha utilizado para estimar la elasticidad del precio en la demanda de alcohol (Manning et al. 1995); el efecto de la educación de los padres y su edad sobre la educación de los hijos (Di Gresia et al. 2005); y en el área forestal se ha propuesto para estudiar la producción de bellotas en un bosque (Cade et al. 1999), para predecir el crecimiento de los árboles (Bohora y Cao 2014) o para determinar la relación alométrica entre el diámetro y la copa de los árboles (Pretzsch et al. 2015). Por lo anterior, el objetivo del trabajo fue evaluar la efectividad de la regresión cuantílica para modelar el volumen fustal de Pinus patula Schl. et Cham. en función del diámetro normal comparando sus resultados con los de un modelo tradicional.
Materiales y métodos
Área de estudio
El estudio se realizó en los bosques templados de Santiago Comaltepec, en la Sierra Norte del estado de Oaxaca, al suroeste de México, entre las coordenadas 17° 43’ 36” - 17° 32’ 50” LN y 96° 35’ 12” - 96° 16’ 02” LO. El predio tiene una superficie de 26.5 km2 (Figura 1), la elevación sobre el nivel del mar fluctúa entre los 1 800 y 3 000 m. La temperatura media máxima anual es de 13.4 °C, con mínima anual de 4.7 °C. La precipitación en el verano oscila entre los 600 y 1 200 mm, y en la temporada de secas la precipitación media es de 225.5 mm con temperatura media de 16 °C (INEGI 2002, INEGI 2018).

Muestreo y variables
Los datos usados provienen de una muestra de 148 árboles dominantes y codominantes de Pinus patula registrados en 60 parcelas temporales de 1 000 m2 distribuidas sistemáticamente en el área de estudio, tamaño de parcela común en el inventario forestal con fines de aprovechamiento forestal. Para predecir el volumen fustal con corteza, se usó como predictor el diámetro normal, a 1.30 m del nivel del suelo, al ser una de las variables indicadoras confiables de las dimensiones de los árboles, que se usa para predecir el volumen, para definir la estructura de un rodal o clasificar una masa forestal, entre otros usos (Gadow et al. 2007, Návar 2009). El diámetro normal se obtuvo con una forcípula y el volumen observado se generó con la ecuación tradicional de Schumacher y Hall (1933) al integrar el diámetro normal y la altura total de los 148 individuos que conformaron la muestra. La estadística descriptiva de las variables usadas se muestra en la Tabla 1.
Análisis de datos
Para probar si la regresión de cuantiles puede mejorar la predicción del volumen fustal de la especie estudiada, se usó solo el diámetro normal como predictor, usando de referencia el modelo exponencial de Berkhout (Loetsch et al. 1973) por ser uno de los mejores modelos de una entrada que predice el volumen fustal de especies de pino con errores mínimos (Bonyad y Rostami 2005, Wardasanti 2011, Ramírez-Martínez et al. 2016), cuya expresión es: V = β0 · DNβ1 Donde: V: volumen (m3), DN: diámetro normal (cm), βi: parámetros de regresión.
Con el método de la regresión cuantílica (Koenker y Bassett 1978, Koenker y Mizera 2004), se generaron las rectas de regresión de los cuantiles de 0.25, 0.50 y 0.75, procurando abarcar la variabilidad de los datos por encima y por debajo de la curva de regresión generada con MCNL. La definición analítica de la regresión cuantílica es: Sea Y una variable aleatoria cualquiera, definida por una función FY(.), de la forma: FY(y) = prob (Y ≤ y) = τ
Tal que, para cualquier valor 0 < τ < 1, Q(τ) = inf y : F(y) ≥ T corresponde al τ-ésimo quantil de X En este sentido, la mediana Q(1/2), juega un papel esencial; y, del mismo modo que la función de distribución, la función cuantílica proporciona una caracterización de la variable aleatoria de interés, Y. De esta forma, un cuantil puede ser planteada como la solución a un problema de optimización simple. Tal que, para cualquier valor 0 < τ < 1, puede definirse como:
Donde: I(.) denota la función indicadora. Al minimizar la esperanza de ρτ (Y - ξ), con respecto a ξ, ξ(τ), la más pequeña de las cuales está en Q(τ). Analógicamente, la muestra de Q(τ), que proviene de una muestra aleatoria y1, ..., yn, de Y's, correspondería a la τ-ésima muestra cuantílica, de modo que el problema de optimización se puede expresar como:
Los planteamientos teóricos de la regresión de cuantiles, la ilustración gráfica de su función de verificación, y otras ecuaciones derivadas se encuentran en Koenker y Bassett (1978) y Koenker y Mizera (2004). La contribución de las constantes de cada recta cuantílica se valoró usando un nivel de significancia de α=0.05 (Di Rienzo et al. 2005) haciendo una corrección de Bonferroni con el fin de reducir en lo posible la probabilidad de cometer el error tipo 1 (Hochberg 1988). Al no observarse una alta variabilidad de los datos (Tabla 1), se generaron solo tres rectas cuantílicas, en los cuantiles 0.25, 0.50 y 0.75, las cuales cubrieron la relativa dispersión de los datos.
