











 nueva página del texto (beta)
nueva página del texto (beta) Español (pdf)
Español (pdf)
 Artículo en XML
Artículo en XML Referencias del artículo
Referencias del artículo
 Enviar artículo por email
Enviar artículo por email Citado por SciELO
Citado por SciELO  Similares en
SciELO
Similares en
SciELO 
 Permalink
Permalink
Introducción
El pronóstico, durante largo tiempo denigrado como una pérdida de tiempo, en el mejor de los casos, o como un pecado en el peor, se convirtió en una necesidad absoluta a lo largo del siglo XVII para aquellos aventureros que buscaron construir su propio futuro (Bernstein, 1998). Su evolución ha ido acompañada de los grandes avances en la estadística del siglo XX y la creciente potencialidad computacional de las primeras décadas del tercer milenio (Hanke y Wichern, 2014).
Un pronóstico es una predicción de uno o más eventos futuros a partir de indicios. El nivel de éxito de un pronóstico radica en la exactitud con la que coincide con la realidad; llegar a este resultado no es una tarea fácil, tal como diría irónicamente el físico danés Niels Bohr: “Es difícil hacer predicciones, especialmente sobre el futuro” (Montgomery, Jennings y Kulahci, 2015).
A pesar de que al predecir el futuro existe un riesgo inherente de imprecisión, el pronóstico es un aspecto importante de la investigación y la práctica de la ingeniería industrial, ya que proporciona información necesaria para tomar buenas decisiones. ¿Cómo un gerente de operaciones establecería programas de producción realistas sin tener alguna estimación de sus ventas? ¿Cómo podría una compañía de atención telefónica determinar su plantilla laboral sin alguna suposición de la demanda futura de sus servicios? Las respuestas a estas y más preguntas requieren la realización de pronósticos.
En noviembre del año 2008, en el marco del Congreso Internacional sobre Pronósticos y Planeación en la Cadena de Suministro, llevado a cabo en la Ciudad de México, Anish Jain, presidente del Institute of Business Forecasting & Planning (IBF), consideró lo siguiente:
En la actualidad, por lo menos 80 por ciento de las empresas en México registran graves errores en sus pronósticos de negocio y planeación de ventas y producción, lo que afecta fundamentalmente a su rentabilidad, productividad y gestión óptima de sus cadenas de suministro, además de poner en riesgo su capacidad competitiva y permanencia en los mercados internacionales, así como la del país en su conjunto (Olavarrieta, 23 de noviembre 2008, párr. 3).
Hasta la publicación de la presente investigación, no se ha encontrado artículo o publicación relacionada que muestre que el porcentaje de empresas con error de pronóstico haya disminuido en la actualidad; sin embargo, y en medio de una difícil recuperación económica por la pandemia de la enfermedad por coronavirus de 2019 (covid-19), los pronósticos son una herramienta importante para que las empresas mejoren su planeación de ventas y de producción mediante la maximización de las ganancias y la minimización de sus costos por una mala optimización de los recursos. Ahora bien, cuando un negocio, sobre todo las pequeñas y medianas empresas, integran los pronósticos como un agente en el proceso de administración de sus procesos y servicios, surge la pregunta: ¿qué modelo de pronósticos debe usarse?
Un ejemplo de la aplicación robusta de los pronósticos se encuentra en el sector público. El 23 de noviembre del año 2017 se publicó en el Diario Oficial de la Federación el Manual de pronósticos, el cual tiene como propósito establecer los procedimientos, reglas y principios de cálculo a seguir por el Centro Nacional de Control de Energía (Cenace) y los participantes del mercado para la estimación de los pronósticos de la demanda y los pronósticos de generación de energía eléctrica (Secretaría de Energía, 23 de noviembre de 2017).
De acuerdo con este manual, los modelos de pronósticos que pueden usarse por el Cenace son: promedio móvil simple, promedio móvil ponderado, regresión lineal múltiple y el método de días similares (si las condiciones del día A son similares a las del día B, el pronóstico es el mismo para ambos). El método de regresión lineal múltiple considera los valores históricos de cinco años de las siguientes variables: demanda real por zona de carga, variables climatológicas por zona de carga, días festivos y días atípicos; también hay que considerar los datos actuales de: demanda horaria real del día de operación, variables climatológicas pronosticadas a siete días, día de la semana al que corresponde el pronóstico, mes al que corresponde el pronóstico, variación de la demanda de los centros de carga y fechas que presenten cambio de horario.
El Cenace tiene la obligación de realizar el pronóstico de la demanda cada hora de la energía eléctrica en megavatios/hora para cada uno de sus sistemas de redes eléctricas, así como usar la métrica de error porcentual absoluto medio (MAPE, por sus siglas en inglés) para medir el grado de certeza del modelo con el que realiza sus pronósticos de demanda.
En la Tabla 1 se muestra un análisis comparativo con base en las métricas de MAPE correspondientes al mes de septiembre del 2021 para los sistemas interconectados de Baja California y Baja California Sur, las cuales fueron obtenidas del Sistema de Información de Mercado (SIM) (Cenace, 10 de octubre de 2021)
Tabla 1 Comparación del error de pronóstico con la métrica MAPE de los sistemas interconectados de la península de Baja California para el mes de septiembre del 2021
| Baja California | Baja California Sur | |
| Porcentaje de pronósticos con MAPE > 5 % | 10 % | 27.50 % |
| Mayor MAPE | 25.36 % | 156.36 % |
| Fecha del mayor MAPE | 24/09/2021 | 09/09/2021 |
Fuente: Elaboración propia con base en el Cenace (10 de octubre de 2021)
Dados los datos analizados, es justo preguntarse a qué se debe la gran diferencia del porcentaje de MAPE entre ambos sistemas eléctricos de la península de Baja California. La respuesta se encuentra al analizar la situación climática de Baja California Sur. Entre el 9 y 10 de septiembre del 2021, el huracán Olaf tocó tierra en los municipios de Los Cabos y La Paz y generó fallas en el suministro eléctrico (Redacción Animal Político, 9 de septiembre de 2021) que el pronóstico no tenía contemplado, lo que causó que los 36 mayores errores de pronóstico del mes se dieran en esas fechas.
Cabe recalcar que el Cenace tiene la libertad de elegir el modelo de pronósticos que considere mejor, incluido el de regresión lineal múltiple, que entre otras variables incluye al clima de la semana; sin embargo, el modelo fue incapaz de reaccionar a un evento atípico, como lo es el paso de un huracán. El caso del uso de pronósticos por parte del Cenace deja algunas enseñanzas a considerar al momento de realizar un modelo para pronosticar la demanda de cualquier producto o servicio:
No existe un modelo de pronósticos que logre estimar exactamente la demanda futura, mucho menos en días atípicos.
Es conveniente tener en cuenta más de un modelo de pronósticos, ya que no hay una certidumbre de cuál puede ser el más exacto en un momento determinado; por ejemplo, un modelo de regresión lineal múltiple no necesariamente es mejor que uno de promedios móviles por ser matemáticamente más complejo, pero sí más costoso, ya que se necesita procesar más información conforme aumentan las variables y muchas de ellas no son estadísticamente significativas, además de que no siempre la demanda se ajusta satisfactoriamente a un comportamiento lineal.
Es importante considerar bajo qué horizonte de pronóstico se comportan mejor los datos; por ejemplo, los pronósticos de demanda de energía del Cenace se adecuan mejor a cada hora y no tanto de forma diaria.
La robustez de un modelo de pronósticos radica principalmente en la cantidad y la calidad de los datos de entrada. Con calidad se hace referencia a que la medición de los datos sea lo más exacta posible a fin de garantizar su confiabilidad.
Las deducciones anteriores son la motivación del presente trabajo de investigación documental, que busca definir la clasificación de los principales tipos de pronósticos, así como proponer algunos de los modelos más representativos de la actualidad que resulten factibles para las pequeñas y medianas empresas, los cuales, con base en la literatura consultada, tienen el potencial para lograr un pronóstico exitoso.
Método
El enfoque metodológico empleado fue el cualitativo. Para ello se tomó en cuenta el método de investigación bibliográfico, con un análisis histórico-lógico del desarrollo de los pronósticos. La revisión de la literatura permitió determinar, extraer, describir, analizar y comparar la información más destacada obtenida de diferentes libros para encontrar el fundamento teórico de los pronósticos de series de tiempo, así como indagar en artículos de revistas científicas e investigaciones recientes enfocados en la utilización de diferentes métodos de pronósticos de demanda mediante series de tiempo.