Para evaluar el ajuste de las rectas ajustadas de cada cuantil, se usaron los criterios de ajuste de análisis gráfico de los residuales y el criterio de información de Akaike (AIC), que mide la calidad relativa del ajuste de un modelo, al medir la diferencia entre la proyección del modelo y la realidad basada en el criterio teórico de la información mínima en el subconjunto Q(τ) asociado a un τ-ésimo cuantil, cuando menor es el valor de AIC, más admisible es el modelo (Akaike 1974). En un inicio se obtuvo un pseudo valor de ajuste (R1) para cada recta cuantílica, al comparar la suma de desviaciones ponderadas para el modelo completo con la misma suma del modelo (Koenker y Machado 1999); al no poder compararse con los indicadores de ajuste del modelo de Berkhout el cuál se ajustó por MCNL, estos coeficientes no se incluyeron; pero se estimaron coeficientes de determinación ajustado (R2 adj) y el error residual para cada cuantil para contrastar con mayor claridad el rendimiento de cada modelo. Los valores de R2 adj, se obtuvieron al extraer y reajustar los valores del subconjunto Q(τ). En este caso, R2 adj, representa el porcentaje de variación de los resultados, explicado por una recta cuantílica, asumiendo que cada recta se asocia a un intervalo definido de valores de la τ-ésima regresión cuantílica. Para el ajuste de los modelos se usó el paquete quantreg de R (Koenker et al. 2015). Los modelos se evaluaron mediante una validación cruzada con una muestra independiente de 50 individuos. Finalmente, los resultados se ejemplificaron buscando la ecuación cuantílica que redujera el error de predicción según la categoría diamétrica de los árboles.
Resultados y discusión
Los coeficientes paramétricos con sus respectivos valores de p-value de las diferentes rectas cuantílicas y del modelo no lineal de Berkhout se muestran en la Tabla 2. Con base en los indicadores de ajuste, el modelo no lineal de Berkhout ajustado por MCNL fue superado en la mayoría de los casos. Tomando en cuenta el R2 adj los valores en los cuantiles de 0.25, 0.50 y 0.75 fueron de 0.94, 0.99 y 0.99, respectivamente; mientras que para el modelo de Berkhout fue de 0.94 (Tabla 2). Al comparar los errores de los modelos, se observó un error de predicción de 0.353 m3 en el cuantil 0.250, 0.1253 m3 en el cuantil 0.50 y 0.408 m3 contraste, con el método de mínimos cuadrados no lineales se observó un error de 0.795 m3. De igual forma al contrastar los valores de AIC, con la técnica de MCNL se obtuvo un valor mayor en comparación con los obtenidos con RC. En todos los casos, las constantes fueron significativas (p < 0.01) al hacer la corrección de Bonferroni.
Tabla 2 Parámetros e indicadores de ajuste para cada recta cuantílica y para el modelo de Berkhout ajustado por mínimos cuadrados no lineales
| Mínimos cuadrados ordinarios | ||||||
|---|---|---|---|---|---|---|
| Modelo | Estimación | P> |t| | AIC | R2 adj | Error residual | |
| Berkhout | β 0 | 0.000591 | <0.0001* | 237.1086 | 0.94 | 0.795 |
| β 1 | 2.138211 | <0.0001* | ||||
| Regresión cuantílica | ||||||
| t= 0.25 | β 0 | -4.17824 | <0.0001* | 33.4014 | 0.94 | 0.353 |
| β 1 | 0.12457 | <0.0001* | ||||
| t= 0.50 | β 0 | -5.011244 | <0.0001* | -31.7449 | 0.99 | 0.125 |
| β 1 | 0.155982 | <0.0001* | ||||
| t=0.75 | β 0 | -5.669588 | <0.0001* | 47.7839 | 0.99 | 0.480 |
| β 1 | 0.185926 | <0.0001* | ||||
AIC: Criterio de información Akaike; R2 adj: Coeficiente de determinación ajustado, β0 y β1: Parámetros estimados para cada modelo. “*” Parámetros significativos con un nivel de significancia de 0.01.
Con las dos técnicas, se observa que la línea proyectada por MCNL solo divide en dos porciones la nube de puntos, mientras que la regresión cuantílica intenta cubrir en lo posible la dispersión de los datos al trazar tres rectas (Figura 2a y 2b). Otras de las ventajas identificadas del RC sobre MCNL, es que la primera técnica puede modelar con mayor robustez una categoría diamétrica específica. En un análisis complementario se comprobó que usando la ecuación del cuantil 0.25, el error de predicción disminuye de forma significativa para los árboles con diámetros entre 55 y 70 cm.