Resultados
Existen variadas clasificaciones sobre los pronósticos de acuerdo con sus características. Una de las más clásicas divide los pronósticos en dos enfoques: cualitativos, basado en las opiniones, experiencia, conocimientos y valores del pronosticador, y cuantitativos, modelos matemáticos con base en un conjunto de datos históricos y valores asociados (Heizer y Render, 2014). Si bien son enfoques distintos, pueden complementarse
dentro de la organización. Aun con todo, para fines de la presente investigación, aquí se hará énfasis en los pronósticos cuantitativos.
Badiru y Omitaomu (2020) proponen una clasificación que engloba satisfactoriamente al enfoque cuantitativo. De acuerdo con el requerimiento de los datos, se dividen los pronósticos en dos tipos:
Pronósticos intrínsecos. Se basa en el supuesto de que los datos históricos pueden describir adecuadamente el escenario del problema que se va a pronosticar. Con el pronóstico intrínseco, los modelos de pronóstico basados en datos históricos utilizan la extrapolación para generar estimaciones para el futuro.
Pronósticos extrínsecos. Mira hacia afuera y asume que los pronósticos internos pueden correlacionarse con factores externos. Por ejemplo, un pronóstico interno de la demanda de un nuevo producto puede basarse en pronósticos externos de los ingresos de los hogares.
Otra forma de llamar a los pronósticos intrínsecos es como pronósticos univariados o de series de tiempo. Mientras que los pronósticos extrínsecos engloban los modelos de regresión lineal simple, regresión lineal múltiple y pronósticos multivariados de series de tiempo, estos últimos consisten en pronosticar dos o más series de tiempo, que tienen correlación, simultáneamente (Korstanje, 2021).
Los buenos pronósticos se basan en la disponibilidad de buenos datos. Para una pequeña o mediana empresa, podría resultar menos accesible el obtener los datos de las diferentes variables significativas para la realización de un pronóstico extrínseco, además de que hay casos donde contar con datos de múltiples variables no garantiza que un modelo de regresión lineal sea mejor que un modelo de series de tiempo univariados. Por lo tanto, para fines de la presente investigación, se recomiendan modelos de pronósticos de series de tiempo univariados.
Heizer y Render (2014) definen que las componentes de una serie de tiempo son:
Tendencia: movimiento gradual (que ocurre de forma sucesiva y continua) de los datos, hacia arriba o hacia abajo, en la serie de tiempo.
Estacionalidad: patrón de datos que se repite después de n periodos de tiempo menores a un año (días, semanas, meses, trimestres, semestres), por ejemplo, los restaurantes experimentan estaciones semanales donde los sábados tienen un aumento de sus ventas.
Ciclos: son patrones en los datos, superiores a un año, debidos a factores diferentes a la estacionalidad. Debido a que no son periódicos, los intervalos de tiempo de las variaciones cíclicas no son fijos. Los ciclos muestran habitualmente los periodos de bonanza, desaceleración o caída de las economías y suelen ser difíciles de pronosticar, dadas sus múltiples causas (acontecimientos políticos, turbulencia internacional, etc.)
Variaciones aleatorias: datos generados por casualidad o situaciones inusuales. Dado que no siguen algún patrón, no se pueden predecir.
En la Figura 1 se muestra una serie de tiempo de la demanda para un periodo de cuatro años. Se muestra la tendencia, la línea de la demanda real, la demanda promedio, los picos estacionales y la variación aleatoria.
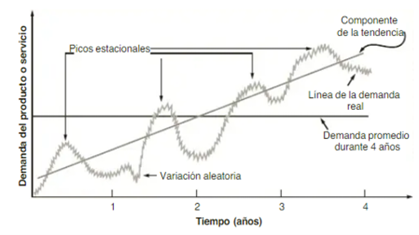
El objetivo del análisis de series de tiempo es utilizar la densidad conjunta para hacer inferencias de probabilidad sobre observaciones futuras; ello resulta más factible si la serie de tiempo es estacionaria. El concepto de estacionariedad implica que la distribución de la serie temporal es invariable con respecto a cualquier desplazamiento temporal. La no estacionariedad en una serie temporal puede reconocerse en el componente de la tendencia. Una gráfica muy dispersa, sin tendencia a un valor particular, es una indicación de no estacionariedad. En algunos casos donde no existe la estacionariedad, se utiliza alguna forma de transformación de datos para lograrla. Para la mayoría de los datos de series de tiempo, la transformación habitual que se emplea es la diferenciación. La diferenciación implica la creación de una nueva serie de tiempo que muestre una estacionariedad, tomando las diferencias entre períodos sucesivos de la serie original (Badiru y Omitaomu, 2020).
El método de Box-Jenkins, mejor conocido como promedios móviles autorregresivos integrados (Arima, por sus siglas en inglés), se utiliza para cualquier patrón de datos, es decir, estacionarios o no estacionarios (mediante la diferenciación), en un horizonte a corto plazo, lo que resulta en una ventaja cuando no se tiene un conocimiento claro del comportamiento de los datos del análisis. Por lo tanto, el modelo Arima es una de las propuestas más populares para la realización de pronósticos (López, 2018; Mills, 2019).
Como se mencionó anteriormente, la complejidad matemática de los modelos no garantiza su éxito (Brighton y Gigerenzer, 2015; Green y Armstrong, 2015); prueba de ello es que en el año 2000 se realizó la tercera competencia Makridakis del International Institute of Forecasters, organizada por el Dr. Spyros Makridakis de la Universidad de Nicosia. Los participantes usaron su método preferido para pronosticar. Un total de 3003 series de tiempo fueron realizadas. Las conclusiones a las que se llegaron fueron:
Al igual que en un estudio previo, los métodos avanzados o estadísticamente complejos no necesariamente dan como resultado pronósticos más precisos que los métodos más simples.
Diferentes medidas de precisión producen resultados consistentes cuando se usan para evaluar diferentes métodos de elaboración de pronósticos (por ello se recomienda elegir más de un criterio para medir el error).
La combinación de tres métodos de suavización exponencial superó, en promedio, a los métodos de suavización de forma separada (suavización simple, suavización de Holt-Winters y suavización Damped). Este fue el único método de combinación de pronósticos que participó en la competencia, logrando los mejores resultados de los 24 métodos de series de tiempo univariadas concursantes, entre ellos, modelos ARIMA, modelos autorregresivos, modelos de análisis de tendencias y redes neuronales artificiales (Makridakis y Hibon, 2000).
La efectividad de los diferentes métodos de elaboración de pronósticos depende de la longitud del horizonte del pronóstico y la clase de datos (anuales, trimestrales, mensuales) que se analizan. Algunos métodos funcionan con más exactitud para horizontes cortos, en tanto que otros son más adecuados para horizontes más largos. Algunos métodos funcionan mejor con datos anuales y otros son más apropiados para datos trimestrales y mensuales (Hanke y Wichern, 2014).
Pasarían 18 años para que se volviera a organizar otra de esta competencia de pronósticos, conocida como M-Competitions. Durante ese largo periodo, el surgimiento de la inteligencia artificial y el aprendizaje automático, llamado en inglés machine learning, permitieron desarrollar técnicas para potenciar el análisis de datos de las computadoras, que, si bien cubre campos que ya habían sido tratados por la estadística inferencial, como los pronósticos, incorpora la complejidad de la lógica computacional para ayudar a obtener el resultado más certero.
Cabe señalar que, así como la complejidad matemática no garantiza un mejor pronóstico, tampoco el recurrir a la inteligencia artificial logra superar categóricamente a los pronósticos clásicos o tradicionales. Stoll (2020) realizó una comparación entre los métodos tradicionales y los de aprendizaje automático para el pronóstico de la demanda de varias familias de productos de una empresa, utilizando como criterios el MAPE y la raíz cuadrada del error cuadrático medio (RMSE), y concluyó que los modelos de suavización exponencial triple y Arima tuvieron mejores resultados que los modelos de pronósticos de aprendizaje automático elegidos para la comparación.
La conclusión de que el modelo de suavización exponencial triple, también conocido como modelo de Holt-Winters, es el mejor concuerda con los resultados de la competencia Makridakis, a pesar de que hayan pasado 20 años entre ambas comparativas. Dicha concordancia sustenta que este modelo es una opción válida actualmente para la realización de un pronóstico de demanda. Aun así, cabe recordar que cada serie de datos es diferente y la superioridad de un método no es previsible con seguridad.
Pero no todo está perdido para los pronósticos de aprendizaje automático. En un escenario extremo llevado a cabo en la misma investigación de Stoll (2020), se utilizaron valores altos de desviación estándar, la presencia de valores atípicos y una pequeña cantidad de observaciones, lo que afectó a ambos tipos de métodos de pronóstico estudiados (métodos tradicionales y de aprendizaje automático). De hecho, en este escenario el modelo de aprendizaje automático de bosques aleatorios (random forest) y el de redes neuronales recurrentes (RNN, por sus siglas en inglés) resultaron dignos contendientes e hicieron un buen intento por seguir la tendencia y la estacionalidad del conjunto de pruebas (Stoll, 2020).