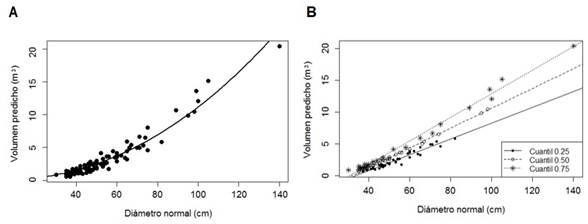
Figura 2 Comportamiento grafico del ajuste del modelo de Berkhout por mínimos cuadrados no lineales (a) y regresión de cuantiles (b)
Los datos estudiados mostraron baja dispersión, de modelarse variables con alta variabilidad, los datos extremos quedarían alejados de la curva trazada por el modelo de Berkhout, ocasionando una subestimación o sobreestimación del volumen fustal (Figura 2a y 2b), error que no se refleja en los indicadores de ajuste, ya que la línea de regresión por MCNL se traza en función de la media (Galton 1890). Una forma de solucionar la alta heterogeneidad de los datos, es trazar tantas rectas como sean necesarias a fin de cubrir los datos extremos (Cade et al. 1999, Cade y Noon 2003; Koenker y Mizera 2004).
Al contrastar los residuos de los dos métodos en un mismo gráfico, se observó un mayor error con los datos del modelo tradicional, lo cual es causado por los valores extremos, los cuales se redujeron usando la ecuación del cuantil 0.75 (Figura 3). El método de MCNL comete un error significativo en las secciones donde la distribución de la variable condicional no es, el cual es corregido parcialmente por la regresión cuantílica al usar las ecuaciones de los cuantiles 0.25 y 0.50, al mejorar la predicción (Figura 3). Con el modelo de Berkhout, se observó una alta heterocedasticidad en los residuales; en contraste, las rectas cuantílicas corrigen este problema. De igual forma, los residuos estudentizados de las distintas rectas cuantílicas se distribuyen dentro de la franja del intervalo de confianza al 95%, como el caso del cuantil 0.50 (Figura 4a), mientras que los residuos de los valores extremos del modelo de Berkhout quedaron fuera de este intervalo (Figura 4b).

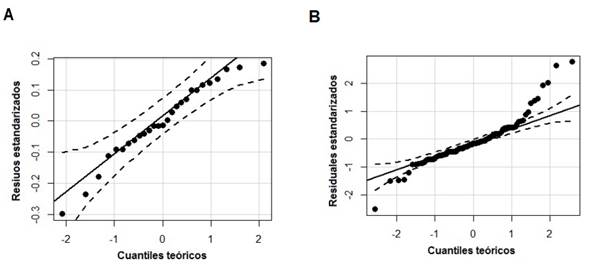
Figura 4 Residuales para la recta cuantílica de τ = 0.50 (a) y residuales del modelo de Berkhout (b) con una confiabilidad de 95%
La correcta aplicación de la regresión cuantílica radica en la adecuada identificación de la fracción de datos susceptibles a ser predichos por la línea o curva cuantílica con el menor error. Usando los parámetros estimados, los modelos finales son: (1) V = 0.000591*DN 2.138211, que corresponde al modelo ajustado por el método de mínimos cuadrados; (2) V = -4.17824 + 0.12457*DN correspondiente al Q(τ = 0.25) ajustado con QR, que fue apropiado para predecir el volumen de árboles con categorías diamétricas de 55 a 80 cm, excluyendo la categoría de 75 cm; (3) V = -5.011244 + 0.155982*DN, modelo final del Q(τ = 0.50), un modelo adecuado para modelar el volumen de árboles con las categorías diamétricas de 40-50, 75 y 95 cm; y (4) V = -5.669588 + 0.185926*DN, correspondiente al Q(τ = 0.75), con óptimo rendimiento para árboles con categorías diamétricas de 30-35 cm, de 90 y de 100 a 140 cm.
Con estos modelos, se presentan los resultados de los dos métodos con medidas de un árbol proveniente de una muestra independiente, para realizar una validación cruzada, con un diámetro de 35 cm y volumen observado de 0.8420 m3. Con el método de MCNL se proyecta un volumen de 1.1834 m3, mientras que el método RC proyecta un volumen de 0.8378 m3; con la ecuación de Q(τ = 0.75) que es el modelo apropiado para esta categoría diamétrica, observándose que el modelo de MCNL comete un error de 0.341 m3 en tanto que con RC es de 0.004 m3. Aparentemente es un error pequeño; pero al multiplicar por el número de individuos de un rodal o predio, se incremente el error. Debe tomarse en cuenta que en este estudio se generaron rectas, pero la predicción puede mejorarse si se generan líneas suavizadas en cada cuantil ajustadas mediante una regresión local.
Al contrastar los modelos ajustados con una muestra independiente, se validó que cada recta cuantílica cubre la dispersión de los datos extremos (Figura 5); en cambio, el modelo de Berkhout, a pesar de ser un modelo de tipo exponencial, excluye los valores extremos. Se concluye que al usar de forma apropiada la regresión cuantílica, la predicción del volumen fustal de las especies maderables como el Pinus patula, puede predecirse con mayor precisión, usando algún atributo de fácil medición, como el diámetro normal, lo que la convierte en una herramienta potencial para modelar datos del área forestal.