Una red neuronal informática trata de simular, de forma virtual, el comportamiento de un cerebro biológico. Análogamente, está compuesta de unidades simples interconectadas, cuyos enlaces hacen que el estado de activación de las células vecinas se vea incrementado o inhibido. A diferencia de otros algoritmos informáticos, este puede aprender por sí mismo a medida que se va ingresando nueva información al sistema. Así, el modelo se va adaptando y el peso de las conexiones va variando; a esto se le conoce como entrenamiento del modelo a partir de una serie de datos.
Las redes neuronales recurrentes son un tipo de redes neuronales cuyo objetivo es detectar dependencias en datos secuenciales; esto significa que tienen la intención de encontrar correlaciones entre diferentes puntos dentro de una secuencia de datos. Las dependencias pueden ser a corto o largo plazo. El problema con las redes neuronales recurrentes es que solo detectan dependencias a corto plazo. Para solucionar esto, en la década de 1990 científicos alemanes desarrollaron una variante, conocida ahora como red neuronal recurrente de gran memoria a corto plazo (LSTM, por sus siglas en inglés), que permite detectar dependencias a largo plazo y mejorar considerablemente los pronósticos, lo que resulta en una alternativa formidable cuando se trata de un pronóstico con base en una serie de datos considerable (Dua, Yadav, Mamgai y Brodiya, 2020; Sherstinsky, 2020).
Sustentando lo anterior, un estudio realizado para el pronóstico del rendimiento de reservas de carbono concluyó que el método de redes neuronales LSTM obtuvo un error medio de pronóstico de 43.75 % menor al de las redes neuronales tradicionales, así como menor tiempo total del CPU y consumo de energía para los cálculos (Huang et al., 2021).
En la Figura 2 se muestra la estructura de una celda de red neuronal LSTM, donde los valores de c corresponden a la memoria, h representa las salidas y x las entradas. Los rectángulos dentro de la celda son redes neuronales simples con sus funciones de activación, mientras que los círculos son operaciones específicas para descartar, actualizar y calcular el nuevo estado de la memoria (Ferro, Celis y Casallas, 2020).

Otro de los modelos de pronóstico de aprendizaje automático, el bosque aleatorio, se basa en gran medida en el clásico modelo de árbol de decisión, pero le agrega más complejidad. Como sugiere el nombre, un bosque aleatorio consta de una gran cantidad de árboles de decisión, cada uno de ellos con una ligera variación, por lo que resulta más eficaz. Generalmente, un bosque aleatorio puede combinar cientos o incluso miles de modelos de árbol de decisión que se ajustan a datos ligeramente diferentes, por lo que no son totalmente iguales. Cuando un modelo de aprendizaje automático a veces puede estar equivocado, es menos probable que la predicción promedio de una gran cantidad de modelos de aprendizaje automático sea incorrecta, como se sustentará más adelante. Esta idea es la base del aprendizaje conjunto. En el bosque aleatorio, el aprendizaje por conjuntos se aplica a una repetición de muchos árboles de decisión. El aprendizaje conjunto se puede aplicar a cualquier combinación de una gran cantidad de modelos de aprendizaje automático. Los árboles de decisión han probado ser un modelo de alto rendimiento y fácil de configurar (Korstanje, 2021).
Un trabajo de investigación que tenía el objetivo de encontrar una metodología para la predicción de la demanda diaria de envíos de una empresa de comercio electrónico, por medio del uso de algoritmos tanto matemáticos como de aprendizaje automático, concluyó que los modelos que mejor se ajustaban a la serie de datos históricos de la empresa fueron estos últimos, específicamente el modelo de bosque aleatorio, tras la calibración de sus parámetros. Cabe recalcar que el segundo mejor modelo fue el de redes neuronales LSTM, por lo que no está demás considerar ambas opciones para la comparativa (Dalmau Barraza, 2020). En la Figura 3 se presenta un diagrama básico sobre el proceso de pronósticos mediante bosque aleatorio, que consiste en el promedio de los pronósticos de una gran cantidad de árboles de decisión.

Para atender el tema de mejorar los pronósticos mediante inteligencia artificial, han surgido durante la última década investigaciones que experimentan con la utilización de modelos que sean híbridos, es decir, que mediante fórmulas matemáticas combinan parámetros de un pronóstico tradicional con un pronóstico de aprendizaje automático, cuyos nombres se formulan al combinar los pronósticos que lo conforman, por ejemplo, el modelo híbrido ARIMA-LSTM (Phan y Nguyen, 2020).
La investigación realizada por Dave, Leonardo, Jeanice y Hanafiah (2021) concluyó que el modelo híbrido Arima-LSTM obtuvo un menor MAPE y un menor RMSE para pronosticar la demanda de exportaciones de Indonesia durante los años 2018 y 2019 comparado con los modelos Arima y LSTM por separado. Considerando que para la comparativa ya se ha recomendado el modelo Arima y el modelo LSTM, no resultará difícil realizar la combinación de ambos, por lo que se recomienda considerar este modelo híbrido a fin de obtener una mejor precisión de pronóstico.
En el año 2017, Facebook lanzó su propio modelo de pronósticos, llamado Prophet, que resulta difícil de clasificar, ya que no es una combinación de dos modelos diferentes, sino que fusiona el carácter paramétrico y estadístico de los modelos tradicionales con los modelos aditivos generalizados, los cuales buscan resaltar la tendencia subyacente de los datos. A su vez, Prophet incluye ciertas características de algunos modelos de aprendizaje automático, como son las máquinas de vectores de soporte, funciones de Kernel y expansiones en series de Fourier. Dado que el modelo no requiere, en la práctica, de un amplio conocimiento matemático ni de programación, se ha vuelto muy popular en el ámbito del análisis de datos y se considera una especie de modelo híbrido (aunque solo conceptualmente) que combina las ventajas de ambos tipos (Hannachi, 30 de abril de 2019).
Una investigación para determinar el mejor modelo de predicción de ventas de un supermercado seleccionó algunos modelos de pronóstico, tales como el modelo aditivo, el modelo Arima y el modelo Facebook Prophet. En dicho trabajo se concluyó que Facebook Prophet es un mejor modelo de predicción en términos de bajo error, mejor predicción y mejor ajuste que sus competidores. El resultado anterior deja entrever que el modelo pseudohíbrido Facebook Prophet tiene posibilidades de mejorar la exactitud de los modelos convencionales tanto estadísticos como de aprendizaje automático (Kumar Jha y Pande, 2021).
Como se mencionó en el modelo de bosque aleatorio, es menos probable que la predicción promedio de una gran cantidad de pronósticos sea incorrecta. Esta creencia se remonta, por lo menos, hasta la investigación realizada por Bates y Granger (1969), su aclamado artículo “The Combination of Forecasts”. En dicha investigación se combinaron dos conjuntos separados de pronósticos de datos de pasajeros de aerolíneas para formar un conjunto compuesto de pronósticos. La principal conclusión a la que se llegó fue que el conjunto compuesto de pronósticos puede producir un RMSE menor que cualquiera de los pronósticos originales. Los errores pasados de cada uno de los pronósticos originales se utilizaron para determinar las ponderaciones de los pronósticos originales, al formar los pronósticos combinados, y se examinaron diferentes métodos para derivar estas ponderaciones.
Años después, Winkler y Makridakis (1983) también obtendrían resultados empíricos que muestran que los pronósticos combinados de cinco modelos estadísticos, incluido el modelo Holt-Winters, son más precisos que los pronósticos por separado. Concluyeron, también, que los promedios ponderados son superiores a los pronósticos obtenidos a partir de un promedio simple, no ponderado, de los mismos modelos. En el artículo se propone un modelo matemático para el cálculo del promedio ponderado de los pronósticos, el cual puede probarse con los modelos propuestos en la presente investigación.
Retomando al Dr. Makridakis, y sus reconocidas competencias de pronósticos, estas volvieron a realizarse a partir del año 2018. Para la cuarta competencia (M4 Competition), se realizaron un total de 100 000 series de tiempo con 61 modelos de pronósticos para finanzas, pronósticos para la industria y pronósticos demográficos, a niveles macro y micro, entre otros. Los modelos fueron creados por los participantes, pertenecientes a empresas y universidades de todo el mundo. Los resultados arrojaron que 12 de los 17 modelos más precisos fueron combinaciones de otros modelos estadísticos, lo que concuerda con las teorías anteriores; sin embargo, un modelo híbrido realizado por Sławek Smyl, de la compañía Uber, resultó ganador (Makridakis, Spiliotis y Assimakopoulos, 2020).
Si bien la quinta competencia Makridakis (M5 competition) finalizó en julio del 2020, el International Institute of Forecasters no ha proporcionado completamente al público los resultados ni los métodos utilizados para los pronósticos, ya que en esta ocasión se trabajó con datos de ventas proporcionados por la empresa Wal-Mart (Makridakis et al., 2021); por lo que probablemente, por confidencialidad, no fue posible publicar el modelo ganador; sin embargo, con base en los datos disponibles, Kolassa (2021) asegura que los métodos de suavización exponencial, con una probabilidad de 92.5 %, son los mejores para el pronóstico de ventas de la empresa Wal-Mart. Lo que sí es un hecho es que las competencias de pronósticos han tenido un nuevo auge tras 18 años de ausencia, y buscan cada año enfocarse en un ámbito distinto; por ejemplo, la M6 Competition, a realizarse del año 2022 al año 2023, se enfocará en los pronósticos de inversiones financieras (M Open Forecasting Center [MOFC], 2021).
Discusión
El objetivo de la implementación de un sistema de pronósticos para un negocio es proporcionar información sobre futuros cambios en el entorno económico y el impacto de estos cambios en la empresa; por ejemplo, la competitividad dentro de la economía de mercado provoca la variabilidad de la demanda de determinados bienes. El nivel de producción debe reflejar las demandas de los clientes; esta demanda puede estimarse mediante pronósticos (Kurzak, 2012).
El presente trabajo de investigación ha optado por proponer una variedad de modelos de pronósticos que han demostrado su efectividad, acorde a diversos estudios comparativos de reciente publicación, para el pronóstico de la demanda en distintos escenarios económicos alrededor del mundo. De los modelos con enfoque estadístico, se proponen el modelo Arima y el modelo de suavización exponencial triple Holt-Winters (Stoll, 2020), recomendación que coincide con los resultados de las competencias Makridakis (Hanke y Wichern, 2014). De los modelos de aprendizaje automático, se sugieren las redes neuronales LSTM, en lugar de una típica red neuronal recurrente (Huang et al., 2021), y el modelo de bosque aleatorio, por demostrar un mejor ajuste en las predicciones (Stoll, 2020). Los resultados de la investigación de Dalmau (2020) destacan estas mismas propuestas. Por último, del enfoque híbrido se proponen el modelo Arima-LSTM, dado que ha demostrado mayor efectividad que los dos pronósticos por separado (Dave et al., 2021), y el modelo Facebook Prophet, por la facilidad de uso y su potencial para competir con otros modelos (Kumar Jha y Pande, 2021; López, 2018).
Se omitió la inclusión de los modelos de regresión lineal puesto que la investigación se enfocó exclusivamente en modelos de pronósticos de series de tiempo univariados. El principal motivo es que la implementación de los modelos de regresión lineal requiere una mayor cantidad de datos conforme se incrementan las variables, así como la necesidad de pruebas estadísticas para elegir las variables significativas para el modelo. Otro motivo es que los modelos lineales se ven limitados cuando la variable de análisis no tiene un comportamiento lineal, como lo puede ser la demanda, las ventas, el precio de un producto, la inflación u otras variables relacionadas al entorno económico (Binner, Bissoondeeal, Elger, Gazely y Mullineux, 2005). Un ejemplo de la afirmación anterior es la investigación de Morales, Ramírez y Rodríguez (2019), donde el modelo de regresión lineal múltiple se vio rebasado por los modelos no lineales de aprendizaje automático para el pronóstico de ventas de diferentes empresas de alimentos. Por otro lado, el modelo Arima, con los datos de una sola variable, tiene el potencial para igualar e incluso superar en ciertos escenarios a un modelo de regresión lineal múltiple (Correia, d'Angelo, Almeida y Mingoti, 2021).
Una vez propuestos los modelos de cada enfoque, la presente investigación propone ir más allá de las competencias o comparativas de los pronósticos, como las M-Competitions descritas por Makridakis et al. (2020), y no solo concluir cuál modelo tiene mejor comportamiento con los datos. Al igual que Rao y Gao (2021), se ha llegado a la conclusión de que, una vez obtenidos los pronósticos de cada uno de los modelos, es recomendable que se combinen a través de algún método de promedios ponderados, y obtener un modelo de pronósticos final que logre mayor precisión que los modelos por separado. Actualmente, los principales softwares de programación gratuitos para análisis de series de tiempo, R y Python, ofrecen distintas librerías y algoritmos para realizar automáticamente la combinación de varios modelos de pronósticos (Dutta, 2020; Hyndman, 2016).
Conclusiones
Con base en la literatura consultada, se concluye que no existe algún modelo de pronósticos que logre determinar perfectamente la demanda futura y la exactitud de este dependerá de la cantidad, la calidad y el comportamiento particular de los datos de la serie de tiempo. Tampoco existen métodos que permitan saber de antemano cuál modelo de pronósticos funcionará mejor, por lo que la tendencia en el ramo es ir aumentando la cantidad de opciones para realizar una comparativa, apoyándose en la potencia actual de las computadoras. Una serie de tiempo ideal es aquella que tiene un patrón en el comportamiento de los datos, es decir, que es una serie estacionaria, lo que permite realizar un pronóstico con menor error de precisión.
Cuando una serie de tiempo no es estacionaria, se recurre a una transformación matemática, conocida como diferencia, que permita trabajar con ella. Los modelos de pronósticos de serie de tiempo tradicionales engloban los métodos que tienen un enfoque puramente estadístico; por otro lado, los modelos modernos abarcan los pronósticos bajo dos enfoques: enfoque de aprendizaje automático (machine learning) y enfoque híbrido. Se encontró evidencia que sustenta que la combinación, mediante métodos de promedios ponderados, de varios modelos de pronósticos suele dar mejores resultados que el pronóstico de los modelos por separado.
En la Tabla 2 se muestran los modelos de pronósticos que la presente investigación propone para realizar una comparativa y determinar cuál modelo se comporta mejor para el pronóstico de la demanda. Como criterios de evaluación se usaron el MAPE y la raíz cuadrada del RMSE.
Tabla 2 Modelos propuestos a pequeñas y medianas empresas para el pronóstico de la demanda
| Modelo | Tipo | Características |
| Suavización exponencial triple (Holt-Winters) | Modelo tradicional. Enfoque estadístico. | Se busca encontrar los valores óptimos de las constantes de atenuación del promedio de los datos (α), de la tendencia (β) y la componente estacional (γ) para construir la serie de tiempo del pronóstico que mejor se ajuste a los datos, por lo que se requiere de patrones de variación regulares. |
| Promedios móviles autorregresivos integrados (Arima) o Metodología de Box-Jenkins | Modelo tradicional. Enfoque estadístico. | Se conforma de las componentes autorregresiva (p), integrada (d) y de media móvil (q) que utilizan las variaciones y correlaciones existentes dentro de la serie de tiempo para determinar patrones y, a partir de ellos, generar un pronóstico, para lo cual a veces es necesario transformar la serie a fin de volverla estacional. |
| Redes neuronales recurrentes de gran memoria a corto plazo (LSTM) | Modelo Moderno. Enfoque de aprendizaje automático. | Funciona a través de celdas que simulan ser una neurona biológica, las cuales realizan operaciones lógicas que le permiten memorizar patrones y dependencias de una serie de datos a corto y largo plazo para de esta forma generar un pronóstico. |
| Bosque aleatorio | Modelo Moderno. Enfoque de aprendizaje automático. | Con base en la serie de datos, el programa crea una gran serie de árboles de decisión con un pronóstico similar para cada uno. El algoritmo promedia todos los pronósticos para obtener un pronóstico final, con menor error que los pronósticos individuales. |
| Arima-LSTM | Modelo moderno. Enfoque híbrido. | Es la combinación del modelo Arima y el modelo de redes neuronales LSTM. |
| Facebook Prophet | Modelo moderno. Enfoque híbrido. | Un modelo fácil de usar que busca que las tendencias no lineales se ajusten a la estacionalidad anual, aun cuando se tengan datos faltantes. Matemáticamente se sustenta en series de Fourier y en la regresión aditiva. |
Fuente: Elaboración propia
Contribuciones a futuras líneas de investigación
El presente trabajo de investigación constituye un análisis del estado del arte de los pronósticos de la demanda mediante análisis de series de tiempo, y hace la recomendación de seis de los modelos más efectivos que se utilizan actualmente, los cuales pueden implementarse en cualquier empresa con un software libre, como pueden ser R y Python, o incluso Excel, si se opta por probar solo los modelos de pronósticos estadísticos. Por último, se recomienda que, una vez realizados los pronósticos, se considere una séptima opción: la combinación, mediante promedios ponderados, de todos los modelos propuestos, y darle mayor peso al método con mejores resultados, a fin de corroborar que la combinación de varios pronósticos resulta mejor que por separado.

